流批一體的實時特徵工程平臺建設實踐
導讀:本文主要分享阿里雲 FeatHub 專案組在特徵工程開發中的平臺實踐和建設經驗。
本次分享分為四大部分,第一部分總體介紹 FeatHub 在特徵開發、部署、監控、分享過程中面臨的場景、目標、痛點和挑戰;第二部分介紹 FeatHub 的架構思路實踐,及相關核心概念;第三部分介紹 FeatHub 在使用過程中的 API 基本使用、基本計算功能,樣例場景的程式碼實踐,還有效能最佳化,未來的擴充套件目標,以及開源社群的共建,提供專案的學習、開發使用,還將分享 FeatHub 歷史資料的回放功能, 支援離線、近線、線上處理和阿里雲上下游元件的支援等問題。
01 為什麼需要 FeatHub
1. 目標場景
(1)需要 Python 環境的資料科學家
今天大部分流行的機器學習的推理和訓練程式基本都是由資料科學家用 Python 來編寫的,比如流行的 TensorFlow、PyTorch 以及一些傳統機器學習場景中用到的 scikit-learn 等等。我們希望支援資料科學家繼續使用熟悉的 Python 編寫特徵工程程式碼來完成端到端機器學習鏈路的開發與部署,並且能夠使用他們所熟悉的 Python 生態環境中的庫。
(2)生成實時特徵
越來越多的機器學習應用在往實時方向發展,透過實時處理可以提高機器學習的效率和準確度。為了達到目標,需要生成實時特徵。這裡不僅僅是去實時獲取查詢特徵,而是要實時生成特徵。例如需要實時獲取使用者在最近兩分鐘內的點選次數,為此需要使用流式計算引擎完成實時特徵計算。
(3)需要開源方案支援多雲部署
越來越多的中小型公司希望做到多雲部署,以得到生產的安全保證,以及獲得雲廠商之間的競價優勢。因此我們的方案不要求使用者繫結一個雲廠商,而是要讓使用者能夠自由地在不同雲廠商之間做選擇,甚至在私有云部署特徵工程作業。
這是 FeatHub 專案設立之初所希望滿足的一些條件。
2. 實時特徵工程的痛點
今天已經有很多公司在開發實時特徵工程作業。其中存在一些痛點,涵蓋了特徵的整個生命週期,包含開發、部署、監控、以及之後的分享。
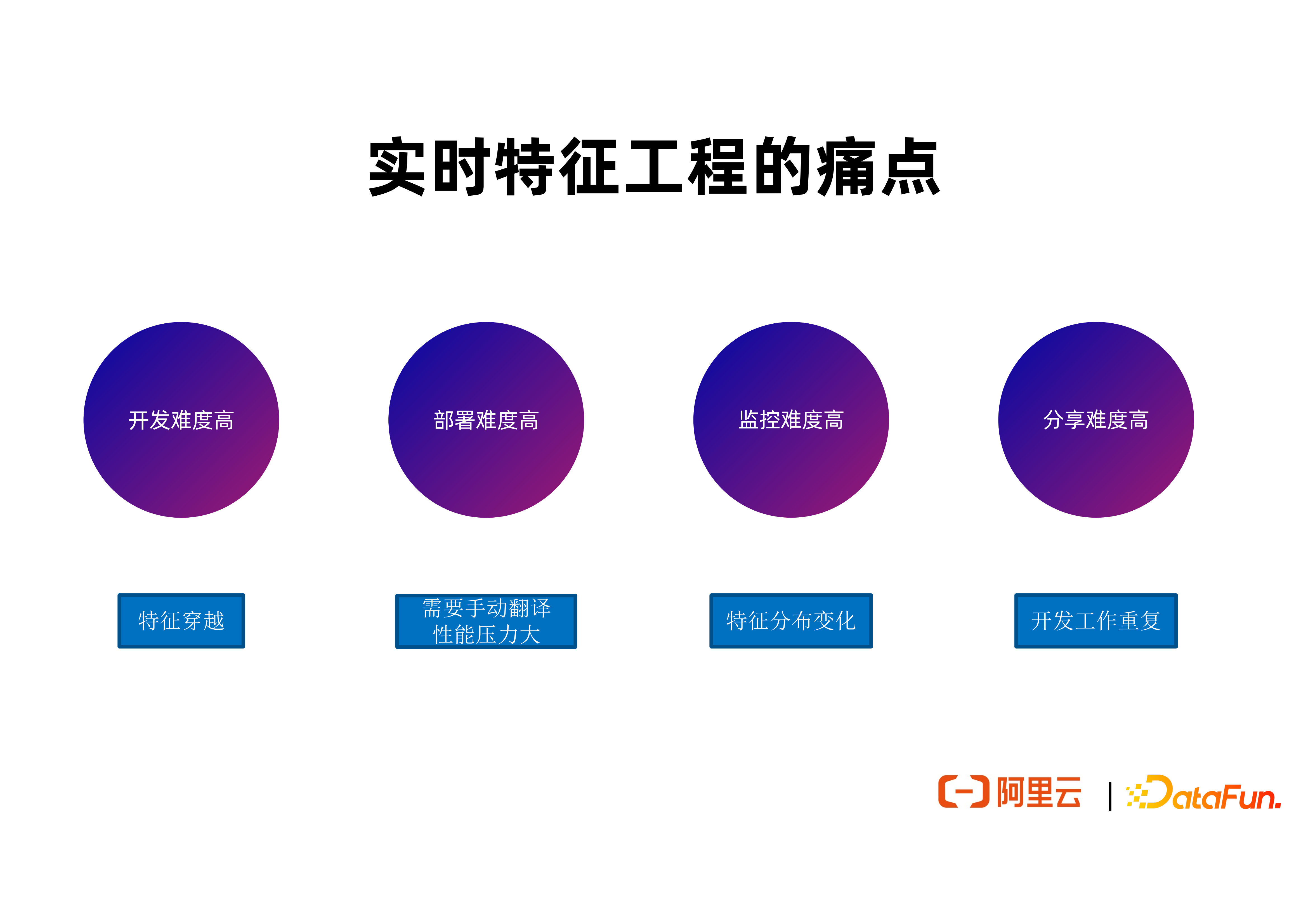
(1)開發難度高
① 特徵穿越
開發階段,用的比較多的是實時特徵框架 Apache Flink,因為 Flink 已經基本上是實時流計算的事實標準,但是用 Flink 或者類似的框架來開發實時特徵存在著需要解決特徵穿越的難點。很多資料科學家並不瞭解特徵穿越的解決經驗,並且需要比較多的學習時間和成本來解決這類問題,這是開發階段的主要痛點。
(2)部署難度高
① 需要手動翻譯
很多公司會有一個專門的平臺團隊把資料科學家寫的單程式 Python 作業翻譯成可分散式執行的 Flink 或者 Spark 作業,來實現高效能高可用的部署。其翻譯過程會增加整個開發生命週期長度。並且因為還需要額外的人力去做翻譯工作,增加了開發成本,更進一步帶來了引入 Bug 的可能。另一撥人將資料科學家的作業翻譯之後的邏輯未必和原先的邏輯保持一致,這樣就帶來更多的 Debug 工作量。
(3)監控難度高
① 特徵分佈變化
