K8S學習之當我們部署應用的時候都發生了什麼?
前言
最近在學習K8S,基礎的知識參考於《Kubernetes in Action》。看完整本書基本上用了2~3個月的時間,進度比較慢;主要都是每天早晨到公司後,在正常工作時間之前的1個小時裡完成的。由於時間拉的很長,各章的知識在我腦袋裡是散狀的,所以在我整理這篇筆記的時候,就想透過一個主題,把相關的內容串起來。第一篇筆記定的主題是“排程-當我們部署應用的時候都發生了什麼?”,先從大的框架上記錄一下K8S的架構與原理;對於卷、網路、configmap等元件會放在第二篇。初學者級別的學習筆記,有問題的地方大佬們及時勘誤。
我在這裡先給大家簡單描述一下,當我們在aone裡手動點選了升級之後,k8s裡都發生了什麼?
當我們在aone裡手動點選了重新部署,aone會透過k8s的api介面通知master節點建立一個Deployment,Deployment會按照配置裡的宣告要求建立一個新的RepliactionSet,RepliactionSet會按照配置的建立一個或者若干個Pod,pod會排程到相應的工作節點上,透過docker拉取映象,啟動應用。
如果你能完全看懂我的描述,並且知道這些英文的工作原理,那你可以關掉網頁了;如果你看完這段描述並不知道我在說什麼,並且還想了解”當我們部署應用的時候都發生了什麼?“的話,那請繼續往下看。
經常混在一起出現的名詞:Docker&虛擬機器&容器
我在看之前經常會把一些名詞”搞混“,至少是沒太明確的瞭解其概念和關係-Docker&虛擬機器&容器。
Docker&虛擬機器
應用容器引擎:讓開發者可以打包他們的應用以及依賴包到一個可移植的映象中,然後釋出到任何流行的Linux或Windows作業系統的機器上,也可以實現虛擬化;如Docker、RKT等。
虛擬機器(Virtual Machine):指透過軟體模擬的具有完整硬體系統功能的、執行在一個完全隔離環境中的完整計算機系統;如vmware、virtualBox。
其實嚴格意義上來講,Docker和虛擬機器不是同一個層級的定義。應用容器引擎和虛擬機器是倆種虛擬技術方案,而Docker只是應用容器引擎中最出名的,RKT是後起之秀。

左圖為Docker容器,右圖為虛擬機器系統,我們從下往上對比大概有如下四個區別
Docker共享宿主作業系統的核心,虛擬機器獨立作業系統核心
Docker不同容器之間資源隔離,虛擬機器在同一個VM上的app共享資源
Docker映象分層,相同的層可以共享,減少網路傳輸壓力;虛擬機器映象不能共享
Docker可移植性沒有虛擬機器好,需要考慮核心版本等;虛擬機器完全獨立可以移植
其實這跟我們很多中臺系統建設的倆個極端是很像的,靈活性越高,通用性就越差;通用性好那就難免要做一些定製化的需求。
容器
容器技術:同一臺機器上執行多個服務,提供不同的環境給服務,服務之間相互隔離。
容器是透過linux核心上提供的cgroups和 Namespace來實現隔離的。cgroups將程式分組管理的核心功能透過cgroups可以隔離程式,同時還可以控制程式的資源佔用(CPU、記憶體等等)情況在作業系統底層限制物理資源;Namespace用來隔離IP地址、使用者空間、程式ID。
值得提前一提的是容器的檔案系統隔離,App的寫入完全隔離,如果修改底層檔案,則複製一份到容器所掛載的檔案系統內,不直接修改底層檔案。
K8S簡介-What Why How
What&Why
從上一節的介紹應該可以看出來,一個應用的部署使用Docker已經完全可以執行起來,那K8S是什麼,在整個應用宣告週期中的作用是什麼?先看一下使用者在使用docker部署應用的過程。

Docker部署的時候,需要開發者來做運維操作的有倆步,一是用Docker構建和推送映象到映象庫,二是在生產機器上拉取映象並執行。這倆步操作看起來沒什麼工作量,畢竟Docker在裡面做了大量的工作;但如果一個App需要部署多臺服務,並且還要做升級更新以及後續的運維操作;如果一個人要負責多個系統成百上千個服務的部署運維,那工作量對他來說就是個災難。所以我們需要一個軟體系統,幫我們更簡單的部署和管理應用,這就是K8S存在的價值。
開發者需要做的是:1、將映象構建並推送到映象庫(在我們常使用的Devops平臺,比如Aone,甚至已經將打包映象透過平臺實現),2、定義好每個應用需要資料的節點數量,其他的運維工作都由K8S來代理;這裡還是需要運維同學的,但由於K8S出色的運維能力支援,使運維工作也很輕鬆,物理資源利用率會更高。
How

先簡單拋一下K8S的架構簡圖,可以先有個大概的瞭解。架構可以分為倆部分,控制皮膚(也就是master節點)用於控制和管理整個叢集;工作節點是執行容器化應用的機器,透過一些元件來完成執行、監控、管理。
工作節點
容器:docker、rtk等
kubelet:與API伺服器通訊,管理所在節點容器
kube-proxy:元件之間的負載均衡
控制皮膚(master)
KubernetesAPI:與其他元件通訊
Scheculer:排程應用
ControllerManager:執行叢集級別的功能,複製元件、跟蹤工作節點、處理節點失敗
etcd:持久化儲存叢集配置
看到這些概念肯定會更頭疼,後面的筆記會盡量用平時我們工作接觸到的東西來幫大家逐步理解。
Aone 、EAS、ASI、K8S、Docker的關係?
