貨拉拉技術穩定性體系1.0建設實踐
一、前言
貨拉拉是大家耳熟能詳的網際網路物流公司,致力於為個人、商戶及企業提供高效的物流解決方案,讓貨物出行更輕鬆。
截至2022年12月,貨拉拉業務範圍已覆蓋360座中國內地城市,月活司機達68萬+,月活使用者達950萬+。
這些數字不僅說明貨拉拉業務規模已十分龐大,更多地表明我們在承擔著一份非常重要的社會責任。而穩定性正是我們履行好這份社會責任的必要因素。
二、背景與挑戰
技術穩定性即系統平穩連續執行的能力,通常採用MTBF/(MTBF+MTTR)來定義,結果越趨於1說明系統越穩定:

其中MTBF即MeanTimeBetweenFailure,指系統連續無故障的時間;MTTR即MeanTimetoRecover,指系統發生故障到恢復的時間。
通俗來說,穩定性期望我們系統的故障率越低越好,處理問題的時長越短越好。同時站在全域性的視角下,穩定性工作還需要充分考量與成本、效率之間的平衡關係,否則只靠堆疊機器、禁止變更就可以大大提升系統穩定性。
基礎原理比較容易理解,但涉及到落地階段就會發現,穩定性工作極具挑戰性,主要體現在以下三點:
組織
穩定性工作與系統生命週期緊密相關,涉及到系統生命週期的每一個環節,也因此關係到參與其中的開發、測試、運維乃至產品、運營、客服等各個角色。
貨拉拉的技術團隊規模已遠超千人,如何在龐大的組織中透過跨團隊溝通協同的方式取得良好工作成效是穩定性建設過程中最常面臨的挑戰。
VUCA
當今網際網路系統具備典型的烏卡(VUCA)特性,即易變性(Volatility)、不確定性(Uncertainty)、複雜性(Complexity)和模糊性(Ambiguity)。

貨拉拉的系統也是如此。空間上存在3000+應用服務、錯綜的依賴呼叫關係;時間上伴隨著各種系統重構、架構改造,使得系統健壯性難以維繫,脆弱易腐化是常態。而複雜易變的系統又帶來高昂的認知成本,進而導致其中風險難以被快速發現和處理,對系統穩定性造成極大威脅。
木桶效應
幾乎所有系統執行以來都發生過問題,而造成這些線上問題的原因也是多種多樣的,比如技術架構缺陷、外部依賴故障、人為操作失誤等等,甚至還可能是因為惡意破壞。
所以穩定性工作必須要考慮到方方面面,不僅僅包含技術,還需要把控人員的穩定性意識和技能,團隊的管理,以及明確各種流程規範制度標準,因為任何地方出現短板都可能造成全域性癱瘓,導致公司業務和使用者體驗受損。
貨拉拉的技術穩定性體系建設也是圍繞上述痛點進行了重點攻堅。
三、過程回顧
下面我將對貨拉拉技術穩定性體系建設的思路歷程和實戰經驗進行回顧,希望能對大家的工作有所幫助。
團隊搭建
術業有專攻,穩定性工作是專業的事,需要有專業的人來做。
21年之前,貨拉拉已初步完成穩定性虛擬小組的搭建,主要負責處理各種穩定性相關的任務,不至於讓穩定性成為無人管轄的蠻荒之地。但虛擬小組裡始終缺少專業專職穩定性技術角色,導致貨拉拉的穩定性難以以體系化的形式向前發展,落地效果得不到保障,各類問題層出不窮,最終導致業務穩定性結果一直不甚樂觀。
