快手關於海量模型資料處理的實踐
01
模型場景介紹
1. 實時大模型

*本文資料具有即時性,不代表實時資料。
快手的模型場景主要是實時的大模型。實時主要體現在社交上。每天都有新使用者上傳 1500 萬以上的影片,每天有億級以上的直播活躍使用者,並且上傳數每年都在同比上漲。
大主要體現在流量規模。快手現在的日活達到了 3.87 億,有千億級別的日均曝光,百億級別的日均播放,模型量級非常大,還要保證實時。並且快手的核心價值觀是平等普惠,即千萬級的使用者同時線上時,個性化請求時會推薦不同的內容。
總結起來,資料處理的特點是既大,又要實時。
2. 推薦業務複雜
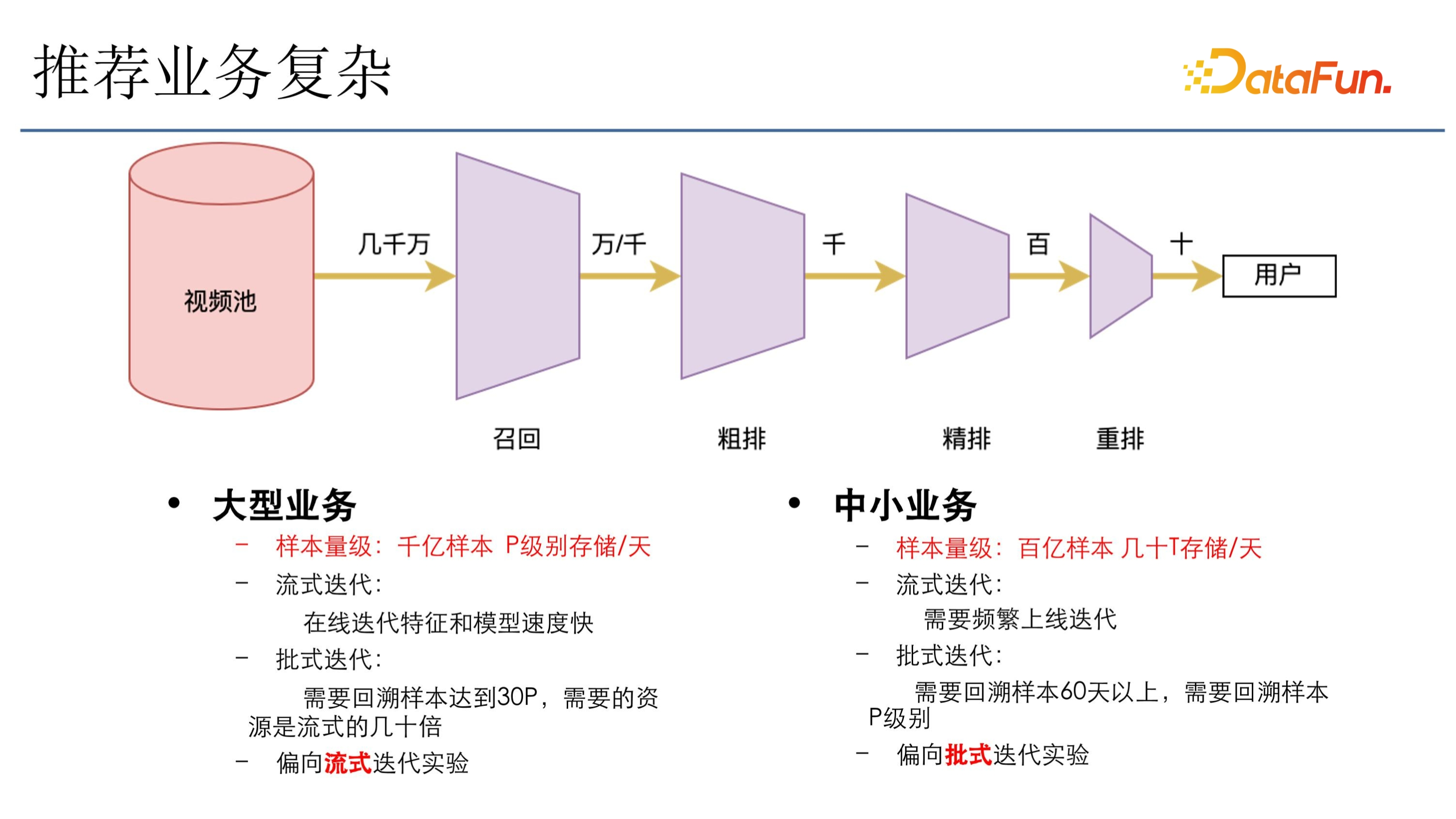
一般的推薦業務架構如上圖所示,在影片池裡(比如有幾千萬的影片)會經過固定的四個階段:(1)召回:從幾千萬的影片裡召回幾萬或者幾千的影片;(2)粗排:透過一個粗排漏斗,選出幾千的影片;(3)精排:幾千的影片又會透過精排,篩選 top 幾百的影片;(4)重排:進入重排,給出模型打分,做模型校驗;(5)返回:加上一些機制和多樣化操作,最後選出幾十個結果返回給使用者,整個漏斗要求非常高。
快手的業務型別比較多樣,主要可以分成大型業務和中小型業務。
大型業務的樣本量級很大,像主站推薦一天的樣本可能有千億,儲存能達到 p 的級別。迭代主要用流式迭代,即線上迭代特徵和模型,速度會非常快。如果選用批式迭代的話,回溯樣本要 30 天,需要的資源是流式迭代的幾十倍,快手大場景下的流量分配又比較多,所以傾向於做線上的流式迭代實驗,速度快,消耗資源量相對也少很多。
中小業務,一天的樣本大約在百億級別,儲存大概幾十 T。選擇流式迭代會需要頻繁上線迭代,而且流量分配也不夠。這種情況下一般儘量選用批式迭代,此時需要很大量級的計算樣本,比如要回溯至少 60 天以上,回溯樣本能達到 p 級別。因為對於大模型來說,如果資料量不夠,模型訓練不充分,效果就會相應地下降。所以在這種小的業務場景裡,還是傾向於批式迭代,回溯更多天的樣本,以使模型達到一個更穩定的狀態。在這種場景下面,會傾向於批次迭代實驗。
3. 推薦模型的資料量
