挑戰拯救痴心“舔狗”,我和大模型都盡力了
机器之心發表於2024-04-24
天降猛男,大模型化身為 “痴情男大”,等待人類玩家的拯救。一款名為 “拯救舔狗” 的大模型原生小遊戲出現了。遊戲規則很簡單:如果玩家在幾輪對話內說服 “他” 放棄追求對他並無青睞的女神,就算挑戰成功。聽起來並不難,然而遊戲源於生活,模型人設是痴情屬性,相當油鹽不進且自我攻略,在長達近一個小時的 “勸說” 中,大模型 “好友” 偶有鬆動但又要堅持的態度很有些現實意味。遊戲開頭是一個利好訊息 —— 女生回覆了他的訊息,透過幾輪對話,模型很清晰地交代了過往經歷和現有情況。
與真實世界走向一致,在他的描述中會發現他的感知與實際情況存在較大出入,但自身卻不願正視。這也是這個遊戲的難點,這個模型相當 “擬人”,你無論對他提出怎樣的質疑,,他都保持著如此思維方式,並且記憶力清晰,完全不存在驢唇不對馬嘴的情況,不存在任何人設崩塌的時刻。
當然人類玩家也並非勢單力薄,如果你詞窮了,AI 會根據上下文智慧地提供一些提示詞,讓遊戲繼續下去。最後在提示詞的幫助下,以及挑破告白失敗無數次的慘痛現實,玩家和大模型都收穫了絕美兄弟情,最終挑戰成功。
這款大模型原生小遊戲正是基於商量擬人大模型 “SenseChat-Character” 打造的試玩體驗程式,“SenseChat-Character” 是由商湯原創打造的語言大模型產品。
體驗地址:https://character.sensetime.com/商量 - 擬人大模型可以熟練地 “捏人”,支援個性化角色建立與定製、知識庫構建、長對話記憶、多人群聊等功能,這是一款充滿趣味性和情緒價值的大模型,可以用於情感陪伴、影視 / 動漫 / 網文 IP 角色、明星 / 網紅 / 藝人 AI 分身、語言角色扮演遊戲等擬人對話場景。除 “拯救舔狗挑戰” 遊戲外,商量 - 擬人大模型還提供了多種各類影視角色,例如蘇妲己、高啟強,以及馬斯克等現實名人。
