檔案系統的發展趨勢與JuiceFS的雲上實踐
導讀:JuiceFS 是一個為雲環境而設計的分散式檔案系統,在 2021 年初開源後,過去一年在開源社群裡發展很快,也受到了很多關注。本次分享希望讓大家瞭解 JuiceFS 的設計背景、設計理念,以及它能夠為開發者帶來的幫助和價值。
今天的介紹會圍繞下面四點展開:
檔案儲存的發展
雲時代的痛點與挑戰
JuiceFS 的設計哲學
JuiceFS 的使用場景
01 檔案儲存的發展

首先我們回顧一下檔案儲存的發展歷程。
1. 區域網時代
2005 年之前還是一個以區域網為主的階段,網際網路才剛剛開始。這個時期的分散式檔案系統或者說檔案儲存大部分是軟硬一體的產品,我們能在市場上看到 NetApp、EMC 還有華為的一些儲存櫃子。這些產品給很多使用者留下了一個印象,那就是儲存實際上就是買硬體,買一個儲存的櫃子就搞定了。
2. 網際網路時代
2005 年之後,寬頻網際網路在全球範圍內普及,網際網路時代到來了。Web2.0的發展速度非常快,由第一代網際網路那種簡單呈現訊息的入口網站轉變成了一個所有使用者都可以在網路上互動的產品形態,出現了像社交網路這樣的產品。整個網際網路產生的資料爆發式增長,這樣的趨勢也就導致像區域網時代一樣去買硬體的儲存櫃已經跟不上網路時代資料增長的發展了。因為買硬體的櫃子會涉及到選型、採購、到貨、上架這樣一個很長的流程,需要做很嚴謹的容量規劃。
就在這個時間點上 Google 提出了他們的 Google File System 的論文,同時在技術社群裡面出現了第一代純軟體定義儲存的分散式檔案系統產品。大家熟知的像大資料領域的 HDFS,已經被紅帽收購的 CephFS、GlusterFS,還有當時面向 HPC 場景的 Lustre、BeeGFS 這些產品都是在 2005 年到 2009 年這樣一個很短的時間視窗內誕生的。這也就意味著這些產品都有一個共同的時代背景以及面向當時硬體環境的設計,比如說當時還沒有云的存在,所有的這些分散式檔案系統都是面向機房裡的物理機設計的。而當時的機房環境和今天最大的區別就是網路環境,當時機房裡面是以百兆網路卡為主的,如今機房裡面基本都是萬兆網路卡了,這些給我們的軟體設計和 IT 基礎架構的設計帶來了很多的改變。
第一代軟體定義儲存的產品像 HDFS 和 CephFS,以及 AI 流行以後的 Lustre 仍然在被很多公司在不同範圍內使用。這些產品在發展過程中面對的新的挑戰就是移動網際網路的出現。
3. 移動網際網路時代
2010 年之後的十年時間,移動網際網路相比 Web2.0 最大的變化就是以前人們只能坐在電腦前使用網路產生資料,而到了移動網際網路時代,每個人每天醒著的時候都可以使用手機來產生資料,這就意味著整個網際網路上資料的增長速度又快了一兩個數量級。
第一代面向機房,用軟體搭建分散式儲存和分散式系統的方案在移動網際網路時代也遇到了挑戰,這也就讓公有云應運而生。最早的像 AWS 就是在 2006 年釋出了第一個產品 S3,在當時都還沒有整個公有云的體系,沒有 EC2 這樣的計算環境,只有一個儲存服務 S3。S3 就是想簡化之前人們自己搭建機房,採購硬體然後透過軟體去搭建分散式系統這個複雜的過程。物件儲存在移動網際網路時代有了一個非常快速的發展,它的誕生是為了解決之前分散式檔案系統的一些問題,但也導致犧牲了一些能力,這個我們後面會再展開講。