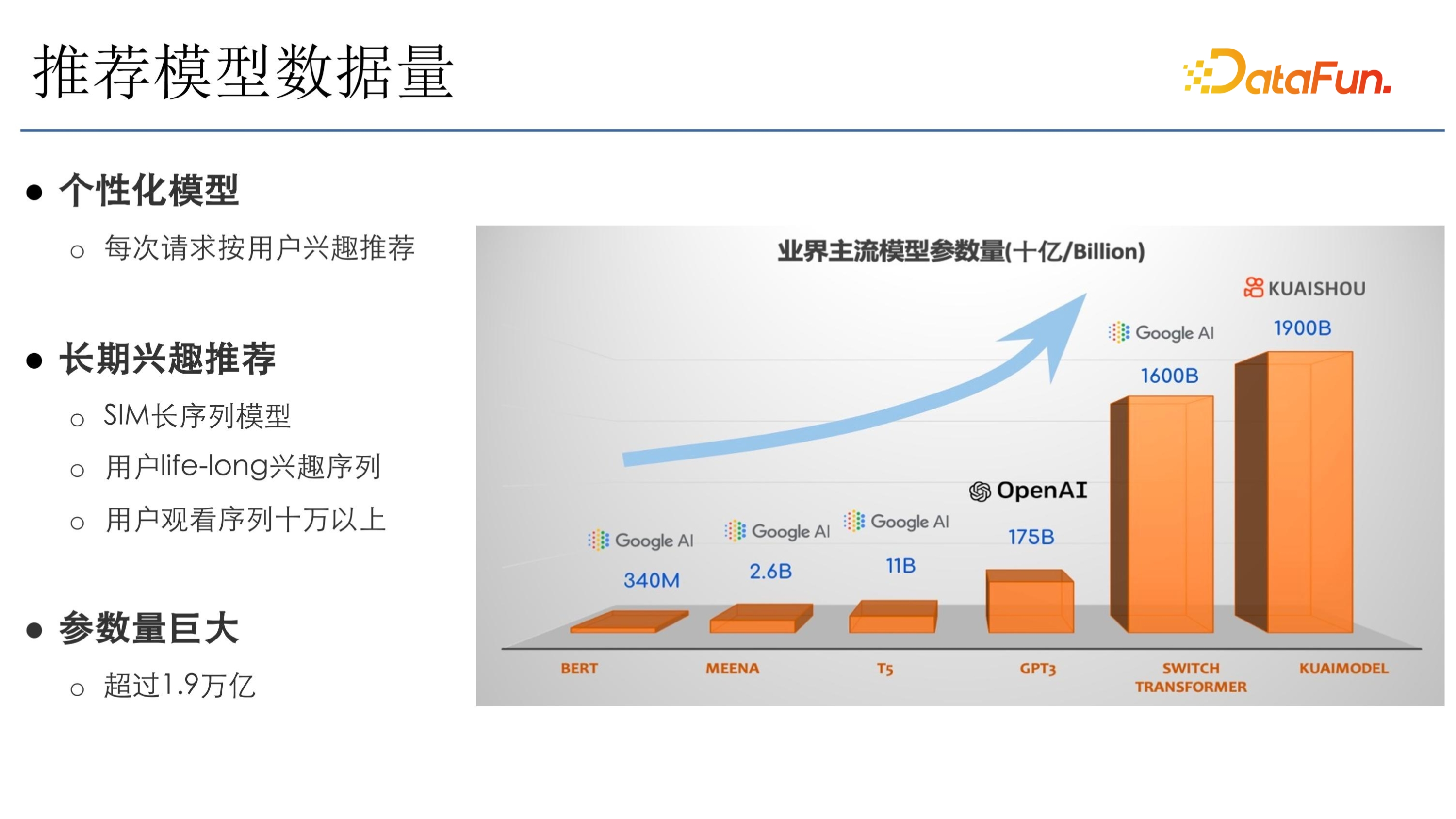
這裡是之前在快手釋出的一個萬億級別模型文章裡的截圖,快手是個性化模型,所以引數量非常大。從圖中對比來看,OpenAI 的 GPT3 引數量是 175B,但快手引數量 1900B,已經到萬億級別了。主要是因為快手選用的是 SIM 長序列模型,需要使用者長期的興趣,然後把該序列輸入到模型。快手有億級使用者,life-long 興趣需 10 萬以上序列,再加上千億級的樣本的疊加,因此引數量非常大,能達到 1.9 萬億。雖然這 1.9 萬億引數跟 OpenAI 的 GPT 3 模型的引數型別不一樣,計算量也不太一樣。但從引數量級上來看,快手推薦是非常大的。
4. 語言模型的演進
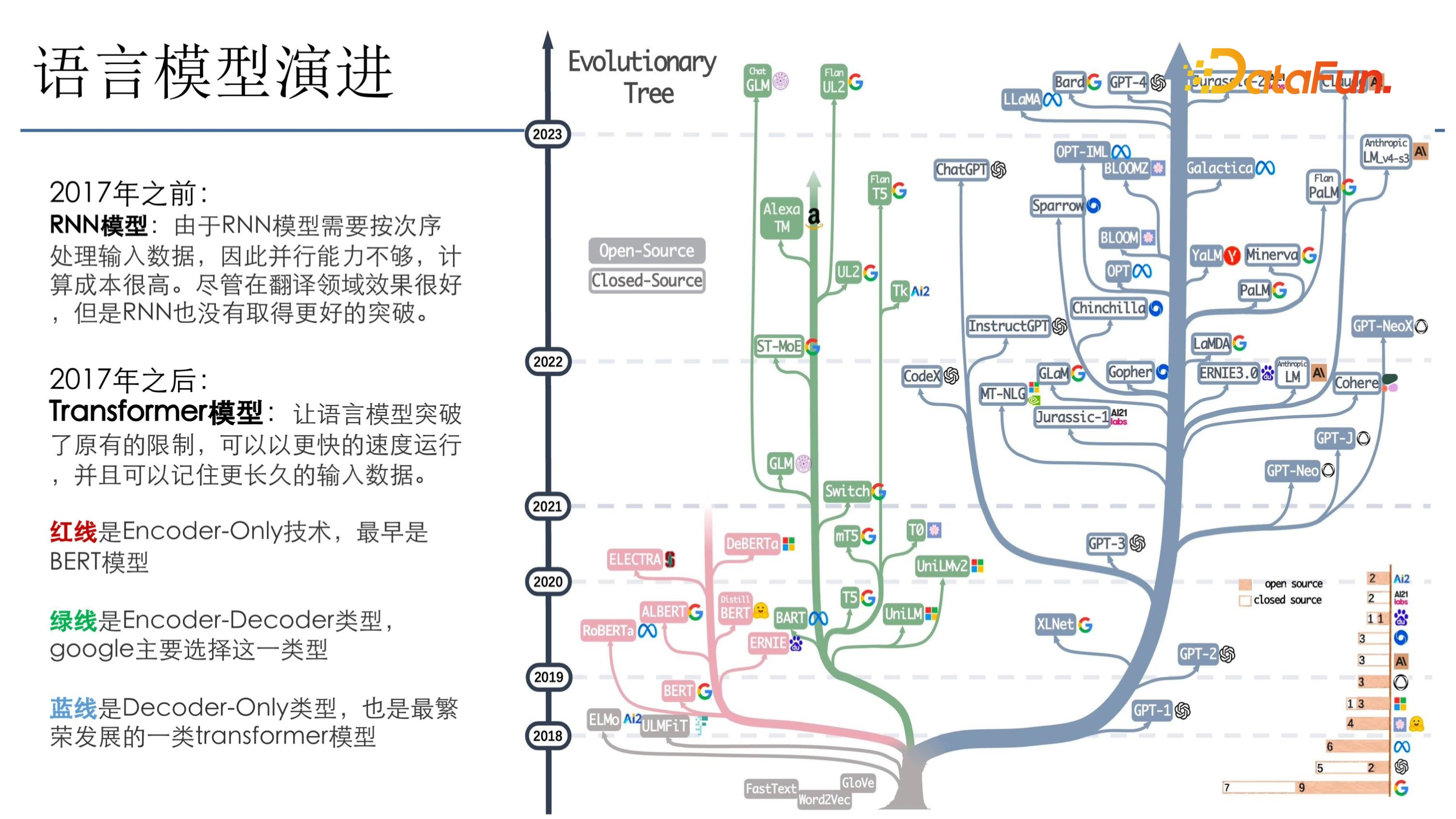
推薦模型跟語言模型緊密相關,一般新模型都會在語言模型上去做迭代,成功之後就會引入推薦模型,比如 DN、RNN、Transformer。上圖是亞馬遜 3 月份時釋出的一個圖,主要介紹了語言模型的一些進展。
可以看到,17 年之前主要是 RNN 模型,RNN 模型是按次序去順序遍歷資料後訓練,該模型對並行算力要求並不高,但模型收斂比較複雜,因為可能會存在梯度消失的問題。2017 年出現 Transformer 之後,語言模型突破了原有的限制,可以做併發迭代,所以其算力大規模增長。
圖中的樹分為三個部分:(1)紅線部分是 encoder-only 技術,最早是 Bert 模型;(2)綠線是 encoder-decoder 型別,Google 主要選擇這一型別;(3)藍線主要是 open API 裡 ChatGPT 選用的型別,這一類模型發展得最好,因為它足夠簡單,只需要考慮 decoder,運算量小,而且模型效果也會很好。
02
大規模模型資料處理
1. 背景-實效性
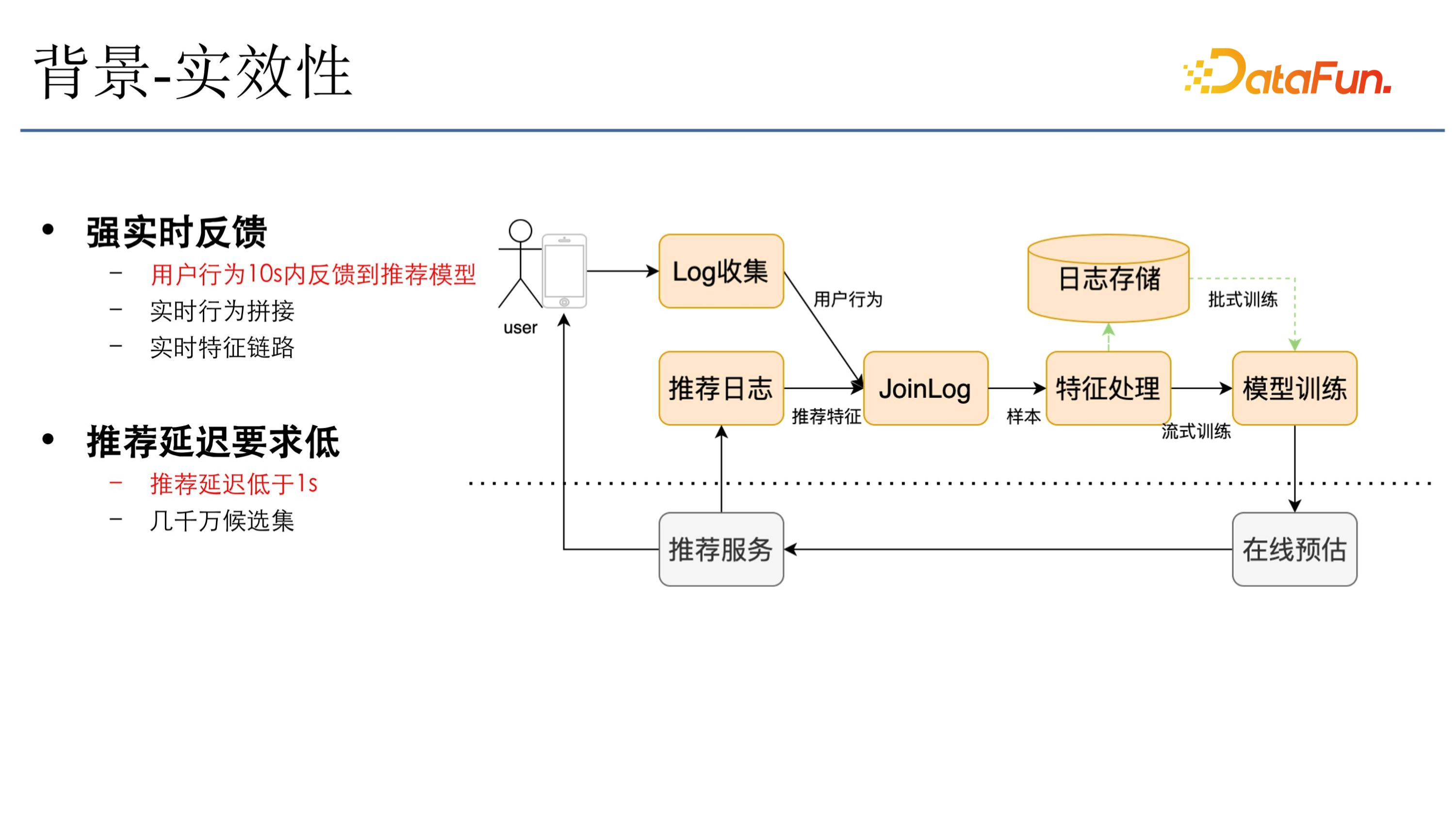
