小紅書社群反作弊探索與實踐
導讀:本文主題是小紅書社群反作弊探索與實踐,主要討論業務風控工作落地的解題思路。
今天的分享會圍繞下面四點展開:社群反作弊的意義;社群黑灰產生態;作弊防控策略;社群反作弊實踐。
01 社群反作弊的意義
在討論社群反作弊之前,先明確下什麼是作弊以及作弊會帶來的行業風險。
1. 作弊的定義和行業風險

發現風險和定義問題是風控工作中非常關鍵的一環,但也是經常被大家忽略的一環。本文給出個人的定義,即“一切透過非正常手段去濫用產品功能,以謀取利益的行為”。關鍵詞“牟利”,不論哪個行業,作弊一定是趨利的。不同行業的作弊風險形式並不固定,其需要結合產品形態和業務模式來界定。
比如,電商場景下作弊可能帶來的風險有刷單、薅羊毛和黃牛等。支付場景的主要風險有交易詐騙,洗錢以及信用卡套現等。那麼,社群場景下又面臨著哪些風險呢?小紅書 UGC 社群的環境下,面臨的主要風險有如下幾類,資料刷量(資料造假),內容引流,欺詐以及虛假種草。
2. 社群反作弊的意義
多數場景下,反作弊的價值透過挽回XX資損來衡量。比如,電商的薅羊毛,支付的反信用卡套現,活動的騙補貼等,衡量標準可以是為平臺節約了多少資損。那在社群中,該如何去衡量價值呢?或者說社群反作弊的意義是什麼?
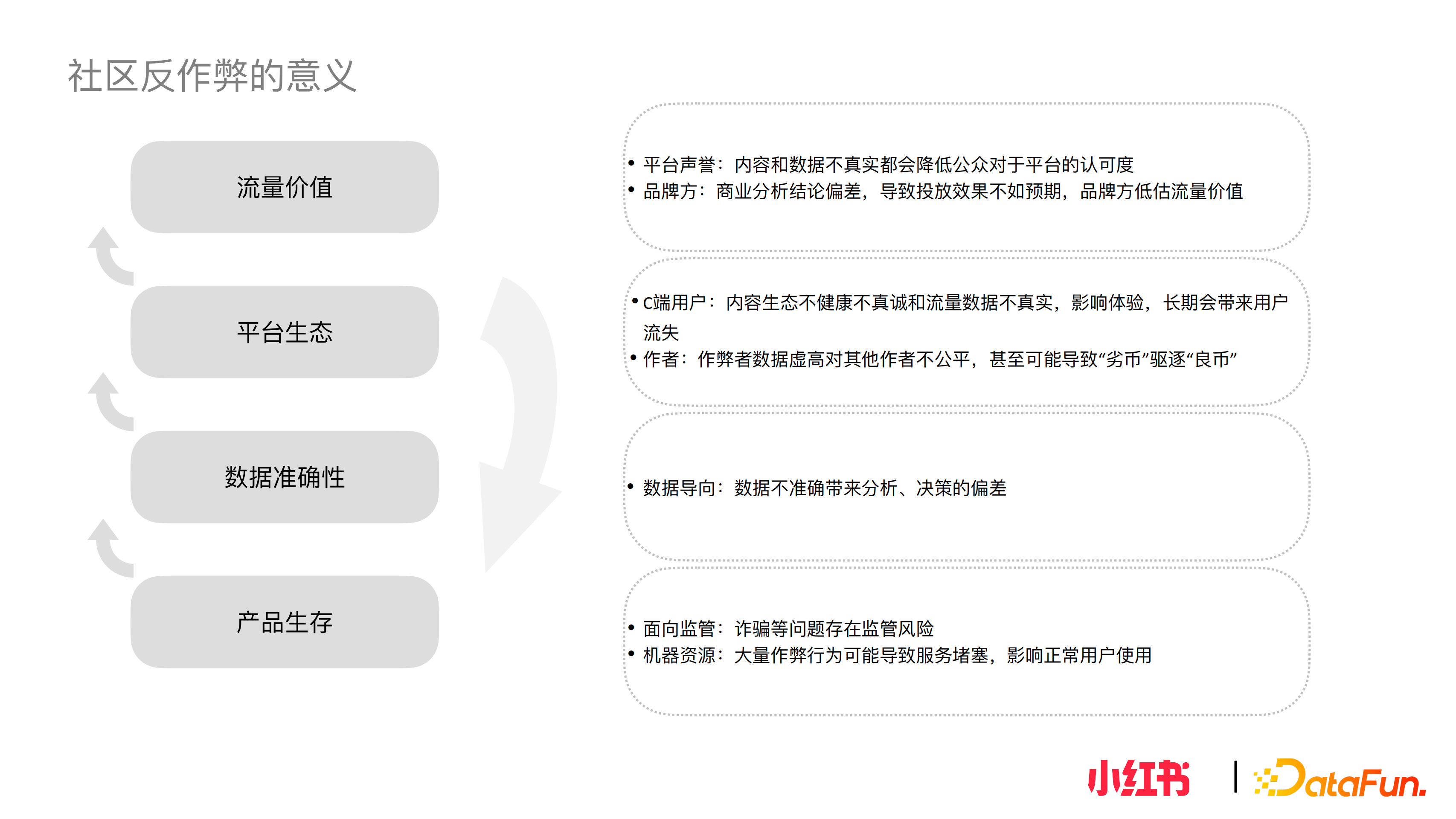
產品生存
面向監管:如果反作弊做得不到位,相應風險問題的濃度就有可能會變高,比如詐騙和刷單問題。近期,有關部門針對網際網路詐騙展開行動,如斷卡行動、清網行動等等。如果這些問題得不到有效解決,會給平臺帶來監管的風險。
機器資源:大量的作弊行為可能佔用網路資源,造成服務的堵塞,影響使用者使用功能。
從以上兩個角度考慮,作弊在短期內是有可能影響產品和平臺生存。
資料準確率
作弊行為會產生大量的垃圾資料,而資料是產品乃至戰略決策的重要支撐。如無法分辨虛假資料,當其量級和佔比達到一定程度時,可能導致分析、決策的偏差和失誤,影響業務的判斷。
平臺生態
