Uber:20萬容器下,CPU節流問題也難不倒我
在 Uber,所有有狀態的工作負載都執行在一個跨大型主機的通用容器化平臺上。有狀態的工作負載包括MySQL、Apache Cassandra、ElasticSearch、Apache Kafka、Apache HDFS、Redis、Docstore、Schemaless等,在很多情況下,這些工作負載位於同一臺物理主機上。
憑藉 65,000 個物理主機、240 萬個核心和 200,000 個容器,提高利用率以降低成本是一項重要且持續的工作。但最近,由於 CPU限流,導致利用率提升這件事沒有那麼順利了。
事實證明,問題在於 Linux 核心如何為程式執行分配時間。在這篇文章中,我們將描述從 CPU 配額切換到cpusets(也稱為 CPU pinning),如何使我們能夠以 P50 延遲的輕微增加換取 P99 延遲的顯著下降。由於資源需求的變化較小,這反過來又使我們能夠將整個叢集範圍內的核心分配減少 11%。
一、Cgroups、配額和 Cpusets
CPU 配額和 cpusets 是Linux核心的排程器功能。Linux核心透過cgroups實現資源隔離,所有容器平臺均以此為基礎。通常,一個容器對映到一個 cgroup,它控制著在容器中執行的任何程式的資源。
有兩種型別的 cgroup(Linux 術語中的控制器)用於執行 CPU 隔離:CPU和cpuset 。它們都控制允許一組程式使用多少 CPU,但有兩種不同的方式:分別透過 CPU 時間配額和 CPU pinning。
