HDFS 塊和 Input Splits 的區別與聯絡
轉載自
過往記憶(https://www.iteblog.com/)
本文連結:
【HDFS 塊和 Input Splits 的區別與聯絡】(https://www.iteblog.com/archives/2365.html)
相信大家都知道,
HDFS
將檔案按照一定大小的塊進行切割,(我們可以通過
dfs.blocksize
引數來設定
HDFS
塊的大小,在
Hadoop
2.x 上,預設的塊大小為 128MB。)也就是說,如果一個檔案大小大於 128MB,那麼這個檔案會被切割成很多塊,這些塊分別儲存在不同的機器上。當我們啟動一個 MapReduce 作業去處理這些資料的時候,程式會計算出檔案有多少個 Splits,然後根據 Splits 的個數來啟動 Map 任務。那麼 HDFS 塊和 Splits 到底有什麼關係?
為了簡便起見,下面介紹的檔案為普通文字檔案。
HDFS塊
現在我有一個名為 iteblog.txt 的檔案,如下:
[iteblog@iteblog.com /home/iteblog]$ ll iteblog.txt -rw-r--r-- 1 iteblog iteblog 454669963 May 15 12:07 iteblog.txt
很明顯,這個檔案大於一個 HDFS 塊大小,所有如果我們將這個檔案存放到 HDFS 上會生成 4 個 HDFS 塊,如下(注意下面的輸出做了一些刪除操作):
[iteblog@iteblog.com /home/iteblog]$ hadoop -put iteblog.txt /tmp [iteblog@iteblog.com /home/iteblog]$ hdfs fsck /tmp/iteblog.txt -files -blocks /tmp/iteblog.txt 454669963 bytes, 4 block(s): OK 0. BP-1398136447-192.168.246.60-1386067202761:blk_8133964845_1106679622318 len=134217728 repl=3 1. BP-1398136447-192.168.246.60-1386067202761:blk_8133967228_1106679624701 len=134217728 repl=3 2. BP-1398136447-192.168.246.60-1386067202761:blk_8133969503_1106679626977 len=134217728 repl=3 3. BP-1398136447-192.168.246.60-1386067202761:blk_8133970122_1106679627596 len=52016779 repl=3
可以看出 iteblog.txt 檔案被切成 4 個塊了,前三個塊大小正好是 128MB(134217728),剩下的資料存放到第 4 個 HDFS 塊中。
如果檔案裡面有一行記錄的偏移量為 134217710,長度為 100,HDFS 如何處理?
答案是這行記錄會被切割成兩部分,一部分存放在 block 0 裡面;剩下的部分存放在 block 1 裡面。具體的,偏移量為134217710,長度為18的資料存放到 block 0 裡面;偏移量134217729,長度為82的資料存放到 block 1 裡面。 可以將這部分的邏輯以下面的圖概括
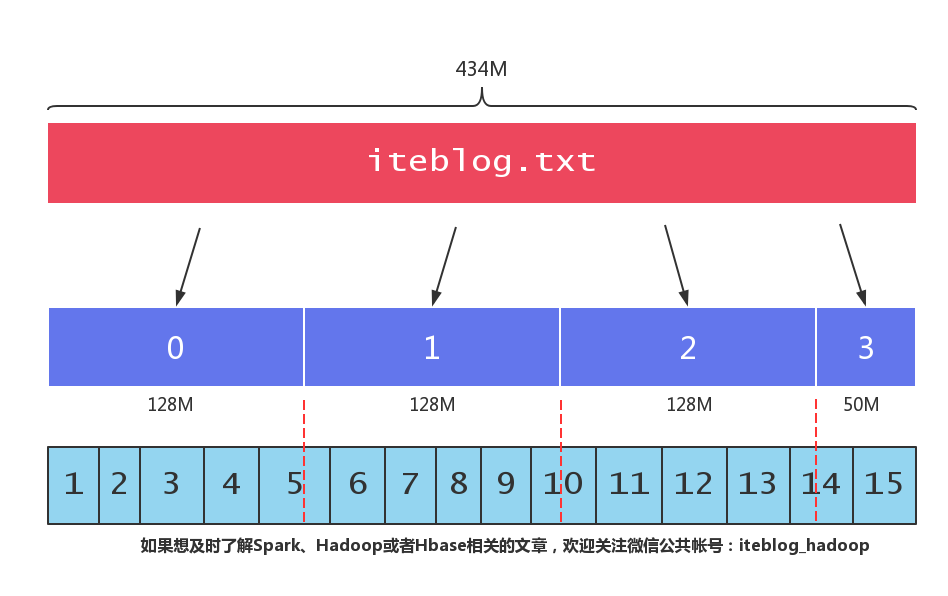
說明:
-
圖中的紅色塊代表一個檔案
-
中間的藍色矩形塊代表一個 HDFS 塊,矩形裡面的數字代表 HDFS 塊的編號,讀整個檔案的時候是從編號為0的 HDFS 塊開始讀,然後依次是1,2,3...