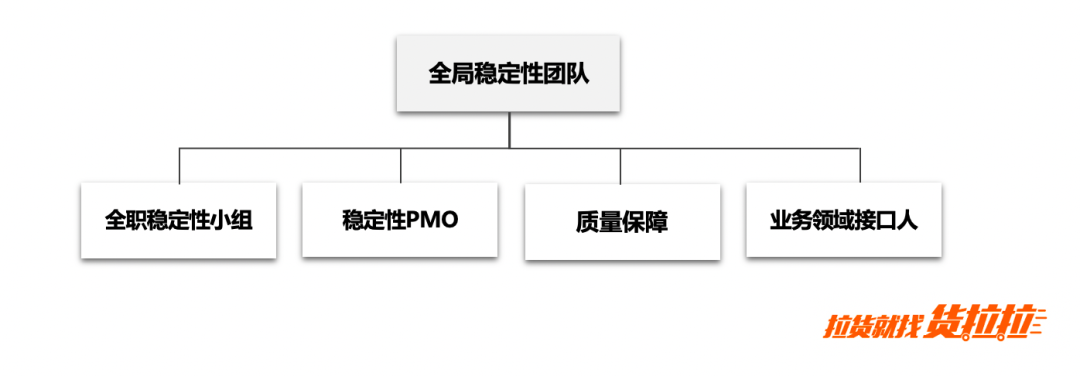
21年中期,貨拉拉全職穩定性小組成立,負責全域性技術穩定性體系的設計、搭建及演進,把控公司穩定性建設的主要方向和核心價值,補齊了全域性穩定性團隊的最後一塊拼圖。
全域性穩定性團隊搭建完成後,我們迅速明確了各成員的職責,使得團隊可以更好地發揮合力的作用。
認知提升
認識世界是改造世界的必要前提。穩定性工作也是如此,想要提升業務的穩定性,先要提升對業務和系統的認知水平。
將一家公司的業務流程、系統架構、呼叫鏈路梳理清楚是一件極其耗費精力的事,其難點主要在資訊的複雜性和零散性。貨拉拉光業務種類就非常多,包括同城/跨城貨運、企業版物流服務、搬家、零擔、汽車租售及車後市場服務。
穩定性的前期工作要特別注意短時間週期內的ROI,因為隨著時間的推移,風險演變為故障的機率會越來越大。
基於此,我們決定先從體量最大業務的核心功能點著手梳理,具體過程如下:
明確業務核心功能點,如使用者下單、司機搶單等;
梳理業務功能點對應的系統入口服務及介面,比如使用者登入對應為A服務下的userLogin介面;
依據入口介面遞迴出所有下游依賴的服務介面,生成呼叫鏈路,並整理出關聯服務集合及特徵資訊。
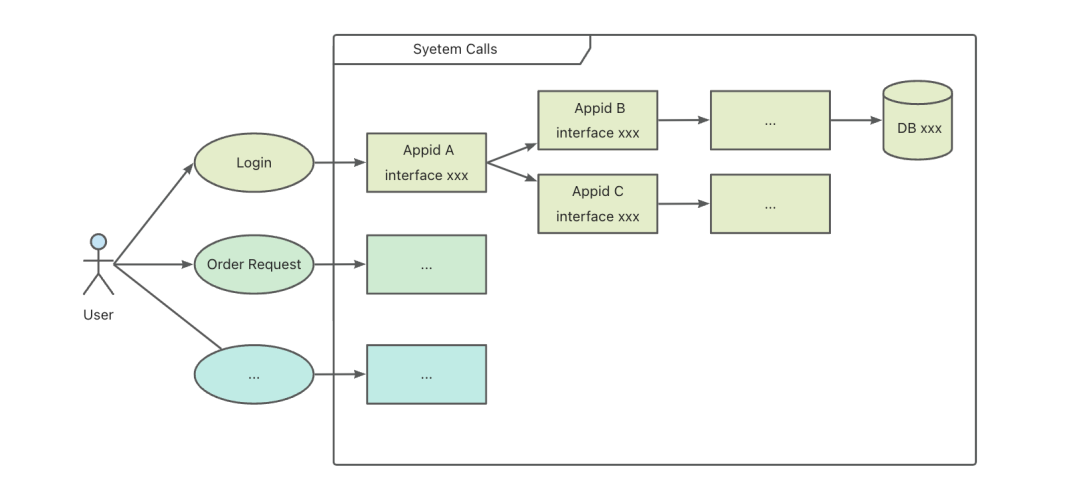
最終在各領域架構師、研發、測試等人員的共同努力下,我們在貨拉拉梳理出一份核心業務功能點及呼叫鏈路資訊庫,為後續治理提供了有效的認知基礎,幫助穩定性工作在前期能夠快速取得成效,比如在進行監控告警覆蓋治理中,會對核心鏈路相關的服務提出更嚴格的結果質量和治理時效要求。
韌性治理
鏈路梳理提升了我們對業務系統的認知能力,同時也幫助我們發現了系統中存在的諸多問題。
比如最常見的超時時間配置過長,還有重試、冪等、限流、強弱依賴等等設計,都存在一些不合理的情況。這些不合理導致我們的系統缺乏足夠的健壯性,尤其是在遇到一些突發狀況時。21年貨拉拉就僅僅因為一個雲上的分鐘級網路抖動異常,導致訂單跌底無法快速自愈,而原因就是核心服務Redis超時時間配置不合理引發的一系列系統崩潰。
所以緊跟著鏈路梳理,我們開展了對核心鏈路的風險治理,具體步驟如下:
依託各方面專家經驗,給出風險治理模型,並拉齊各領域架構師對風險治理模型進行商討確認;
依據風險治理模型對核心鏈路的每個呼叫環節開展集中評審,輸出不滿足標準的待改造項;
針對待改造項進行排期追蹤,並對已完成的改造項進行驗收,確保改進落實完成。
經過這次集中治理,我們發現並治理了近200項線上風險,系統韌性得到可觀提升。
值得注意的是,韌性治理並非能夠一勞永逸,因為隨著時間推移,新的風險會被再次引入,需要依靠標準化流程化的架構評審和自動化的風險掃描建立起韌性治理的長效機制。
故障應急
《Google SRE》中有這樣一句話:系統正常,只是該系統無數異常情況下的一種特例。相信大家一定深有體會。
核心鏈路的韌性治理只是幫助我們減小了故障發生的機率,還遠達不到杜絕故障發生。
事實上,沒有任何辦法能夠杜絕故障發生,故障必然發生是客觀事實規律。在時間的不斷流逝中,硬體一定會損壞,軟體一定會有Bug,人也一定會犯錯,而且不止一次。