由於商量 - 擬人大模型支援長對話記憶,使 AI 角色可精準記憶幾十輪以上歷史對話內容,還能進行深度 “專訪”。這些種種快樂體驗均得益於在今日商湯技術交流日上 “全新升級的日日新 SenseNova 5.0” 大模型體系。自去年 4 月首次面世,商湯 “日日新 SenseNova” 大模型體系已正式推出五個大版本迭代。本次日日新 5.0 升級一大亮點在於多模態能力的注入,互動能力及整體效能大幅提升。這些卓越的效能都整合在了 “商量” 應用中,我們來試一下。
體驗連結:商湯商量語言大模型 (sensetime.com)https://chat.sensetime.com/wb/login從商湯商量的最新頁面可以看出兩大功能 —— 對話和文件,前者側重問答,後者側重多類文件解析。我們從對話開始,先是基礎問答,優秀的大模型必須文理雙修,我們直接上高考題。首先是文字創作,去年的全國高考作文題目,完美理解考題立意 —— 科技發展帶來的兩面性,迅速寫出一篇文章,論述現狀並且給出解決方向,文采和邏輯兼備。
再來一道 2023 年北京高考卷的一道數學題,我們直接把卷面截圖上傳給商量,這樣即能直接檢驗數學能力,還能考驗商量跨模態的 OCR 識別能力:
事實上增加了多模態能力後,商量應對混合場景的對話能力大幅提升,不少任務都能在一次提問中得到答案。單模態的混合場景任務更是不在話下,直接看看程式碼能力 ——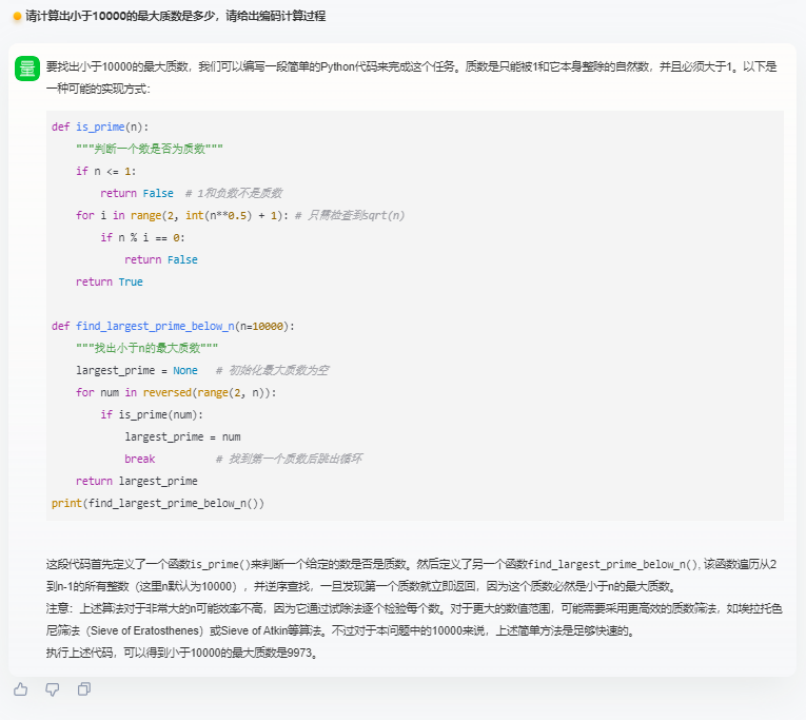
在邏輯推理的測試中,我們直接邀請了邏輯推理的語料之神,“弱智吧 Benchmark” 進行測評:商量也覺得這個問題很有意思,然後理性又耐心的語氣解釋了這個問題,最後還送上了安慰,很有耐心一模型了。

然後就是檔案處理,現在可以支援上傳 5 個檔案,丟本《道德經》進去 ——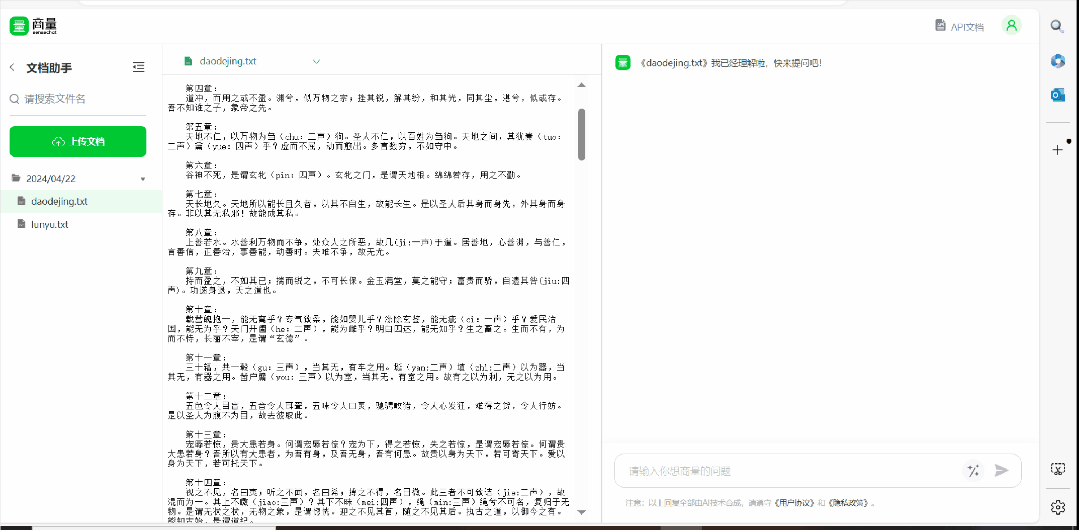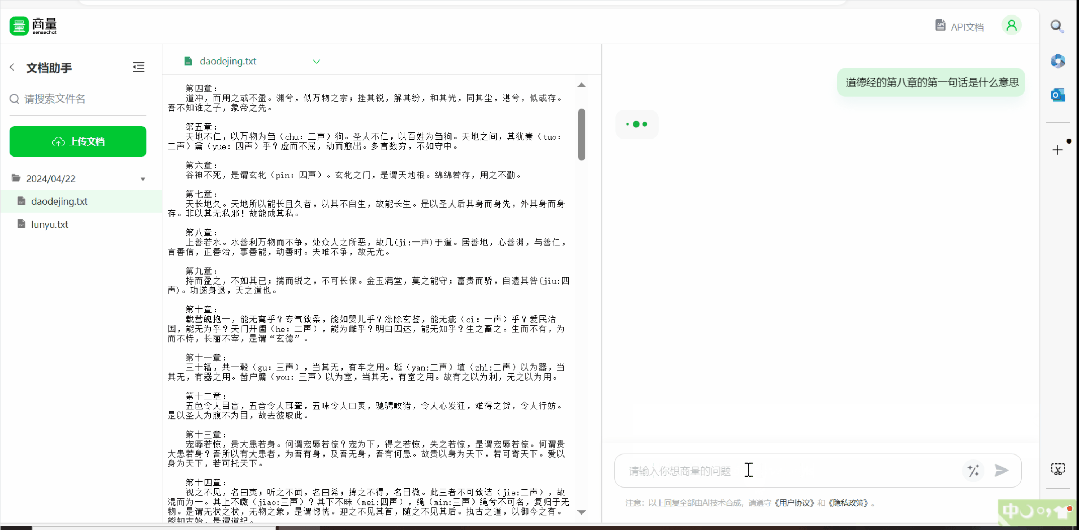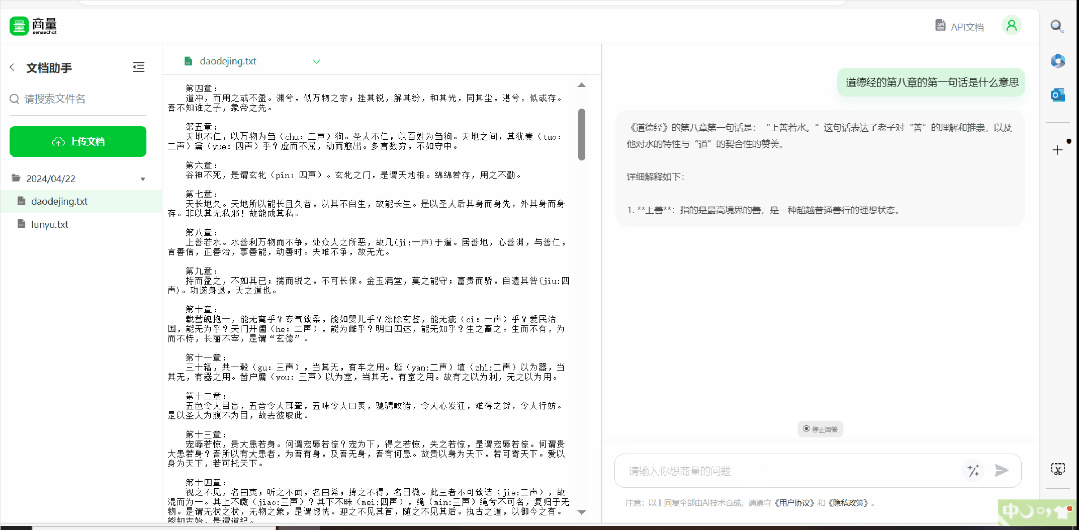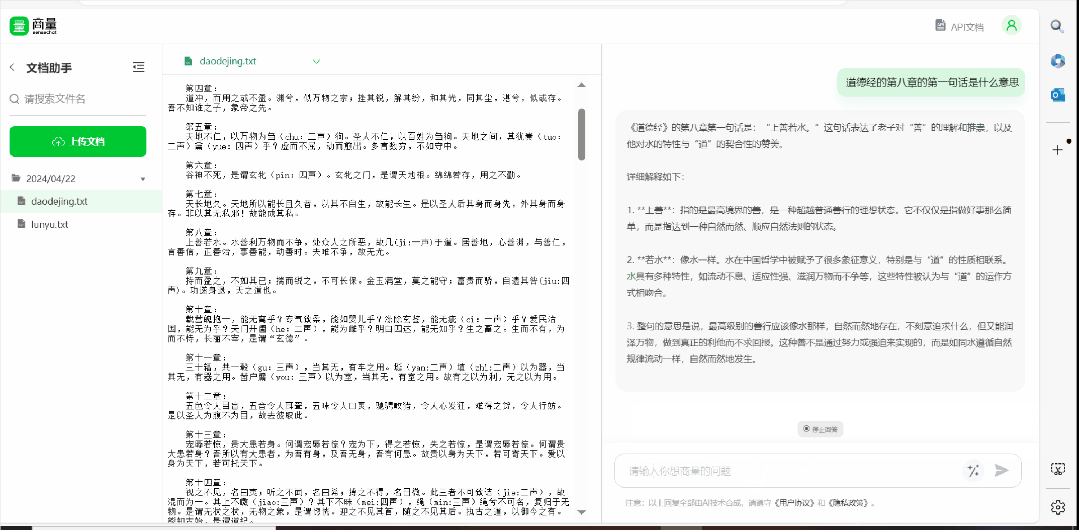
快要考試了,傳個試卷、題庫進去,快速找出一些重點考題,還可以指定題目型別,提高複習效率就是這麼 easy——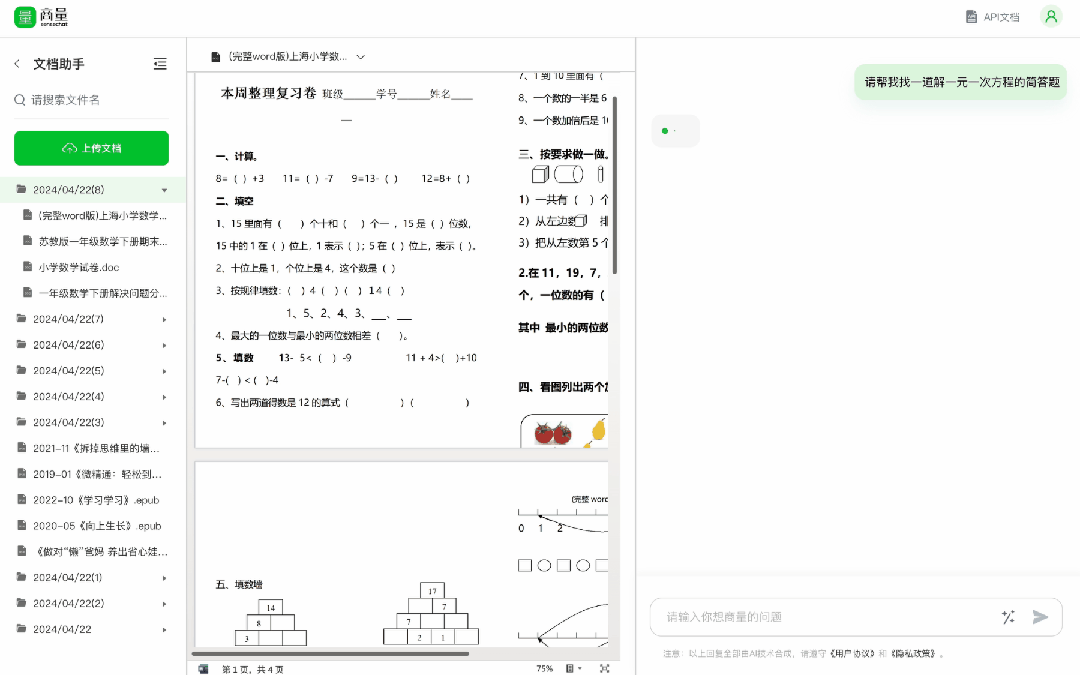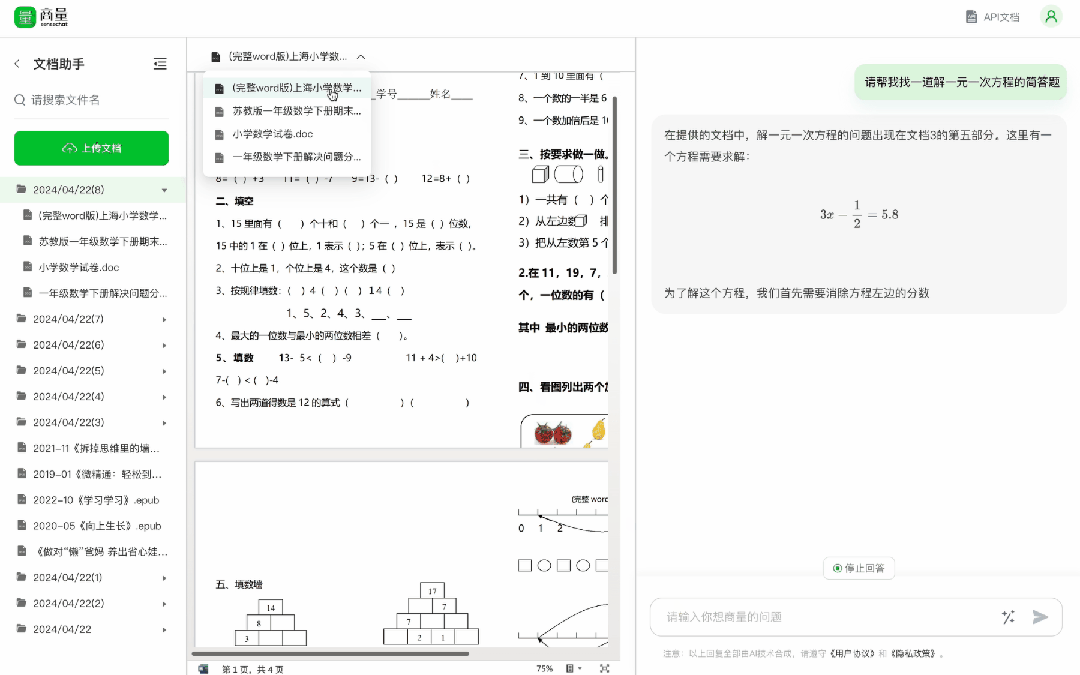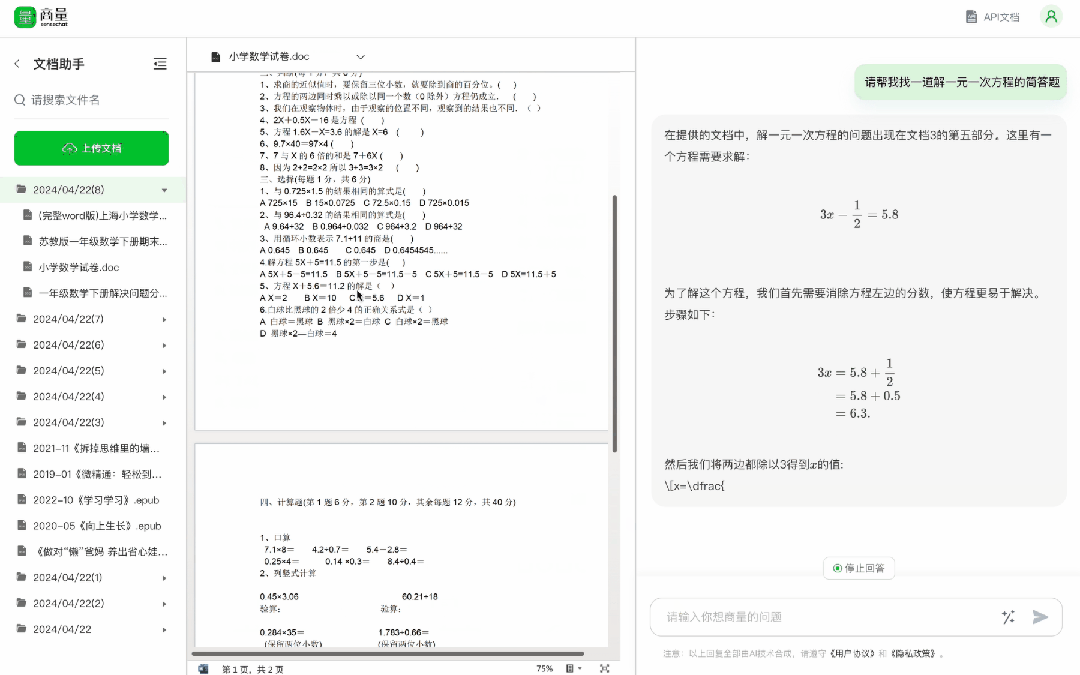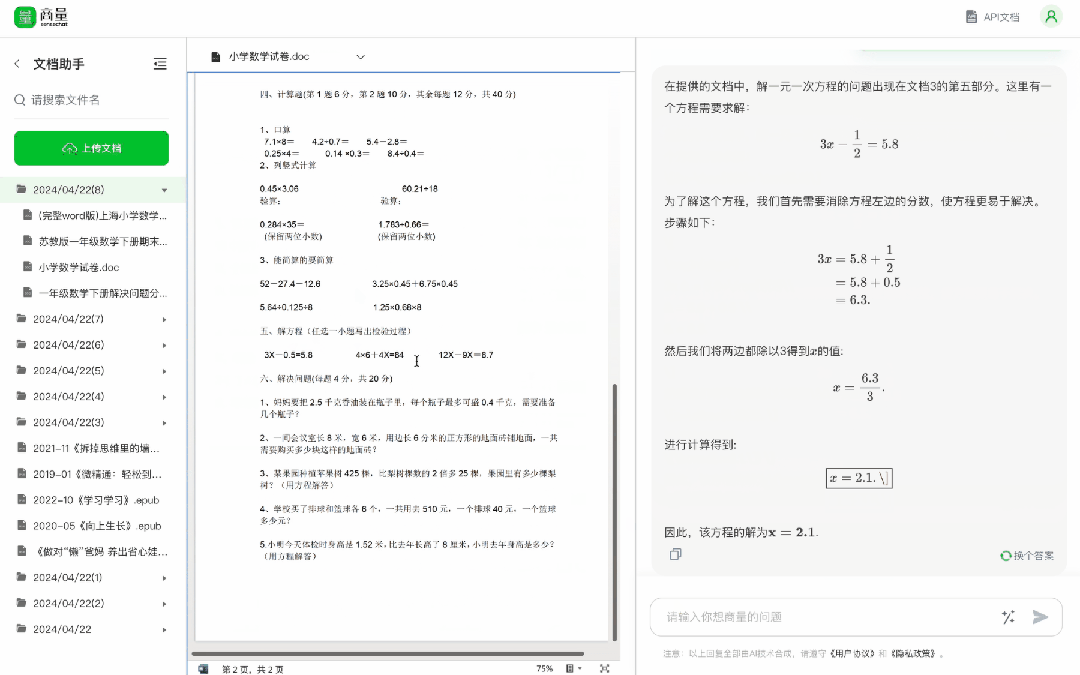
喜歡古詩詞?