從預防、應急、覆盤全流程詳談系統穩定性建設
前言
安全是產品的底座,是體驗的基礎,也是企業的一項核心競爭力。安全生產是一項系統性的工作,同時也是一件比較瑣碎的事,需要做方方面面的考慮盡一切可能保障系統安全穩定執行。個人之前一直負責商品的穩定性工作,在這方面有比較多的經歷和實踐。
記得在18年的時候,我們做商品釋出的元件化改造,當時正好碰上網站剛開始類目調整,一度連續3個月每個月都有故障,當時穩定性的壓力很大。當然那也是一個契機,商品的穩定性建設也是從那個時候開始起步,然後逐步的完善。
大綱
安全生產建設大致上可以分為這三個階段:
事前:故障預防,這裡需要考慮的就是怎麼透過預先的設計,最大限度的保證質量,降低風險,提升穩定性。
事中:應急處置,出了問題以後怎麼處理,快恢手段有哪些,流程是什麼。
事後:覆盤改進,事後肯定要總結經驗,舉一反三解決同類的問題,不要被同一棵石頭絆倒兩次。
一、故障預防
魏文王問扁鵲:你醫術為啥這麼好?
扁鵲說:我醫術在我三兄弟裡面算差的。最好的是我大哥,還沒有任何症狀就撲滅了,次好是我二哥,一點點輕微的症狀就解決了。再次就是我,出了嚴重的問題我才開始醫治,所以雖然我名滿天下,但是我醫術可比我的大哥二哥差得遠啦。
做個類比,故障預防做的好的就是大哥,應急處置做的好的就是二哥,總結覆盤做的好的就只能是扁鵲了。所以預防生產事故的發生是最重要的,也是最基礎的。
1、架構設計
單個技術點在絕大部分時候都可以正常工作,但是當規模和複雜度達到一定程度的時候,失敗其實無處不在。--《安全生產指南》
面向失敗設計是應對安全生產最重要的方法論和指導方針。只有對各種失敗場景有提前的佈防才可以在出問題的時候有效應對。那麼面向失敗設計具體有哪些方式方法?
1)冗餘設計避免單點
冗餘最早是航空器常用的技術術語,飛機設計最顯著的一個特點就是冗餘,比如一般大型客機都會有兩套甚至四套引擎,類似的還有兩套基本同質的主副駕駛系統。為什麼要這麼設計,還有額外的成本,根本原因還是因為冗餘設計可以在一套出現問題時另一套依然能保障系統正常執行。
在ICBU的場景中中美新容災就是我們最主要的冗餘設計,也是穩定性保障最核心的手段。商品是ICBU內第一個構建起中美異地容災能力的業務場景,也正是因為有了這個能力幫助商品避免了不少的故障發生。
2)服務分治避免雪崩
