位元組跳動基於Apache Atlas的近實時訊息同步能力最佳化
位元組資料中臺DataLeap的Data Catalog系統透過接收MQ中的近實時訊息來同步部分後設資料。Apache Atlas對於實時訊息的消費處理不滿足效能要求,內部使用Flink任務的處理方案在ToB場景中也存在諸多限制,所以團隊自研了輕量級非同步訊息處理框架,支援了位元組內部和火山引擎上同步後設資料的訴求。本文定義了需求場景,並詳細介紹框架的設計與實現。
背景
動機
位元組資料中臺DataLeap的Data Catalog系統基於Apache Atlas搭建,其中Atlas透過Kafka獲取外部系統的後設資料變更訊息。在開源版本中,每臺伺服器支援的Kafka Consumer數量有限,在每日百萬級訊息體量下,經常有長延時等問題,影響使用者體驗。
在2020年底,我們針對Atlas的訊息消費部分做了重構,將訊息的消費和處理從後端服務中剝離出來,並編寫了Flink任務承擔這部分工作,比較好的解決了擴充套件性和效能問題。然而,到2021年年中,團隊開始重點投入私有化部署和火山公有云支援,對於Flink叢集的依賴引入了可維護性的痛點。
在仔細的分析了使用場景和需求,並調研了現成的解決方案後,我們決定投入人力自研一個訊息處理框架。當前這個框架很好的支援了位元組內部以及ToB場景中Data Catalog對於訊息消費和處理的場景。
本文會詳細介紹框架解決的問題,整體的設計,以及實現中的關鍵決定。
需求定義
使用下面的表格將具體場景定義清楚。

相關工作
在啟動自研之前,我們評估了兩個比較相關的方案,分別是Flink和Kafka Streaming。
Flink是我們之前生產上使用的方案,在能力上是符合要求的,最主要的問題是長期的可維護性。在公有云場景,那個階段Flink服務在火山雲上還沒有釋出,我們自己的服務又有嚴格的時間線,所以必須考慮替代;在私有化場景,我們不確認客戶的環境一定有Flink叢集,即使部署的資料底座中帶有Flink,後續的維護也是個頭疼的問題。另外一個角度,作為通用流式處理框架,Flink的大部分功能其實我們並沒有用到,對於單條訊息的流轉路徑,其實只是簡單的讀取和處理,使用Flink有些“殺雞用牛刀”了。
