為什麼要用Tair來服務低延時場景-從購物車升級說起
「購物車升級」是今年雙十一的重要體驗提升專案,體現了大淘寶技術人“用技術突破消費者和商家體驗天花板”的態度。這是一種敢於不斷重新自我審視,然後做出更好選擇的存在主義態度。
「體驗提升」通常表現在以前需要降級的功能不降級,以前不夠實時的資料逐漸實時,以前呼叫鏈路的長耗時逐步降低——這通常是龐大的系統工程,需要涉及到的每一個環節(客戶端、應用、中介軟體、資料庫、網路、容器、系統核心等元件)提供最強的產品能力來支撐。到資料庫這個環節,挑戰通常是訪問量和連線數暴漲的前提下,仍要保持延時穩定和成本可控。
低延時是這些挑戰裡面的核心,是記憶體資料庫 Tair 提供的服務本質。在高吞吐、大連線數、熱點請求、異常流量、複雜計算邏輯、彈性伸縮這些真實場景下保持穩定的低延時,是 Tair 能夠在低延時場景被選擇的關鍵因素。 作為今年支撐購物車升級的核心產品,Tair 使用的記憶體/SCM 混合儲存、水平擴充套件分割槽無鎖和 SQL 引擎等技術是在支撐十四次雙十一的過程中逐漸打磨完善的,在這些技術的基礎上 Tair 使用 Fast Path 執行 SQL 、執行器模式及運算元適配等技術持續進行服務端最佳化。本文將圍繞 Tair 低延時這一本質特徵在構建時所採用的系統手段,藉此提出更多問題來探討,進一步打造更強大的記憶體資料庫。

Tair 在低延時場景下的服務能力
低延時的基石
儲存引擎的效能是資料庫低延時的基石。從功能上看,我們會關心儲存引擎提供的併發(執行緒安全、無鎖)、事務處理(MVCC、衝突識別、死鎖識別、操作原子性)、快照(標記資料集狀態、降低延遲、減少容量膨脹)等能力。這裡把併發放到後面論述,先看單次請求的延時,主要涉及到儲存介質和資料索引。
儲存介質
作為記憶體資料庫,Tair 在絕大部分場景使用單次訪問延時在 ns 級別的記憶體 / SCM 作為主要的儲存介質。以 Table 儲存為例,服務端的常駐資料大概可以分為 Tuple(可以認為是表裡面的某一行)、String Pool、Index 三部分,這些資料都是存放在記憶體 / SCM 中,只有快照和日誌會存放在磁碟上。
除了儲存介質的延時,通常我們還需要關心的是介質的成本。成本一方面是從硬體上,Tair 是率先採用 SCM 的雲產品,相對於 DRAM,SCM 的密度更高能支援持久化,且成本更低。上面提到的三部分資料結構中, Tuple 和 String Pool 是主要佔用資料的空間,存放在空間更大的 SCM 上,Index 需要頻繁訪問且佔用空間更低,存放在空間較小延時更低的 DRAM 上。
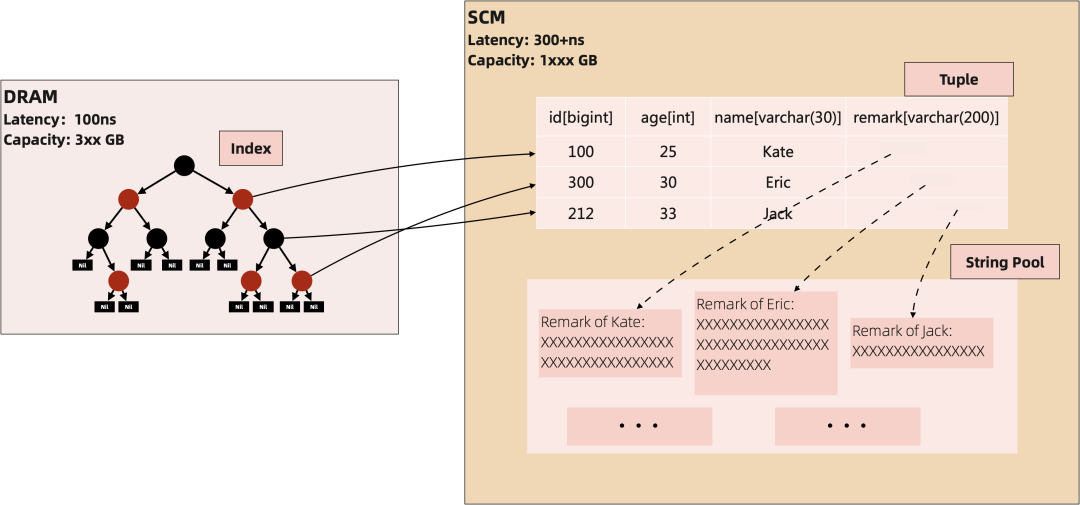
另外一方面是從資料結構上去降低成本,這裡的技術手段包括,設計更友好的資料結構和碎片整理的機制、進行透明的資料壓縮。Tair 中會以 Page 為單位來管理 Tuple,隨著資料的刪除,每個 Page 會有一些空閒的 Tuple,儲存引擎會按照空閒率來對 Page 分組,當整體的空閒率高於一定閾值(預設是 10%)時,就會試圖根據空閒率進行頁的合併。
索引