其實就是做好隔離。中國古代的木船設計有一個很重要的發明叫“水密隔艙”,現在很多軍用艦船也有借鑑。典型的像航空母艦據說有2000多個獨立的密閉隔倉,作用就是當船舶遭遇意外或者破損進水時,可以透過隔離受損艙室減緩下沉。它是一種安全生產的設計,對我們有借鑑意義,系統要做模組化的設計、薄弱點或者風險點可以被單獨隔離和降級,保障整體可用性。
我們之前發生過一次問題,因為ES叢集中一臺物理機故障導致上層應用的執行緒池被耗盡從而引起服務不可用,根本原因就是隔離沒有做好。

3)服務冪等保證一致
服務或介面應該保證冪等,多次呼叫和一次呼叫結果應該是一致的,避免重複呼叫導致資料或邏輯異常。

4)服務無狀態可漂移
服務或介面最好設計成無狀態模式,從擴充套件性的角度來講,無狀態模式可以很容易的根據流量情況彈性伸縮。
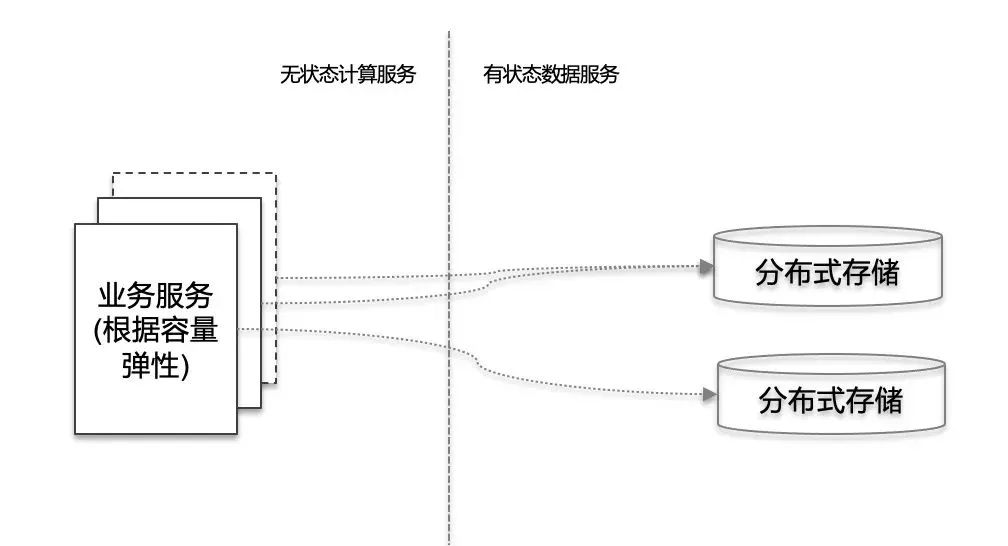
5)執行狀態精確監控
把我們的應用系統比做飛機,我們的系統也需要各種感測器和儀表盤去實時監控系統執行狀態,系統對於運維人員來說應該是個白盒而不是黑盒。核心的業務或者系統監控有助於提前發現問題,細粒度、多維度的監控有助於快速定位問題。
6)自動化運維管控
最好的處理是不需要處理。
核心思路是一切操作標準化、流程化、自動化,降低人為干預、提升操作效率。像商品釋出/商品管理都有一些自動容災預案,可以在出現問題時自動快恢。下面的案例是週末出現的一次風險預警就是透過自動執行快恢避免了線上故障的發生。

另外今年旺鋪的一次風險預警,在出現容量效能問題的時候也是透過自動彈性擴容快速解決了問題。
2、編碼開發
1)併發控制
在服務能力受限的情況下,我們需要主動控制客戶端併發數。特別是任務型場景,通常有靜態限流和動態限流兩種選擇。
靜態限流比較簡單但有一個侷限就是資源利用率不高。動態限流的原理是根據服務端的響應情況動態調整客戶端速率,簡單來講就是計算服務超時/異常的數量,超時多了請求就放慢一點。
2)資料控制
資料是資訊系統中的血液,透過資料的流動才能將一個個業務或功能模組串聯在一起。一方面是資料的生產要嚴格校驗保證資料的合法性和準確性。另一方面是資料的消費,需要評估單次處理的資料量、資料處理頻次,不要因為高併發、海量資料導致系統記憶體、負載承壓。商品曾經因為這個經歷過最慘痛的教訓:

3)防禦程式設計
批次容錯
比如一個列表肯定不能因為某一行有問題而導致整個列表出不來。同樣的同步任務也不能因為某一個任務異常而堵塞整個任務佇列。所以需要對這些場景做好容錯處理,其實還是在強調隔離風險。像商品的引擎同步任務、質量分計算任務都有獨立的線上實時佇列、實時重試佇列、離線佇列,目的就是為了不影響實時增量任務的正常執行。