另外一個比較標準的方案是Kafka Streaming。作為Kafka官方提供的框架,對於流式處理的語義有較好的支援,也滿足我們對於輕量的訴求。最終沒有采用的主要考慮點是兩個:
對於Offset的維護不夠靈活:我們的場景不能使用自動提交(會丟訊息),而對於同一個Partition中的資料又要求一定程度的並行處理,使用Kafka Streaming的原生介面較難支援。
與Kafka強繫結:大部分場景下,我們團隊不是後設資料訊息佇列的擁有者,也有團隊使用RocketMQ等提供後設資料變更,在應用層,我們希望使用同一套框架相容。
設計
概念說明
MQ Type:Message Queue的型別,比如Kafka與RocketMQ。後續內容以Kafka為主,設計一定程度相容其他MQ。
Topic:一批訊息的集合,包含多個Partition,可以被多個Consumer Group消費。
Consumer Group:一組Consumer,同一Group內的Consumer資料不會重複消費。
Consumer:消費訊息的最小單位,屬於某個Consumer Group。
Partition:Topic中的一部分資料,同一Partition內訊息有序。同一Consumer Group內,一個Partition只會被其中一個Consumer消費。
Event:由Topic中的訊息轉換而來,部分屬性如下。
Event Type:訊息的型別定義,會與Processor有對應關係;
Event Key:包含訊息Topic、Partition、Offset等後設資料,用來對訊息進行Hash操作;
Processor:訊息處理的單元,針對某個Event Type定製的業務邏輯。
Task:消費訊息並處理的一條Pipeline,Task之間資源是相互獨立的。
框架架構
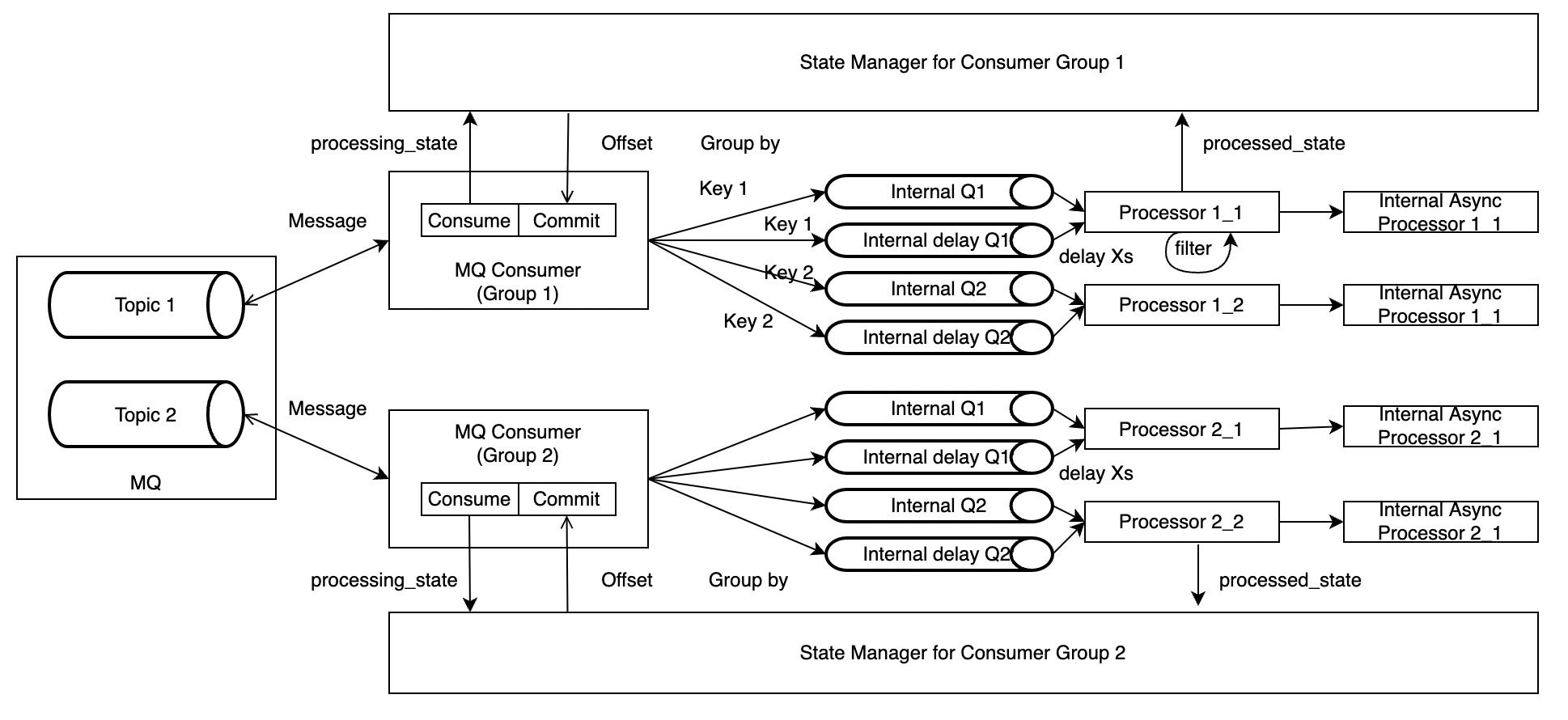
整個框架主要由MQ Consumer, Message Processor和State Manager組成。
MQ Consumer:負責從Kafka Topic拉取訊息,並根據Event Key將訊息投放到內部佇列,如果訊息需要延時消費,會被投放到對應的延時佇列;該模組還負責定時查詢State Manager中記錄的訊息狀態,並根據返回提交訊息Offset;上報與訊息消費相關的Metric。