4. 雲原生時代
在移動網際網路蓬勃發展之後,現在又迎來了物聯網的發展,這對儲存的規模、易管理性和擴充套件能力等各方面都有了一個全新的要求。當我們回顧公有云時會發現缺少一個非常適合雲環境的分散式檔案系統,直接將上一時代的 HDFS、CephFS、Lustre 這樣的產品放到公有云上又不能體現出雲的優勢。
02 雲時代的痛點與挑戰
1. 各代檔案儲存的特性
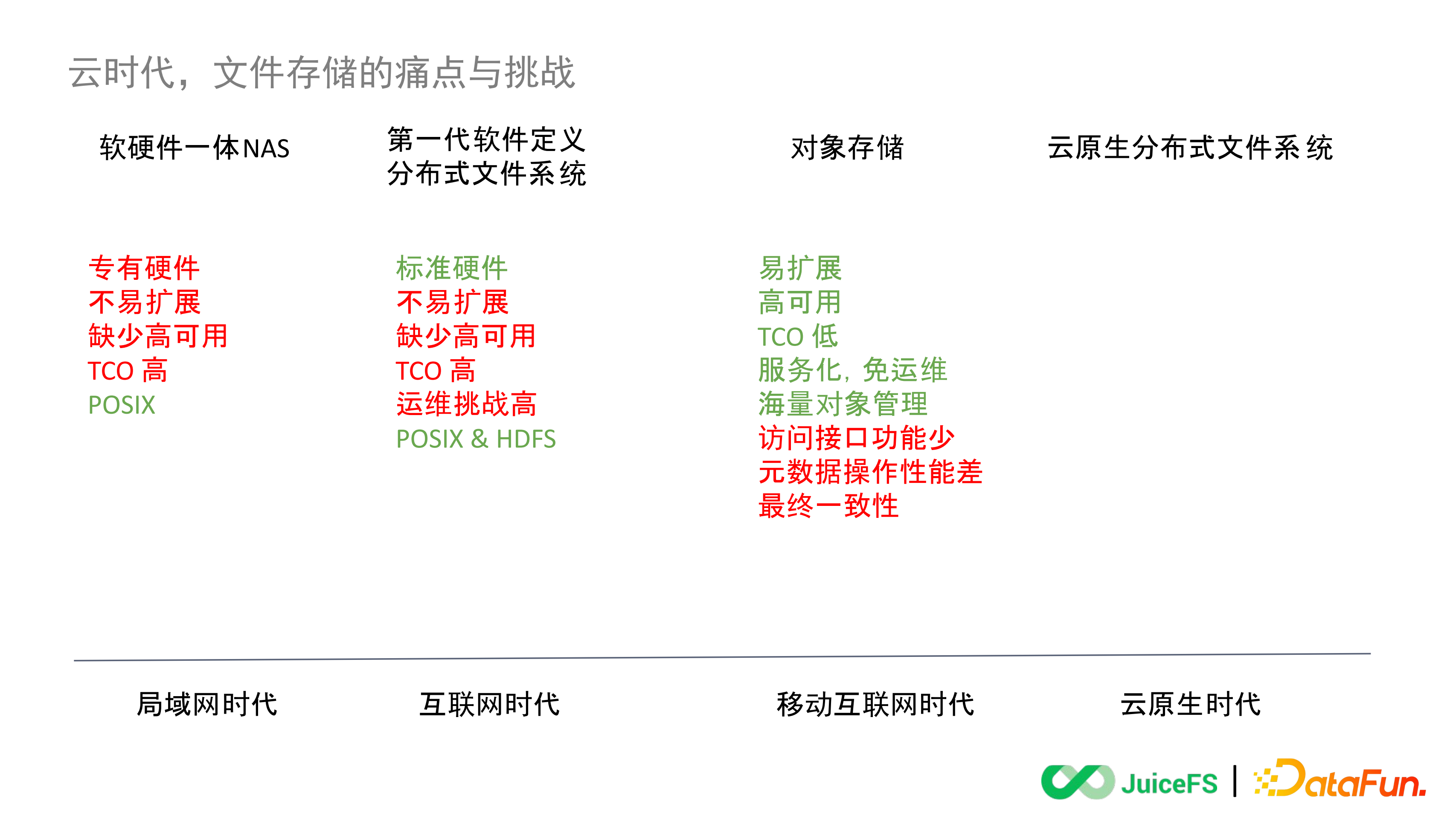
下圖展示了這四個時代對應的儲存產品的特點,以今天的視角回看,其中紅字是每代產品中存在的問題,綠字是其好的特性。
2. 軟硬體一體 NAS
第一代硬體產品在當時都是採用專有的硬體,擴容並不方便,因為相容問題無法將不同廠商的硬體對接到一起使用。並且當時這一代軟硬一體 NAS 也缺少高可用,大部分採取主從互備的方式。對於今天更大負載,更大規模的系統主從互備的可用性是不夠的。此外,還存在整體成本較高的問題,因為需要專門的硬體,網路環境和相匹配的維護能力。
當時這一套軟硬一體 NAS 有一個最大的優勢就是它是 POSIX 相容的,學習成本很低,對使用者而言就和使用 Linux 本地盤的體驗是一樣的。這就意味著開發上層應用的時候是非常簡單的,無論直接透過系統呼叫還是透過各種語言的框架去開發都是 POSIX 相容的,會很方便。
3. 第一代軟體定義分散式檔案系統
到了網際網路時代,第一代軟體定義分散式檔案系統包括 HDFS、CephFS 不再依賴於專有硬體,都是用標準的 X86 機器就可以搞定了。相比第一代軟硬一體的擴充套件性有所提高,但是和後來的雲端儲存相比還是不易擴充套件,能看到像 CephFS、HDFS 也都有一些單叢集的上限,這是在當時的容量規模下進行設計造就的侷限。
此外仍然缺少高可用的設計,大部分依舊採用主從互備,這樣一來仍然要為機房獨立的採購硬體,研究、維護大規模的分散式系統,因此整體的 TCO 還是相對較高的。同時相比上個時代對於運維的挑戰更高了,因為不存在廠商的服務了,需要自己構建一套運維團隊,擁有足夠的運維能力,深入掌握這套開源的檔案系統。
好在像 CephFS、Lustre 這些仍然是 POSIX 相容的,而 HDFS 為了滿足大資料 Hadoop 生態架構提出了一套新的儲存介面 HDFS API。如果詳細的去分析這套 API 能發現它其實是 POSIX 的一個子集,假設說 POSIX 有 200 個介面,到 HDFS 大概就剩下一半。從檔案系統的功能上來看,它是對一個完整的檔案系統做了一些裁剪,比如 HDFS 是 Append Only 的檔案系統,也就是隻能寫新資料、追加檔案,而不能對已有的檔案做覆蓋寫。這是當時 HDFS 為了實現更大規模資料的儲存而犧牲掉的一部分檔案系統語義上的能力。
4. 物件儲存
物件儲存相比之前的檔案系統提出了三個核心的能力:易擴充套件、高可用和低成本。在這三個核心能力的基礎上提出要實現服務化,即使用者不再需要投入任何成本在搭建、運維、擴容這些事情上了;此外還提出作為一個雲服務要能裝下足夠海量的資料。
但是與此同時也犧牲了很多檔案系統原生支援的能力。
