作者:來自 vivo 網際網路伺服器團隊- Zheng Rui
本文結合個人理解梳理了BitMap及Roaring BitMap的原理及使用,分別主要介紹了Roaring BitMap的儲存方式及三種container型別及Java中Roaring BitMap相關API使用。
一、引言
在進行大資料開發時,我們可以使用布隆過濾器和Redis中的HyperLogLog來進行大資料的判重和數量統計,雖然這兩種方法節省記憶體空間並且效率很高,但是也存在一些誤差。如果需要100%準確的話,我們可以使用BitMap來儲存資料。
BitMap 點陣圖索引資料結構被廣泛地應用於資料儲存和資料搜尋中,但是對於儲存較為分散的資料時,BitMap會佔用比較大的記憶體空間,因此我們更偏向於使用 Roaring BitMap稀疏點陣圖索引進行儲存。同時,Roaring BitMap廣泛應用於資料庫儲存和大資料引擎中,例如Hive,Spark,Doris,Kylin等。
下文將分別介紹 BitMap 和 Roaring BitMap 的原理及其相關應用。
二、BitMap原理
BitMap的基本思想就是用bit位來標記某個元素對應的value,而key就是這個元素。
例如,在下圖中,是一個位元組代表的8位,下標為1,2,4,6的bit位的值為1,則該位元組表示{1,2,4,6}這幾個數。

在Java中,1個int佔用4個位元組,如果用int來儲存這四個數字的話,那麼將需要4 * 4 = 16位元組。
BitMap可以用於快速排序,查詢,及去重等操作。優點是佔用記憶體少(相較於陣列)和運算效率高,但是缺點也非常明顯,無法儲存重複的資料,並且在儲存較為稀疏的資料時,浪費儲存空間較多。
三、Roaring BitMap 原理
3.1 儲存方式
為了解決BitMap儲存較為稀疏資料時,浪費儲存空間較多的問題,我們引入了稀疏點陣圖索引Roaring BitMap。Roaring BitMap 有較高的計算效能及壓縮效率。下面簡單介紹一下Roaring BitMap的基本原理。
Roaring BitMap處理int型整數,將32位的int型整數分為高16位和低16位分別進行處理,高16位作為索引分片,而低16位用於儲存實際資料。其中每個索引對應一個資料桶(bucket),那麼一共可以包含2^16 = 65536個資料塊。每個資料桶使用container容器來儲存低16位的部分,每個資料桶最多儲存2^16 = 65536個資料。
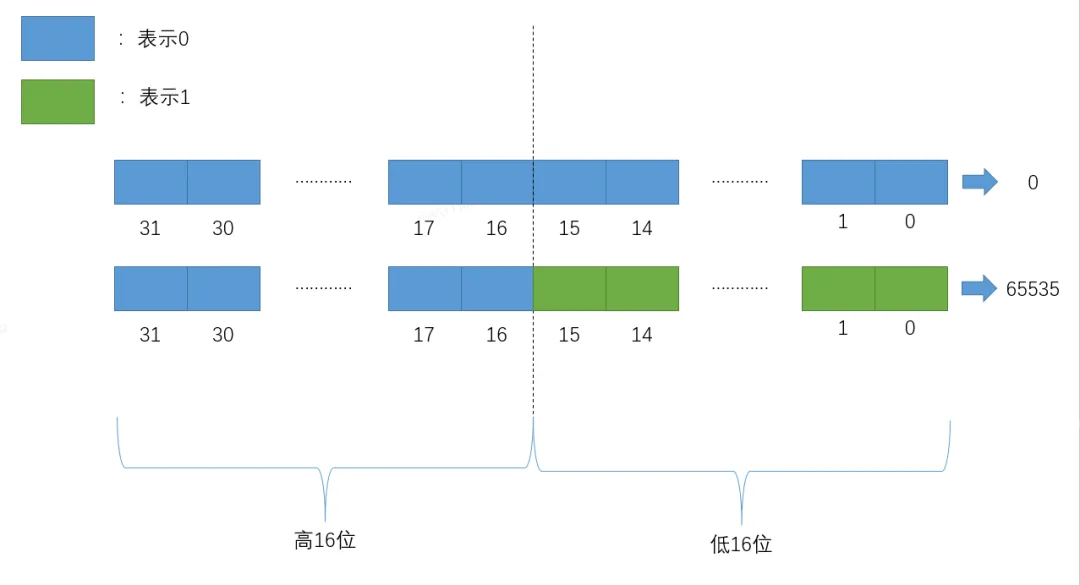
如上圖所示,高16位作為索引查詢具體的資料塊,當前索引值為0,低16位作為value進行儲存。
Roaring BitMap在進行資料儲存時,會先根據高16位找到對應的索引key(二分查詢),低16位作為key對應的value,先透過key檢查對應的container容器,如果發現container不存在的話,就先建立一個key和對應的container,否則直接將低16位儲存到對應的container中。
Roaring BitMap的精妙之處在於使用不同型別的container,接下來將對其進行介紹。
3.2 container型別
1.ArrayContainer
顧名思義,ArrayContainer直接採用陣列來儲存低16位資料,沒有采用任何資料壓縮演算法,適合儲存比較稀疏的資料,在Java中,使用short陣列來儲存,並且佔用的記憶體空間大小和資料量成線性關係。由於short為2位元組,因此n個資料為2n位元組。ArrayContainer採用二分查詢定位有序陣列中的元素,因此時間複雜度為O(logN)。ArrayContainer的最大資料量為4096, 4096 * 2b = 8kb。
2.BitMapContainer
BitMapContainer採用BitMap的原理,就是一個沒有經過壓縮處理的普通BitMap,適合儲存比較稠密的資料,在Java中使用Long陣列儲存低16位資料,每一個bit位表示一個數字。由於每個container需要儲存2^16 = 65536個資料,如果透過BitMap進行儲存的話,需要使用2^16個bit進行儲存,即8kb的資料空間。
可以從下圖中看出ArrayContainer和BitMapContainer的記憶體空間使用關係,當資料量小於4096時,使用ArrayContainer比較合適,當資料量大於等於4096時,使用BitMapContainer更佳。
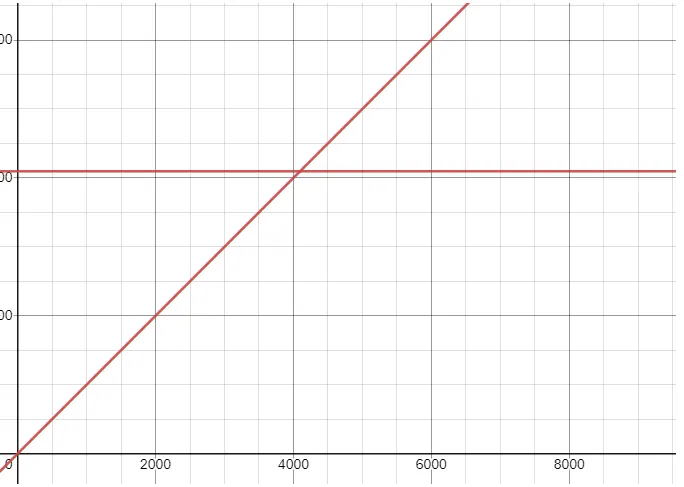
因為BitMap直接使用位運算,所以BitMapContainer的時間複雜度為O(1)。
