貨拉拉國際化測試之深度學習實踐
一、背景與挑戰
隨著貨拉拉國際化業務市場的飛速擴張和產品的高速迭代,質量保障工作遇到了前所未有的挑戰。特別是我們的業務覆蓋了13個不同的國家和地區,涉及近20種語言,橫跨8個時區,17種支付方式,除了常規的邏輯功能測試之外,錯綜複雜的‘國際化’因素也大大增加了QA的單一重複性勞動。
1.1 多語言測試挑戰
語種數量:受限於熟悉的語種數量,對於陌生的語言,很難分辨APP是否載入了正確的語種。

精準翻譯:對於高度相似的翻譯,如有個別文字遺漏或者錯誤,測試人員很難透過肉眼識別。

1.2 多時區測試挑戰
時區轉換場景多樣化:業務的多樣性需要不同層級服務對時間做不同的控制轉換,大大增加了測試挑戰。
跨天業務問題: 如果轉化時區後剛好跨天跨月跨年,則以整天整月整年為開始結束條件邏輯可能出現問題。
夏令時問題 : 部分市場有夏/冬令時變化,一旦政策改變,而程式碼時間沒有及時跟進更改,會導致一系列的問題。
多次轉換問題 : 國際化的業務鏈路比較長,服務中還存在時區被多次轉換,統一修改特別困難。
1.3 歷史工具的侷限性
隨著業務場景的複雜化,之前針對單個場景開發的資料對比式工具,其侷限性就暴露的越來越明顯了,例如:
部署複雜: 後端翻譯檔案對比是一個GUI工具,需要在Window和macOS上獨立安裝,且依賴較多。
易用性差: 介面級別翻譯對比工具,每次需要review程式碼,找到需要測試的欄位key和value值。
依賴性強: App前端翻譯強依賴於UI自動化,而UI自動化經常變動,維護工作量很大。
覆蓋面低: 時區校驗工具只能覆蓋一部分後端介面的時區轉換檢查。
擴充套件性差: 大部分工具只能解決單一場景,很難透過簡單升級解決更復雜的業務場景。
二、整體解決方案
2.1 平臺架構
受制於上述工具的侷限性,我們急需一套更完整的高擴充套件性方案來統一解決上述問題。注意到深度學習技術在各行各業得到了創新應用,我們也嘗試引入深度學習並不斷實踐,為國際化AI智慧全測平臺提供基礎的機器學習能力,進而為上層業務場景提供不同的測試解決方案。

平臺共分為3大層:客戶端、業務層、AI層(AI+底層支援)
客戶端: 平臺的入口,直接面向使用者,主要分為兩大塊,包括時區工具、多語言工具,以及配套使用的介面錄製、定時配置、多語言資料同步等功能,並且可以支援第三方平臺的資料同步。
業務層: 平臺中層邏輯處理層,連線客戶端和AI層的重要模組。包括各資料中心單獨預處理的時區、多語言資料的資料格式化、資料特徵處理,將處理好的資料提交到AI層,接受AI返回的識別結果並生成報表,以及整體的正確率統計 、 統計報告,並且有專門的噪音最佳化功能,用以降低人工維護成本,最後提交問題給到對應的開發和測試人員。
AI層: 平臺的最核心層,主要用於識別時間欄位,時間檢查,語言,語言檢錯等,並且將結果反饋到業務層,能夠隨時接收資料的正向傳播,以及修正結果的反向傳播的模組。
2.2 底層實現
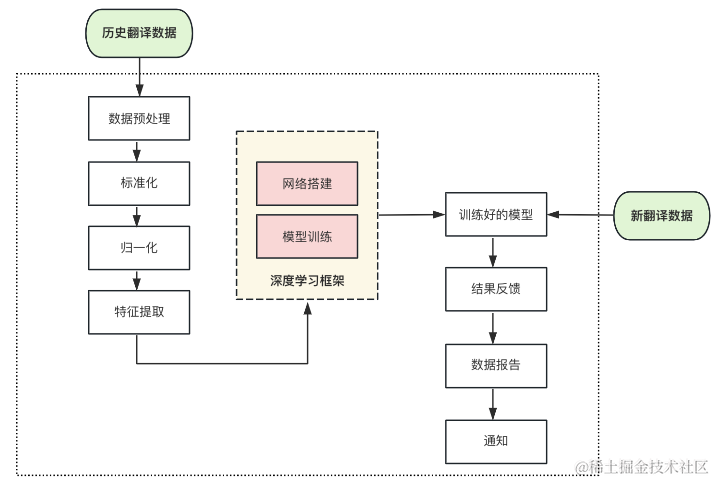
