序列推薦系統的前世今生
前言
推薦系統在各種線上平臺中有廣泛的應用。使用者在各種線上平臺的行為天然地具有先後順序,並且使用者興趣也會隨著時間發生變化。考慮使用者行為的時序關係和興趣變化可以給使用者提供更好的推薦體驗。在序列推薦模型發展的過程中,借鑑了很多其他領域的優秀演算法。本文大致按照時間順序,介紹序列推薦模型的發展歷程。首先,本文介紹非深度學習方法用於序列推薦的嘗試。然後,本文介紹Transformer誕生之前的基於深度學習方法的序列推薦模型,隨後介紹基於Transformer架構和其變種的序列推薦模型,最後介紹近期將對比學習用於序列推薦的嘗試。
早期非深度學習方法
FPMC
Factorizing Personalized Markov Chains for Next-Basket Recommendation. WWW 2010.
儘管FPMC是比較早期的非深度學習方法,還是經常被各種新序列推薦模型的作為比較方法,所以放在這裡作為我們的開篇。FPMC運用了非常經典的思想,和矩陣分解(MF)有異曲同工之妙。
FPMC是矩陣分解和馬爾可夫鏈分解的結合。在FPMC中,作者假設每一時刻使用者可能和多個物品互動,同一使用者同一時刻互動的所有物品,就構成了一個basket. 在FPMC中,作者使用使用者ID和當前時刻使用者互動過的物品ID預測下一時刻使用者將要互動的物品。可以認為,在FPMC中,作者僅使用了使用者最近互動過的物品作為使用者的行為序列。
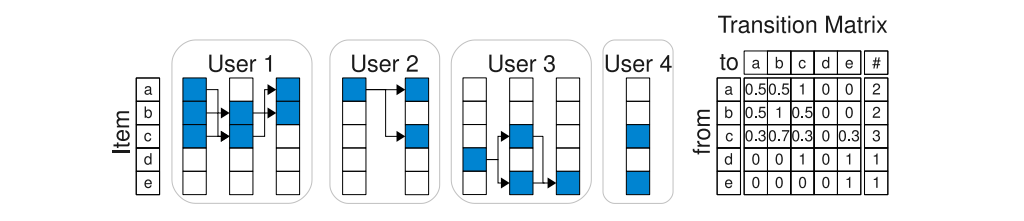
圖1:FPMC的物品轉移矩陣
作者把使用者下一時刻將要互動的物品的得分分解成為兩部分,第一部分使用使用者本身的特徵預測,第二部分使用當前物品預測。第一部分的分數使用矩陣分解計算,等於使用者向量和物品向量的點積。第二部分的分數透過物品間的轉移矩陣估計得到。FPMC使用類似矩陣分解的方法建模物品間的轉移矩陣,使用當前時刻物品的向量和下一時刻物品的向量的點積擬合物品轉移矩陣。最終,使用者對物品的興趣分數是這兩部分得分的相加。
FPMC使用S-BPR損失訓練。S-BPR和BPR損失計算方法基本相同,只是額外考慮了當前時刻使用者互動的物品。
Transformer誕生前的深度學習方法
GRU4Rec
Session-based Recommendations with Recurrent Neural Networks. ICLR 2016.
