貨拉拉一站式雲原生AI平臺建設實踐
背景
資料工程、模型訓練、線上服務是機器學習技術實現的三駕馬車,這個流程中處理的資料量大,計算量大、訓練框架和版本多樣、底層依賴複雜,資源算力管理,需要人工介入解決很多問題,給AI落地帶來了比較困難。針對這一系列的問題,貨拉拉大資料智慧平臺組從2020年開始就在探索提供一套完整的雲原生的一站式AI解決方案,並從那時起就自建了Kubernetes 叢集,後續提供了GPU按量訓練能力、劃分獨立資源池納管了其它部門機器,圍繞著K8S平臺完善了監控告警、容器日誌收集能力,打通了大資料底層儲存,引入OBS、S3物件儲存,保證大資料AI化業務能穩定執行於K8S雲原生底座上。
從系統層面來看,大資料智慧平臺組在雲原生資源管理平臺上構建了Flink on k8s的特徵平臺、 notebook on K8S模型訓練、資料查詢及視覺化平臺、基於 K8S的線上推理平臺。自建雲原生K8S系統還支撐著智慧定價、ABTest等系統執行計算任務,利用雲原生特性賦能業務系統同時充分利用了叢集資源。另外,Docker映象解決了大資料AI組建對系統環境的依賴,K8S統一對底層資源管理,方便的構建多租戶例項的Notebook、自動擴縮容能夠為模型在推理提供自動化伸縮的能力,支援離線批任務、支援定時排程以及線上服務,多種多樣的任務型別使用了K8S Deployment、Cronjob、job、DaemonSets任務型別。
整體框架
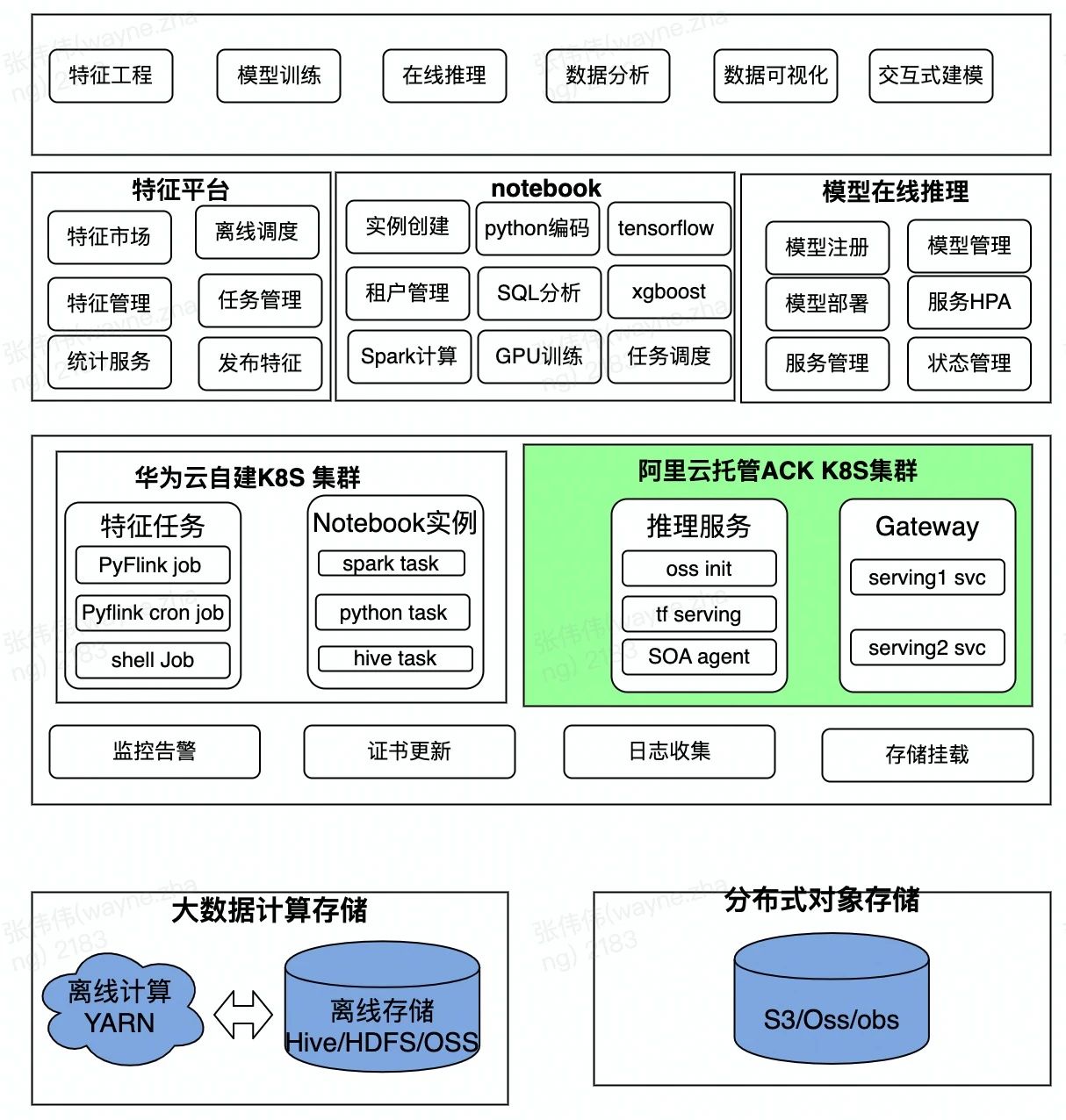
上圖是貨拉拉雲原生AI系統的整體框架,從資料接入、特徵工程、資料分析、資料視覺化、notebook線上開發、模型訓練、以及模型線上部署等階段,圍繞著AI整條鏈路孵化了專注于于資料ETL處理的特徵平臺、支援多種計算引擎的notebook線上開發及訓練平臺、支援模型註冊管理及釋出於一體的模型線上推理平臺,其中的特徵平臺底層的計算引擎是基於Flink on K8S去跑特徵任務,大資料儲存計算都可以新增到映象中可避免宿主機中安裝大量依賴包。