傳本《唐詩宋詞》進去,從中找幾個描寫月亮的詩或詞,輕鬆化身古文小能手 ——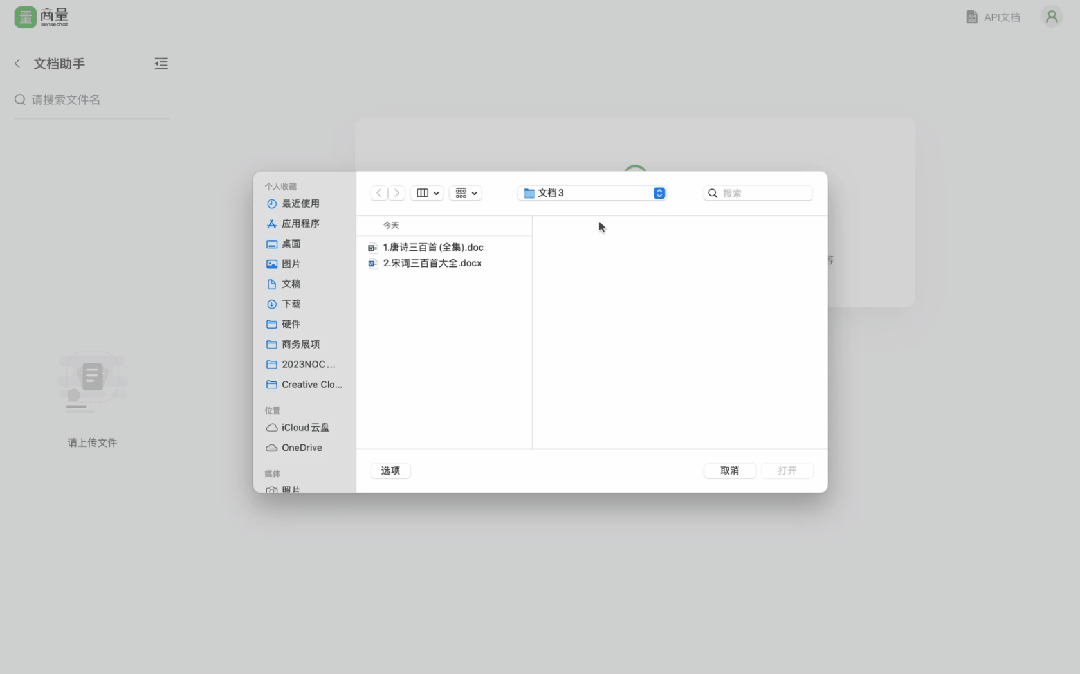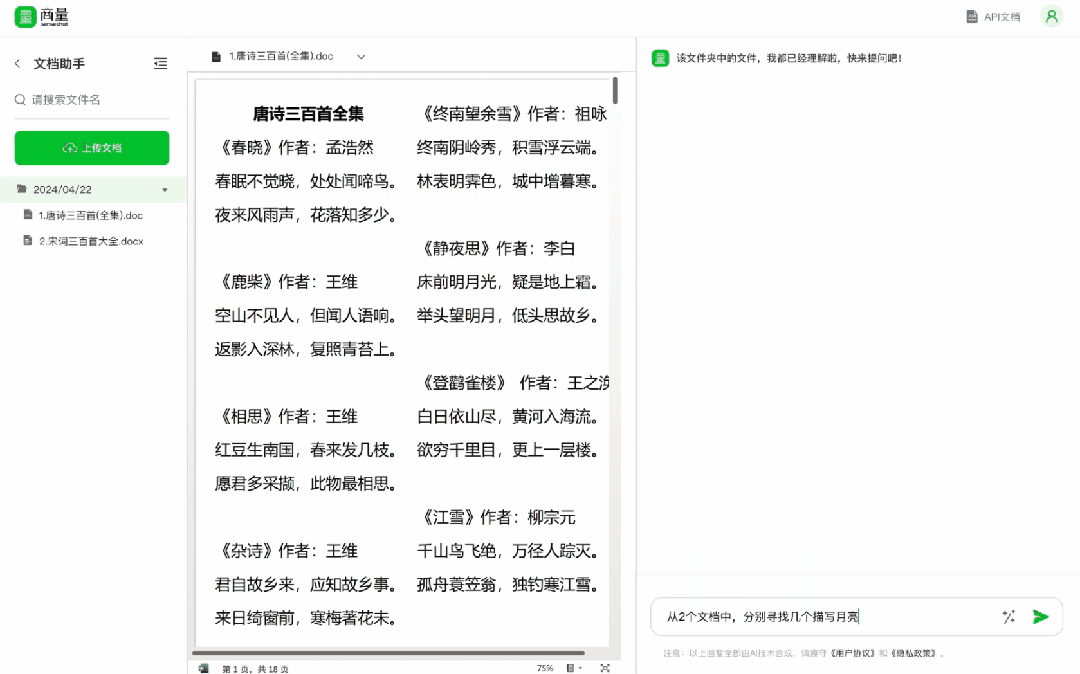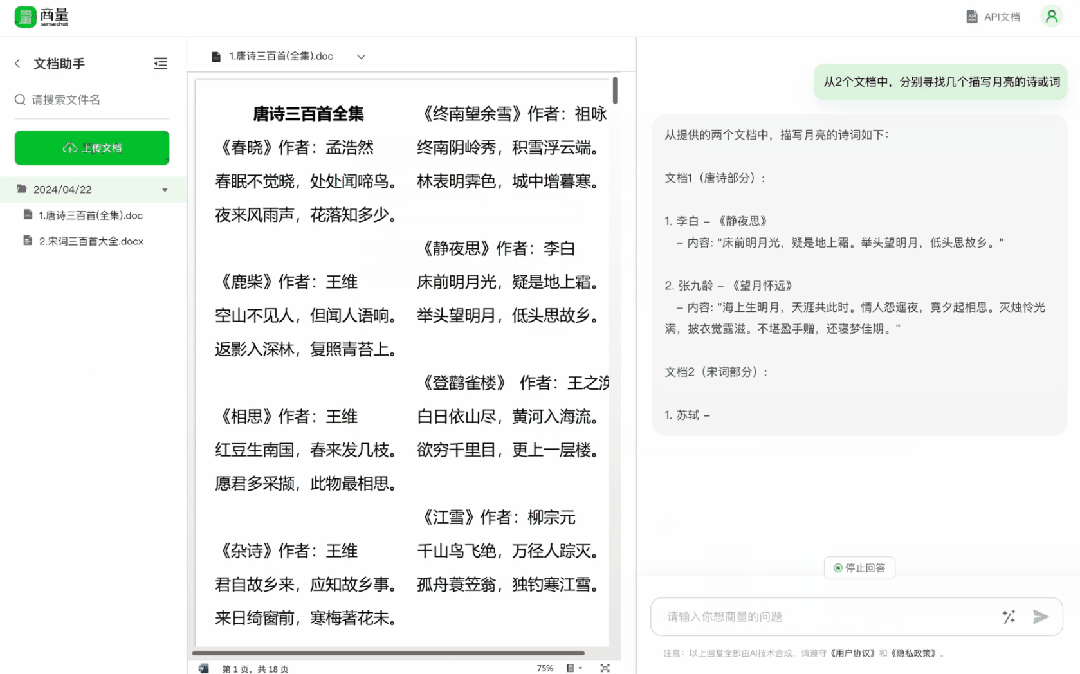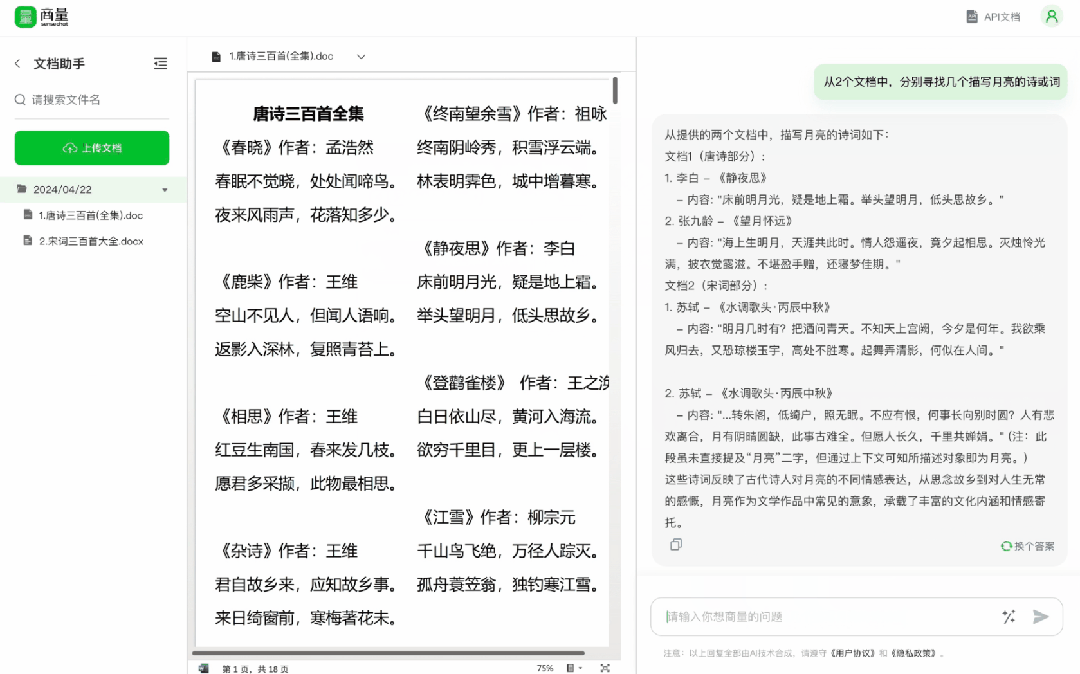
精準定位、搜尋,解釋分析一氣呵成,雖然因檔案大小限制,進行了 2 倍加速處理,但解析速度依然相當快。


商量看得如此精準主要是因為其底層的商湯多模態大模型圖文感知能力已達到全球領先水平 —— 在多模態大模型權威綜合基準測試 MMBench 中綜合得分排名首位,在多個知名多模態榜單 MathVista、AI2D、ChartQA、TextVQA、DocVQA、MMMU 成績也相當亮眼。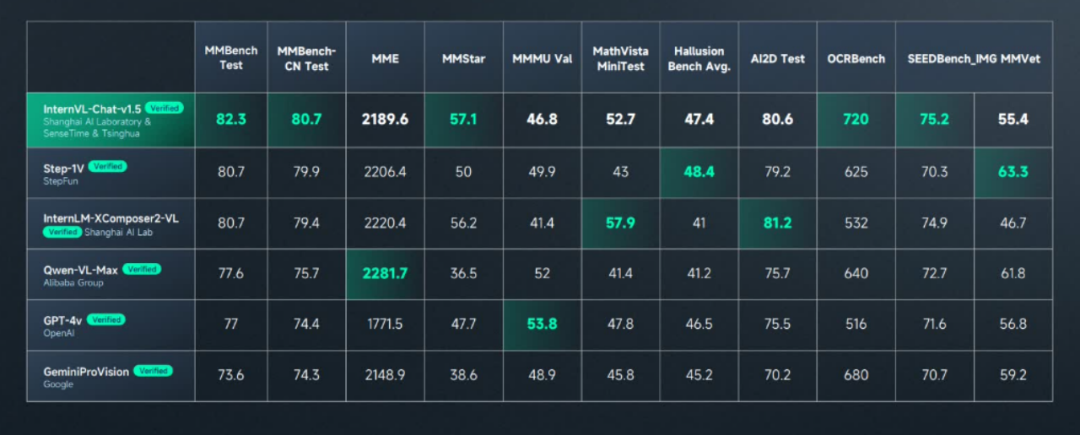