一張圖簡單表示一下,我們工作中經常出現的一些平臺的關係

k8s和docker的關係我們已然瞭解;ASI是阿里雲基於K8S之上封裝的一個容器管理平臺,支援幾乎所有阿里上雲的中介軟體,整合了阿里的安全元件,使集團內部使用更方便和安全;Aone和EAS都是依賴ASI+各種Devops功能,以此應對各自垂直場景上的運維易用性需求。
應用都跑在哪裡?Pod
在K8S架構簡圖裡有這樣一個細節,有一些應用是獨立容器部署的,有一些則是多個容器組合放在一起部署,這是符合實際需求的。比如倆個應用需要透過ipc(程式之間通訊)、或者需要共享本地檔案系統,但在linux容器之間是相互隔離的。所以在K8S中,並不是以容器為最基礎的部署單位來執行的,而是抽象出一個概念叫Pod。
概念:Pod是一個並置容器,作為K8S最基礎的構建模組。一個pod中可以有多個容器,但一個容器是不會跨工作節點的。我們平時部署的應用就是在pod中執行的,一個容器中原則上只有一個應用程式(除非有守護程式),這樣做的好處也是為了可以減少應用之間的依賴方便擴縮容等運維動作。
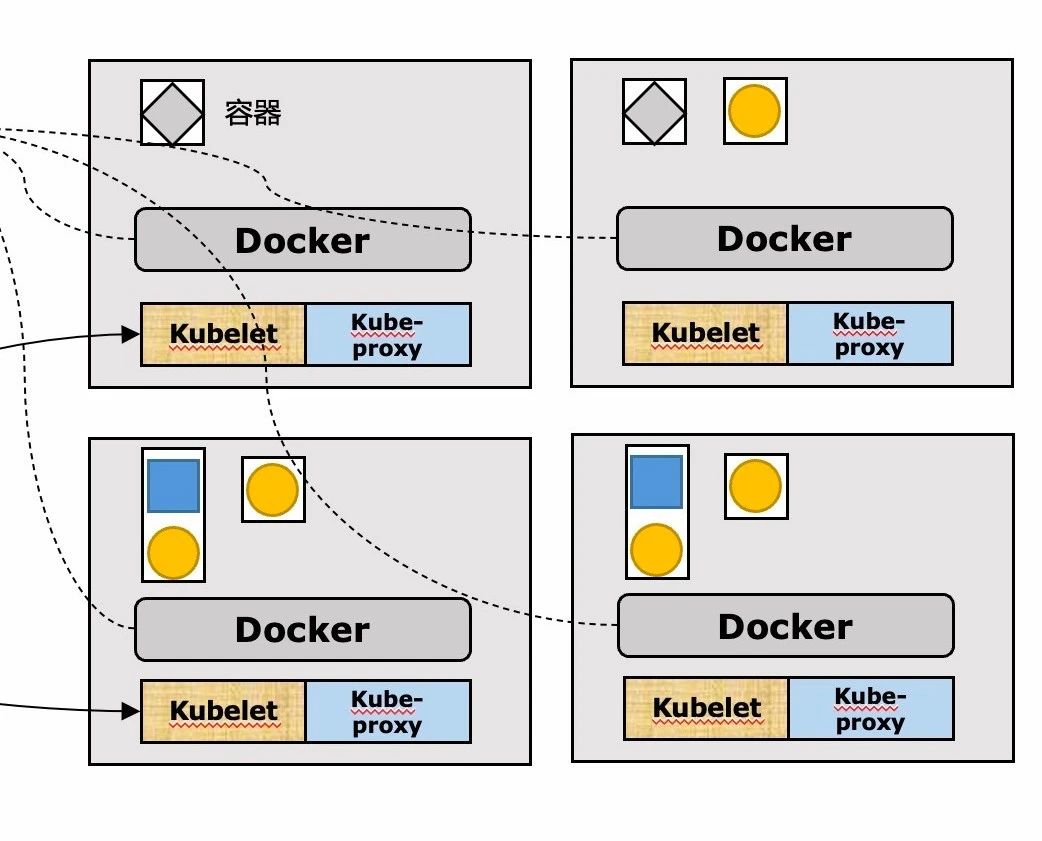
實現原理
K8S會將同一個pod中的容器,放在同一個linux的namespace下。
對於容器和pod之間如何合理的組合,個人理解一個最基礎的判斷方法,就是這倆個容器是否是同生命週期的;其實我們遇到的大多數的情況都是一個pod中只有一個容器。
標籤(label)
標籤是一種簡單卻功能強大的Kubernetes特性,不僅可以組織pod,也可以組織所有其他的Kubernetes資源。
之所以在這裡提出來標籤的概念,是因為後續介紹的K8S的執行機制裡,大量的使用標籤篩選器(Selector),是個非常重要的屬性。後面聊到的各種資源裡圈定控制的範圍就是透過標籤選擇器來搞定的。如下圖所示,透過標籤的篩選分類,可以區分出各種環境,以此來做靈活的批次運維管理。