快手對資料時效性要求很高,使用者看到影片後會反饋到快手的 log 收集系統,該使用者的行為會實時地拼接推薦日誌(推薦日誌就是推薦服務落下來的特徵),特徵流加上行為流成為樣本流進入後面的特徵處理,然後進入模型訓練。模型訓練完成後實時更新到線上預估,線上預估會根據模型的更新推薦出最符合使用者需求的一些影片。該鏈路要求延遲必須要在一秒內,需要將使用者行為儘快反饋到模型裡,所以對於大資料處理的時效性要求是非常高的。
2. 大資料量處理
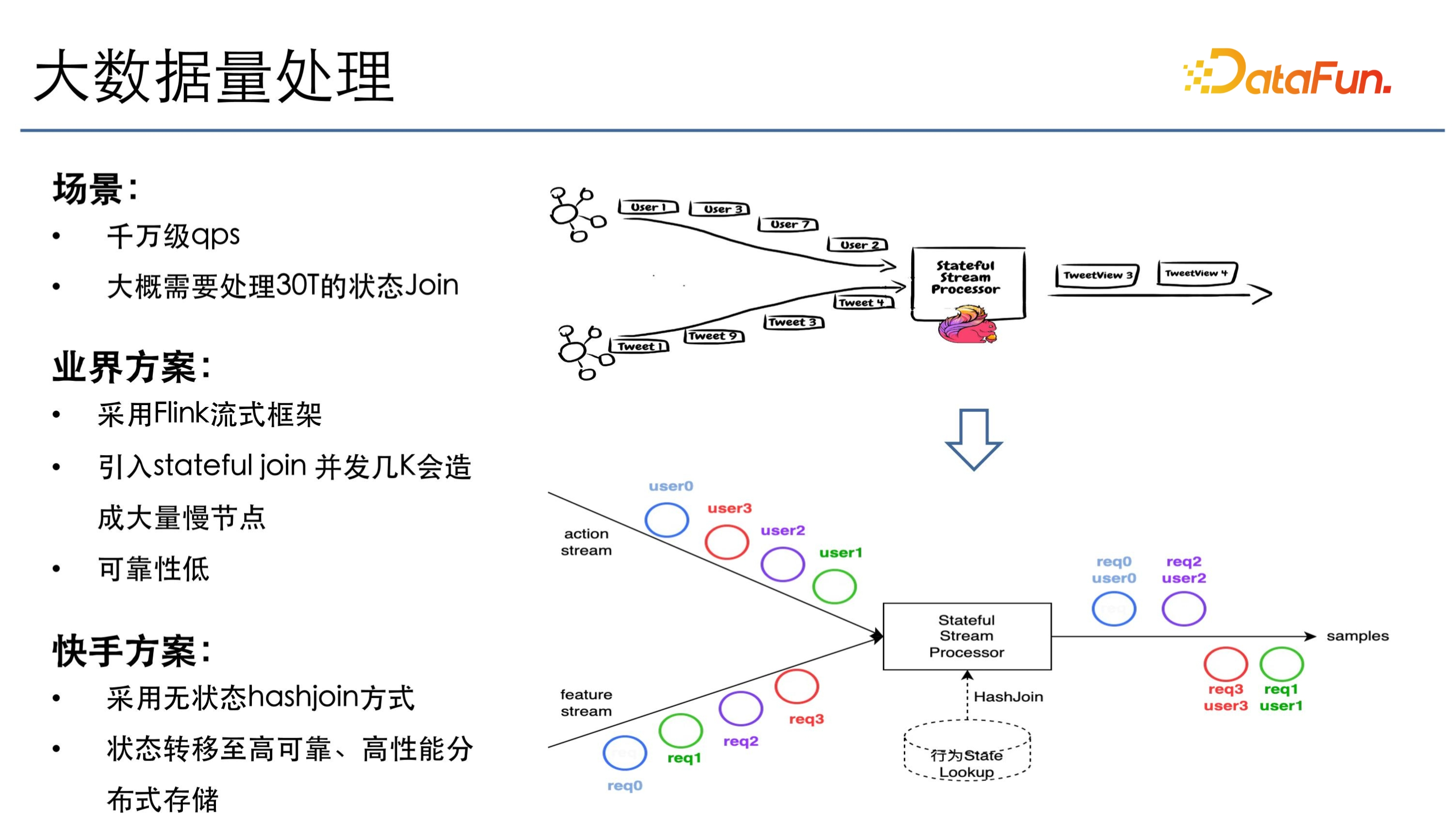
快手有千萬級使用者線上,不考慮行為多樣性的情況下,QPS 至少是千萬級的,如果區分到行為的多樣性,這個組合數量就更爆炸了,高峰期大概每秒需要處理 30T 左右的狀態。
業界方案主要是採用 Flink 流式框架,但如果直接用 Flink 引入 state join,在併發幾千的情況下會造成大量的慢節點。因為 30T 狀態如果 1000 併發的話,需要存 30G 的狀態,如果 1 萬併發也得存 3G。3G 在 1 萬併發下的慢節點的機率會非常大。在這種情況下如果出現慢節點,需要幾個小時恢復,這對於推薦系統肯定是不能忍受的。
所以快手選擇了一個折中方案,把狀態下沉至高效能儲存上,然後採用無狀態 hash join 的方式來做一個實時 join 的狀態,只要使用者的行為和特徵都到齊,就立即觸發樣本的下發,這樣就可以保證行為能夠及時地反饋到模型。雖然特徵和行為來的順序不一樣,但透過外部的狀態,再加上 Flink 流式框架並行的操作,就能實現大規模高效能的 join。
3. 複雜特徵計算

在上述處理完成之後,是特徵計算場景,主要有兩種計算,標量計算和向量計算。標量計算類似於特徵處理,比如要把某些值求和、求平均。在向量計算裡,會對一批樣本同一列進行一個同樣的操作,放在 GPU 透過 cuda 計算。這樣,透過使用 GPU 和 CPU 協同的方式實現高效能運算,一些標量操作在 CPU 上計算,記憶體訪問也會在 CPU 上進行,然後傳輸到 GPU 上去做高效能的 GPU 計算。