資料相容
另外有些存量業務,可能已經積累了很多的歷史資料。拿商品來舉例,今天我們的認知裡moq就是最小起訂量肯定是數字,包裝重量肯定也是數字,但其實之前商品的部分屬性是可以自定義的,有些可能是使用者隨便填的,所以在功能升級迭代的過程中需要考慮對歷史資料的相容。
4)簡化程式碼
越簡單東西的越可靠,越複雜的東西容錯性越低。把簡單的事情想複雜,把複雜的事情做簡單。
少用同步鎖:系統設計和編碼儘量使用無鎖實現,避免引起不必要的死鎖問題。商品同樣因為同步鎖的原因出現過線上問題:

慎用執行緒池:其實跟同步鎖類似,它是一個比較危險的操作,要做好測試和驗證。
3、容災防護
1)過載保護
過載保護是保障系統整體可用的重要手段之一,設計過載保護可以有效避免因為流量問題導致的系統不可用。所以我們的應用要具備自我防護的能力,web型應用接入流量清洗系統,服務型應用做好服務限流。
2)依賴降級
當前大部分的業務系統都比較複雜,特別是在分散式架構中,一個請求可能依賴多個系統支撐共同完成。呼叫鏈路中的任何一個節點都可能影響整體穩定性。所以一方面我們要保證自身服務的穩定性,另外一方面也要考慮在依賴服務出現問題後怎麼保證主鏈路的可用。而依賴降級的前提是先理清依賴關係:
弱依賴就自動降級比如校驗類的。
有一些是強依賴但可以非同步處理的就降級後非同步重試。
有一些是強依賴又不能非同步的,就需要產品化了,把降級能力作為產品設計的一部分。
下圖是商品釋出鏈路的部分容災降級點:
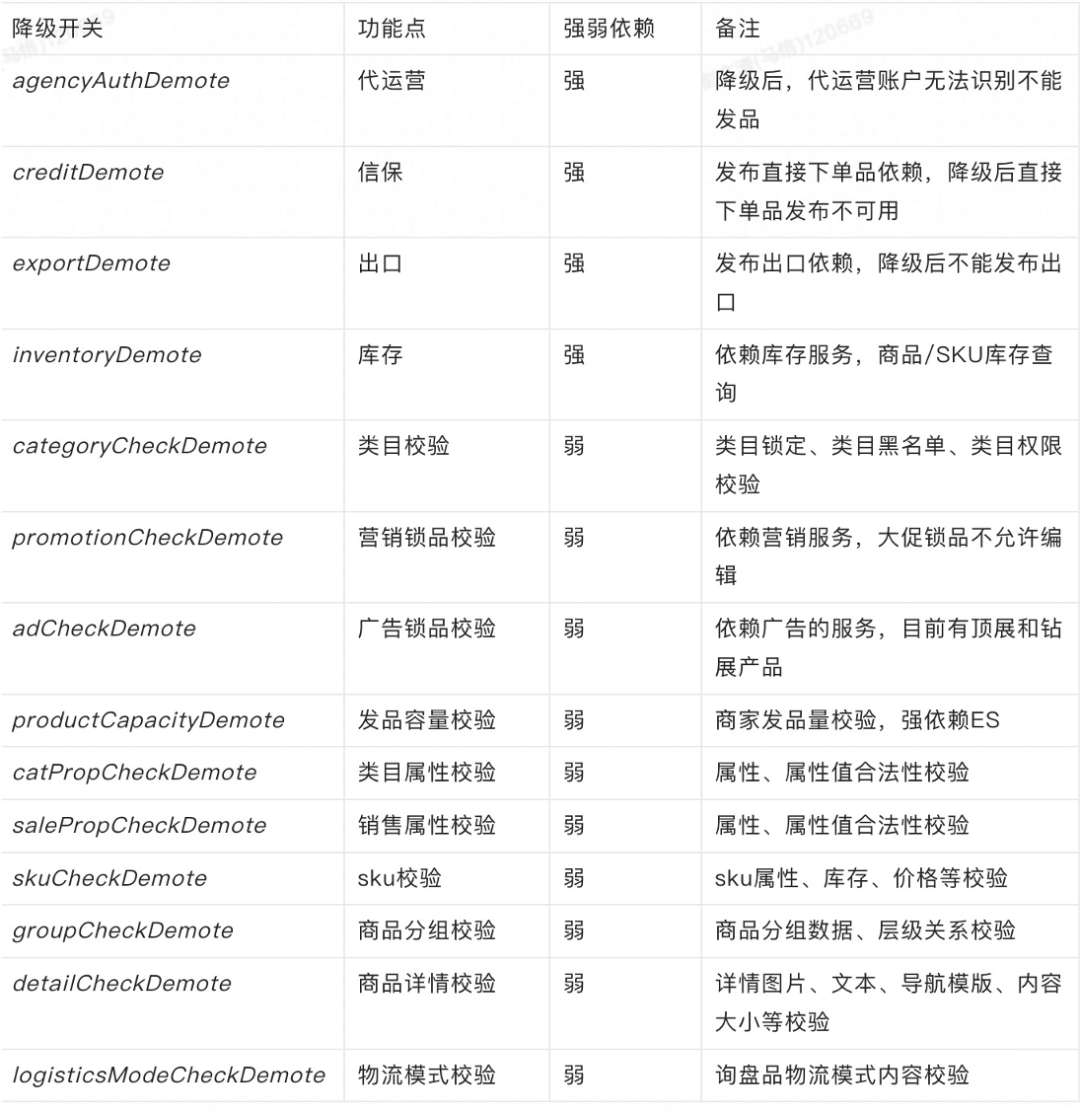
這其中超過95%都從來沒有使用過。安全生產的建設就是這樣,很多穩定性保障措施大部分時候都默默無聞,但是真正使用到的時候卻都是關鍵的時刻。
4、監控預警
1)監控標準化
一堆無意義的"System Error"無濟於事,標準錯誤碼和SPM監控是當前比較好的一個實踐。
2)預警有效性
召回優先
預警有效性其實比較難做,監控覆蓋度越廣,預警機制越靈敏,報警量可能就會越多,誤報也會越多。商品無人值守樣板間在開始時候也是召回優先,誤報慢慢收斂,這是一個持續治理的過程。
報警分層