RNN一般被用來建模序列資料,常常被用在自然語言處理(NLP)中。RNN和前饋神經網路的區別是RNN會儲存隱藏狀態。GRU是為了解決RNN梯度消失問題的一種改進模型。
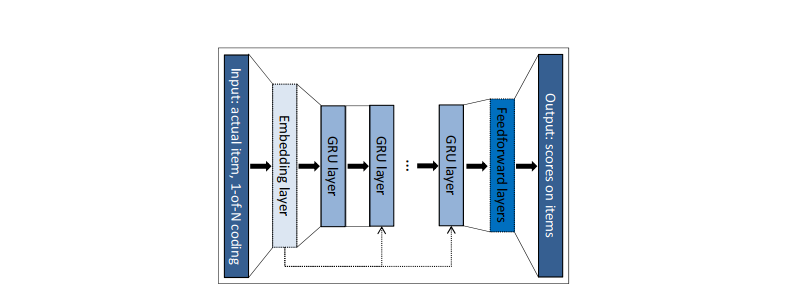
圖2:GRU4Rec的模型結構
GRU4Rec的輸入為使用者的行為序列,透過embedding層後送入到GRU,GRU會在每個時刻預測候選物品的分數。由於不同使用者的行為序列長度差異很大,為了充分利用GPU的平行計算能力,作者將比較短的使用者序列拼接在一起,合成一個序列,然後多個序列組成batch,進行訓練。在訓練時,如果一個序列包含了多個使用者,會在使用者發生變化時,把GRU對應的隱藏狀態重置。
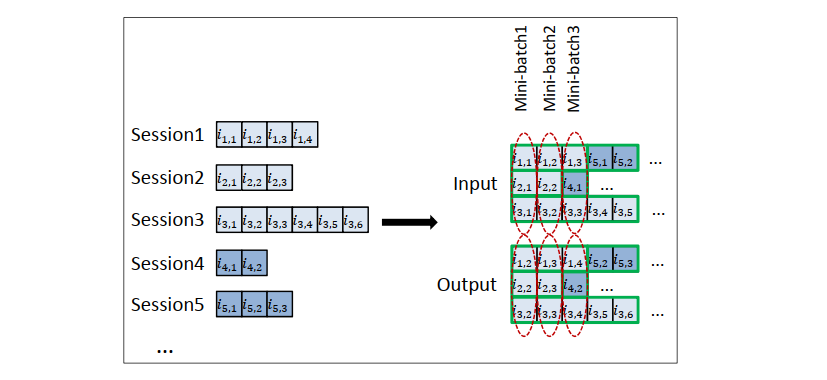
圖3: GRU4Rec在構建batch時會把較短的使用者行為序列拼成一個比較長的序列
GRU4Rec使用BPR或者由作者提出的TOP1損失訓練。TOP1損失透過逼近正樣本物品在參考物品中的歸一化排序來最佳化模型。作者未能使用多分類交叉熵穩定地訓練模型。在GRU4Rec中,輸入層的Embedding和輸出層不共享。
GRU4Rec+
Recurrent Neural Networks with Top-k Gains for Session-based Recommendations. CIKM 2018.
在保持GRU4Rec模型結構不變的情況下,新的作者對負取樣策略和損失函式進行了改進。模型效果取得了大幅提升。
負取樣方面,在GRU4Rec中,作者使用同一個batch中其它使用者行為序列對應的目標物品作為負樣本。例如每個 batch 有N條使用者行為序列,每條使用者行為序列對應1個目標物品。這樣,每條使用者行為序列對應的1個目標物品作為正樣本,其他N-1個物品作為負樣本。這種取樣方法等價於基於流行度取樣。在GRU4Rec+中,除了使用當前batch中的其他使用者行為序列的目標物品作為負樣本以外,作者還同時使用從某個預定義分佈中取樣得到的物品作為負樣本。這個預定義的分佈可以是均勻分佈或者流行度分佈,或者兩者的混合。
在損失函式方面,作者透過對多分類交叉熵損失的數值穩定性進行修正,使模型能夠使用交叉熵訓練,大大提高的模型的效果。作者還提出了TOP1-max和BPR-max損失,效果有進一步提升。
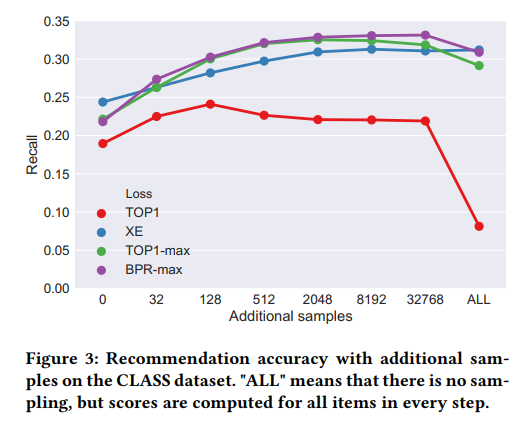
圖4: GRU4Rec+中不同損失函式和不同額外負樣本數量對模型效果的影響
最後,作者還對NLP中常用weight-tying技術,在序列推薦資料集中做了實驗。作者發現,大部分資料集,共享模型輸入層和輸出層的embedding權重,效果都會提高。除了提高效能之外,透過共享權重,模型的引數也大大減少。因此,預設情況下,當前的序列推薦模型都會使用weight-tying.
