一、作業內容
作業①:
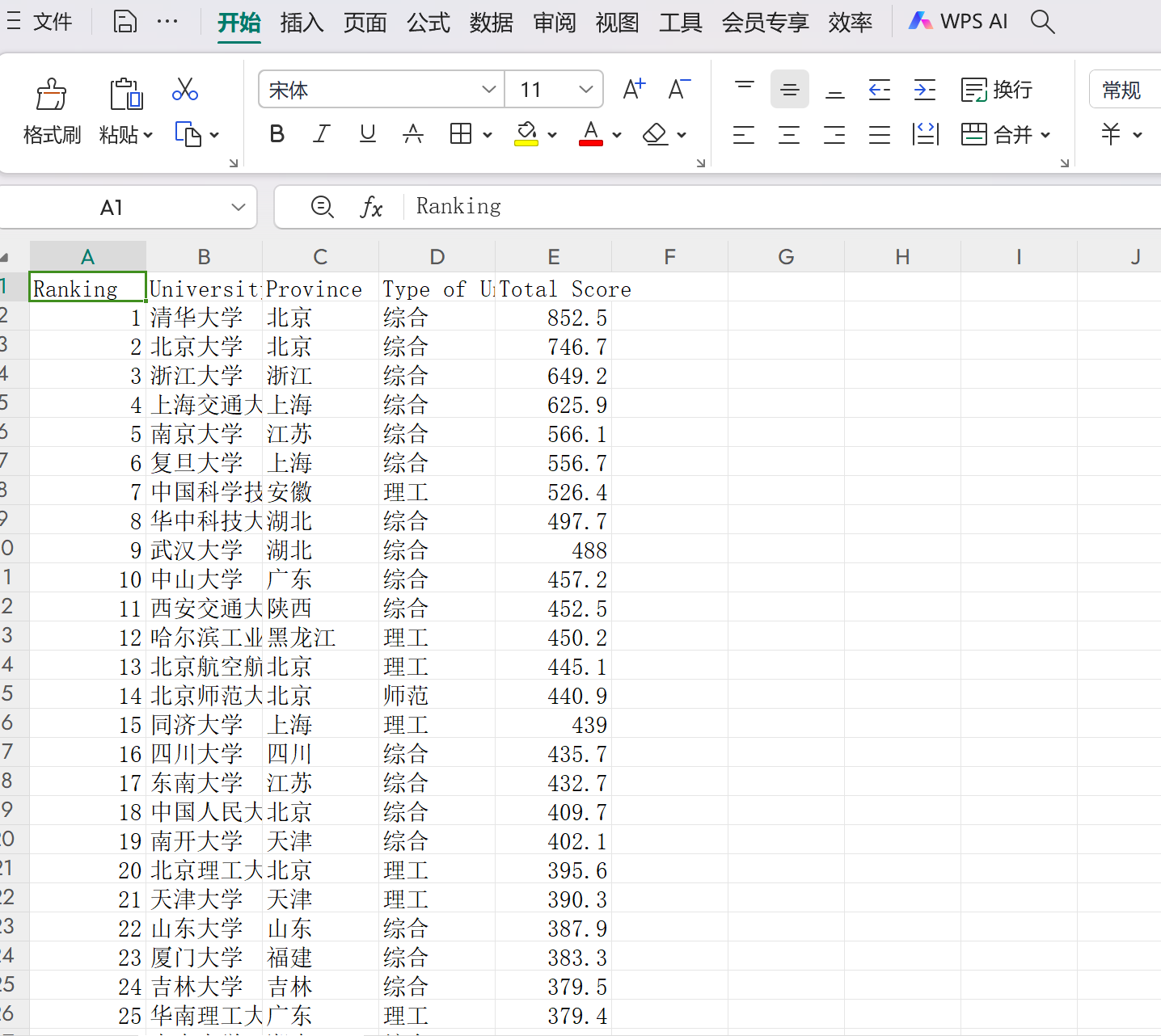
要求:用requests和BeautifulSoup庫方法定向爬取給定網址(http://www.shanghairanking.cn/rankings/bcur/2020)的資料,螢幕列印爬取的大學排名資訊。
import urllib.request
from bs4 import BeautifulSoup
import csv
# 定義爬取和解析網頁的函式
def scrape_university_rankings(url):
# 使用urllib獲取網頁內容
with urllib.request.urlopen(url) as response:
html_content = response.read()
# 使用BeautifulSoup解析HTML
soup = BeautifulSoup(html_content, 'html.parser')
# 找到包含排名資訊的表格
table = soup.find('table')
# 建立一個列表來儲存所有行的資料
rows_data = []
# 遍歷表格的每一行
for row in table.find_all('tr')[1:]: # 跳過表頭
cols = row.find_all('td')
ranking = cols[0].text.strip()
university_name = cols[1].text.split('\n')[0].strip() # 假設中文名稱在第一行
province = cols[2].text.strip()
type_of_university = cols[3].text.strip()
total_score = cols[4].text.strip()
# 將當前行資料新增到列表中
rows_data.append([ranking, university_name, province, type_of_university, total_score])
# 將資料寫入CSV檔案
with open('university_rankings.csv', mode='w', newline='', encoding='utf-8') as csvfile:
fieldnames = ['Ranking', 'University Name', 'Province', 'Type of University', 'Total Score']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
for data_row in rows_data:
writer.writerow({'Ranking': data_row[0],
'University Name': data_row[1],
'Province': data_row[2],
'Type of University': data_row[3],
'Total Score': data_row[4]})
# 爬取並列印大學排名資訊
url = 'http://www.shanghairanking.cn/rankings/bcur/2020'
scrape_university_rankings(url)
效果如下:

