從0到1:億級訊息推送的穩定性保障攻略
一、訊息推送簡介
1、什麼是訊息推送
訊息推送每天都在我們的手機上發生,除非你的手機沒有安裝App或關閉了通知欄許可權。
2、訊息推送的價值
從使用者的生命週期來看,訊息推送對於提高App活躍度、提升使用者粘性和使用者留存率都起到了重要作用。
提升新使用者次日留存,低成本促活,對平臺的短期留存率影響顯著。
提升老使用者活躍度,push可以透過外部提醒起到拉活的作用。很多內容平臺類App的使用者push首次啟動佔比可達 10%以上,因此push對DAU的增量貢獻不容小覷。
流失使用者召回,當使用者流失後,若push許可權未關閉,透過訊息推送的方式,有可能重新喚醒使用者。
二、背景和痛點
訊息中心為得物App提供了強大,高效的使用者觸達渠道,其中push對於得物DAU的貢獻有可觀的佔比,這也就意味著每一條推送訊息都是一次與使用者溝通的寶貴機會,所以推送的穩定性成為我們關注的首要問題,那麼我們遇到的以下痛點就亟待解決。
訊息中心沒有明確訊息推送的耗時標準,業務和技術之間存在gap,業務方對於推送的訊息什麼時候到達沒有明確的心理預期。
從技術上來講訊息推送各個節點的耗時不明確,無法對各個節點的耗時做針對性的最佳化,這也就需要我們針對訊息推送的節點耗時進行監控。
