毫秒間查詢千億級Trace資料,SkyWalking上鍊路追蹤這麼強?
一、開篇
自從SkyWalking開始在公司推廣,時不時會在排查問題的人群中聽到這樣的話:“你咋還沒接SkyWalking?接入後,一眼就看出是哪兒的問題了…",正如同事所說的,在許多情況下,SkyWalking就是這麼秀。作為實踐者,我非常感謝SkyWalking,因為這款國產全鏈路監控產品給公司的夥伴們帶來了實實在在的幫助;也特別感謝公司的領導和同事們,正因為他們的支援和幫助,才讓這套SkyWalking(V8.5.0)系統從起初的有用進化到現在的好用;從幾十億的Segment儲能上限、幾十秒的查詢耗時,最佳化到千億級的Segment儲能、毫秒級的查詢耗時。
小提示:
SkyWalking迭代速度很快,公司使用的是8.5.0版本,其新版本的效能肯定有改善。
Segment是SkyWalking中提出的概念,表示一次請求在某個服務內的執行鏈路片段的合集,一個請求在多個服務中先後產生的Segment串起來構成一個完整的Trace,如下圖所示:

SkyWalking的這次實踐,截止到現在有一年多的時間,回顧總結一下這段歷程中的些許積累和收穫,願能反哺社群,給有需求的道友提供個案例借鑑;也希望能收穫到專家們的指導建議,把專案做得更好。因為安全約束,要把有些內容和諧掉,但也努力把這段歷程中那些靚麗的風景,儘可能完整地呈現給大家。
二、為什麼需要全鏈路監控
隨著微服務架構的演進,單體應用按照服務維度進行拆分,組織架構也隨之演進以橫向、縱向維度拆分;一個業務請求的執行軌跡,也從單體應用時期一個應用例項內一個介面,變成多個服務例項的多個介面;對應到組織架構,可能跨越多個BU、多個Owner。雖然微服務架構高內聚低耦合的優勢是不言而喻的,但是低耦合也有明顯的副作用,它在現實中給跨部門溝通、協作帶來額外的不可控的開銷;因此開發者尤其是終端業務側的架構師、管理者,特別需要一些可以幫助理解系統拓撲和用於分析效能問題的工具,便於在架構調整、效能檢測和發生故障時,縮減溝通協作方面的精力和時間耗費,快速定位並解決問題。
我所在的平安健康網際網路股份有限公司(文中簡稱公司),是微服務架構的深度實踐者。公司用網際網路技術搭建醫療服務平臺,致力於構築專業的醫患橋樑,提供專業、全面、高品質、一站式企業健康管理服務。為了進一步提高系統服務質量、提升問題響應效率,部門在21年結合自身的一些情況,決定對現行的全鏈路監控系統進行升級,目的與以下網路中常見的描述基本一致:
快速發現問題
判斷故障影響範圍
梳理服務依賴並判斷依賴的合理性
分析鏈路效能並實施容量規劃
三、為什麼選擇SkyWalking
