位元組跳動湖平臺在批計算和特徵場景的實踐
隨著業務的發展,位元組跳動特徵儲存已到達 EB 級別,日均增量 PB 級別,每天訓練資源量級為百萬 Core。隨之而來的是內部業務方對原始資料儲存、特徵回填需求、降低成本、提升速度等需求的期待。本次分享將圍繞問題背景、選型 & Iceberg 簡介、基於 Iceberg 的實踐及未來規劃展開。
01 問題背景
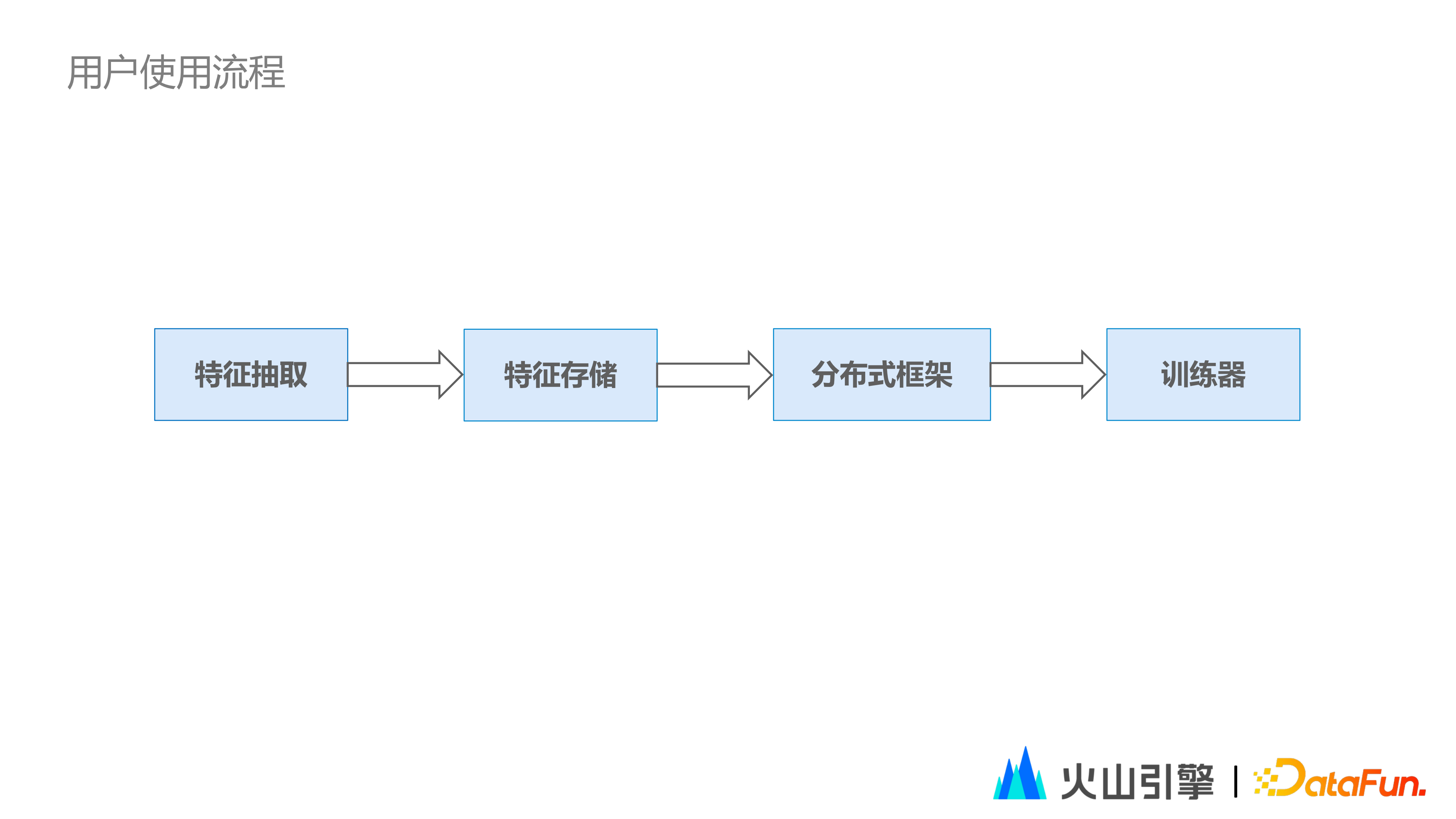
1. 使用者使用流程
如我們所知,位元組跳動是一家擅長做 A/B test 的公司。以特徵工程調研場景為例,流程如下:
(1)首先由演算法工程師進行線上特徵抽取。
(2)將抽取到的特徵,使用 Protobuf 的格式按行存至 HDFS。
出於儲存成本的考量,一般只儲存抽取後的特徵,而不儲存原始特徵。
(3)將 HDFS 儲存的特徵交由位元組自研的分散式框架( Primus )進行併發讀取,並進行編碼和解碼操作,進而傳送給訓練器。
(4)由訓練器對模型進行高效訓練。
① 如果模型訓練效果符合演算法工程師的預期,說明該調研特徵生效,進而演算法工程師對調研特徵進行回溯,透過 Spark 作業將特徵回填到歷史資料中,分享給其他演算法工程師,進而迭代更多的優質模型。
② 如果模型訓練效果不符合演算法工程師的預期,則調研特徵不對原有特徵集合產生影響。
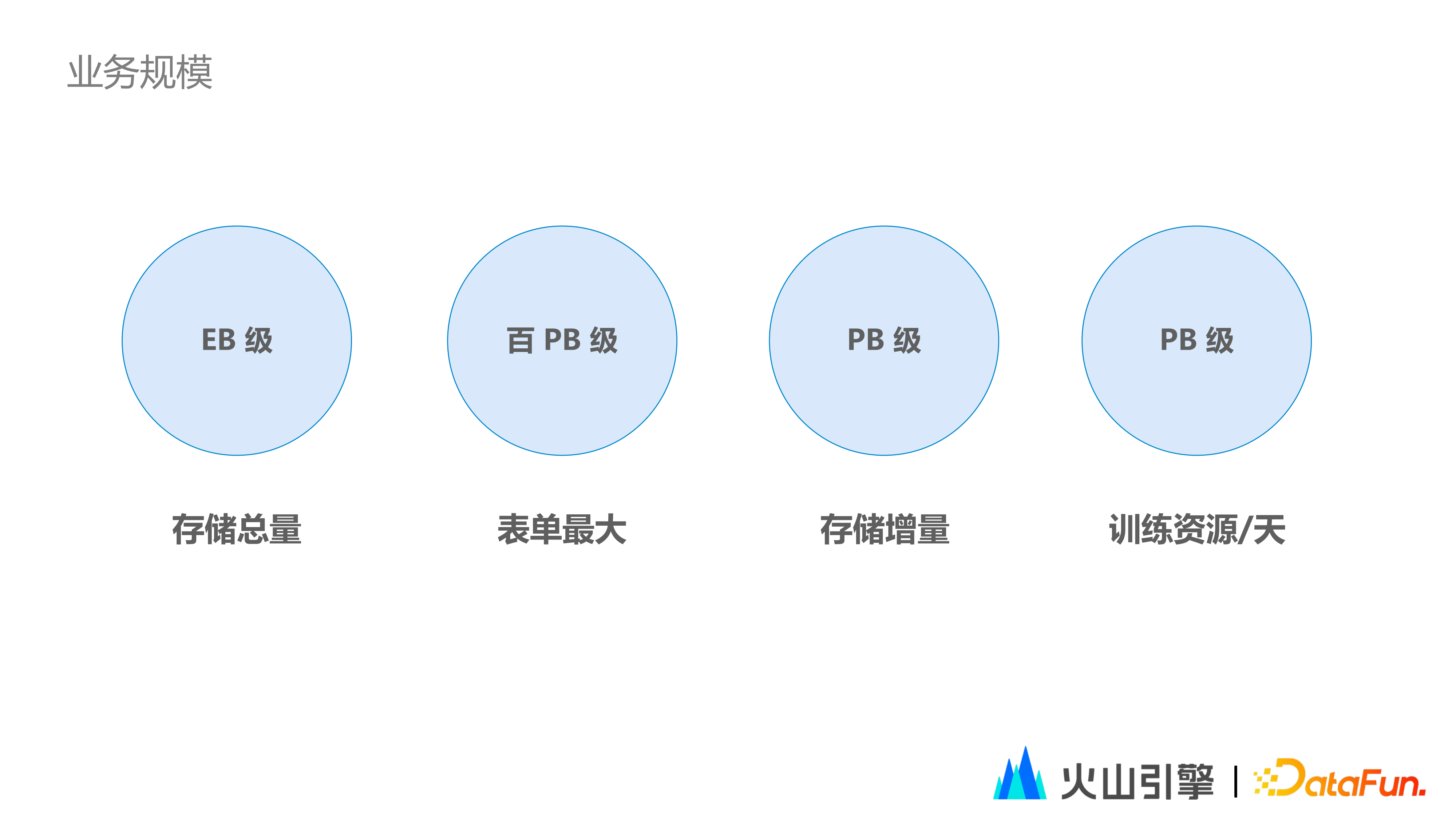
2. 業務規模
公司龐大的業務規模,帶來了巨大的計算和儲存體量:
(1)特徵儲存總量達 EB 級。
(2)單表特徵最大可達百 PB 級(如廣告業務)。
(3)單日特徵儲存增量達 PB 級。
(4)單日訓練資源開銷達 PB 級。
3. 遇到的問題
當特徵調研場景疊加巨大的資料體量,將會遇到以下困難:
(1)特徵儲存空間佔用較大。
(2)樣本讀放大,不能列裁剪,很難落特徵進樣本。
(3)樣本寫放大,COW 很難做特徵回溯調研。
(4)不支援特徵 Schema 校驗。
(5)平臺端到端體驗差,使用者使用成本高。
02 選型 & Iceberg 簡介
在特徵調研場景下,行儲存是個低效的儲存方式;因此,我們選擇 Iceberg 儲存方式來解決上述問題。
1. 整體分層
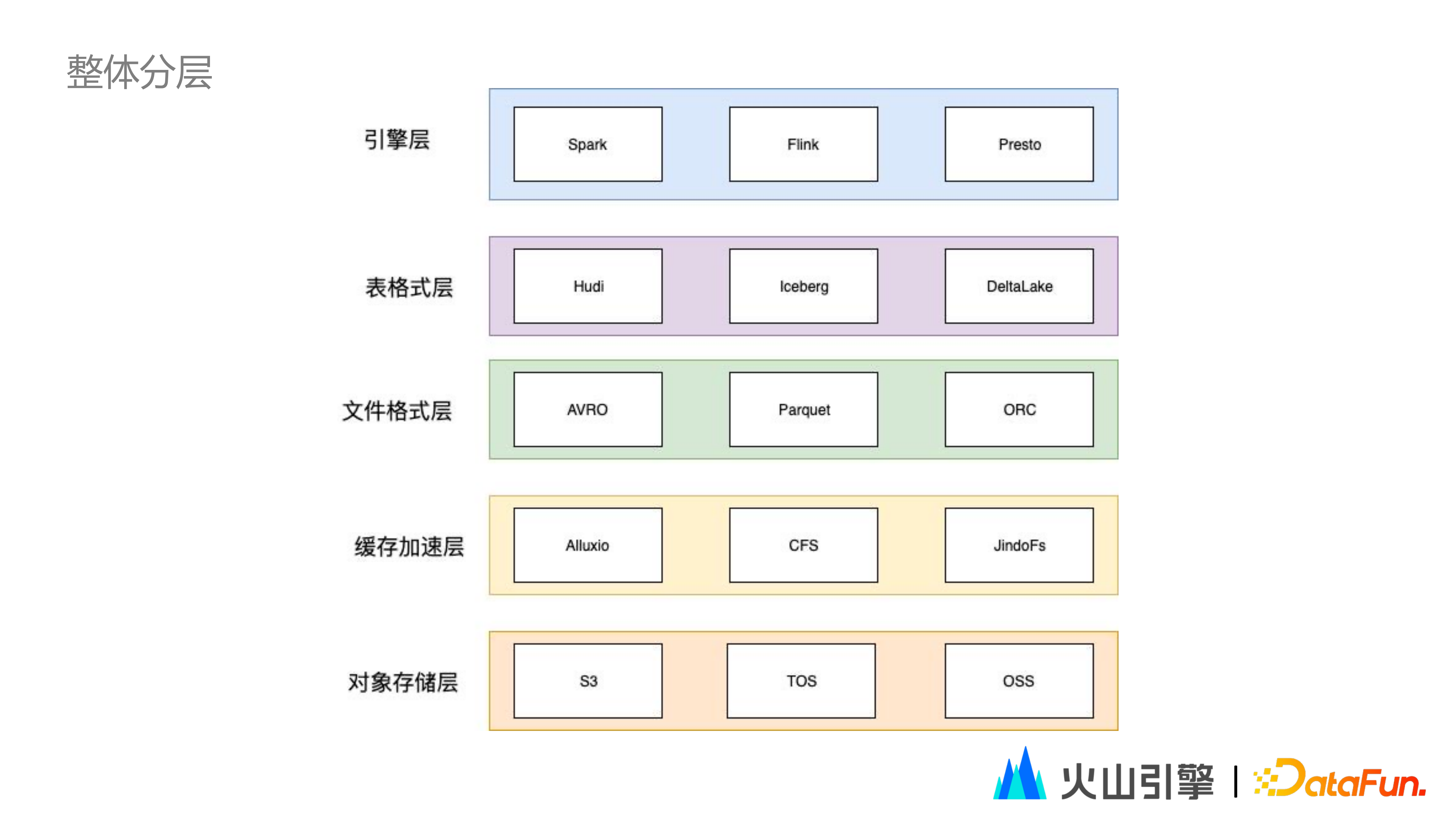
Apache Iceberg 是由 Netflix 公司推出的一種用於大型分析表的高效能通用表格式實現方案。