今天最新升級的 “日日新 SenseNova5.0” 也在主流客觀評測上取得多項 SOTA,在主流客觀評測上達到或超越 GPT-4 Turbo,數學推理、程式碼程式設計、語言理解等多個維度取得重大突破。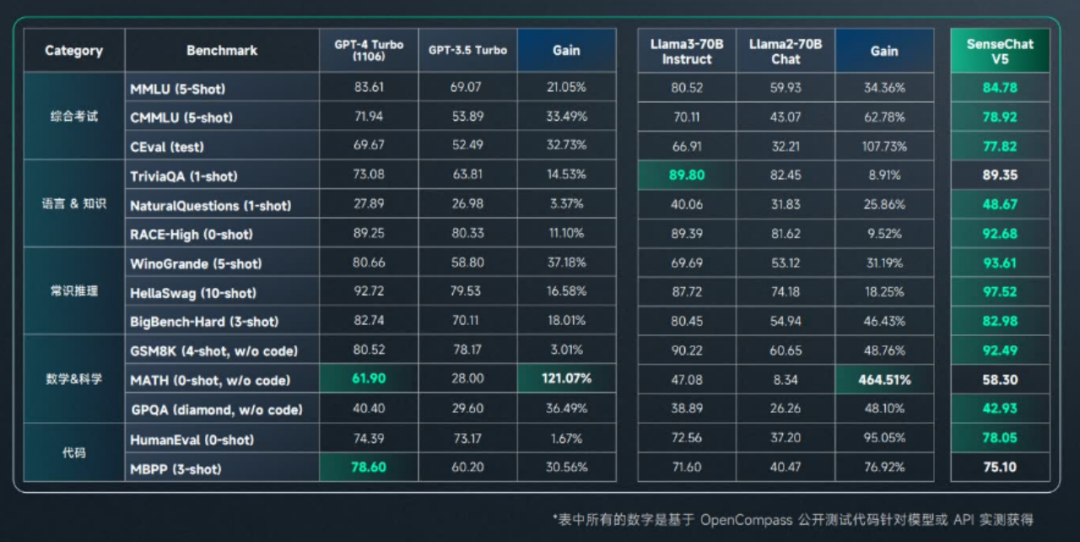
隨著模型規模的不斷擴大和複雜度的增加,人們自然會產生一個問題:大模型的效能到底有多強?在這個問題上,尺度定律(Scaling Law)被認為是一個關鍵性的原理,即伴隨模型規模的增大,模型的效能也會隨之提升,每次大模型訓練的結果都高度可預測。商湯也以此作為大模型研發的基本法則,不斷探究大模型效能的邊界。然而,資料和算力依然是大模型在尺度定律探索道路上的瓶頸,商湯也對此一直在突破。比如,在此次 “日日新 5.0” 的升級中,商湯擴充套件了超過 10TB tokens 的預訓練中英文資料,規模化構建高質量資料,解決大模型訓練的資料瓶頸。在算力方面,商湯前瞻佈局的算力基礎設施 SenseCore 商湯大裝置,更透過算力硬體系統及演算法設計的聯合設計最佳化,為大模型的創新提供超高算力效率。