第一是介面少了。物件儲存提供的 API 往往是 HDFS 的一個子集,相比 POSIX 能提供的能力就更少了。前面舉例說假如 POSIX 有 200 個 API,那到 HDFS 可能只有 100 個了,到 S3 的時候大概只剩 20-30 個了。
第二是後設資料操作效能下降了。物件儲存本身並不是為那些需要操作複雜後設資料的應用設計的,最開始設計物件儲存只是想實現資料上傳再透過 CDN 進行分發這樣一個簡單的業務模型。最初S3裡的介面其實只有 PUT、GET 和 DELETE,後來又衍生出了 LIST、HEAD,但能看到像 RENAME、MV 這些在檔案系統裡很常見的操作至今物件儲存都是不支援的。
5. 物件儲存與檔案系統的區別
接下來我們再展開看一下物件儲存和檔案系統的幾個區別。
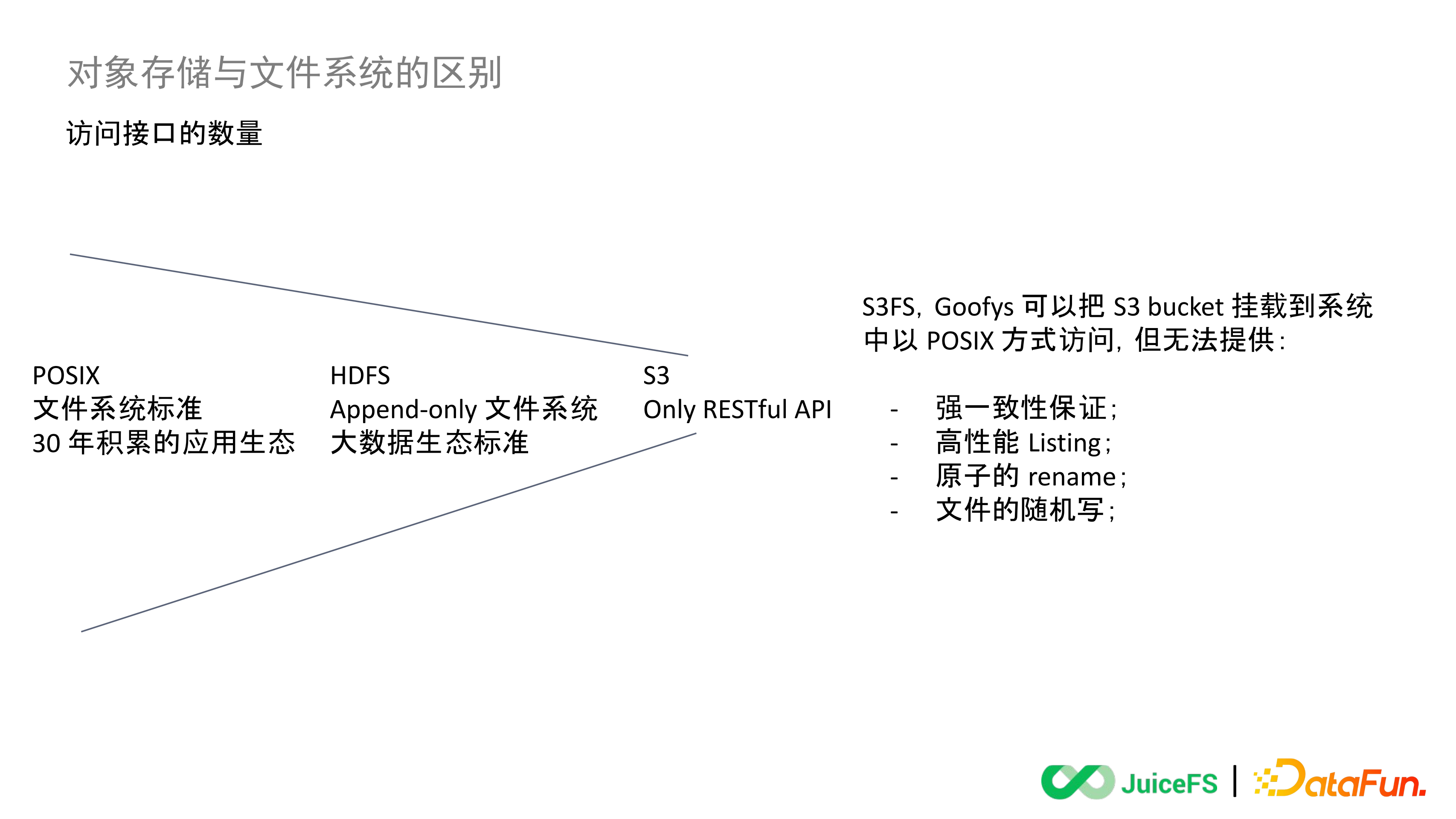
6. 訪問介面的數量
POSIX
POSIX 協議已經內建到 Linux 作業系統的核心裡了,可以透過系統呼叫直接訪問一個 POSIX 相容的儲存系統,Open、Write、Read 這些標準的介面也已經內建到各個程式語言裡面了。在 POSIX 之上構建出來的應用生態從 Linux 開始流行到現在至少有三十年的時間了,再基於 POSIX 標準去做全新的檔案系統上層應用不需要做任何的適配修改,也不需要提供任何特殊的 SDK,各個語言都是可以直接訪問的。
HDFS
HDFS 是一個只能追加的檔案系統。它提供了一套自己的 SDK,比如說有大家熟知的用在 Hadoop 裡面的 Java SDK。但這給上層的應用開發帶來了一些新的挑戰,即原來的程式是沒辦法直接使用 HDFS 的,必須在跟檔案系統打交道這一層去做替換。替換的過程中就要去考慮介面之間是不是一一對應的,不對應的時候用什麼方式能構建平滑的對映關係。
HDFS 經過十幾年的發展已經成為 Hadoop 領域的一個預設標準,但其實在其他領域並沒有得到廣泛的應用,就是因為 HDFS 有著一套自己的 API 標準。HDFS 今天最成熟的還是用在 Hadoop 體系裡面的 Java SDK。而其他的像 C、C++、Python、Golang 這些語言的 SDK 成熟度都還不夠,包括透過 FUSE、WebDAV、NFS 這些訪問 HDFS 的方式也不是很成熟,所以至今 HDFS 主要還只停留在 Hadoop 體系內去使用。
S3
S3 最開始是基於 HTTP 協議提供了一套 RESTful API,好處是更加的標準和開放,但是同時也意味著它和現有的應用程式是完全不能相容的,每一個應用都需要面向它做對接適配或者針對性的開發。S3 本身提供了很多語言的 SDK 方便開發者使用,也誕生了一些第三方專案,其中最著名的是 S3FS 和 Goofys。這兩個專案都是支援將 S3 的 Bucket 掛載到系統裡,像訪問本地盤一樣讀寫資料,現在各個公有云上也有提供針對自己物件儲存的一些類似方案。
