構建資料紐帶:全鏈路血緣
全鏈路血緣是大資料時代企業資料管理的重要組成部分,在企業資料治理、鏈路追蹤、問題排查、價值評估等方面具有重要意義。本文將從全鏈路血緣的概念、使用場景、產品實踐等方面進行詳細介紹。
01 什麼是全鏈路血緣
全鏈路血緣是指資料在其生命週期內變化的完整流程,包括資料的起源、傳輸、儲存、加工和使用等生命週期的各個環節。我們今天要介紹的全鏈路血緣覆蓋了業務端到端的完整血緣鏈路,即包括最上游的來源業務系統、業務庫表傳輸到數倉表、數倉表間加工關係、表和指標的關係、表和標籤的關係、表和API的關係、表和BI報表的關係等,旨在釐清資料最源端來自哪裡,資料最下游被用去了哪裡。
02 全鏈路血緣使用場景
為什麼我們反覆強調資料血緣?為什麼要費力去構建資料血緣關係?因為資料血緣在資料管理過程中發揮了重要作用,總結為以下幾點:
1. 問題追溯和下游影響評估
當資料出現異常時,資料開發及運維人員可以根據資料血緣來分析和追溯異常資料的源頭,並評估對下游資料的影響範圍,及時對下游進行資料修復,提高資料穩定性。