特徵平臺
特徵平臺主要是給資料科學家、資料工程師、機器學習工程師去使用,能夠解決資料儲存分散、特徵重複、提取複雜、鏈路過長、使用困難等問題。主要功能是把資料從Hbase、Hive、關係型資料庫等各類大資料ODS(Operational Data store )層進行快速的資料 ETL ,將資料抽取到ES、Redis、HBase、Hive,後設資料在特徵平臺進行管理,並統一了資料出口,用來做演算法模型的資料測試、訓練、推理及其它資料應用。
鏈路的流批一體

K8S任務流程
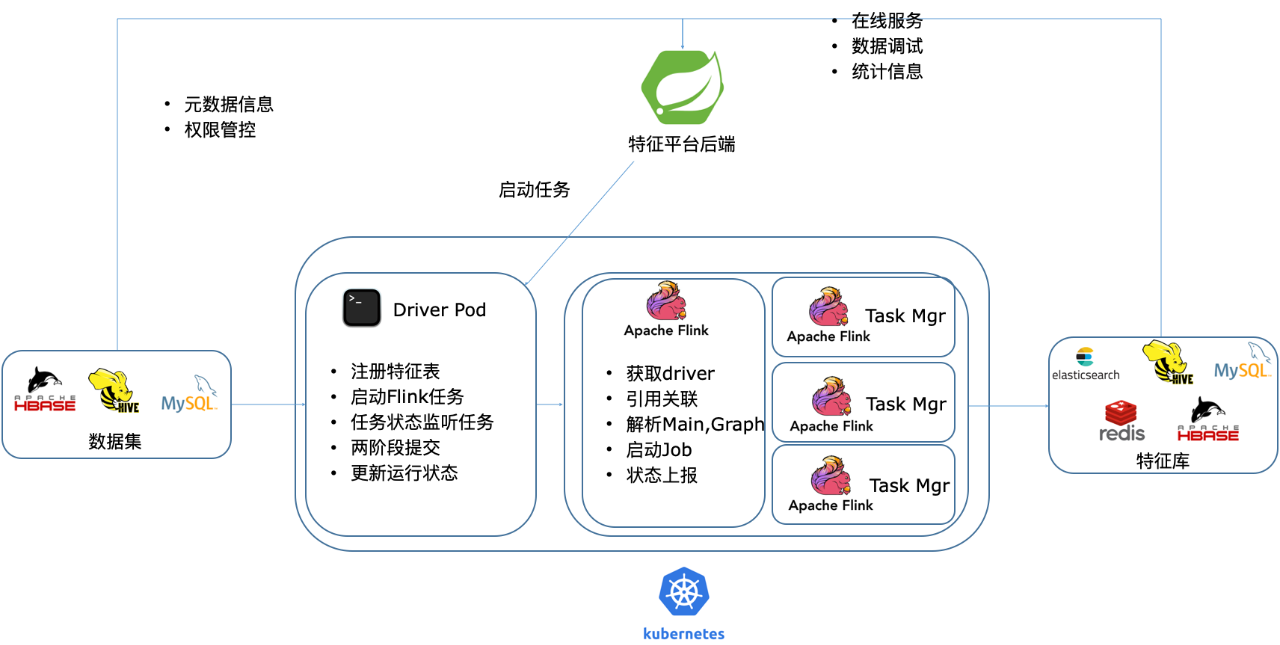
目前特徵平臺核心是採用Flink去實現資料的ETL,底層的是基於Kubernetes叢集去排程Flink ETL作業。Flink任務邏輯主要藉助pyflink去實現,PyFlink裡面包含任務的計算邏輯,把任務從source經過資料處理sink到對應的儲存,自定義實現了redis connector、最佳化ElasticSearch connector。依據K8S提供的Cronjob物件建立了定時特徵任務,可以定時的去做週期性的Flink任務,上層開放API提供外部驅動的特徵任務,叢集部署EFK在平臺層進行日誌的檢視。
互動式建模
Notebook是大資料智慧平臺組基於Apache Zeppelin進行定製開發,為資料分析師、AI演算法開發者量身打造的互動式開發工具,支援多種計算引擎如:Spark、Python、JDBC、Markdown、Shell terminal、Beeline、Hive sql 、Tensorflow供使用者選擇,使用者可以使用Notebook完成資料準備、資料預處理、資料分析視覺化,演算法除錯與模型訓練。