二、CPU 配額
CPU控制器使用配額來實現隔離。對於一個CPU 集,你指定要允許的 CPU 比例(核心)。使用以下公式將其轉換為給定時間段(通常為 100 毫秒)的配額:
配額 = core_count * 週期(quota = core_count * period)
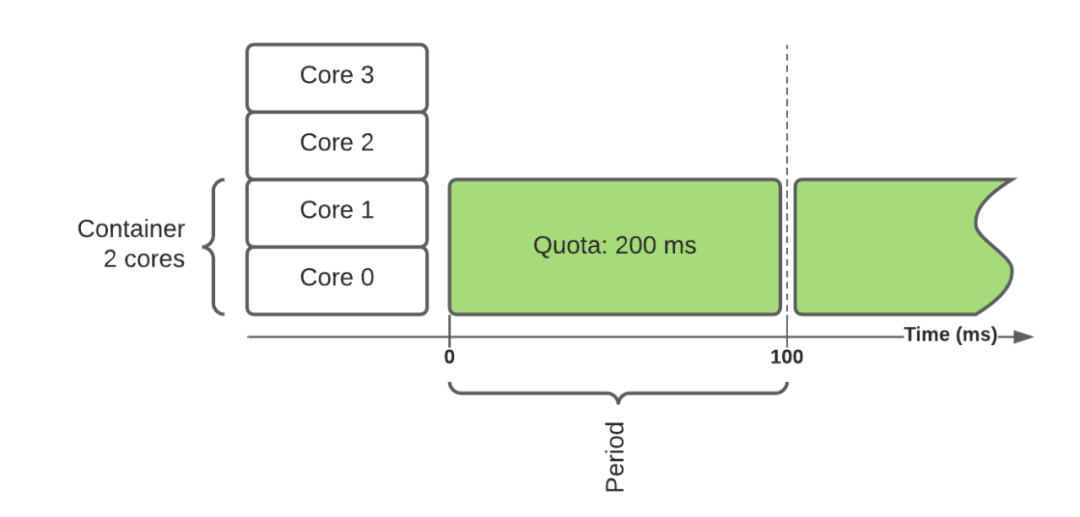
在上面的例子中,有一個需要 2 個核心的容器,這相當於每週期需要 200 毫秒的 CPU 時間。
三、CPU 配額和節流
由於容器內的多處理/執行緒,這種方法被證明是有問題的。這會使容器過快地用完配額,導致它在剩餘時間段內受到限制。如下圖所示:
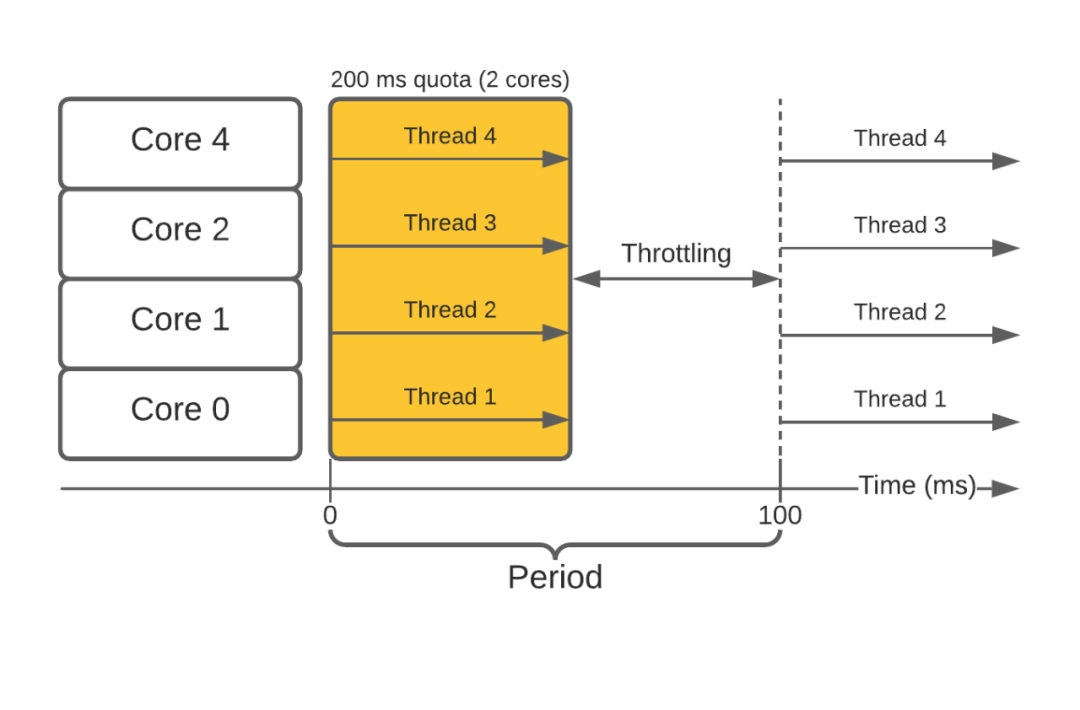
對於提供低延遲請求的容器來說,這是個問題。突然間,由於節流,通常需要幾毫秒才能完成的請求可能需要超過 100 毫秒。
簡單的解決方法是為程式分配更多的 CPU 時間。雖然這很有效,但在規模上也很昂貴。另一種解決方案是根本不使用隔離。然而,這對於同一地點的工作負載來說是一個非常糟糕的主意,因為一個程式可能會完全耗盡其他程式。
四、使用 Cpusets 避免節流
cpuset 控制器使用 CPU pinning 而不是配額——它基本上限制了一個容器可以在哪些核心上執行。這意味著有可能將所有容器分佈在不同的核上,以便每個核只服務於一個容器。這樣就實現了完全隔離,不再需要配額或節流,換句話說,可以用延遲的一致性和更繁瑣的核管理,來與處理突發和簡單配置進行妥協。上面的例子看起來像這樣:
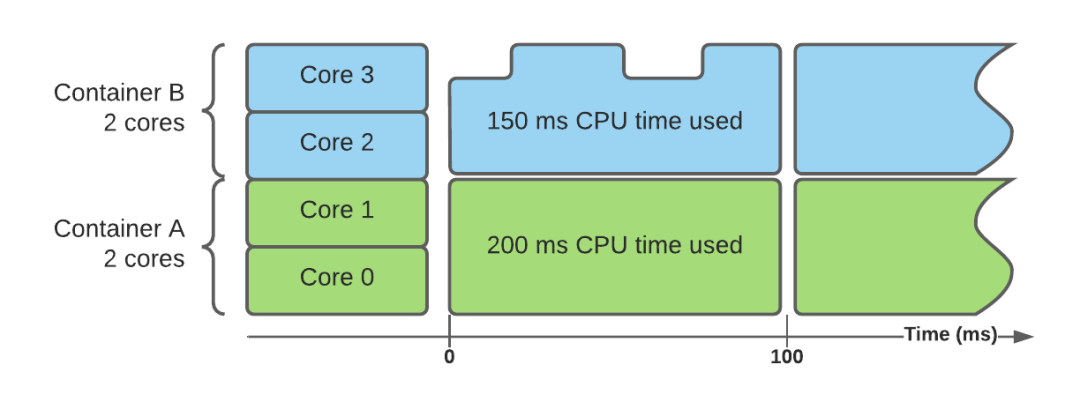
兩個容器在兩組不同的核心上執行。它們被允許在這些核心上儘可能地使用,但不能使用未分配的核心。
這樣做的結果是 P99 的延遲變得更加穩定。下面是一個在啟用 cpuset 時對生產資料庫叢集(每一行是一個容器)進行節流的例子。正如預期的那樣,所有節流都消失了:
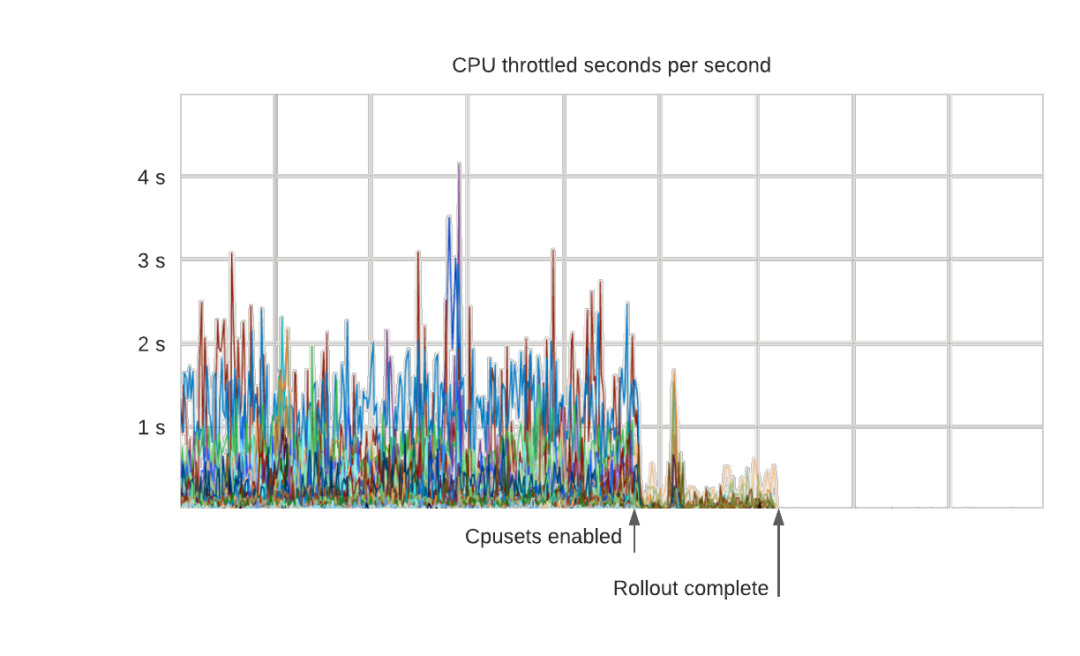
節流現象消失了,因為容器能夠自由使用所有分配的核心。更有趣的是,由於容器能夠以穩定的速率處理請求,P99 的延遲也得到了改善。在這種情況下,由於消除了嚴重的節流,延遲下降了50%左右。
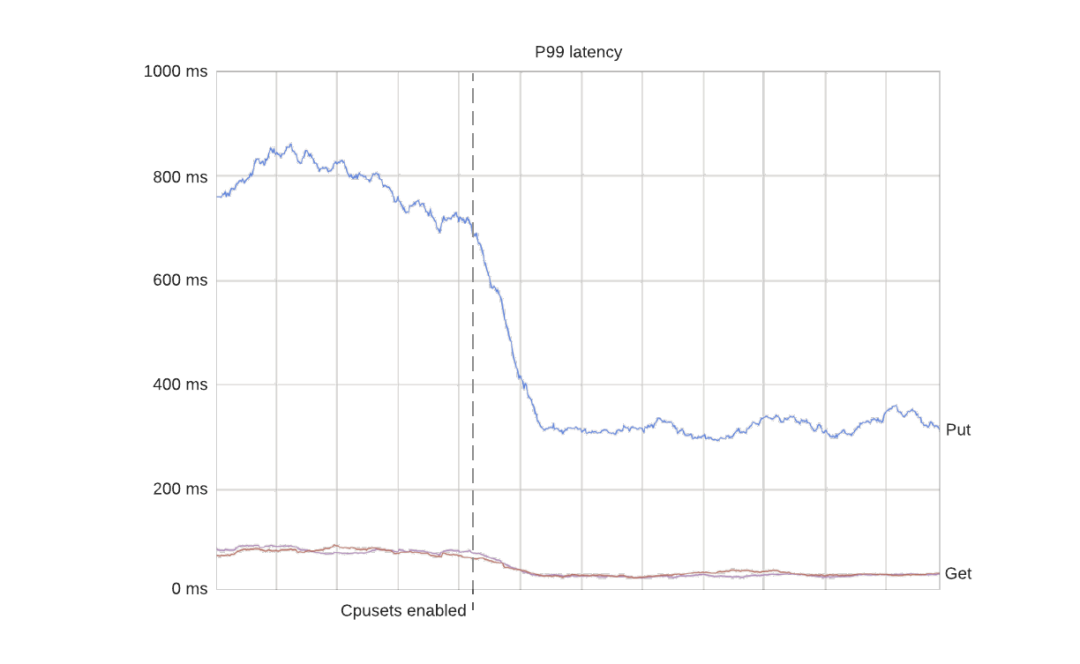
在這一點上值得注意的是,使用 cpusets 也有負面影響。特別是,P50 延遲通常會增加一點,因為它不再可能突入未分配的核心。結果 P50 和 P99 的延遲變得更接近,這通常是可取的。這點將在本文末尾進行更多討論。
五、分配 CPU
為了使用 cpusets,容器必須繫結到核心。正確分配核心需要一些關於現代 CPU 架構如何工作的背景知識,因為錯誤的分配會導致效能顯著下降。
CPU 通常圍繞以下結構構建:
一臺物理機可以有多個 CPU 插槽
每個插座都有獨立的L3快取
每個 CPU 有多個核心
每個核心都有獨立的 L2/L1 快取
每個核心都可以有超執行緒
超執行緒通常被視為核心,但分配 2 個超執行緒而不是 1 個可能只會將效能提高 1.3 倍