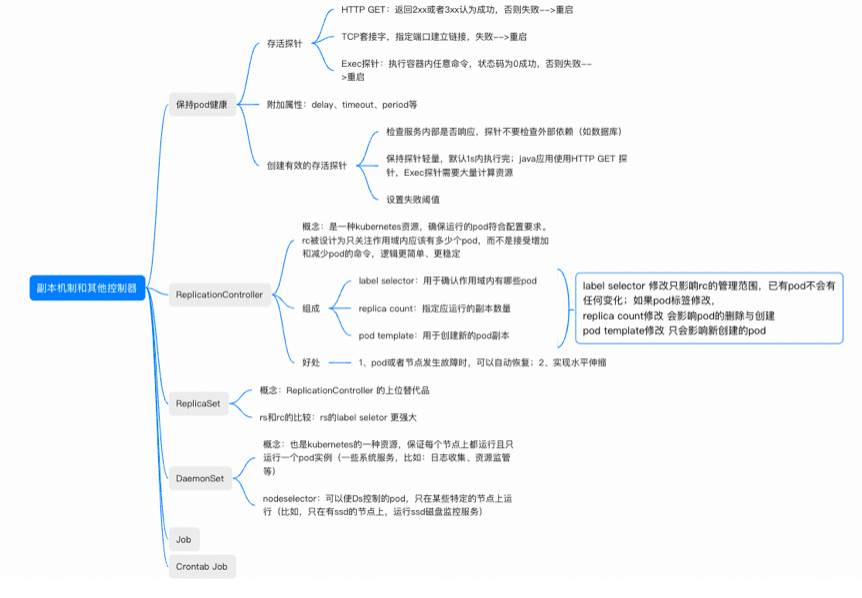
如何保證啟動的數量和版本?ReplicationController
因為這篇筆記主要想記錄K8S中部署應用時是如何排程的,所以我們先略去用Pod內部涉及到的一些其他元件,比如volume、網路、configMap等。我們直接進入到K8S的副本機制,也就是K8S是透過什麼機制來保證Pod符合配置要求(映象版本,部署個數等)。
ReplicationController
是一種kubernetes資源,確保執行的pod符合配置要求(宣告式),簡稱RC。之所以把”宣告式“標亮,是因為這跟K8S實現機理有關,所有的資源定義的API都是宣告式api,這個在後續會詳細聊。
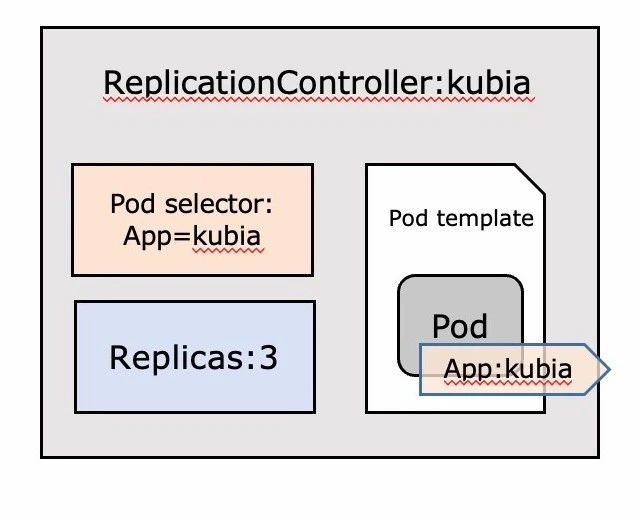
用途
1、pod或者節點發生故障時,可以自動恢復;2、實現水平伸縮
組成
RC的宣告主要分為三個部分,pod selector、replicas、pod template。透過這些我們就可以告訴K8S一個應用在部署在容器中時,用哪個版本的映象,執行多少個。RC也會透過pod selector進行管理和運維動作。
Pod selector:用於確認作用域內有哪些pod
Replicas:指定應執行的副本數量
Podtemplate:用於建立新的pod副本模板
How it works
場景1:當一個Pod出現故障,我們將其手動觸發刪除時;RC會拉取template中配置版本的映象,建立一個相同標籤的Pod。在實際工作中,如果遇到某一個節點無法work,我們在aone裡操作銷燬的時候,最底層的排程就是這樣的。