Caser
Personalized top-n sequential recommendation via convolutional sequence embedding. WSDM 2018.
既然RNN可以用來學習序列推薦任務。透過將時間作為一個維度,Embedding維度作為另一個維度,看作二維圖片,能否用卷積神經網路(CNN)來進行建模呢?在Caser中,作者就使用CNN學習序列推薦任務。
在Caser中,模型使用使用者近期互動過的L個物品預測接下可能的互動的T個物品。模型的輸入為使用者ID和使用者互動過的物品ID序列。經過embedding層之後,使用者的行為序列變為一個矩陣,一個維度為時間,維度的大小記為L ,一個維度為物品的 embedding維度,維度的大小記為d. 為了方便後續討論,我們把這個矩陣稱為 embedding序列。
模型使用兩種卷積濾波器對embedding序列進行處理。一種卷積濾波器只會沿著時間維度滑動,卷積核的尺寸為h × d, h可以是任意小於等於L的數。另一種卷積濾波器只會沿著embedding維度滑動,卷積核的尺寸為L × 1,等價於對每個embedding維度不同時刻的特徵進行加權求和。第一種濾波器的輸出結果,還會在時間維度進行最大池化,每個濾波器最終得到一個d維向量。所有的濾波器的輸出拼接在一起,經過一個全連線層後再和使用者embedding拼接在一起,輸入預測層,得到在不同物品上的分數。
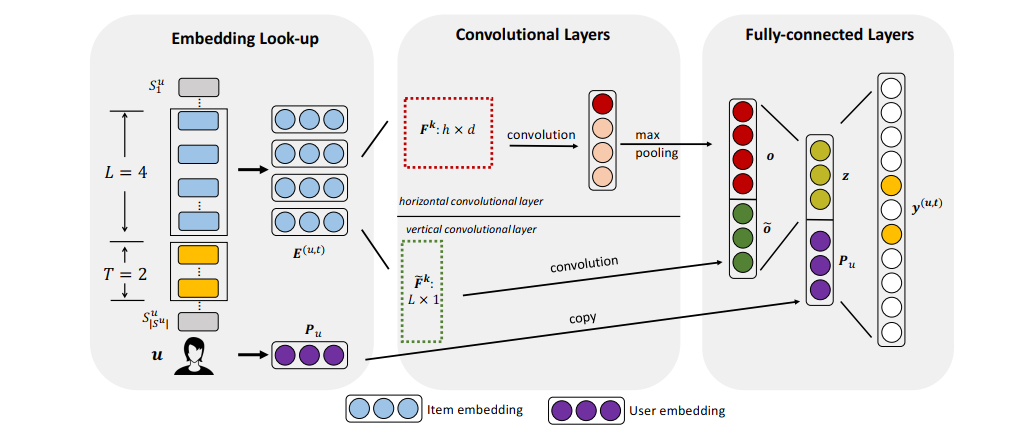
圖5: Caser的模型結構
Caser使用二分類交叉熵(BCE)損失訓練。
基於Transformer的方法
SASRec
Self-attentive sequential recommendation. ICDM 2018.
2017年,谷歌提出了使用自注意力機制建模自然語言處理任務的模型的Transformer, 在機器翻譯任務上取得了傑出的效果。機器翻譯是序列輸入序列輸出的任務。用於機器翻譯的Transformer由編碼器(Encoder)和解碼器(Decoder)組成。使用位置編碼協助自注意力機制處理序列中不同元素(稱為Token)之前的先後順序關係。相對於使用RNN處理序列,使用自注意力機制更高效,效果更好。
序列推薦是一個輸入序列輸出Token的任務,和機器翻譯任務有相同點。所以作者在這篇論文中嘗試使用自注意力機制解決序列推薦問題。作者只使用Transformer 的解碼器部分。自注意力層使用單向注意力。模型的輸入為使用者最近互動過的物品序列的embedding和可學習的位置編碼,預測使用者將要互動的下一個物品。這個任務稱為下一個物品預測任務(Next Item Prediction Task).