為了保證演算法迭代的靈活性,採用了 DSL 抽象。因為 SQL 不能完全描述所有的特徵處理場景。比如有一些在時間視窗的操作,如果透過 SQL 去做需要寫一些自定義的 UDF,這樣很不利於迭代。所以我們的 DSL 是用 Python 描述的,使用者可以透過 Python 直接呼叫下層的高效執行運算元。第一步先寫計算層,使用 C++ 實現一些高效的 operator,包括 cuda 和 CPU 相關的計算也都是透過 C++ 庫去做的。在 runtime 下面採用 Flink 的分散式框架加上 GNI 的方式去呼叫 C++ 的這些運算元,以達到高效能、高吞吐的處理。
4. 推薦場景特點
推薦場景下有兩個特點,一個是批流一體,另一個是潮汐。
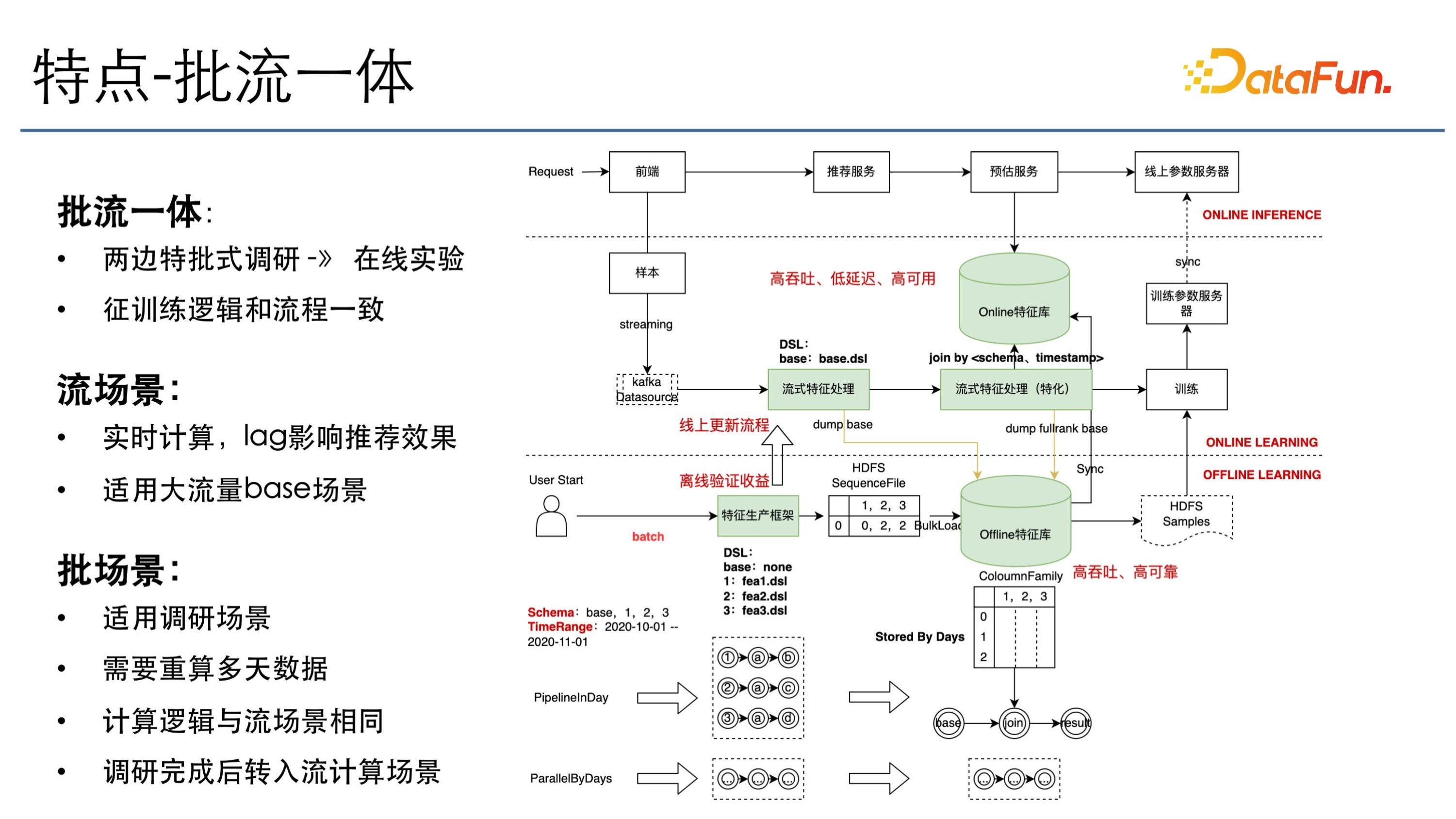
批式調研和線上實驗這兩種場景會需要有批流一體,因為在批場景裡調研特徵或調研模型結構完成之後,需要到線上去做上線,因此需要有一個批流一體的統一描述語言加上統一的執行引擎。使用者在批式上調研,會使用 DSL、Hadoop 和 Spark 把所有的資料計算出來,做模型迭代。模型迭代成功之後做特徵上線,上線到流式通用特徵處理框架上,或是上線到流式特徵框架特化的一個處理框架上。這裡之所以會分出兩個節點,主要是因為有一些特徵是所有模型公用的,所以可能在通用的框架下面,這樣只需要計算一次。而在特化的運算元下面則是一些模型所特有的特徵,因此分開處理。但這兩個計算引擎和語言描述其實是一樣的。同樣地,這些通用處理的資料需要落盤到批場景下。批場景下有很多是基於 base 的特徵去迭代,會加入它自己的性價特徵,所以在批次場景下面計算的也是 Delta。
上線完之後就會到線上服務,這裡會有一個高效能的儲存和計算庫去承接,這一點在後文中還會講到。在流式場景下,注重的是高吞吐、低延遲和高可用。在批場景下,主要關注高吞吐、高可靠。

另外一個特點就是請求潮汐。上圖是請求潮汐的示意圖(並不是快手的真實流量)。從圖中可以看到,有早高峰和晚高峰兩個高峰。在高峰期需要給足線上的算力,在低峰期則要把冗餘的算力利用起來。
在這種情況下,快手的大資料處理框架以及線上所有的模組需要針對潮汐的特點,去做雲原生架構的一些改造,比如快速恢復、自動伸縮、快速伸縮。快速伸縮主要是因為在自動伸縮的時候並不能保證是高效的,比如一次自動伸縮需要耗一小時或者幾個小時之久,那麼線上的請求在這幾個小時之間會有比較大的損失。