特徵工程作業的整個質量和效率不只是取決於作業有沒有 Bug,還依賴於上游的輸入資料數值分佈能滿足一些特性,例如能接近於訓練時的資料數值分佈。很多作業的推理效果下降,經常是由於上游作業生產的資料分佈發生了變化。這種情況下,需要開發者去追蹤整個鏈路,一段段去看在哪個地方的特徵資料分佈發生了變化,根據具體情況再去看是否需要重新訓練或者解決 Bug。這部分人力工作量過大也是一個痛點。
(4)分享難度高
① 開發工作重複
雖然很多特徵計算作業的開發團隊和場景不同,但其實用了類似甚至相同的特徵定義。很多公司中沒有一個很好的渠道,讓公司內不同團隊能查詢和複用已有特徵。這就導致不同團隊經常需要做重複開發,甚至對於相同特徵需要重複跑作業去生成一些特徵。這帶來了人力和計算/儲存資源的浪費,因為需要更多的計算、記憶體、儲存空間去生成相同特徵。
② point-in-time correct 語義
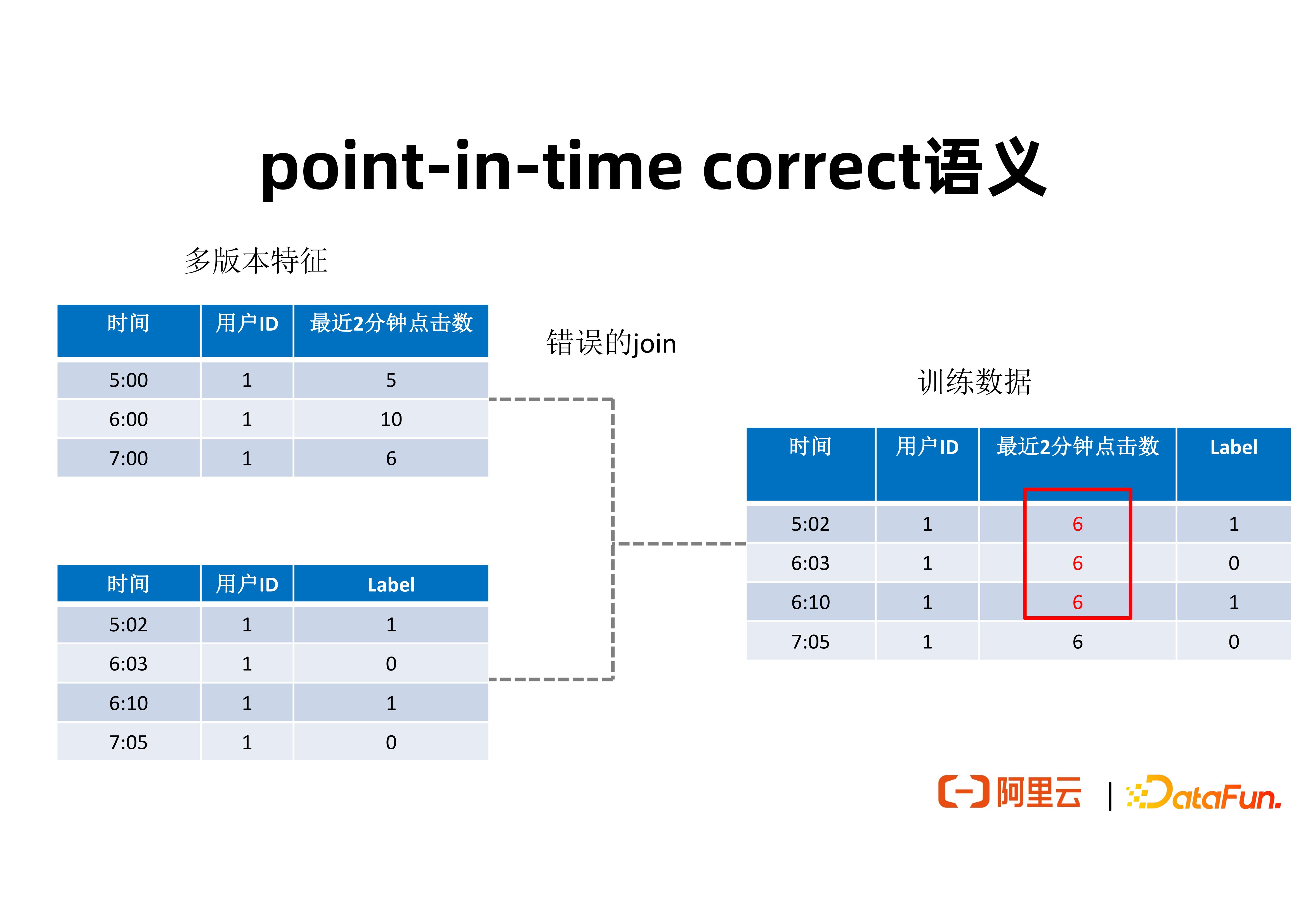
為了讓大家能夠理解什麼叫特徵穿越,上圖給出了一個簡單例子,來展現這個問題。圖左上表是使用者的一個行為特徵,表達了在不同時間節點,對於一個給定 ID 的使用者,在最近兩分鐘內的點選數。這個點選數可能幫助我們推理使用者是否會點選某個廣告。為了用這些特徵去做訓練,通常需要將特徵拼接到使用者帶有 Label 的一些資料集上。圖左下表展現的是一個使用者實際有沒有點選廣告的一些正樣本和負樣本的資料集,標註了在不同的時間點,使用者所產生的正樣本或負樣本。為了將這兩個資料集中的特徵拼接起來,形成訓練用的資料集,通常需要根據使用者 ID 作為 key 進行特徵拼接。如果只是簡單地進行 Table Join,不考慮時間戳,就可能產生特徵穿越問題。 例如在 6:03 分時,使用者最近 2 分鐘點選數應該是 10,但拼接得到的特徵值可能是來自 7:00 分時的 6。這種特徵穿越會帶來實際推理效果的下降。一個具有 point-in-time correct 語義的 Join 結果應該如下圖所示:

為了在樣本拼接時避免特徵穿越,對於在上圖左表中的每一條資料,應該在維表的多個版本特徵當中找到時間戳小於並且最接近於左表中的時間戳的特徵數值,並將其拼接到最終生成的訓練資料集上。這樣一個具有 point-in-time correct 語義的拼接,將產生上圖右邊所顯示的訓練資料集。針對不同的時間點,都有所對應最近兩分鐘內產生的特徵值。這樣生成的訓練資料集可以提高訓練和推理的效果。
3. Feature Store 的核心場景
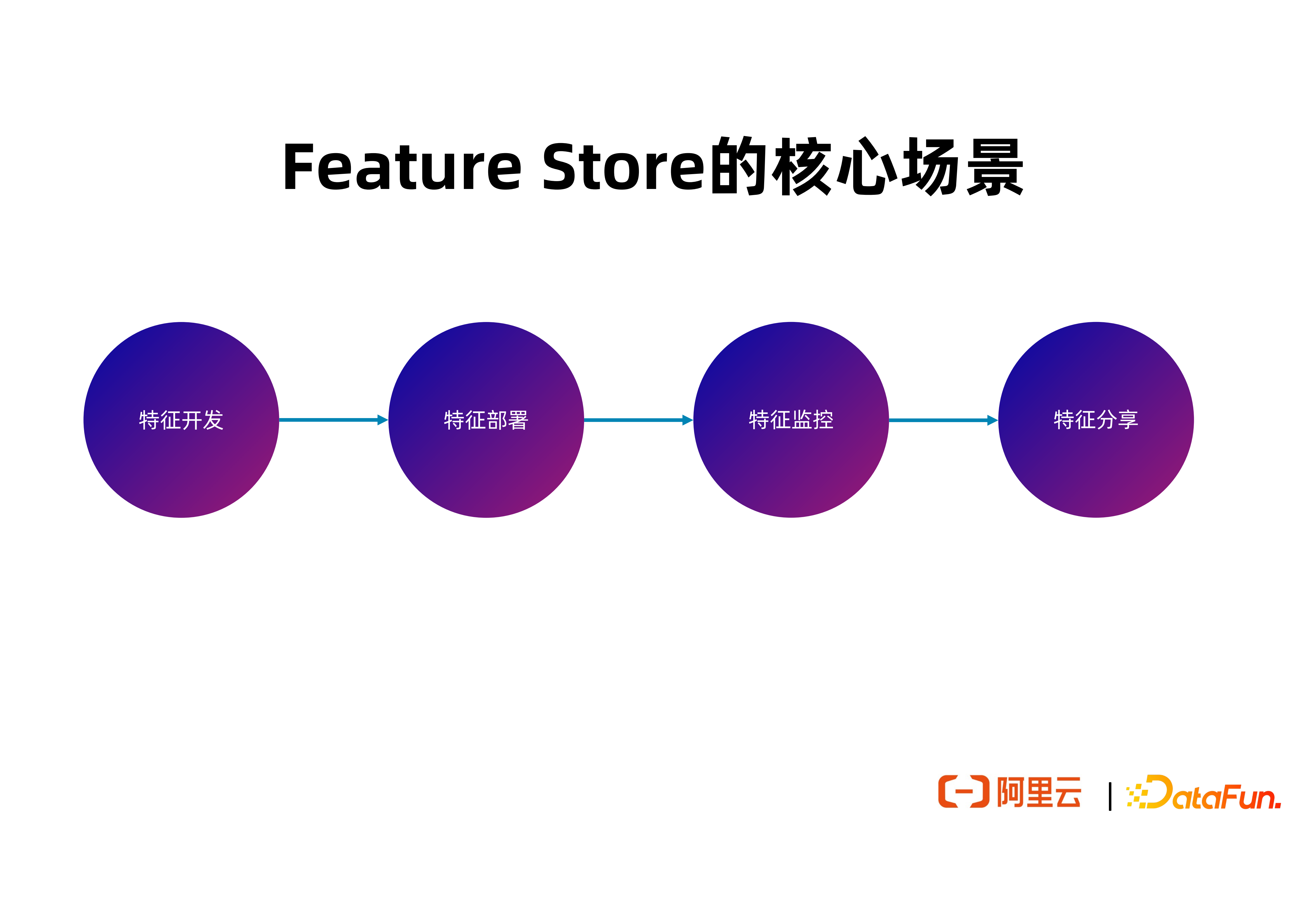
接下來介紹 FeatHub 作為一個 Feature Store,對於整個特徵開發週期的每一階段試圖解決的問題和提供的工具。
(1)特徵開發
在特徵開發階段,FeatHub 會提供一個基於 Python 的具有高易用性的 SDK,讓使用者能簡潔地表達特徵的計算邏輯。特徵計算本質是一個特徵的 ETL。開發階段最重要的是 SDK 的易用性和簡潔性。
(2)特徵部署
在特徵部署階段,FeatHub 會提供執行引擎,實現高效能,低延遲的特徵計算邏輯的部署,並且能對接不同的特徵儲存。部署階段最重要的是執行引擎的效能和對接不同特徵儲存的能力。