所以做穩定性工作就要有故障隨時會發生的覺悟,並且要以良好的心態去接納故障的發生。
除了要培養良好的心態,我們還對以下幾點進行了重點建設:
快速恢復
故障應急的第一原則是快速恢復,因為故障每多持續一秒,都會有更多的使用者受到影響,更多的公司利益遭受損失,嚴重情況下還有可能發展成社會級別惡性事件。
結合應急響應生命週期分析可以發現,快速恢復的關鍵點主要在故障發現、應急組織、初因分析、恢復執行,以此思路我們分別做了以下事項:
1)故障發現:根據核心業務梳理建設相關監控看板及告警;
2)應急組織:應急人員模組化管理、應急群一鍵拉起、指揮官機制統籌應急秩序;
3)初因分析:變更關聯、應用健康狀態自動分析;
4)恢復執行:快恢SOP沉澱、應急預案梳理。
經驗吸取
故障最大的價值就是帶給了我們寶貴的經驗教訓,避免相似問題再次發生或再次造成不可接受的影響是故障恢復後的關鍵任務。
在貨拉拉,我們主要依靠事後覆盤、改進事項追蹤和週期性故障回顧三個機制來確保故障價值在短中長期都能得到充分發揮。
變更管控
變更是極大的風險引入渠道,變更的前置准入已經有CR、QA、灰度等層層關卡把守,於是我們重點圍繞異常變更發生後如何減小影響和如何快速恢復做了以下建設:
1)依據貨拉拉訂單量級的時間分佈定義變更視窗並加以嚴格管控,禁止視窗期外尤其是業務高峰期的變更,並規範緊急變更流程規範。一個異常變更發生在業務高峰期和低峰期的影響面差異是非常巨大的;
2)收口各渠道的變更記錄,做到異常發生第一時間自動查詢近期變更資訊,以便快速定位和引導回滾,這個能力極大地幫我們減少了問題恢復時長。
防微杜漸
海恩法則指出:每一起嚴重事故的背後,必然有29次輕微事故和300起未遂先兆以及1000起事故隱患。這啟示我們不僅要著眼於故障的處置,還要關注日常的細小問題,每一個細小問題的背後都可能在醞釀著一個重大故障。
基於海恩法則的金字塔模型,我們建設起了風險隱患機制,針對線上的每一個異常事件啟動應急追蹤,確保問題能夠快速恢復,阻止事件惡化,並在事後開展覆盤,將故障扼殺在搖籃裡。

以演促防
疫苗透過主動注入減毒滅活細菌病毒的方式幫助人體免疫系統積累抵抗記憶和保護物質,我們的系統也需要經常透過演練的方式來幫助相關人員加強應急意識、熟悉應急流程、檢驗應急手段,甚至透過混沌工程無差別攻擊的手段,主動暴露系統中存在的問題。
貨拉拉也在此理解基礎上建立起演練相關的機制和工具:
1)應急響應演練:透過一站式應急響應平臺拉起線上事件,檢驗工具流程可靠性,考察人員響應質量,加強研發應急響應意識;
2)預案演練:依託預案平臺提前梳理線上應急預案,並針對預案開展演練,以檢驗預案執行決策邏輯合理性,並觀察預案執行效果是否符合預期;
3)故障注入演練:透過故障演練平臺實現生產環境真實異常注入,並以此開展故障演練檢驗系統健壯性,或開展攻防演練鍛鍊研發應急處理能力、檢驗告警規則有效性、暴露當前系統或機制中可能存在的問題;
4)災備演練:檢驗公司面對災難級事件時的資料及系統恢復能力,確保公司系統不會遭受毀滅性打擊。