Tair 目前在使用的索引主要有 HashTable、SkipList、RBTree、RTree、Number Tree、Inverted index 等,分別應用於不同的場景。索引和需要服務的模型是相關聯的,比如如果服務的主要模型是 Key-Value,那麼主索引使用 HashTable 來達到 O(1)的時間複雜度,ZSet 涉及到資料排序和排名的獲取,所以 Zset 使用了一個可以在查詢時同時獲取 Rank 的 Skiplist 作為索引。排序場景使用 SkipList 作為索引是記憶體資料庫中比較常見的方案,相較於 BTree 來說,由於沒有 Structure Modification,更易於實現併發和無鎖,當然,也會增加一些 Footprint。在 Table 儲存中,使用 RBTree 作為排序索引,在資料量達到 10k 的場景下,RBTree 能夠提供更穩定的訪問延時和更低的記憶體佔用。
在資料庫系統中,索引能力的增強還可以讓執行器對外暴露更強的運算元,比如 Tair 中的 RBTree 提供了快速計算兩個值之間 Count 的能力,對外提供了 IndexCountOperator,這樣類似於 Select count(*) from person where age >= 8 and age <= 25 的查詢就可以直接使用 IndexCountOperator 來獲取結果,無需樸素地呼叫 IndexScanOperator -> AggregateOperator對索引進行掃描才得出結果。

低延時的挑戰
合適的儲存介質和索引只是提供低延時的一個前提,要在真實環境提供低延時的記憶體資料庫服務,至少需要經歷高吞吐的磨練。剛才我們關注了單個請求的延時,介質的延時和索引操作的時間複雜度會影響單個請求的延時。如果一個資料庫節點需要承擔每秒數十萬的請求,這些是不夠的,資料庫節點需要擁有良好的併發能力。如果吞吐近一步增長,帶來的 CPU、網路消耗已經超過了單機的極限的時候,比如大促峰值時 Tair 某叢集每秒提供了數千萬的讀,這些讀會帶來數萬兆的網路流量消耗,這時候就需要產品能夠支援水平擴充套件,“凡治眾如寡,分數是也”,把請求散落到不同的 Sharding,提供穩定的低延遲。
高併發
併發是低延時場景一個關鍵挑戰。解法通常分為兩種,一種是在儲存引擎內部支援更細粒度的鎖或者無鎖的併發請求;還有一種是在儲存引擎外部來進行執行緒模型的最佳化,保證某一部分資料(一般來說是一個分割槽)只被一個執行緒處理,這樣就能夠在單執行緒引擎之上構建出高吞吐的能力。
早期的版本中,Tair 的鎖粒度是例項級別的,鎖開銷損耗較大。為了提升單機的處理能力,Tair 引入了 RCU 無鎖引擎,實現記憶體 KV 引擎的無鎖化訪問,成倍提升了記憶體引擎的效能,相關工作發表在 FAST20 上:《HotRing: A Hotspot-Aware In-Memory Key-Value Store》。

在提升單機引擎的併發上,SQL 場景使用了另外一種解法,讓每一個 Partition 的資料由一個單獨的執行緒來進行處理,這樣能在引擎內部透過增加分割槽達到線性的擴充套件,而且無需使用前面提到的無鎖實現中常會使用的重試步驟。相對於上面的方案,這種方案的工程難度更低,且能夠天然地支援 Serializable 的事務隔離級別,某一特定時刻只有一個事務能夠執行在特定的分割槽上,增加 undo buffer 即可以保證事務的原子性。