Message Processor:負責從佇列中拉取訊息並非同步進行處理,它會將訊息的處理結果更新給State Manager,同時上報與訊息處理相關的Metric。
State Manager:負責維護每個Kafka Partition的訊息狀態,並暴露當前應提交的Offset資訊給MQ Consumer。
實現
執行緒模型
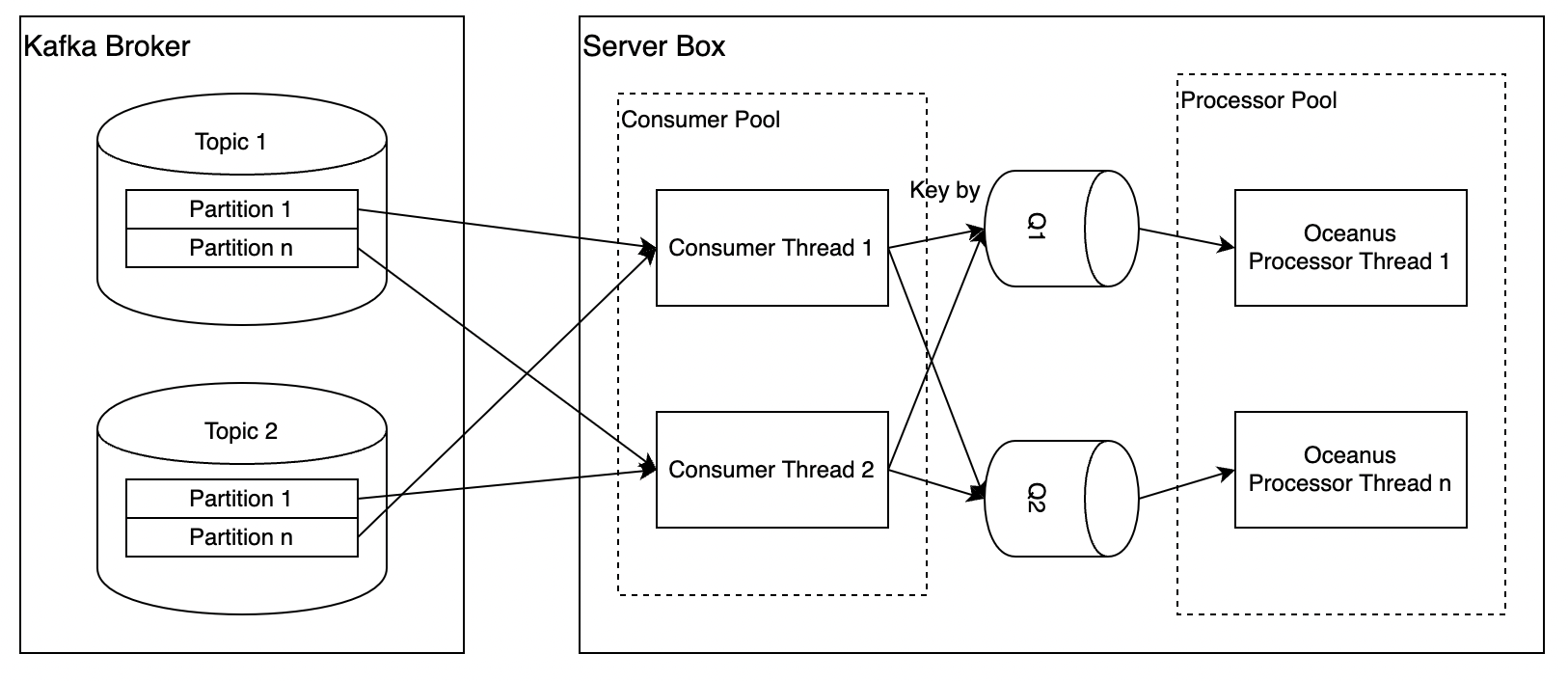
每個Task可以執行在一臺或多臺例項,建議部署到多臺機器,以獲得更好的效能和容錯能力。
每臺例項中,存在兩組執行緒池:
Consumer Pool:負責管理MQ Consumer Thread的生命週期,當服務啟動時,根據配置拉起一定規模的執行緒,並在服務關閉時確保每個Thread安全退出或者超時停止。整體有效Thread的上限與Topic的Partition的總數有關。
Processor Pool:負責管理Message Processor Thread的生命週期,當服務啟動時,根據配置拉起一定規模的執行緒,並在服務關閉時確保每個Thread安全退出或者超時停止。可以根據Event Type所需要處理的並行度來靈活配置。
兩類Thread的性質分別如下:
Consumer Thread:每個MQ Consumer會封裝一個Kafka Consumer,可以消費0個或者多個Partition。根據Kafka的機制,當MQ Consumer Thread的個數超過Partition的個數時,當前Thread不會有實際流量。
Processor Thread:對應一個內部的佇列,並以FIFO的方式消費和處理其中的訊息。
StateManager
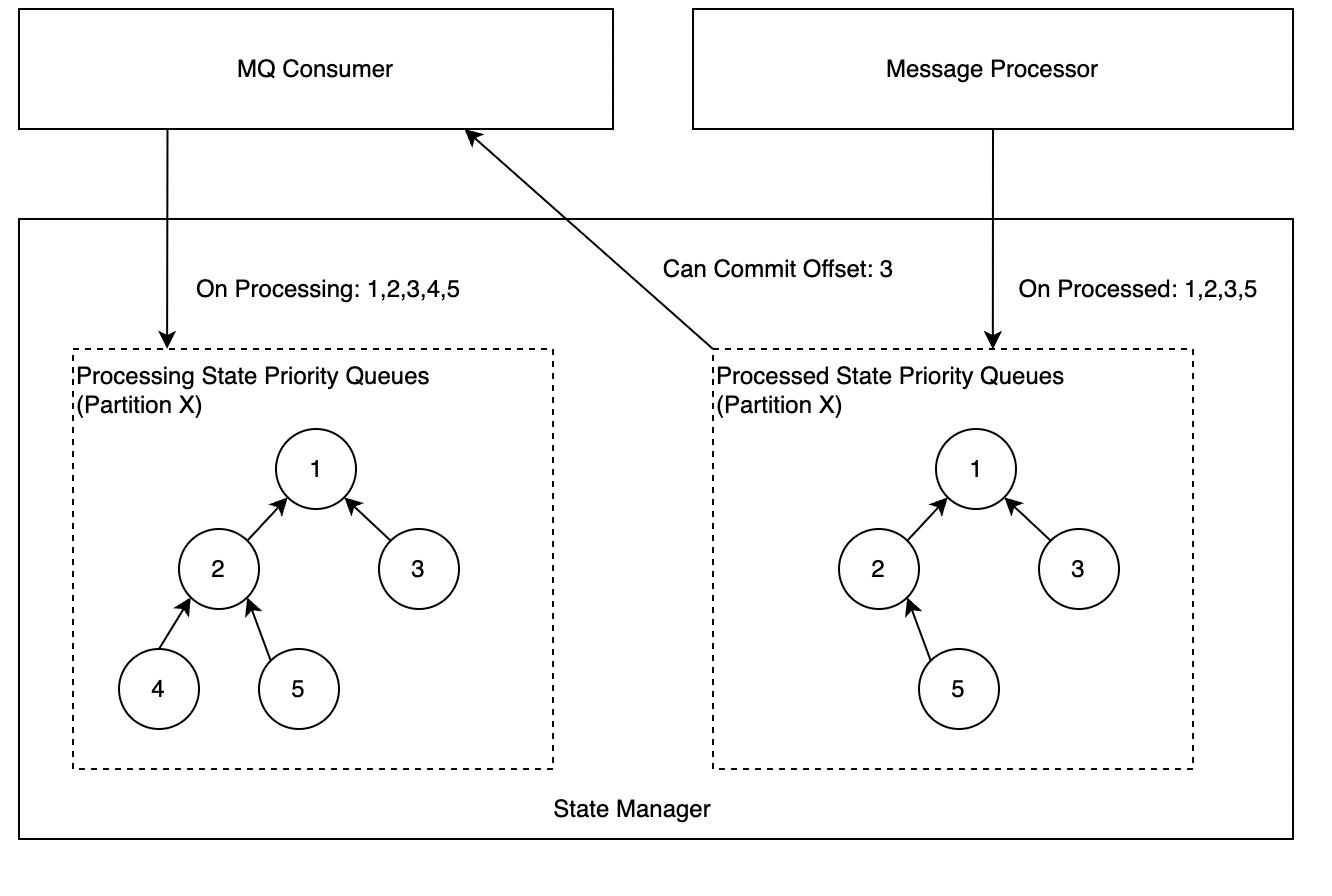
在State Manager中,會為每個Partition維護一個優先佇列(最小堆),佇列中的資訊是Offset,兩個優先佇列的職責如下:
處理中的佇列:一條訊息轉化為Event後,MQ Consumer會呼叫StateManager介面,將訊息Offset 插入該佇列。