訊息推送的穩定性依賴於第三方的推送通道,而三方通道對於我們來講就是個黑盒子,如何做到三方通道異常及時發現並止損也是需要考慮的問題。
在我們正常的迭代過程中,有時候不可避免的會出現些異常或者有壞味道的程式碼,這些問題能不能及時發現、及時止損,能不能及時告警出來。
三、監控的實踐
1、SLA監控簡介
SLA(Service-Level Agreement),也就是服務等級協議,指的是系統服務提供者(Provider)對客戶(Customer)的一個服務承諾。
這是衡量一個大型分散式系統是否“健康”的常見方法。在開發設計系統服務的時候,無論面對的客戶是公司外部的個人、商業使用者,還是公司內的不同業務部門,我們都應該對自己所設計的系統服務有一個定義好的SLA。
因為SLA是一種服務承諾,所以指標可以多種多樣。最常見的四個SLA指標,可用性、準確性、系統容量和延遲。
對於訊息推送而言,我們主要關注的是訊息能否及時可靠的送達給使用者,也就是SLA中關注的時效性和穩定性的問題。
目前訊息中心針對實效性和穩定性的開發已經完成並初顯成效,下面主要針對時效性和穩定性的監控做一些介紹。

2、系統架構圖
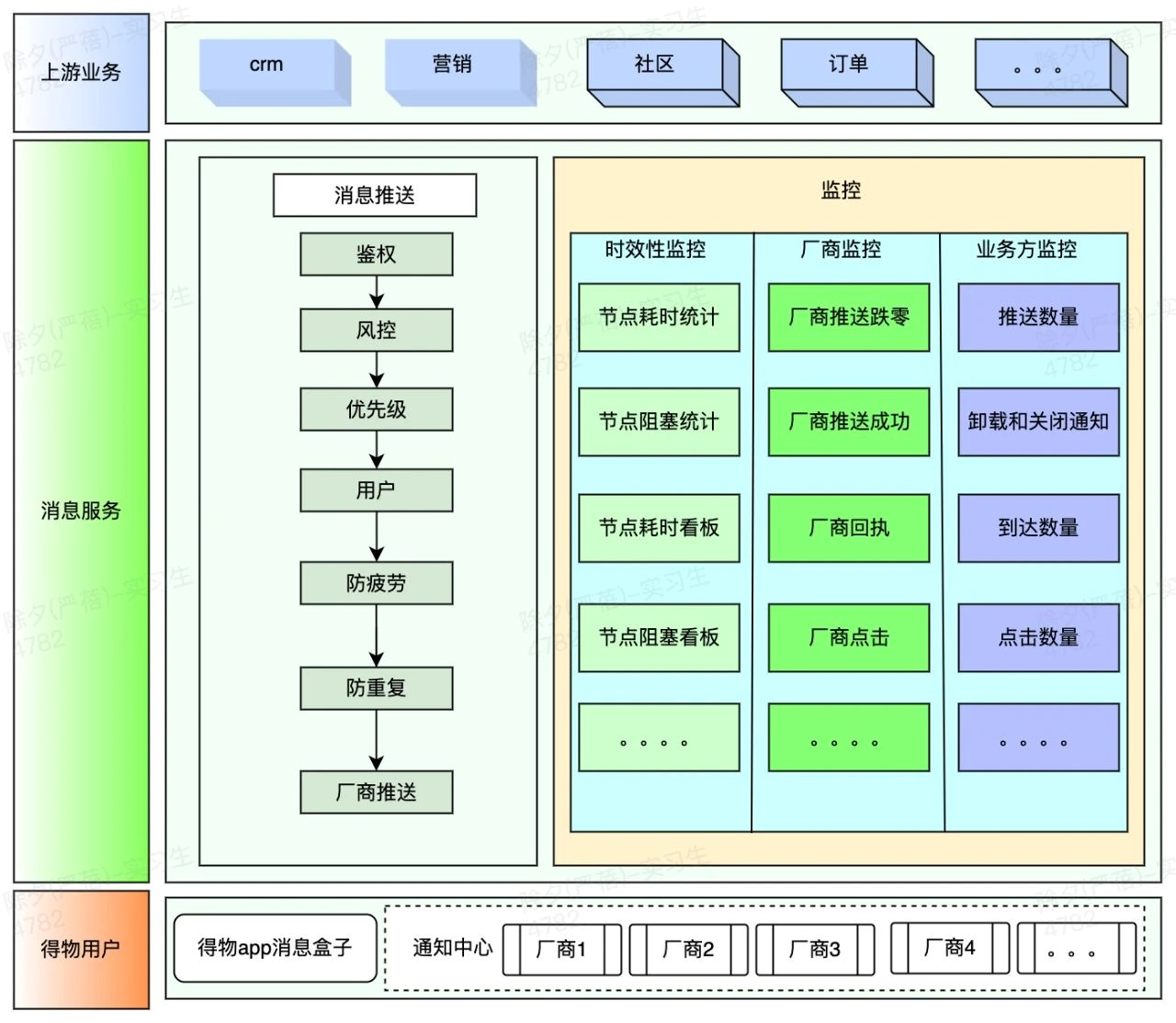
3、時效性監控
1)節點的拆分