但是使用這種方式需要滿足一些假設:對每個 Partition 的訪問是均衡的;跨 Partition 的訪問比較少。如果某個 Partition 存在熱點訪問,也就是明顯高出其它的 Partition,由於只有一個執行緒能處理這個 Partition 的資料,很容易造成這個 Parition 的請求堆積;如果出現跨 Partition 的訪問,就需要在各個 Partition 之間做同步,這樣也會造成等待並影響併發效能。目前支援的優惠、購物車場景都是使用者維度的,表中的 partition column 都是 buyer_id,所以單個請求基本是針對某一個特定分割槽的,資料鏈路不存在跨分割槽請求。資料統計呼叫的類似於 Select count(*) from table這種請求,由於儲存引擎的支援,單分割槽內可以 O(1) 的時間返回,所以也不存在問題。當然,對於 delete * from table 這種跨分割槽的寫操作,目前會對請求造成秒級抖動,未來會加入 Lazy Free 的處理邏輯,降低對正常請求的影響。

水平擴充套件
水平擴充套件是應對高吞吐的有效手段之一。水平擴充套件為分散式系統帶來了應對高吞吐的能力,但同時相對於單節點的系統而言,也會帶來很多挑戰,比如:跨節點的請求如何保證事務性;如何彈性地進行節點增減;如何應對節點的失效等。在 Tair 的大部分場景而言,並不存在需要保證跨分割槽請求的原子性。Tair 的 SQL 引擎也支援跨節點的分散式事務,但是這些分散式事務一般不是常規的業務訪問,而是運維類的操作。
對於很多系統而言,分割槽和節點是 N 對1 的關係(常見於 Hash 分割槽),採用固定的分割槽數,和動態的節點數是一種常見的解決方案,比如說 Redis Cluster,在這類系統中,彈性地進行節點增減的問題就轉換為如何在節點前進行分割槽遷移的問題。也有一些系統的分割槽和節點是 1對1 的(常見於 Range 分割槽),比如 HBase,在這類系統中,彈性伸縮的問題就轉換為分割槽分裂的問題了。
對於節點失效,涉及到判活和後續的資料處理兩類的問題。對於很多系統而言,冗餘和分片是分開的,比如 Redis Cluster、MongoDB、AnalyticDB Worker,即有一個 HA Group 的概念,HA Group 中的每一個節點,資料是完全一致的。不同系統處理的時候依然會有些區別,一些系統 HA Group 中的某一個節點所有分割槽都是 Leader,我們稱為 Leader 節點,提供讀寫服務,其它節點只有冗餘資料的同步流量,稱為 Follower 節點,比如 Redis Cluster,這類系統在排程系統不夠成熟的時期,有一個明顯的短板就是 Follower 節點所在的機器資源是有空餘的,通常是透過樸素的混布來提供資源的利用率,但也帶來了部署上的複雜度,所以在系統設計的時候就會有這樣的考量:能不能在 HA Group內分散這些分割槽的 Leader 呢,於是就有了下面這些系統。一些系統 HA Group 的每一個節點都承擔部分分割槽的 Leader,這就是每個節點都會提供讀寫服務,比如 AnalyticDB Worker。