另外,還需要把線上服務的資源池和大資料處理的資源池統一起來,這樣所有資源在低峰期時可以把冗餘算力給批式場景、大模型預訓練場景或者大模型批次預估的場景,使資源得以利用。快手現在所有的架構都在向雲原生架構演進。
03
大規模模型資料儲存
1. 儲存特點
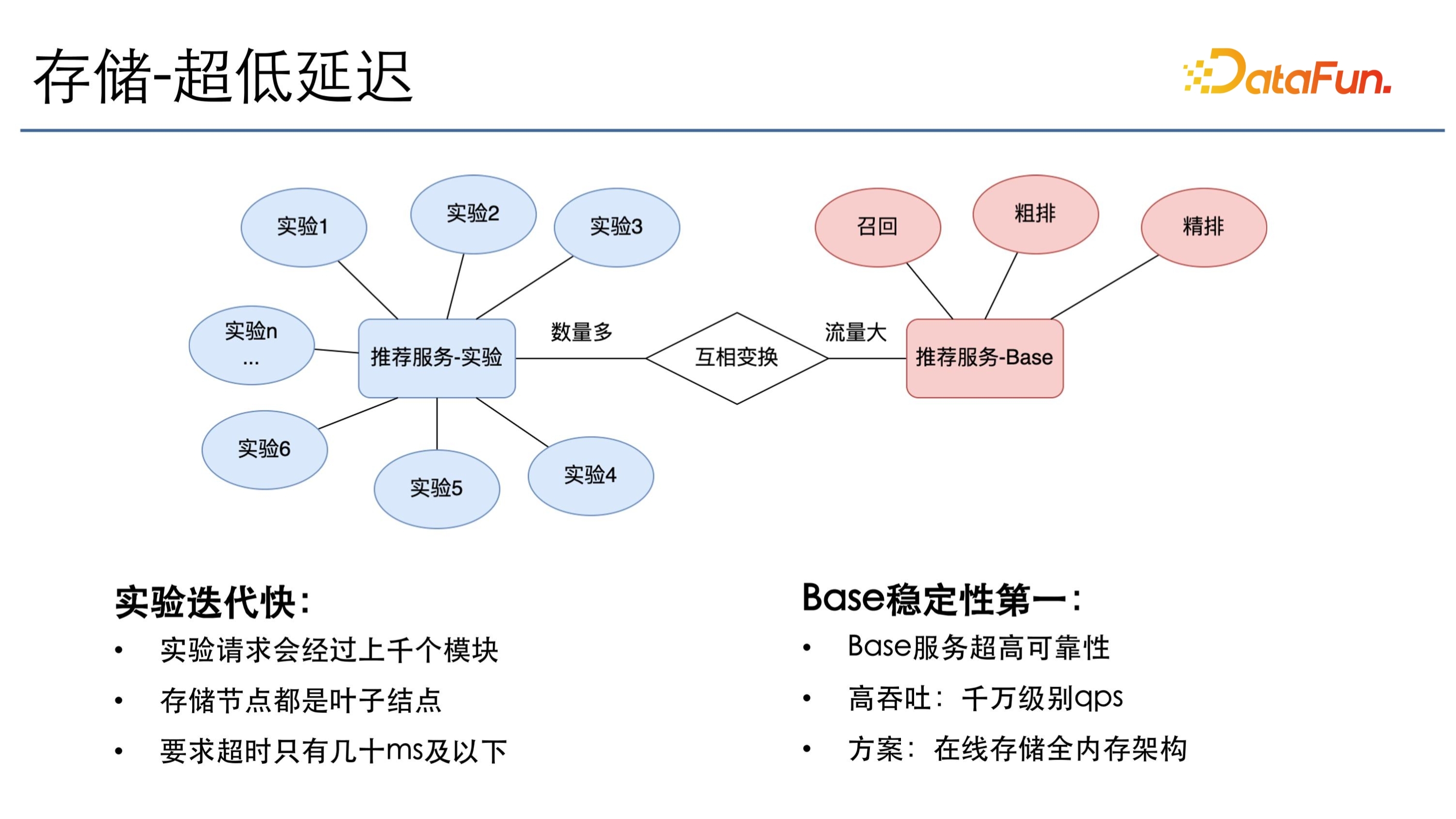
大規模資料儲存的第一個特點就是超低延遲,因為儲存節點儲存的都是狀態,一些計算節點需要很多的狀態資訊才能去計算,所以儲存節點大部分時間都是在葉子節點,而且推薦的線上實驗有上千個模組,每一個模組只能給十毫秒以內或者最多幾十毫秒的超時時間,因此要保證所有儲存節點都是低延遲、高吞吐並且高可用的。
推薦實驗和推薦服務 base 之間有一個互相切換的過程。一般並行的實驗數量非常多,實驗完成之後會去切換成一個線上的 base,這樣它承擔的流量就會非常大。比如在訓練服務 base 裡會有召回的 base、粗排的 base和精排的 base,各個 base 都需要去承擔千萬級的 QPS,而且要提供超高的可靠性。所以線上儲存部分,大量選用的是全記憶體架構。

其次,快手有超大儲存的需求。前文中提到,快手大模型有 1.9 萬億的引數量,如果換成普通八維的 float,需要的儲存也要有 64T,而且還有一個全使用者的行為序列,有 180T 左右的狀態資訊。如果要採用全記憶體的儲存,將會需要 2000 多臺機器。而且所有的狀態需要在 30 分鐘內恢復,因為推薦系統如果超過 30 分鐘不恢復,會對線上產生非常大的影響,使用者體驗會很差。
針對上述需求,我們的方案主要有以下幾個:
(1)特徵 score 的准入:特徵 score 可以理解為特徵重要性,即將一些重要性比較低,對預估效果影響也微乎其微的特徵不放在線上儲存上;
(2)LRU 和 LFU 的淘汰:因為是線上的模型,需要保證可靠性,即記憶體需要維持在一個穩定範圍內,不能一直增長。因此我們將最遠更新的優先淘汰,最先訪問的優先保留;
(3)NVM 新硬體技術:全記憶體架構的資源消耗也是一個非常大的問題。我們引入了 NVM 硬體技術。NVM 是一個持久化儲存,是 Intel 新發布的一個硬體,它會在 DR 和 SSD 之間,有接近於記憶體的速度,同時有接近於 SSD 的儲存空間,既能兼顧儲存也能兼顧效能。