另外可以根據監控場景對報警分層, 透過報警分層一定程度上可以兼顧召回和免打擾。重要的業務系統監控推送到核心預警群,非故障場景或者輔助定位的監控報警可以推送到其他普通預警群。同樣也需要對報警通知方式做分層,比如成本率下跌2%可能是釘釘通知,下跌5%就需要電話通知。
5、測試迴歸
測試迴歸是質量保障很重要的一個環節。
1)單元測試
單測我相信有人會懷疑它的價值,而且在剛開始的時候的確比較耗費時間精力,但是它是一個難而正確的事情,這裡分享兩點:
單測是程式碼的照妖鏡,我們會發現通常單測很難跑起來的往往就是程式碼設計不合理,耦合過多,單測可以幫助自己最佳化程式碼。
單測是質量的保證。前端時間跟我對接的前端同學突然跟我說,“文清,沒想到這次專案這麼順利”,這個專案也是我個人第一次在一個專案裡寫完整的單測程式碼。從我個人的實踐經歷來看,單測特別是對於喜歡重構的人來說還是非常有價值的。
2)巡檢/流量回放
我們當前的業務大部分都比較複雜,有非常多的分支流程。舉個例子商品有5000多個葉子類目,每個類目的商品表單是不一樣的,這麼多的場景靠人肉是根本覆蓋不了的,只能靠機器和自動化去迴歸。前臺頁面場景巡檢是一個比較好的方式,它可以模擬使用者操作。對於後臺服務流量回放也是一種可行的方案,商品無人值守樣板間也在使用巡檢和流量回放來保障釋出質量。
3)壓測
新的服務上線前需要評估流量和效能情況,根據預估對服務進行壓測以驗證是否能夠滿足需求。同時整個鏈路能夠支撐的QPS上限也需要透過壓測確定,幫助我們合理的評估系統水位。
6、變更釋出
回過頭去分析會發現其實我們大部分問題都是變更引入的。商家技術部三規九條裡有規定變更釋出三原則 “可灰度、可監控、可回滾”。釋出之前要做好釋出計劃和評審,檢查是否滿足這三個要素。
灰度分為功能灰度和釋出灰度,功能灰度可以根據自己的團隊情況設計。釋出灰度首先從流程上建議增加小流量灰度環境,部分流量可以劫持到小流量環境,一些重大的問題可以在小流量環境提前發現。另外有條件的應用也建議分單元/分割槽域分開部署,短時間內模擬藍綠部署,為容災切流創造條件。
對於回滾,切記要做回滾驗證,不要一股腦不暫停回滾完。因為之前碰到過一個案例,越回滾問題越嚴重,原因是當時的問題是遠端快取異常導致應用啟動後出現資料異常,回滾重啟後又導致已釋出機器本地快取失效放大了影響面。
二、應急處置
故障預防是降低問題發生的機率,不是消滅問題。根據墨菲定律,只要存在可能就一定會發生。所以應急處置就是我們的兜底手段,是保證高可用性的重要一環。
1、容災切流