社群的Zeppelin主要是單機多程式方式執行,K8S部署不完善,不滿足可擴充套件性、隔離性。同時機器學習深度學習對底層環境的依賴,部署到Kubernetes上以映象容器的方式啟動,也就是水到渠成的事情,可以解決Zeppelin的擴充套件性、安全性、隔離性問題。部署到K8S 需要解決如下問題:對接K8S管理Zeppelin服務的生命週期,包括Zeppelin服務的啟動、Zeppelin停止、狀態更新、資源回收。每個使用者建立獨立Zeppelin Server解決多租房問題,並暴露出統一的服務訪問入口。解決了Zeppelin Server停止後,使用者建立的Note資料能夠持久化不隨著服務的停止而刪除。為了滿足使用者對週期性外部驅動分析訓練的需求,需要設計一層計算驅動任務給notebook插上定時排程和外部驅動的翅膀。
如下所示,notebook實現的架構圖

架構主要分為三部分:
1. Zeppelin服務的啟動,停止和狀態獲取,這塊主要包含呼叫k8s Api去建立Namespace、ConfigMap、Service、RBAC、PV、PVC以及Zeppelin Server Deployment等Zeppelin啟動相關的k8s物件,這裡我們做了相關個性化開發,首先是透過呼叫JAVA K8S API去建立Zeppelin K8S物件,其次就是透過掛載NFS或S3解決 notebook 無法持久化儲存問題、接著就是另外新增init container容器去實現多個使用者demo note的複製操作,其中還會涉及以configmap和環境變數 實現相關動態引數的傳遞。