(3)特徵告警
在特徵監控階段,為了方便開發者及時發現特徵數值分佈的變化並做出應對,FeatHub 將來會產生一些常用指標來覆蓋常見的特徵質量問題,例如具有非法數值的特徵比例,或者特徵平均值,並根據這些指標進行報警,去及時通知負責人調查相關特徵分佈變化的原因和做出應對,來維護端到端的推薦鏈路的效果。
(4)特徵分享
在特徵分享階段,FeatHub 將來會提供特徵的註冊和搜尋能力,支援同一公司內不同團隊的開發人員去查詢自己想要的特徵是不是已經存在,並複用這些特徵定義和已經產生的特徵資料。
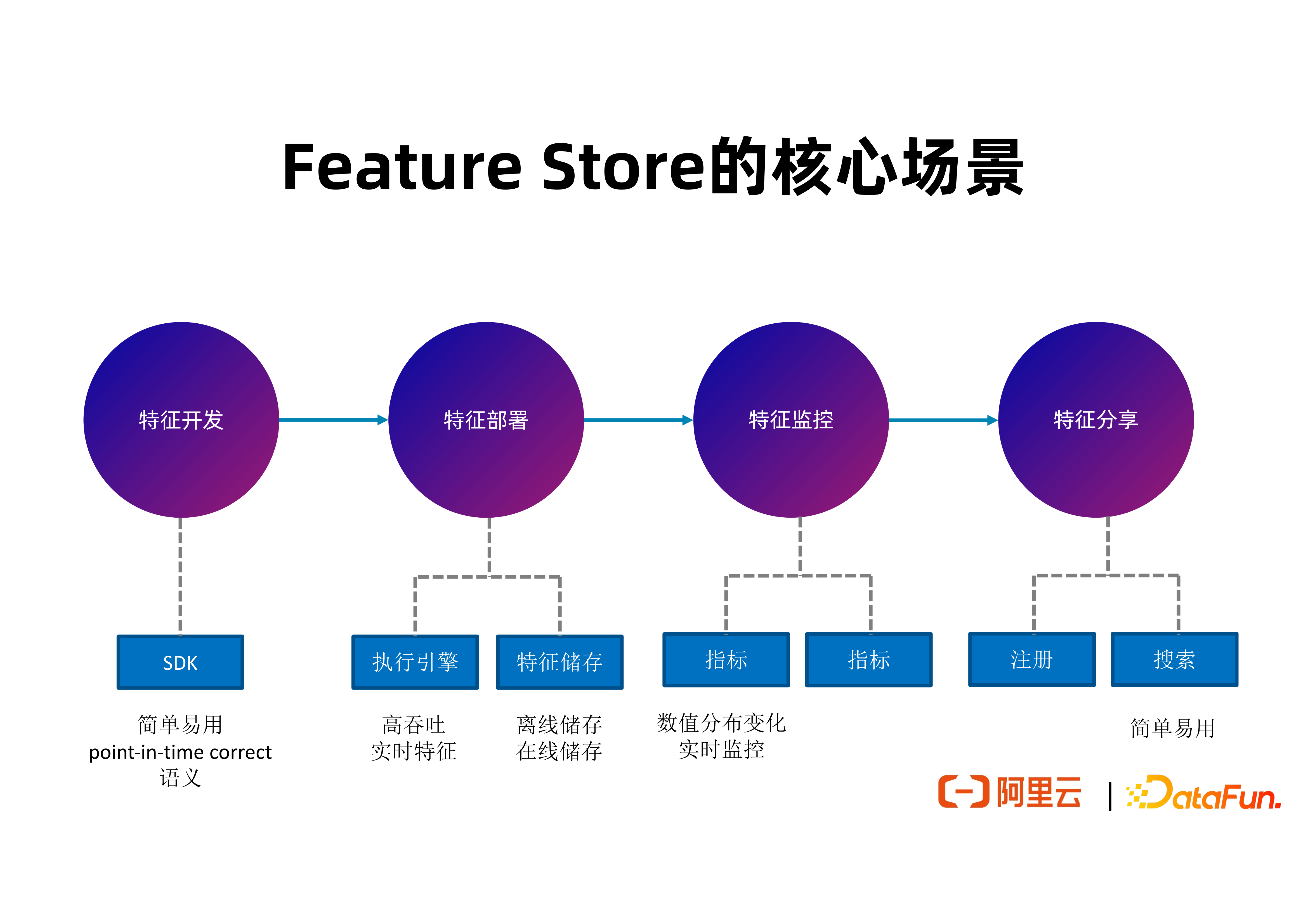
上圖中說明 FeatHub 的核心特點。在開發階段,FeatHub 能提供簡單易用的 SDK,支援具有 point-in-time correct 語義的特徵拼接,特徵聚合等邏輯。在部署階段,FeatHub 能支援高吞吐、低延遲的特徵生成,支援使用 Flink 作為執行引擎來計算特徵;並且能支援多種特徵儲存系統,方便使用者自由選擇所希望使用的儲存型別。在監控階段, FeatHub 將能提供實時指標來監控特徵分佈的變化,包含離線和實時監控,方便開發者及時發現問題。在分享階段,FeatHub 將會提供簡單易用的 Web UI 以及 SDK,支援開發者註冊,搜尋和複用特徵。

在 Feature Store 領域內已經有一些具有代表性的 Feature Store 專案,例如今年初 LinkedIn 開源的 Feathr,以及開源了多年的 Feast。我們調研了這些專案,發現他們並不能很好地達成我們提出的目標場景。
FeatHub 相比現有方案,帶來的額外價值包括:
① 簡單易用的 Python SDK。FeatHub 的 SDK 參考了已有的 Feature Store 專案的 SDK,能支援這些專案的核心功能,並進一步提升了 SDK 的抽象能力和易用性,
② 支援單機上的開發和實驗。開發者不需要對接分散式的 Flink 或 Spark 叢集來跑實驗,而只需要使用單機上的 CPU 或者記憶體資源就可以進行開發和實驗,並能使用 scikit-learn 等單機上的機器學習演算法庫。
③ 無需修改程式碼即可切換執行引擎。當使用者完成單機上的開發後,可以將單機執行引擎切換到 Flink 或 Spark 等分散式執行引擎,而無需修改表達特徵計算邏輯的程式碼。使用 Flink 作為執行引擎可以讓 Feathub 支援高吞吐、低延時的實時特徵計算。FeatHub 將來會進一步支援使用 Spark 作為執行引擎,讓使用者在離線場景中可以得到潛在的更好的吞吐效能,根據場景自由選擇最合適的執行引擎。
④ 提供執行引擎的擴充套件能力。FeatHub 不僅可以支援以 Flink、Spark 作為執行引擎,還支援開發者自定義執行引擎,使用公司內部自研的執行引擎進行特徵 ETL。
⑤ 程式碼開源,使得使用者可以自由選擇部署 FeatHub 的雲廠商,也可以在私有云中進行部署。
02 FeatHub 架構與核心概念
1. 架構