雖然這些能夠實現把 Bucket 掛載到作業系統裡,但是無法提供的是資料強一致性的保證,然後是高效能的 Listing,以前在本地盤裡列目錄是一個很輕量的動作,但是在物件儲存的 Bucket 裡去列目錄效能代價是很高的。此外,物件儲存也還沒有支援原子的 Rename 和對檔案進行隨機寫。POSIX 相容的檔案系統裡是有 API 支援對檔案的隨機寫的,開啟一個檔案然後 Seek 指定的偏移量去更新它的內容。但是在物件儲存上面要想實現對資料或者說對檔案的區域性進行更新,唯一能做的就是先將檔案完整的下載到本地,更新其中需要修改的那一部分資料,再把這個檔案完整的上傳回物件儲存裡面。整個隨機寫的操作代價是非常大的,無法支援需要隨機寫的應用。
7. Rename 的行為差異
現在 S3 原生的 API 裡仍然沒有 Rename,官方 SDK 和很多第三方工具的確提供了這個功能,比如透過 Goofys 或者 S3FS 把 Bucket 掛載到機器上再執行 Rename。但這裡的 Rename 和檔案系統原生的 Rename 是有差別的,這裡舉一個例子。
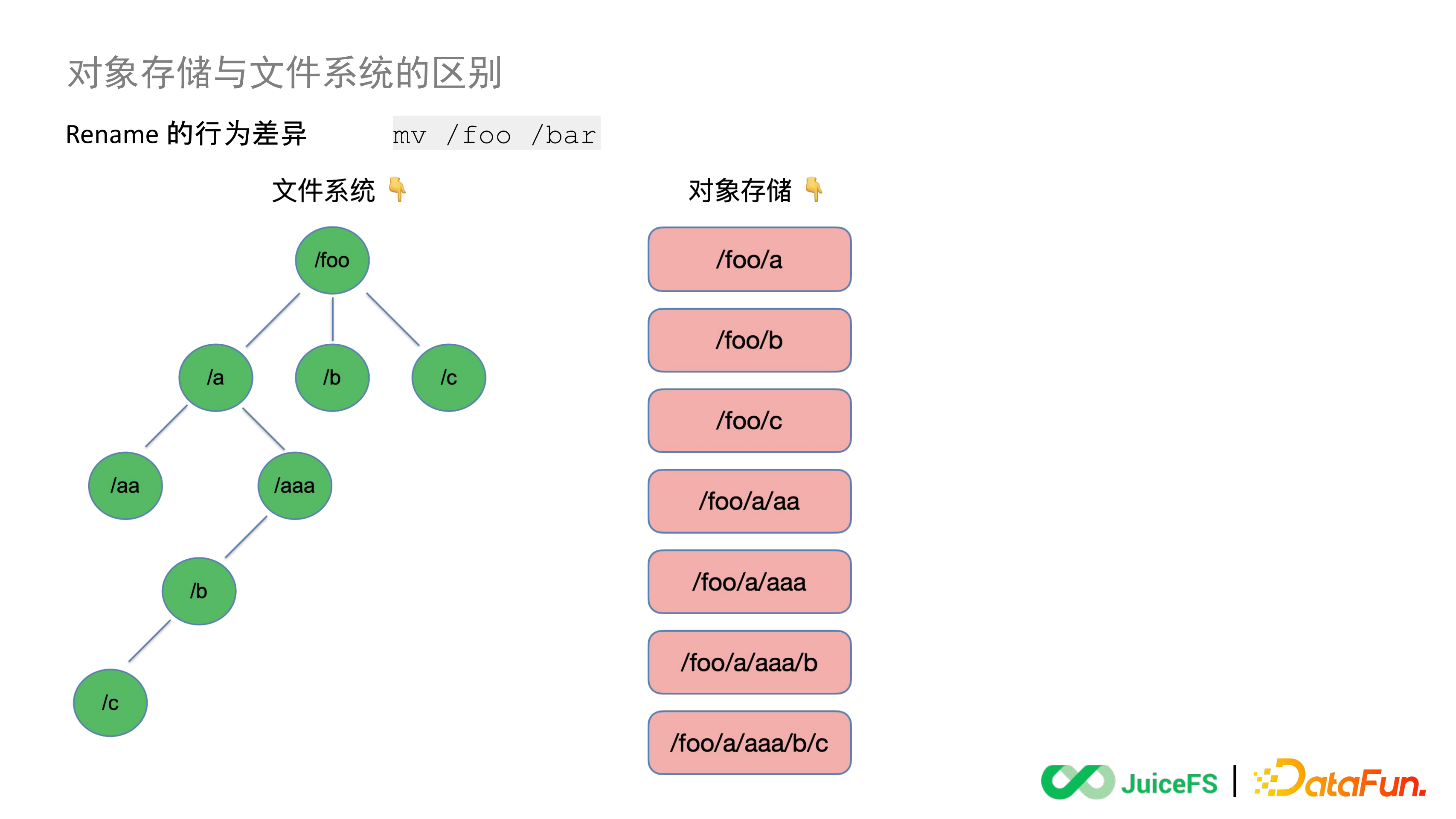
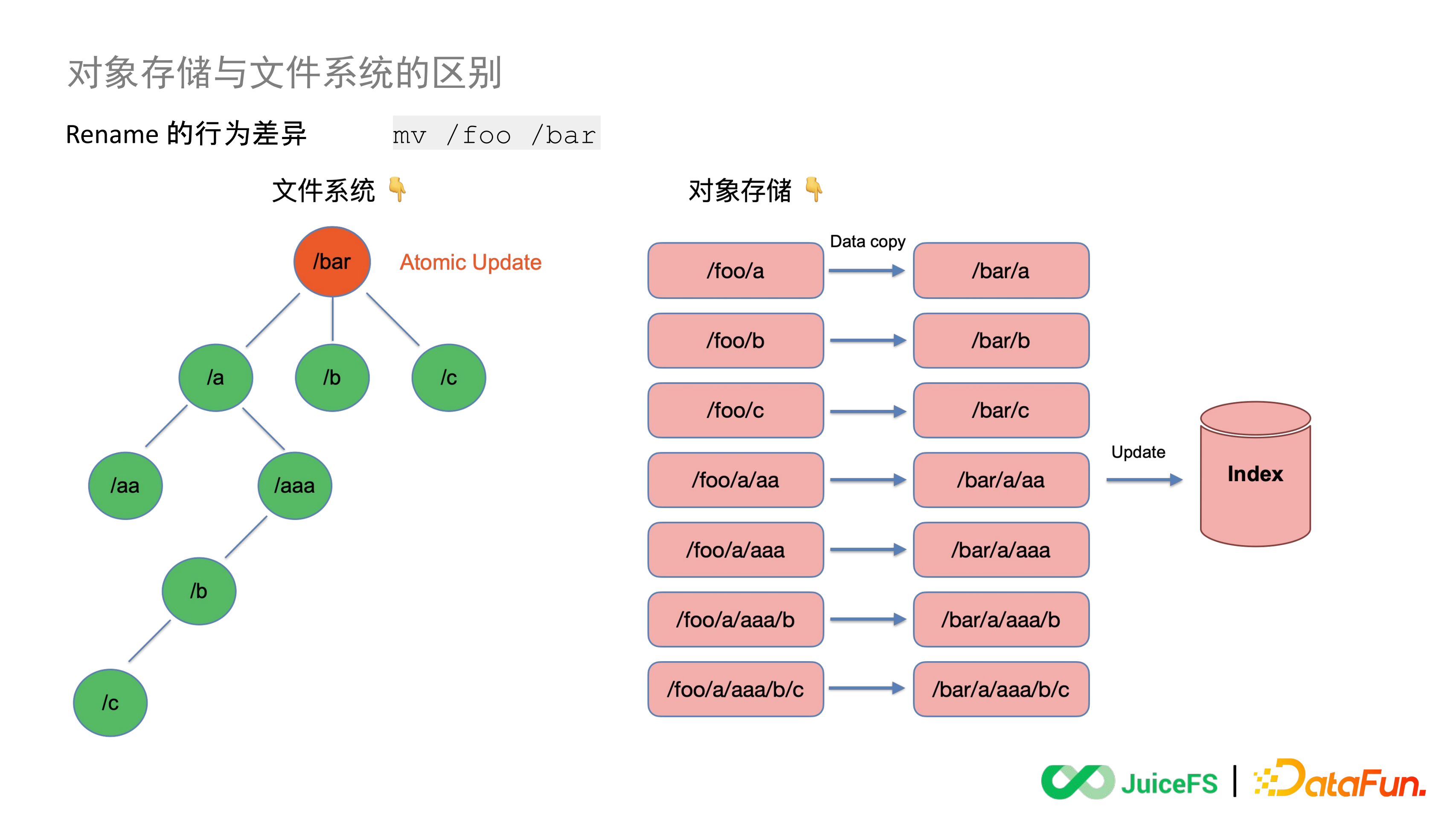
左邊模擬檔案系統,這是一個樹形結構的目錄樹。而物件儲存是不存在原生的樹形結構的,它會透過設定物件的 Key 值(物件名)來模擬出一個路徑,實際上物件儲存裡面的資料結構是扁平的,即右邊這樣的結構。
如果此時要執行一個 Rename 操作,把 /foo 這個目錄名改成 /bar,因為檔案系統是樹形的資料結構,所以它就能找到這個目錄名對應的 Inode 去執行一個原子的更新,把 foo 替換成 Bar。
因為物件儲存的資料結構是扁平的,所以需要在物件儲存裡對這個 Key 的索引去做一次搜尋,找到所有以 foo 為字首的物件,可能是 1 個也可能是 100 萬個。搜尋出來以後要將這些物件進行一次 lO 複製,用新的名字作為 Key 值複製一遍,複製之後再更新相關的索引資訊同時刪掉舊的物件。
能看到這是一個比較長的操作過程,要先搜尋物件,然後複製,再更新索引,整個過程其實是沒有事務去保證的,有可能會出現一致性問題。目前大部分的物件儲存會保證最終一致性,只有少數的物件儲存會在自己原生的 API 裡面保證強一致性,但是在第三方工具做的像 Rename 這樣的衍生 API 裡仍然只是保證最終一致性。
8. 最終一致性
這裡再透過一個例子來解釋最終一致性以及它可能對應用造成的影響。
這裡畫了一副漫畫,講了老奶奶的一隻貓跑到了樹上,她想請這個小朋友幫她救貓,小朋友說沒問題,我幫你把貓拿回來。大家可以看到他居然從另外一個畫面裡把貓給取了出來,老奶奶很疑惑,為什麼樹上和小朋友手裡各有一隻貓?小朋友說這只是一個 SYNC 的問題,你再去 Check 一下就好了,老奶奶再往樹上看的時候樹上的貓已經不見了。這裡其實就體現了前面講的 Rename 的過程,即在一個很長的流程裡資料沒有保持完整的一致性狀態。
對應的命令在左邊,首先列了一下這個 Bucket 的目錄,發現有一個檔案 cat.txt,將它 MV 到新的目錄,換完目錄之後看到原來的這個目錄裡面還有這個cat.txt,而新的目錄裡也有了一個 cat.txt,此時看到了兩隻貓,這看起來就不像是 MV 的操作了。但其實這是一個 SYNC 狀態的問題,可能過了一會再去原來的舊目錄裡檢視檔案就會發現 cat.txt 不見了,在操作過程中去觀察時資料狀態還沒有一致,但是系統會保證最終是一致的狀態。而如果上層的應用在資料狀態不一致的時候就已經去依賴它來進行下一步操作的話,那應用可能就會出錯了。