3.RunContainer
RunContainer採用Run-Length Encoding 行程長度編碼進行壓縮,適合儲存大量連續資料。Java中使用short陣列進行儲存。連續bit位程度越高的話越節省儲存空間,最佳場景下(65536個資料全為1)只需要儲存4位元組。最差場景為所有資料都不連續,所有儲存資料位置為奇數或者偶數,這種場景需要儲存128kb。由於採用二分查詢演算法定位元素,因此時間複雜度為O(logN)。
行程長度編碼即的原理是對連續出現的數字進行壓縮,只記錄初始數字和後續連續數量。
例如:[1,2,3,4,5,8,9,10]使用編碼後的資料為[1,4,8,2]。
Java 裡可以使用runOptinize()方法來對比RunContainer和其他兩個Container儲存空間大小,如果使用RunContainer儲存空間更佳則會進行轉化。
根據上面三個Container型別我們可以得知如何進行選擇:
-
Container預設使用ArrayContainer,當元素數量超過4096時,會由ArrayContainer轉換BitMapContainer。
-
當元素數量小於等於4096時,BitMapContainer會逆向轉換回ArrayContainer。
-
正常增刪元素不會使Container直接變成RunContainer,而需要使用者進行最佳化方法呼叫才會轉換為最節省空間的Container。
3.3 Roaring BitMap 相關原始碼
介紹完Roaring BitMap的三種container型別以後,讓我們瞭解一下,Roaring BitMap的相關原始碼。這裡介紹一下Java中增加元素的原始碼實現。
public void add(final int x) {
final short hb = Util.highbits(x);
final int i = highLowContainer.getIndex(hb);
if (i >= 0) {
highLowContainer.setContainerAtIndex(i,
highLowContainer.getContainerAtIndex(i).add(Util.lowbits(x)));
} else {
final ArrayContainer newac = new ArrayContainer();
highLowContainer.insertNewKeyValueAt(-i - 1, hb, newac.add(Util.lowbits(x)));
}
}Roaring BitMap首先獲取新增元素的高16位,然後再呼叫getIndex獲取高16位對應的索引,如果索引大於0,表示已經建立該索引對應的container,故直接新增相應的元素低16位即可;否則的話,說明該索引對應的container還沒有被建立,先建立對應的ArrayContainer,再進行元素新增。值得一提的是,在getIndex方法中,使用了二分查詢來獲取索引值,所以時間複雜度為O(logn)。
// 包含一個二分查詢
protected int getIndex(short x) {
// 在二分查詢之前,我們先對常見情況最佳化。
if ((size == 0) || (keys[size - 1] == x)) {
return size - 1;
}
// 沒有碰到常見情況,我們只能遍歷這個列表。
return this.binarySearch(0, size, x);
}對於元素新增,三種Container提供了不同的實現方式,下面將分別介紹。
1. ArrayContainer
if (cardinality == 0 || (cardinality > 0
&& toIntUnsigned(x) > toIntUnsigned(content[cardinality - 1]))) {
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitMapContainer().add(x);
}
if (cardinality >= this.content.length) {
increaseCapacity();
}
content[cardinality++] = x;
} else {
int loc = Util.unsignedBinarySearch(content, 0, cardinality, x);
if (loc < 0) {
// 當標籤中元素數量等於預設最大值時,把ArrayContainer轉換為BitMapContainer
if (cardinality >= DEFAULT_MAX_SIZE) {