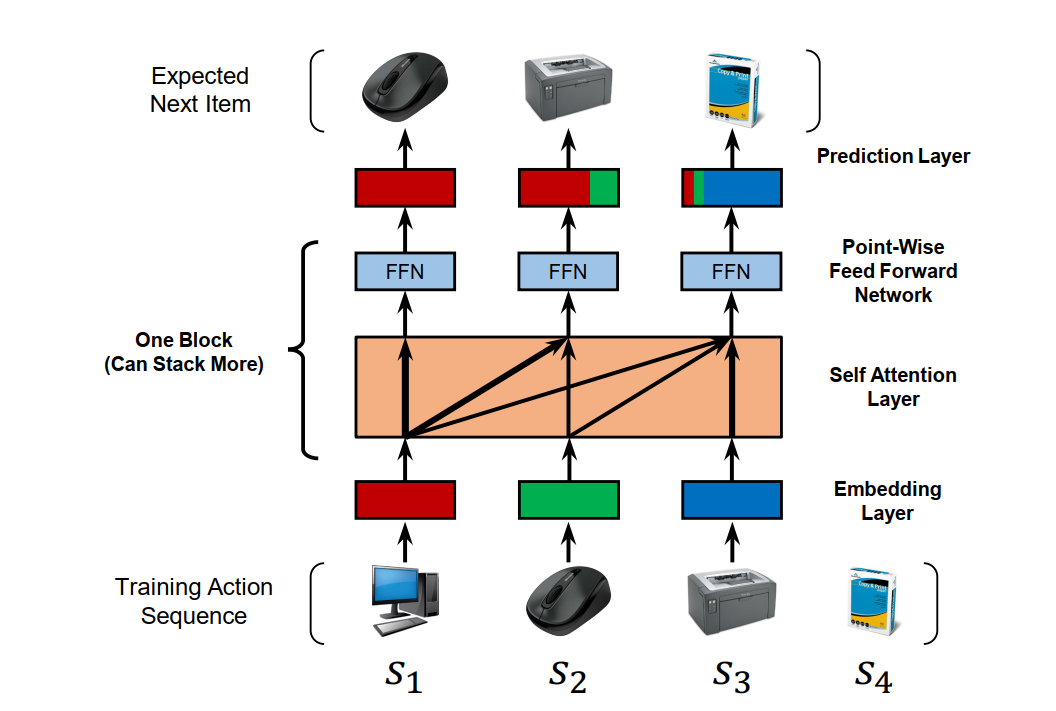
圖6: SASRec的模型結構
SASRec使用BCE損失序列,為每一個正樣本取樣一個負樣本。
由於引入了自注意力機制,SASRec在各個資料集上的表現超過了前文提到的所有模型。
BERT4Rec
BERT4Rec: Sequential Recommendation with Bidirectional Encoder Representations from Transformer. CIKM 2019.