-
最下面的一行矩形代表檔案裡面儲存的內容,每個小矩形代表一行資料,裡面的數字代表資料的編號。紅色的豎線代表 HDFS 塊邊界(block boundary)。
從上圖我們可以清晰地看出,當我們往 HDFS 寫檔案時,HDFS 會將檔案切割成大小為 128MB 的塊,切割的時候不會判斷檔案裡面儲存的到底是什麼東西,所以邏輯上屬於一行的資料會被切割成兩部分,這兩部分的資料被物理的存放在兩個不同的 HDFS 塊中,正如上圖中的第5、10以及14行被切割成2部分了。
File Split
現在我們需要使用 MapReduce 來讀取上面的檔案,由於是普通的文字檔案,所以可以直接使用
TextInputFormat
來讀取。下面是使用
TextInputFormat
獲取到的
FileSplit
資訊:
scala> FileInputFormat.addInputPath(job,new Path("/tmp/iteblog.txt"));
scala> val format = new TextInputFormat;
scala> val splits = format.getSplits(job)
scala> splits.foreach(println)
hdfs://iteblogcluster/tmp/iteblog.txt:0+134217728
hdfs://iteblogcluster/tmp/iteblog.txt:134217728+134217728
hdfs://iteblogcluster/tmp/iteblog.txt:268435456+134217728
hdfs://iteblogcluster/tmp/iteblog.txt:402653184+52016779
可以看出,每個 FileSplit 的起始偏移量和上面 HDFS 每個檔案塊一致。但是具體讀資料的時候,MapReduce 是如何處理的呢?我們現在已經知道,在將檔案儲存在 HDFS 的時候,檔案被切割成一個一個 HDFS Block,其中會導致一些邏輯上屬於一行的資料會被切割成兩部分,那
TextInputFormat
遇到這樣的資料是如何處理的呢?
對於這種情況,
TextInputFormat
會做出如下兩種操作:
-
在初始化
LineRecordReader的時候,如果FileSplit的起始位置start不等於0, 說明這個 Block 塊不是第一個 Block,這時候一律丟掉這個 Block 的第一行資料。 -
在讀取每個 Block 的時候,都會額外地多讀取一行,如果出現資料被切割到另外一個 Block 裡面,這些資料能夠被這個任務讀取。
使用圖形表示可以概括如下:

說明:
-
圖中的紅色虛線代表 HDFS 塊邊界(block boundary);
-
藍色的虛線代表Split 讀數的邊界。
從圖中可以清晰地看出:
-
當程式讀取 Block 0 的時候,雖然第五行資料被分割並被儲存在 Block 0 和 Block 1 中,但是,當前程式能夠完整的讀取到第五行的完整資料。
-
當程式讀取 Block 1 的時候,由於其
FileSplit的起始位置start不等於0,這時候會丟掉第一行的資料,也就是說 Block 1 中的第五行部分資料會被丟棄,而直接從第六行資料讀取。這樣做的原因是,Block 1 中的第五行部分資料在程式讀取前一個 Block 的時候已經被讀取了,所以可以直接丟棄。 -
其他剩下的 Block 讀取邏輯和這個一致。
總結
從上面的分析可以得出以下的總結
-
Split 和 HDFS Block 是一對多的關係;
-
HDFS block 是資料的物理表示,而 Split 是 block 中資料的邏輯表示;
-
滿足資料本地性的情況下,程式也會從遠端節點上讀取少量的資料,因為存在行被切割到不同的 Block 上。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/31473948/viewspace-2200044/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- javaSE中的==和equals的聯絡與區別Java
- 程式和執行緒的區別與聯絡執行緒
- cookie與session的區別與聯絡CookieSession
- Session與Cookie的區別與聯絡SessionCookie
- JRE與JDK的區別與聯絡JDK
- Instruction和Question的區別和聯絡Struct
- SCADA和PLC的區別聯絡
- Vue中watch、computed與methods的聯絡和區別Vue
- tcp/ip和http的區別和聯絡TCPHTTP
- http、socket、tcp的區別和聯絡?HTTPTCP
- Python中__new__和__init__的區別與聯絡Python
- Kafka與ActiveMQ的區別與聯絡詳解KafkaMQ
- 詳解Kafka與ActiveMQ的區別與聯絡!KafkaMQ
- B/S與C/S的聯絡與區別
- Rxjs map, mergeMap 和 switchMap 的區別和聯絡JS
- Unicode,UTF-8和UTF-16的區別與聯絡Unicode
- java-介面和抽象類的聯絡和區別。Java抽象
- 跟你深入剖析可迭代物件和迭代器的區別與聯絡物件
- `std::packaged_task`、`std::thread` 和 `std::async` 的區別與聯絡Packagethread
- 可觀測性與傳統監控的區別和聯絡
- 【Python入門必看】Python中Cookie和Session的區別與聯絡!PythonCookieSession
- 感知器、logistic與svm 區別與聯絡
- 區塊鏈和挖礦有什麼聯絡?區塊鏈
- ipv4與ipv6的聯絡與區別
- jQuery與JavaScript與ajax三者的區別與聯絡jQueryJavaScript
- 簡述Spring容器與SpringMVC的容器的聯絡與區別SpringMVC
- hive中order by、distribute by、sort by和cluster by的區別和聯絡Hive
- C/C++引用和指標的聯絡和區別C++指標
- 【知識點】 gcc和g++的聯絡和區別GC
- 產品經理和專案經理區別與聯絡
- KPI vs OKR:區別與聯絡的終極指南KPIOKR
- 單機、分散式、叢集的區別與聯絡分散式
- Linux中程式和執行緒的區別與聯絡,建議收藏!Linux執行緒
- 【科普】等級保護與分級保護的區別和聯絡!
- spring、springmvc、springboot、springcloud 之間的聯絡和區別SpringMVCSpring BootGCCloud
- 陣列地址與指標之間的區別與聯絡陣列指標
- 程序、執行緒和協程之間的區別和聯絡執行緒
- 模電和數電在應用上的區別和聯絡