AI底層由深度學習模型支撐,其基本流程就是藉助編碼器 - 解碼器神經網路結構,以詞語序列或時區因子等作為訓練集輸入,結合注意力機制進行網路訓練,然後用測試集上的誤差作為最終模型在應對現實場景中的泛化誤差,不斷獲得泛化能力更強的網路模型,再透過對誤差因子閾值的調整決定模型判定結果,最終輸出翻譯及時區判定結果,整體的網路結構示意圖如下:

三、應用之多語言測試
3.1 解決方案
3.1.1 資料集
在國際化,語言翻譯預期結果維護在Crowdin平臺上,因此對於多語言翻譯資料集,主要由以往需求的已翻譯文案及其存放於Crowdin的預期結果構成,並按照8:2比例劃分為訓練集以及測試集。
比如將“You already have an ongoing order. ”翻譯成中文,翻譯好的句子分別為“您已有一張進行中訂單” 和“您已有一張訂單” 和“我進行中訂單”,將其組合成三種資料,其中1表示翻譯正確,0表示翻譯錯誤:
"You already have an ongoing order. "-“您已有一張進行中訂單”:1
"You already have an ongoing order. "-“您已有一張訂單”:0
"You already have an ongoing order. "-“我進行中訂單”:0
具體的資料預處理步驟為:
匯入測試apk,如果該apk是第一次進行語種分類檢測,需先獲取原始碼master分支或使用上一版本的apk進行模型訓練。如果已有模型資料,反編譯該測試apk獲取翻譯檔案資料,然後對比上一版本的翻譯檔案,獲取有變更或者新增的翻譯內容,即為檢測資料。
對檢測資料進行格式化,去掉噪音資料,例如取值符號($),百分號(%),顏色編碼(F16622)等與語種無關資料,提高訓練資料質量。
對降噪後的訓練資料進行分詞,以獲得量級更大數量更充分的特徵詞。由於不同語種的差異,例如中文、日語等語種有大量的不重複單個字元,且和其他語種的重複率不高,切分單個詞作為特徵詞就可以作為特徵詞進行訓練。但如果是同一個語系,不同語種使用的單個字元重複率很高,使用單個字元進行分詞提取分類的準確率就不太理想,這個時候可以使用二元字元組合作為特徵詞,這樣可以有效的區分同語系不同語種,且能使得特徵詞的數量增加許多。
3.1.2 模型機制
模型訓練:藉助於網路分類器能力,選出最有可能的類別,即該類別在當前特徵變數的條件機率和先驗機率下,後驗機率最大。對於本方案,就是計算提取匯入的翻譯文字進行向量化後,根據模型的特徵詞和條件機率獲取特徵變數,再結合每個語種的先驗機率,計算該翻譯文字的各個語種在條件依賴於當前特徵向量的後驗機率,後驗機率最大的語種類別,即為檢測的語種分類結果。
模型預測:使用之前訓練好的分類器模型進行語種檢測,如果檢測資料中有和目標語種不符的資料,輸出對應的key-value,在開發人員修正錯誤後,使用正確的資料透過調整注意力等權重因子重新訓練模型,如果沒有語種分類不符合預期的資料,檢測完畢後直接用新的翻譯檔案再次訓練模型,從而保證模型的不斷最佳化。