這裡舉了幾個例子來說明雖然今天物件儲存是能夠給我們提供優秀的擴充套件性、低廉的成本和便捷的使用方式,但是當我們需要對資料進行更復雜的分析、計算操作時物件儲存仍然會給我們帶來一些不方便的地方,比如說介面很少、需要針對性的開發、後設資料的效能差。以前在檔案系統裡很輕量的操作,在物件儲存裡可能會變得很複雜;此外還可能會引入一些一致性的問題,對資料精確性要求很高的場景就不適合了。
03 JuiceFS 的設計哲學
從軟硬一體到第一代軟體定義檔案系統再到 S3 各有各的優缺點,所以今天當我們在雲的環境裡面去看的時候會發覺缺少一個非常完善,非常適合雲環境又能很好的支援大資料、AI 還有一些新興的海量資料處理或者密集計算這些場景的檔案系統產品,既可以讓開發者非常容易的使用又有足夠的能力去應對這些業務上的挑戰,這就是我們設計 JuiceFS 的初衷。

1. JuiceFS 的設計目標
(1)多場景,多維度
前面分析了當前市面上的場景,當我們想去為雲環境設計 JuiceFS 這個產品的時候,我們開始考慮自己的設計目標,要比較前面這些產品的一些優劣勢和它們的設計思路,同時也要更多的關注使用者業務場景的需求。檔案系統是在整個 IT 基礎架構中非常底層的產品,使用它的場景會非常的豐富,在不同的場景裡對檔案系統本身的規模、擴充套件性、可用性、效能、共享的訪問能力以及成本甚至還有很多維度的要求都是不一樣的,我們要做的是雲環境通用型產品,就需要在這個矩陣上去做取捨。
2. 架構的設計選擇
在多場景、多維度的前提下做架構設計時有幾個宏觀的方向是我們非常堅持的:
完全為雲環境設計
後設資料與資料分離
這種設計會為我們在多場景多維度上去做取捨的時候帶來更多的靈活性。像 HDFS 是後設資料和資料分離的方案,而 CephFS 就更像是後設資料和資料一體的方案。
外掛式引擎
我們提出把 JuiceFS 設計成一種外掛式的引擎,讓資料管理、後設資料管理包括客戶端都能提供一種外掛式的能力,讓使用者結合自己的場景去做不同維度上外掛的選擇,來拼插出一個最適合自身業務場景需求的產品。
Simple is better
我們一直堅持 Linux 的一個最基本的設計哲學“Simple is better”,要儘可能的保持簡單,一個基礎設施產品只有足夠簡單才能做的足夠健壯,才能給使用者提供一個易維護的使用體驗。
3. 關鍵能力
再細化一層到 JuiceFS 產品設計的關鍵能力上,我們提出在運維上做服務化,像 S3 一樣使用,不需要使用者自己維護;能支援多雲,而非針對某一個雲或者某一種環境設計,要在公有云、私有云、混合雲的環境裡都能用;支援彈性伸縮,不需要手動擴容縮容;儘可能做到高可用、高吞吐和低時延。
前面提到 POSIX 協議以及 HDFS 和 S3 各自的標準,雖然 POSIX 是一個訪問介面上的最大集,但經過這些年的發展後,如今 Hadoop 生態中面向 HDFS 開發的元件非常之多,S3 經過十幾年的發展面向它 API 開發的應用也非常多。這三個是今天市面上最流行的訪問標準,因此最理想的情況是在一個檔案系統上能夠對外輸出三種不同標準的 API 的訪問能力,這樣已有的這些程式就都可以直接對接進來,新的應用也可以選擇更適合的訪問協議進行開發。