文化建設
穩定性從來都不是幾個人的事情,而是整個公司的事情。提高所有人員的穩定性意識和技能,是穩定性建設的重中之重,也是一家公司能在穩定性方面一直保持優秀狀態的基礎。
所以穩定性文化建設在貨拉拉也是一門必修課,主要分為了以下幾個階段進行開展:
第一階段,我們邀請在穩定性方面能力優越的人開展分享或培訓,幫助公司其他同事加深對穩定性的印象和理解;
第二階段,我們藉助所有技術專家的力量,依靠Design for failure的系統設計理念,從設計規約、編碼保護、資訊保安、變更操作、工具使用、應急排錯幾個角度闡述了設計原則和優秀實踐;整理完成後我們將內容印製成冊,供所有技術人員日常學習,並開展考試檢驗掌握情況;
第三階段,我們試圖讓穩定性變得更具趣味性一些,於是策劃開展了穩定性文化月活動,透過遊戲、互動的方式,讓大家在學習到穩定性知識點的同時還能收穫有趣實用的精美禮品。

四、實戰演練
經過上述介紹,大家應該對穩定性工作或多或少有了更多瞭解,那麼假如現在你到了一家新公司負責穩定性建設工作,面對新業務新系統新同事,該如何開展具體工作呢。
圍繞應急響應
首先,短期工作一定要圍繞應急響應出發。在穩定性建設的初期,各個環節存在各種漏洞,是線上問題頻發的階段,如何快速發現問題,快速組織人員應急,一定程度上決定著問題恢復的速度。用最快的時間梳理好公司核心業務指標,配置監控大盤和告警,明確應急拉群通告機制,確保能夠以最快的速度發現問題並進入戰鬥狀態。
深挖系統問題
應急響應基礎打牢之後,結合穩定性定義,下一步要考慮如何避免問題發生機率,建立起系統穩定性保護屏障。行之有效的手段是對關鍵業務下的系統鏈路進行梳理和治理,幫助我們認識到當前系統狀態,發現短板解決短板,達到提升系統健壯性的目的。
持續運營演進
解決兩大核心問題之後,要把重點放在如何一勞永逸地解決穩定性問題這個目標上。透過集中治理改造,系統穩定性會在短期內得到提升,但隨著時間推移,內部在變化,外部也在變化,人員在變化,穩定性資源投入也在變化,如何保障好的結果不遭受意外,如何讓我們在最壞的情況下(如黑天鵝事件)還能有兜底措施,是需要花大量時間思考和建設的事,這個命題即為技術穩定性體系運營。明確穩定性各領域執行機制,各角色職責,並透過資料指標進行度量,確保系統穩定性處於一個健康的狀態。
經過以上三個階段,這家公司的技術穩定性將會揚帆起航,幫助公司在征服星辰大海的道路上越走越遠。
五、總結與展望
相信大家在工作中也遇到過不是很重視穩定性的技術人員,覺得自己的本職工作只是應對業務需求寫寫程式碼,穩定性是額外的事,如果不是領導安排,是不會主動做的。這種想法一方面是沒有深刻領會到Owner意識,另一方面也給自己的職業發展套上了枷鎖。
還有一些技術人員認為穩定性工作不過是配配監控告警,日常值班處理一下線上問題,並且疲於很多穩定性治理專案,最後應付應付草草了事。這一方面是工作態度問題,一方面也側面反映出穩定性工作的體感確實有待提升。
業內穩定性領域發展至今還算不上很成熟,沒有很多公開的系統化的方案來指導穩定性建設工作,而且很多公司的穩定性建設需要因地制宜,生搬硬套往往得不到好的效果。