如上圖所示,系統分成引擎層、表格式層、檔案格式層、快取加速層、物件儲存層。圖中可以看出,Iceberg 所處的層級和 Hudi,DeltaLake 等工具一樣,都是表格式層。
(1)向上提供統一的操作 API
Iceberg 定義表後設資料資訊以及 API 介面,包括表欄位資訊、表檔案組織形式、表索引資訊、表統計資訊以及上層查詢引擎讀取、表寫入檔案介面等,使得 Spark, Flink 等計算引擎能夠同時高效使用相同的表。
(2)下層有 parquet、orc、avro 等檔案格式可供選擇。
(3)下接快取加速層,包括開源的 Alluxio、位元組火山引擎自研的 CFS 等。
CFS 全稱是 Cloud File System,是面向火山引擎和專有云場景下的大資料統一儲存服務,支援高效能的快取和頻寬加速,提供相容 HDFS API 的訪問介面。
(4)最底層的實際物理儲存,可以選擇物件儲存,比如 AWS S3,位元組火山引擎的 TOS,或者可以直接使用 HDFS。
透過上圖可以比較清晰地瞭解到,Iceberg 這個抽象層最大的優勢在於:將底層檔案的細節對使用者遮蔽,將上層的計算與下層的儲存進行分離,從而在儲存和計算的選擇上更為靈活,使用者可以透過表的方式去訪問,無需關心底層檔案的資訊。
2. Iceberg 簡介
(1)Iceberg 架構
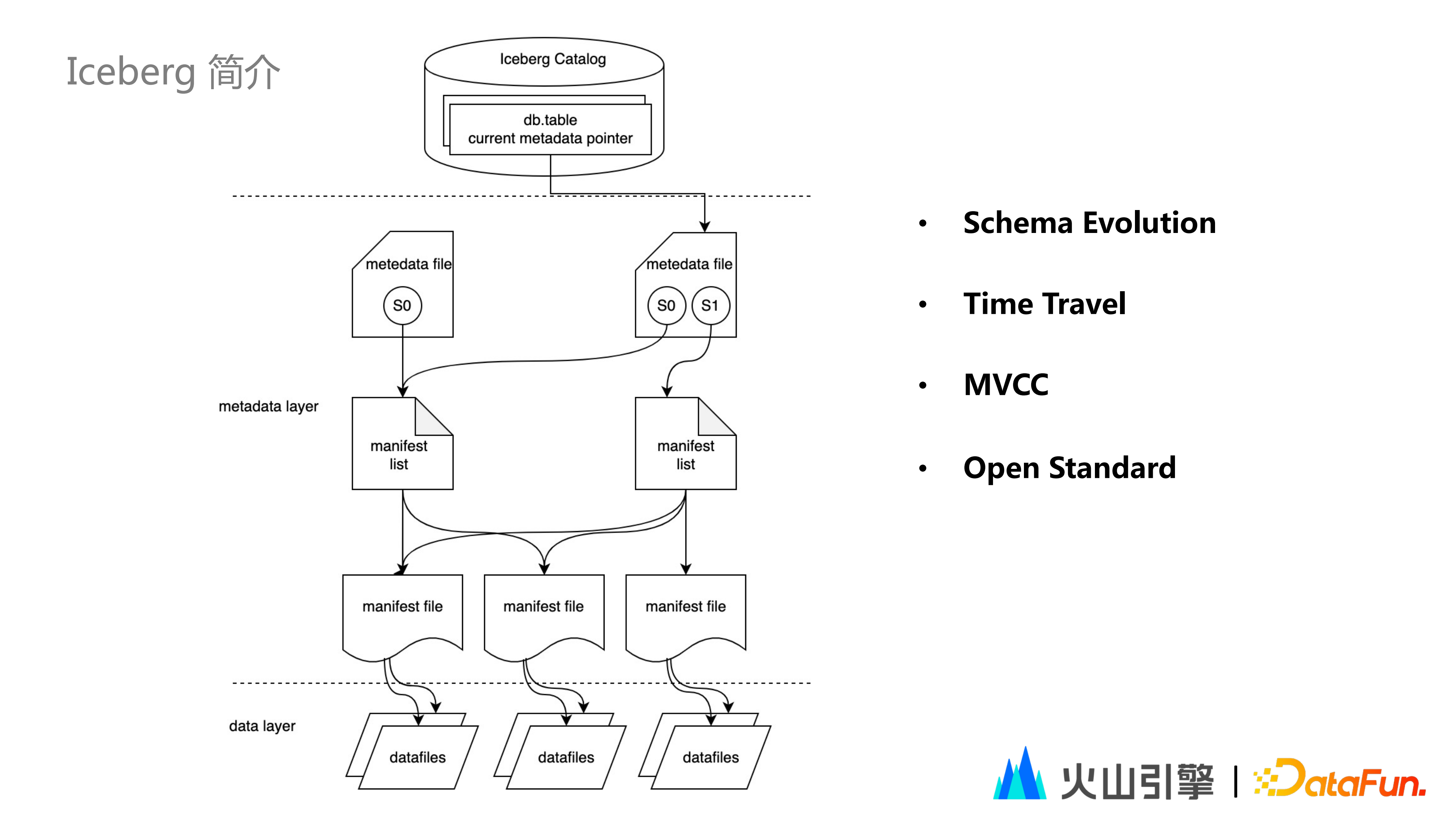
Iceberg 的本質是一種檔案的組織形式。如上圖所示,包括多級的結構:
① Iceberg Catalog:用於儲存表和儲存路徑的對映關係,其核心資訊是儲存 Version 檔案所在的目錄。
Iceberg Catalog 共有8種實現方式,包括 HadoopCatalog,HiveCatalog,JDBCCatalog,RestCatalog 等
不同的實現方式,其底層儲存資訊會略有不同;RestCatalog 方式無需對接任何一種具體的儲存,而是透過提供 Restful API 介面,藉助 Web 服務實現 Catalog,進一步實現了底層儲存的解耦。
② Metadata File:用來儲存表的後設資料資訊,包括表的 schema、分割槽資訊、快照資訊( Snapshot )等。
Snapshot 是快照資訊,表示表在某一時刻的狀態;使用者每次對 Table 進行一次寫操作,均會生成一個新的 SnapShot。
Manifestlist 是清單檔案列表,用於儲存單個快照的清單檔案。
