事關每個人幸福的演算法模型:被困先驗 - astralcodexten
如今人工智慧研究和人類大腦研究相互促進,本文提出一種理性模型事關每個人的幸福,如果你理解了,你就會釋然:人類大腦是將原始經歷(如感覺、記憶)與上下文(如先驗、期望、其他相關的感覺和記憶)結合起來產生感知。大白話:人類感知=原始經歷(raw experience/evidence )+上下文(先驗priors),本文是圍繞這兩個部分比重不同展開的。中國有句諺語:一朝被蛇咬,十年怕草繩,本文提出“被困先驗”模型解釋這種心理現象以及形成偏見和固執的原因:
一般人的認知方式是一種正常的貝葉斯推理:假設您住在加利福尼亞州的一個普通郊區,而您的朋友說她在上班途中看到了土狼。你能相信她 :您的原始經歷(朋友說的這句話,未經分析的經歷,原始經歷,raw experience)和您的上下文背景(土狼在您所在的地區很豐富)加起來好像是那麼一回事;但是,假設您的朋友說她在上班途中看到一隻北極熊。現在,您就對此懷疑了;原始經歷(朋友說的這件事)是相同的,但是上下文(先驗是加利福尼亞出現北極熊的概率很低)使其變得難以置信。
正常認知的貝葉斯推理舉例
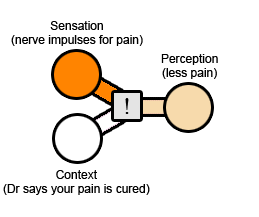
安慰劑作用幾乎同樣道理:您很痛苦,所以您的醫生給您開了一個“止痛藥”(您不知道這確實是一種糖藥)。原始經歷是神經發出的疼痛衝動與以前一樣多。上下文是您剛吃了一顆藥,醫生保證您會得到改善。結果:您的痛苦減輕了。
下圖感嘆號的灰色框,代表“加權演算法”。有時,演算法會將幾乎所有的精力都放在原始經歷上,最終結果將都是原始經歷,只需要根據上下文對其進行少量調整。在其他時候,它將幾乎全部放在上下文上,最終結果將幾乎完全不依賴於原始經歷。或者這個演算法的權重為50-50。這裡的因素非常複雜,我希望即使我將灰色框也視為黑色框,您仍然可以找到幫助。
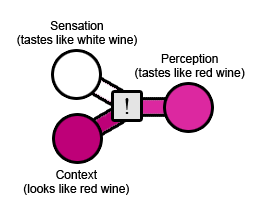
案例2:如果將白葡萄酒染成紅色,很多人會說它的味道像紅酒。原始經歷是:葡萄酒本身的味道,就是白葡萄酒。但實際情況上下文是您喝的是紅色液體。結果:它的味道像紅酒。(這裡權重多數傾斜在了上下文)
什麼是被困先驗
有很多關於老鼠的習慣研究:敲響鈴鐺,然後給老鼠電擊。在您執行了足夠的次數後,他們會害怕鐘聲-聽到它們後便會畏縮(一朝被蛇咬,十年怕草繩)。然後,您切換為響鈴,不觸電。剛開始時,老鼠仍然不怕鐘聲。但是過了一會兒,他們意識到鐘聲再也不會傷害他們了。他們會像對待其他噪音一樣進行調整。他們失去了恐懼-他們習慣了。
人類也會發生同樣的事情。也許當您還很小的時候,一隻大狗在向您咆哮,有一陣子您怕狗了。但是隨後您遇到了許多友好的可愛幼犬,您意識到大多數狗並不可怕,並且您得出了一些合理的結論,例如“長大的大狗很可怕,但可愛的幼犬卻並不可怕”。
有些人卻永遠無法做到這一點。他們會感到恐懼,對狗的病理恐懼(一朝被蛇咬,十年怕草繩)。在其最初的技術用途中,恐懼症是一種強烈的恐懼,無論您有多少次接觸狗而沒有發生任何不好的事情,您都會保持恐懼。為什麼?
在過去,心理學家會通過向患者灌輸恐懼物件來治療恐懼症。我們會將您放在一個巨大的羅威納犬的房間裡,鎖上門,等到您出來時,也許您將不再怕狗了。聽起來野蠻?也許是這樣,但更重要的是它實際上並沒有起作用。您可以和羅威納犬一起呆在房間裡整整一整天,羅威納犬可以入睡或舔臉,或者做一些其他足以使您相信它並不可怕的事情,而等到您離開時,您就會比您進門時更怕狗。
現在是通過這種辦法解決:首先,讓您從看狗的圖片開始,如果您的情況足夠嚴重,甚至這些圖片也會使您有些緊張。一旦您看了成千上萬張照片,就習慣了看它們。然後,我們將把您放在一個大房間裡,關著一隻可愛的小狗在籠子裡。您不必靠近小狗,也不必撫摸小狗,只需坐在房間裡就不會抓狂。一旦您完成了無數次的嘗試並失去了所有的恐懼,直到您被羅威納犬鎖在房間裡為止。
有道理的是,一旦您與狗接觸一百萬次並且一切正常,一切都會好起來的,您會失去對狗的恐懼-這是正常的習慣。
但是現在我們回到了最初的問題:為什麼我們不能只從羅威納犬開始呢?