這類有 HA Group 的系統,判活和後續資料處理一般只在 HA Group 內,即某個節點失效後,會把訪問流量轉移到 HA Group 內的其它節點,然後透過上層的排程在 HA Group 內補充新的節點。還是老問題,在排程系統還不夠成熟的時期,補充新的節點也會帶來運維的複雜度,那就會有新的考量:能不能跨越 HA Group 的限制,把冗餘的個數和系統內節點的個數解耦呢?於是就有了 Kudu 這類系統的架構,冗餘和分片是交織起來的,某一個節點失效之後,它上面的分割槽會由中心節點來排程到其它節點。在排程能力非常成熟的今天,資料庫系統自身的能力怎麼和資料庫相關的排程能力想結合,也會給系統架構帶來新的啟發。

超大連線數
連線數的限制是一個比較容易被忽略的約束。但在一個真實的系統中,連線數過多會給系統帶來巨大的壓力。比如說 Redis,即使在 6.0 支援了多 io 之後,能夠支援的連線數也是有限的。而目前直接訪問 Tair 的應用動輒有 100k 規模的容器數目,所以支援很多連線數是一個必選項。其中涉及到的技術主要是幾方面:a. 提高多執行緒 io 的能力,目前成熟的網路框架基本都有這個能力;b. 把 io 執行緒和 worker 執行緒解耦,這樣可以獨立增強 worker 的處理能力,避免對 io 產生阻塞,當然這個策略取決於 worker 的工作負載,對於單次處理延時穩定較小的場景,支援無鎖併發後,整個鏈路使用 io 執行緒處理避免執行緒切換是更優的方案;c. 輕量化連線,把關聯到連線上的業務邏輯和 io 功能剝離開,可以更加靈活地做針對性的最佳化,一些系統中連線對資源的消耗較大,一個連線需要消耗 ~10M 的記憶體資源,這樣連線數就比較難以擴充套件了。
穩定的低延時
現在有了高效的儲存引擎和水平擴充套件,已經具備了提供低延時和高吞吐服務的能力,但是成為一個健壯地提供低延時的資料庫系統還需要能夠應對一些異常的場景,比如說某一個分割槽有熱點訪問,比如說某個租戶的流量異常對其它租戶產生干擾,比如說某些慢請求消耗了大量的服務資源。本章節將介紹 Tair 是如何處理這些“異常”場景來提供穩定的低延時的。
熱點策略
熱點訪問是商品維度、賣家維度的資料常常會遇到的一個挑戰,熱點方案也是 Tair 能夠服務於低延時場景的關鍵能力。前面講了水平擴充套件之後,使用者的某個請求就會根據一定的規則(Hash、Range、List 等)路由到某一個分割槽上,如果存在熱點訪問,就會造成這一個分割槽的訪問擁塞。處理熱點有很多方案,比如二級雜湊,這種方案對於熱點的讀寫可以做進一步拆分的場景是有用的,比如現在我們有一個賣家訂單表,然後賣家 id 是分割槽列,則我們可以再以訂單 id 做一次二級雜湊,解決一個大賣家導致的熱點問題;目前淘寶大規模使用的 Tair 的 KV 引擎不滿足使用二級雜湊的前提,一般來說商品的資訊對映到 Tair 內就是某一個 Value,更新和讀取都是原子的。所以 Tair 目前使用的方案是在一層進行雜湊,藉助於和客戶端的互動,將熱點資料分散到叢集當中的其它節點,共同來處理這個熱點請求,當然這種方案需要應用接受熱點在一定時間內的延遲更新。另外這種方案需要客戶端和服務端協同,需要應用升級到對應的客戶端才能使用。所以最新的 Tair 熱點策略在相容社群 Redis 的服務時使用了不同的方案,應用能夠直接使用任一流行的開源客戶端進行訪問,因此需要在服務端提供獨立的熱點處理能力。目前的 Tair 熱點能力是由 Proxy 來提供的,相對於 Tair 之前的方案,這種方案擁有更強大的彈性和更好的通用性。