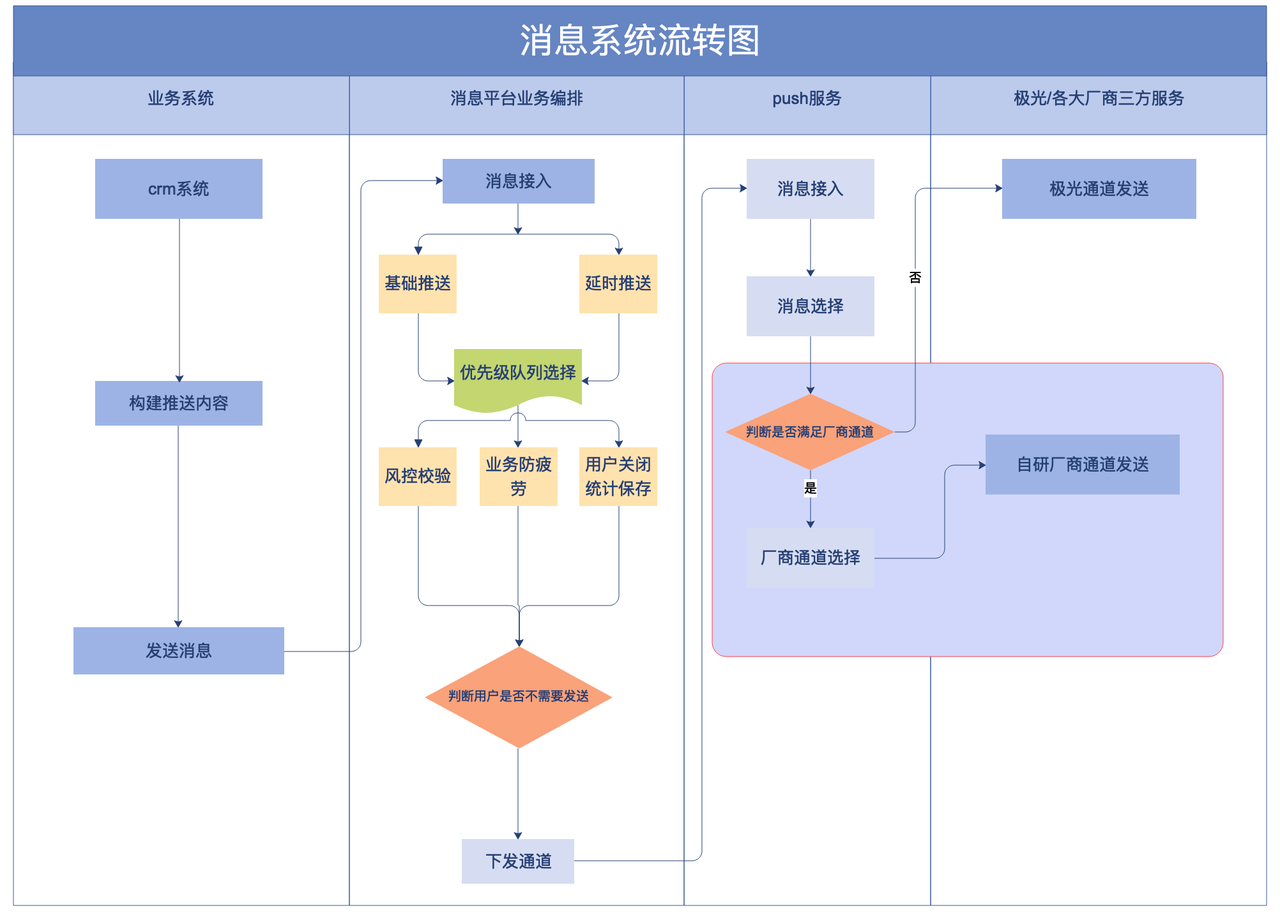
如何做到時效性的無死角監控,那麼我們就要對訊息推送的整個流程進行拆分,把整個流程拆分成若干個獨立且無依賴的可監控節點。
從訊息系統流轉圖中可以看到,整個推送流程是清晰明瞭的,訊息的的推送主要會經歷推送鑑權、使用者查詢、防疲勞過濾、防重複過濾等的邏輯處理。
考慮到每個業務邏輯的處理是相互獨立且無依賴的,那我們就可以根據具體的業務處理邏輯進行節點的拆分,這樣就可以做到拆分無遺漏,監控無死角,拆分後的具體節點如下:
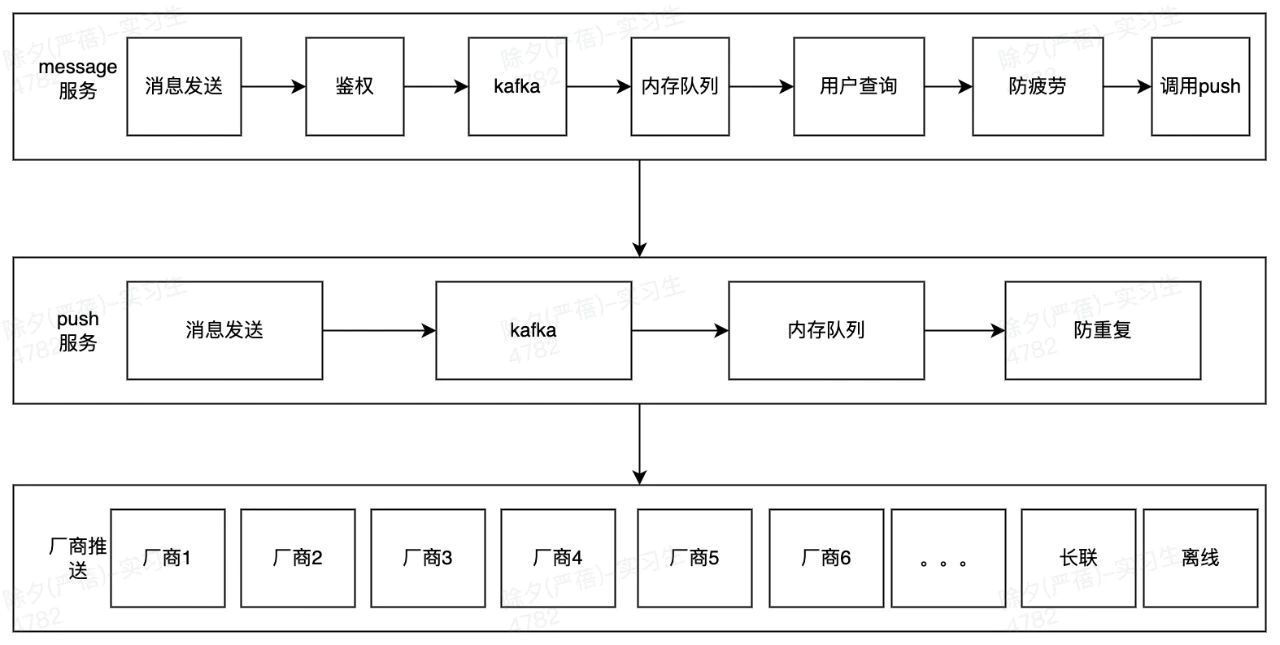
2)節點耗時的計算
具體的節點拆分邏輯和耗時邏輯的計算如下圖:
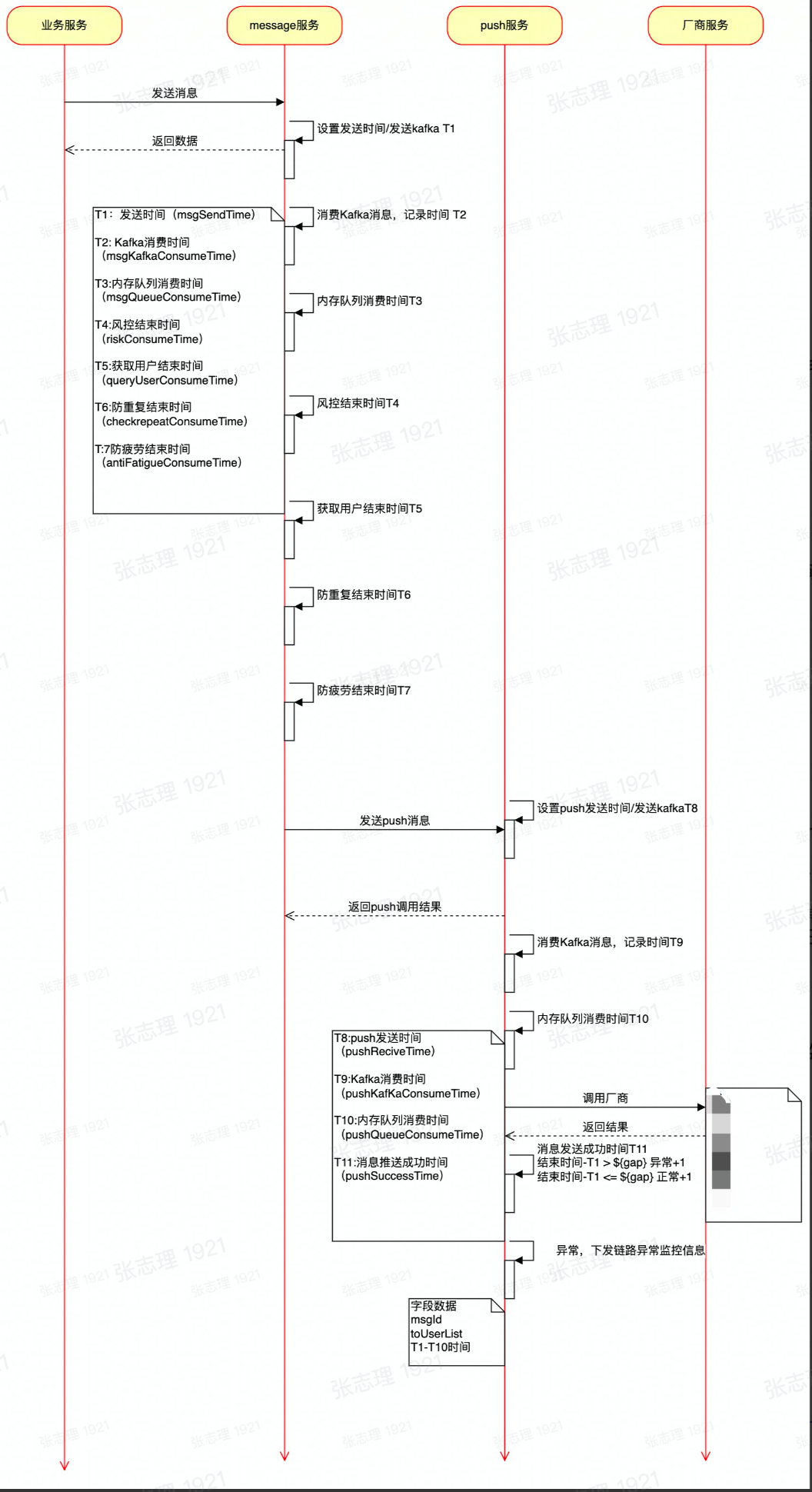
節點耗時的計算:記錄節點訊息推送到達的時間,並計算節點推送耗時,例如防疲勞耗時=T7(antiFatigueConsumeTime)-T6(checkrepeatConsumeTime)
節點阻塞量的計算:記錄節點訊息推送的瞬時阻塞量, 例如防疲勞節點阻塞量 = 防疲勞的總量-防疲勞已經處理的量。
3)節點指標的制定
既然需要監控的節點已經拆分明確了,那針對這些節點我們監控哪些指標才是有意義的呢?
