
AIxiv專欄是機器之心釋出學術、技術內容的欄目。過去數年,機器之心AIxiv專欄接收報導了2000多篇內容,覆蓋全球各大高校與企業的頂級實驗室,有效促進了學術交流與傳播。如果您有優秀的工作想要分享,歡迎投稿或者聯絡報導。投稿郵箱:liyazhou@jiqizhixin.com;zhaoyunfeng@jiqizhixin.com。

在人工智慧的前沿領域,大語言模型(Large Language Models,LLMs)由於其強大的能力正吸引著全球研究者的目光。在 LLMs 的研發流程中,預訓練階段佔據著舉足輕重的地位,它不僅消耗了大量的計算資源,還蘊含著許多尚未揭示的秘密。根據 OpenAI 的研究,在 InstructGPT 的開發過程中,預訓練階段近乎耗盡了全部的算力和資料資源,佔比高達 98% [2]。
預訓練模型宛如一頭未經雕琢卻力量強大的猛獸。在經歷了漫長的預訓練階段後,模型已經建模了大量而又豐富的世界知識。藉助高質量的對話資料進行有監督微調(Supervised Fine-Tuning,SFT),我們可以使這個「野獸」理解人類的語言、適應社會的需要;而後透過基於人類反饋的強化學習(Reinforcement Learning with Human Feedback,RLHF)的進一步最佳化,使其更精準地契合使用者的個性化訴求,在價值觀上與人類「對齊」,從而能更好地服務於社會。諸如 SFT 和 RLHF 等相關對齊階段,可以視為對這頭猛獸的馴化過程。但我們的目標不止於此,更重要的是揭示賦予 LLMs 獨特能力的根本過程 —— 預訓練(The Pre-training Period)。預訓練階段猶如一個蘊藏無限可能的寶盒,亟待科研人員深入挖掘其中更為深遠的價值及運作機制。當前,多數開源的 LLMs 僅公佈模型權重與效能指標,而深入理解模型行為則需要更多詳盡資訊。LLM360 [4] 與 OLMo [5] 的全面開源,向研究者和社群提供了包括訓練資料、超參配置、預訓練過程中的多個模型權重切片以及效能評測在內的全方位深度解析,大大增強了 LLMs 訓練過程的透明度,助力我們洞悉其運作機理。人類到底能否信任 LLMs?面對這一核心問題,上海 AI Lab、中國人民大學、中國科學院大學等機構從預訓練階段入手,試圖洞察 LLMs 這個龐然大物。團隊致力於剖析 LLMs 如何在預訓練階段內構建可信的相關概念(Trustworthiness),並試圖探索預訓練階段是否具備引導和提升最終 LLMs 可信能力的潛力。
- 論文標題:Towards Tracing Trustworthiness Dynamics: Revisiting Pre-training Period of Large Language Models