最佳化後:
心得體會:
透過編寫這個簡單的網頁爬蟲,我體驗到了資料抓取與處理的全過程。首先,利用urllib.request獲取了上海軟科釋出的中國大學排名網頁內容,接著使用BeautifulSoup庫解析HTML文件,從中抽取了包含排名資訊的表格。這一過程讓我深刻理解了網路資源的結構化表示以及如何有效地從這些結構中提取所需資訊。此外,我還學習瞭如何將提取到的資料整理成列表,並最終以CSV格式儲存下來,便於後續分析或分享。
作業②:
要求:用requests和re庫方法設計某個商城(自已選擇)商品比價定向爬蟲,爬取該商城,以關鍵詞“書包”搜尋頁面的資料,爬取商品名稱和價格。
import requests
import re
from html import unescape
# 修改URL以訪問第二頁
url = r'http://search.dangdang.com/?key=%CA%E9%B0%FC&act=input&page_index=2'
try:
req = requests.get(url)
req.raise_for_status()
req.encoding = req.apparent_encoding
except Exception as e:
print(f"Error in request: {e}")
else:
data = req.text
# 查詢商品列表的開始位置
match = re.search(r'<ul class="bigimg cloth_shoplist" id="component_59">.*?</ul>', data, re.DOTALL)
if match:
data = match.group(0)
# 初始化計數器
i = 1
# 迴圈查詢每個商品項
while True:
start = re.search(r'<li', data)
if not start:
break # 如果沒有找到<li>標籤,則退出迴圈
end = re.search(r'</li>', data)
if not end:
break # 如果沒有找到</li>標籤,則退出迴圈
my_data = data[start.end():end.start()]
# 提取價格
price_match = re.search(r'<span class="price_n">(.*?)</span>', my_data)
price = price_match.group(1) if price_match else 'N/A'
# 解碼HTML實體
price = unescape(price)
# 提取商品名
title_match = re.search(r'title="(.*?)"', my_data)
name = title_match.group(1) if title_match else 'N/A'
# 列印結果
print(i, name, price, sep='\t')
# 更新data為下一個商品之後的內容
data = data[end.end():]
# 計數器遞增
i += 1
else:
print("No matching content found for the product list.")
效果如下:

心得:
透過這次實踐,我體驗了使用Python進行網頁資料抓取的過程,並且成功獲取了當當網上關於“書包”關鍵詞搜尋結果第二頁的商品資訊。利用requests庫傳送HTTP請求並處理響應,結合正規表示式從HTML內容中提取所需的資料,這個過程讓我對網路爬蟲有了更深入的理解。
總結
整個過程中,我學會了如何構造正確的URL以訪問特定頁面,以及如何有效地解析和提取網頁中的結構化資料。面對複雜的HTML文件時,選擇合適的正規表示式模式至關重要,這要求我們不僅要熟悉目標網站的結構,還要具備良好的模式匹配技能。
作業③:
要求:爬取一個給定網頁( https://news.fzu.edu.cn)或者自選網頁的所有JPEG和JPG格式檔案
輸出資訊:將自選網頁內的所有JPEG和JPG檔案儲存在一個資料夾中
import os
import requests
from bs4 import BeautifulSoup
from urllib.parse import urljoin
# 設定請求頭資訊
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36 Edg/129.0.0.0'
}
# 目標URL
url = 'https://news.fzu.edu.cn'
# 傳送HTTP請求
response = requests.get(url, headers=headers)
response.raise_for_status() # 檢查請求是否成功
# 解析HTML內容
soup = BeautifulSoup(response.text, 'html.parser')
# 建立儲存圖片的目錄
output_dir = 'downloaded_images'
os.makedirs(output_dir, exist_ok=True)
# 查詢所有圖片標籤
images = soup.find_all('img')
for img in images:
# 獲取圖片連結
img_url = img.get('src')
if not img_url:
continue # 跳過沒有src屬性的圖片標籤
# 處理相對路徑
full_img_url = urljoin(url, img_url)
# 檢查圖片副檔名是否為.jpeg或.jpg
if not (full_img_url.lower().endswith('.jpg') or full_img_url.lower().endswith('.jpeg')):
continue # 如果不是,則跳過
# 獲取圖片名稱
img_name = os.path.basename(full_img_url)
# 請求圖片資料
img_response = requests.get(full_img_url, headers=headers)
img_response.raise_for_status()
# 儲存圖片
with open(os.path.join(output_dir, img_name), 'wb') as f:
f.write(img_response.content)
print("JPEG/JPG圖片下載完成!")
效果如下:

心得:
透過這次實踐,我體驗了使用Python進行網頁圖片抓取的全過程。首先,我利用requests庫傳送帶有適當User-Agent的HTTP請求,成功獲取了福州大學新聞網的頁面內容。接著,藉助BeautifulSoup解析HTML文件,從中定位所有圖片標籤,並處理了相對路徑問題以構建完整的圖片URL。在過濾出.jpg和.jpeg格式的圖片後,再次使用requests下載這些圖片到本地資料夾中。
總結
此次專案主要實現了從指定網站自動下載JPEG/JPG格式圖片的功能。過程中涉及的關鍵技術包括設定合適的請求頭來模擬瀏覽器訪問、使用BeautifulSoup解析HTML文件以提取圖片連結、處理URL的相對路徑確保能正確訪問資源,以及將圖片資料寫入本地檔案系統。
不足與反思
在爬取第一個作業的時候,出現了爬取的序號和名稱對應混亂,修改後較好,後續新增了csv.
在爬取第三個作業的時候,爬取https://news.fzu.edu.cn/yxfd.htm只出現了三張圖片,於是我換了一個網https://news.fzu.edu.cn/,爬出來叫多照片,為後續將再次嘗試。