在做技術選型時,網路中搜集的資料顯示,谷歌的Dapper系統,算是鏈路追蹤領域的始祖。受其公開論文中提出的概念和理念的影響,一些優秀的企業、個人先後做出不少非常nice的產品,有些還在社群開源共建,如:韓國的Pinpoint,Twitter的Zipkin,Uber的Jaeger及中國的SkyWalking等,我司選型立項的過程中綜合考慮的因素較多,這裡只歸納一下SkyWalking吸引我們的2個優勢:
1)產品的完善度高:
java生態,功能豐富
社群活躍,迭代迅速
2)鏈路追蹤、拓撲分析的能力強:
外掛豐富,探針無侵入
採用先進的流式拓撲分析設計
“好東西不需要多說,實際行動告訴你“,這句話我個人非常喜歡,關於SkyWalking的眾多的優點,網路上可以找到很多,此處先不逐一比較、贅述了。
四、預研階段
當時最新版本8.5.0,梳理分析8.x的釋出記錄後,評估此版本的核心功能是蠻穩定的,於是基於此版本開始了SkyWalking的探索之旅。當時的認知是有限的,序列思維模型驅使我將關注的問題聚焦在架構原理是怎樣、有什麼副作用這2個方面:
1)架構和原理:
agent端 主要關注 Java Agent的機制、SkyWalking Agent端的配置、外掛的工作機制、資料採集及上報的機制。
服務端 主要關注 角色和職責、模組和配置、資料接收的機制、指標構建的機制、指標聚合的機制及指標儲存的機制。
儲存端 主要關注 資料量,儲存架構要求以及資源評估。
2)副作用:
功能干擾
效能損耗
1、架構和原理
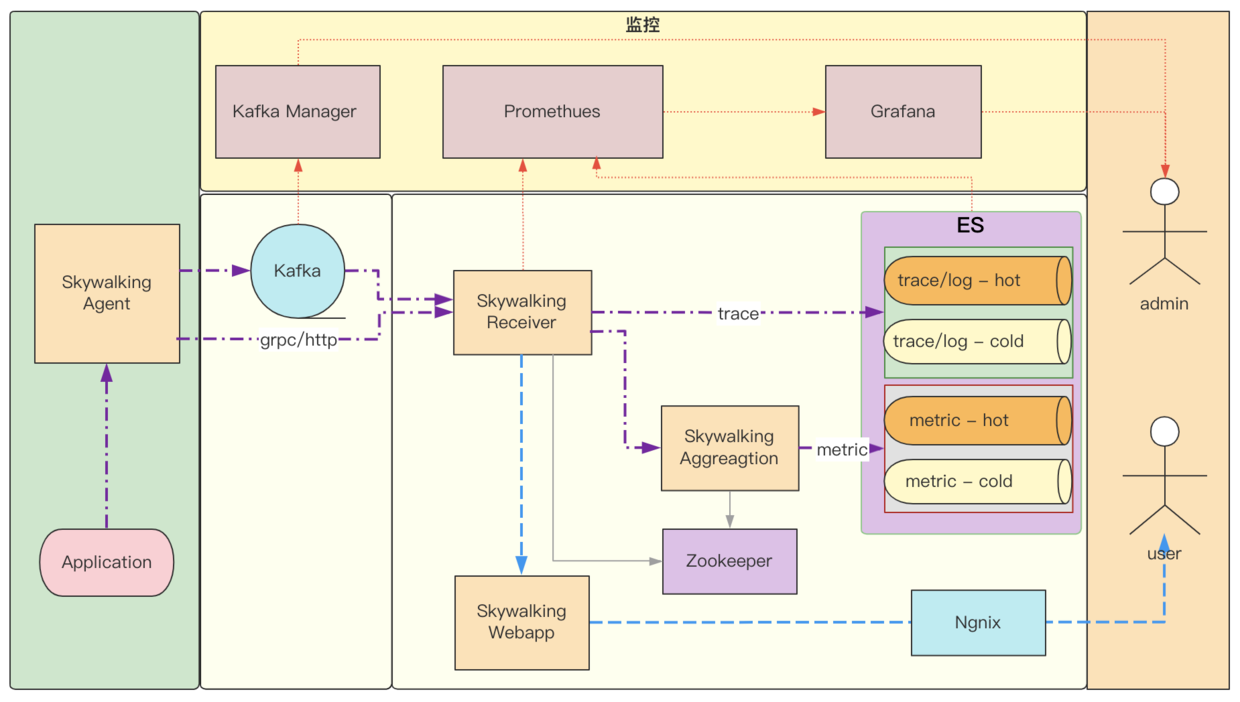
SkyWalking社群很棒,官網文件和官方出版的書籍有較系統化的講解,因為自己在APM系統以及Java Agent方面有一些相關的經驗沉澱,透過在這兩個渠道的學習,對Agent端和OAP(服務端)很快便有了較系統化的認知。在做系統架構選型時,評估資料量會比較大(成千上萬的JVM例項數,每天採集的Segment數量可能是50-100億的級別),所以傳輸通道選擇Kafka、儲存選擇Elasticsearch,如此簡易版的架構以及資料流轉如下圖所示:
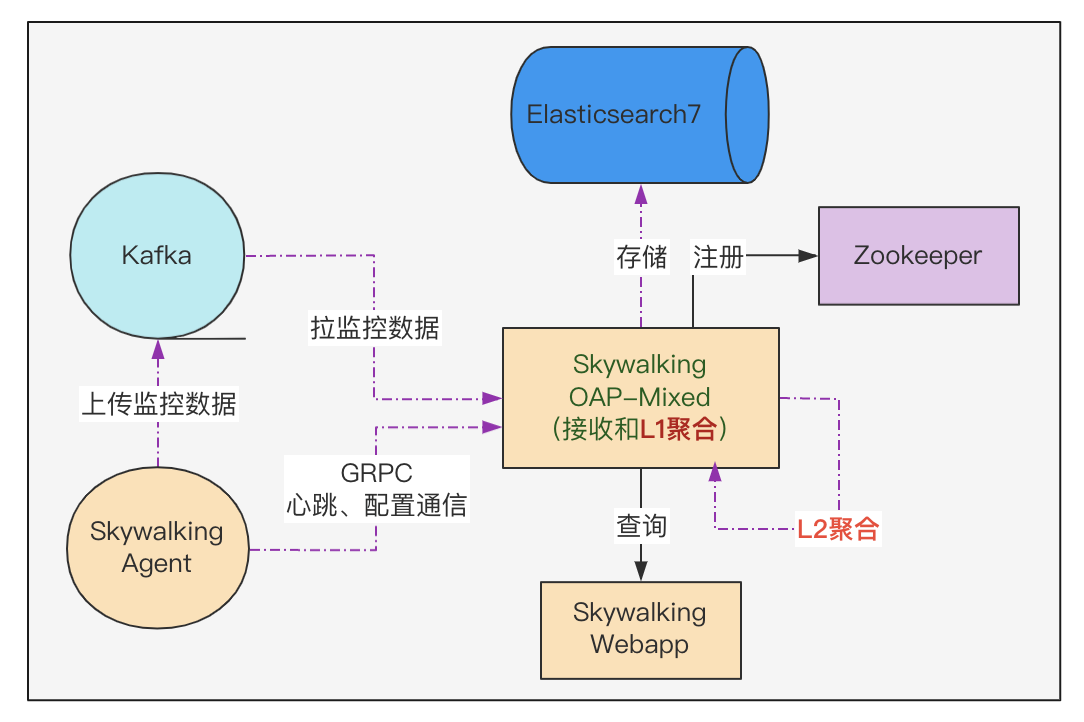
這裡有幾處要解釋一下:
Agent上報資料給OAP端,有grpc通道和kafka通道,當時就盲猜grpc通道可能撐不住,所以選擇kafka通道來削峰;kafka通道是在8.x里加入的。
千億級的資料用ES來做儲存肯定是可以的。
圖中L1聚合的意思是:SkyWalking OAP服務端 接收資料後,構建metric並完成metric 的Level-1聚合,這裡簡稱L1聚合。