所有這些都意味著選擇正確的核心實際上很重要。最後一個問題是編號不是連續的,有時甚至不是確定性的——例如,拓撲可能如下所示:
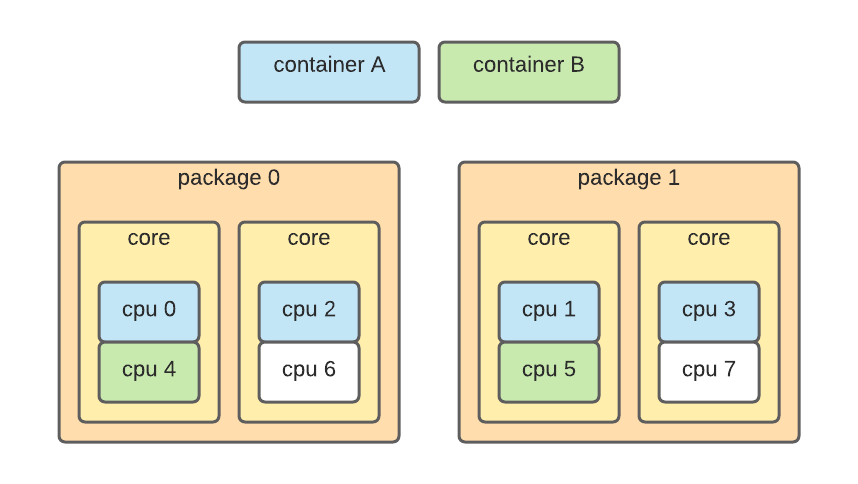
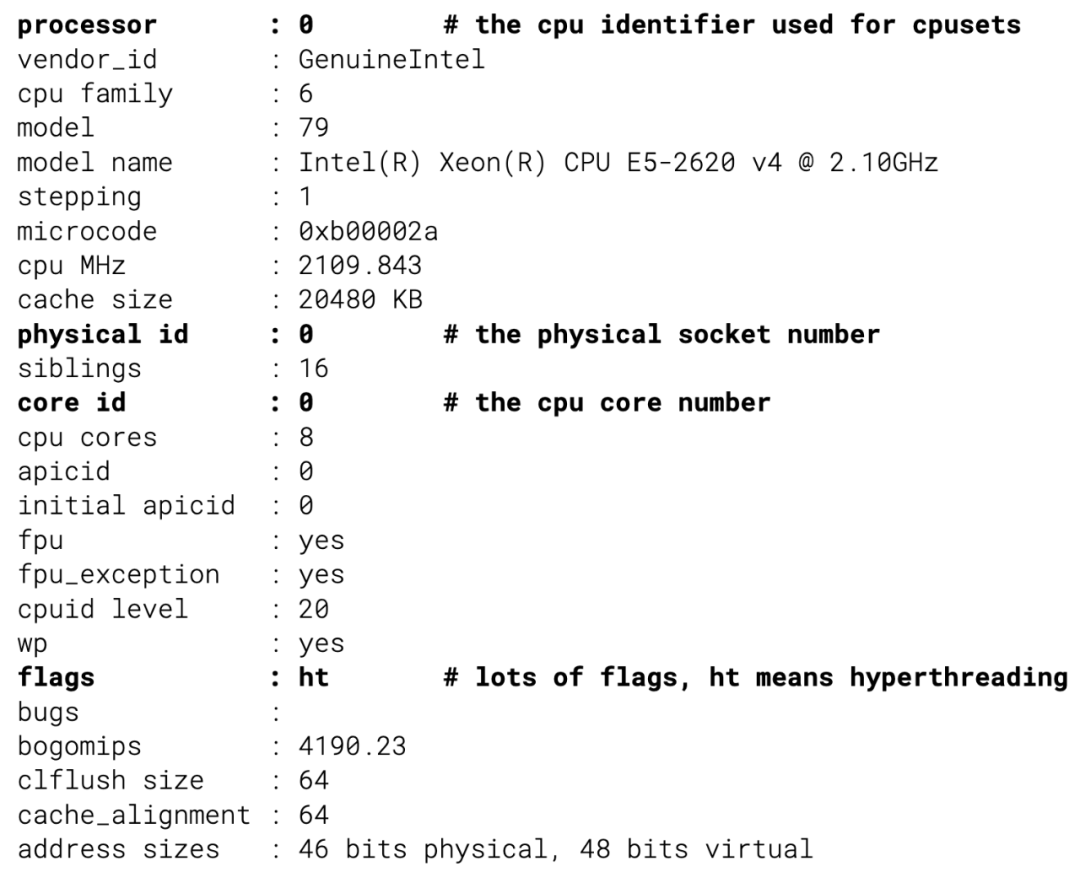
在這種情況下,一個容器被安排在物理套接字和不同的核心上,這會導致效能下降——我們已經看到由於錯誤的套接字分配,P99 延遲降低了多達 500%。為了處理這個問題,排程器必須從核心收集確切的硬體拓撲,並使用它來分配核心。原始資訊在 /proc/cpuinfo 中找到:
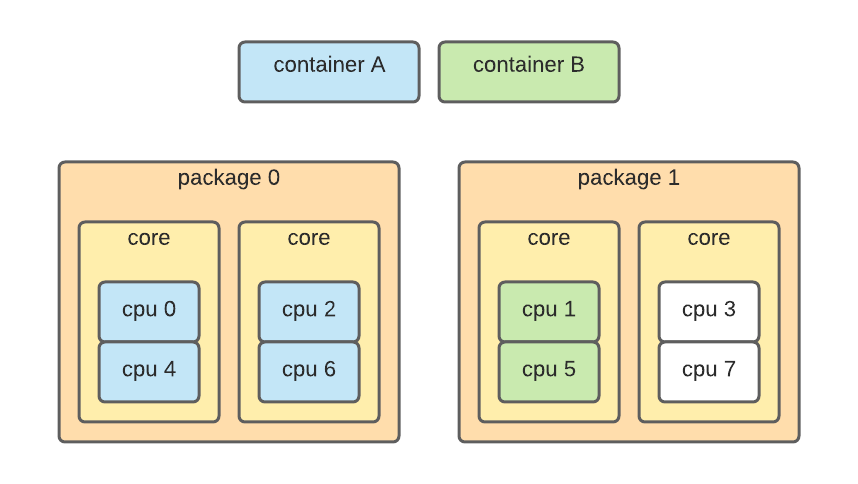
利用這些資訊,我們可以分配物理上相互接近的核心:
六、缺點和侷限性
雖然 cpusets 解決了大部分延遲的問題,但也存在一些限制和權衡:
無法分配小數核心。這對於資料庫程式來說不是問題,因為它們往往很大,因此向上或向下舍入不是問題。但是,這確實意味著容器的數量不能大於核心的數量,這對於某些工作負載來說是有問題的。
系統範圍的程式仍然可以竊取時間。例如,透過 systemd、kernel workers 等在宿主機上執行的服務,仍然需要在某個地方執行。理論上也可以將它們分配給一組有限的核心,但這可能很棘手,因為它們需要的時間與系統負載成正比。一種解決方法是在容器子集上使用實時程式排程——後文會介紹這一點。