場景2:當一個標籤為kubia的pod,被重新打上新標籤的時候,RC會發現數量不符合要求,拉取template中配置版本的映象,建立標籤為kubia的Pod。在實際工作中,當我們在重新部署的時候,第一個要重新部署的pod可能會被打上”待銷燬“的標籤,等新的pod啟動之後,才正式的銷燬。
場景3:當RC感知到 Replicas宣告減少。實際工作中,在縮容的時候,K8S會按照一定的優先順序規則,對已有容器進行銷燬。優先順序規則的底層邏輯總結起來就是:狀態越穩定,銷燬優先順序越低。
優先順序如下:
1 如果pod沒分配到節點,先被刪除 。
2 如果pod的狀態是 Pending>PodUnknown>PodRunning,則Pending優先被刪除,PodUnknown次之,PodRunning最後被刪除。
3 不是Ready狀態的Pod先被刪除。
4 如果Pod都是Ready狀態,則最後一個變成Ready狀態的Pod先被刪除(Ready時間最短的)。
5 重啟次數大的Pod先被刪除。
6 建立時間最新的Pod先被刪除。
場景4:當RC感知到Replicas宣告增加。實際工作中的擴容場景,過程與場景1類似,不贅述。
場景5:當映象版本升級的時候。
注意,修改模板的動作,並不會觸發容器的重新部署,但當場景1、2出現的時候,RC會控制用新的映象版本建立Pod。
ReplicationSet和StatefulSet
ReplicationSet與ReplicationController類似,但擁有較RC更強大的標籤篩選器,是RC的上位替代品,簡稱RS。
StatefulSet:從rc和rs的副本機制可以看出來,當新建立一個pod的時候,和原有pod是完全沒有關係的,也就是說他們是用來管理無狀態Pod的。而StatefulSet是用於管理有狀態Pod的,應對新的pod需要與原pod具有相同的網路標識,可以訪問同一份持久化資料等需求。由於涉及到的其他資源很多,我會放到第二篇筆記中來記錄,順便引出volume和網路等資源。
如何觸發應用升級?