圖中L2聚合的意思是:服務端 基於metric的Level-1聚合結果,再做一次聚合,即Level-2聚合,這裡簡稱L2聚合。後續把純Mixed角色的叢集拆成了兩個叢集。
2、副作用
對於質量團隊和接入方來說,他們最關注的問題是,接入SkyWalking後:
是否對應用有功能性干擾
在執行期能帶來哪些效能損耗
這兩個問題從3個維度來得到答案:
1)網路資料顯示:
Agent帶來的效能損耗在5%以內
未搜到功能性干擾相關的資料(盲猜沒有這方面問題)
2)實現機制評估:
位元組碼增強機制是JVM提供的機制,SkyWalking使用的位元組碼操控框架ByteBuddy也是成熟穩定的;透過自定義ClassLoader來載入管理外掛類,不會產生衝突和汙染。
Agent內外掛開發所使用的AOP機制是基於模板方法模式實現的,風控很到位,即使外掛的實現邏輯有異常也不影響使用者邏輯的執行。
外掛採集資料跟上報邏輯之間用了一個輕量級的無鎖環形佇列進行解耦,算是一種保護機制;這個佇列在MPSC場景下效能還不錯;佇列採用滿時丟棄的策略,不會有積壓阻塞和OOM。
3)效能測試驗證:
測試的老師針對dubbo、http這兩種常規RPC通訊場景,進行壓力測試和穩定性測試,結果與網路資料描述一致,符合預期。
五、POC階段
在POC階段,接入幾十個種子應用,在非生產環境試點觀察,同時完善外掛補全鏈路,對接公司的配置中心,對接釋出系統,完善自監控,全面準備達到推廣就緒狀態。
1、對接釋出系統
為了對接公司的釋出系統,方便系統的釋出,將SkyWalking應用拆分為4個子應用:
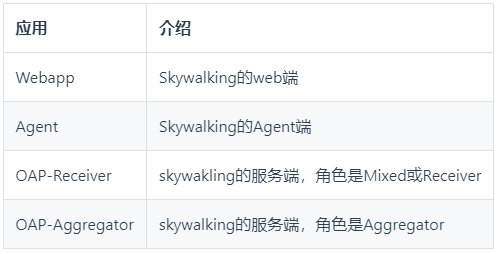
這裡有個考慮,暫定先使用純Mixed角色的單叢集,有效能問題時就試試 Receiver+Aggregator雙角色叢集模式,最終選哪種視效果而定。
SkyWalking Agent端是基於Java Agent機制實現的,採用的是啟動掛載模式;啟動掛載需在啟動指令碼里加入掛載Java Agent的邏輯,釋出系統實現這個功能需要注意2點:
啟動指令碼掛載SkyWalking Agent的環節,儘量讓使用者無感知。
釋出系統在掛載Agent的時候,給Agent指定應用名稱和所屬分組資訊。
SkyWalking Agent的釋出和升級也由釋出系統來負責;Agent的升級採用了灰度管控的方案,控制的粒度是應用級和例項級兩種:
按照應用灰度,可給應用指定使用什麼版本的Agent
按照應用的例項灰度,可給應用指定其若干例項使用什麼版本的Agent
2、完善外掛補全鏈路
針對公司OLTP技術棧,量身定製了外掛套,其中大部分在開源社群的外掛庫中有,缺失的部分透過自研快速補齊。