Manifestfile 是儲存的每個資料檔案對應的清單檔案,用來追蹤這個資料檔案的位置、分割槽資訊、列的最大最小值、是否存在 null 值等統計資訊。
③ Data File 是儲存的資料,資料將以 Parquet、Orc、Avro 等檔案格式進行儲存。
(2)Iceberg 特點
① SchemaEvolution:Iceberg 表結構的更新,本質是內在元資訊的更新,因此無需進行資料遷移或資料重寫。Iceberg 保證模式的演化(Schema Evolution)是個獨立的、沒有副作用的操作流程,不會涉及到重寫資料檔案等操作。
② Time travel:使用者可任意讀取歷史時刻的相關資料,並使用完全相同的快照進行重複查詢。
③ MVCC:Iceberg 透過 MVCC 來支援事務,解決讀寫衝突的問題。
④ 開放標準:Iceberg 不繫結任何計算引擎,擁有完全獨立開放的標準,易於擴充。
(3)Iceberg 讀寫流程和提交流程
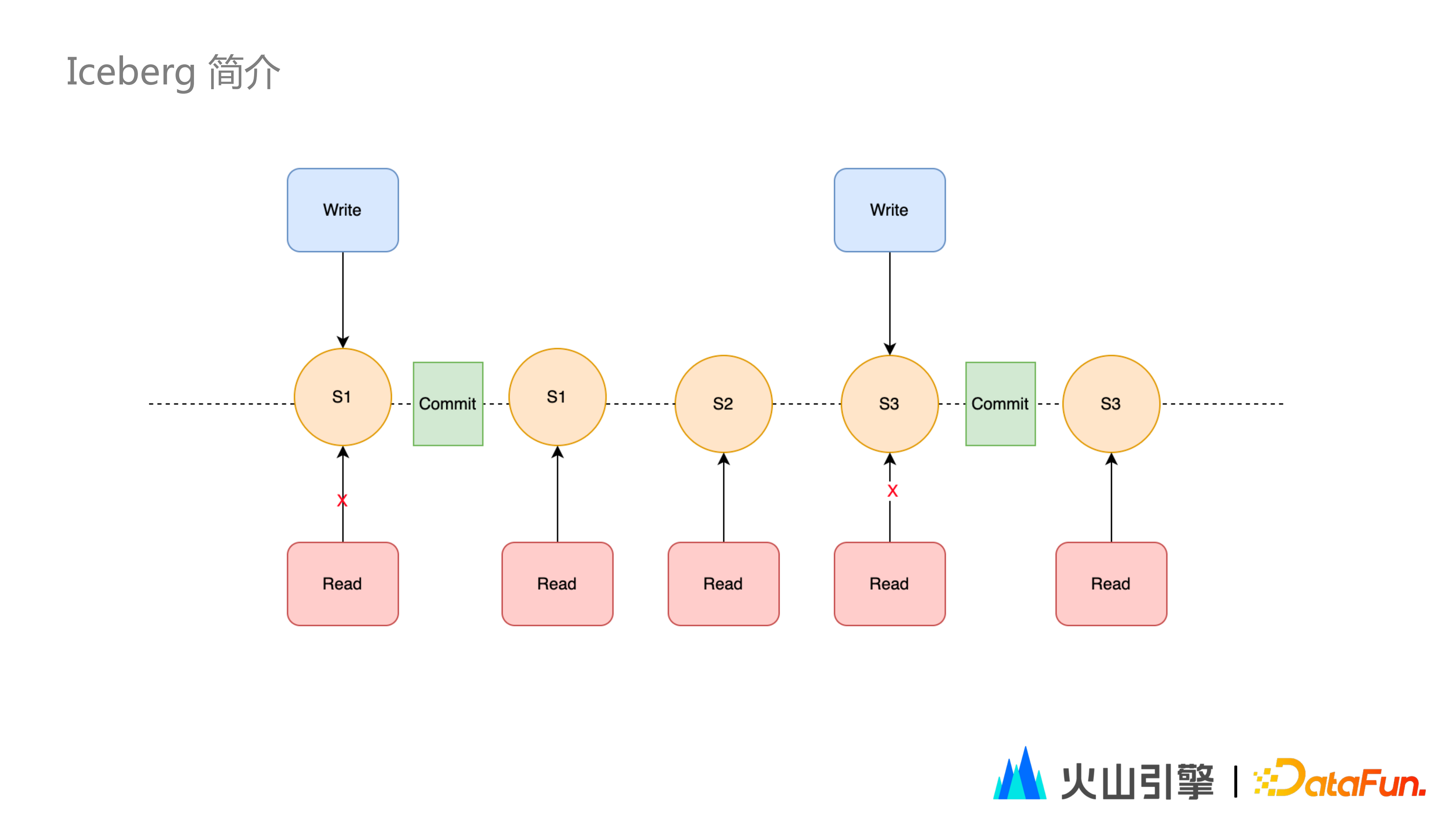
① 讀寫
每次 Iceberg 的寫操作,只有發生 commit 之後,才是可讀的;如有多個執行緒同時在讀,但一部分執行緒在寫,可以實現:只有 commit 完整的資料之後,對使用者的讀操作才能被使用者的讀執行緒所看到,實現讀寫分離。
例如上圖中,在對 S3 進行寫操作的時候,S2、S1 的讀操作是不受影響的;此時 S3 無法被讀到,只有 commit 之後 S3 才會被讀到。此時 Current Snapshot 會指向 S3。
Iceberg 預設從最新 Current Snapshot 讀取資料;如果讀更早的資料,可指定對應的Snapshot 的 id ,實現資料回溯。
② 事務性提交
寫操作:記錄當前後設資料的版本——base version,建立新的後設資料以及 manifest 檔案,原子性將 base version 替換為新的版本。
原子性替換:原子性替換保證了線性歷史,透過後設資料管理器所提供的能力,以及 HDFS 或本地檔案系統所提供的原子化 rename 能力實現。
衝突解決:基於樂觀鎖實現,每一個 writer 假定當前沒有其他的寫操作,對錶的 write 進行原子性的 commit,若遇到衝突則基於當前最新的後設資料進行重試。
(4)分割槽裁剪
① 直接定位到 parquet 檔案,無需呼叫檔案系統的 list 操作。
② Partition 的儲存方式對使用者透明,使用者在修改 partition 定義時,Iceberg 可以自動地修改儲存佈局,無需使用者重複操作。