副本機制和其他控制器-手動升級
上一節我們瞭解了K8S內部是如何用rc、rs等資源來保證pod的是符合配置要求的。也提到了映象版本升級是不會觸發更新的,所以在實際運維的時候,使用者不可能手動的來觸發。我們先來看下手動操作帶來的問題:
手動升級的弊端

手動操作通常有倆種模式。
第一種是recreate:升級完rc之後把所有的pod全部刪除等rc自動建立;或者建立倆個rc,等新rc下的pod全部可用,再把服務重定向到新的pod上。這樣會導致服務的短暫(也不一定短暫)不可用,或者造成資源的浪費。
第二種是rolling-update,也是建立倆個rc,銷燬一箇舊的,然後建立一個新的,直到全部切換。這樣的問題是手工操作很複雜,透過kubctl客戶端訪問api的方式進行,很有可能中間中斷魯棒性很低。而且很大一個問題是由於是先銷燬,所以無法回滾。
手工操作太麻煩了怎麼辦?Deployment
Deployment宣告式升級應用-代理了手工操作
為了解決上述手動操作的弊端,K8S使用了計算機接經典解決方案-套一層,一層解決不了就倆層。K8S提供了一個更高階的資源Deployment,用於部署應用並以宣告的方式升級應用,代理了上一節提到的手工操作。
Deployment的優點在於,只需要做宣告式的升級,僅改動一個欄位,k8s就會接管後續所有的升級動作,穩定可靠。並且Deployment會預設儲存倆版replicationSet(只保留就的rs,不保留舊pod),所以可以做到回滾。
控制滾動升級速率
k8s釋出的時候,可能經常遇到釋出“太快不穩定”或“太慢體驗差”的情況。Deployment是透過maxSurge 和 maxUnava工lable倆個引數來控制滾動升級的速率:
maxUnavailable:和期望ready的副本數比,不可用副本數最大比例(或最大值),這個值越小,越能保證服務穩定,更新越平滑;
maxSurge:和期望ready的副本數比,超過期望副本數最大比例(或最大值),這個值調的越大,副本更新速度越快。
機理:宣告式+監聽
到這裡其實我們已經算是瞭解了手動觸發升級的時候,k8s裡會涉及到的大部分的資源元件,以及他們各自的工作原理,接下來我們把他們整個流程串起來,還原一下現場。
簡單回顧一下k8s的架構簡圖,架構分為控制平面(master)與工作節點。API伺服器用於所有內部外部的元件通訊;etcd是個分散式持久化引擎,用於儲存pod、rs等等的配置;控制器執行叢集級別的功能,複製元件、跟蹤工作節點、處理節點失敗;排程器負責判斷pod應該排程到哪個工作節點上;kubelet用於工作節點與api伺服器通訊和控制本工作節點上幾乎所有事情。
為了保證高可用狀態,叢集裡有多個主節點,預設配置下會有三個主節點,其他倆個的控制器和排程器就是非活躍狀態,但是API伺服器是都會接受通訊請求,etcd之間也會同步配置資訊。
現場還原
當主節點透過API伺服器收到部署的命令時
1、API伺服器會透過介面傳過來的宣告配置,建立Deployment資源。
2、Deployment控制器會監聽到Deployment資源建立的訊息,呼叫API伺服器根據宣告來建立ReplicasSet資源。
3、ReplicaSet控制器會監聽到ReplicaSet資源建立的訊息,呼叫API伺服器根據宣告來建立Pod資源。
4、排程器會監聽到Pod資源建立的訊息,然後根據規則給Pod分配一個工作節點,呼叫API伺服器寫入到Pod的配置中(如何決定給pod分配哪個工作節點,後面會說)。
5、工作節點的Kubelet會監聽到Pod分配工作節點的訊息,根據Pod的宣告來來通知Docker拉取映象,執行容器。