目前訊息推送高峰耗時較長,各業務域對於訊息的到達時間也沒有明確的心理一個預期,另外訊息中心也無法感知推送在整個鏈路各個節點的耗時情況,無法針對節點耗時做到有針對性的最佳化,所以節點的推送量和推送耗時就是我們需要重點關注的指標。
節點的阻塞量可以讓我們及時感知到推送中存在的積壓問題,在大促期間,訊息的推送量也會達到一個高峰,訊息目前是否有堆積,處理的速度是否跟的上,是否需要臨時擴容,那麼節點的阻塞量就成了一個比較有意義的參考指標。
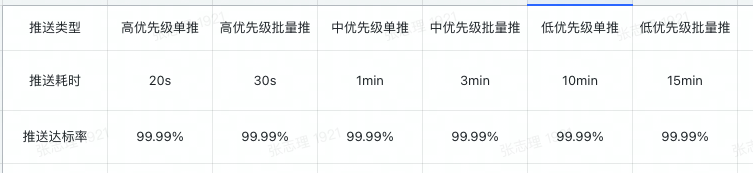
考慮到訊息推送是有優先順序的並且區分單推和批次推,所以我們要針對不同的優先順序和推送方式設定不同的標準,訊息推送耗時的具體標準如下:
4)技術方案的實現
為了能感知到訊息推送中發生的異常和耗時情況,這就需要我們標準化監控指標和監控的節點。
其中耗時指標可以感知節點的耗時和程式碼的壞味道,阻塞量可以監控到節點的堆積情況,推送成功率可以感知節點的推送異常等。
另外節點拆分後我們可以很快定位到異常發生的具體位置,經過拆分監控的主要節點包括鑑權、風控、使用者查詢、防疲勞、防重複、廠商呼叫等。
另外訊息中心每天推送大量訊息給得物使用者,SLA監控任何一個操作嵌入主流程中都可能導致訊息推送的延遲。
這也就要求監控和主流程進行隔離,主流程的歸主流程,SLA 的歸 SLA,SLA 監控程式碼從主流程邏輯中剝離出來,徹底避免SLA程式碼對主流程程式碼的汙染,這也就要求SLA邏輯計算需要獨立於推送業務的主流程進行非同步計算,防止SLA監控拖垮整個主流程,那麼Spring AOP+Spring Event就是最好的實現方式。
5)結果
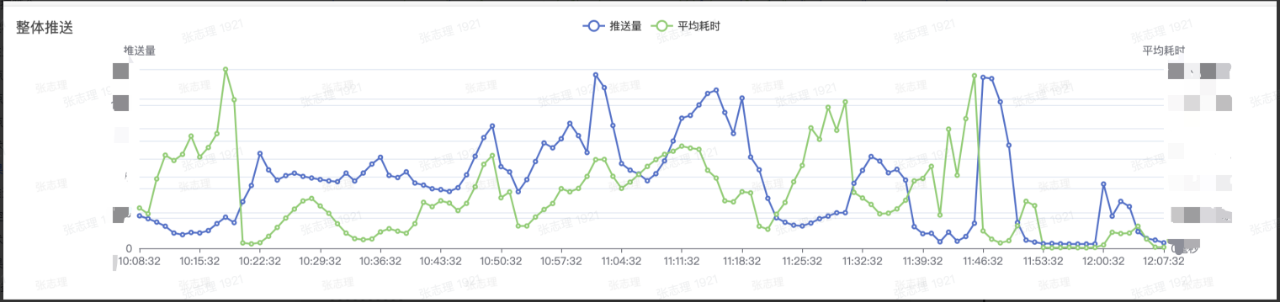