強一致性是檔案系統必備的能力,最終一致性是不能被接受的;還有海量小檔案的管理,這是上一代檔案系統普遍都沒有解決的問題,因為在上一代的時間點上根本不存在海量小檔案的場景,而今天我們看到在 AI 的領域裡面,管理海量小檔案逐漸變為基礎需求。比如說在自動駕駛、人臉識別、聲文分析這些場景裡面大家都在面對著十幾億,數十億甚至上百億的檔案,而又沒有一個檔案系統能夠應對這樣的規模,我們設計 JuiceFS 就要解決這個核心問題。後面還包括用透明的快取做加速,儘量保持低成本這些也都在我們的設計目標裡。
4. JuiceFS 的架構設計
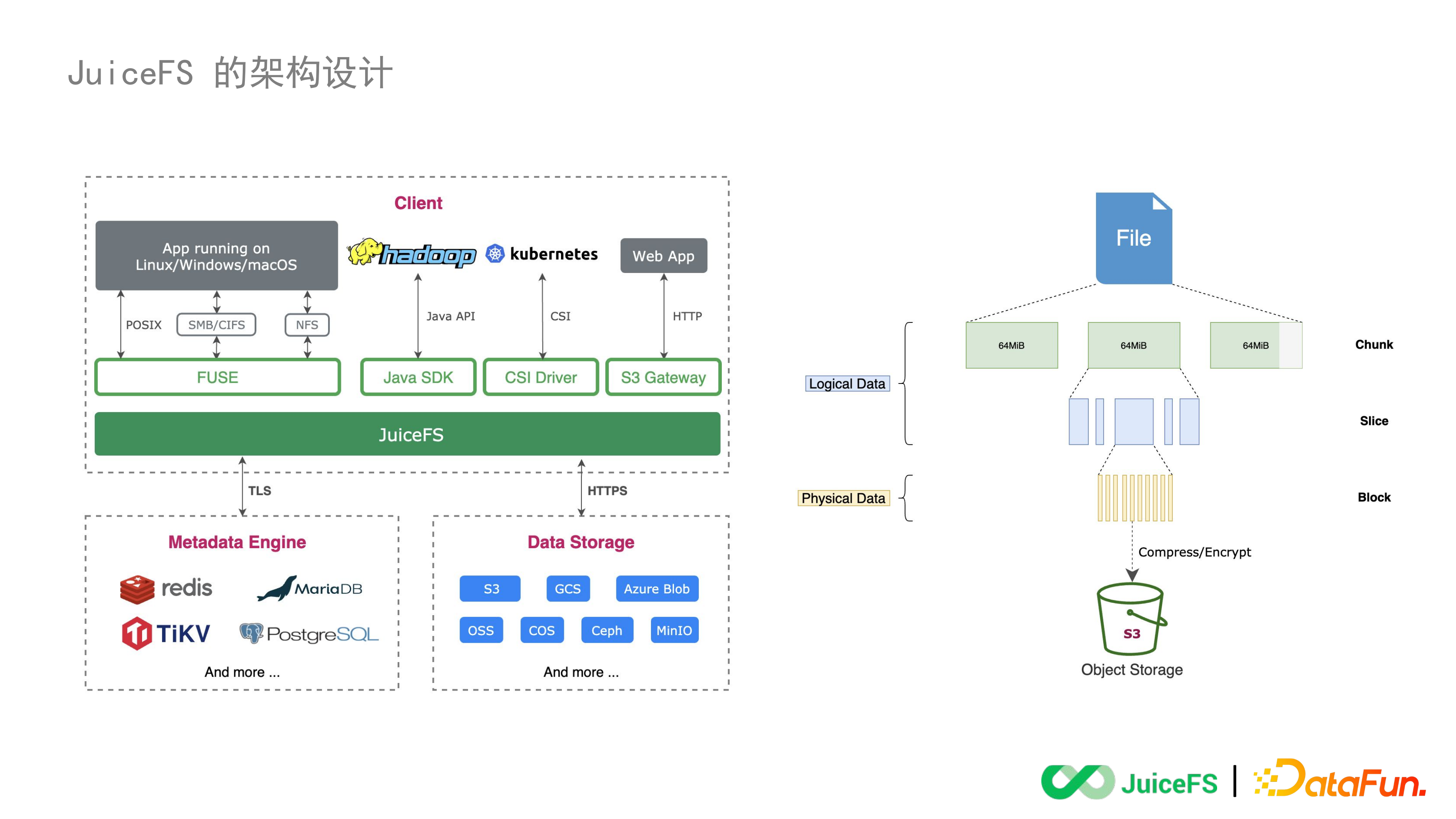
現在讓我們來看一下最終的設計,左邊是 High Level 的架構圖,右邊是資料存取的結構圖。
5. 整體架構
架構圖能體現出我們外掛式的設計,這裡有三個大的虛線框分別表示分散式檔案系統裡的三大元件:左下角的後設資料引擎,右下角的資料引擎以及上方的訪問客戶端。後設資料引擎,資料引擎和客戶端三個元件都是外掛式的設計,開發者可以結合具體應用和自己熟悉的技術棧去做選擇。
在後設資料引擎上使用者可以選擇市面上最流行的開源資料庫包括 Redis、MySQL、PostgreSQL、TiKV,最近還支援了單機的 SQLite、BadgerDB 和 Kubernetes 上大家比較熟悉的 ETCD,還包括我們目前正在自研的一個記憶體引擎,總共已經支援了 9-10 款不同的儲存引擎能夠去管理 JuiceFS 的後設資料。這樣設計一是為了降低學習成本和使用門檻,二是可以方便使用者結合具體場景對資料規模、效能、永續性、安全性的要求去做取捨。
資料引擎是用來存取資料檔案的,我們相容了市場上所有的物件儲存服務。回顧上一代的分散式檔案系統,HDFS 裡有 Datanode,CephFS 裡有 RADOS,幾乎每一個檔案系統都做了一件共同的事情就是把大量的裸機節點裡的磁碟透過一個服務管理好,包括資料內容和資料副本。當我們考慮為雲環境設計的時候就發現公有云上的物件儲存已經能把資料管理做的非常完美了,它有足夠強的擴充套件性,足夠低的成本,足夠安全的能力。所以我們在設計 JuiceFS 的時候就不再自己去做資料管理而是完全交給物件儲存來做。無論是公有云私有云還是一些開源專案提供的,我們認為它們都是高可用,安全和低成本的。
上方的虛線框代表了 JuiceFS 的客戶端,其中最底層這個是 JuiceFS 客戶端裡面的一個 Core Lib,負責與後設資料引擎和資料引擎通訊,並面向應用輸出四種不同的訪問方式:
FUSE:百分之百相容 POSIX,透過 LTP 和 pjd-fstest 測試
Java SDK:服務於 Hadoop 生態,完全相容 HDFS API
CSI Driver:在 Kubernetes 的環境裡面可以用 CSI 的方式訪問
S3 Gateway:輸出一個 S3 的 End point 去對接 S3 的 API
6. 資料儲存