需要進行碎片整理。隨著時間的推移,可用核心將變得碎片化,並且需要移動程式以建立連續的可用核心塊。這可以線上完成,但是從一個物理套接字移動到另一個將意味著記憶體訪問突然變得遠端。這也可以緩解,另一篇文章會介紹[2]。
沒有突發限制。有時你可能希望使用主機上未分配的資源來加速正在執行的容器。在這篇文章中,我們討論了獨佔的 cpusets,但可以將同一個核心分配給多個容器(即 cgroups),也可以將 cpusets 與配額結合使用,這允許突破限制。
七、結論
切換到有狀態工作負載的 cpusets 是 Uber 的一項重大改進。它使我們能夠實現更穩定的資料庫級別的延遲,並且透過減少過度配置以處理由於節流導致的峰值,節省了大約 11% 的核心。由於沒有突發限制,相同大小的容器現在在主機之間的表現是一樣的,這也導致了更穩定的效能。
來自 “ 雲原生技術社群 ”, 原文作者:Joakim Recht;原文連結:https://server.it168.com/a2023/0918/6821/000006821691.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 我遇過的最難的Cookie問題Cookie
- 我遇過的最難的 Cookie 問題Cookie
- 面試必問題:JS防抖與節流面試JS
- 你問我答:容器篇(1)
- JS專題之節流函式JS函式
- TF實戰Q&A丨這個問題,我以前也遇到過
- 面試疑難問題面試
- vue專案使用lodash節流防抖函式問題與解決Vue函式