2. 輔助資料治理,數倉鏈路最佳化
透過資料血緣檢視資料鏈路上是否存在不合理的資料依賴,例如跨層依賴或者迴圈依賴,從而進一步分析是否存在重複計算或資源浪費的情況。此外,資料血緣也可用於孤島資料清理。當一個資料沒有上下游時,可將其初步識別為孤島資料,並進行分析和清理,從而避免不必要的儲存和計算開銷。
3. 資料價值衡量
透過對資料節點的下游進行彙總,排序及分析,可作為資料價值評估依據。下游輸出較多的資料節點,其業務使用場景較多、價值密度較高,可新增資料質量監控和基線保障措施等;對於沒有下游使用的冰冷資料,可以進行歸檔冷備、或下線等。
4. 基於血緣的變更通知
隨著業務的複雜度和資料量級的增加,資料間的關係錯綜複雜,牽一髮而動全身。當出現業務變更或資料異常時,需要將變更情況及時通知下游,此時一一尋找下游負責人並逐個通知則非常困難,極容易出現漏通知、重複通知的情況,而基於資料血緣自動通知下游相關業務方則省時省力、精準高效。
03 全鏈路血緣構建實踐
3.1 整體方案介紹
我們將資料流轉過程大致分為4個部分:
源業務系統:資料的來源業務系統,例如OA系統、人力資源系統、櫃檯系統、訂單系統等;
業務庫表:各業務系統資料對應的實際儲存的業務庫表資訊;
大資料平臺:透過實時傳輸、離線傳輸,將業務資料傳輸到大資料平臺上,後續可對資料進行離線/實時加工、指標關聯、標籤關聯等;
資料應用:加工完成的資料,可用於生成資料服務API、BI報表等,用於業務分析決策。
如下圖所示:

根據上面的資料流轉示意圖,並結合某電商訂單的業務場景為例,一個精簡化的全鏈路血緣示意圖如下所示:
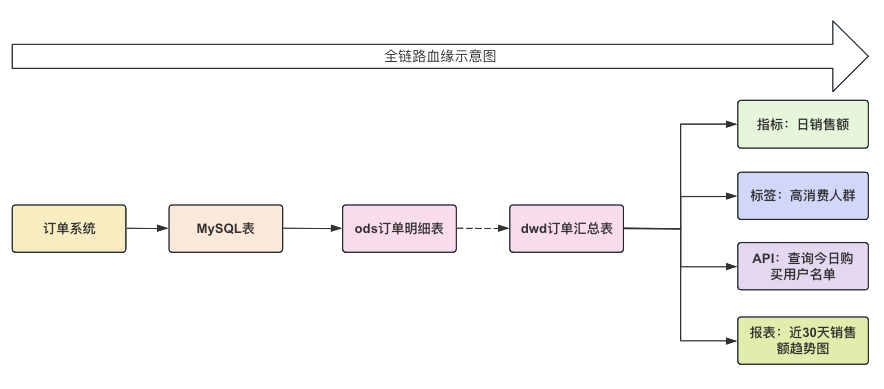
3.2 產品操作演示
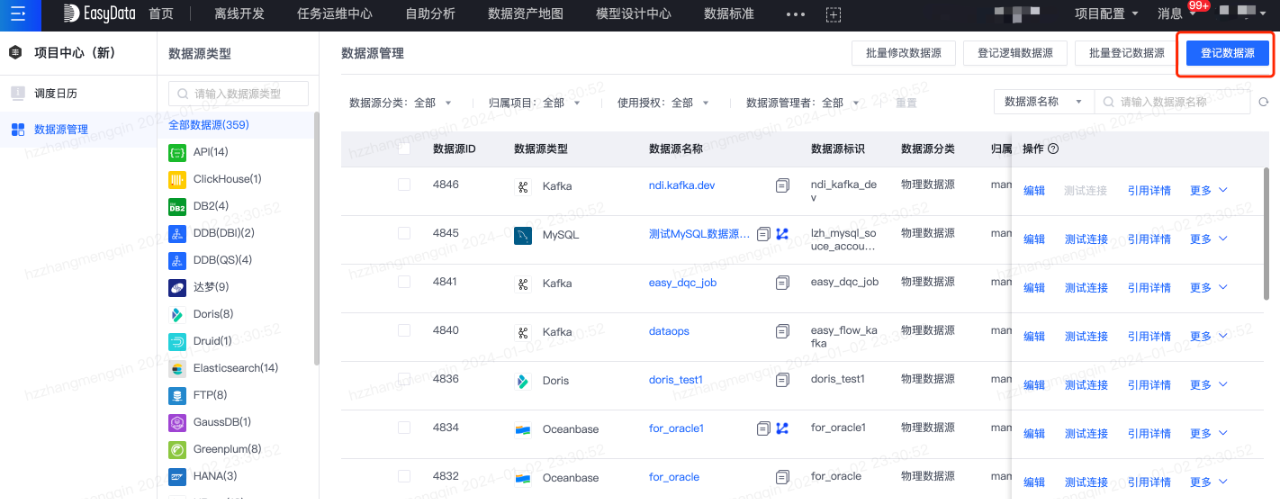
第一步:登記外部資料來源
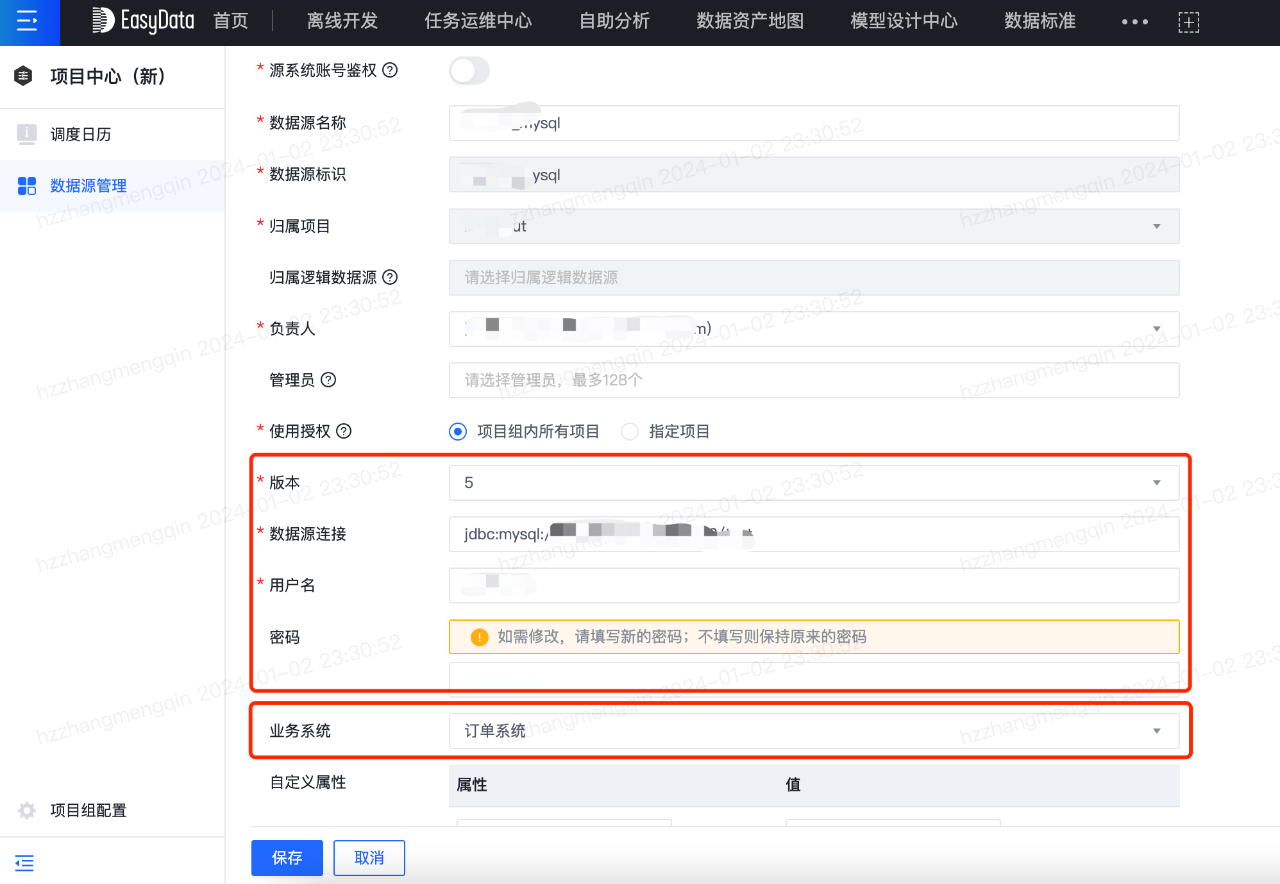
外部業務系統的資料首先需要登記在平臺上,才能進行資料傳輸和後續的加工。資料來源登記如下圖所示:
第二步:建立資料傳輸/資料加工任務
資料來源登記完成後,接下來先建立資料傳輸任務,將MySQL中原始資料同步到數倉ods層表中。資料傳輸任務建立流程如下:
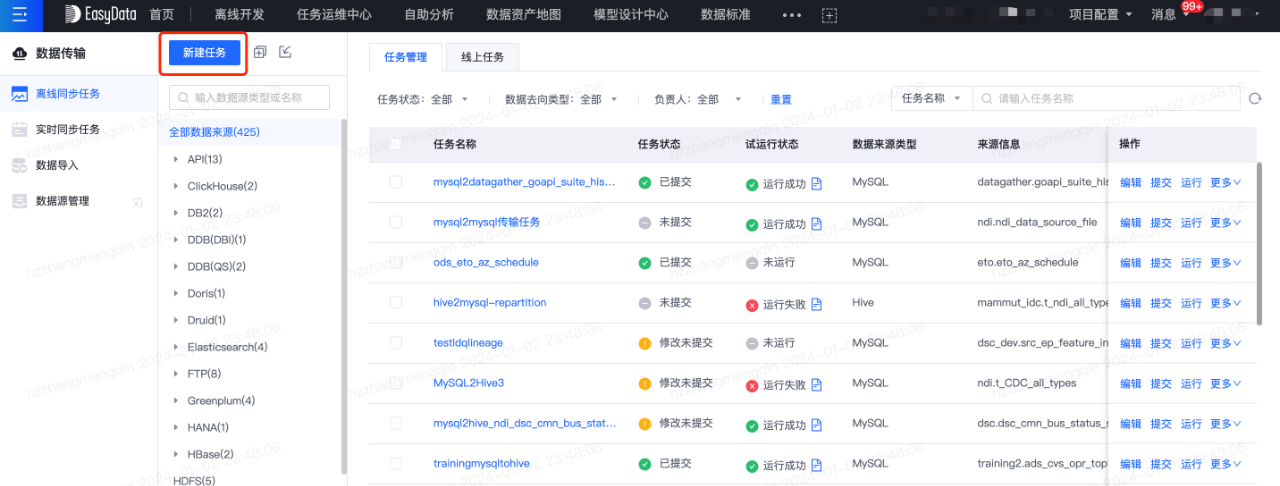
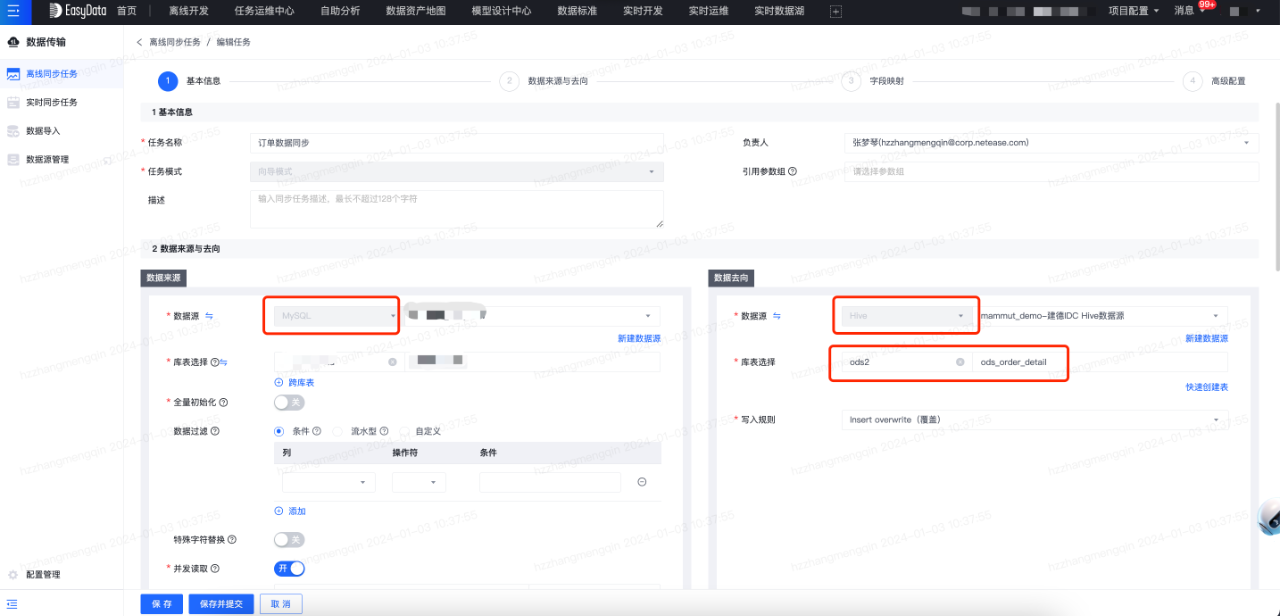
接下來建立離線開發任務,將傳輸任務同步過來的ods層表進一步加工成彙總表,離線加工任務流如下所示:
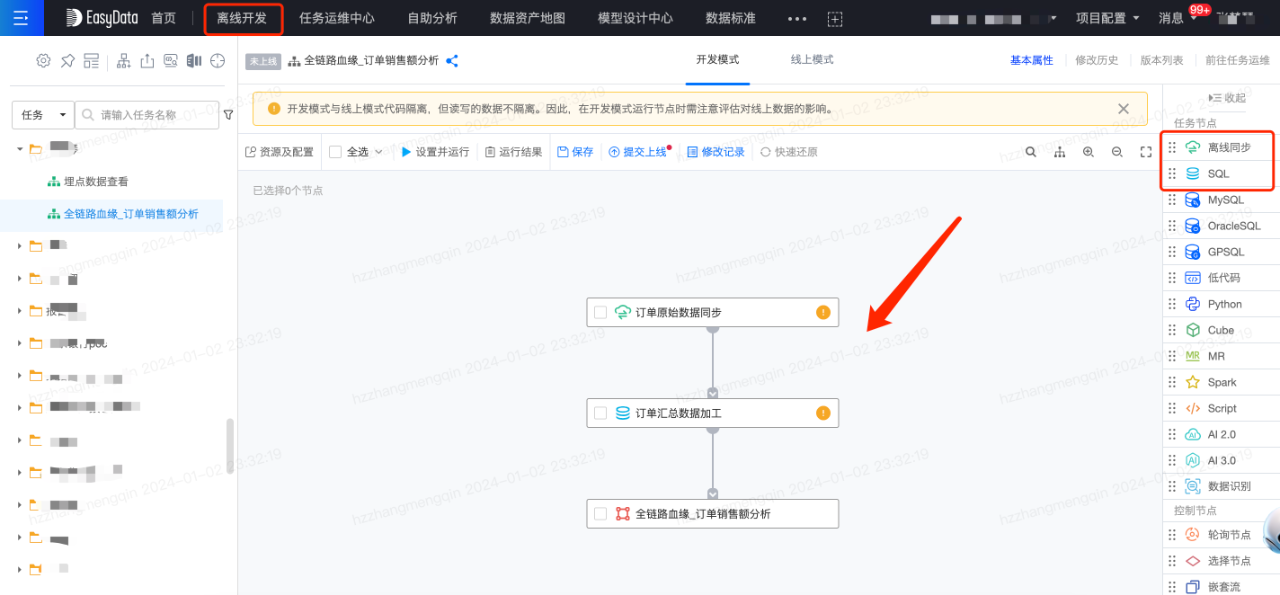
任務建立完成後,編輯SQL程式碼,最後除錯執行完成後即可釋出上線,這裡不做詳細介紹了。至此已實現【源業務系統->MySQL表->數倉ods表->數倉dwd表】的血緣鏈路構建,如下圖所示:

第三步:關聯指標、關聯標籤
為了呈現全鏈路血緣中指標、標籤、API、報表等血緣,我們繼續進行後續操作。指標和標籤的血緣關係建立渠道較多,這裡我們從後設資料視角出發,給表欄位關聯指標和標籤即可。
在後設資料管理模組中,給表欄位關聯指標如下圖所示:
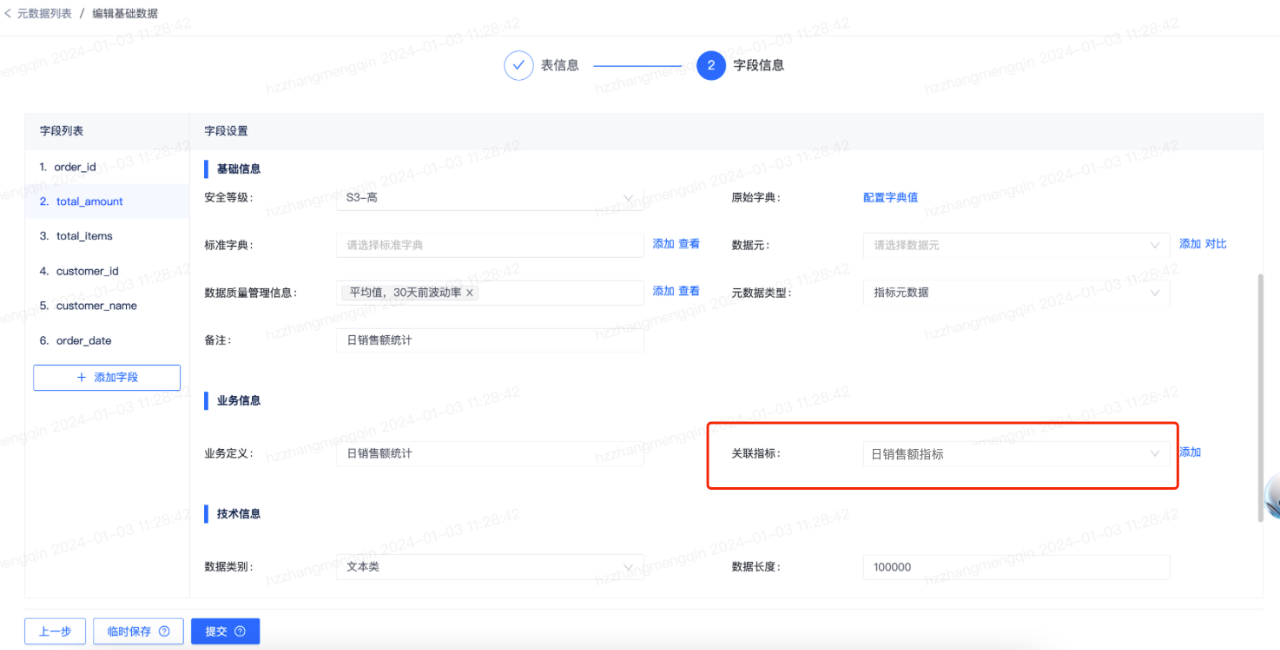