3.2 收益
測試流程簡潔:無需程式碼側介入,透過反編譯apk獲取翻譯檔案,無需獲取app原始碼,省去鑑權過程,除此之外,透過上傳apk反編譯測試,可直接測試目標app,如果在原始碼側檢測,還需確認分支,簡化了測試過程。
測試效率高:高效地完成自動化語種分類檢測,覆蓋各個語種,人力投入小,且只對更新或者增量的內容進行檢測,避免了重複檢測。
準確率高:分類器模型基於apk原本的翻譯檔案資料不斷最佳化,從而保證語種檢測較高的準確率。
維護成本低:模型在每次訓練最佳化後自動儲存,模型穩定,無需手動跟隨需求迭代更新。
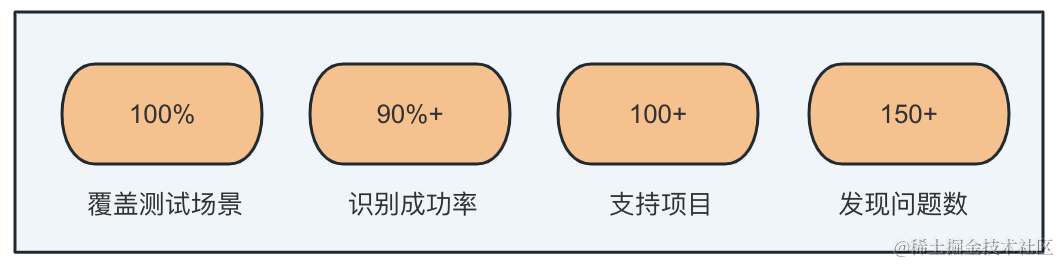
覆蓋面廣:平臺結合機器學習,不需要人工識別多地區語言翻譯,能夠100%覆蓋前後端翻譯場景,識別成功率90%+,目前已服務專案100+,發現翻譯缺失或者錯誤問題150+。
四、應用之多時區測試
4.1 解決方案

4.1.1 資料集
在國際化,時區介面中會有多個因子如cityid、marketid、hlang、時間欄位、時間戳等(例如:yyyy-MM-dd HH:mm:SS、yyyy-MM-ddTHH:mm:ss、yyyy-MM-ddTHH:mm:ss.SSS、yyyy-MM-dd HH:mm:ss.SSS、yyyy-MM-dd、yyyy-MM,yyyy/MM/dd等),在實際測試中,我們透過結合多個因子判斷出相關該場景對應的時區,這一部分工作,同樣可以交給深度學習模型,讓深度學習模型從介面提供的多個因子中判斷當前場景會應用的時區。具體的資料集構造操作如下:
實時獲取最新的時區資料庫,獲取資料庫中各地時區、夏令時的政策,可以解決各地政策變化時,程式碼未及時調整,導致的時間不準確問題。
將時區因子打散隨機組合,按照key-value格式構造時區因子資料集,如:
51001+正確的hlang:西三區
51001+錯誤的hlang:西三區
61001+正確的hlang:西六區
為提高資料質量更好地進行網路訓練,對資料集進行預處理,進行歸一化、標準化等降噪操作。
4.1.2 模型機制
模型訓練:將時區因子及其預期結果輸入到網路模型中,透過由RNN構造的編碼器和解碼器,逐層訓練調整學習因子及注意力因子等,對網路模型進行充分的正向及反向訓練,最終泛化得到誤差符合預期的網路模型。
模型預測:使用之前訓練好的深度模型進行時區判定檢測,如果檢測結果出現時區誤判的資料,同樣輸出對應的key-value,調整修改該資料集,重新訓練最佳化網路模型。
4.2 收益
維護成本低: 一次錄入,重複使用。如果有業務改動時,僅需改動少量引數即可重新執行。
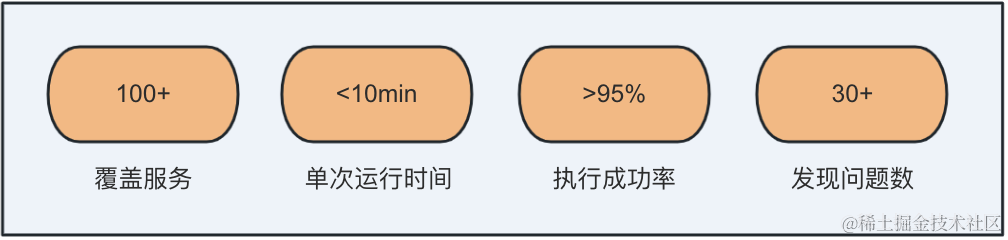
執行效率高: 一次執行時間不超過10min,極大的降低版本頻繁迭代導致的人力不足的情況。
發現問題準: 識別時區問題準確率很高,基本不會有誤報。
覆蓋面積廣: 已經覆蓋國際化8個時區,覆蓋服務100+。