處理完的佇列:一條訊息處理結束或最終失敗,Message Processor會呼叫StateManager介面,將訊息Offset插入該佇列。
MQ Consumer會週期性的檢查當前可以Commit的Offset,情況列舉如下:
處理中的佇列堆頂 < 處理完的佇列堆頂或者處理完的佇列為空:代表當前消費回來的訊息還在處理過程中,本輪不做Offset提交。
處理中的佇列堆頂 = 處理完的佇列堆頂:表示當前訊息已經處理完,兩邊同時出隊,並記錄當前堆頂為可提交的Offset,重複檢查過程。
處理中的佇列堆頂 > 處理完的佇列堆頂:異常情況,通常是資料回放到某些中間狀態,將處理完的佇列堆頂出堆。
注意:當發生Consumer的Rebalance時,需要將對應Partition的佇列清空
KeyBy與Delay Processing的支援
因源頭的Topic和訊息格式有可能不可控制,所以MQ Consumer的職責之一是將訊息統一封裝為Event。
根據需求,會從原始訊息中拼裝出Event Key,對Key取Hash後,相同結果的Event會進入同一個佇列,可以保證分割槽內的此類事件處理順序的穩定,同時將訊息的消費與處理解耦,支援增大內部佇列數量來增加吞吐。
Event中也支援設定是否延遲處理屬性,可以根據Event Time延遲固定時間後處理,需要被延遲處理的事件會被髮送到有界延遲佇列中,有界延遲佇列的實現繼承了DelayQueue,限制DelayQueue長度, 達到限定值入隊會被阻塞。
異常處理
Processor在訊息處理過程中,可能遇到各種異常情況,設計框架的動機之一就是為業務邏輯的編寫者遮蔽掉這種複雜度。Processor相關框架的邏輯會與State Manager協作,處理異常並充分暴露狀態。比較典型的異常情況以及處理策略如下:
處理訊息失敗:自動觸發重試,重試到使用者設定的最大次數或預設值後會將訊息失敗狀態通知State Manager。
處理訊息超時:超時對於吞吐影響較大,且通常重試的效果不明顯,因此當前策略是不會對訊息重試,直接通知State Manager 訊息處理失敗。
處理訊息較慢:上游Topic存在Lag,Message Consumer消費速率大於Message Processor處理速率時,訊息會堆積在佇列中,達到佇列最大長度,Message Consumer 會被阻塞在入隊操作,停止拉取訊息,類似Flink框架中的背壓。