以上是包含 FeatHub 主要模組的架構圖。最上層提供了一套 Python SDK,支援使用者定義資料來源、資料終點以及特徵計算邏輯。由 SDK 所定義的特徵可以註冊到特徵後設資料中心,支援其他使用者和作業來查詢和複用特徵,甚至可以基於特徵後設資料進一步分析特徵血緣。特徵定義包含了特徵的 source、sink,以及常見的計算邏輯,例如 UDF 呼叫、特徵拼接,基於 over 視窗與滑動視窗的聚合等。當需要取生成使用者所定義的特徵時,FeatHub 會提供一些內建的 Feature Processor,也就是執行引擎,去執行已有特徵的計算邏輯。當使用者需要在單機上做實驗時,可以使用 Local Processor 使用單機上的資源,無需對接一個遠端的叢集。當需要生成實時特徵時,可以使用 Flink Processor 完成高吞吐、低延時的流式特徵計算。
將來也可以支援類似於 Lambda Function 的 Feature Service 來實現線上的特徵計算,以及對接 Spark 來完成高吞吐的離線特徵計算。執行引擎可以對接不同的離線和線上特徵儲存系統,例如用 Redis 完成線上特徵儲存,用 HDFS 完成離線特徵儲存,以及用 Kafka 完成近線特徵儲存。
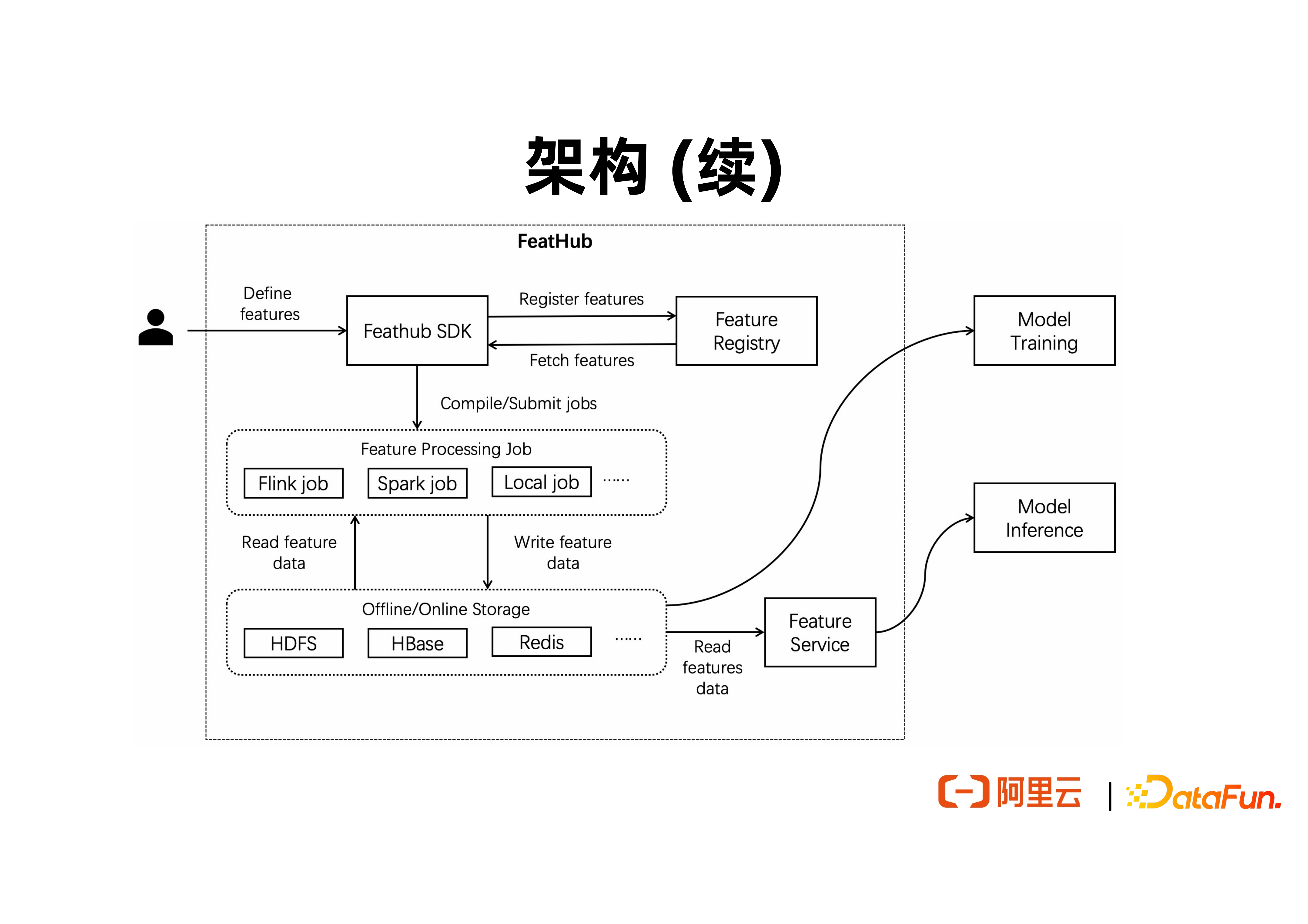
上圖展現了 FeatHub 如何被使用者使用,以及對接下游的機器學習訓練和推理程式,使用者或開發者將透過 SDK 來表達所希望計算的特徵,然後提交到執行引擎上進行部署。特徵經過計算後,需要輸出到特徵儲存,例如 Redis 和 HDFS。一個機器學習離線訓練程式可以直接讀取 HDFS 中的資料去做批次訓練。一個線上的機器學習推理程式可以直接讀取 Redis 中的資料進行線上推理。
2. 核心概念
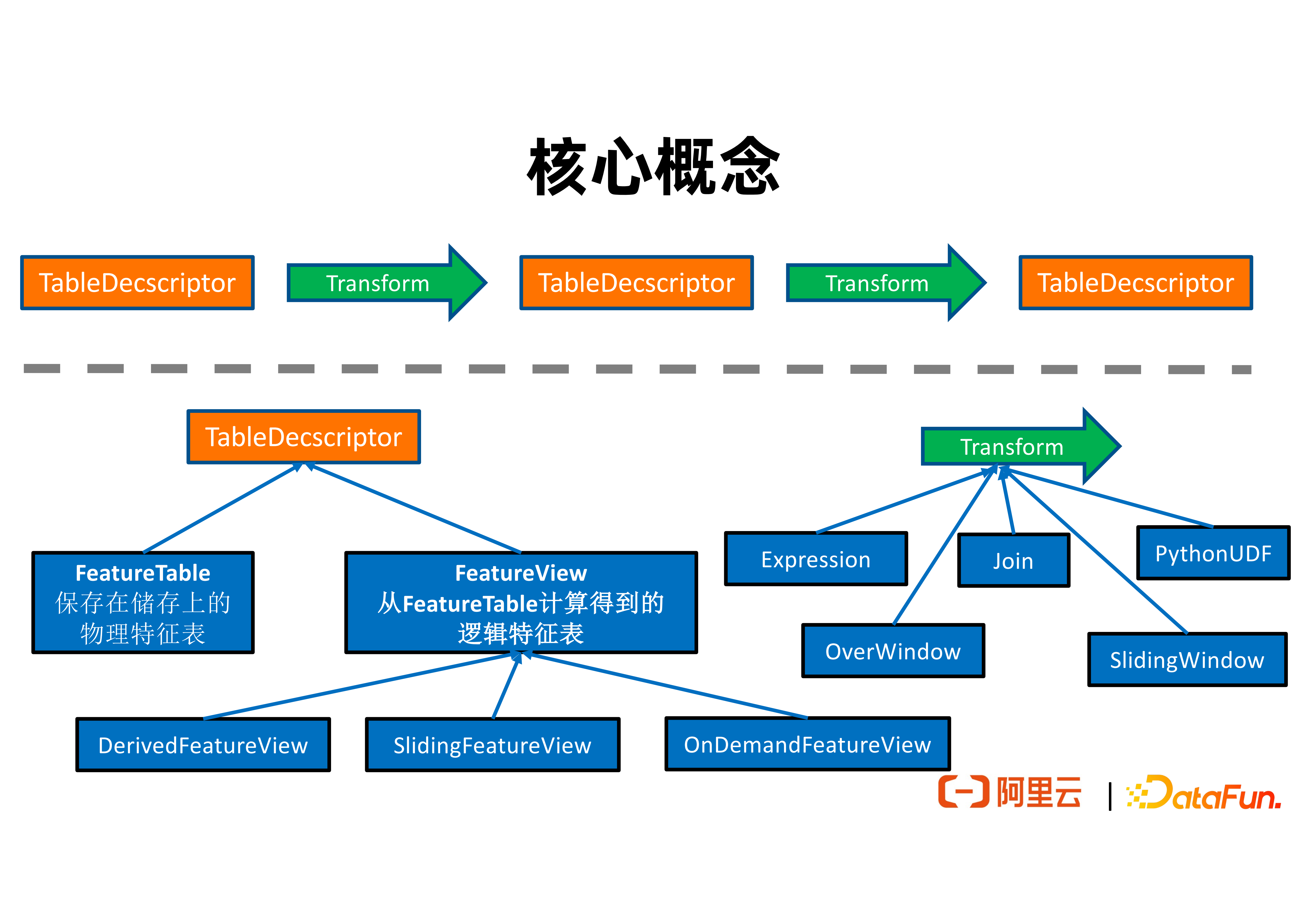
上圖展現了 FeatHub 中的核心概念之間的關係。一個 TableDescriptor 表達一組特徵的集合。TableDescriptor 經過邏輯轉換可以生產一個新的 TableDescriptor。
TableDescriptor 分為兩類。其中 FeatureTable 表達的是具有特定實體地址的表,例如可以是一個在 Redis 中的表,也可以是一個在 HDFS 中的表。FeatureView 則是一些不一定有實體地址的邏輯表,通常是從一個 FeatureTable 經過一連邏輯串轉換後得到的。
FeatureView 有如下 3 個子類:
① DerivedFeatureView 輸出的特徵表和其輸入的特徵表(i.e. source)的行基本是一對一的。它可以支援表達單行轉換邏輯(e.g. 加減乘除),over window 聚合邏輯,以及特徵拼接邏輯。它可用於生成訓練資料。例如在之前所介紹的例子中,需要將訓練樣本去拼接來自不同維表的特徵以得到實際的訓練資料,就可以使用 DerivedFeatureView 來完成。