return toBitMapContainer().add(x);
}
if (cardinality >= this.content.length) {
increaseCapacity();
}
System.arraycopy(content, -loc - 1, content, -loc, cardinality + loc + 1);
content[-loc - 1] = x;
++cardinality;
}
}
return this;
}ArrayContainer把新增元素分成兩種場景,一種走二分查詢,另外一種不走二分查詢。
第一種場景:不走二分查詢。
當基數為0或者值大於container中的最大值,可以直接新增,因為content陣列是有序的,最後一個是最大值。
當基數大於等於預設最大值4096時,ArrayContainer將轉換為BitMapContainer。如果基數大於content的陣列長度的話,需要將content進行擴容。最後進行賦值即可。
第二種場景:走二分查詢。
先透過二分查詢找到對應的插入位置,如果返回loc大於等於0,說明存在,直接返回即可,如果小於0才進行後續插入。後續操作同上,當基數大於等於預設最大值4096時,ArrayContainer將轉換為BitMapContainer。如果基數大於content的陣列長度的話,需要將content進行擴容。最後透過複製陣列將元素插入到content陣列中。
2. BitMapContainer
public Container add(final short i) {
final int x = Util.toIntUnsigned(i);
final long previous = BitMap[x / 64];
long newval = previous | (1L << x); BitMap[x / 64] = newval;
if (USE_BRANCHLESS) {
cardinality += (previous ^ newval) >>> x;
} else if (previous != newval) {
++cardinality;
}
return this;
}BitMap陣列為BitMapContainer的儲存容器存放資料的內容,資料型別為long,在這裡我們只需要找到x在BitMap中的位置,並且把相應的bit位置1即可。x/64就是找到對應long的舊值,1L<<x 就是把對應的bit位置為1,再跟舊值進行或操作,就可以得到新值,再將這個新值存回到bitmap陣列即可。<="" span="">
3. RunContainer
public Container add(short k) {
int index = unsignedInterleavedBinarySearch(valueslength, 0, nbrruns, k);
if (index >= 0) {
return this;// already there
}
index = -index - 2;
if (index >= 0) {
int offset = toIntUnsigned(k) - toIntUnsigned(getValue(index));
int le = toIntUnsigned(getLength(index));
if (offset <= le) {
return this;
}
if (offset == le + 1) {
// we may need to fuse
if (index + 1 < nbrruns) {
if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {
// indeed fusion is needed
setLength(index,
(short) (getValue(index + 1) + getLength(index + 1) - getValue(index)));
recoverRoomAtIndex(index + 1);
return this;
}
}
incrementLength(index);
return this;
}
if (index + 1 < nbrruns) {
// we may need to fuse
if (toIntUnsigned(getValue(index + 1)) == toIntUnsigned(k) + 1) {
// indeed fusion is needed
setValue(index + 1, k);