- 論文連結:https://arxiv.org/abs/2402.19465
- 專案主頁:https://github.com/ChnQ/TracingLLM
- 發現 LLMs 在預訓練的早期階段就建立了有關可信概念的線性表徵,能夠區分可信與不可信的輸入;
- 發現預訓練過程中,LLMs 表現出對於可信概念類似於「資訊瓶頸」先擬合、再壓縮的學習過程;
- 基於表徵干預技術,初步驗證了 LLMs 在預訓練過程中的切片可以幫助提升最終 LLMs 的可信能力。
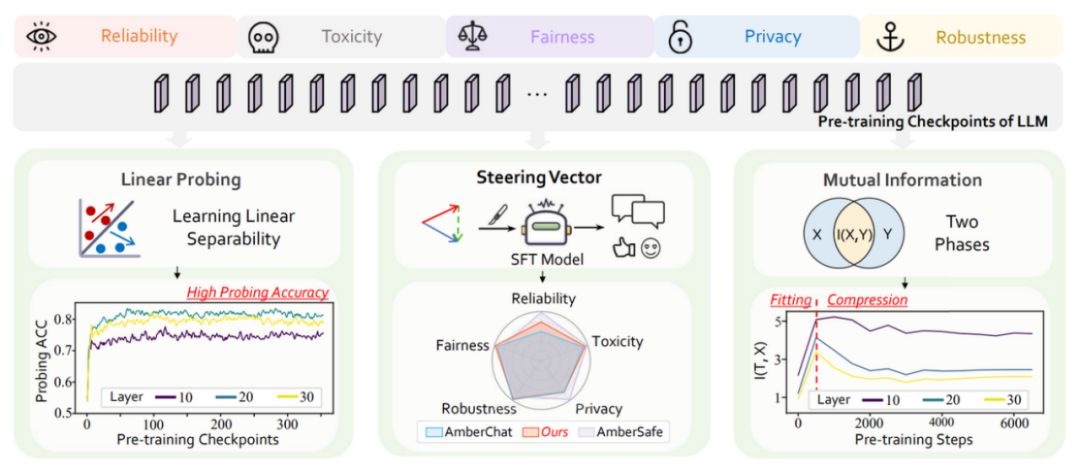
在本研究中,團隊使用了 LLM360 [4] 開源專案所提供的豐富 LLM 預訓練資源。該專案以 1.3 萬億 Tokens 的預訓練資料預訓練出其基礎的 7B 模型 Amber,並均勻地開源了 360 個預訓練過程中的模型引數切片。此外,基於 Amber,LLM360 進一步釋出了兩個微調模型:使用指令微調最佳化的 AmberChat 模型和經過安全對齊最佳化的 AmberSafe 模型。1 LLMs 在預訓練過程中迅速建立起有關可信概念的線性表徵資料集:本文主要探究可信領域下的五個關鍵維度:可靠性(reliability)、毒性(toxicity)、隱私性(privacy)、公平性(fairness)和魯棒性(robustness)。每個維度下,團隊均選取了具有代表性的相關資料集來輔佐研究:TruthfulQA、Toxicity、ConfAIde、StereoSet 以及經過特定擾動處理的 SST-2。團隊根據原資料集的設定,對每個樣本進行標註,以標識每個輸入樣本是否包含不正確、有毒、隱私洩露、有歧視和被擾動的資訊。實驗設定:本文采用線性探針(Linear Probing)技術 [6] 來量化 LLMs 內部表徵對可信概念的建模情況。具體地,對於某個可信維度下的資料集,團隊收集所有切片在該資料集下的內部表徵,對於每個切片的每一層表徵都訓練一個線性分類器,線性分類器在測試集上的正確率代表著模型內部表徵區分不同可信概念的能力。前 80 個切片的實驗結果如下(後續完整切片的實驗結果請移步正文附錄,實驗趨勢大體相同):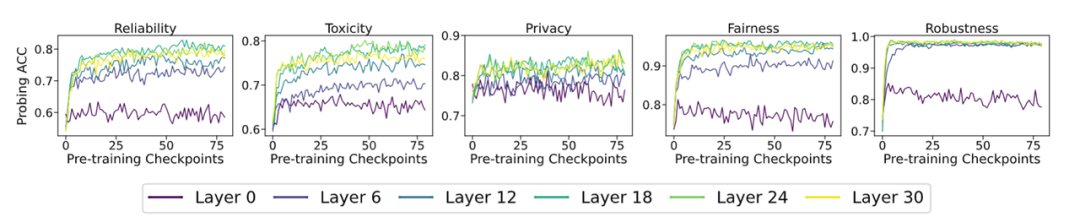
- 隨著預訓練的進行,在所選取的五個可信維度上,大模型中間層的表徵可以很好地區分是否可信;
- 對於區分某個樣本是否可信,大模型在預訓練的早期階段(前 20 個切片)就迅速學習到相關概念。