這些外掛給各元件的核心環節埋點,採集資料上報給SkyWalking後,Web端的【追蹤】頁面就能勾勒出豐滿完美的請求執行鏈路;這對架構師理解真實架構,測試同學驗證邏輯變更和分析效能損耗,開發同學精準定位問題都非常的有幫助。這裡借官方線上Demo的截圖一用(抱歉後端程式設計師,五毛特效都沒做出來,豐滿畫面還請自行腦補)
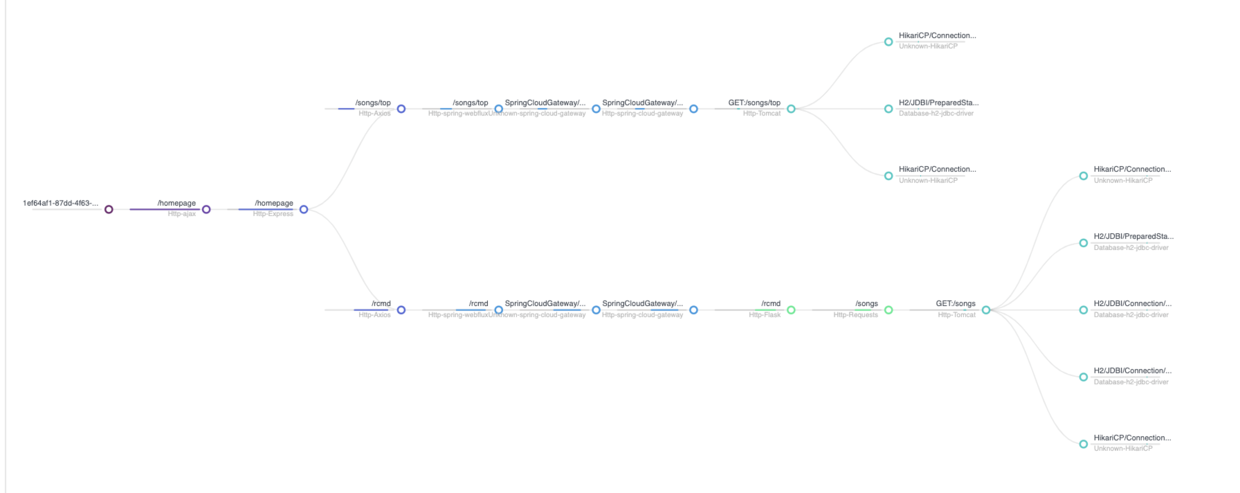
友情小提示:移除不用的外掛對程式編譯打包和減少應用啟動耗時很有幫助。
3、壓測穩測
測試的老師,針對SkyWalking Agent端的外掛套,設計了豐富的用例,壓力測試和穩定性測試的結果都符合預期;每家公司的標準不盡一致,此處不再贅述。
4、對接自研的配置中心
把應用中繁雜的配置交給配置中心來管理是非常必要的,配置中心既能提供啟動時的靜態配置,又能管理執行期的動態配置,而且外部化配置的機制特別容易滿足容器場景下應用的無狀態化要求。囉嗦一下,舉2個例子:
調優時,修改引數的值不用來一遍開發到測試再到生產的釋出。
觀測系統狀態,修改日誌配置後不需要來一遍開發到測試再到生產的釋出。
Skywaling在外接配置中心這塊兒,適配了市面中主流的配置中心產品。而公司的配置中心是自研的,需要對接一下,得益於SkyWalking提供的模組化管理機制,只用擴充套件一個模組即可。
在POC階段,梳理服務端各模組的功能,能感受到其配置化做的不錯,配置項很豐富,管控的粒度也很細;在POC階段幾乎沒有變動,除了對Webapp模組的外部化配置稍作改造,與配置中心打通以便在配置中心管理Webapp模組中Ribbon和Hystrix的相關配置。
5、完善自監控
自監控是說監控SkyWalking系統內各模組的運轉情況:
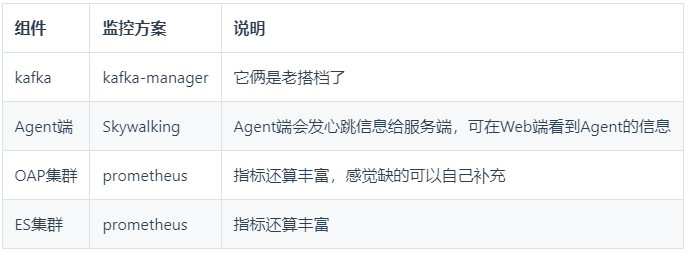
完善自監控後的架構如下圖所示:
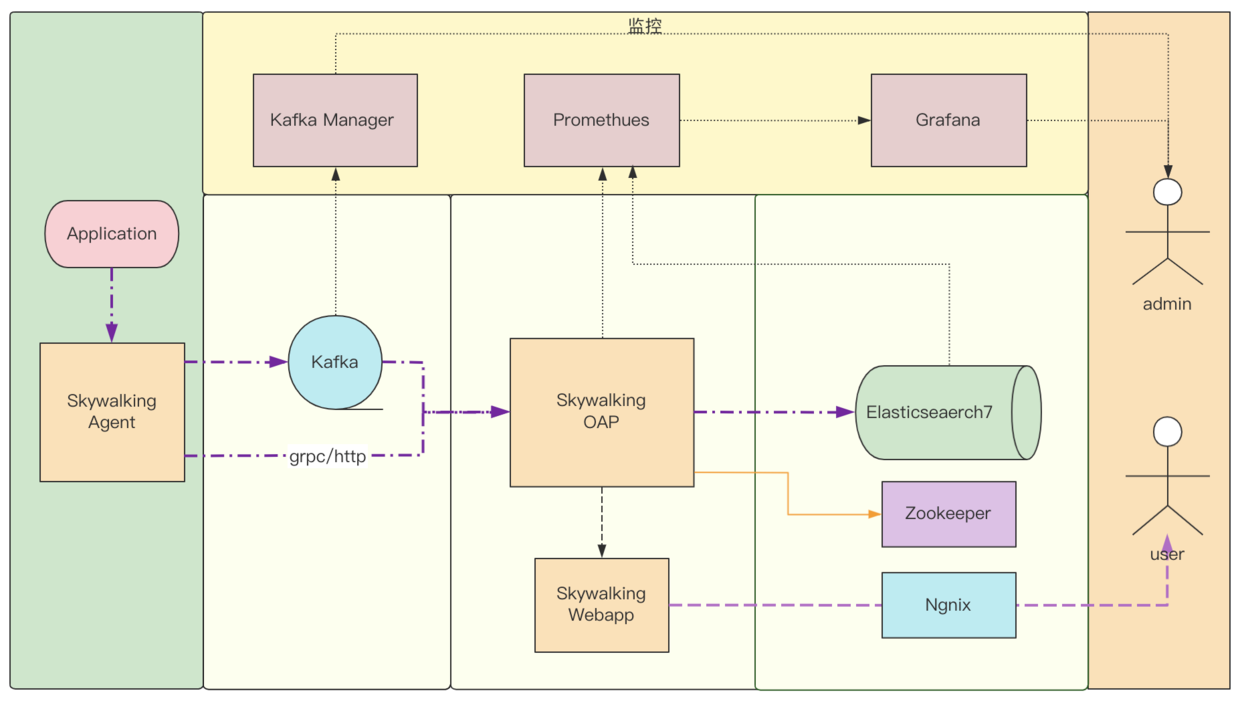
6、自研Native端SDK
公司移動端的應用很核心,也要使用鏈路追蹤的功能,社群缺了這塊,於是基於SkyWalking的協議,移動端的夥伴們自研了一套SDK,彌補了Native端鏈路資料的缺失,也在後來的秒開頁面指標統計中發揮了作用。隨著口口相傳,不斷有團隊提出需求、加入建設,所以也在持續迭代中;內容很多,這裡先不展開。
7、小結
POC階段資料量不大,主要是發現系統的各種功能性問題,查缺補漏。
六、最佳化階段
SkyWalking的正式推廣採用的是城市包圍農村的策略;公司的核心應用作為第一批次接入,這個策略有幾個好處:
核心應用的監管是重中之重,優先順序預設最高。
核心應用的上下游應用,會隨著大家對SkyWalking依賴的加深,而逐步自主接入。