② SlidingFeatureView 支援表達由滑動視窗計算得到的特徵。它輸出的特徵表和其輸入的特徵表的行不一定是一對一的。這是因為即使沒有新的輸入,滑動視窗計算得到的特徵數值會隨著時間流逝而變化。SlidingFeatureView 可以用於維護實時生成的特徵,並輸出到線上特徵儲存,例如 Redis,用於線上推理。例如,我們可以用 SlidingFeatureView 去計算每個使用者最近兩分鐘內點選某個網頁的次數,並將特徵數值實時更新到 Redis 中,然後廣告推薦鏈路就可以線上查詢這個特徵的值來做線上推理。
③ OnDemandFeatureView 可以與 Feature Service 用在一起,支援線上特徵計算。例如在使用高德地圖時,開發者可能會希望在收到使用者的請求之後,根據使用者當前的物理位置與上一次傳送請求時的物理位置,計算出使用者移動的速度和方向速度,來協助推薦路線的決策。這些特徵必須在收到使用者請求的時候進行線上計算得到。OnDemandFeatureView 可以用於支援這類場景。
Transform 表達的是特徵計算邏輯。FeatHub 當前支援如下 5 種特徵計算邏輯:
① Expression 支援使用者基於一個 DSL 語言表達單行的特徵計算邏輯。其表達能力接近SQL 語言中的 select 語句,可以支援加減乘除和內建函式呼叫,可以讓熟悉 SQL 的開發者快速上手。
② Join 表達的是特徵拼接邏輯。開發者可以指定維表的名字和需要拼接的特徵名字等資訊。
③ PythonUDF 支援使用者自定義 Python 函式來計算特徵。
④ OverWindow 表達的是 Over 視窗聚合邏輯。例如在收到一行資料時,使用者希望根據之前的 5 行資料,進行聚合並計算有多少條資料符合某個規則。
⑤ SlidingWindow 表達的是滑動視窗聚合邏輯。
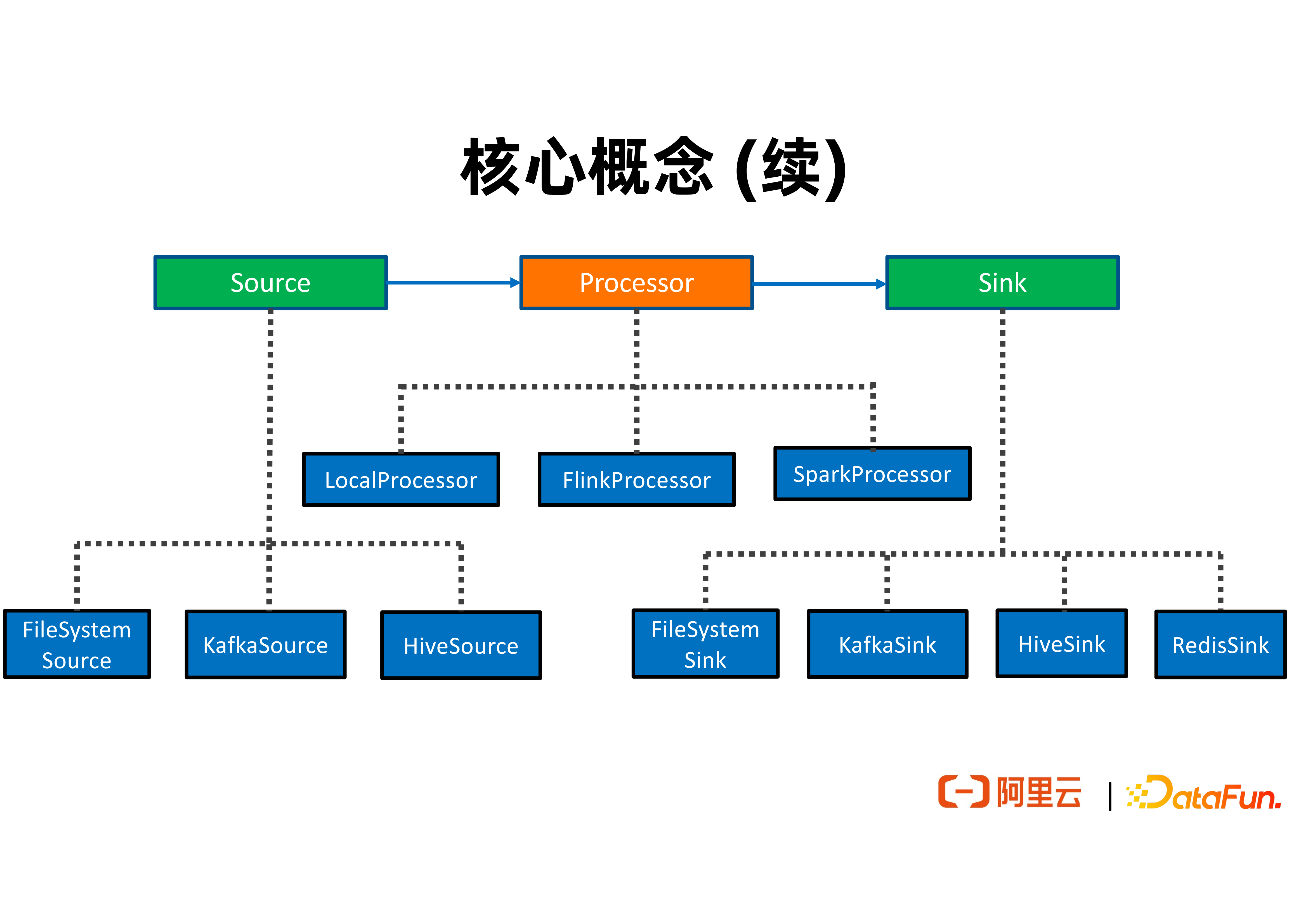
從上圖中可以看到,通常一個特徵 ETL 作業會從特徵源表讀取特徵,經過多次特徵計算邏輯產生新的特徵,並將生成的特徵輸出到特徵結果表。特徵源表可以對接不同的特徵儲存,例如有 FileSystem,Kafka,Hive 等。類似的,特徵結果表也可以對接 FileSystem,Kafka,Redis 等特徵儲存。
Processor 包括 LocalProcessor、FlinkProcessor、SparkProcessor,分別可以使用單機物理資源,分散式的 Flink 叢集,以及分散式 Spark 叢集,去執行使用者所定義的特徵計算邏輯。
03 FeatHub API 展示
1. 特徵計算功能

在介紹了 FeatHub 的架構和核心概念後,我們將透過一些樣例程式來展現 FeatHub SDK 的表達能力以及易用性。對於特徵開發 SDK 來說,其最核心的能力就是如何表達新的特徵計算邏輯。FeatHub SDK 支援特徵拼接、視窗聚合、內建函式呼叫以及自定義 Python 等能力,將來還可以支援基於 JAVA 或者 C++ 的 UDF 呼叫。