監控
為了方便運維,在框架層面暴露了一組監控指標,並支援使用者自定義Metrics。其中預設支援的Metrics如下表所示:

線上運維case舉例
實際生產環境執行時,偶爾需要做些運維操作,其中最常見的是訊息堆積和訊息重放。
對於Conusmer Lag這類問題的處理步驟大致如下:
檢視Enqueue Time,Queue Length的監控確定服務內佇列是否有堆積。
如果佇列有堆積,檢視Process Time指標,確定是否是某個Processor處理慢,如果是,根據指標中的Tag 確定事件型別等屬性特徵,判斷業務邏輯或者Key設定是否合理;全部Processor 處理慢,可以透過增加Processor並行度來解決。
如果佇列無堆積,排除網路問題後,可以考慮增加Consumer並行度至Topic Partition 上限。
訊息重放被觸發的原因通常有兩種,要麼是業務上需要重放部分資料做補全,要麼是遇到了事故需要修復資料。為了應對這種需求,我們在框架層面支援了根據時間戳重置Offset的能力。具體操作時的步驟如下:
使用服務測暴露的API,啟動一臺例項使用新的Consumer GroupId: {newConsumerGroup} 從某個startupTimestamp開始消費
更改全部配置中的 Consumer GroupId 為 {newConsumerGroup}
分批重啟所有例項
總結
為了解決位元組資料中臺DataLeap中Data Catalog系統消費近實時後設資料變更的業務場景,我們自研了輕量級訊息處理框架。當前該框架已在位元組內部生產環境穩定執行超過1年,並支援了火山引擎上的資料地圖服務的後設資料同步場景,滿足了我們團隊的需求。
下一步會根據優先順序排期支援RocketMQ等其他訊息佇列,並持續最佳化配置動態更新,監控報警,運維自動化等方面。
來自 “ DataFunTalk ”, 原文作者:位元組跳動資料平臺;原文連結:http://server.it168.com/a2022/1024/6769/000006769745.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 位元組跳動基於Doris的湖倉分析探索實踐