在整個實現流程中,我highlight了倆個詞,一個是”監聽“、一個是”宣告“,這是K8S架構實現中最重要的倆個機理。
首先“監聽”,大家應該都理解,透過相關元件之間的訊息監聽,事件鏈的方式完成整個部署工作,可以解耦各個資源之間的依賴。
另一個是“宣告“,主節點中提供的所有API都是宣告式的,只定義期望的狀態,系統來負責向指定的狀態來進行工作;而命令式api需要呼叫者直接下達執行命令,並監控狀態,再進行下一步命令的下達。
宣告式 vs. 命令式
1、可以有效的避免單點故障,系統會想統一的狀態工作,不會發生某個命令沒有收到而帶來狀態的不統一。
2、Master節點更簡單,簡單在大多數情況下就意味著穩定和效率。
3、K8s的元件可以更具備組合性和擴充套件性,可以升級到達某個狀態的資源和元件,不用考慮歷史命令式API的相容問題。
宣告式API也分為倆種,eedge triggering(邊緣觸發) 和 level triggering(水平觸發)
水平觸發(level-triggered,也被稱為條件觸發)LT: 只要滿足條件,就觸發一個事件(只要有資料沒有被獲取,就不斷通知你)
邊緣觸發(edge-triggered)ET: 每當狀態變化時,觸發一個事件
這倆種方式各有各的優勢與應用場景,K8S使用的水平觸發(LT)方式,因為雖然在正常情況下ET比LT更節省資源,但如果在狀態變化的時候,使用ET的方式並且正好丟掉了訊息(在實際複雜網路環境下很有可能發生),就會使狀態與實際預想的不一致。而K8S架構中最重要的就是狀態的宣告,如果訊息丟失,則會引發各種不受控的問題出現。
做了一次分享,會覺得這部分比較難理解,舉個例子:
團隊有100個bug,Leader在群裡發訊息:100個bug明天下班之前改完(誰改Leader不管),這就是宣告式。
100個bug,A處理60個,B處理40個;第二天Leader看了下aone,還有超過50個沒改,@C一起來處理,這就是命令式。
宣告式的好處是:1、Leader只要結果不關注細節,可以做其他事情。2、如果A居家隔離,沒有收到訊息,為了達到目標,團隊裡會有人自動補位一起改bug。
不管哪種方式的訊息,如果Leader一直在確認是否所有人都收到,不是就不斷的發,這是水平觸發;如果Leader發進群裡就不再管了,這是邊緣觸發。
如何自動擴縮容?HPA&VPA
我們可以透過調高 ReplicationController、 ReplicaSet、 Deployment等可伸縮資源的 replicas 欄位,來手動實現 pod中應用的橫向擴容 。我們也可以透過增加pod容器的資源請求和限制來縱向擴容pod (儘管目前該操作只能在pod建立時,而非執行時進行)。雖然如果你能預先知道負載何時會飆升,或者如果負載的變化是較長時間內逐漸發生的,手動擴容也是可以接受的,但指望靠 人工干預來處理突發而不可預測的流量增長,仍然不夠理想 。
K8S提供了HorizontalpodAutoscaler(HPA),就是英文字面意思。橫向伸縮的意思是,透過增加或者減少同樣配置的pod的數量,來動態滿足業務需求量。
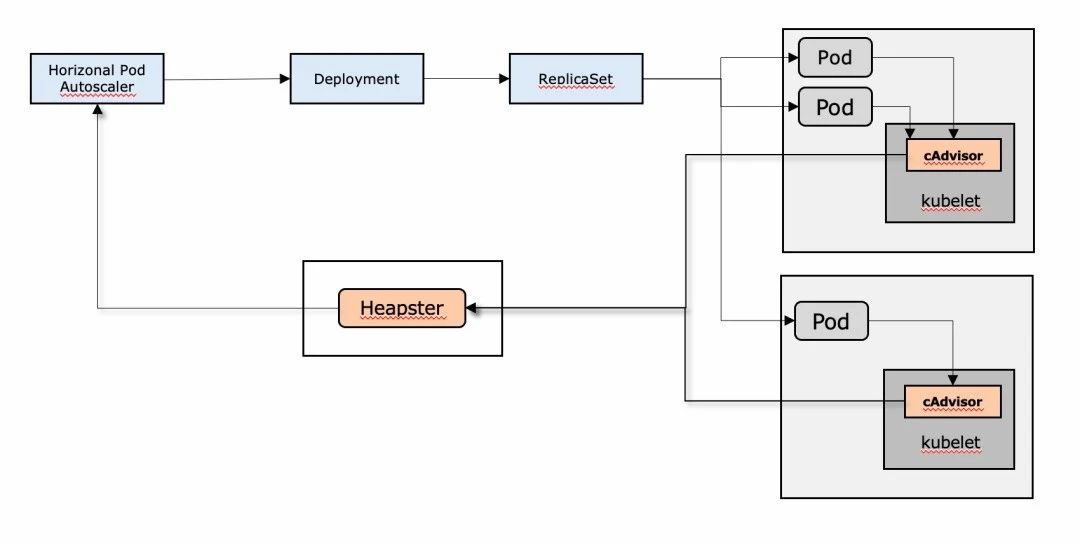
HPA是用來宣告橫向自動擴縮容的高階資源,它需要監控到相關pod的資源使用情況。K8S在每個工作節點的kubelet中都有一個cAdvisor,用於收集本工作節點的資源使用情況,然後在叢集中會啟動一個Heapster來從所有節點採集度量資料。這樣HPA就可以透過Heapster拿到它想要的資料。Heapster經常與influxdb、grafana一起使用,被稱為監控三件套,從圖中可以看出Heapster也是以pod的方式執行在某個工作節點上。
How it works?