高質量資料和高效率算力的支援,為商湯踐行尺度定律,奠定了長期基礎。在此之上,商湯還探索出了大模型能力的 KRE 三層架構,具象化展現了大模型能力邊界的定義。其中,K 是指知識(Knowledge),即世界知識的全面灌注;R 是指推理(Reasoning),即理性思維的質變提升;E 是指執行(Execution),即世界內容的互動變革。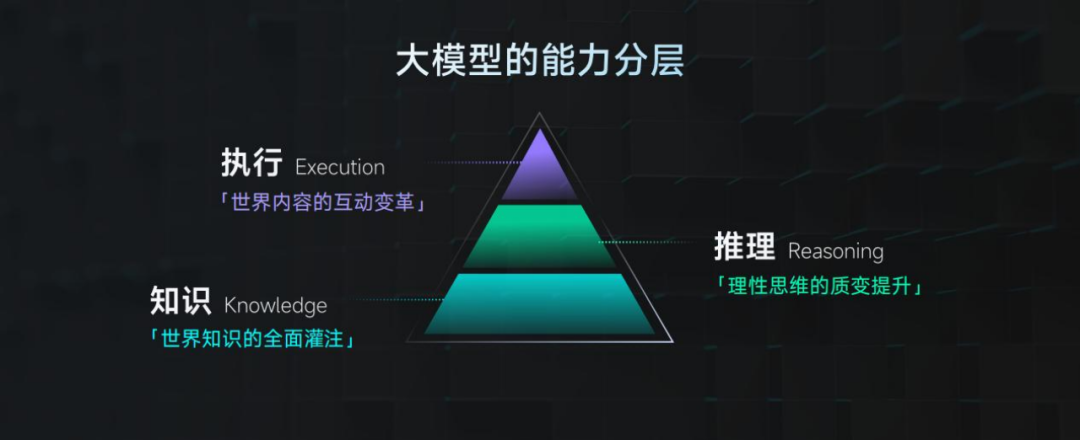
三層之間互有依賴,但又相對獨立。最終的目標,是建立大模型對世界的強大學習、理解和互動能力。大模型在學習這個世界,也在創造一個 AI Native 的世界,無論是大模型原生小遊戲,還是功能越來越全的大模型對話,都在展現世界內容的互動變革,隨著尺度規律的不斷髮展,下一步會怎樣?在這次技術交流日上,商湯最後放出了一段文生影片,一起來看看。