健康和真誠的內容生態和真實的資料是使用者體驗的保障。
我們將 C 端使用者分為兩類,一類使用者無法分辨虛假資料和內容,於他們而言不真實的內容或資料會帶來決策的誤導;另一類使用者能分辨虛假資料和內容,不至於被誤導,但分辨和篩選的過程大大增加獲取有效資訊的成本。從長期來看,作弊可能會帶來對平臺的不信任和使用者流失。
對於作者來說,作者是社群內容生產的核心原動力。如果作弊者的資料虛假、虛高的話,對其他作者不公平。長期來看,作弊會導致“劣幣”驅逐“良幣”。
流量價值
最後一層,作弊行為會影響流量的價值,內容和資料的不真實,本身會降低公眾對平臺的認可度,長期來看會影響使用者使用平臺的興致。從商業化的角度,最關心流量價值的是投放者,對於投放者,如果資料不準確會影響商業分析的結論偏差,導致投放效果不如預期,低估品牌的流量價值。
舉例來說,某投放方透過資料分析挑選與其內容匹配且有流量的博主,認可其帶貨能力。假設該博主的資料是透過作弊刷出來的,投放後會發現效果不佳,ROI 不如預期,長此以往會引出平臺互動 ROI 低的結論,導致對於平臺流量價值的低估。
綜上,不論是從平臺生態還是流量價值的層面來看,虛假資料和內容都會影響平臺發展潛力。做好社群反作弊,可以提高產品長期發展的上限。
02 社群黑灰產生態
1. 作弊背後的產業鏈:分工明確

作弊背後牟利者的產業鏈是什麼?黑灰產的產業鏈分工非常明確,大致可以分上中下游三個部分。
上游主要來負責提供核心物料,比如,申請賬號,如手機號(貓池、接碼平臺)、IP 資源(代理IP,秒波 IP)、裝置的(模擬器改機、雲控手機)。
中游負責技術的實現,比如做號:註冊賬號 ->養號 -> 將號賣給下游、封裝刷量自動化指令碼、營銷工具等。
下游實現變現,一般是運營人員,是非技術的部分。通常,在黑灰色產業鏈中技術人員不會直接參與服務的變現。比如刷量服務中,常見透過網站裂變的形式發展代理和下線,實現刷量服務運營。在詐騙行業中,詐騙團伙中各司其職:運營人員一部分負責引流,一部分負責引流後培養使用者信任,最後引導完成詐騙。