在後設資料管理模組中,給表欄位關聯標籤如下圖所示:

第四步:建立資料服務API
將表生成資料服務API後,系統將自動建立表和API間的血緣關係。在資料服務模組中,建立API流程如下:
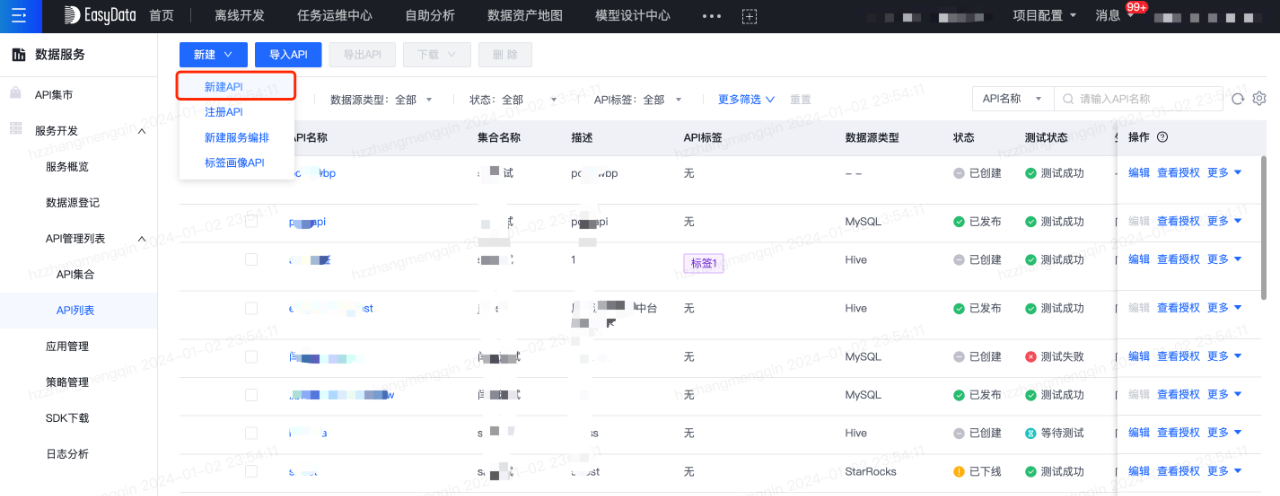
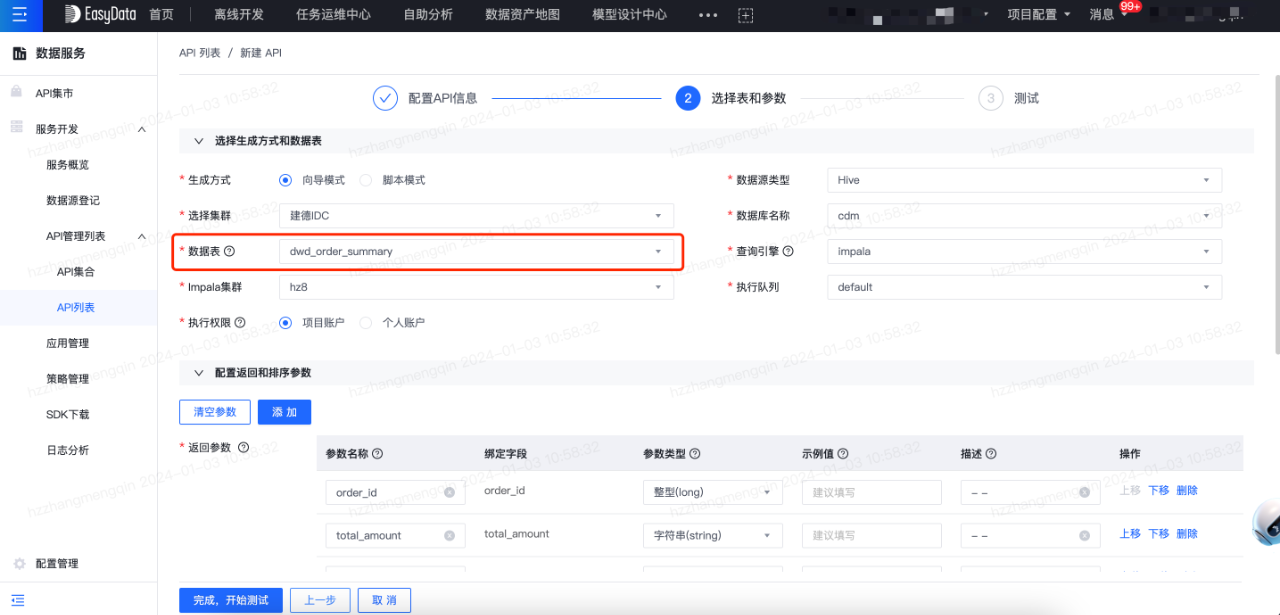
第五步:建立BI報表
加工完成的表可以在BI系統中透過視覺化配置生成需要的各種報表。在BI系統中需要將數倉Hive叢集的資訊先登記上來,然後建立模型表,最後選擇模型表後就能繪製報表資料了。報表編輯頁如下所示:
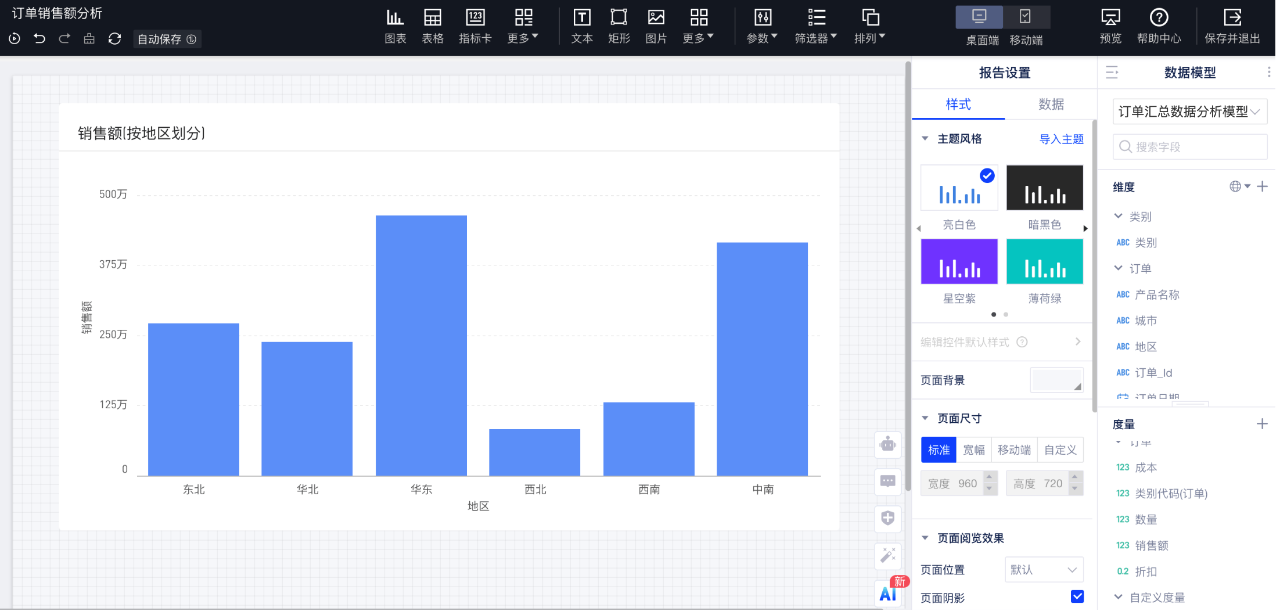
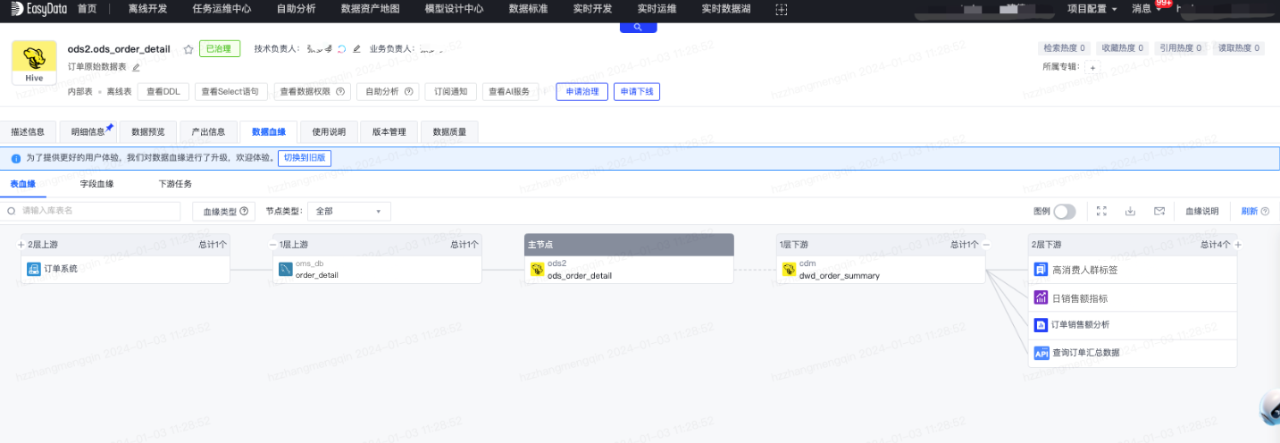
第六步:檢視全鏈路血緣圖
透過以上步驟,基本已經完成了從源端業務系統到表、表間資料加工、表和指標關聯、表和標籤關聯、表生成API、表生成報表的全鏈路血緣構建,完整的血緣圖展示如下:
04 寫在最後