出現故障我們首先需要做的不是定位原因,而是及時止血和快速恢復,而容災切流往往是快恢的首選,時效性最高。
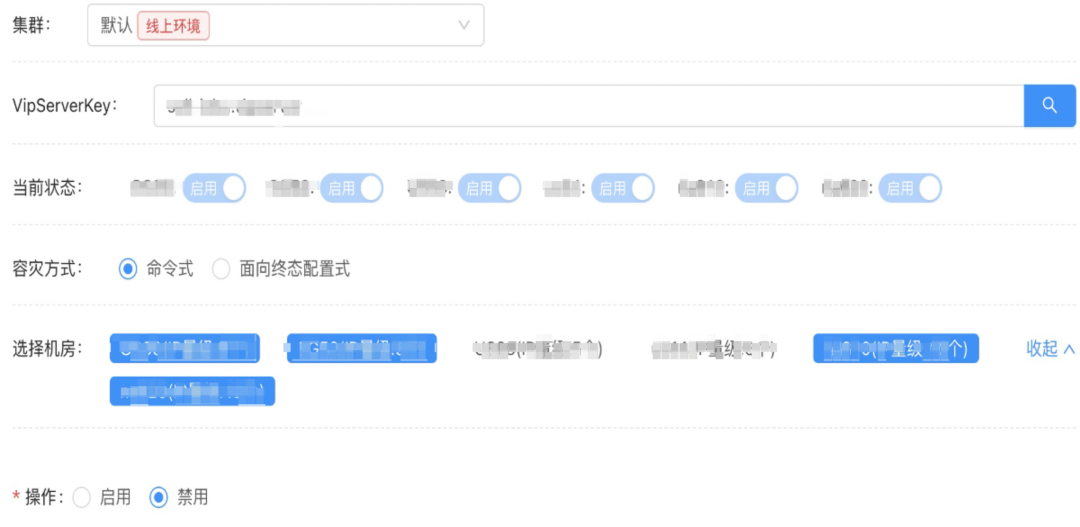
web型應用
當前成熟的方案是vipserver容災機制。原理也很簡單,多單元的機器都掛載到vipserverkey下,正常情況下因為同機房規則生效請求都是單元內呼叫。當需要容災時拉黑異常單元下的機器,同機房規則失效流量就會串流到其他單元從而達到跨單元容災的效果。
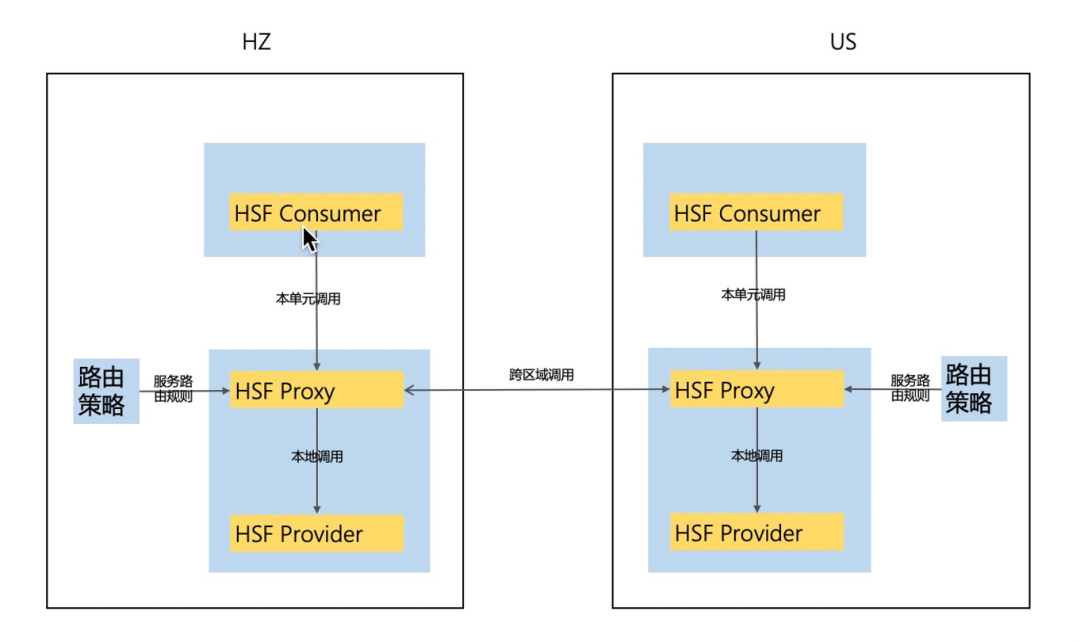
服務型應用
當前還沒有特別標準的方案,商品的做法是使用代理服務多地註冊,在容災切流時透過呼叫不同單元的代理服務來達到跨單元切流的效果。
2、變更回滾
出現線上問題的時候,如果無法透過容災切流的手段解決就要看一下有沒有變更釋出,判斷如果可能跟變更有關就先回滾,重要的還是要做好回滾驗證。
3、擴容重啟
遇到突發流量、下游系統慢或本身資源容量不足都可能導致應用自身負載承壓。在遇到資源瓶頸的時候快速擴容就是首選,這個時候考驗的是系統的彈效能力。當前也有一些可行的方案:
VPA:基於CPU/記憶體垂直彈性,調整的是cpu核數和記憶體大小,不過有上限。
HPA:基於CPU/記憶體水平彈性,缺點就是擴容速度不夠快,還是要經歷應用啟動的過程,應對突發的流量波峰可能不太可行。
KPA:基於流量/響應水平彈性,據稱是CSE的替代者,猜測應該可以透過回放記憶體映象來實現快速擴容。
當無法擴容的時候,重啟是解決系統效能問題的另一個重要手段。據不科學的統計,90%的暫不明原因的效能問題可以透過重啟暫時解決或一定程度上緩解。
4、限流降級
面對容量問題,除了擴容以外另一個選擇就是限流和降級,可以根據重要程度優先對邊緣應用和非核心場景做限制。
分層分場景
我們支撐的業務肯定是有優先順序的,有核心的業務,也有邊緣場景。當需要做限流降級處置的時候不能一刀切,要根據重要程度先對非重要的應用作限制。
分使用者粒度
同樣我們服務的使用者也是有優先順序的。以商品為例有付費商家和免費商家,那麼在整體資源受限的情況下就可以先對免費商家做降級處理。
根據資源佔用分層
像商品場景存在品量非常多的商家,這部分使用者的某些操作可能對系統資源佔用比較大,比較常見的就是引起資料熱點或者資料偏移,而這些都是影響效能的因素,所以對資源佔用大戶也要有對應的處置措施,比如禁讀禁寫。