當然安全是第一位的,無論新系統多好、多厲害,其引入都需遵守安全穩定的前提要求。既要安全又要快速還要方便,於是基於之前Agent灰度接入的能力,在釋出系統中增加應用Owner自助式灰度接入和快速解除安裝SkyWalking Agent的能力,即應用負責人可自主選擇哪個應用接入,接入幾個例項,倘若遇到問題僅透過重啟即可完成快速解除安裝;這個能力在推廣的前期發揮了巨大的作用;畢竟安全第一,信任也需逐步建立。
隨著應用的接入、使用,我們也逐漸遇到了一些問題,這裡按照時間遞增的順序將問題和最佳化效果快速的介紹給大家,更多技術原理的內容計劃在公眾號『架構染色』專輯【SkyWalking調優系列】補充。開始之前有幾個事項要說明:
下文中提到的數字僅代表我司的情況,標註的Segment數量是處理這個問題的那段時間的情況,並不是說達到這個數量才開始出現這個現象。
這些數值以及當時的現象,受到宿主機配置、Segment資料的大小、儲存處理能力等多種因素的影響;請關注調整的過程和效果,不必把數字和現象對號入座哈。
1、啟動耗時
1)問題
有同事反饋應用啟動變慢,排查發現容器中多數應用啟動的總耗時,在接入SkyWalking前是2秒,接入後變成了16秒以上,公司很多核心應用的例項數很多,這樣的啟動損耗對它們的釋出影響太大。
2)最佳化
記錄啟動耗時並隨著其他啟動資料上報到服務端,方便檢視對比。
最佳化Kafka Reporter的啟動過程,將啟動耗時減少了3-4秒。
最佳化類匹配和增強環節(重點)後,容器中的應用啟動總耗時從之前16秒以上降低到了3秒內。
梳理Kafka 啟動和上報的過程中,順帶調整了Agent端的資料上報到kafka的分割槽選擇策略,將一個JVM例項中的資料全部傳送到同一個的分割槽中,如此在L1層的聚合就完成了JVM例項級的Metric聚合,需注意調整Kafka分片數來保證負載均衡。
2、kafka積壓-6億segment/天
1)問題
SkyWalking OAP端消費慢,導致Kafka中Segment積壓。未能達到能用的目標。
2)最佳化
從SkyWalking OAP端的監控指標中沒有定位出哪個環節的問題,把服務端單叢集拆為雙叢集,即把 Mixed角色的叢集 ,修改為 Receiver 角色(接收和L1聚合)的叢集 ,並加入 Aggregation角色(L2聚合)的叢集,調整成了雙叢集模式,資料流傳如下圖所示:
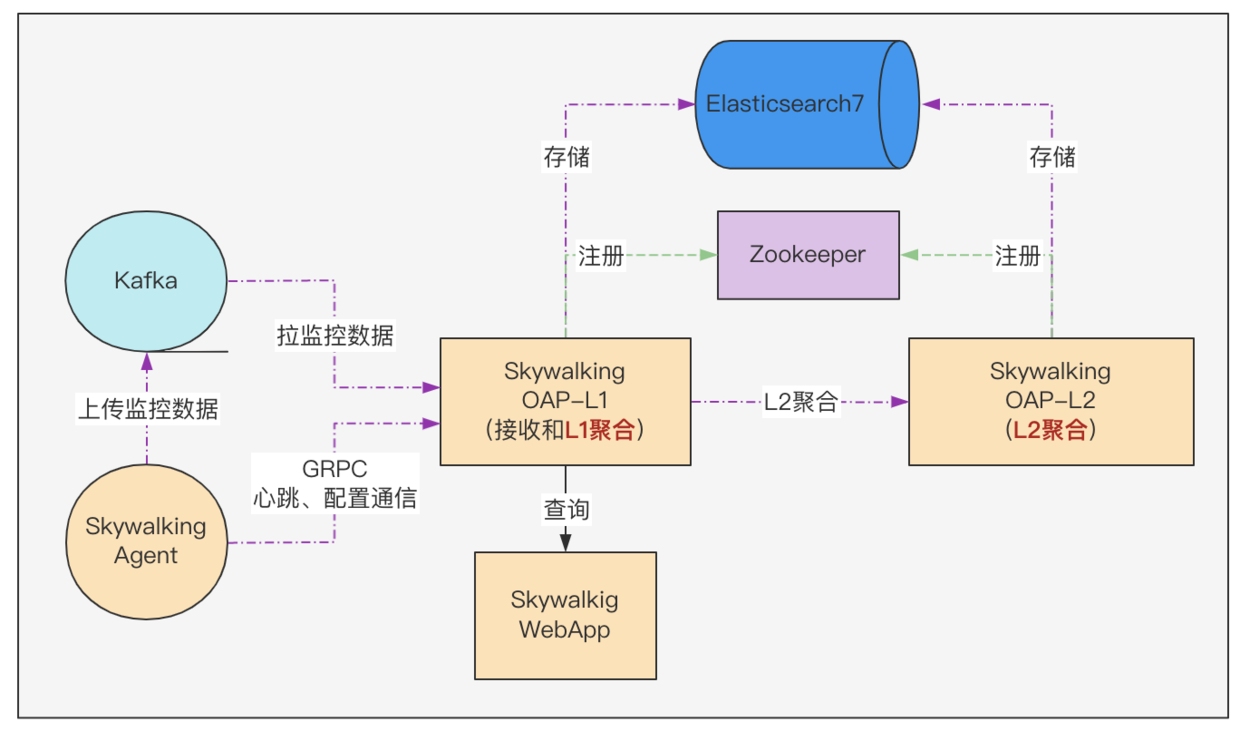
3、kafka積壓-8億segment/天
1)問題
SkyWalking OAP端消費慢,導致Kafka中Segment積壓,監控指標能看出是在ES儲存環節慢,未能達到能用的目標。