2. 作弊手法迭代:從自動化工具逐漸演變為真人眾包,作弊成本增加,識別難度變大
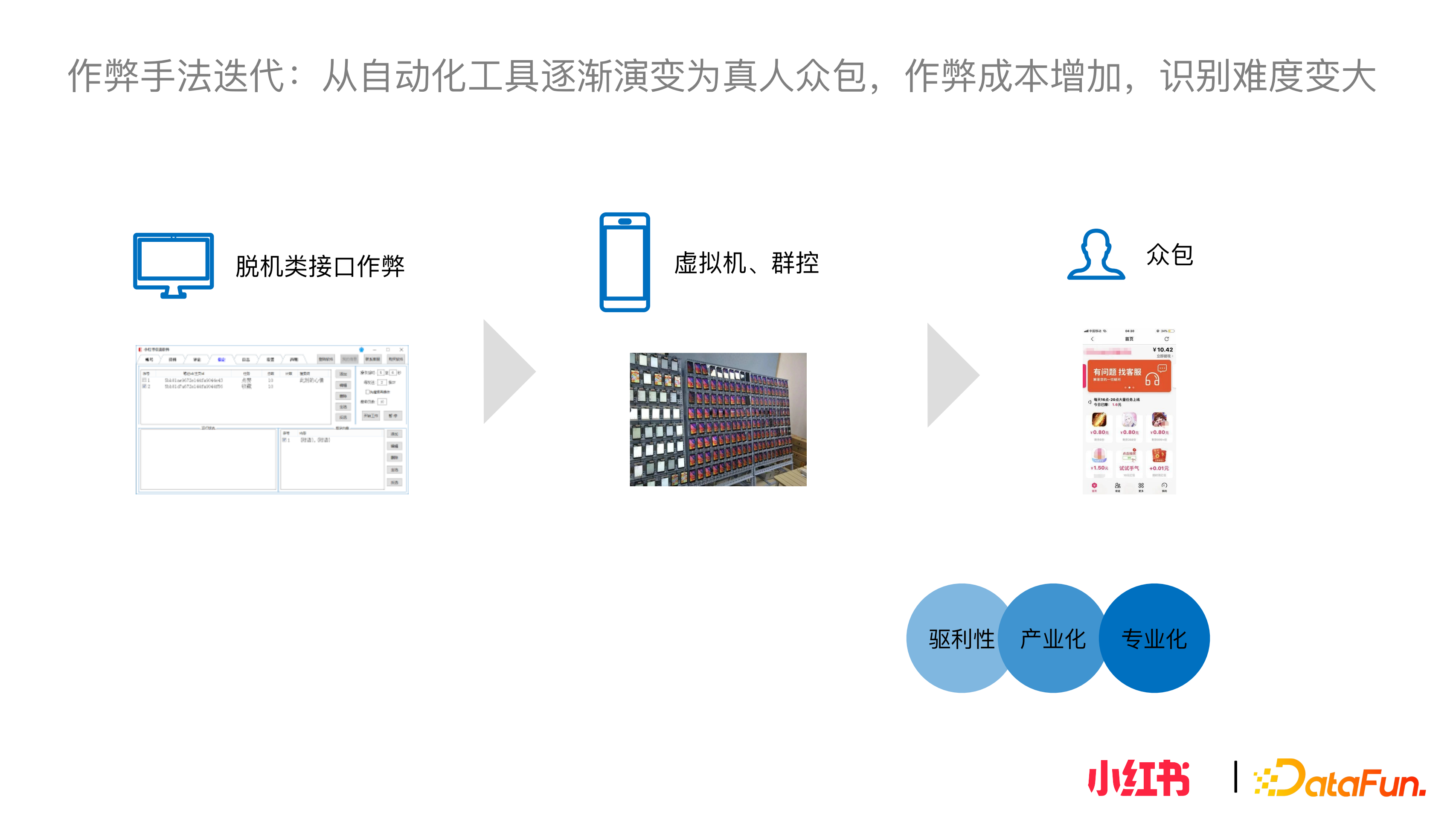
早期大多數的攻擊是離線類介面作弊,透過對抗慢慢衍生出虛擬機器和群控的形式。近些年眾包作弊的形式也慢慢成為主流。對於黑產作弊手法的迭代,可以看出作弊成本變得越來越高。離線僅需要賬號和 IP,一旦突破防護即可實現大量作弊行為;群控則需要購買真實裝置;眾包則是依賴真人以任務分包的形式達到目的。雖然眾包技術含量沒有那麼高,但全量識別的成本和難度是更高的。
從上述產業鏈可以看出,整個作弊行業的趨利性是非常明顯的,背後往往會有著比較明確的變現思路和方法。而黑產的專業性也是在利益的驅動下迅速提升。不管從上游的資源到下游的獲利,都分工明確,協同高效,慢慢的衍生出識別難度越來越大的作弊形式。這也要求做風控的同學跟進行業的形勢和進展,做到知己知彼,在識別對抗的過程中不斷的完善自我,做到迭代的最佳化。
03 作弊防控策略
1. 作弊防控思路

面對已知風險和產業鏈,下面來討論下整個作弊防控的策略。所謂策略須先明確作弊防控的目標,以及達到目標的關鍵路徑。
首先明確對於反作弊的預期。反作弊的本質是與作弊者成本的對抗,任何反作弊系統都無法做到 100% 的準確和召回。前面提到,無論何種形式作弊,它都是以牟利為目的的,而利益的來源是作弊成本和收益之間的價值差異。反作弊的工作就是提高作弊成本,儘量壓縮作弊利益空間,降低作弊者的動機。因此,合理的目標設定是降低作弊行為在正常行為中的佔比,控制風險的濃度。
關鍵路徑是化被動識別為主動防禦,如果長期作為被動方,可能沒辦法有全盤宏觀的概念。要做到主動防禦,一是構建風險的感知能力,儘早發現風險並且快速反應迭代;二是控制黑產的核心資源(賬號,裝置),樹立高門檻設定准入壁壘,並將有問題的賬號進行存量清理。收縮作弊者能使用的賬號量和裝置量,相應的新賬號成本也會變高,這就控制了核心資源。
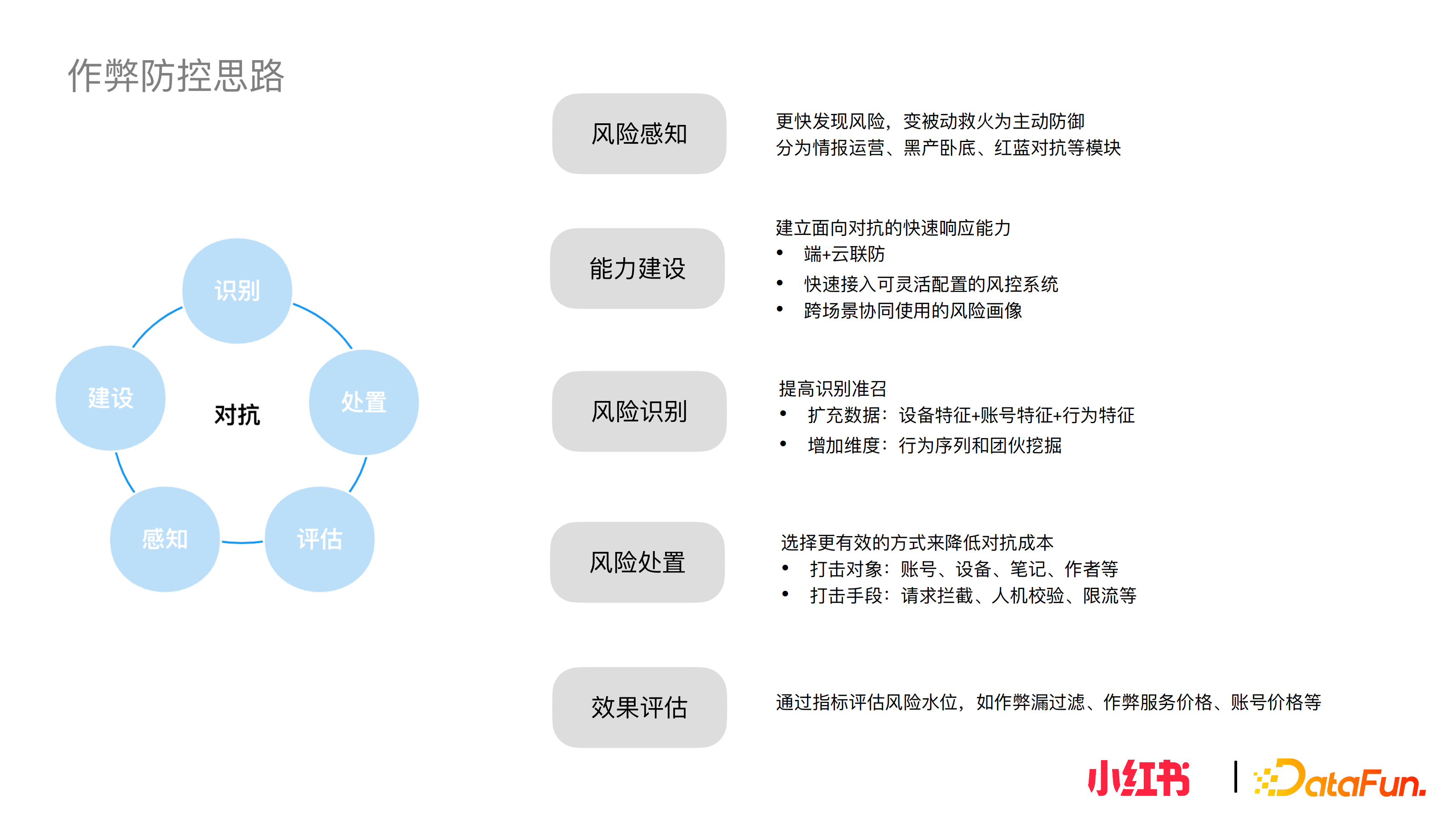