2. Zeppelin 服務的訪問,這塊主要設計了為每個使用者建立獨立的Namespace,並啟動一個獨立Zeppelin server 去做多租戶, 每個使用者暴露不同的訪問url,然後部署一個Nginx 並建立暴露NodePort 型別Nginx Service去代理不同使用者的訪問連結 ,透過Nginx解析url location獲取不同使用者Namespace及具體的location 拼裝成最終不同使用者反向代理的DNS地址。
3. 計算框架支援,為了更好地落實降本增效,充分利用大資料原有的yarn計算叢集,透過部署livy服務,Zeppelin notebook中對接livy服務,使得spark任務能夠透過livy提交到大資料yarn計算機群中。另外一個就是透過繼承jdbc 實現hive sql、OLAP引擎的支援。
打通計算和儲存
Zeppelin 支援許多大資料計算引擎,需要解決依賴包安裝、環境變數配置、直譯器配置等工作,作為notebook平臺這些功能在Zeppelin Server啟動後就可以直接使用,不需要使用者再配置這類繁瑣的工作,我們在設計開發的時候,打通底層spark 訪問儲存HDFS、新建了HIVE SQL直譯器,映象中內建大資料客戶端、配置DNS域名解析、解決了許可權認證、包依賴等問題,使用者最終可以直接訪問生產Hive 、HDFS。
資源隔離及回收
k8s叢集CPU、GPU、記憶體是有限制的,納管其它部門的機器資源想單獨隔離使用,如果沒有排程和隔離策略的話,當申請的資源過多,影響到其他任務的排程,同時也會跑到其它私有資源,更進一步的如果k8s分配出去的資源無法回收,總有一天會有資源用盡導致其他任務無法排程的情況。