右側的圖說明了我們是如何利用物件儲存做資料持久化的。類似 HDFS,一個檔案透過 JuiceFS 寫到物件儲存裡時會被切割,預設是每 4M 為一個資料塊存到物件儲存裡。這樣切割的好處是可以提高讀寫的併發度,提升效能,這是在原來的物件儲存裡很難做到的。資料切割也有助於我們實現一個機制,即寫到物件儲存中的所有資料塊只新增不修改。當需要對資料做覆蓋寫的時候,會把覆蓋寫的內容作為一個新的資料塊寫到物件儲存裡並同步更新後設資料引擎,這樣的話就可以讀到新資料但是又不用修改舊資料塊。這樣的設計既可以支援隨機寫又可以規避掉物件儲存的最終一致性問題,同時利用這個機制還可以為客戶端提供細粒度的本地快取的能力。

7. JuiceFS 的可觀測性
我們設計 JuiceFS 的時候還有一個很重要的目標就是提升使用者體驗。這裡指的使用者既包括使用檔案系統的開發者又包括維護檔案系統的運維和 SRE 同學。要做到好用好維護,我們就考慮提供在雲原生設計中經常提及的可觀測性。以往我們使用檔案系統時認為系統是快是慢更偏向於感性的判斷,很難看到非常詳細的資料。
而 JuiceFS 提供了可觀測性的能力,可以在客戶端裡開啟一個詳細的 accesslog,裡面會輸出上層應用訪問檔案系統時所有操作的細節,包括所有對後設資料的請求,所有資料訪問請求的細節以及消耗的時間。再透過一個工具將這些資訊進行彙總,就可以看到上層應用執行過程中與檔案系統這一層是如何互動的。當再遇到檔案系統慢時,就可以很容易的分析出這個慢是什麼原因造成的,是因為有太多的隨機寫,還是因為多執行緒併發之間存在阻塞。這裡我們提供了 CLI 工具,在我們公有云的雲服務上還提供了一些基於 GUI 的視覺化工具去做觀測,相信這樣的觀測能力對於上層應用的開發以及對於檔案系統本身的運維都是很有幫助的。
04 JuiceFS 的使用場景

最後來分享一下 JuiceFS 社群中使用者最常應用的一些場景。
1. Kubernetes
在 Kubernetes 裡一些有狀態的應用需要一個持久卷,這個 PV 的選擇一直是 Kubernetes 社群裡面使用者經常討論的問題。以前大家可能會選擇 CephFS,但是帶來的挑戰就是運維相對複雜,JuiceFS 希望給大家提供一個更易運維的選項。
2. AI
因為 JuiceFS 提供了多訪問協議的支援,所以在 AI 場景中很長的 Pipeline 上的各個環節都可以很方便的使用。JuiceFS 還提供了透明的快取加速能力,可以很好的支援資料清洗、訓練、推理這些環節,也支援了像 Fluid 這樣的 Kubernetes 裡面 AI 排程的框架。
3. Big Data
JuiceFS 有一個很重要的能力就是海量檔案的管理能力,JuiceFS 就是為管理數十億檔案的場景去做設計和最佳化的。在大資料場景下,因為它完全相容 HDFS API,所以老的系統無論是什麼發行版都可以很平滑的遷移進來。此外,在 Hadoop 體系外的很多MPP資料庫像 ClickHouse、Elasticsearch、TDengine 和 MatrixDB 作為新的資料查詢引擎,預設設計是為了追求更高效能的寫入,需要配備 SSD 這樣的儲存磁碟。但是經過長時間的使用後,在大資料量下就能發現這些資料是有熱資料也有溫、冷資料的,我們希望能用更低成本的去儲存溫、冷資料。JuiceFS 就支援簡單透明的儲存溫、冷資料,上層的資料庫引擎基本不需要做任何修改,可以直接透過配置檔案對接進來。