1、首先HPA會從Heapster中獲取到所管理的pod的資源度量。
2、計算當前狀態下,所需要的pod數量。
如下圖,假設Hpa中設定的cpu使用率為50%,hpa會將各個pod的cpu使用率加和,再除以50%,向上取整。
3、如果發現所需pod數與現有副本數有差別,則會更新deployment中的replicas欄位,就會觸發自動的擴縮容。
當然擴縮容太過於頻繁會導致服務的不穩定,所以hpa中支援最快伸縮的間隔,預設擴容最快3分鐘,縮容最快5分鐘。
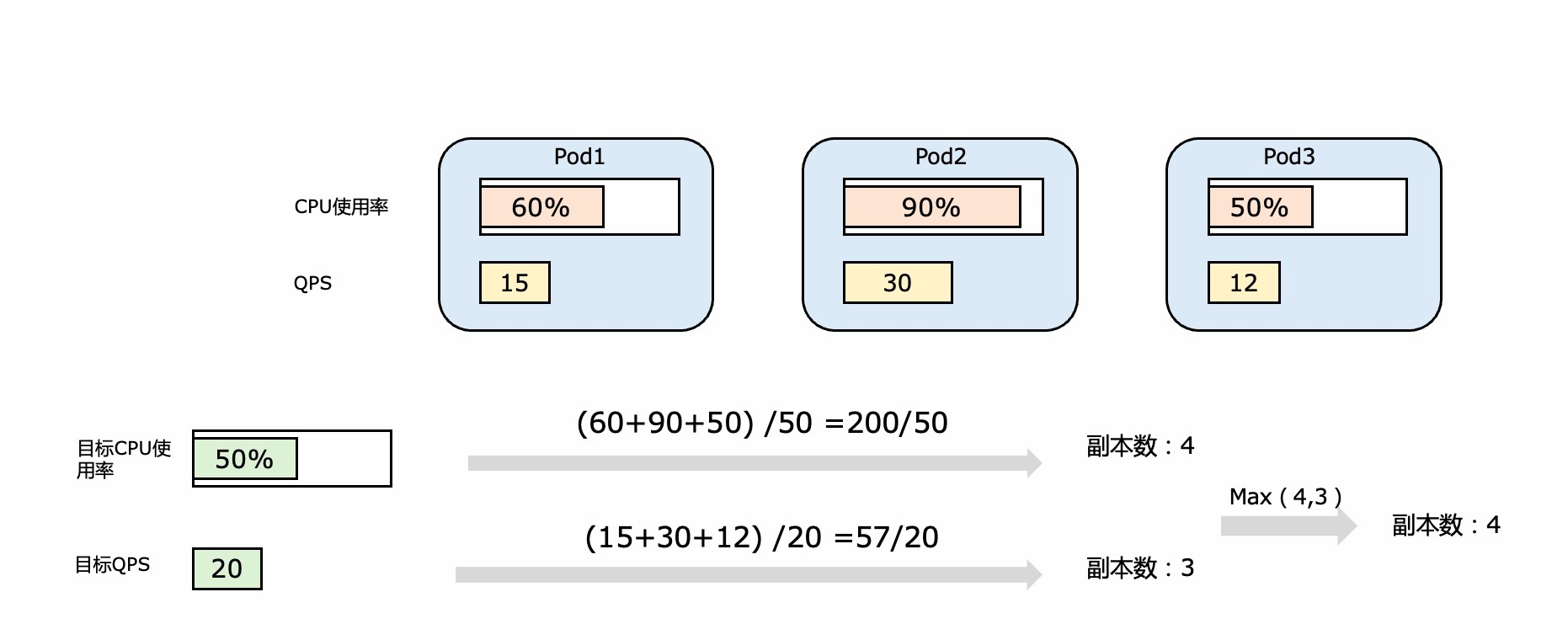
上面介紹的是個簡單的場景,使用者只透過cpu使用率來控制伸縮,如果使用者希望透過多硬體指標監控的話, K8S會取多個度量的最大值來進行擴容。HPA也同時支援多種型別的度量方式,Resource度量就是上面提到的,根據硬體指標來做度量;Pod度量型別可以用來監控QPS或者訊息佇列中的數量等;Object度量型別可以用來監控外部資源,比如依賴外部服務的個數來動態調整pod的個數。
VPA 全稱 Vertical Pod Autoscaler,即垂直 Pod 自動擴縮容,它根據容器資源使用率自動設定 CPU 和 記憶體 的requests,從而允許在節點上進行適當的排程,以便為每個 Pod 提供適當的資源。垂直自動擴容是在k8s1.9版本之後才提供的。
VPA vs. HPA
優點:可以節省資源,比如一個這批pod的內容使用量特別高,但cpu使用效率很低,HPA會直接擴N個相同配置的pod,來滿足記憶體使用需求;VPA會啟動一個記憶體量更大,cpu量更小的pod來執行應用。HPA會明顯浪費更多的資源。
缺點:VPA的擴容需要重啟pod,這樣可能會造成服務的不穩定。雖然在社群中已經有一些最佳化方案(),但重建Pod環境無論怎樣都會有一些風險。
所以HPA和VPA各有各的使用場景,我們團隊是做toB的業務,我大概看了一下,基本上都是VPA的伸縮方式。但如果是2C的應用,對穩定性的要求非常高,建議使用HPA,在應用釋出之前應該做好每個pod的各項資源的合適配比。
上面一直在聊的是Pod的伸縮,但如果叢集中工作節點的資源不能滿足需求了怎麼辦?K8S提供了Cluster Autoscaler(CA),它的伸縮方式與HPA大體一致,如果有感興趣的可以自行了解一下細節。
結尾
本篇文章最後,把前言中的”當我們在aone裡手動點選了升級之後,k8s裡都發生了什麼?“再貼在這裡看一下↓↓↓
當我們在aone裡手動點選了重新部署,aone會透過k8s的api介面通知master節點建立一個Deployment,Deployment會按照配置裡的宣告要求建立一個新的RepliactionSet,RepliactionSet會按照配置的建立一個或者若干個Pod,pod會排程到相應的工作節點上,透過docker拉取映象,啟動應用。
如果大家看完文章能看懂這段文字,說明已經瞭解了整個過程,要是還能想起來一些執行機理或者其中資源的實現原理就更好了。