下面對作弊防控思路做進一步的拆解,也是一個比較通用的方法論,個人認為可以應用到各類風險控制場景裡。首先業務風控最大的難點是對抗,無論作弊變成何種形式,唯一不變的就是對抗,它是一直存在的。圍繞對抗抽象出幾個模組:風險感知、能力建設、風險識別、風險處置、效果評估。在遇到新的對抗時,這幾個環節間會進行不斷的迴圈迭代。下面以小紅書社群反作弊為例,具體介紹這幾個模組的設定。
風險感知層負責更快發現風險,化被動救火為主動防禦。具體分為情報運營,黑產臥底和紅藍軍對抗,幫助風險識別更早的發現問題,可以說情報是整個風險防控體系的眼睛,解決“看得見”的問題。
能力建設是面向對抗的快速響應能力。這部分涉及的模組,一是端+雲聯防,在合法合規前提下透過端獲取裝置資訊,並進一步加工為可用特徵,供雲防策略和演算法使用。二是可以快速接入且可靈活配置的風控系統,以實現策略規則的快速迭代。三是為更快的實現從零到一的落地風控場景,搭建可跨場景協同使⽤的風險畫像平臺,在新風險場景裡快速遷移和使用資料基建能力。
風險識別模組,面向對抗需提高識別的準召。從幾個角度擴充能力,首先擴充資料,結合裝置特徵、賬號特徵、行為特徵,以及其他場景下識別的風險畫像,做聯合使用分析。其次,從挖掘的角度,利用官方平臺和作弊者之間的資訊不對稱性,尋找作弊使用者相較於正常使用者的異常點:① 嘗試由點到線,從分析單個行為變成分析一序列為即行為序列挖掘;② 從單點到面, 透過賬號、IP 或裝置等節點之間的拓撲關係進行團伙挖掘,可以帶來很大的增益。
風險處置方面需要選擇更有效的方式提高繞過成本。主要分為兩個層面,一是處置物件,二是處置手段。在每個場景下該怎麼處置,並沒有一個標準答案,建議結合具體業務和業務中的風險來判斷,瞭解風險背後的動機,在考慮應該採取怎樣的處置手段才能提高繞過成本。
效果評估可以評估風險水位,一般來說常用的指標有作弊漏過量、漏過率、作弊服務價格、賬號價格等。
2. 實現方案——風控體系:⽀持快速接入分析、靈活配置與能力遷移