2. 儲存方案-NVM Table

儲存方案是 NVM Table,分成異構儲存的三層:物理層提供底層儲存的 API,包括 NVM 儲存和 memory 儲存;中間 memory pool 封裝統一的管理功能,把 NVM 和 memory 的模組都管理起來;上層業務透過 memory pool 的一個 API 去呼叫下層的 NVM 和 memory,提供統一的查詢邏輯。
在資料結構佈局方面,memory pool 採用的是 block 介面抽象。將 NVM 和 memory 分成若干不同的、可透過全域性統一地址來訪問的 block,這樣就可以實現 zero copy 的訪問自由化。對於一些頻繁訪問的 key,會放到 mem-key 上。不常訪問的 key 會放在到 NVM 上。一些索引的 key 會頻繁訪問,但查詢到 key 之後,其 value 在最後要返回給上游的時候才會用到,並且量級較大,所以將 value 放到持久化的儲存。Key 查詢比較多,同時也比較小,所以放在記憶體,這樣就實現了記憶體和 NVM 的零複製技術。這裡的雜湊表採用了業界領先的無鎖技術,以減少臨界區的競爭,完成高效儲存。
從 NVM Table 的一個場景測試資料可以看出,其網路的極限吞吐與 JIRA 是相當的。跨網路訪問一般是網路達到極限,所以 NVM 頻寬可以完全覆蓋網路頻寬,瓶頸主要在網路上,這樣就能保證 NVM 既有成本上的收益,也有大儲存和高吞吐的收益。另一方面,恢復時間也下降了 120 倍。最開始恢復 T 的資料需要兩個小時,採用 NVM 之後只需要2分鐘。

3. 儲存方案-強一致性

儲存方面,還有強一致性的需求,主要是因為在推薦場景裡也有一些廣告和電商的推薦,需要儲存的副本特別多。因為當一些新的短影片或者新物料進來時,下游所有模組會有一個併發分發,需要保證這些影片在 10 秒內到達所有的推薦服務,且所有推薦服務裡的狀態需要保證一致。否則對於模型的效果影響很大。