(5)謂詞下推
Iceberg 會在兩個層面實現謂詞下推:
① 在 snapshot 層面,過濾掉不滿足條件的 data file。
② 在 data file 層面,過濾掉不滿足條件的資料。
其中,snapshot 層面的過濾操作為 Iceberg 所特有,正是利用到 manifest 檔案中的後設資料資訊,逐欄位實現檔案的篩選,大大地減少了檔案的掃描量。而同為 Table Format 產品、在位元組其他業務產線已投入使用的 Hudi,雖然同樣具備分割槽剪枝功能,但是尚不具備謂詞下推功能。
03 基於 Iceberg 的實踐
Hudi、Iceberg、DeltaLake 這三款 TableFormat 產品各有優劣,然而並沒有任何一款產品能夠直接滿足我們的使用場景需求;考慮到 Iceberg 具備良好的 Schema Evolution 能力,支援下推,且無需繫結計算引擎等優點,因此位元組選擇使用 Iceberg 作為資料湖工具。
1. 整體架構
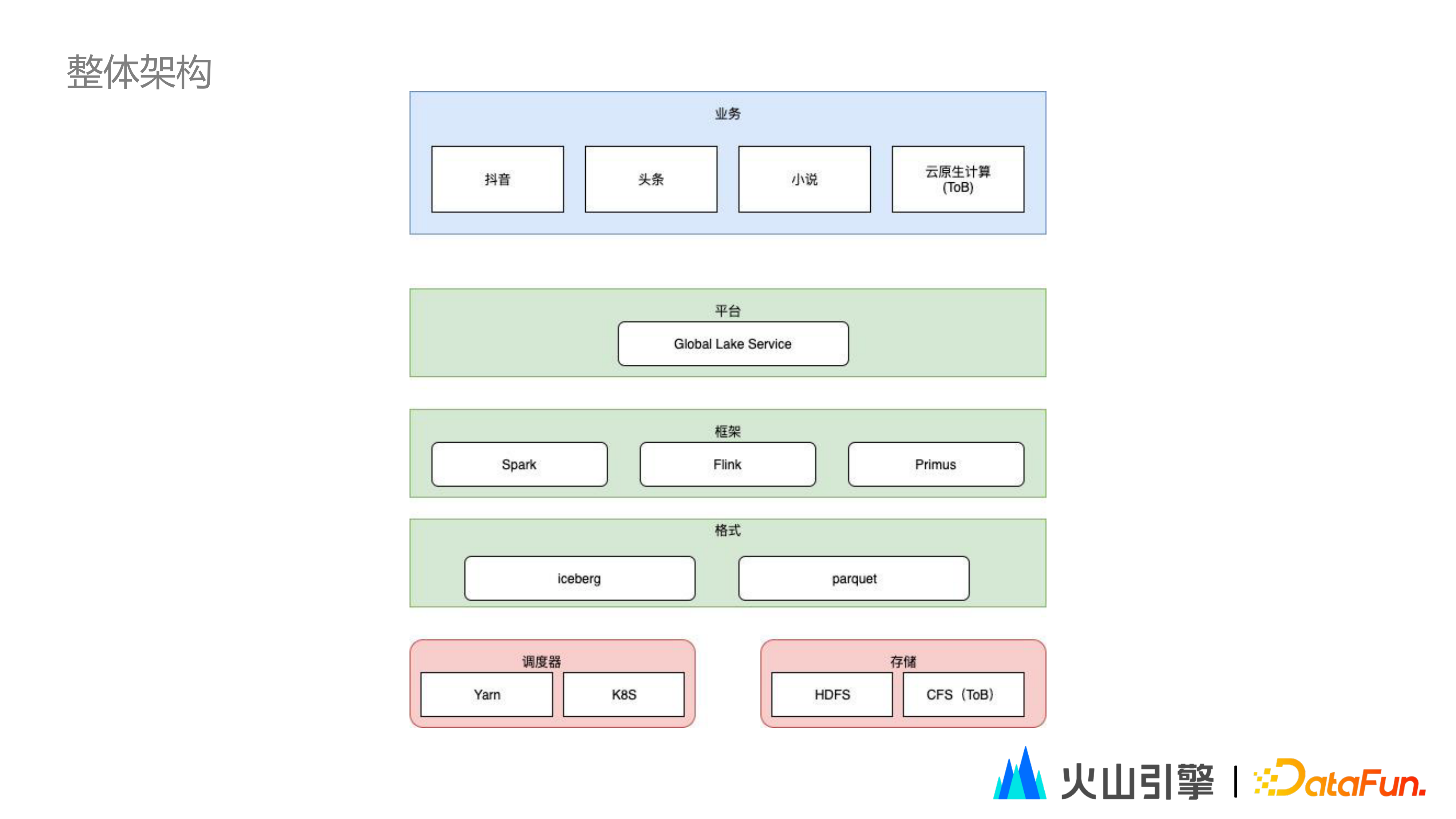
① 在位元組的整體架構中,最上層是業務層,包含抖音,頭條,小說等位元組絕大部分業務線,以及火山引擎雲原生計算等相關 ToB 產品(如 Seveless Spark 等)。
② 在平臺層,使用 Global Lake Service 給業務方提供簡單易用的 UI 和訪問控制等功能。
③ 在框架層,我們使用 Spark 作為特徵處理框架(包含預處理和特徵調研等),使用位元組自研的 Primus 分散式框架作為訓練框架,使用 Flink 實現流式訓練。
④ 在格式層,選擇 parquet 作為檔案格式,使用 Iceberg 作為表格式。
⑤ 最下層是排程器層和儲存層。選擇 Yarn 和 K8S 作為排程器;儲存層一般選擇 HDFS 進行儲存,對於 ToB 產品,則使用 CFS 進行儲存。
2. Data-Parquet
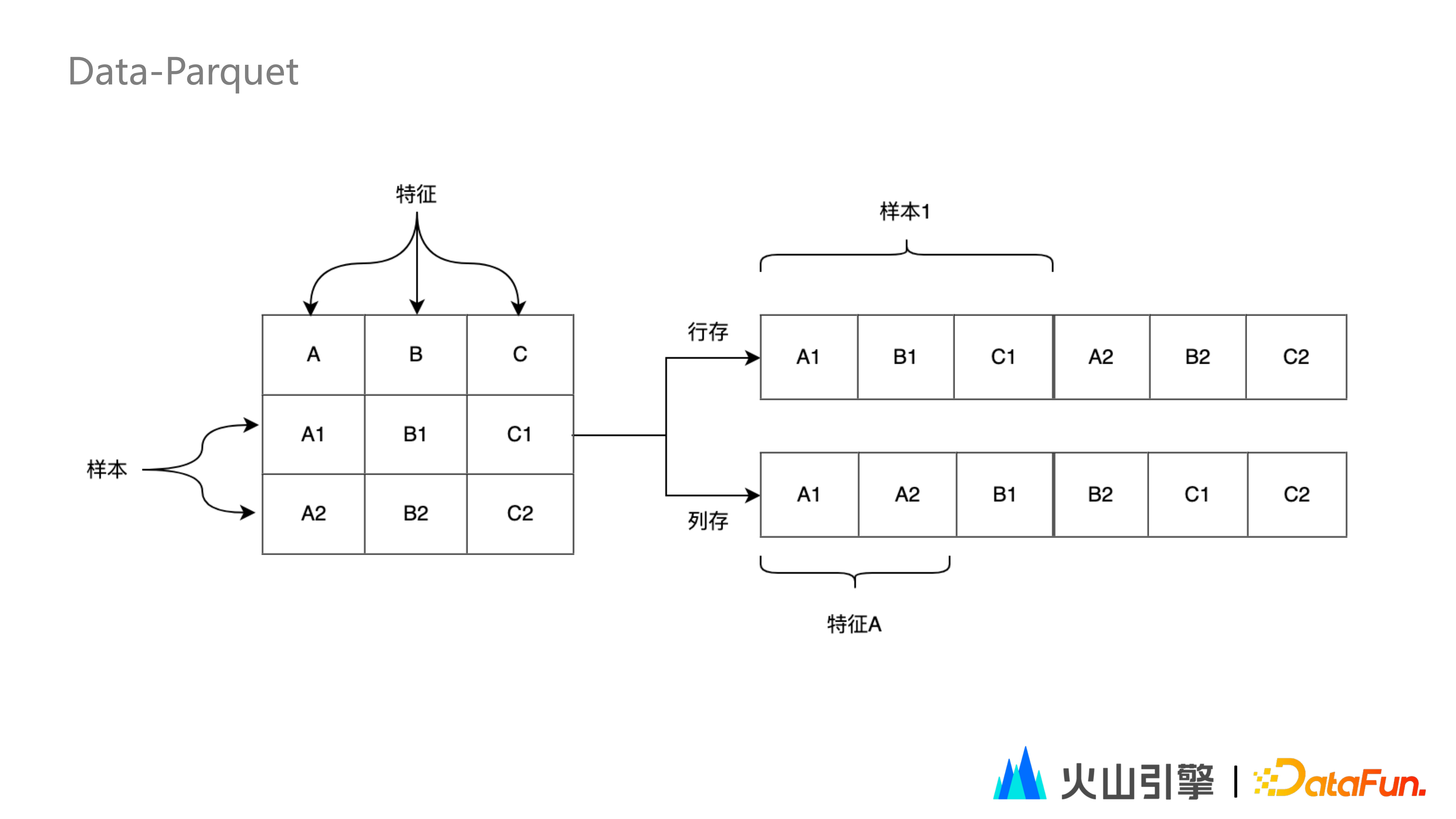
結合上圖可以看出,列儲存在特徵調研場景存在以下優勢:
① 可選擇指定列進行讀取:有效減少讀放大問題,同時易於增列,即新增一列的時候,只需單獨寫入一列即可,後設資料資訊會記錄每一列所在的磁碟位置。
② 壓縮:同一列的資料格式相同,因此具有更好的壓縮比;同一列的資料名稱相同,因此無需進行冗餘字串儲存。