小紅書的風控體系,分為業務資料接入層,資料加工層,分析決策層,資料採集能力沉澱及運營和評估模組。
業務資料層,覆蓋使用者全場景的行為風控。從裝置啟用->賬號註冊\登入->內容瀏覽 ->互動->內容釋出,從多場景層面實現聯防聯控。對於明確的作弊使用者,直接拒絕訪問從而加強准入的防禦壁壘; 對於疑似異常使用者或高難度作弊註冊,建議做延遲處理或在後續關鍵環節上做攔截處置,可以達到增加繞過成本的目的:具體來說,如果在註冊時直接攔截,作弊者可快速驗證攔截原因;延遲攔截後作弊者定位識別方法的難度變大,找到繞過方法的成本也更高。
資料接入層,風控引擎支援實時請求接入,也支援準實時流式接入和離線資料接入。
資料加工層重點針對身份特徵,網路環境,裝置資訊、行為資料、時序特徵,累計因子等去做加工和挖掘,並輸入至決策分析層。
決策分析層由策略引擎、模型引擎和資料引擎組成。其中策略引擎完成實時的規則產出和返回,支援靈活的策略配置和策略上下線。模型引擎,對於簡單模型,可以做到線上 Serving;對於複雜模型或需要分析的模型,需透過近線或離線實現。
資料採集的能力沉澱層,包含裝置指紋採集、名單系統、風險畫像、關係圖計算和風險事件模組。一方面,作為分析決策層的資料來源做輸入。另一方面,實現識別能力的遷移、使用等等。決策分析層也會向能力沉澱層做輸出, 將新識別風險點落到能力沉澱裡複用至其他風險場景。
04 社群反作弊實踐
該章節主要分享小紅書社群資料刷量風險的識別和治理工作。
1. 資料刷量反作弊實踐——風險治理

風險治理環節置關重要,在實踐中我們發現,同樣的識別結果,在選擇不同的治理物件和方式時,效果差異性非常大。分享下我們的理解,可以從影響、實現鏈路以及作弊動機三個層面剖析資料刷量的問題:
Q:資料刷量帶來的影響是什麼?
A:博主的虛假粉絲,筆記的虛假點贊、收藏、分享、閱讀等。
Q:實現刷量的鏈路是什麼?
A:買量者購買刷量服務,或在眾包平臺發單等;刷單者提供服務來牟利。
Q:作弊背後的真實動機是什麼?
