1. 常見演算法複雜度
大O加上()的形式,裡面其實包裹的是一個函式f(),O(f()),指明某個演算法的 “耗時/耗空間”與“資料增長量”之間的關係。其中的 n代表輸入資料的量。
1.1. O(1)
1. 解釋
最低複雜度,常量值。也就是 “耗時/耗空間” 與 “資料增長量” 無關,無論輸入資料增大多少倍,“耗時/耗空間” 都不變。
2. 舉例
雜湊演算法就是典型的 O(1)時間複雜度演算法,例如 HashMap、布隆過濾器等雜湊演算法的應用,無論資料規模多大,在計算出 hash key 的值之後,都可以一次性找到目標(不考慮雜湊衝突的話)。
1.2. O(n)
1. 解釋
資料量增大幾倍,耗時也增大幾倍。
2. 舉例
例如:最常見的遍歷演算法,遍歷一次所有值,找出其中的最大值。
1.3. O(n^2)
1. 解釋
對n個數排序,需要掃描 n^2次。
2. 舉例
例如:氣泡排序法、選擇排序法等。因為該演算法都是2層迴圈,第一層迴圈遍歷 n-1 趟,第二層迴圈遍歷 n-i 趟(i遞增)。
1.4. O(logn)
1. 解釋
當資料增大n倍時,耗時增大logn倍。
這裡 log 是以2為底。比如:log256=8
2. 舉例
二分查詢法就是 O(logn) 的演算法,每找一次就排除一般的可能性,256條資料中只需查詢8次就可以。
1.5. O(nlogn)
1. 解釋
當資料增大n倍時,耗時增大 n乘以logn 倍。例如當資料增大256倍,耗時增大 256*8 倍。
這個複雜度高於線性O(n),低於平方O(n^2)。
2. 舉例
歸併排序法、快速排序法的時間複雜度就是 O(nlogn)。
2. 排序演算法複雜度
網上看到這張圖:
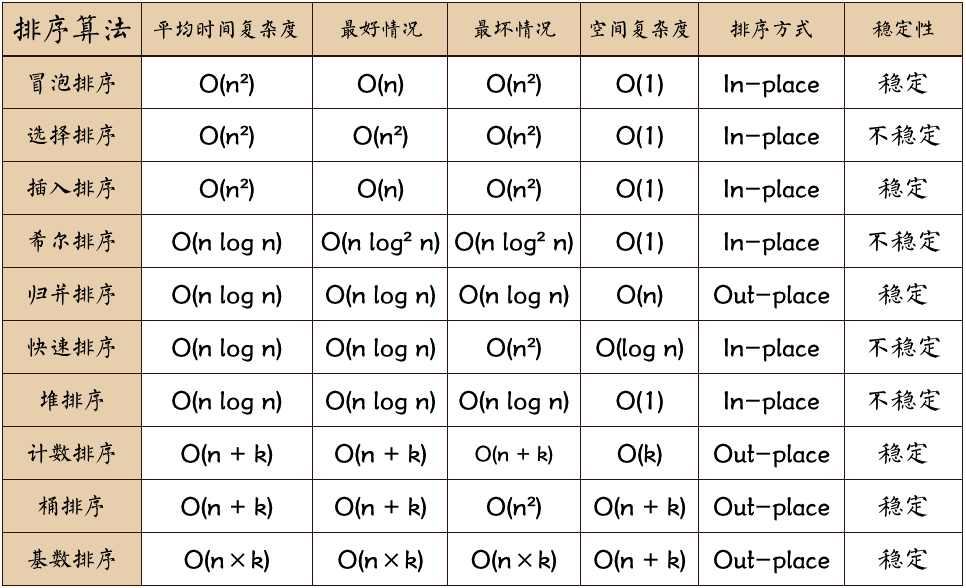
2.1. 氣泡排序為啥 O(n^2)
氣泡排序法遍歷的次數:
- 總層數:
n−1 - 每層遍歷次數:
n−i(i在 1 ~ n 遞增) - 可基於 ∑i 求和,計算出總次數:
n(n−1)/2=n^2/2 - n/2
既然是 n^2/2 - n/2,為什麼說時間複雜度是 O(n^2) 呢?因為我們常說的複雜度不是準確的值,而是當資料量膨脹時,隨之時間膨脹的模型。當 n 趨向於無限大時,n^2/2 - n/2 也就趨向於 n^2。
2.2. 快速排序為啥 O(nlogn)
1. 演算法原理
- 從待排序的n個記錄中任意選取一個記錄(通常選取第一個記錄)為分割槽標準;
- 把所有小於該排序列的記錄移動到左邊,把所有大於該排序碼的記錄移動到右邊,中間放所選記錄,稱之為第一趟排序;
- 然後對前後兩個子序列分別重複上述過程,直到所有記錄都排好序。
2. 穩定性
不穩定排序。
3. 時間複雜度
O(nlog2n)至O(n2),平均時間複雜度為O(nlgn)。
4. 最好的情況
是每趟排序結束後,每次劃分使兩個子檔案的長度大致相等,時間複雜度為O(nlog2n)。
- 總層數:
logn,因為假設每次劃分都使兩個子檔案的長度大致相等,那麼劃分logn 次後即無法繼續劃分。 - 每層遍歷次數:
n-i - 總次數:同氣泡排序法,當n趨於無限大,總次數為 nlogn