③ 謂詞下推:對每一列資料記錄相應的統計資訊(如 min,max 等),因此可以實現部分的謂詞下推。
為了解決業務方的痛點問題,我們改成使用 Parquet 列儲存格式,以降低資料的儲存成本;同時由於 Parquet 選列具備下推到儲存層的特性,在訓練時只需讀取模型所需要的特徵即可,從而降低訓練時序列化、反序列化的成本,提升訓練的速度。
然而使用 Parquet 列儲存,帶來優點的同時也相應地帶來了一些問題:
① 原來的行儲存方式是基於 Protobuf 定義的半結構化資料,無需預先定義 Schema;然而使用 Parquet 之後,需要預先指定 Schema 才能進行資料的存取;這樣在特徵新增和淘汰的時候,Schema 的更新將會變成一個棘手的問題。
② 此外,Parquet 不支援資料回填;如果需要要回填比較長的資料,就需要將資料全量讀取,增加新列,再全量寫回。這樣一方面會造成大量計算資源的浪費,另一方面會帶來 overwrite 操作,導致正在進行訓練的任務由於檔案被替換而失敗。
為了解決以上兩個問題,我們引入了 Iceberg 來支援 SchemaEvolution,特徵回填以及併發讀寫。
3. 特徵回填
(1)COW
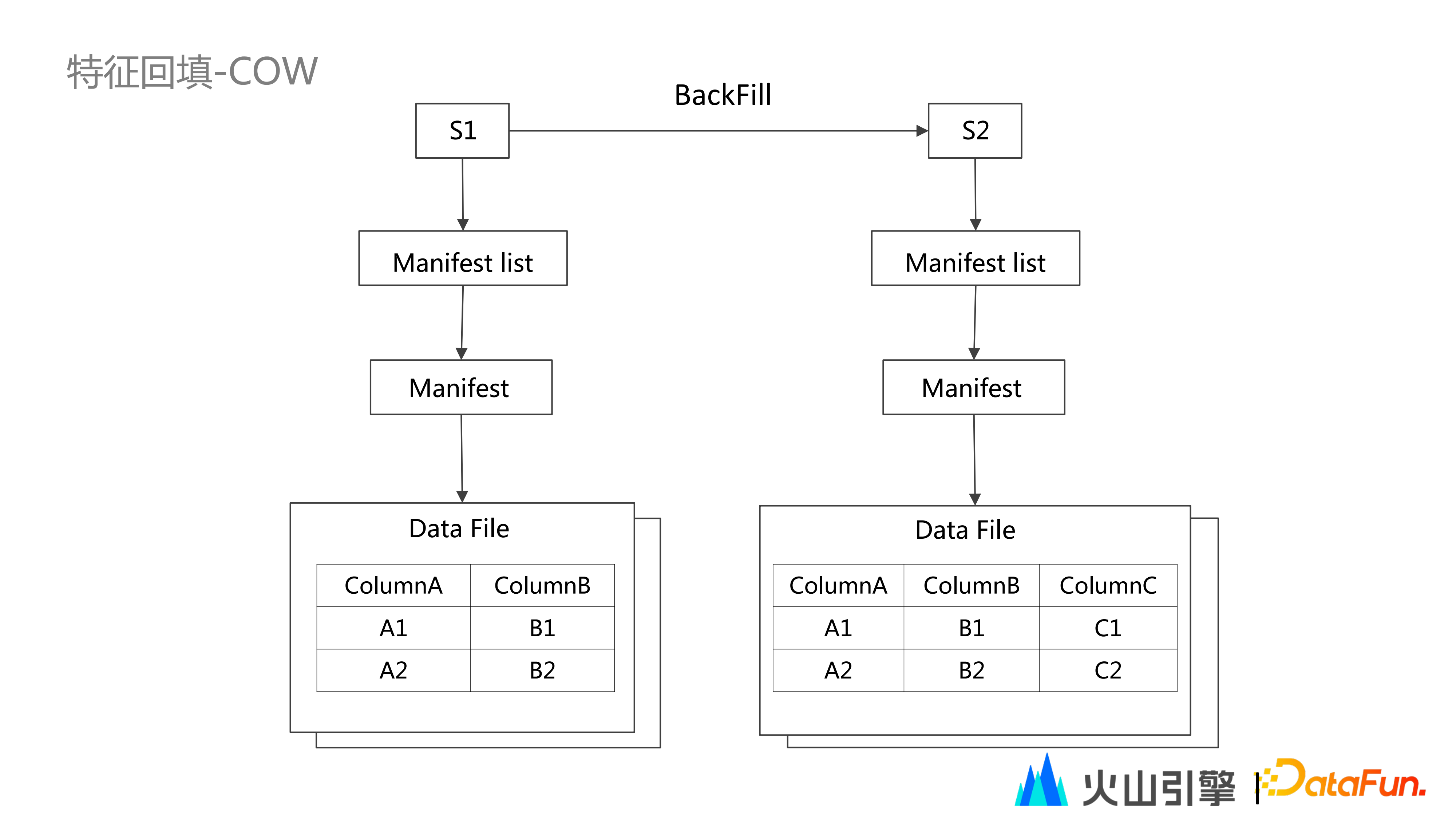
從上圖可以看出,使用 Iceberg COW(Copy on write)方式進行特徵回填,透過 BackFill 任務將原快照中的資料全部讀出來,然後新增新列,進而寫出到新的 Data File 中,並生成新的快照。
這種方式的缺點在於,僅僅新增一列資料的寫入,卻需要整體資料全部讀出隨後再全部寫回,不僅浪費了大量的計算資源和儲存資源;因此,我們基於開源的 Iceberg 自研了一種 MOR(Merge on Read)的 BackFill 方案。
(2)MOR

從上圖可以看出,在 MOR 方案中,我們仍然需要一個 BackFill 任務來讀取原始的 Data File 檔案;所不同的是,我們只需讀取少數需要的欄位。比如我們需要對 A 列透過一些計算邏輯生成 C 列,那麼 BackFill 任務只需從 Snapshot1 中讀取 A 列的資料,且只需將 C 列的 update 檔案寫入 Snapshot2。
隨著新增列的增多,我們需要將 update 檔案合併到 Data File 裡面;為此,我們進一步提供一種 Compaction 邏輯,即讀取舊的 Data File 和 Update File,併合並生成新的 Data File。實現細節如下:
① 舊 Data File 和 Update File 都需要一個主鍵,並且每個檔案都需要按照主鍵排序。
② 讀取舊 Data File 時,會根據使用者選擇的列,分析具體需要哪些 Update File 和 Data File。
③ 根據舊 Data File 中 min-max 值去選擇對應的 Update File。
由此可以看出,MOR 的本質是對多個 Data File 檔案和 Update File 檔案進行多路歸併,而歸併的順序由 SEQ 決定,SEQ 大的資料(表明資料越新)會覆蓋 SEQ 小的資料。
(3)兩種特徵回填方式對比
① COW
讀寫放大嚴重。
儲存空間浪費。
讀取邏輯簡單。
寫入耗費更多資源。
讀取無需額外計算資源。
② MOR
沒有讀寫放大。
節省儲存空間。
讀取邏輯複雜。
寫入耗費較少資源。
絕大多數場景,不需要額外資源。
相比於 COW 方式的全量讀取和寫入,MOR 的優勢在於只讀取需要的列,同樣也只寫入更新的列,因此避免了讀寫放大的問題,節省大量計算資源,並大大降低讀寫 I/O;相比 COW 方式每次 COW 都翻倍的情況,MOR 只需儲存新增列,大量節省了儲存資源。
對於模型訓練任務而言,大多數模型訓練只需要用到少量的列,因此大量的線上模型都無需 MOR 操作,涉及開銷可忽略不計;對於少數的特徵調研模型,只需讀取模型對應的 Update File 即可,因此帶來的讀取資源增加也非常有限。
4. 其他

除了上面提到的藉助 Compaction 提高讀效能以及分析特徵刪除場景外,我們還提供了以下幾個服務:
(1)Expiration
① Snapshot Expiration:用於處理過期的 Snapshots。過期 Snapshots 不及時清理,會導致後設資料檔案堆積,從而帶來檔案膨脹問題,會給演算法工程師帶來困擾,因此需要服務定期做一些清理。我們透過平臺化改造實現 Snapshots 檔案的統一維護和清理;
② Data Expiration:大部分資料是有新鮮度和時效性的,因此使用者可設定資料儲存多久後被清理。
(2)CleanUp
由於一些事務的失敗,或者一些快照的過期,導致檔案在後設資料檔案中已經不再被引用,需要定期清理掉。
(3)Roll-Back
對於一些在 table 中非預期資料或者 schema 變更,希望將其回滾到之前穩定的 snapshot;結合平臺的事件管理器,可以比較容易的實現這一功能。
(4) Statistics