2)最佳化
最佳化segment儲存到ES的批處理過程,調整BulkProcessor的執行緒數和批處理大小。
最佳化metrics儲存到ES的批處理過程,調整批處理的時間間隔、執行緒數、批處理大小以及刷盤時間。
4、kafka積壓-20億segment/天
1)問題
Aggregation叢集的例項持續Full GC,Receiver叢集透過grpc給Aggregation叢集傳送metric失敗。未能達到能用的目標。
2)最佳化
增加ES節點、分片,效果不明顯。
ES叢集有壓力,但無法精準定位出是什麼資料的什麼操作引發的。採用分治策略,嘗試將資料拆分,從OAP服務端讀寫邏輯調整,將ES單叢集拆分為 trace叢集 和 metric叢集;之後對比ES的監控指標明確看出是metric叢集讀寫壓力太大。
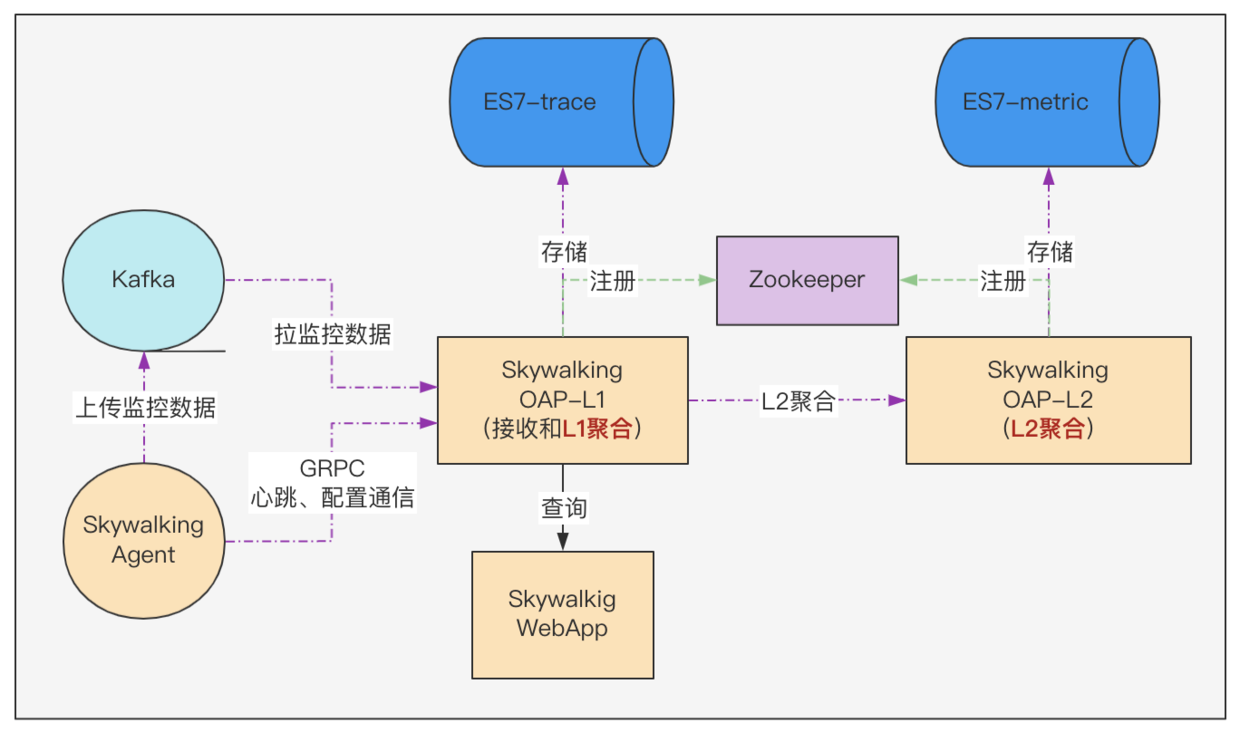
最佳化Receiver叢集metric的L1聚合,完成1分鐘的資料聚合後,再提交給Aggregation叢集做L2聚合。
Aggregation叢集metric的L2 聚合是基於db實現的,會有 空讀-寫-再讀-累加-更新寫 這樣的邏輯,每次寫都會有讀,調整邏輯是:提升讀的效能,最佳化快取機制減少讀的觸發;調整間隔,避免觸發累加和更新。
將metric批次寫ES操作調整成BulkProcessor。
ES的metric叢集使用SSD儲存,增加節點數和分片數。
這一次的持續最佳化具有里程碑式的意義,Kafka消費很快,OAP各機器的Full GC沒了,ES的各方面指標也很穩定;接下來開始最佳化查詢,提升易用性。
5、trace查詢慢-25億segment/天
1)問題
Web端【追蹤】頁中的查詢都很慢,僅儲存了15天的資料,按照traceId查詢耗時要20多秒,按照條件查詢trace列表的耗時更糟糕;這給人的感受就是“一肚子墨水倒不出來”,未能達到好用的目標。
2)最佳化
ES查詢最佳化方面的資訊挺多,但透過百度篩選出解決此問題的有效方案,就要看我們家愛犬的品類了;當時蒐集整理了並嘗試了N多最佳化條款,可惜沒有跟好運偶遇,結論是顏值不可靠。言歸正傳,影響讀寫效能的基本要素有3個:讀寫頻率,資料規模,硬體效能;trace的情況從這三個維度來套一套模板:

這個分析沒有得出具有指導意義的結論,讀寫頻率這裡粒度太粗,使用者的使用情況跟時間也有緊密的關係,情況大概是:
當天的資料是讀多寫多(當天不斷有新資料寫入,基於緊急響應的需求,問題出現時可能是近實時的排查處理)。
前一天的資料是讀多寫少(一般也會有問題隔天密集上報的情況,0點後會有前一天資料延遲到達的情況)。