A:買量者希望透過刷假資料提高自我流量的價值,但該價值是假的,他想營造出一種虛假的高價值,從而去實現商業化的流量變現。
我們有一些不同的治理方案:
一、對於影響的治理方案是清理這部分作弊的行為所得。但是,僅清理虛假流量,唯一的損失就是買量付出的錢。但對於買量者,還可以嘗試其他作弊服務。因為作弊買量價位不會非常高,不斷嘗試的可能性就很強。關鍵點在於嘗試作弊是沒有邊際成本的,比如某人偷東西后只是要求把偷竊所得還回去,而不會把他抓起來,只要不被發現就賺了。
二、對於實現鏈路,針對刷量作弊的賬號做治理。比如識別到一個用於刷量的機器賬號,平臺將該賬號封禁。從賬號的成本上考慮,提供刷量服務者手上的賬號量會變的越來越少,做賬號成本就會變高,刷量的服務價格就會上漲,刷量者嘗試新手法時成本也會變高。
三、從作弊動機角度考慮,按作弊程度作流量分發降權或商業權益限制。對買作弊流量的筆記做流量分發限制,作弊後可以獲得的流量比不作弊更少。其次是限制買作弊流量博主的商業權益,因為很多買量者想透過商業化實現流量變現,對商業權益限制使齊無法做商業合作,對作弊者來說是很大的損失。該模組治理效果,可以大大降低買量者的作弊意願。
從實踐來說,從治理【風險影響】轉變為治理【實現鏈路】與【作弊動機】,作弊意願降低,作弊量級下降顯著。
2. 資料刷量反作弊實踐——風險識別
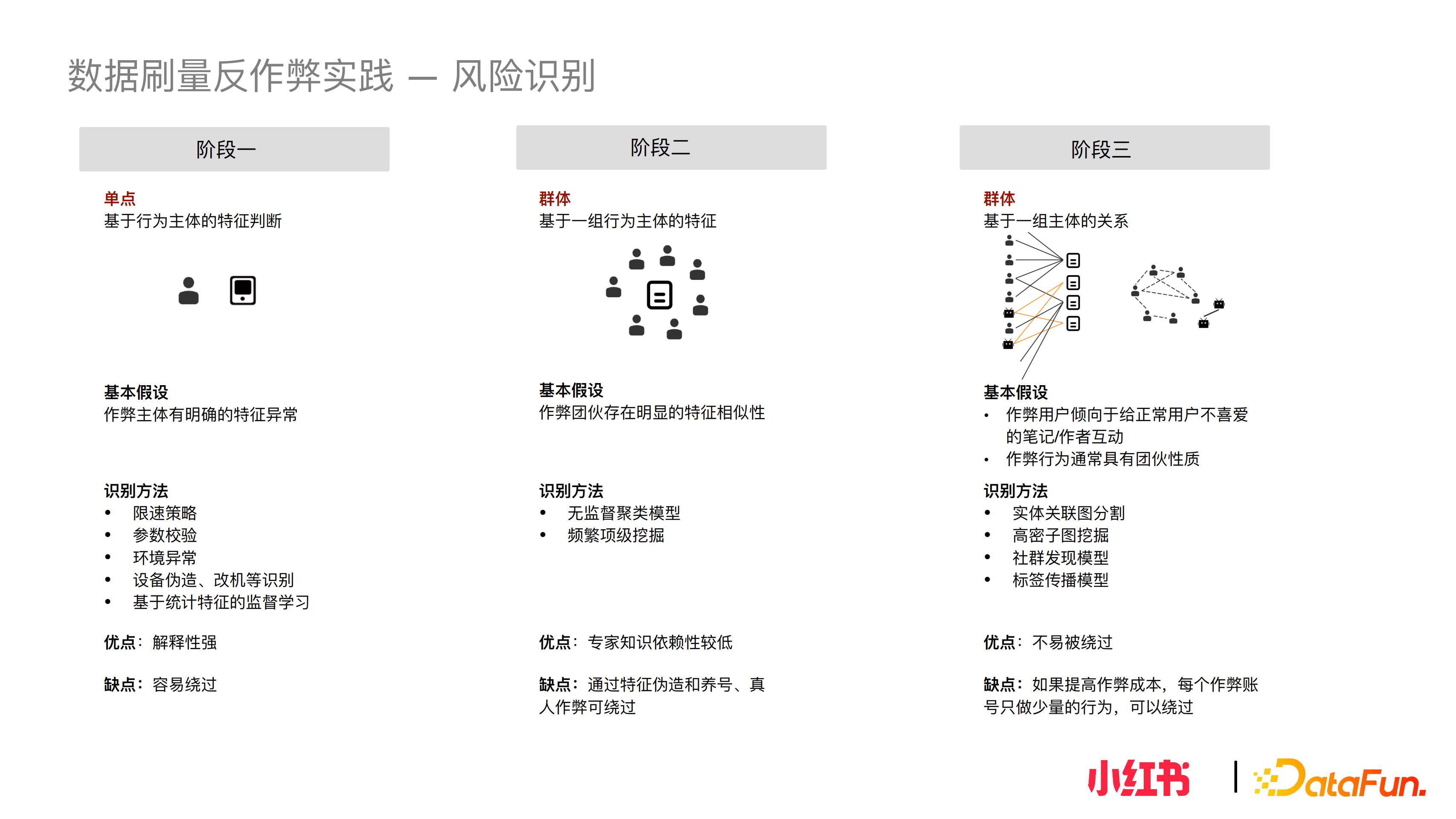
資料刷量的風險識別實踐分為三個階段,隨著對抗的展開識別方案不斷迭代。
第一個階段,在沒有風控沒有對抗的情況下,發現風險是相對容易的,粉線隱蔽性不強,該階段基於行為的主體特徵做異常識別,基本假設是作弊主體有明確的特徵異常。相應的識別方法如限速策略、引數校驗、環境異常、裝置偽造改機等識別,以及基於統計特徵的監督學習。優點是識別方式解釋性非常強。缺點是比較容易繞過。拿限速策略舉個例子,上線初期攔截效果明顯,但很快作弊者就會摸到限速閾值,只要將速度降下來就可繞過。但是從對抗層面來說,閾值是不可能無限下壓的,當速度與正常使用者重合時,閾值就無法下調了。