訊息推送實效性監控做完之後,對服務節點耗時異常可以及時感知,同時也完成了關鍵節點耗時的指標化,可以明確的看到所有節點在各個時間的耗時情況,同時也對訊息推送針對各個節點的的最佳化起到了指導作用。
時效性節點監控:
時效性節點告警:

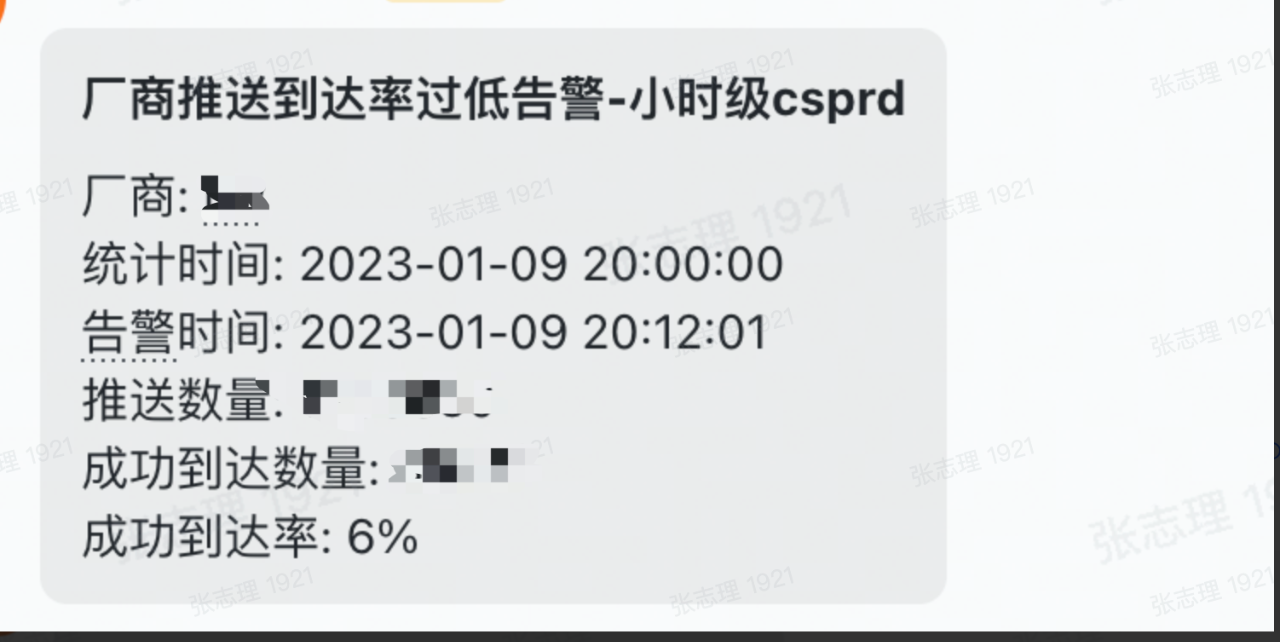
4、廠商推送監控
1)監控指標制定
訊息推送接入的有多個推送通道,如何做到對這些通道做到無死角的監控和及時感知?
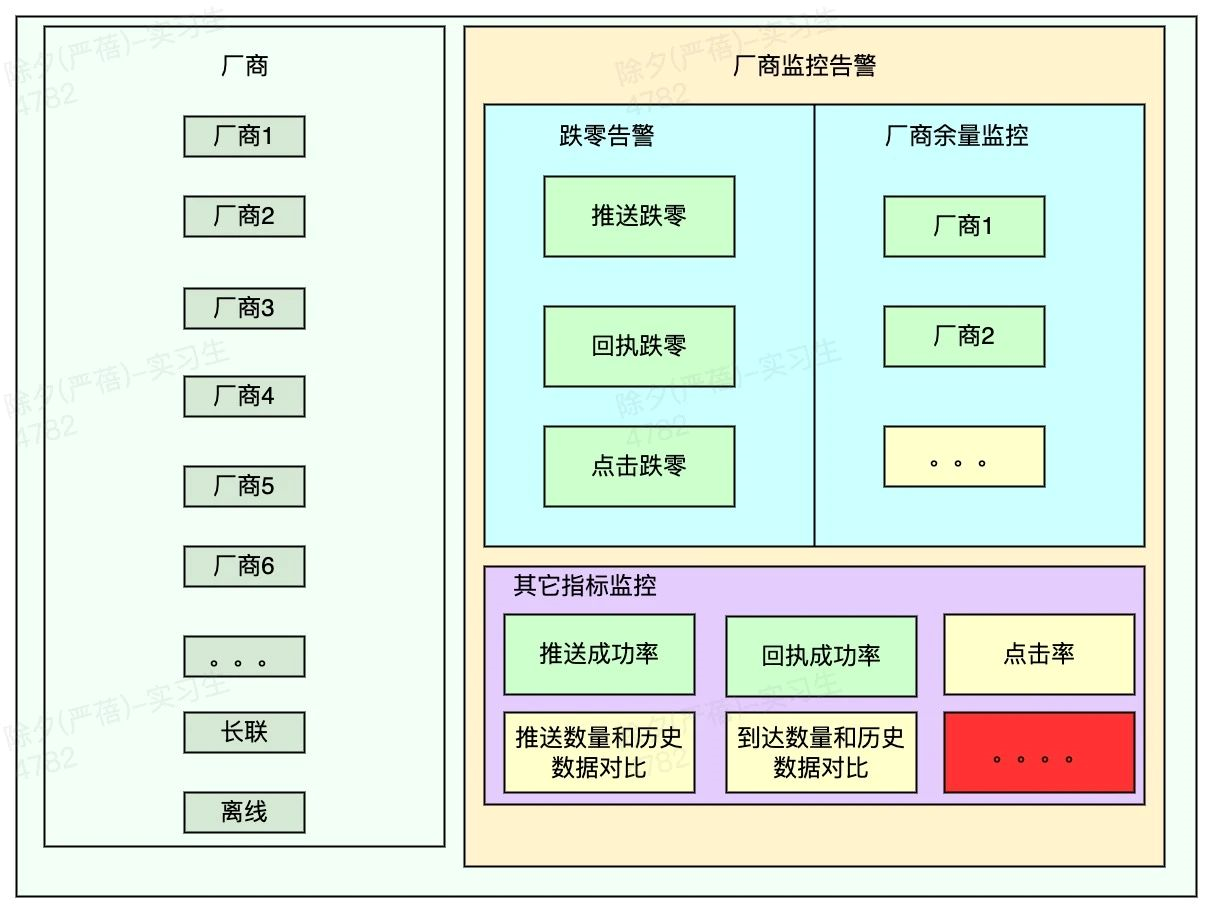
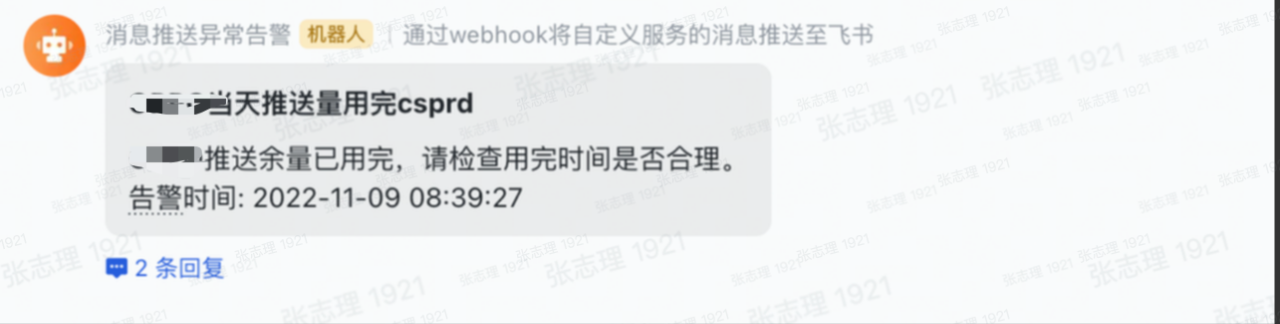
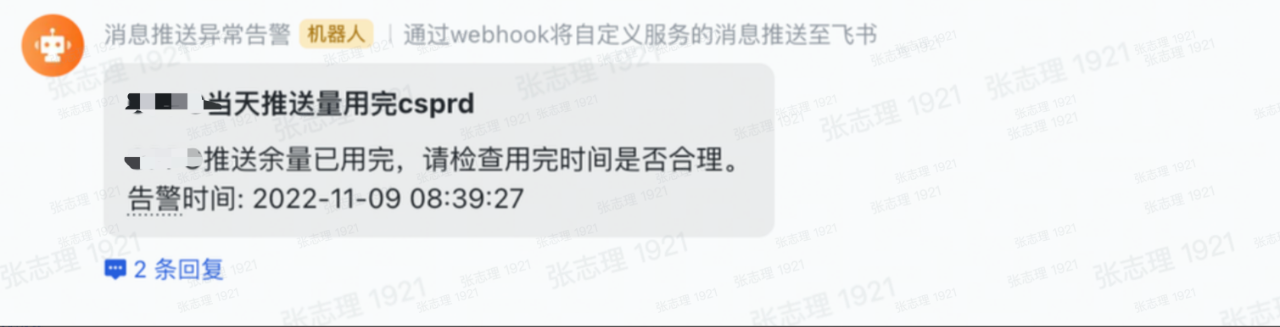
在做廠商監控之前,我們就已經遇到了廠商通道推送跌零的情況,這種情況下整個推送通道都掛掉了,我們要及時通知廠商進行修復,所以廠商推送跌零告警和廠商餘量監控是必須的。
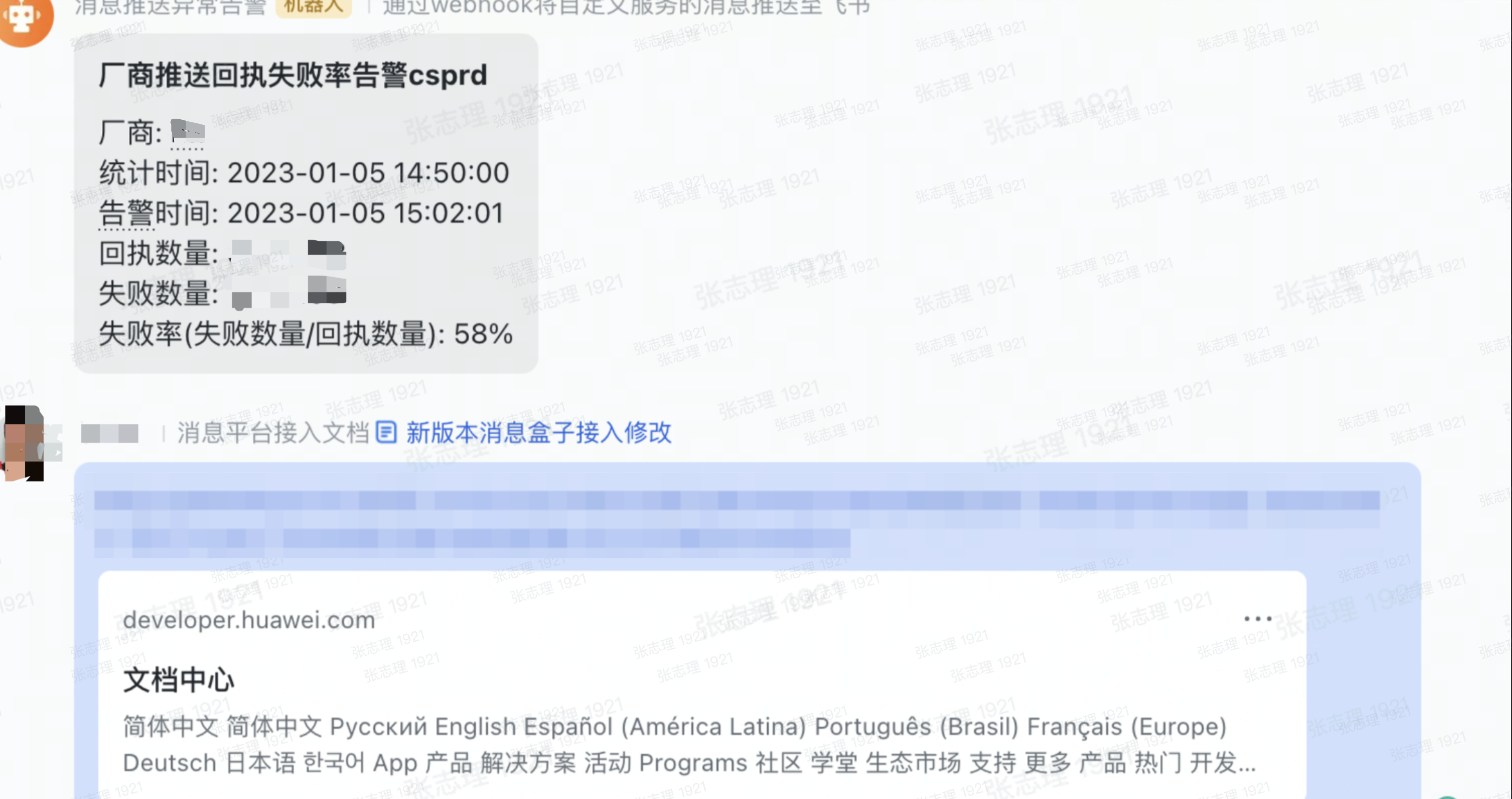
從現有資料來看,廠商的推送成功率、回執成功率、點選率都穩定在一定的的區間。如果廠商推送的指標資料偏離這個區間則說明推送有異常,所以推送成功率、回執成功率、點選率的監控是必須的。
另外從業務請求傳送的使用者數來看,每天的訊息推送基本是穩定的,相對應的廠商的回執數量和點選數量也是穩定的,那麼對廠商推送成功的數量,回執的數量和點選的數量監控也有一定的參考意義。
業務側請求傳送的使用者數:

廠商監控告警:
2)技術方案實現
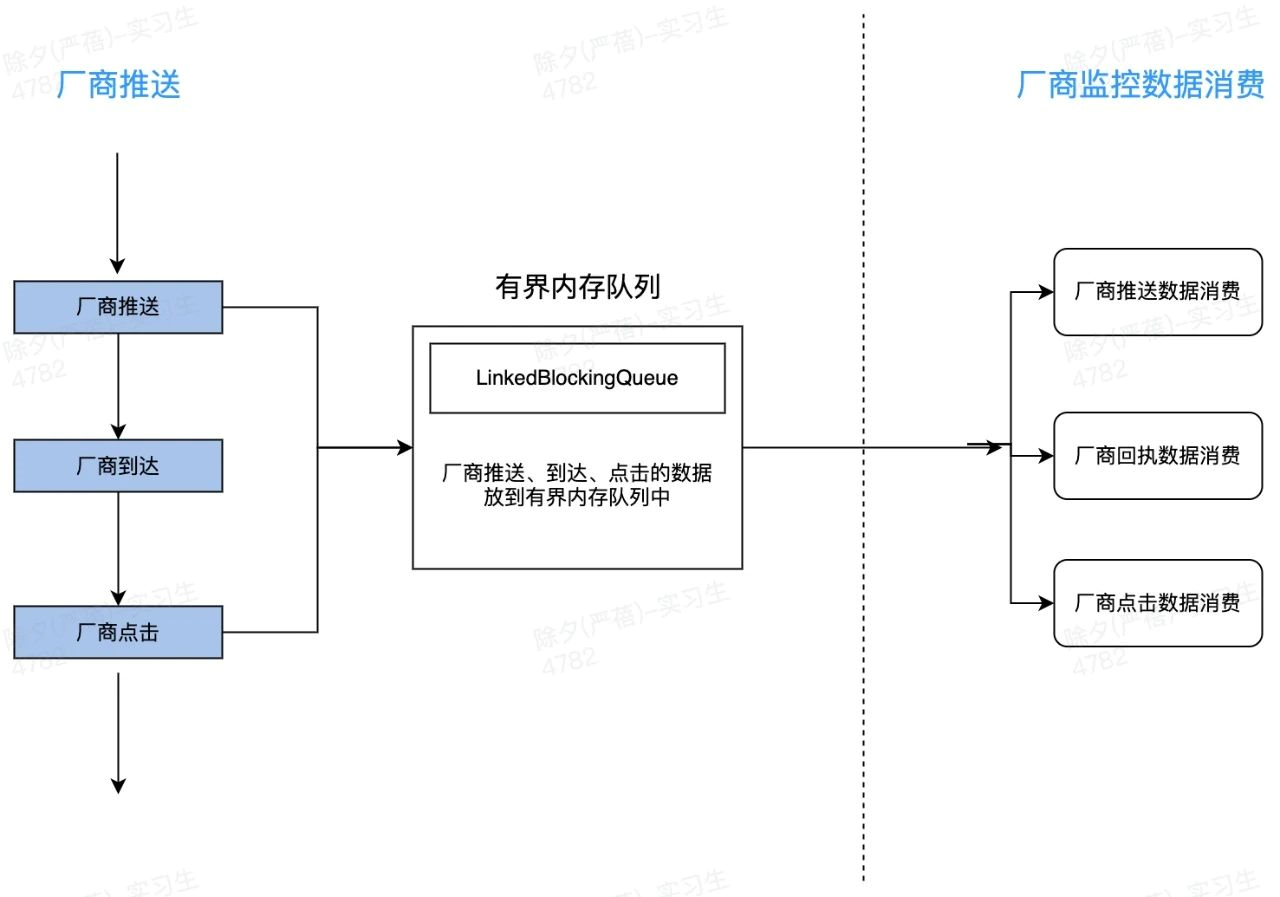