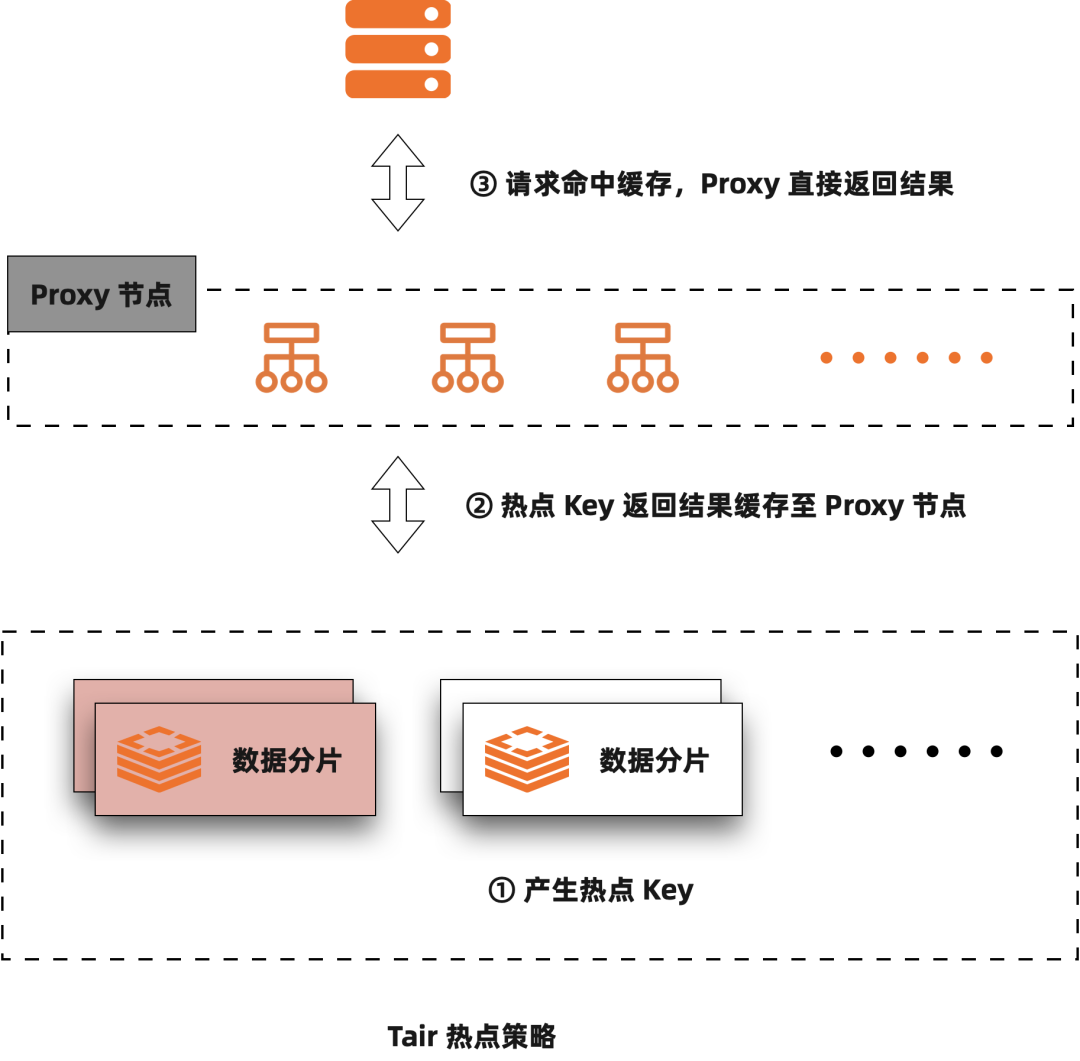
流控
服務於多租戶的資料庫系統,解決資源隔離的問題通常需要對進行容量或者訪問量的配額管理來保證 QoS。即使服務於單租戶的系統,也需要在使用者有突發異常流量時,保證系統的穩定性,識別出異常流量進行限制,保證正常流量不受影響,比如 Tair 中對於 慢 SQL 識別和阻斷。再退一步,即使面對無法識別的異常流量,如果判斷請求流量已經超過了服務的極限,按照正常的行為進行響應會對服務端造成風險,需要進行 Fast Fail,並保證服務端的可用性,達到可用性防禦的目的,比如 Tair 在判斷有客戶端的 Output Buffer 超過一定記憶體閾值之後,就會強制 Kill 掉客戶端連線;在判斷目前排隊的請求個數或者回包占用的記憶體超過一定閾值之後,就會構造一個流控的回包並回復給客戶端。
流控一般包含以下幾部分內容:請求資源消耗的統計,這部分是為流控策略和行為提供資料支撐;流控的觸發,一般是給資源消耗設定一個閾值,如果超過閾值就觸發;流控的行為,這部分各個系統根據服務的場景會有較大的不同;最後的流控的恢復,也是就是資源消耗到達什麼情況下解除流控。
執行流程最佳化
經典的 NoSQL 系統,提供的 API 都是和服務端的處理流程非常耦合的,比如說 Redis 提供了很多 API,光是 List 就有 20 多個介面。在服務端其實很多介面的執行過程中的步驟是比較類似的,比如說有一些 GenericXXX 的函式定義。我們再看看一般的 RDBMS 中的處理 SQL 的流程,一般是 解析(從 SQL 文字到 AST),然後是最佳化器編譯 (把 AST 編譯成運算元,TableScan、Filter、Aggregate),然後是執行器來執行。類比到 Redis 中,使用者傳進來的就是 AST,且服務端已經預定了執行計劃,直接執行就行了。如果我想使用 SQL,不想學習這麼多 API,同時由於我的訪問場景是比較固定的,比如進行模板化之後,只有十多種 SQL 語句,且訪問的資料比較均衡,某一條特定的語句所有的引數用一條特定的索引就足夠了,有沒有辦法在執行過程中省去解析、編譯的開銷來提高執行的效率?有很多同學可能已經想到了儲存過程。是的,儲存過程很多場景是在擴充表達能力,比如多條語句組成的儲存過程,需要進行比較複雜的邏輯判斷,單條語句儲存過程本質上是在靈活性和效能上進行折衷。Tair 所有線上執行的 SQL 都是預先建立儲存過程的,這樣進行訪問就類似於呼叫 Redis 的一個 API 了,這是在複雜計算邏輯的場景下保證低延時的一種方案。
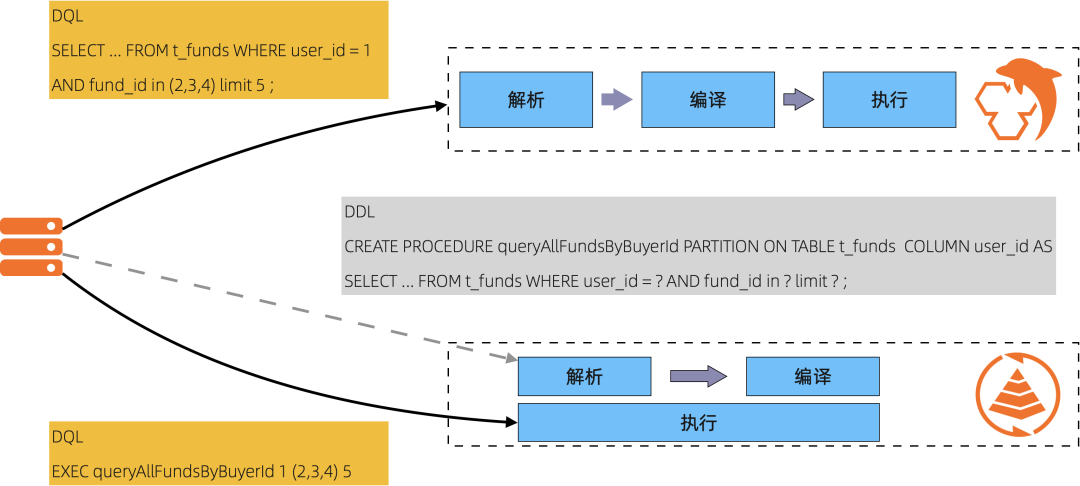