由於第一階段識別打擊生效,出現了對抗,單點分析已不能覆蓋大部分風險。所以第二階段,基於群組行為主體的特徵分析挖掘異常。基本假設是作弊團伙存在明顯的特徵相似性。識別方式上,嘗試無監督的聚類演算法或頻繁項挖掘等。優點是對專家知識的依賴度比較低,可以透過無監督手法找到新團伙;缺點是透過特徵偽造、養號、真機可一定程度上繞過識別。
第二階段上線後,黑灰產又調整了一次作弊模式。意識到,一是需要加強裝置改進引數的真實性。二是透過代理做IP打散,甚至嘗試真人眾包的作弊模式。
在該階段我們再次探索資料刷量背後不變的模式是什麼?刷量的本質是本身沒有流量的人,希望給自己的資料做作假。作弊使用者傾向於給正常使用者不喜愛的筆記/作者互動,且這類作弊互動是具有批次性質的。為了達到效果,買量者不會只買一個作弊行為。在這個假設下,我們基於拓撲關係設計圖的構建和圖相關演算法。在構建過程中,嘗試構建同構圖,比如人與人之間的關係,有相似行為的人構邊,或使用過相同介質的人構邊。也嘗試構建異構圖,異構圖中很多實體都是可以構點,不限於人或裝置,可以是IP、手機號、行為的物件等。在構圖完成後,可以在拓撲結構上實現圖分割、高密子圖挖掘、社群發現模型或者標籤傳播模型等。
這類方案的優點是不太容易被繞過;缺點是如果作弊者不斷提高作弊成本,每個作弊賬號和IP用的次數極少,在只做少量行為的情況下,關聯關係很有可能在構邊的過程中丟失,導致識別漏過。
不過這種情況下,每個作弊行為的成本非常高,提高作弊成本的目標也基本達到了。
來自 “ DataFunTalk ”, 原文作者:費棟;原文連結:http://server.it168.com/a2023/0119/6786/000006786944.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- Native Flink on Kubernetes 在小紅書的實踐
- 2019年小紅書社群趨勢報告
- Flutter探索與實踐Flutter