這裡我們對每個namespace 增加了Resource Quota限制了每個使用者最大的資源量,資源隔離統一對K8S叢集的計算節點打上不同的標記,規定了一些節點是notebook 公用的節點,一些節點是其它人獨有的資源,上層在建立任務的時候可以指定資源組,預設建立的Zeppelin notebook會排程到公用資源組節點上去,如果有些notebook比較重要就會指定到另外的資源組中,針對資源組增加了審批。
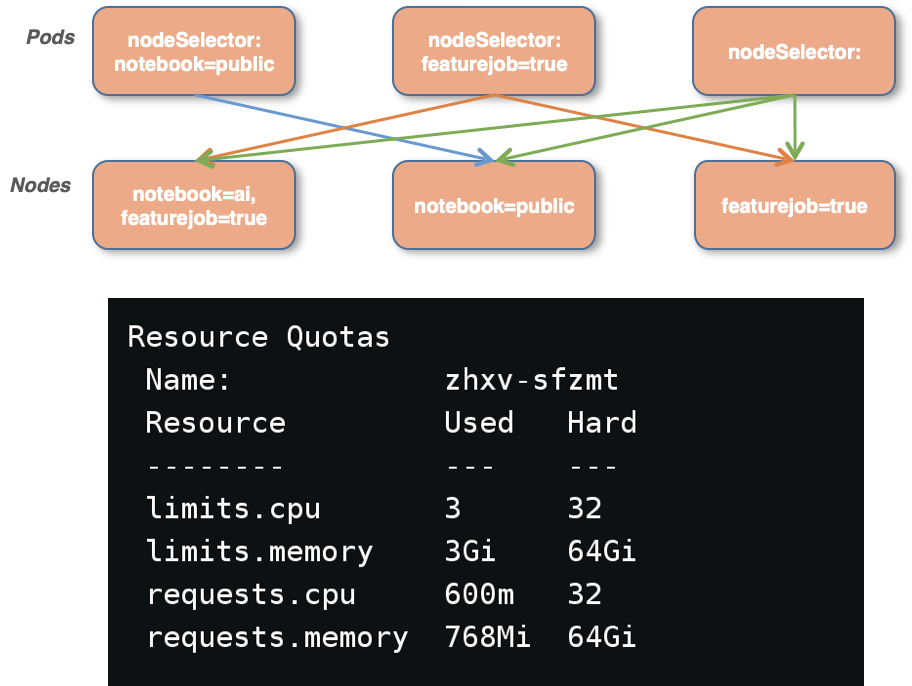
資源回收主要是前端選擇空閒停止時間,後端服務程式獲取配置引數,在Zeppelin server 與直譯器互動請求的地方啟動執行緒,不停更新互動時間,直到判斷空閒超過配置時間,觸發程式退出操作。
模型訓練gpu管理
異構叢集中如何對機器進行管理是一個比較複雜的問題,存在不同的雲廠商以及自有機器混用的情況下,解決的方案就是分為不同的的叢集,透過多叢集進行管理,還有就是不同地點位置甚至網路環境混用,透過一層排程層進行管理,這裡主要的架構如下:
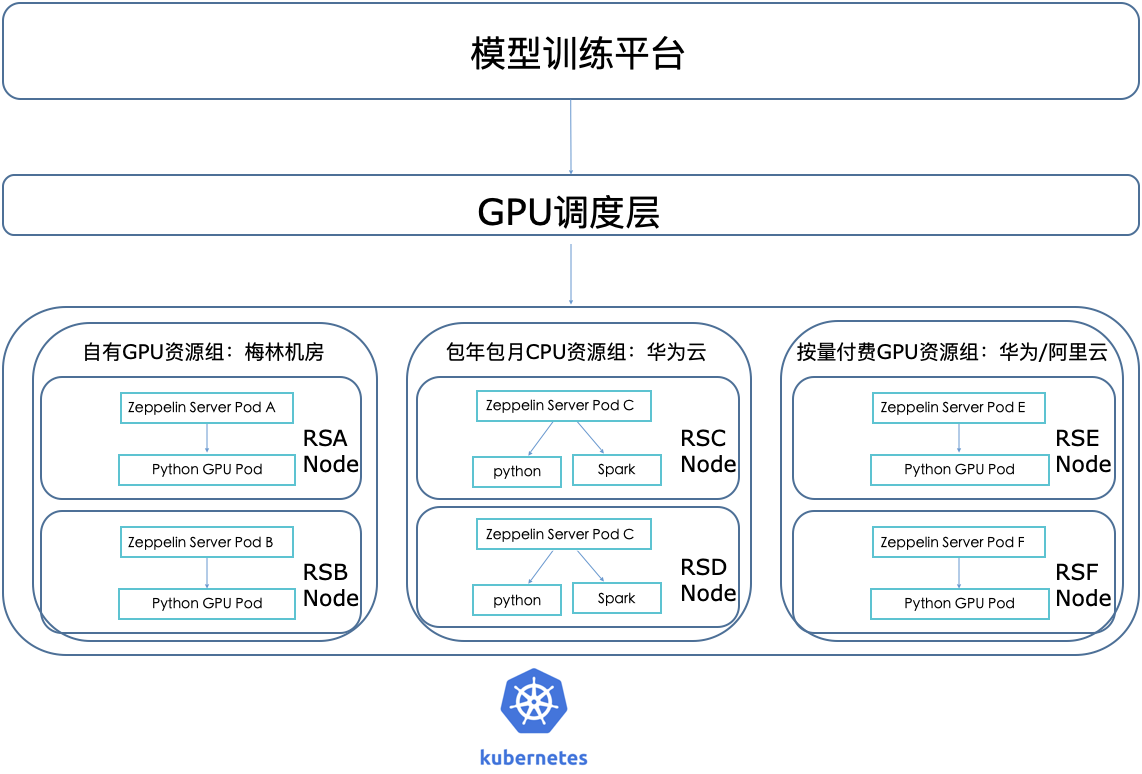
K8S 叢集主要構建在華為雲,在GPU場景下會單獨抽離一層GPU排程層,不同地區或者不同規格的GPU劃分到不同的資源組,資料庫中對這些GPU機器進行型別區分。比如針對GPU按量付費場景,在啟動GPU任務時候,會選擇不同的資源組,從資源組中選定特定的GPU節點,會為GPU和notebook建立繫結關係,透過呼叫運維提供的GPU例項開機介面啟動GPU節點,在任務空閒回收或者手動停止例項的時候呼叫運維停機介面,對GPU機器進行關機處理。
資料持久化和多計算框架資料共享
沒有資料持久化,容器中使用者建立Zeppelin notebook重啟後notebook檔案資料就會消失 ,不同計算任務執行在不同的的K8S pod之間如何共享檔案?