很多熟悉資料庫實現的同學對火山執行模型都不陌生,tuple-at-a-time 的執行方式會消耗比較多的 cpu cycle,對 cache locality 也不太友好。在分析場景,通常會引入 code-gen 技術來進行最佳化,比如 Snowflake、GreenPlum。Tair 中使用 Pipeline 執行模型,使用 Bulk Processing 更適合目前應用的 TP 場景。使用 Pipeline 執行模型對於運算元的設計和執行計劃的生成更有挑戰,以 Scan 運算元為例,Scan 運算元中內聯了 Filter、Aggregate 和 Projection,Scan 運算元本身邏輯比較多,且在執行計劃編譯過程需要在邏輯最佳化階段進行運算元內聯的轉換。
更多場景的低延時
從最早的 KV 到擴充套件的 Pkey-Skey-Value,再到 List、Zset,再到支援地理位置的 GIS,再到支援全文索引的 Search 和 Table 結構 的 SQL,Tair 早已不再是一個單純用來儲存熱資料的快取,而是能夠把更多儲存上構建的計算能力方便地提供給業務使用的記憶體資料庫。這一章節介紹記憶體資料庫 Tair 在雙十一場景的應用。
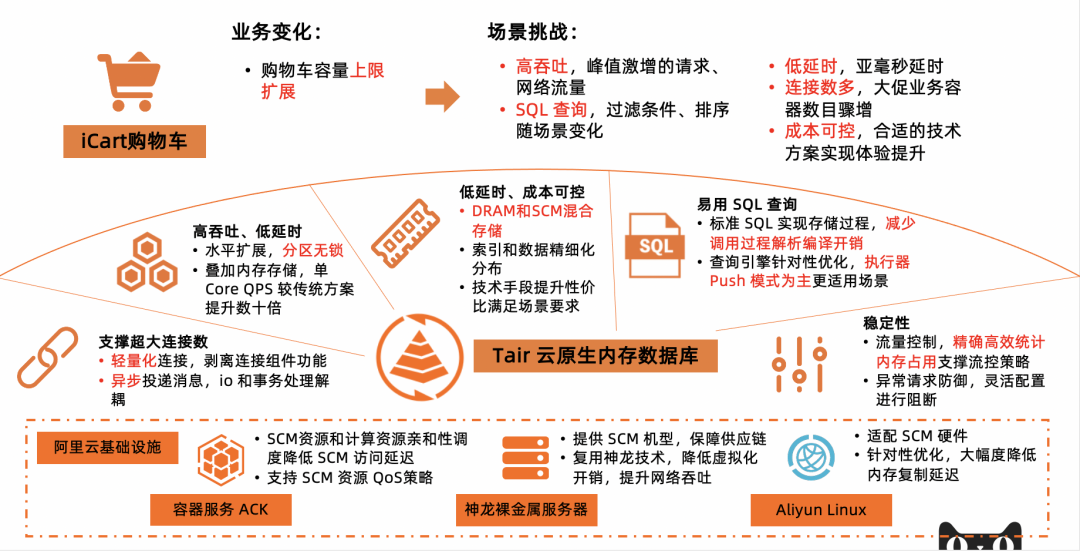
購物車使用 Tair 支撐容量升級
提到 MySQL,開發者很容易想到 Table 模型,想到 SQL 查詢來進行過濾、排序、聚合等操作;想到 Redis,很容易想到高吞吐、低延時。使用 Redis 來進行讀加速的場景,都需要把 MySQL 中資料查詢出來之後,序列化到某一個 Value,加速場景直接獲取 Value 即可,無需再進行過濾、排序等操作。如果一個讀加速的場景不僅需要高吞吐低延時,也需要進行過濾等操作,Redis 還能夠滿足需求麼?更進一步,如果引入讀加速的過程中不希望改變資料模型,依然希望使用表模型,省去模型轉換的心智負擔,同時擁有高吞吐低延時,支撐 10w 級別的連線數,需要使用什麼產品呢?目前優惠查詢和購物車的場景的需求抽象出來就是這樣,這種需要關係型資料庫超級只讀的場景就需要引入 Tair 的 SQL引擎,兼有 MySQL 和 Redis 優勢的產品。
銷量統計使用 Tair 提升實時計算
歷史上雙十一因無法解決銷量的實時計算問題對商家產生過很多困擾。為應對2022年雙十一,Tair 銷量計數專案應運而生:利用已有的 Tair 非精確“去重計數”運算元開發新的“去重求和”運算元,解決使用者商品銷量計數慢而無法實時獲得銷量資料的痛點問題。透過對使用者的商品訂單訊息進行原子地“去重和銷量的實時求和”能力,雙十一首次做到了“買家訂單數不降級”、“商品月銷量不降級”兩項大促核心體驗。同時,利用 Tair-PMem 底座進一步幫助使用者降低使用成本,提升資料持久化能力。相比於傳統的 AP 類資料庫,透過開發的獨特非精確計算運算元,有效降低了單 QPS 的計算成本。
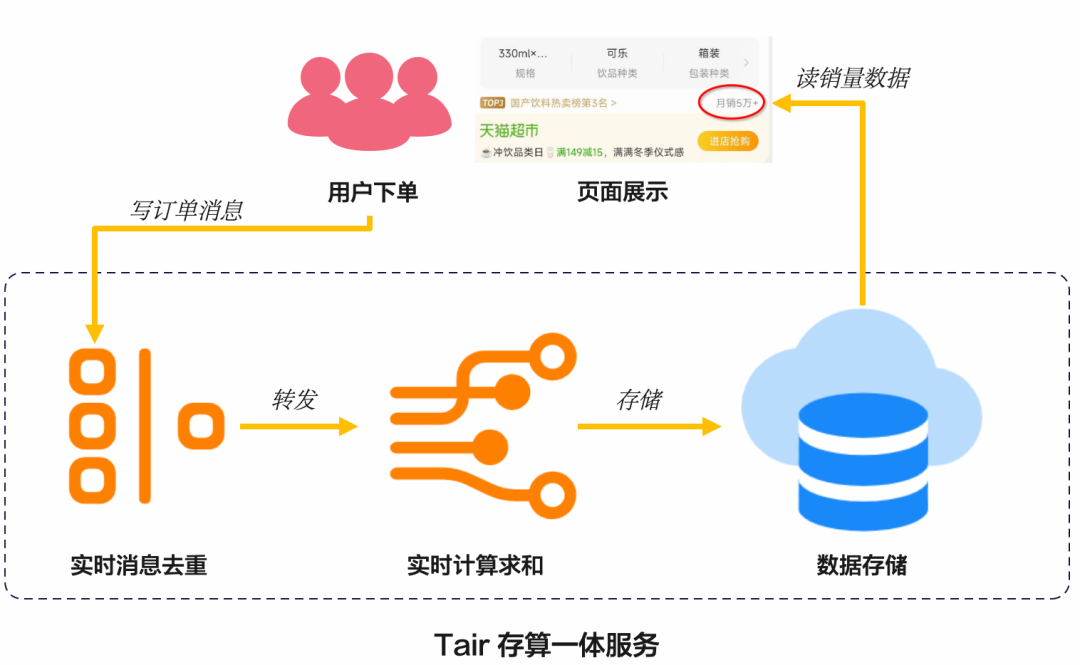
淘菜菜使用 Tair 進行賣家優惠券召回
淘菜菜是阿里社群電商對外的統一品牌,賣家維度的優惠券召回作為一個重要的功能模組,需要搜尋系統滿足低成本、實時索引和低延遲的搜尋能力。鑑於之前使用的搜尋系統無法滿足需求,淘菜菜今年雙十一首次使用 TairSearch 能力實現賣家維度優惠券召回功能,Tair 以其高效實時的記憶體索引技術為商家提供更加平滑友好的操作體驗。