NLP 的經典任務除了預測下一個詞,還有完形填空任務(Cloze Task),就是將一個句子中的某個詞遮蓋住,要求模型從所有詞中選出最合適的一個。BERT4Rec就是透過學習完形填空任務進行序列推薦。BERT4Rec使用Transformer編碼器和雙向注意力。
在BERT4Rec訓練時,首先會抽取一個使用者的互動物品序列,將其中的部分物品遮蓋住,用[Mask]替換,作為模型的輸入序列。模型學習預測被遮蓋的物品。由於序列推薦的任務是使用使用者已經發生的互動物品序列預測接下來使用者要互動的物品,因此在推斷時,BERT4Rec將[Mask]拼接在使用者互動過的物品序列最後,輸入模型。模型預測[Mask]位置的物品就是使用者將要互動的物品。
由於遮蓋物品預測任務(Mask Item Prediction Task)和實際推斷時的下一物品預測任務對齊地不是很好,所以模型在訓練時還會增加一部分樣本,這部分樣本只遮蓋最後一個物品。
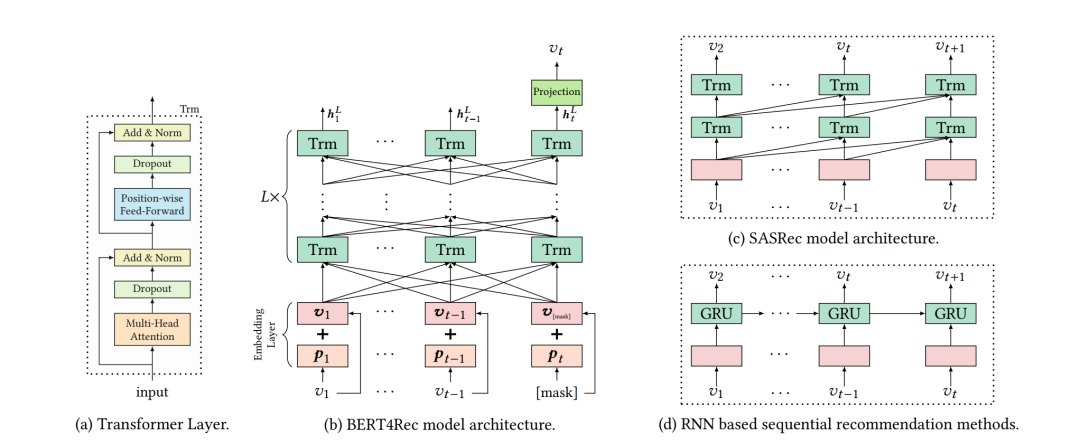
圖7: BERT4Rec的模型結構,以及和SASRec等模型結構的對比
BERT4Rec使用多分類交叉熵訓練(Categorical Cross Entropy)。除了目標物品外,訓練集中的其他物品都作為負樣本。
TiSASRec
Time Interval Aware Self-Attention for Sequential Recommendation. WSDM 2020.
使用者的行為序列中,除了有互動物品之間的先後順序資訊之外,還有互動物品之間的時間間隔資訊。大部分序列推薦模型中,都沒有考慮互動物品之間的時間間隔。在TiSASRec中,作者使用相對位置編碼(Reletive Positional Encoding)和自注意力機制,顯式建模使用者行為序列中物品之間的時間間隔和先後順序。
相對於 SASRec將位置編碼和物品Embedding直接在模型輸入層相加,TiSASRec在模型自注意力層加入位置編碼和時間間隔編碼,具體透過在自注意力層計算時,向Key和Value向量中加入位置資訊和時間間隔資訊實現。以Key計算為例,在計算 Key時,Key會加入時間間隔向量和位置向量。時間間隔向量和位置向量都透過 Emebdding Lookup得到。使用者互動過的物品之間的時間間隔是連續值,透過除以一個預先定義好的值再取整變為一個整數,使用這個整數查詢時間間隔Embedding表得到時間間隔向量。Value向量計算同理,Value計算時也會加入時間間隔向量和位置向量。不過,Key和Value的時間間隔嵌入矩陣和位置嵌入矩陣是不共享的。