5、應急公告
如果短時間內無法恢復(參考1-5-10標準),那麼就需要掛應急公告減少使用者進線,每個業務場景的應急公告應該預先編制完成,在有需要時一鍵執行。
6、應急參考
應急處置的方案有很多,但是在處理線上問題時應該是有優先順序的,先做什麼其次做什麼最後做什麼。下圖是整理的一份應急處置SOP參考文件。它不是操作手冊,不能在出問題時再去查閱,而是每個人腦子裡應該有這樣一張圖,對於線上應急處理流程爛熟於胸。
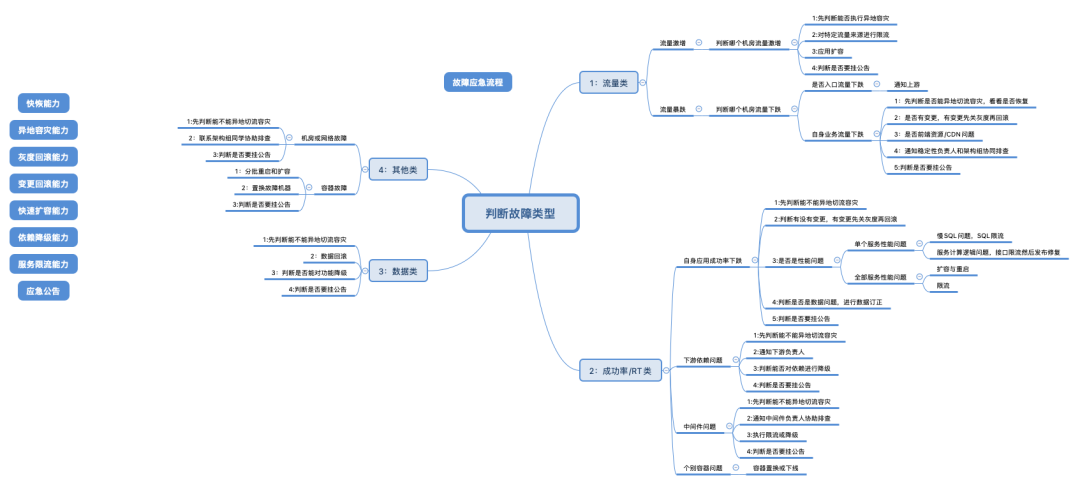
7、故障演練
所有的安全生產的措施都做好了,那麼怎麼驗證它可以正常工作,故障演練是很好的手段。一方面可以檢驗穩定性保障措施的可用性,另外一方面也可以鍛鍊技術人員的應急處理能力。我看到過不止一次有人在處理故障時很緊張手都在抖。所以常態化的故障演練,特別是突襲演練可以讓更多人參與到應急處理的過程中去,多實踐才可以在真正發生問題的時候有條不紊。
三、覆盤改進
1、歸納總結
出問題不可怕,重要的是分析這個過程中存在什麼問題,流程機制上有什麼漏洞,從而幫助我們做的更好。商品的穩定性措施就是在一次次面對各種問題的過程中總結和實踐的。
2、經驗分享
歸納總結是利己,避免自己再犯相同的錯誤。經驗分享是利他,幫助別人不要掉到同樣的坑裡。另外技術風險防控平臺裡的大部分故障都是公開的,可以看看自己的應用有沒有同樣的風險。
總結
風險意識
做好穩定性最重要的是要有風險意識,對生產保持敬畏之心。有風險意識才會在產研的全流程中關注穩定性的事情。比如新引入了一個依賴,就會考慮它異常了對於自己有什麼影響,有沒有容災方案,能不能降級等等。另外有風險意識也會慢慢的形成一些良好的習慣,比如定期Review系統水位,我個人每天早上剛到公司做的第一件事就是看一下監控和報警。
減少損失
應急處置的第一原則是把損失降到最低,先恢復,再定位。
風險自愈
安全生產建設最終的目的應該是具備自愈能力,在系統出現問題時能夠及時介入並自動恢復。
向人體學習,他擁有一套三重的免疫系統,這是一個百年的相當穩定的系統。-- 魯肅
所以事前要有風險意識,事中要及時止損,事後查漏補缺構建風險自愈的能力。更重要的是秉持長期主義的精神,相信最終能夠做好安全生產的事情。