用來實現一些湖平臺視覺化資訊的展示,以及後端服務給業務帶來的價值歸納。
5. 平臺化改造
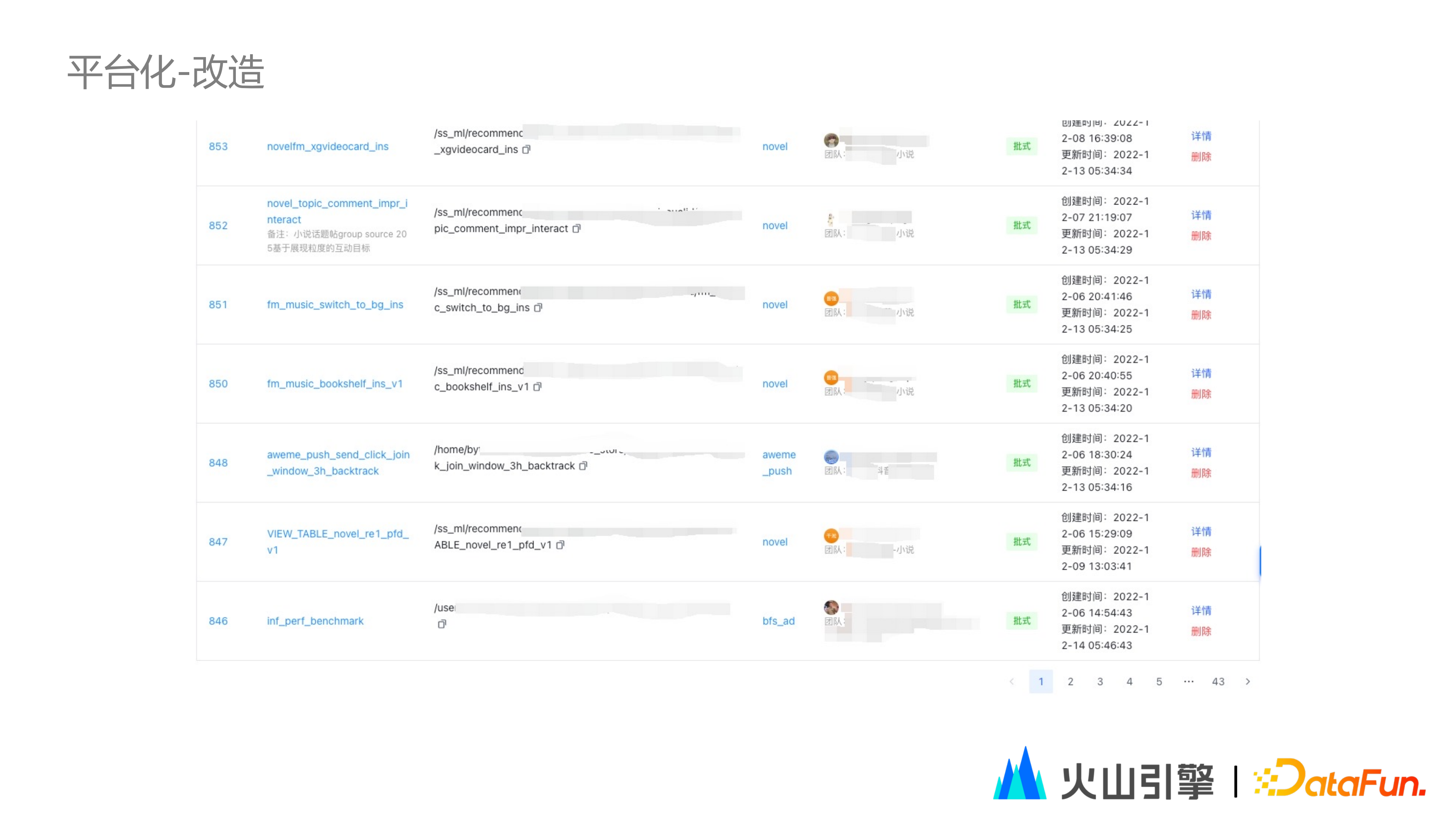
這裡分享下位元組內部實現的平臺化工作。上圖是批式特徵儲存的列表,藉助站內實現的湖平臺化工作,業務部門可以輕鬆實現特徵的視覺化操作,以及資訊概覽的獲取。
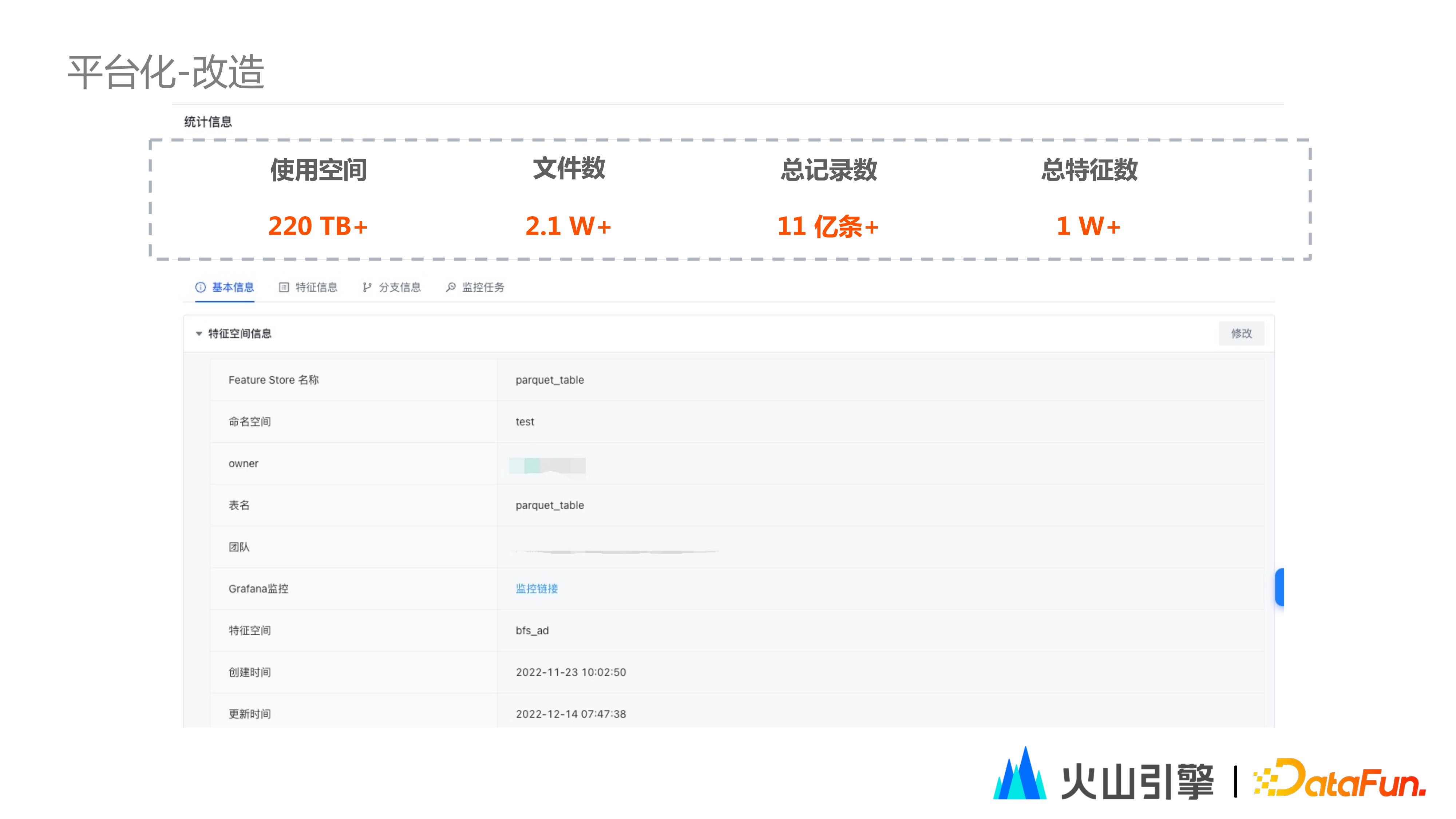
下圖是一張特徵表樣例,透過這張表可以直觀地看到儲存空間的使用、檔案數的統計、記錄數統計、特徵統計等資訊。這張表並不是資料規模最大的表,最大的表來自抖廣,百 PB 量級的資料,千萬級別的檔案數。
04 未來規劃
1. 規劃重點
未來規劃方面,我們計劃逐步支援以下功能:
(1)湖冷熱分層
在成本最佳化方面,我們規劃做湖冷熱分層。前文提到對於儲存超過一定時間的資料,可以直接刪除;然而對於一些場景,這些資料還會被使用,只是訪問頻率較低;因此未來考慮增加資料湖冷熱分層功能,幫助使用者降低成本。
(2)物化檢視
在查詢最佳化方面,我們計劃做物化檢視。這個也是源於我們 ToB 客戶的真實需求,用來提升查詢效能。目前這部分最佳化工作正處於一個商業化交付的流程中,大家也可以後續在我們的產品上進行體驗。
(3)Self-Optimize
在體驗最佳化方面,實現 Self-Optimize,例如前文提到的一些資料維護最佳化等。
(4)支援更多引擎
在生態豐富方面,我們會支援更多的引擎對接 Iceberg。
2. 整體平臺架構總覽
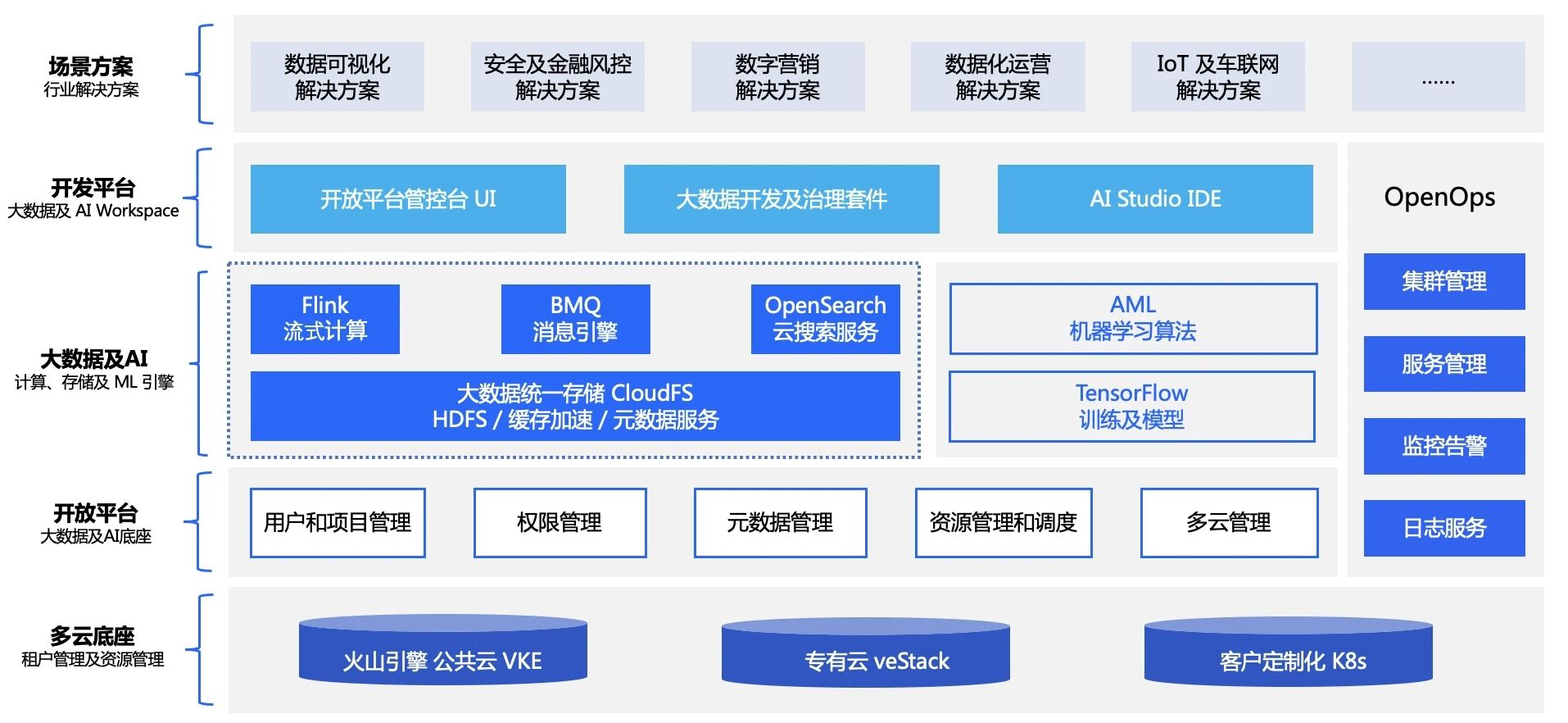
如前文所述,該平臺不僅支援公司內部的業務,還會支援一定的 ToB 的業務;這些在位元組內部實現的功能,以及未來我們規劃的能力也會基於內外一致的思路去做演進;最終都會落到上圖中涉及到的幾款雲原生計算產品上,如流式計算 Flink 版,雲原生訊息引擎 BMQ,雲搜尋服務 OpenSearch,大資料檔案儲存 CloudFS 等。目前該產品尚未轉正式收費,感興趣的朋友可以登入火山引擎官網體驗。
整體平臺架構以計算引擎產品為核心,包含兩部分服務:
(1)雲原生管理控制
① Quota 服務。
② 租戶管理服務。
③ 執行時管理。
④ 生態整合服務。
⑤ 交付部署服務。
⑥ 閘道器服務。
(2)雲原生運維平臺
① 元件服務生命週期管理。
② Helm Chart 管理。
③ 日誌、審計。
④ 監控報警。
⑤ 容災、高可用。