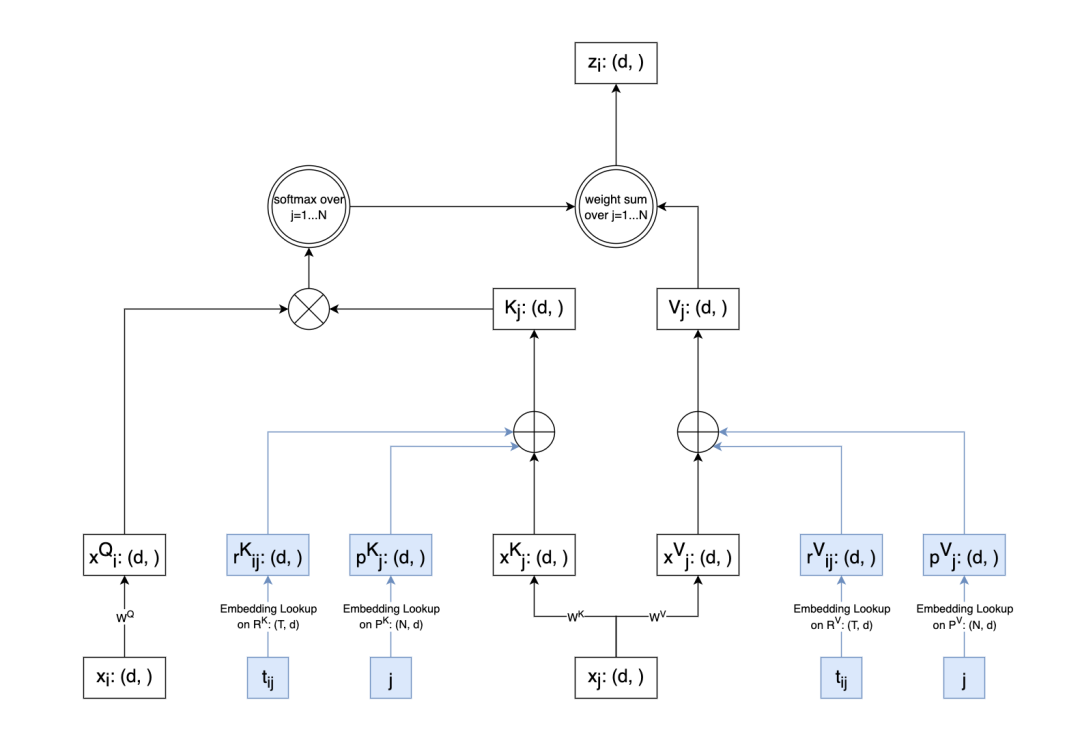
圖8: TiSASRec中基於相對位置編碼建模使用者行為序列中物品互動的時間間隔和先後關係
和SASRec一樣,TiSASRec使用單向注意力, 使用BCE損失訓練,每一個正樣本抽取一個負樣本。
由於增加了時間間隔注意力,TiSASRec效果相對於SASRec會有一定提升。
FMLP-Rec
Filter-enhanced MLP is All You Need for Sequential Recommendation. WWW 2022.
Transformer 使用自注意力機制學習不同物品間的相互關係,實現不同位置Token之間的資訊互動。除了自注意力機制外,其他方法也可以實現不同Token之間的資訊互動。在FMLP-Rec中,作者使用訊號處理中的濾波方法對Token序列進行處理。
FMLP-Rec 模型結構整體上和 Transformer 編碼器類似,只是對自注意力層進行了替換,新的層稱為濾波器層(Filter Layer )。濾波器層首先使用離散傅立葉變換將Token的Embedding序列變換到頻域,然後使用可學習的濾波器對頻域訊號進行濾波處理。數學上,頻域濾波就是使用頻域訊號和濾波器的頻域表示相乘(Element-wise Product)。濾波後,使用傅立葉逆變換將頻域訊號變回時域。使用濾波方法對行為序列Embedding進行處理,具有一定的可解釋性。可以理解為對使用者行為訊號中的不同頻率進行過濾或加強。相對於自注意力層O(N^2)的計算複雜度,包含快速傅立葉變換(FFT)的濾波器層的計算複雜度只有O(NlogN),小於自注意力層。
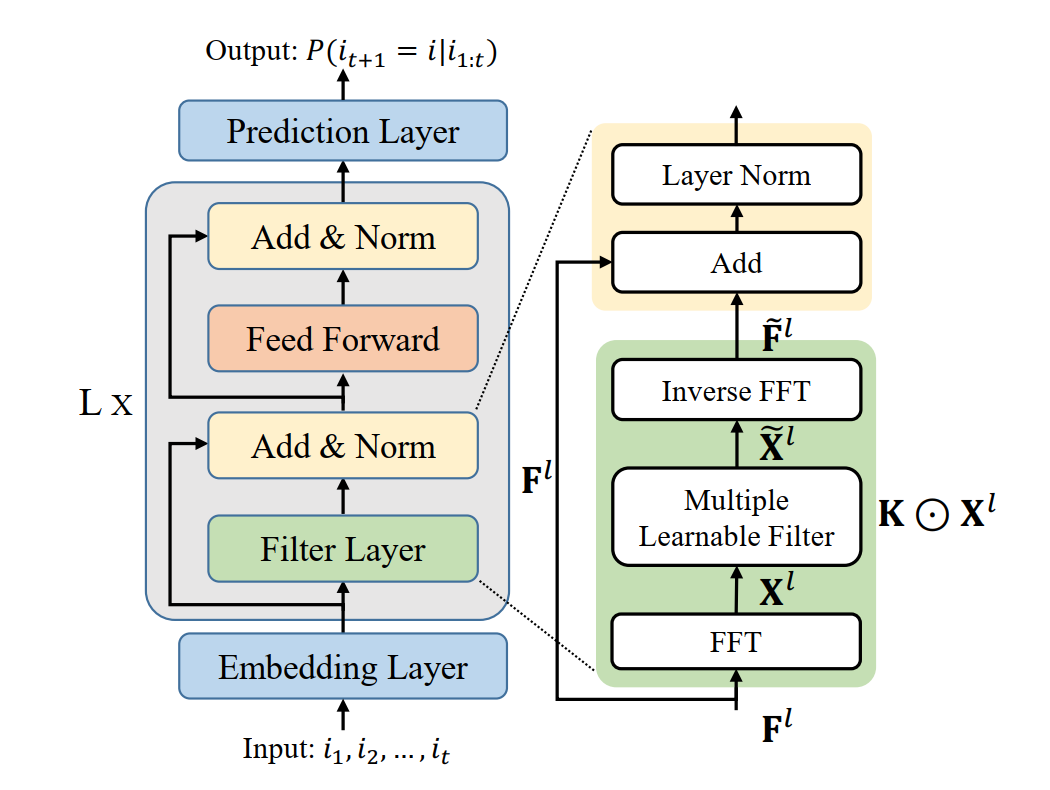
圖9: FMLP-Rec的模型結構
FMLP-Rec使用多分類交叉熵訓練,訓練集中除目標物品和使用者互動過的物品以外的所有物品作為負樣本。
基於對比學習的方法
CLS4Rec
Contrastive Learning for Sequential Recommendation. SIGIR 2021.