- 中信建投:孤獨的騰訊,跳動的位元組(位元組跳動篇-附下載)
- 關於位元組跳動的神話與現實(上)
- 關於位元組跳動的神話與現實(下)
- 位元組跳動,跳動的“遊戲夢”遊戲
- 位元組跳動資料湖在實時數倉中的實踐
- 端到端最佳化所有能力,位元組跳動提出強化學習LLM Agent框架AGILE強化學習框架
- 位元組跳動上海招人
- 不要神化位元組跳動
- 基於TimeLine模型的訊息同步機制模型
- 位元組跳動視訊編解碼面經
- 位元組跳動VS騰訊:世紀之戰
- Voodoo、騰訊的王炸組合能否“幹掉”位元組跳動?Odoo
- 基於WebSocket的實時訊息傳遞設計Web
- 攪局者,位元組跳動
- 位元組跳動“玩心”變重
- 再見了,位元組跳動
- 位元組跳動ios面經iOS
- 位元組跳動流式資料整合基於Flink Checkpoint兩階段提交的實踐和優化優化
- 位元組跳動的「遊戲」法則遊戲
- 位元組跳動的技術架構架構
- 李亞坤:Hadoop YARN在位元組跳動的實踐HadoopYarn
- 位元組跳動在 Go 網路庫上的實踐Go
- KMQ:基於Apache Kafka的可靠性訊息佇列MQApacheKafka佇列
- 位元組跳動和TikTok內推
- 位元組跳動的16款重度遊戲遊戲
- 位元組跳動的遊戲大冒險遊戲
- 【位元組跳動】【上海】iOS開發實習生招聘iOS
- 【位元組跳動】【上海】Android開發實習生招聘Android
- 【位元組跳動】【上海】前端開發實習生招聘前端
- 位元組跳動 YARN 雲原生化演進實踐Yarn
- 位元組跳動BitsAI-CR:基於LLM的程式碼審查系統技術揭秘AI
- Presto 在位元組跳動的內部實踐與優化REST優化
- 手握15億月活,位元組跳動跳向何方?
- 15億月活背後的無奈,位元組跳動撼動騰訊或仍為時尚早
- 10000小時後,我從外包走進了位元組跳動
- 位元組跳動近日申請多個“位元組遊戲”商標遊戲
- 秋招真實記錄:緊張的337小時,我終於等來了位元組跳動offer(Android崗)Android