廠商每天有數億的訊息推送,這也就意味著廠商的監控不能嵌在主流程中處理。廠商的監控程式碼要從主流程邏輯中剝離出來,避免監控拖垮主流程,同樣避免監控異常影響到推送的主流程。針對廠商推送的監控,目前使用的是有界記憶體佇列實現。
3)結果
訊息推送廠商監控上線之後,可以及時感知到廠商推送的異常資訊,對於廠商推送的異常和廠商規則的更改等可以做到及時的感知。
四、帶來的收益
1、異常的及時發現
監控上線後及時發現了發現了廠商推送執行緒關閉失敗,廠商推送跌零、廠商營銷訊息規則更改、廠商通道偶發不可用等問題,並做到了及時的止損。
在時效性監控上線之後,發現了因廠商推送執行緒建立關閉失敗導致執行緒數逐漸上升問題,避免了線上故障的發生。

廠商異常導致推送跌零,監控發現後及時通知到廠商並止損。
發現廠商營銷訊息規則更改的異常,並及時經梳理各大廠商文件後發現除了多個廠商通道在未來一個月內也會有規則的更改,訊息平臺及時適應了廠商規則,接入廠商系統通道,做到了及時止損。
2、服務效能的提升
時效性監控上線後發現了多個服務可以最佳化的點,其中多個廠商和推送節點在高峰推送時耗時較高,很明顯節點耗時和廠商推送 SDK 連線池和連線時間引數需要最佳化。最佳化後訊息推送整體的吞吐量實現了翻倍的提升。
五、展望未來
由於時間問題,目前訊息監控只做了時效性和廠商推送穩定性相關的監控,但是監控上線後帶來的收益還是比較可觀的,可以預見的是監控的構建在未來必將帶給我們更大的收益,後續我們可以從以下點豐富現有監控。
考慮到業務預的推送量和推送時間是穩定的,那麼我們可以針對業務維度新增推送資料的監控,及時感知上游推送資料的變化。
其次我們可以針對各個節點的推送異常、漏斗轉化率、服務效能等做監控,進一步豐富訊息平臺的監控體系。