近幾年,對比學習在人工智慧的其他領域,如計算機視覺中受到了很大的關注。在CLS4Rec中,作者嘗試使用對比學習來增強序列推薦的效果。之所以說是增強,是因為,CLS4Rec仍然會學習下一個物品預測任務。在這個任務的基礎上,作者增加了對比學習任務。
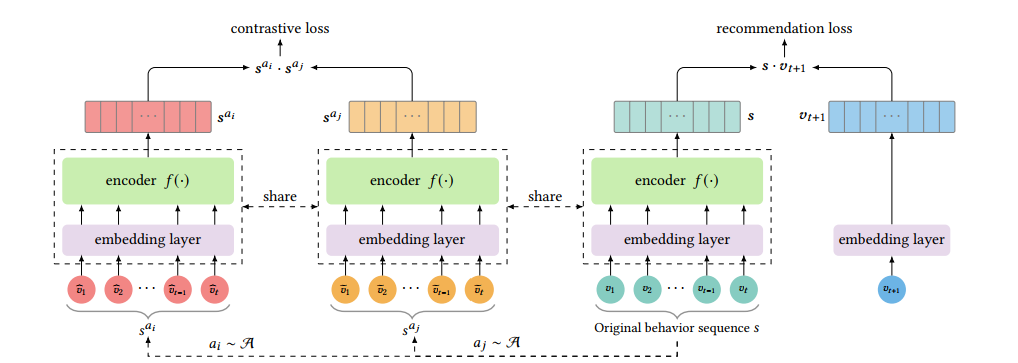
圖10: CLS4Rec同時學習對比學習任務和推薦任務
新增的對比學習任務主要首先對每個Batch中的每個使用者的行為序列進行小幅度的變換,然後讓網路判斷變換後序列哪些來源於同一個序列。這個變換可以是物品裁剪(Item Crop),物品遮蓋(Item Mask),物品打亂(Item Reorder).文章發現,透過要求序列模型學習判斷變換後的序列是否來源於相同的原序列,可以提升模型的效果。但是不同的資料集適合的變換可能不同。

圖11: 用於生成對比學習樣本的變換
下面介紹論文中涉及到的三種變換和對比損失的計算。物品裁剪是指把使用者行為序列中的一部分連續的序列擷取出來,和其他變換後的序列比較,計算相似度,判斷哪些變換後的序列屬於同一使用者。物品遮蓋是指把使用者行為序列中的某一部分物品遮蓋起來,用零向量替代。物品打亂是指將使用者行為序列中一小段連續幾個物品的順序打亂。計算對比損失時,一個batch包含N個未變換的序列和2N個變換後的序列,即每個未變換的序列生成兩個變換後的序列。對於某一個使用者變換後的序列,來自相同使用者透過不同變換得到的序列作為正類別,其他使用者變換後的序列,總共2N-2個作為負類別,組成總共2N-1類的分類問題,模型預測哪一個樣本也來自這個使用者,使用交叉熵計算對比損失。
作者發現,物品裁剪在多個資料集上都有效果。物品遮蓋和物品打亂在部分資料集上可能會有負向作用。
CLS4Rec使用多分類交叉熵學習下一物品預測任務,隨機取樣的物品作為負樣本。對比學習任務損失的權重小於下一物品預測任務損失的權重。
結語
我們從非深度學習方法FPMC出發,首先回顧如何將矩陣分解思想運用到序列推薦。隨著深度學習的發展以及在深度學習在自然語言處理和計算機視覺領域展現出非凡的效果,適合這些領域的模型也被改造應用到了序列推薦,取得了不錯的效果。 Transformer和自注意力機制的應用則進一步推進了序列推薦的發展。近期,對比學習大熱,序列推薦領域也進行了對比學習的嘗試,取得了初步的效果。
應用建議