以上功能均為 Serverless 的全託管產品,讓使用者更聚焦於自己的業務邏輯,減少資料運維帶來的困擾。
來自 “ DataFunTalk ”, 原文作者:劉緯;原文連結:http://server.it168.com/a2023/0512/6803/000006803415.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 位元組跳動資料湖在實時數倉中的實踐
- 位元組跳動基於Doris的湖倉分析探索實踐
- 位元組跳動在 Go 網路庫上的實踐Go
- 位元組跳動自研萬億級圖資料庫 & 圖計算實踐資料庫
- 位元組跳動資料中臺的Data Catalog系統搜尋實踐
- 流批一體的實時特徵工程平臺建設實踐特徵工程
- 安全容器在邊緣計算場景下的實踐
- 位元組跳動校招提前批開啟
- 李亞坤:Hadoop YARN在位元組跳動的實踐HadoopYarn
- 位元組跳動 YARN 雲原生化演進實踐Yarn
- Presto 在位元組跳動的內部實踐與優化REST優化
- 位元組跳動自研一站式萬億級圖儲存/計算/訓練平臺
- 位元組跳動 Flink 大規模雲原生化實踐
- 位元組跳動打遊戲,抖音平臺當先鋒?遊戲
- 位元組跳動和TikTok內推
- 深度介紹Flink在位元組跳動資料流的實踐
- 位元組跳動,跳動的“遊戲夢”遊戲
- 位元組跳動的多平臺綻放祕訣 | Flutter 開發者故事Flutter
- FeatHub:流批一體的實時特徵工程平臺特徵工程
- 位元組跳動機器學習系統雲原生落地實踐機器學習
- 位元組跳動上海招人
- 不要神化位元組跳動
- vivo 實時計算平臺建設實踐
- 2020,位元組跳動在海外的關鍵一年
- 中信建投:孤獨的騰訊,跳動的位元組(位元組跳動篇-附下載)
- vivo AI 計算平臺的 ACK 混合雲實踐AI
- 位元組跳動流式資料整合基於Flink Checkpoint兩階段提交的實踐和優化優化
- Flink 在風控場景實時特徵落地實戰特徵
- 攪局者,位元組跳動
- 位元組跳動“玩心”變重
- 再見了,位元組跳動
- 位元組跳動ios面經iOS
- 位元組跳動2020屆提前批 AI Lab 三面視訊面 計算機視覺演算法崗AI計算機視覺演算法
- 位元組跳動筋斗雲人才計劃開啟
- 剛面完位元組跳動,估計涼了。
- 位元組跳動的「遊戲」法則遊戲
- 位元組跳動的技術架構架構
- 求助 位元組跳動的 App 效能分析工作臺的 window 版本桌面APP