上圖展示了一個特徵拼接的程式碼片段。在這個例子中,假設 HDFS 中有原始的正負樣本資料,記錄了使用者購買商品的行為。我們想進一步想獲取使用者在購買每個商品時的商品價格。一個 price_updates 表維護了商品價格變化的資料。每次商品價格變化時,會在 price_updates 表中產生一行資料,包含商品 ID 和最新的商品價格。我們可以使用 JoinTransform,設定 table_name=price_updates,feature_name=price,以及 key=item_id,來表達相應的特徵拼接邏輯。這樣 FeatHub 就可以根據在 price_updates 中,找到具有給定 item_id 的行,並根據時間戳,找到最合適的 price 數值,來拼接到樣本資料表上。
Over 視窗聚合的程式碼片段則展示瞭如何用 OverWindowTransform 來計算特徵。使用者可以使用 expr=”item_counts * price”,以及 agg_fun=”SUM”,來根據購買的商品數量和價格,計算出最近時間視窗中的總消費量。其中視窗的時間長度為 2 分鐘。group_by_keys=[“user_id”] 則說明了我們會為每個使用者單獨計算出對應的總消費量。
滑動視窗聚合與 Over 視窗聚合比較類似,API 上唯一區別是可以額外指定 step_size。如果 step_size=1 分鐘,則視窗會在每分鐘進行滑動併產生新的特徵值。
內建函式呼叫的程式碼片段展示瞭如何使用 DSL 語言表達加減乘除和 UDF 呼叫。假設輸入的資料包含計程車接送乘客的時間戳。我們可以透過呼叫 UNIX_TIMESTAMP 內建函式將接送乘客的時間戳轉換為整數型別的 epoch time,然後將得到的 epoch time 相減,得到每次旅程的時間長度,作為一個特徵用於之後的訓練和推理。
在 PythonUDF 呼叫的程式碼片段中,使用者可以自定義一個 Python 函式,對輸入的特徵進行任意的處理,例如產生小寫的字串。
透過以上幾個程式碼片段,我們可以看出 FeatHub 的 API 是比較簡潔易用的。使用者只需要設定計算邏輯所必須的引數,而無需瞭解處理引擎的細節。
2. 樣例場景
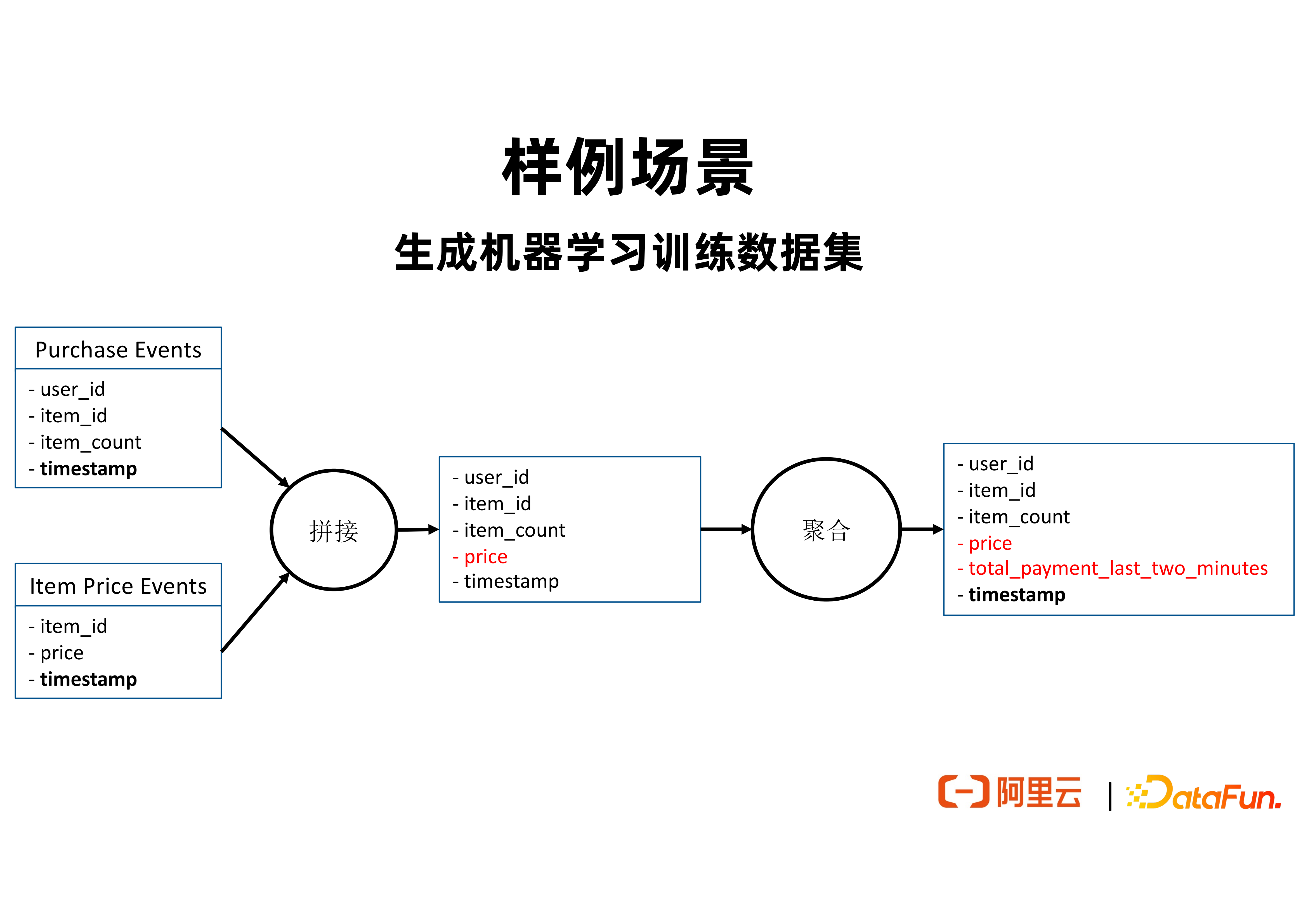
在以上樣例場景中,使用者有兩個資料來源。其 Purchase Events 包含使用者購買商品的樣本資料,可以來自於 Kafka,也可以來自於 FileSystem;Item Price Events 包含商品價格變動的資料。每次商品價格變化時,會在 Item Price Events 中產生一行資料,包含商品 ID 和最新的商品價格。我們希望對於每條使用者購買商品的樣本資料,計算使用者在該行為發生時最近兩分鐘內的消費總量,作為特徵來協助推理出使用者會不會購買某樣商品。為了生成這個特徵,可以使用上圖中所描述的計算邏輯,先將 Item Price Events 中的 price 特徵以 item_id 作為 join_key 拼接到 Purchase Events 上。然後再基於時間視窗和使用 user_id 作為 group_by _keys 進行聚合,來計算得到每個使用者最近兩分鐘內的消費總量。
3. 樣例程式碼

以上程式碼片段展示了一個樣例 FeatHub 應用所需要完成的步驟。
① 首先使用者需要建立一個 FeatHubClient 並設定 processor_type。如果是本地實驗,可以設定成 Local,如果是遠端分散式生產部署,可以設定成 Flink。