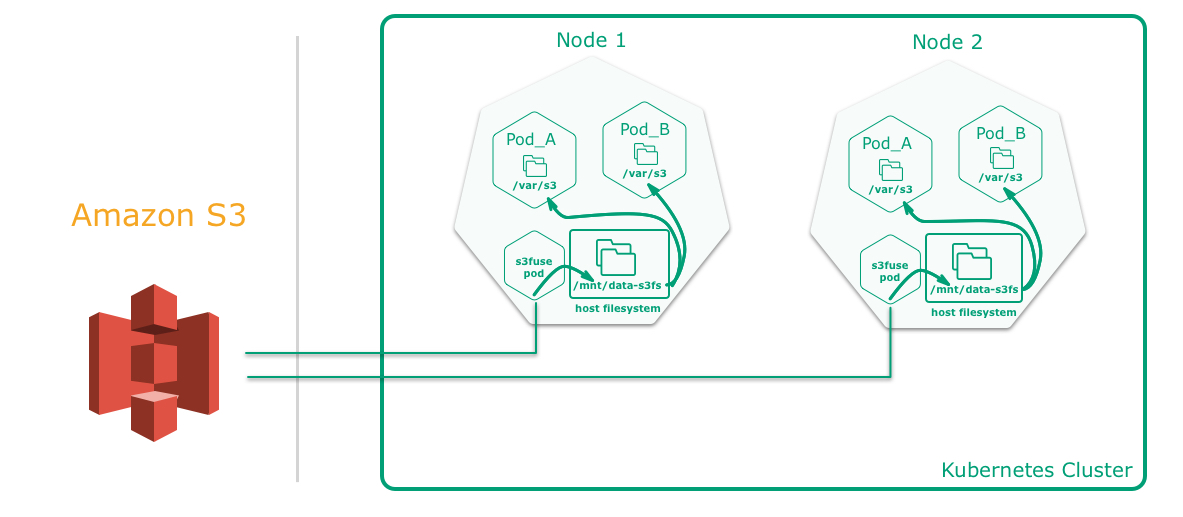
這裡為每個啟動的Zeppelin Server及其建立的計算pod掛載統一的分散式儲存,透過subpath引數為每個使用者建立不同的子目錄解決使用者資料隔離的問題。不同使用者掛載到容器中就是同一個網路儲存不同的子目錄。這裡面的實現一個是利用K8S DaemonSet 這樣每個k8S的計算節點中會執行一個pod用來,POD中採用s3fs對物件儲存進行掛載,該Pod會把宿主機中的目錄掛載到容器中,掛載程式把物件儲存掛到當前目錄,這樣宿主機就有了對應物件儲存的檔案目錄結構,這樣zeppelin執行啟動的計算pod都去掛載宿主機的這個目錄,就可以達到多POD檔案共享及資料持久化的功效。
Notebook任務驅動
為了滿足使用者對週期性外部驅動分析訓練的需求,同步了notebook指令碼到notebook管理平臺,可以對單獨的notebook指令碼 配置一個計算驅動任務,定時任務可以在k8s中繫結一個cronjob到了預定時間去啟動任務呼叫Zeppelin server的介面排程執行對應的notebook指令碼,外部驅動任務透過管理平臺暴露任務建立API,可以供其它第三方平臺透過api呼叫去啟動notebook服務,這樣就給notebook插上了定時排程和外部驅動的翅膀。
模型線上推理
AI整個流程中,模型線上推理是AI應用的最後一環,模型比較小的情況下可以直接嵌入到後端業務程式碼中,作為一個常見的介面對外提供服務,但是隨著模型越來越大、模型更新越來越頻繁,有必要對模型服務進行獨立拆分,獨立的對模型進行更新和釋出,模型訓練框架眾多、模型格式多樣以及線上服務對服務穩定性要求高、對服務延遲比較敏感,但總的來說大部分模型的模型管理、模型部署、服務的更新具有通用性,具體的不同在於可以借鑑底層映象進行區別的處理。因此有一個通用的模型部署管理平臺能夠避免業務在應用模型推理時所帶來的重複性建設,大大加快模型服務的落地。為公司AI應用能夠大量落地,大資料智慧平臺組開發了統一的模型線上服務平臺。一線網際網路企業主要是基於雲原生、服務網格去打造統一的模型線上推理平臺,因此智慧平臺組也同樣是基於雲原生K8S去實現基礎設施到服務監控告警鏈路的整個流程的建設。
整體框架

模型管理
模型管理主要是針對外部訓練模型提供模型上傳、模型註冊、模型版本管理等對模型進行增刪改的管理功能,針對線下大模型模型註冊線下提供一個GO開發的二進位制工具,讓使用者可以按照工具提示上傳模型到工具中封裝的OSS統一目錄中,後續使用者可以複製工具生成的模型路徑註冊模型到模型管理平臺,平臺對模型格式進行校驗,避免無效的模型註冊。
模型服務
模型服務主要是把靜態的模型部署成線上服務,使用者在模型服務平臺中可以選擇模型倉庫對應的模型版本、設定模型執行的例項個數,選擇是否開啟HPA自動擴縮容。模型部署具體實現是透過構建K8S deployment物件模版,其中的Pod 包含三個容器接耦了三塊功能,這三個容器分別是初始化容器去實現oss模型檔案掛載、接入服務用來埋點指標收集 java 網路代理、TfServing推理框架的封裝,實現模型的複製、服務監控指標的收集、推理載入線上服務。透過平臺部署的每個模型服務,在K8S中會建立一個型別為LB的Service,服務部署平臺會獲取LB的地址拼接成服務url暴露給服務使用方。對於部署的服務,透過個性化網路代理埋點服務狀態、服務請求qps、服務耗時的指標資訊,共同匯聚到公司統一的監控系統,監控系統可以透過服務ID等資訊查詢各個模型服務的執行狀況。