在實際資料生產過程中,由於業務的複雜性高、資料來源廣、資料應用場景多,血緣圖會更加的錯綜複雜,上述案例只是一個精簡的資料鏈路,目的是介紹全鏈路血緣中的關鍵節點要素。在推進全鏈路血緣的過程中,我們也在思考一些問題,怎樣保障資料血緣的準確度、怎麼評估血緣的覆蓋率、怎樣將資料血緣價值最大化等等。
圍繞資料血緣領域,我們也實現了手工血緣、欄位血緣、血緣下載、血緣OpenAPI等能力,也落地了一套血緣覆蓋率統計規則,如果您對以上內容或者其他資料血緣相關內容感興趣可以在評論區留言,小編可根據大家反饋情況考慮後期繼續發表血緣相關文章,期待和您分享哦~
來自 “ 網易有數 ”, 原文作者:夢琴;原文連結:https://server.it168.com/a2024/0116/6837/000006837198.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 資料血緣系列(1)—— 為什麼需要資料血緣?
- 資料血緣系列(3)—— 資料血緣視覺化之美視覺化
- Yelp 的 Spark 資料血緣建設實踐!Spark
- 資料血緣系列(4)—— 資料血緣的特點與相關概念
- 火山引擎DataLeap資料血緣技術建設實踐
- 什麼是大資料血緣?大資料
- 前瞻|Amundsen的資料血緣功能
- 構建基於 Ingress 的全鏈路灰度能力
- 火山引擎DataLeap:「資料血緣」踩過哪些坑?
- 火山引擎 DataLeap:揭秘位元組跳動資料血緣架構演進之路架構
- 主機廠資料資產血緣分析治理實踐
- 一文詳解後設資料管理與資料血緣
- 在邊緣構建智慧網路的未來
- 英特爾如何助力構建邊緣智慧的工業網際網路---振工鏈
- 小白資料分析——Python職位全鏈路分析Python
- 區塊鏈構建資料可信流通體系區塊鏈
- 打造全鏈路資料隱私合規平臺
- 數倉血緣關係資料的儲存與讀寫
- 好書推薦《資料血緣分析原理與實踐 》:資料治理神兵利器
- CODING 程式碼資產安全系列之 —— 構建全鏈路安全能力,守護程式碼資產安全
- 實時通訊全鏈路質量追蹤與指標體系構建指標