我們採用了 Raft 協議加 BT 的模式。Raft 協議主要負責選組和同步資料,BT 的模式主要是改造 BT 同步的模式,比如在幾千上萬臺機器規模下的同步,如果同時用主從同步的話,主節點的出口頻寬可能會是從節點的千倍以上,頻寬就會成為瓶頸,下發的狀態就會非常少,高吞吐和資料同步會受到影響。
我們的方案是分散式的平衡樹分發,構造一個平衡二叉樹,把所有主從節點進行組織,每個節點只管有限個從節點,從而保證從主節點同步到葉子節點所需要的頻寬不變,但是單節點的頻寬限制為小於等於 2,這樣在全域性下既能做到一次性,也能做到高效地同步,10 秒內即可將所有影片狀態分發到每個節點。
04
展望
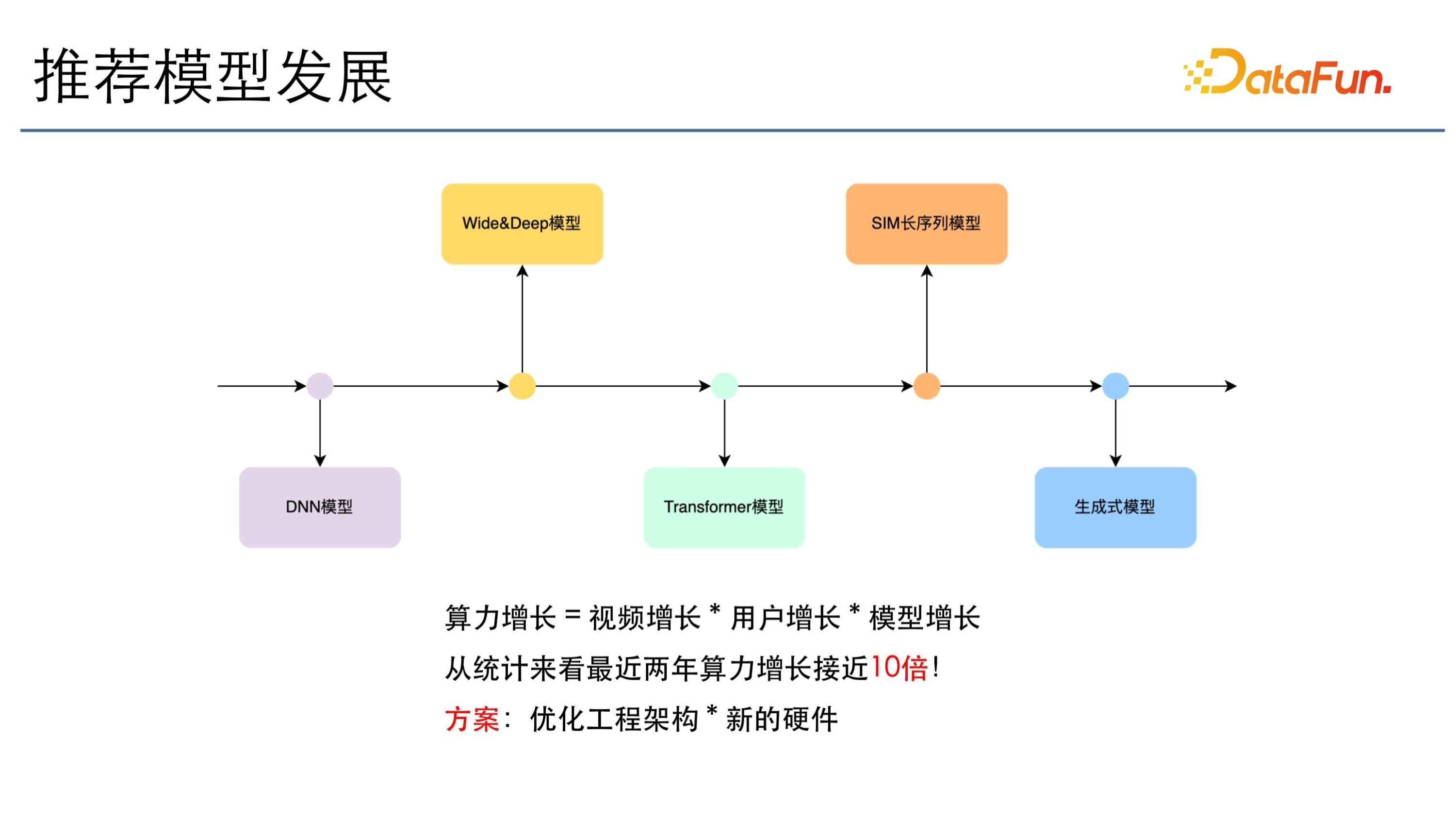
推薦模型的發展跟語言模型是相關的,從 DNN 模型到 Wide&Deep,到 Transformer,再到 SIM 長序列及生成式模型,模型增長了很多倍。除了模型的增長,算力增長也會隨影片的增長和使用者的增長,呈現出指數級的上升。從統計資料來看,最近兩年推薦模型的算力增長接近 10 倍,我們的方案主要是最佳化工程架構和新的硬體技術。

生成式模型會帶來計算量的爆炸,因為它是一個 token-based 的推薦,每次推薦需要之前所有的 token 作為 context,在這種情況下生成的效果才會最好。如果沒有 token-based,那麼與算力不會呈指數級增長。因此,推薦的壓力,將主要來自狀態儲存的大規模提升,因為目前的推薦模型主要是 pointwise 的推薦,對於長序列推薦模型算力也是有限的。如果全部採用深層次模型推薦,其狀態儲存還將再增長 10 倍,挑戰會非常大。因此我們需要透過一些新硬體,比如 CXL、NVM 以及新推出的 Grace 架構,再加上工程上的最佳化,比如狀態做差分、傳輸計算等等,來應對未來的挑戰。
來自 “ DataFunTalk ”, 原文作者:王靖;原文連結:https://server.it168.com/a2024/0207/6839/000006839590.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 海量資料處理
- 海量資料處理2
- 海量資料的併發處理
- 超3萬億資料實時分析,JCHDB助力海量資料處理