setLength(index + 1, (short) (getLength(index + 1) + 1));
return this;
}
}
}
if (index == -1) {
// we may need to extend the first run
if (0 < nbrruns) {
if (getValue(0) == k + 1) {
incrementLength(0);
decrementValue(0);
return this;
}
}
}
makeRoomAtIndex(index + 1);
setValue(index + 1, k);
setLength(index + 1, (short) 0);
return this;
}RunContainer中的兩個資料結構,nbrruns表示有多少段行程,資料型別為int,valueslength陣列表示所有的行程,資料型別為short。
-
首先,使用二分查詢+順序查詢在valueslength陣列中查詢元素k的插入位置index。如果查詢到的index結果大於等於0那就說明k是某個行程起始值,已經存在,直接返回。
-
-index-2是為了指向前一個行程起始值的索引。
-
接下來是一些偏移量和索引值的判斷,主要是為了確認k是否落在上一個行程裡,或者外面,如果落在上一個行程裡,則直接返回,否則需要新建一個行程或者就近與一個行程混合並且將行程長度加1。
3.4 BitMap 和 Roaring BitMap 儲存情況對比
public static void count(Integer inputSize) { RoaringBitMap BitMap = new RoaringBitMap(); BitMap.add(0L, inputSize);
//獲取BitMap個數
int cardinality = BitMap.getCardinality();
//獲取BitMap壓縮大小
int compressSizeIntBytes = BitMap.getSizeInBytes();
//刪除壓縮(移除行程編碼,將container退化為BitMapContainer 或 ArrayContainer) BitMap.removeRunCompression();
//獲取BitMap不壓縮大小
int uncompressSizeIntBytes = BitMap.getSizeInBytes();
System.out.println("Roaring BitMap個數:" + cardinality);
System.out.println("最好情況,BitMap壓縮大小:" + compressSizeIntBytes / 1024 + "KB");
System.out.println("最壞情況,BitMap不壓縮大小:" + uncompressSizeIntBytes / 1024 / 1024 + "MB");
BitSet bitSet = new BitSet();
for (int i = 0; i < inputSize; i++) {
bitSet.set(i);
}
//獲取BitMap大小
int size = bitSet.size();
System.out.println("BitMap個數:" + bitSet.length());
System.out.println("BitMap大小:" + size / 8 / 1024 / 1024 + "MB");
}上述程式碼使用了Java內建的BitMap(BitSet) 和 Roaring BitMap進行儲存大小對比,輸出結果如下所示。
-
Roaring BitMap個數:1000000000
-
最好情況,BitMap壓縮大小:149KB
-
最壞情況,BitMap不壓縮大小:119MB
-
Roaring BitMap個數:1000000000
-
BitMap大小:128MB
可以發現,Roaring BitMap的壓縮效能效果非常好,同等情況下,是BitMap佔用記憶體的近一千分之一。在退化成BitMapContainer/arrayContainer之後也仍然比使用基本的BitMap儲存效果好一些。
四、Roaring BitMap 使用
4.1 Java 中相關 API 使用
在Java中,Roaring BitMap提供了交併補差集等操作,如下程式碼所示,列舉了Java中roaing BitMap的相關API使用方式。
//新增單個數字
public void add(final int x)
//新增範圍數字
public void add(final long rangeStart, final long rangeEnd)