常識性的答案是,只有當與狗的經歷最終變得安全無事時,您才會習慣。但是和羅威納犬一起呆在房間裡真是太恐怖了。這不是安全的好經歷。
表面上看:習慣化需要一種安全感,但是(像其他所有感性一樣)其實這種所謂習慣還是取決於原始經歷和上下文的結合。
原始經驗:羅威納犬平靜地搖著尾巴,看起來不嚇人。但是一旦被狗嚇壞之後,就有一個非常強烈的原始經歷,結果:羅威納犬令人恐懼。以後你做的任何上下文的更新將傾向於狗是可怕的,而不是相反!

這就是被困的先驗。
它被困是因為無論您得到什麼新證據,最終感知都永遠不會更新。您可以連續擁有一百萬條與狗有關的好經歷,而每條狗只會使您更深地擔心狗。您先前對狗的恐懼決定了您目前的經歷,而這反過來又成為了以後相遇時的精神錯亂。
被困先驗的高階版本
上面的部分描述了被困先驗的簡單認知情況。它根本沒有帶來情感的想法:如果使用相同型別的貝葉斯推理演算法實現計算機程式,那麼無情感的威脅評估計算機程式可能會理想地解決相同的問題。但是,當人們情緒激動時,就會發現自己更容易產生偏見。為什麼?
Van der Bergh等人建議,當原始經歷太不能忍受時,您的大腦會減少“原始經歷”通道上的頻寬,以保護您免受創傷性情緒的影響。這就是為什麼某些創傷受害者對其創傷的描述通常很短,不詳細且不切實際的原因。這樣可以保護受害者,使其不必在所有血腥細節中都受到可怕的刺激和負面情緒的影響。但這也確保上下文(而不是原始經歷本身)將在確定他們對事件的感知中起主導作用。
您無法更新有關這隻狗很友善的感知,因為您的原始經歷頻寬變得非常狹窄。你最終認知是幾乎完全基於你對狗有什麼原生經歷。
有人稱其為母狗吃餅乾,當您處於被虐待或其他可怕關係中。您的伴侶給了您充分的理由來憎恨他們。即使看到他們吃餅乾的看似無辜的事情,也會讓您很生氣。從理論上講,與伴侶的互動中,他們只是吃薄脆餅乾而不會以任何方式打擾您,這應該會產生一些習慣,這只是很小的證據,表明它們並不總是那麼糟糕。實際上,這隻會使您更討厭它們。在這一點上,您對它們不好的原始經歷之所以如此之高,以至於每一次互動,無論它如何進行,都會使您更加討厭它們。您被之前認為它們不好的東西困住了,產生了偏見。
這種模型表明:越來越多的證據只會使您更加確定自己的既定信念也就是原始經歷,而不論它是否可能否定了你的原始經歷,這些都是被困先驗的悲哀,這些人好像命中註定了。(偏見、固執己見一生無法醒悟)
更多點選標題見原文,原文後有非常熱烈的長篇討論,因為這種模型理論事關每個人的幸福。
相關文章
- 讓一個人越活越幸福的5個方法
- 每個 Linux 遊戲玩家都絕不想要的惱人體驗Linux遊戲
- 每個綠帶都應該知道的事
- 【躍遷】每個人都是自己的天使投資人
- @中建八局承@海口灣廣場疫情防控事關每個人,容不得半點鬆懈
- 關於遠端辦公,每個企業都需要知道的5件事
- IT職場:每個黑帶都應該知道的事
- 《每個人的戰爭》讀書筆記筆記
- 每個人都應該知道的jQuery的提示jQuery
- 每週刷個 leetcode 演算法題LeetCode演算法
- 3個每個人都討厭的Java實踐 - MilošJava
- 不是每個人的一生都會有貴人相助
- Qshutdown – 一個先進的關機神器
- 每個人都能實現“數字人自由”?HPG
- GPT大模型不再遙不可及:本地化部署讓每個人都能擁有GPT大模型
- 眾包趨勢:每個人都將與平臺發生關係
- 關於Unicode,字符集,字元編碼,每個程式設計師都應該知道的事Unicode字元程式設計師
- 周朝陽:2020年應對風險的十個建議!與每一個人息息相關
- 每個運維人員應該知道的 10 個 Linux 命令!運維Linux
- 事業觀、金錢觀與幸福觀
- 每個人都應該懂點攻防
- 每個人對元宇宙的理解都錯了 - ShaanVP元宇宙
- 關於 996 I·C·U 這事,想說點小小的、個人的看法996
- 演算法金 | Transformer,一個神奇的演算法模型!!演算法ORM模型
- 關於JavaScript物件,你所不知道的事(一)- 先談物件JavaScript物件
- 為什麼每個人都在談論 WebAssemblyWeb
- 沒有人玩MMO,每個人都在玩MMO
- 重要!每個開發者都應該掌握的9個核心演算法演算法
- 演算法金 | 一個強大的演算法模型,GP !!演算法模型
- 演算法金 | 一個強大的演算法模型,GPR !!演算法模型
- 每個開發人員都應該知道的 10 個 GitHub 倉庫Github
- 關於GAN的個人理解
- AAAI 2020 論文解讀:關於生成模型的那些事AI模型
- 做自己喜歡的遊戲,是一件很幸福的事遊戲
- 資料視覺化,個人經驗總結(Echarts相關)視覺化Echarts
- 任務設計:關於幸福的生產力
- 作業系統實驗——讀者寫者模型(寫優先)作業系統模型
- 《幸福研究期刊》:研究發現少量運動與幸福感增加相關