對於訊息推送來講也要考慮推送的轉化率問題,那麼解除安裝、遮蔽等指標也是我們需要監控的點,透過這些業務指標及時感知推送的效果,做到精細化的管控。
六、總結
訊息平臺監控上線後帶來的收益還是比較可觀的,包括多次異常的及時發現和止損,還有發現多個可以最佳化的效能點,實現了服務高峰吞吐量的翻倍,同時也解決了我們現在遇到的以下痛點。
時效性明確的給到了不同優先順序的耗時標準,避免了業務和技術之間的gap,業務方對於推送的耗時也有了明確的心理預期。
時效性使得節點耗時的效能問題可以一目瞭然,透過對現有節點耗時問題的最佳化,訊息服務的吞吐量實現了翻倍的提升。
廠商穩定性監控使得廠商異常可以及時感知,其中廠商穩定性監控上線後發現多起廠商推送的異常,並做到了及時的解決和止損。
SLA時效性和廠商穩定性上線後,訊息中心可以及時感覺到推送鏈路的異常和程式碼的壞味道,特別是對於新上線的程式碼,如果存在異常可以及時感知。
來自 “ 得物技術 ”, 原文作者:暖樹;原文連結:https://server.it168.com/a2024/0202/6839/000006839075.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 從0到1,億級訊息推送的穩定性保障|得物技術
- 從0到1,億級訊息推送的穩定性保障 | 得物技術
- 概念解讀穩定性保障
- 研發效能與穩定性保障
- 穩定性保障,如何慢慢放量灰度
- “從0到1”的開發者全套攻略與揭秘非洲的十億級遊戲市場遊戲
- 從前端程式設計師的視角看小程式的穩定性保障前端程式設計師
- Kubernetes 穩定性保障手冊:洞察+預案
- Kubernetes 穩定性保障手冊 -- 極簡版