5. 最壞的情況
是待排序記錄已經排好序。
- 第一趟經過n-1次比較後第一個記錄保持位置不變,並得到一個n-1個元素的子記錄;
- 第二趟經過n-2次比較,將第二個記錄定位在原來的位置上,並得到一個包括n-2個記錄的子檔案。
依次類推,這樣總的比較次數是:Cmax=∑i=n−1(n−i)=n(n−1)/2=O(n2)
6. 複雜度總結
透過最好、最壞的情況對比,每層遍歷的次數差距不大,差距大在層數。
這裡層數的計算,實際等同於二叉樹的高度,二叉樹查詢演算法的複雜度就 O(logn),我們就拿它當二叉樹來看。
如果二叉排序樹的子樹間的高度相差太大,就會讓二叉排序樹操作的時間複雜度升級為O(n),為了避免這一情況,為最壞的情況做準備,就出現了平衡二叉樹。
總結:
- 當二叉樹趨於平衡,也就是快排的每次劃分比較均等,層數趨於 logn,快排複雜度趨於 O(nlogn)。
- 當二叉樹不夠平衡,甚至都成一條直線了,層數趨於 n,快排複雜度趨於 O(n^2)。
3. 資料結構:堆
3.1. 定義
定義
堆是使用陣列實現,基於完全二叉樹的資料結構。
完全二叉樹
- 二叉樹: 每個非葉子節點最多有兩個分支節點。
- 滿二叉樹: 每個非葉子節點都有兩個子節點。
- 完全二叉樹: 最後一層的最後一個節點的父節點不滿足滿二叉樹之外,其它非葉子節點都滿足滿二叉樹。
最小堆與最大堆
- 最大堆:是一個完全二叉樹,所有的父節點都大於或等於它的左右孩子節點。
- 最小堆:是一個完全二叉樹,所有的父節點都小於或等於它的左右孩子節點。
後一半是葉子節點
堆的前一半是非葉子節點,後一半是葉子節點。
因為葉子節點排在陣列最後,而假設某葉子節點位置為 k,對應父節點為 k/2。
3.2. 堆操作
二叉堆雖然是一個完全二叉樹,但是它的儲存方式並不是鏈式儲存,而是順序儲存,它所有的節點都儲存在陣列中。
- 它是完全二叉樹,除了樹的最後一層結點不需要是滿的,其它的每一層從左到右都是滿的,如果最後一層結點不是滿的,那麼要求左滿右不滿。
它通常用陣列來實現。並且從索引 1 開始儲存,即索引 0 直接廢棄。具體方法就是將二叉樹的結點按照層級順序放入陣列中,根結點在位置 1,它的子結點在位置 2 和 3,而子結點的子結點則分別在位置 4, 5 , 6 和 7,以此類推。
如果一個結點的位置為 k,則它的父結點(根節點沒有父結點)的位置為[k/2],而它的兩個子結點的位置則分別為2k和2k+1。這樣,在不使用指標的情況下,我們也可以透過計算陣列的索引在樹中上下移動。
- 每個結點都(大於或小於)等於它的兩個子結點。這裡要注意堆中僅僅規定了每個結點(大於或小於)等於它的兩個子結點,但這兩個子結點的順序並沒有做規定,跟二叉查詢樹是有區別的。
- 上述提到的結點需要(大於或小於)等於它的兩個子節點,是根據堆的類別來判斷的。將根節點最大的堆叫做最大堆或大根堆,結點需要大於等於它的兩個子結點;根節點最小的堆叫做最小堆或小根堆,結點需要小於等於它的兩個子結點。
1. 堆的插入