整篇文章到這裡已經快9K字了,其實為了更簡單易懂的把整個知識點串起來,已經隱藏掉了很多實現細節,文章中的內容也大概輸出了學習筆記中不到50%的章節。希望後續還有時間把後面沒有分享出來的內容碼下來,畢竟整個過程對自己是個很大的鞏固和提升。
來自 “ 阿里開發者 ”, 原文作者:肖迪(墨詡);原文連結:http://server.it168.com/a2022/1223/6782/000006782192.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 當我們談 Java 併發的時候,你們在談什麼?Java
- 當我們談深度學習時,我們用它落地了什麼?深度學習
- 當我們說外掛系統的時候,我們在說什麼
- [譯] 當你建立 Flexbox 佈局時,都發生了什麼?Flex
- 當我們在談論高併發的時候究竟在談什麼?
- 當我們說開放世界的時候,我們到底在說些什麼?
- 當執行時,發生了什麼?
- 當我們談論Spring的時候到底在談什麼Spring
- 當我們在談論VR敘事的時候,我們究竟在談論什麼?VR
- 當我們在談論建構函式注入的時候我們在談論什麼函式
- 我們都應該學習PHPPHP
- 當我談自律的時候,我會談什麼(一)
- 遊戲的特質:當我們說“play”的時候,究竟在說什麼?遊戲
- 當我們談論Promise時,我們說些什麼Promise
- 當我們談優化時,我們談些什麼優化
- 當我們在談零信任時,我們談的是什麼?
- 當我們談論MOD時,我們在談論什麼?
- 當我們聊kubernetes operator時,我們在聊些什麼
- 當我們呼叫Express的res.render的時候Express
- 當我們的執行 java -jar xxx.jar 的時候底層到底做了什麼?JavaJAR
- 當我們談論版權保護的時候
- 當 Redis 發生高延遲時,到底發生了什麼Redis
- 我們該學習什麼?
- 當我們擔心人工智慧時,我們擔心什麼?人工智慧
- 當我呼叫了$().append()後,jQuery內部發生了什麼?APPjQuery
- 為什麼程式設計師在學習程式設計的時候什麼都記不住?程式設計師
- 當我們在談論極簡時,我們在談論什麼
- 當我們談深度學習時,我們用它落地了什麼?阿里雲內容安全功能全新升級深度學習阿里
- 當我們開發一個介面時需要注意些什麼
- 【iOS】當我們在application:DidFinishLaunchWithOptions:中返回NO時會發生什麼iOSAPP
- 智慧音響,什麼時候才能讓我們滿意?
- 在Linux中,我們都知道,dns採用了tcp協議,又採用了udp協議,什麼時候採用tcp協議?什麼 時候採用udp協議?為什麼要這麼設計?LinuxDNSTCP協議UDP
- 當我們在談論HTTP快取時我們在談論什麼HTTP快取
- 當我們談論格鬥遊戲時,我們在談論什麼遊戲
- 當我們在討論遊戲社群時,我們在討論什麼?遊戲
- 當我們在聊 RN 時,我們在聊什麼 | 技術點評
- 當我們建立HashMap時,底層到底做了什麼?HashMap
- 當提到“事件驅動”時,我們在說什麼?事件