- 以PSI為紐帶連結全生態KOL 《和平精英》想構建一個高度開放的內容大生態
- Node.js 應用全鏈路追蹤技術——[全鏈路資訊獲取]Node.js
- 全鏈路壓測(1):認識全鏈路壓測
- 攜程酒店基於血緣後設資料的資料流程最佳化實踐
- 資料鏈路層
- 火山引擎DataLeap資料血緣技術實現與具體用例
- 博睿資料攜手F5共同構建金融科技從程式碼到使用者的全資料鏈DNA
- 商業資料分析師——IT和商業之間的紐帶
- 使用zipKin構建NetCore分散式鏈路跟蹤NetCore分散式
- 全鏈路壓測(5):生產全鏈路壓測實施全流程
- PCIe資料鏈路層
- 建築建材電商供應鏈系統,構建高效運轉的全產業生態鏈產業
- 乾貨 | 攜程酒店基於血緣後設資料的資料流程最佳化實踐
- 基於圖資料庫的後設資料血緣關係分析技術研究與實踐資料庫
- Spark SQL 欄位血緣在 vivo 網際網路的實踐SparkSQL
- 金融行業如何通過資料鏈DNA實現自主化、全鏈路監控?行業
- MySQL資料庫之網際網路常用架構方案(全)MySql資料庫架構