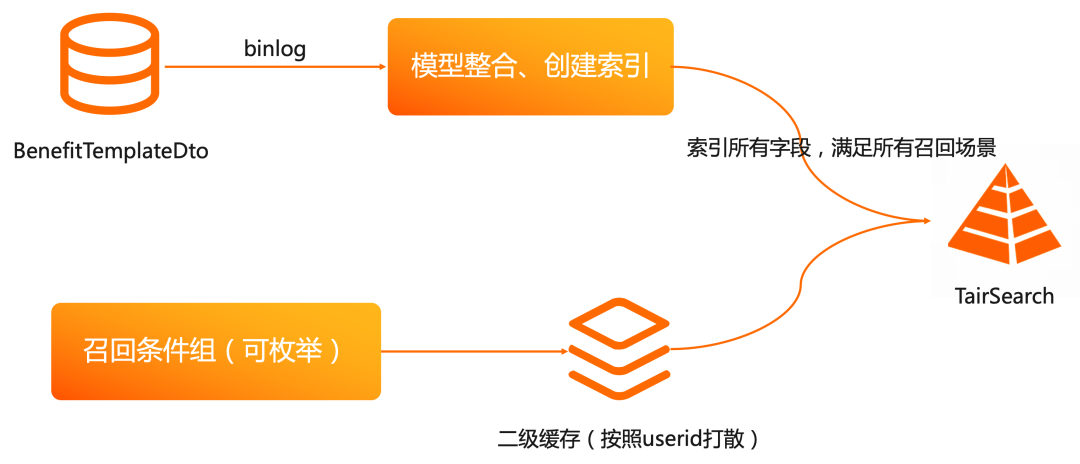
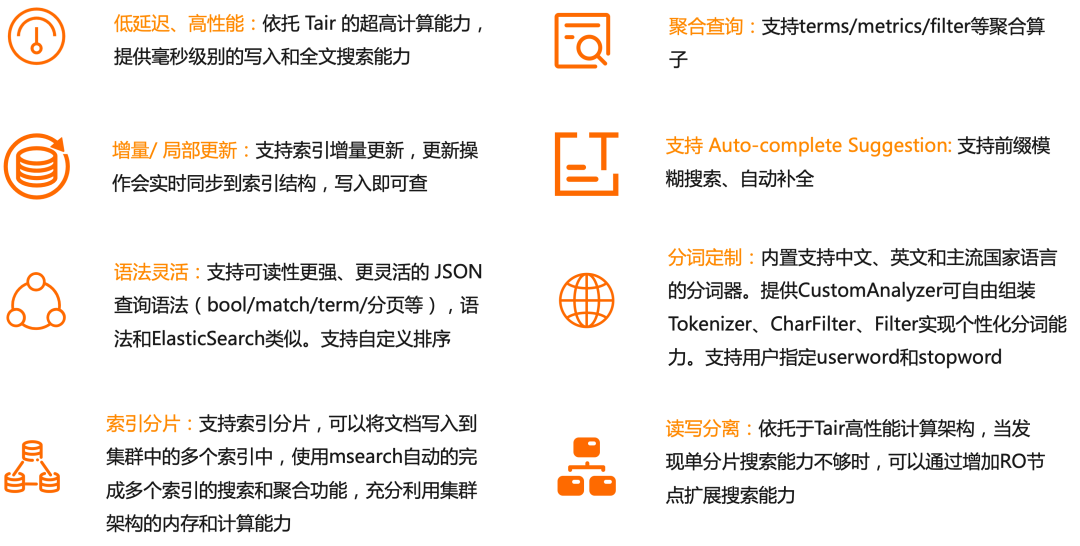
TairSearch 是Tair自主研發的高效能、低延時、基於記憶體的實時搜尋特性,不但增強了 Tair 在實時計算領域的能力,還和現有的其他資料結構一起為使用者提供一站式的資料解決方案。Tair採用了和 ElasticSearch(下文稱之為ES)相似的基於 JSON 的查詢語法,滿足了靈活性的同時還相容ES使用者的使用習慣。Tair 除了支援 ES 常用的分詞器,還新增JIEBA 和 IK 中文分詞器,對中文分詞更加友好。Tair支援豐富的查詢語義和聚合能力,並且支援索引實時更新和區域性更新。Tair 可以透過 msearch 方案實現索引的分片和搜尋能力,並透過讀寫分離架構實現搜尋效能的水平擴充套件。
判店場景使用 Tair 解決熱點商家判店
隨著同城購業務的興起,商戶判店場景越來越流行,判店就是商家給自己的一個門店圈出來一個銷售範圍,可以是行政區域,也可以是不規則形狀,或者按照半徑圈選,如果消費者在這個銷售範圍內就認為門店對該消費者可售,如果不在消費範圍內則不可售,抽象此模型則是:點和多邊形包含關係的判斷。
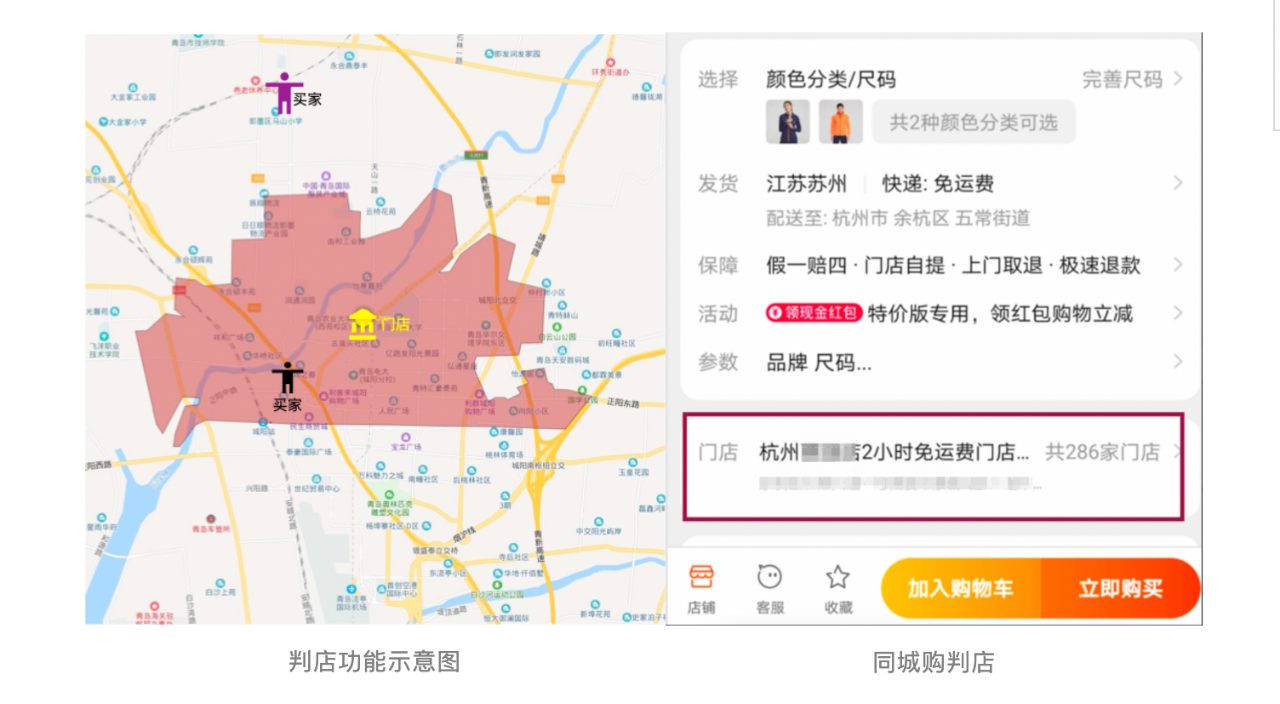
傳統的判店架構使用 MySQL 或者 PostGis 資料庫,雖然其對 GIS 相關能力有專業的支援,API 也比較完備,但是由於其本身磁碟儲存的特性,查詢速度較慢,特別是資料量較大的場景下,產生多次磁碟讀 IO,導致業務查詢超時。
新一代判店系統,依託 Tair 的 Gis 能力,底層使用 RTree 結構,支援常見的 Contains, Within, Intersects 等關係判斷,可以在 ms 級別返回查詢資料,目前已經在淘菜菜、天貓超市、淘鮮達、盒馬、同城購等多個業務使用。
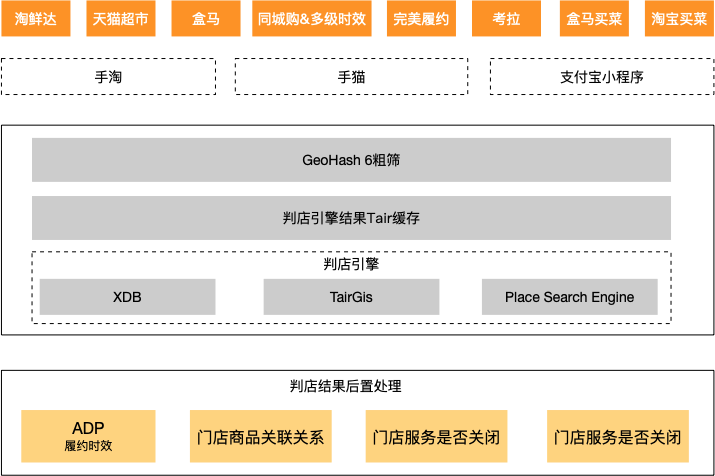
TairGis 的新一代判店系統
互動場景使用 Tair 多種高效能資料結構快速支撐業務
雙十一主互動場景一直是技術挑戰最大的場景之一,一方面參與活動的使用者數量大,在活動時間集中活躍,帶來的大量的訪問請求對資料庫層面的衝擊尤其巨大;另一方面要求活動體驗不降級,對延時的要求更高。今年主互動活動--猜價格,使用了 Tair 單一資料庫的模式支撐了整個互動活動。在主互動場景中,Tair 作為KV資料庫支撐幾乎所有的資料儲存和讀寫,後端無 DB 兜底,是唯一的資料來源,除了要求讀寫的低延遲、高併發以外,還要求資料的絕對安全無丟失。

TairHash 提供的高併發寫入能力確保了千萬級使用者的答案提交順暢;TairZSet 提供的有序資料結構,幫助應用在10s內計算出千萬體量的使用者分數排行榜,並支撐快速查詢;帶有二級Key 主動過期的 TairHash 為業務設計復活卡、拉新、錦鯉抽獎等多種玩法提供了方便而強大的技術支撐。
Tair 已經在這一類需要低延遲、高併發、資料安全、快速開發的業務場景中表現出了強大的能力,還將持續追求更高效能、更易用、更安全。