減少潛在資損: 提前發現時區處理錯誤造成的派券、用券時長超過預期時長,而這些有可能進一步導致超發、超用等潛在資損問題。
五、未來展望
未來,我們將繼續利用深度學習能力,進一步幫助技術團隊提升業務迭代效率:
提測前,基於深度學習方法如ATLAS等為程式生成單測用例斷言,更快地幫助開發驗證軟體基本模組的準確性,提高冒煙測試的透過率。
測試階段,藉助深度學習網路框架的圖文識別能力,基於自然語言的處理解析測試用例,基於網路影像識別的能力和底層引擎驅動完成用例的執行,從而更好地助力UI 自動化測試。
利用深度學習能力解決更多國際化特有的測試難題,比如多支付方式等。
來自 “ 貨拉拉技術 ”, 原文作者:質量保障部;原文連結:https://server.it168.com/a2023/1227/6835/000006835022.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 貨拉拉服務端質量保障之測試策略篇服務端
- 貨拉拉貨運iOS使用者端架構最佳化實踐iOS架構
- 貨拉拉服務化實踐-為啥都愛“造輪子”?
- Webnovel 國際化實踐Web
- 貨拉拉自助資料分析平臺實踐
- 網易易盾深度學習模型工程化實踐深度學習模型
- 貨拉拉大資料測試質效提升之路大資料
- 基於CPU的深度學習推理部署優化實踐深度學習優化
- 深度學習之瑕疵缺陷檢測深度學習
- 深度學習之目標檢測深度學習
- 雲上深度學習實踐分享——雲上MXNet實踐深度學習
- 貨拉拉技術穩定性體系1.0建設實踐
- 八大深度學習最佳實踐深度學習
- 深度學習的應用與實踐深度學習
- API自動化測試實踐API
- Docker與自動化測試及其測試實踐Docker
- 【SpringBoot學習(四) 使用 thymeleaf實現國際化功能】Spring Boot
- 貨拉拉利用時空熵平衡提升營銷效率的實踐熵
- 愛奇藝深度學習雲平臺的實踐及優化深度學習優化
- 在 Google Colab 中快速實踐深度學習Go深度學習
- 學習筆記之測試筆記
- 介面測試學習之jsonJSON
- 介面測試學習之 jsonJSON
- 深度學習之PyTorch實戰(4)——遷移學習深度學習PyTorch遷移學習
- 深度學習及深度強化學習研修深度學習強化學習
- 深度學習、強化學習核心技術實戰深度學習強化學習
- 自動化測試的最佳實踐
- 前端自動化混沌測試實踐前端
- UI自動化測試工程實踐UI
- 自動化測試實踐總結
- 貨拉拉大資料離線混合引擎服務建設實踐大資料
- 愛奇藝深度學習雲平臺的實踐及最佳化深度學習
- 深度學習+深度強化學習+遷移學習【研修】深度學習強化學習遷移學習
- 美團深度學習系統的工程實踐深度學習
- 深度學習及深度強化學習應用深度學習強化學習
- iOS語言國際化/本地化-實踐總結iOS
- 貨拉拉一站式雲原生AI平臺建設實踐AI
- 介面自動化測試工程實踐分享