4. NAS Migration to Cloud
前面更多提到的是在網際網路行業中應用較多的場景,而很多其他領域以往的行業應用都是基於 NAS 構建的,我們看到當前的趨勢是這些行業都在向雲環境遷移,藉助雲彈性的能力,利用更大規模的分散式環境去完成他們需要的諸如資料處理、模擬、計算這些場景。這裡存在一個挑戰就是如何把原先機房裡的 NAS 遷移到雲上。無論是社群還是商業的客戶,JuiceFS 這邊都支援了從傳統的機房環境上雲這樣一個遷移 NAS 的過程,我們已經接觸過的有基因測序、藥物研究、遙感衛星,甚至像 EDA 模擬、超算這些領域,他們都已經藉助 JuiceFS 實現了將機房中的 NAS 很平滑的上雲。
來自 “ DataFunTalk ”, 原文作者:蘇銳;原文連結:http://server.it168.com/a2023/0103/6784/000006784110.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- OA協同辦公系統的發展趨勢
- 前端發展趨勢與 ViewDesign 的崛起前端View
- 線上教育的不同模式的發展趨勢模式
- “雲安全”的發展趨勢是怎樣的呢?
- 雲端計算與商業智慧的7個發展趨勢
- 雲原生 Cloud Native 在企業中的應用與發展趨勢Cloud
- 遊戲的發展趨勢遊戲
- juicefs:一個基於Redis和雲物件儲存的分散式POSIX檔案系統UIRedis物件分散式
- 遊戲的發展 雲遊戲 未來趨勢遊戲
- AR擴增實境的發展趨勢分析
- 國產作業系統生態發展趨勢作業系統
- 音訊製作的現狀與發展趨勢音訊
- 如何利用 JuiceFS 的效能工具做檔案系統分析和調優UI
- 2019前端開發的發展趨勢前端
- 大資料的發展趨勢大資料
- JuiceFS CSI Driver 的最佳實踐UI
- 雲ERP系統選擇哪家好?中小企業上雲趨勢
- 分散式儲存系統的最佳實踐:系統發展路徑分散式
- 邊緣計算與資料中心的發展趨勢
- 構建檔案館發展新趨勢:智慧檔案館三維視覺化方案視覺化
- 商場會員營銷體系的發展趨勢
- Solon Web 檔案上傳的最佳實踐Web
- 未來app開發的發展趨勢APP
- 工作流管理的發展趨勢
- 淺談web前端的發展趨勢Web前端
- 資料管理治理的發展趨勢
- 語音社交系統的亮點在哪,未來行業發展趨勢如何?行業
- 百億級小檔案儲存,JuiceFS 在自動駕駛行業的最佳實踐UI自動駕駛行業
- 檔案系統(八):Linux JFFS2檔案系統工作原理、優勢與侷限Linux
- 一文詳解雲原生應用實踐與未來趨勢
- 檔案數字化是檔案管理的未來趨勢
- AI 近期發展趨勢AI
- 阿里雲李克:邊緣雲技術發展與實踐阿里
- 網路安全發展的趨勢及措施
- Linux檔案系統的實現Linux
- 從行業發展趨勢入手,看電商直播系統未來發展重點行業
- 雲端計算是什麼?雲端計算的發展趨勢是什麼?
- 雲上大資料儲存:探究 JuiceFS 與 HDFS 的異同大資料UI