貨拉拉的技術穩定性體系建設也經歷了重重坎坷,1.0體系初具成效最大的功勞在所有參與者共同努力,穩定性做得好一定是合力的結果。
未來,貨拉拉技術穩定性建設會在當前“保無故障”的基礎上繼續朝著“減負”和“智慧化”兩個方向演進:透過更強的工具自動化能力,提高穩定性工作效率,減輕穩定性工作負擔;透過專家經驗沉澱和AI能力的引入,提高穩定性工作的質量,降低故障帶來的影響,幫助貨拉拉更好地提升使用者體驗、履行社會責任。
來自 “ 貨拉拉技術 ”, 原文作者:CI團隊-李全;原文連結:http://server.it168.com/a2023/0407/6797/000006797943.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 貨拉拉王海華:大資料安全體系建設實踐和思考大資料
- 【穩定性】穩定性建設之依賴設計
- 前端監控穩定性資料分析實踐 | 得物技術前端
- 前端監控穩定性資料分析實踐|得物技術前端
- 多利熊基於分散式架構實踐穩定性建設分散式架構
- 螞蟻集團TRaaS技術風險防控平臺入選中國信通院《資訊系統穩定性保障能力建設指南(1.0)》最佳實踐案例
- 貨拉拉大資料離線混合引擎服務建設實踐大資料
- 貨拉拉一站式雲原生AI平臺建設實踐AI
- 雙11在即,分享一些穩定性保障技術乾貨
- 剖析多利熊業務如何基於分散式架構實踐穩定性建設分散式架構
- 下單穩定性治理 | 得物技術
- AI驅動的京東端到端補貨技術建設實踐AI
- 蘑菇街SRE體系建設實踐
- 大型微服務架構穩定性建設策略微服務架構
- 貨拉拉自助資料分析平臺實踐
- 架構-穩定性建設邏輯問題實戰總結架構
- 火山引擎DataLeap資料血緣技術建設實踐
- 螞蟻集團TRaaS入選中國信通院《資訊系統穩定性保障能力建設指南》最佳實踐案例
- 從預防、應急、覆盤全流程詳談系統穩定性建設
- 技術乾貨 | Flutter線上程式設計實踐總結Flutter程式設計
- vivo 服務端監控體系建設實踐服務端
- 貨拉拉國際化測試之深度學習實踐深度學習
- 有數BI大規模報告穩定性保障實踐
- Apache Flink 在小米的穩定性最佳化和實踐Apache
- 【穩定性】從專案風險管理角度探討系統穩定性
- 貨拉拉貨運iOS使用者端架構最佳化實踐iOS架構
- 穩定性
- 淺談系統的不確定性與穩定性
- 地圖POI類別標籤體系建設實踐地圖
- 滴滴資料倉儲指標體系建設實踐指標
- 基於Kubernetes的Serverless PaaS穩定性建設萬字總結Server
- 貨拉拉利用時空熵平衡提升營銷效率的實踐熵
- 貨拉拉服務化實踐-為啥都愛“造輪子”?
- “資料+技術”助力雲原生智慧運維體系建設運維
- 如何保障系統穩定性並實現綠色減排?螞蟻集團有這些關鍵技術
- 螞蟻微貸互動營銷技術體系實踐
- 這是阿里技術專家對 SRE 和穩定性保障的理解阿里
- 混沌工程:系統穩定性的 “疫苗”