② 使用者需要建立 Source 來讀取資料,例如可以使用 FileSystemSource 讀取在離線儲存系統中的資料,或者使用 KafkaSource 讀取近線儲存系統中的實時資料。FileSystemSource 中,使用者可以指定例如 data_format,schema、檔案的位置等資訊。值得注意的是,使用者可以提供 time_stamp_field 和 time_stamp_format,分別表達資料來源表中代表時間的列以及對應的解析格式。FeatHub 將使用這些資訊完成做 point-in-time correct 的特徵計算,避免特徵穿越的問題。
③ 使用者可以建立一個 FeatureView 來表達特徵拼接和聚合的邏輯。如果要做拼接,使用者可以 item_price_events.price 來表達希望拼接的特徵。FeatHub 會找到名字為 item_price_events 的表並從中拿到名字為 price 的特徵。使用者還可以使用 OverWindowTransform 來完成 Over 視窗聚合,定義一個名為total_payment_last_two_minutes 的特徵。其中 window_size=2 分鐘表示對於兩分鐘內的資料應用指定的表示式和聚合函式來計算特徵。

④ 對於已經定義的 FeatureView,如果使用者想做本地開發和實驗,並使用 scikit-learn 演算法庫進行單機上的訓練,可以使用 to_pandas() API 來將資料以 Pandas DataFrame 格式獲取到單機的記憶體中。
⑤ 當使用者需要完成特徵的生產部署時,可以使用 FileSystemSink 指定用於存放資料的離線特徵儲存。然後呼叫 execute_insert() 將特徵輸出到所指定的 Sink 當中。

FeatHub 的基本價值是提供 SDK 來方便使用者開發特徵,並且提供執行引擎來計算特徵。除此之外,FeatHub 還將提供執行引擎的效能最佳化,讓使用者在特徵部署階段獲得更多的收益。例如對於基於滑動視窗聚合的特徵,目前如果使用原生的 Flink API 來計算,Flink 會在每個滑動的 step_size 都輸出對應的特徵值,無論特徵的數值是否發生了變化。對於 window_size=1 小時,step_size=1 秒這樣的滑動視窗,大部分情況下 Flink 可能會輸出相同的特徵數值。這樣會浪費網路流量、下游儲存等資源。FeatHub 中支援使用者配置滑動視窗的行為,允許滑動視窗只在特徵數值發生變化的時候輸出特徵,來最佳化特徵計算作業的資源使用量。
另外 FeatHub 還將進一步最佳化滑動視窗的記憶體和 CPU 使用量。在某些場景中,使用者會定於許多類似的滑動視窗特徵。這些特徵只有 window size 不一樣。例如我們可能希望得到每個使用者最近 1 分鐘,5 分鐘,和 10 分鐘內的購買商品的花費總數。如果使用原生的 Flink API 來計算,作業可能會使用三個聚合運算元來分別計算這 3 個特徵。每個聚合運算元會有單獨的記憶體空間。考慮到這些運算元所處理的資料和計算邏輯具有較大的重合,FeatHub 可以用一個自定義運算元,統一完成這些特徵的計算,來達到節約記憶體和 CPU 資源的目標。