堆是用陣列完成資料元素的儲存的,我們往陣列中從索引 1 處開始,依次往後存放資料,但是堆中對元素的順序是有要求的,每一個結點的資料要(大於或小於)等於它的兩個子結點的資料,所以每次插入一個元素,都會使得堆中的資料順序變亂,這個時候我們就需要透過一些方法讓剛才插入的這個資料放入到合適的位置。
如果往堆中新插入元素,我們只需要不斷的比較新結點 a[k] 和它的父結點 a[k/2] 的大小,然後根據結果完成資料元素的交換,就可以完成堆的有序調整。這裡就設計到堆的上浮操作,等會再細談。
2. 刪除根節點
由堆的特性我們可以知道,索引1處的元素,也就是根結點。當我們把根結點的元素刪除後,堆的順序就亂了,那麼我們應該怎麼刪除呢?
思路:
- 交換根節點與最後一個元素
- 把末尾的根節點刪除
- 對新的根節點進行下沉操作,使之處於正確的位置
當需要刪除最值時,只需要將最後一個元素放到索引 1 處,並不斷的拿著當前結點 a[k] 與它的子結點 a[2k]和 a[2k+1] 中的(較大者或較小者,根據最大堆、最小堆判斷)交換位置,即可完成堆的有序調整。
3. 上浮操作
最大堆的上浮思路:
- 確定需要上浮元素的下標 k
- 當 k > 1時,比較 item[k] 與 item[k / 2] 的大小
2.1. 若 item[k] > item[k / 2],交換兩者位置,k = k / 2
2.2. 若 item[k] <= item[k / 2],上浮結束
最小堆的上浮思路:
- 確定需要上浮元素的下標 k
- 當 k > 1時,比較 item[k] 與 item[k / 2] 的大小
2.1. 若 item[k] < item[k / 2],交換兩者位置,k = k / 2
2.2. 若 item[k] >= item[k / 2],上浮結束
4. 下沉操作
最大堆的下沉思路:
- 確定需要下沉元素的下標 k
- 當 k 2 <= N (N 為堆中元素個數)時,比較 item[k] 與 max{ item[k 2],item[k 2 + 1]} 的大小,並記錄 item[k 2],item[k * 2 + 1] 較大值的下標 maxIndex
2.1. 若 item[k] < item[maxIndex],交換兩者位置,k = maxIndex
2.2. 若 item[k] >= maxIndex,下沉結束
最小堆的下沉思路:
- 確定需要下沉元素的下標 k
- 當 k 2 <= N (N 為堆中元素個數)時,比較 item[k] 與 min{ item[k 2],item[k 2 + 1]} 的大小,並記錄 item[k 2],item[k * 2 + 1] 較小值的下標 minIndex
2.1. 若 item[k] > item[maxIndex],交換兩者位置,k = minIndex
2.2. 若 item[k] <= maxIndex,下沉結束
5. 堆的構造
堆的構造,最直觀的想法就是另外再建立一個新陣列,然後從左往右遍歷原陣列,每得到一個元素後,新增到新陣列中,並透過上浮,對堆進行調整,最後新的陣列就是一個堆。