- ChatGPT的探索與實踐ChatGPT
- OceanBase 的探索與實踐
- 彈性探索與實踐
- 得物社群 golang 灰度環境探索和實踐Golang
- 讀書小組實踐
- 小紅書“致歉濾鏡景點”:種草社群的尺度在哪?
- Android元件化探索與實踐Android元件化
- Zoho推出《中國ToB超級應用探索與實踐白皮書》
- 小紅書:深耕內容社群,掘金種草經濟(附下載)
- TiDB 社群成長足跡與小紅花 | TiDB DevCon 2019TiDBdev
- Presto在滴滴的探索與實踐REST
- FlutterWeb效能優化探索與實踐FlutterWeb優化
- 小紅書近線服務統一排程平臺建設實踐
- 開源實踐 | 攜程在OceanBase的探索與實踐
- 開源實踐 | 攜程在 OceanBase 的探索與實踐
- 益普索&小紅書:2020小紅書年中美妝洞察報告
- 遊戲社群新勢力,小紅書的使用者們這麼玩遊戲
- 人崗匹配排序的探索與實踐排序
- 資料庫治理的探索與實踐資料庫
- Flink CDC 在京東的探索與實踐
- 小紅書如何實現數倉效率與成本的雙重最佳化
- 小紅書怎麼開通直播?小紅書開通直播的圖文教程
- 食品類小紅書營銷方案 小紅書廣告投放上海氖天
- 小紅書怎麼優化排名,小紅書怎麼釋出seo筆記?優化筆記
- 前端資料層的探索與實踐(一)前端
- 前端資料層的探索與實踐(二)前端
- 資料庫智慧運維探索與實踐資料庫運維
- vivo 在離線混部探索與實踐
- Flutter包大小治理上的探索與實踐Flutter
- vivo直播應用技術實踐與探索
- vivo 故障定位平臺的探索與實踐
- 未讀訊息(小紅點),前端與 RabbitMQ實時訊息推送實踐,賊簡單~前端MQ
- 小紅書API介面測試 | 小紅書筆記詳情 API 介面測試指南API筆記
- 小紅書達人種草模型 小紅書達人合作方式上海氖天模型
- 美團外賣小程式的探索與實踐丨掘金開發者大會