再早的話無新資料寫入,資料越早被讀的機率也越小。
基於以上分析,增加時間維度並細化更多的參考因素後,分析模型變成了這樣:
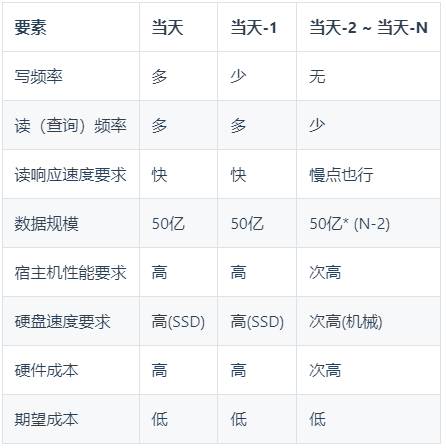
從上表可以看出,整體呈現出hot-warm資料架構的需求之勢,近1-2天為hot資料,之前的為warm資料;恰好ES7提供了hot-warm架構支援,按照hot-warm改造後架構如下圖所示:
恰逢公司ES中臺調優版的ES釋出,其內建的ZSTD壓縮演算法空間壓縮效果非常顯著。
對 trace叢集進行hot-warm架構調整,查詢耗時從20多秒變成了2-3秒,效果是非常明顯的。
從查詢邏輯進一步調整,充分利用ES的資料分片、路由機制,把全量檢索調整為精準檢索,即降低檢索時需要掃描的資料量,把2-3秒最佳化到毫秒。
這裡要炫一個5毛特效,這套機制下,Segment資料即使是保留半年的,按照TraceId查詢的耗時也是毫秒。
至此完成了查詢千億級Trace資料只要毫秒級耗時的階段性最佳化。
6、儀表盤和拓撲查詢慢
1)問題
Web端的【拓撲】頁,在開始只有幾十個應用的時候,雖然很慢,但還是能看到資料,隨著應用增多後,【拓撲】頁面資料請求一直是超時(配置的60s超時)的,精力有限,先透過功能降級把這個頁面隱藏了;【儀表盤】的指標查詢也非常的慢,未能達到好用的目標。
2)最佳化
Web端的【儀表盤】頁和【拓撲】頁是對SkyWalking裡metric資料的展現,metric資料同trace資料一樣滿足hot-warm的特徵。
①metric叢集採用hot-warm架構調整,之後儀表盤中的查詢耗時也都減小為毫秒級。
②【拓撲】頁介面依然是超時(60s),對拓撲這裡做了幾個針對性的調整:
把內部的迴圈呼叫合併,壓縮呼叫次數。
去除非必要的查詢。
拆分隔離通用索引中的資料,避免互相干擾。
全量檢索調整為精準檢索,即降低檢索時需要掃描的資料量。
至此完成了拓撲頁資料查詢毫秒級耗時的階段性最佳化。
7、小結
SkyWalking調優這個階段,恰逢上海疫情封城,既要為生存搶菜,又要翻閱學習著各種ES原理、調優的文件資料,一行一行反覆的品味思考SkyWalking相關的原始碼,嘗試各種方案去最佳化它,夢中都在努力提升它的效能。疫情讓很多人變得焦慮煩躁,但以我的感受來看在系統的效能壓力下疫情不值一提。凡事貴在堅持,時間搞定了諸多困難,調優的效果是很顯著的。
可能在業務價值驅動的價值觀中這些技術最佳化不產生直接業務價值,頂多是五毛特效,但從其他維度來看它價值顯著:
對個人來說,技術有提升。
對團隊來說,實戰練兵提升戰力,團隊協作加深友情;特別感謝ES中臺這段時間的鼎力支援!