總結
以上簡單的介紹了K8S在貨拉拉大資料領域的應用與實踐,對於一個AI平臺來說雲原生容器化應該是業界標配,尤其是在面對機器學習、深度學習、分散式訓練、GPU算力管理調配這種複雜的場景。大資料智慧平臺專案組前期透過自建華為雲環境K8S叢集,到針對線上服務的阿里雲場景,採用阿里雲ACK K8S叢集,雙叢集跨雲使用。
雲原生AI機器學習系統的設計到實現涉及大資料、雲原生、AI三個交叉領域的知識和技能體系,構建一個一站式的完善的機器學習平臺需要演算法、工程、基礎架構的合力,目前貨拉拉大資料雲原生機器學習平臺只是覆蓋AI的機器學習的鏈路,一些基礎能力還不支援,比如說分散式機器學習、GPU分散式訓練、GPU分散式推理,相比於投入資源構建系統,賦能業務才是最重要的,打造強大的系統,最終賦能業務可以說任重而道遠。
來自 “ 貨拉拉技術 ”, 原文作者:大資料技術團隊;原文連結:http://server.it168.com/a2023/0323/6795/000006795619.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 貨拉拉自助資料分析平臺實踐
- 基於 Kubernetes 的雲原生 AI 平臺建設AI
- PAI:一站式雲原生AI平臺AI
- 中原銀行 AI 平臺建設實踐AI
- [平臺建設] HBase平臺建設實踐
- 貨拉拉技術穩定性體系1.0建設實踐
- AI雲平臺建設意義AI
- 車路協同雲控平臺建設實踐
- 貨拉拉大資料離線混合引擎服務建設實踐大資料
- 阿里雲 PB 級 Kubernetes 日誌平臺建設實踐阿里
- 國家質量基礎設施一站式服務平臺建設,NQI雲平臺建設
- 貨拉拉王海華:大資料安全體系建設實踐和思考大資料
- 公有云上構建雲原生 AI 平臺的探索與實踐 - GOTC 技術論壇分享回顧AIGo
- vivo 實時計算平臺建設實踐
- 一文讀懂得物雲原生AI平臺--KubeAI的落地實踐過程AI
- 高德Serverless平臺建設及實踐Server
- 高德 Serverless 平臺建設及實踐Server
- 擺脫 AI 生產“小作坊”:如何基於 Kubernetes 構建雲原生 AI 平臺AI
- AI雲平臺怎麼構建AI
- vivo AI 計算平臺的 ACK 混合雲實踐AI
- 網易數帆雲原生日誌平臺架構實踐架構
- 雲音樂輿情平臺建設雲音樂輿情平臺建設
- 將軍令:資料安全平臺建設實踐
- 宜信智慧監控平臺建設實踐|分享實錄
- 質量基礎設施一站式NQI雲平臺系統建設方案
- 國家質量基礎設施(NQI)一站式服務平臺,NQI雲服務平臺建設
- 海大集團的可觀測平臺建設實踐
- 將雲原生進行到底:騰訊百萬級別容器雲平臺實踐揭秘
- 流批一體的實時特徵工程平臺建設實踐特徵工程
- Aggregated APIServer 構建雲原生應用最佳實踐APIServer
- 如何降低 Flink 開發和運維成本?阿里雲實時計算平臺建設實踐運維阿里
- 揭秘貨拉拉大模型應用平臺的應用部署大模型
- 宜信微服務任務排程平臺建設實踐微服務
- 微眾銀行-訊息服務平臺建設實踐
- 實用教程 | 雲原生安全平臺 NeuVector 部署
- 融雲 IM 在 Electron 平臺上的設計實踐
- 銀行基於雲原生架構的 DevOps 建設實踐經驗架構dev
- 青團社:億級靈活用工平臺的雲原生架構實踐架構