//移除數字
public void remove(final int x)
//遍歷RBM
public void forEach(IntConsumer ic)
//檢測是否包含
public boolean contains(final int x)
//獲取基數
public int getCardinality()
//位與,取兩個RBM的交集,當前RBM會被修改
public void and(final RoaringBitMap x2)
//同上,但是會返回一個新的RBM,不會修改原始的RBM,執行緒安全
public static RoaringBitMap and(final RoaringBitMap x1, final RoaringBitMap x2)
//位或,取兩個RBM的並集,當前RBM會被修改
public void or(final RoaringBitMap x2)
//同上,但是會返回一個新的RBM,不會修改原始的RBM,執行緒安全
public static RoaringBitMap or(final RoaringBitMap x1, final RoaringBitMap x2)
//異或,取兩個RBM的對稱差,當前RBM會被修改
public void xor(final RoaringBitMap x2)
//同上,但是會返回一個新的RBM,不會修改原始的RBM,執行緒安全
public static RoaringBitMap xor(final RoaringBitMap x1, final RoaringBitMap x2)
//取原始值和x2的差集,當前RBM會被修改
public void andNot(final RoaringBitMap x2)
//同上,但是會返回一個新的RBM,不會修改原始的RBM,執行緒安全
public static RoaringBitMap andNot(final RoaringBitMap x1, final RoaringBitMap x2)
//序列化
public void serialize(DataOutput out) throws IOException
public void serialize(ByteBuffer buffer)
//反序列化
public void deserialize(DataInput in) throws IOException
public void deserialize(ByteBuffer bbf) throws IOException對於序列化來說,Roaring BitMap官方定義了一套序列化規則,用來保證不同語言實現的相容性。
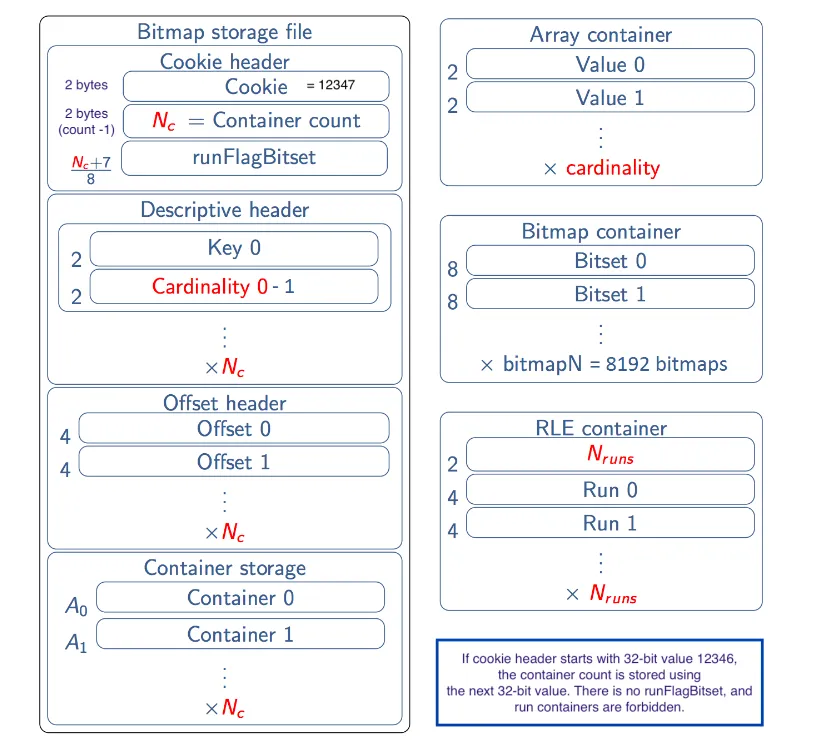
Java中可以使用serialize方法進行序列化,deserialize方法進行反序列化。
4.2 業務實際場景應用
Roaring BitMap可以用來構建大資料標籤,針對型別特徵來建立對應的標籤。
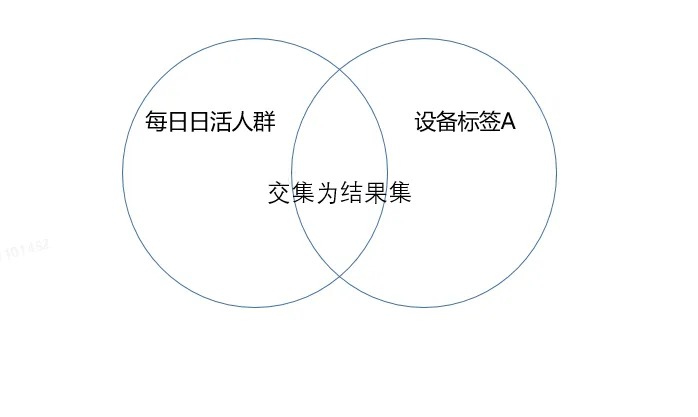
在我們的業務場景中,有很多需要基於人群標籤進行交併補集運算的場景,下面以一個場景為例,我們需要計算每天某個裝置介面 在裝置標籤A上的查詢成功率,因為裝置標籤A中的裝置不是所有都活躍在網的,所以我們需要將裝置標籤A與每日日活人群標籤取交集,得到的交集大小才能用作成功率計算的分母,另外拿查詢成功的標籤人群做分子來進行計算即可,查詢時長耗時為1s。
假如沒有使用標籤儲存集合之前,我們需要在hive表中查詢出同時滿足當天在網的活躍使用者和裝置A的使用者數量,查詢時長耗時在幾分鐘以上。兩種方式相比之下,使用Roaring BitMap查詢的效率更高。
五、總結
本文結合個人理解梳理了BitMap及Roaring BitMap的原理及使用,分別主要介紹了Roaring BitMap的儲存方式及三種container型別及Java中Roaring BitMap相關API使用,如有不足和最佳化建議,也歡迎大家批評指正。
參考資料:
-
Chambi S , Lemire D , Kaser O , et al.
Better BitMap performance with Roaring
BitMaps[J]. Software—practice & Experience, 2016, 46(5):709-719.
-
https://RoaringBitMap.org/
-
https://github.com/RoaringBitMap/RoaringFormatSpec