上述的方式雖然很直觀,也很簡單,但是我們可以用更聰明一點的辦法完成它。建立一個新陣列,把原陣列[0 ~ length -1]的資料複製到新陣列的 [1 ~ length]處,再從新陣列長度的一半處開始往 1 索引處掃描(從右往左),然後對掃描到的每一個元素做下沉調整即可。
6. 堆的排序
實現步驟:
- 構造堆
- 得到堆頂元素,這個值就是最大值
- 交換堆頂元素和陣列中的最後一個元素,此時所有元素中的最大元素已經放到合適的位置
- 對堆進行調整,重新讓除了最後一個元素的剩餘元素中的最大值放到堆頂
- 重複2~4這個步驟,直到堆中剩一個元素為止
對於堆的構造,上述已經談到,對構造好的堆,我們只需要做類似於堆的刪除操作,就可以完成排序。
- 將堆頂元素和堆中最後一個元素交換位置;
- 透過對堆頂元素下沉調整堆,把最大的元素放到堆頂(此時最後一個元素不參與堆的調整,因為最大的資料已經到了陣列的最右邊)
- 重複1~2步驟,直到堆中剩最後一個元素。
3.3. 優先佇列
佇列是一種先進先出(FIFO)的資料結構,但有些情況下,操作的資料可能帶有優先順序,一般出佇列時,可能需要優先順序高的元素先出佇列。
此時,資料結構應該提供兩個最基本的操作,一個是返回最高優先順序物件,一個是新增新的物件。這種資料結構就是優先順序佇列(Priority Queue)。
優先順序佇列實現了Queue介面。
JDK1.8中的 PriorityQueue底層使用了堆的資料結構。
優先佇列按照其作用不同,可以分為以下兩種:
- 最大優先佇列:可以獲取並刪除佇列中最大的值,基於最大堆實現。
- 最小優先佇列:可以獲取並刪除佇列中最小的值,基於最小堆實現。
4. 問題考察
這裡轉述一個問題:
假如有10億條資料,希望找出最大的10條,最優方案有哪些?具體時間複雜度是多少?
我們可以用 n 代替1億,k代替10,下列有三種解法作為參考。
1. 解法一:O(nlogn)
看到取最大/小數,估計很多人首先想到的,就是透過xx排序法做個排序,然後再取值。然後快速排序法相對而言複雜度最低,就由此答案。
整個過程的複雜度也就是快速排序法的複雜度:O(nlogn)。
2. 解法二:O(nk)
第一種解法最大的問題在於,雖然快速排序法對整體排序的複雜度最好,但我只需要獲取最大的10條資料,卻花費效能,對10億條資料都做了排序。
因此這就誕生了第二種解法,就使用氣泡排序法、選擇排序法等,只需要10次遍歷,就能選出最大的10條資料。
每次遍歷需要 n-i次,因為n有10億,i最大僅為10,那麼整個過程的複雜度為:O(n*10)。
3. 解法三:O(nlogk)
接下來換一種思路:
- 我們先取前10條資料維護一個集合,只找出這10條資料中的最小值。
- 然後從第11條資料開始依次遍歷,如果第i條資料大於集合內的最小值,那麼就用這第i條資料替換集合內的最小值,並且對集合內的資料重新排序。
- 當遍歷到最後一條資料,這集合內的資料就是最大的10條資料了。
接下來算一下複雜度:
- 遍歷次數:n-10,約為n。
找到集合內的最小值:
- (1)如果是直接遍歷,複雜度為 O(10);
- (2)如果我們維護最小堆,複雜度為 O(log10)。明顯最小堆複雜度更低。
- 總最小時間複雜度:O(nlog10)