- 如何利用 “叢集流控” 保障微服務的穩定性?微服務
- 四個步驟,教你落地穩定性保障工作
- Kubernetes 穩定性保障手冊 -- 日誌專題
- PHash從0到1
- 如何去設計前端框架能力?星巴克訊息開放專案從0到1,從點到面的思考前端框架
- 阿里雲訊息佇列 RocketMQ、Kafka 榮獲金融級產品穩定性測評 “先進級” 認證阿里佇列MQKafka
- 教你從0到1搭建小程式音視訊
- [譯] Flutter 從 0 到 1Flutter
- 【穩定性】從專案風險管理角度探討系統穩定性
- 設計一個百萬級的訊息推送系統
- SAP QM 穩定性研究功能研習系列1 - 穩定性研究總流程
- OpenSergo & CloudWeGo 共同保障微服務執行時流量穩定性GoCloud微服務
- Kubernetes 穩定性保障手冊 -- 可觀測性專題
- 訊息推送平臺的實時數倉?!flink消費kafka訊息入到hiveKafkaHive
- 銀行卡資訊驗證API介面:高準確性與穩定性的雙重保障API
- 從0到1實現PromisePromise
- 從 0 到 1 認識 TypescriptTypeScript
- 工業「嫁衣」,從0到1
- Python從0到1的學習之道Python
- 從0到1,小白的前端摸索之路前端
- 0到1,Celery從入門到出家
- 這是阿里技術專家對 SRE 和穩定性保障的理解阿里
- Filecoin激勵機制:通過Slashing保障網路穩定性
- 有數BI大規模報告穩定性保障實踐
- Kafka 的穩定性Kafka
- 穩定性
- 訊息推送背後的思考
- 做產品,選擇從0到1還是從1到N?
- 如何理解敏捷開發的從0到1敏捷