來自 “ 阿里開發者 ”, 原文作者:彭文清(馬恪);原文連結:http://server.it168.com/a2023/0504/6802/000006802180.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 淺談系統的不確定性與穩定性
- 【穩定性】穩定性建設之依賴設計
- 【穩定性】從專案風險管理角度探討系統穩定性
- 大促穩定性保障深度覆盤,包含應對措施和案例分析
- 城市應急指揮系統詳情分析及建設方案概述
- 全鏈路壓測(11):聊聊穩定性預案
- 貨拉拉技術穩定性體系1.0建設實踐
- Dubbo 穩定性案例:Nacos 註冊中心可用性問題覆盤
- 大型微服務架構穩定性建設策略微服務架構
- SAP QM 穩定性研究功能研習系列1 - 穩定性研究總流程
- 雙重預防體系建設和系統軟體開發
- 21年技術建設覆盤
- 為什麼系統極點關係到系統穩定性
- 穩定性
- 如何加強機場安防及應急通訊系統?(中篇)
- Kubernetes 穩定性保障手冊:洞察+預案
- 談談Linux系統啟動流程Linux
- 基於Kubernetes的Serverless PaaS穩定性建設萬字總結Server
- 多利熊基於分散式架構實踐穩定性建設分散式架構
- 架構-穩定性建設邏輯問題實戰總結架構
- 穩定性領導者!阿里雲獲得信通院多項系統穩定性最高階認證阿里
- 網路安全應急預案 資訊保安應急預案 應急演練
- 5.28應急響應思路流程
- 薩摩耶雲建立資料安全應急處置機制可靠性和穩定性
- 邁道雙重預防體系智慧化管理系統助力集團施工企業落實雙重預防機制建設
- 「重磅」2021程式設計師應急指北:穩住別慌程式設計師
- 深度解析APS系統異常預警處理:從識別到解決的全流程策略
- 螞蟻集團TRaaS技術風險防控平臺入選中國信通院《資訊系統穩定性保障能力建設指南(1.0)》最佳實踐案例
- Kafka 的穩定性Kafka
- Win10開機預設開啟小鍵盤?Win10系統設定小鍵盤預設開啟的詳細步驟Win10
- 從前端程式設計師的視角看小程式的穩定性保障前端程式設計師
- 知攻善防Web1應急靶機筆記--詳解Web筆記
- 螞蟻集團TRaaS入選中國信通院《資訊系統穩定性保障能力建設指南》最佳實踐案例
- 內地到香港抽血鑑定性別流程超全超詳細_容媽媽網
- 快取系統穩定性 - 架構師峰會演講實錄快取架構
- 防溺水預警識別系統
- 剖析多利熊業務如何基於分散式架構實踐穩定性建設分散式架構
- App穩定性測試APP