- 我的《海量資料處理與大資料技術實戰》出版啦!大資料
- 關於一類資料處理
- 日均處理萬億資料!Flink在快手的應用實踐與技術演進之路
- 處理XML資料應用實踐XML
- 關於 Eloquent ORM 對資料處理的思考ORM
- 關於主資料的實踐和思考
- Serverless 在大規模資料處理的實踐Server
- 海量資料處理利器 Roaring BitMap 原理介紹
- Jtti:怎樣正確處理Redis中的海量資料JttiRedis
- Pandas多維特徵資料預處理及sklearn資料不均衡處理相關技術實踐-大資料ML樣本集案例實戰特徵大資料
- 關於資料庫事務併發的理解和處理資料庫
- 基於python的大資料分析-資料處理(程式碼實戰)Python大資料
- 基於python的事件處理模型Python事件模型
- 阿里巴巴資深大資料工程師:大資料處理實踐阿里大資料工程師
- 複雜場景資料處理的 OLTP 與 OLAP 融合實踐
- Flink CDC + Hudi 海量資料入湖在順豐的實踐
- 關於丟失表空間資料檔案的處理方式
- 海量資料處理問題知識點複習手冊
- 大資料量處理實踐方案整理大資料
- 關聯模型欄位取別名查詢不出資料的處理方法模型
- 快手流批一體資料湖構建實踐
- 阿里海量大資料平臺的運維智慧化實踐阿里大資料運維
- 關於SQL Serve資料庫r帳號被禁用的處理方法SQL資料庫
- 簡述高併發解決思路-如何處理海量資料(中)
- 羅強:騰訊新聞如何處理海量商業化資料?
- 關於Python中的日期處理Python
- N道大資料海量資訊處理 演算法面試集錦大資料演算法面試
- 快手基於 Apache Flink 的實時數倉建設實踐Apache
- C++進階(點陣圖+布隆過濾器的概念和實現+海量資料處理)C++過濾器
- SQL on Hadoop在快手大資料平臺的實踐與優化SQLHadoop大資料優化
- ThinkJS 關聯模型實踐JS模型
- 關於 es 資料同步的一次效能優化實踐優化
- 基於DataLakeAnalytics的資料湖實踐
- 基於 Spark 的資料分析實踐Spark