寫在最後
在產品力上,Tair 提供了遠遠不止以上圍繞著低延時來打造的產品能力,比如資料多副本管理、全球多活、任意時間點恢復、審計日誌等等。同時 Tair 在相容 Redis 之外,提供了豐富的資料處理能力和基於不同儲存介質的混合引擎來提升價效比。
2022 年還有一些其它的事情在發生:Tair 的論文發表在資料庫領域頂會 VLDB ,雲原生記憶體資料庫 Tair 獨立產品上線阿里雲官網,Tair 全自研 Redis 相容核心在公共雲所有 Region 上線等等。有一些成績,也有很多挑戰,還有更多機會。Tair 會將已經具備的能力建設得更通用,並在新的領域尋求新的突破,在更豐富的低延時場景承擔起更重要的責任,為客戶創造更多價值。
來自 “ 阿里開發者 ”, 原文作者:付秋雷(漠冰);原文連結:http://server.it168.com/a2022/1130/6778/000006778014.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 工位出租,場景服務領域升級
- springboot為什麼要用延遲匯入?Spring Boot
- 為什麼要用setTimout來做定時器?定時器
- 為什麼說軟體服務的未來必然是WebAssembly?Web
- 為什麼要用Redis?Redis為什麼這麼快?(來自知乎)Redis
- 華為面試題:購物車問題(01揹包演算法升級)面試題演算法
- 什麼是svg?說說svg有什麼運用場景?SVG
- 周朝陽:A級景區為什麼會時時降價打折
- 從《全境封鎖2》的近況說起:玩家們對服務型遊戲究竟能忍到什麼時候?遊戲
- 低延時音影片技術在OPPO雲渲染場景的應用
- 微服務為什麼一定要用docker微服務Docker
- 為什麼要用dockerDocker
- 為什麼要用docker?Docker
- 為什麼要用RedisRedis
- 從服務之間的呼叫來看 我們為什麼需要Dapr
- 程式設計為什麼那麼難:從儲值卡扣款說起程式設計
- 為什麼說“概率”帶來一場現代革命?
- 為什麼要用混合加密?加密
- 為什麼要用SOCKS代理?
- Go-kratos 框架商城微服務實戰之購物車服務 (十二)Go框架微服務
- 企業為什麼要用雲端計算?企業購買雲端計算時需要注意什麼?
- IT 服務管理可以為你帶來什麼好處?
- 為什麼說儲存是區塊鏈最佳落地應用場景區塊鏈
- 說說如何使用 Vue.js 開發購物車功能Vue.js
- 我們為什麼要用RedisRedis
- 為什麼要用單例模式?單例模式
- 為什麼要用資料中臺
- 為什麼要用where 1=1
- 為什麼要用Node.jsNode.js
- 為什麼要用工廠模式模式
- 為什麼要用Redis叢集?Redis
- 什麼?你的新年購物車裡竟然沒有TA?
- day01-從一個基礎的socket服務說起
- 智慧小車開發篇 - 低時延直播測試
- Nvidia為什麼收購Mellanox?這篇說透了
- 為什麼說資料服務是資料中臺的標配?
- 高德“3D”視界,為生活服務行業帶來新升級3D行業
- 什麼業務場景適合使用Redis?Redis