對公司來說,易用性的提升將充分發揮SkyWalking的價值,在問題發生時,給到同事們切實、高效的幫助,使得問題可以被快速響應;須知戰爭拼的是保障。
這期間其實也是有考慮過其他的2個方案的:
使用降低取樣率的兜底方案;但為了得到更準確的指標資料,以及後續其他的規劃而堅持了全取樣。
採用ClickHouse最佳化儲存;因為公司有定製最佳化的ES版本,所以就繼續在ES上做儲存最佳化,剛好藉此機會驗證一下。後續【全鏈路結構化日誌】的儲存會使用ClickHouse。
這個章節將內容聚焦在落地推廣時期技術層面的準備和調優,未描述團隊協調、推廣等方面的情況;因每個公司情況不同,所以並未提及;但其實對多數公司來說,有些專案的推廣比技術本身可能難度更大,這個專案也遇到過一些困難,PM去推廣是既靠能力又靠顏值, 以後有機會再與大家探討。
七、未來規劃
H5、Native以及後端應用都在持續接入中,相應的SDK也在不斷地迭代;目前正在基於已建立的鏈路通道,完善【全鏈路業務狀態追蹤】和【全鏈路結構化日誌追蹤】,旨在給運營、客服、運維、開發等服務在一線的同事們提供多視角一站式的觀測平臺,全方位提升系統服務質量、提高問題響應速度。
來自 “ dbaplus社群 ”, 原文作者:石頁兄;原文連結:http://server.it168.com/a2022/1010/6767/000006767449.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- skywalking鏈路追蹤
- Istio Trace鏈路追蹤方案
- 微服務鏈路追蹤元件 SkyWalking微服務元件
- 鏈路追蹤_SkyWalking的部署及使用
- 日誌收集和鏈路追蹤:skywalking
- Elasticsearch如何做到億級資料查詢毫秒級返回?Elasticsearch
- druid查詢原始碼追蹤UI原始碼
- 1.3萬億條資料查詢如何做到毫秒級響應?
- 分散式鏈路追蹤自從用了SkyWalking,睡得真香!分散式
- .NET6接入Skywalking鏈路追蹤完整流程
- SkyWalking —— 分散式應用監控與鏈路追蹤分散式
- 微服務追蹤SQL上報至Jaeger(支援Istio管控下的gorm查詢追蹤)微服務SQLGoORM
- 鏈路追蹤 SkyWalking 原始碼分析 —— 除錯環境搭建原始碼除錯
- 分散式應用追蹤系統 - Skywalking分散式
- 微服務追蹤SQL(支援Isto管控下的gorm查詢追蹤)微服務SQLGoORM
- 上億級別資料庫查詢資料庫
- .NET Core整合SkyWalking+SkyAPM-dotne實現分散式鏈路追蹤分散式
- gRPC的請求追蹤神器 go tool traceRPCGo
- 得物雲原生全鏈路追蹤Trace2.0-採集篇
- Spring cloud 整合 SkyWalking 實現效能監控、鏈路追蹤、日誌收集SpringCloud
- B站直播的極速排障建設-全鏈路Trace追蹤
- 鏈路追蹤(Tracing)的前世今生(上)
- oracle 並行查詢時並行資源分配追蹤測試Oracle並行
- 鏈路追蹤
- Oracle執行語句跟蹤 使用sql trace實現語句追蹤OracleSQL
- 註解列印日誌和資料鏈路追蹤
- 搭建資料追蹤系統
- Skywalking-02:如何寫一個Skywalking trace外掛
- 少即是多:從分鐘級提升到毫秒級的PostgreSQL查詢SQL
- 毫秒級查詢的離線IP地址定位庫,太實用了!
- NFTScan x TiDB丨一棧式 HTAP 資料庫為 Web3 資料服務提供毫秒級多維查詢TiDB資料庫Web
- Tockler for Mac時間追蹤工具Mac
- Spring Cloud 鏈路追蹤SpringCloud
- go的鏈路追蹤Go
- DHorse的鏈路追蹤
- 百億級資料分表後怎麼分頁查詢?
- 在MongoDB資料庫中查詢資料(上)MongoDB資料庫
- golang 接入鏈路追蹤(opentracing)Golang