由於當前基於Transformer結構的序列推薦模型已經是主流的序列推薦方法,所以實際應用一般可以考慮SASRec或者SASRec的改進模型。直接選擇SASRec,也能取得不錯的效果。後續的大部分序列推薦方法都是基於SASRec進行改進,因此,如果從SASRec和BERT4Rec中選一個的話,選擇SASRec. 我們上線了SASRec和 FMLP-Rec, 用於網易新聞中影片推薦的召回環節,都取得了一定的效果。
來自 “ 網易傳媒技術團隊 ”, 原文作者:羅凡;原文連結:https://server.it168.com/a2023/1107/6828/000006828205.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 推薦演算法的“前世今生”演算法
- 對話系統的前世今生
- 推薦系統論文之序列推薦:KERL
- 分散式系統:CAP 理論的前世今生分散式
- 開源監控系統Prometheus的前世今生Prometheus
- 恆生O32系統的前世今生
- Omi框架Store體系的前世今生框架
- RabbitMQ的前世今生MQ
- InfiniBand 的前世今生
- MySQL 的前世今生MySql
- Mybatis的前世今生MyBatis
- Unicode的前世今生Unicode
- Dubbo的前世今生
- Serverless 的前世今生Server
- IPD的前世今生
- CRM的前世今生
- DBHub的前世今生
- Webpack前世今生Web
- React ref 的前世今生React
- React Portal的前世今生React
- 遊戲的前世今生遊戲
- HTTP/2.0的前世今生HTTP
- 元件化的前世今生元件化
- 聊聊 HTAP 的前世今生
- 聊聊ChatGPT的前世今生ChatGPT
- 外掛的前世今生
- 【UV統計】海量資料統計的前世今生
- Serverless For Frontend 前世今生Server
- iOS Device ID 的前世今生iOSdev
- JavaScript – 非同步的前世今生JavaScript非同步
- “錕斤拷”的前世今生
- 資料庫的前世今生資料庫
- Redux的前世-今生-來世Redux
- LangChain和Hub的前世今生LangChain
- 雲原生的前世今生(一)
- 中國SaaS的前世今生
- SAP Cloud for Customer的前世今生Cloud
- HTTP 協議的前世今生HTTP協議