FeatHub 目前已經在 GitHub 開源,能夠支援一些基本的 LocalProcessor 和 FlinkProcessor 的功能。我們會進一步完善 FeatHub 的核心功能來方便使用者特徵工程的開發和落地。其中包括支援更多常用的離線儲存、線上儲存,對接 Notebook,提供 Web UI 來視覺化特徵的後設資料,支援使用者做特徵的註冊、搜尋、複用,以及支援使用 Spark 作為 FeatHub 的執行引擎。
來自 “ DataFunTalk ”, 原文作者:林東博士;原文連結:http://server.it168.com/a2023/0329/6796/000006796509.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- FeatHub:流批一體的實時特徵工程平臺特徵工程
- vivo 實時計算平臺建設實踐
- [平臺建設] HBase平臺建設實踐
- 快手流批一體資料湖構建實踐
- 百度流批一體的實時多維分析實踐
- Flink 流批一體在小米的實踐
- Arctic 基於 Hive 的流批一體實踐Hive
- 流批一體在京東的探索與實踐
- Dataphin流批一體的實時研發
- Flink 流批一體方案在數禾的實踐
- 愛奇藝大資料實時分析平臺的建設與實踐大資料
- 流批一體的近實時數倉的思考與設計
- 螞蟻實時低程式碼研發和流批一體的應用實踐
- 流批一體架構在快手的實踐和思考架構
- 位元組跳動湖平臺在批計算和特徵場景的實踐特徵
- 高德Serverless平臺建設及實踐Server
- 中原銀行 AI 平臺建設實踐AI
- 高德 Serverless 平臺建設及實踐Server
- OnZoom 基於Apache Hudi的流批一體架構實踐OOMApache架構
- 攜程基於Flink的實時特徵平臺特徵
- 愛奇藝統一實時計算平臺建設
- 海大集團的可觀測平臺建設實踐
- 宜信智慧監控平臺建設實踐|分享實錄
- Serverless 工程實踐 | 快速搭建 Kubeless 平臺Server
- Serverless 工程實踐|自建 Apache OpenWhisk 平臺ServerApache
- Serverless 工程實踐 | 自建 Apache OpenWhisk 平臺ServerApache
- 將軍令:資料安全平臺建設實踐
- 車路協同雲控平臺建設實踐
- 流批一體在 AI 核心電商領域的探索與實踐AI
- 觸寶科技基於Apache Hudi的流批一體架構實踐Apache架構
- 農業銀行湖倉一體實時數倉建設探索實踐
- 實時開發平臺建設實踐,深入釋放實時資料價值丨 04 期直播回顧
- 貨拉拉一站式雲原生AI平臺建設實踐AI
- 阿里雲 PB 級 Kubernetes 日誌平臺建設實踐阿里
- Flink 在螞蟻實時特徵平臺的深度應用特徵
- 如何降低 Flink 開發和運維成本?阿里雲實時計算平臺建設實踐運維阿里
- 得物前端巡檢平臺的建設和應用實踐前端
- 數倉服務平臺在唯品會的建設實踐