- Ubuntu1804下k8s-CoreDNS佔CPU高問題排查UbuntuK8SDNS
- 節流
- JavaScript專題系列-防抖和節流JavaScript
- 04.JavaIO流問題JavaAI
- 警方披露Uber撞人案細節,解密Uber自動駕駛系統解密自動駕駛
- NP難問題求解綜述
- 我的前端筆記之 懶載入 與 節流前端筆記
- cpu使用率過高問題(Java)Java
- 如何捕獲問題SQL解決過度CPU消耗的問題SQL
- 事件節流事件
- 新 Uber 司機端是如何克服網路延遲問題
- 使用 nsenter 排查容器網路問題
- websphere 受管節點問題Web
- 教你兩招解決EOS CPU短缺問題
- 記一次排查CPU高的問題
- 回溯演算法 | 追憶那些年曾難倒我們的八皇后問題演算法
- 02_流體容器
- 面試官: 我必問的容器知識點!面試
- 由節流函式引發出我對event-loop的思考,順便刷刷爆款題函式OOP
- JVM 常見線上問題 → CPU 100%、記憶體洩露 問題排查JVM記憶體洩露
- Java —— 節點流Java
- 防抖節流
- 我遇到的小白問題
- jenkins 容器內的許可權問題Jenkins
- 工作疑難問題解決4例
- 如何解決MES交付困難問題?
- 難度2:素數距離問題
- Android學習: 疑難問題總結Android
- 我也沒想到 Springboot + Flowable 開發工作流會這麼簡單Spring Boot
- 我的創業你也可以複製:現金流的重要性創業