2 資訊瓶頸視角下審視 LLMs 有關可信概念的預訓練動態受到利用互資訊來探測模型在訓練過程中動態變化的啟發 [7],本文也利用互資訊對 LLMs 表徵在預訓練過程中的動態變化做了初步探索。團隊借鑑了 [7] 中使用資訊平面分析傳統神經網路訓練過程的方法,分別探究了模型表徵 T 與五個原始資料集 X 之間的互資訊,以及模型表徵 T 與資料集標籤 Y 之間的互資訊。其中,在 Reliability 維度上的實驗結果如下(其他可信維度的實驗結果請移步原文附錄):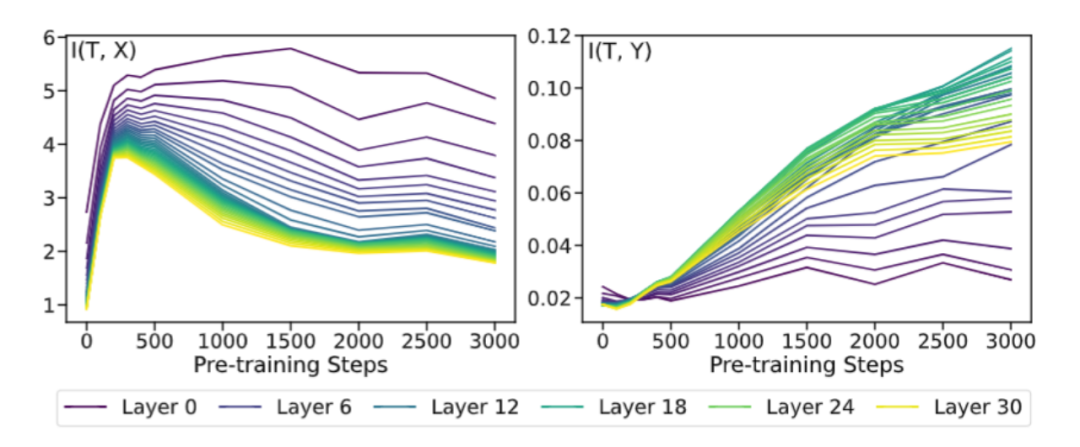
從圖中可以看出,T 與 X 的互資訊呈現出先上升後下降的趨勢,而 T 與 Y 的互資訊則持續上升。綜合來看,團隊發現這些趨勢與經典論文 [7] 中描述的先「擬合」 (fitting) 後「壓縮」 (compression) 兩個階段相吻合。具體來說,大語言模型在初始隨機化時並不具備保留資訊的能力,因此互資訊接近於 0;隨著預訓練的進行,大模型逐漸具備語言理解和概念建模的能力,因此互資訊持續增長;隨著預訓練的進一步進行,大模型逐漸學會壓縮無關資訊並提取有效資訊,因此 T 和 X 的互資訊減少,而 T 和 Y 的互資訊繼續增長。從互資訊的角度,這是一個很有趣的發現。儘管定義和實驗設定存在細微的差異,但大語言模型和傳統神經網路的預訓練階段都能被劃分為「擬合」和「壓縮」兩個階段。這暗示著大語言模型和傳統神經網路的訓練過程中可能存在一些共通之處。這一發現不僅豐富了團隊對大模型預訓練動態的理解,也為未來的研究提供了新的視角和思路。3 預訓練切片如何助力最終 LLMs 可信能力提升團隊觀察到,既然 LLMs 在其預訓練的早期階段就已經學習到了有關可信概念線性可分的表徵,那麼一個很自然的問題是:LLMs 在預訓練過程中的切片能不能幫助最終的指令微調模型(SFT model)進行對齊呢?團隊基於表徵干預的技術(Activation Intervention),給予該問題初步的肯定回答。表徵干預(Activation Intervention)是 LLMs 領域中一個正在快速興起的技術,已被多個場景下驗證有效 [8-9]。這裡以如何減輕 LLMs 的幻覺問題,讓其回答變得更「真實」為例 [8],簡要闡述表徵干預技術的基本流程:1. 首先,分別使用涵蓋真實與虛假資訊的正負文字來刺激 LLMs 並收集其對應的內部表徵;2. 然後,對正負表徵的質心作差獲得「指向真實方向的引導向量(Steering Vector)」;3. 最後,在 LLMs 前向推理時每一步產生的表徵上加上該引導向量,達到干預輸出的目的。不同於上述方法從待干預模型自身抽取引導向量,團隊意在從 LLMs 預訓練過程的切片中構建引導向量來干預指令微調模型,如下圖所示。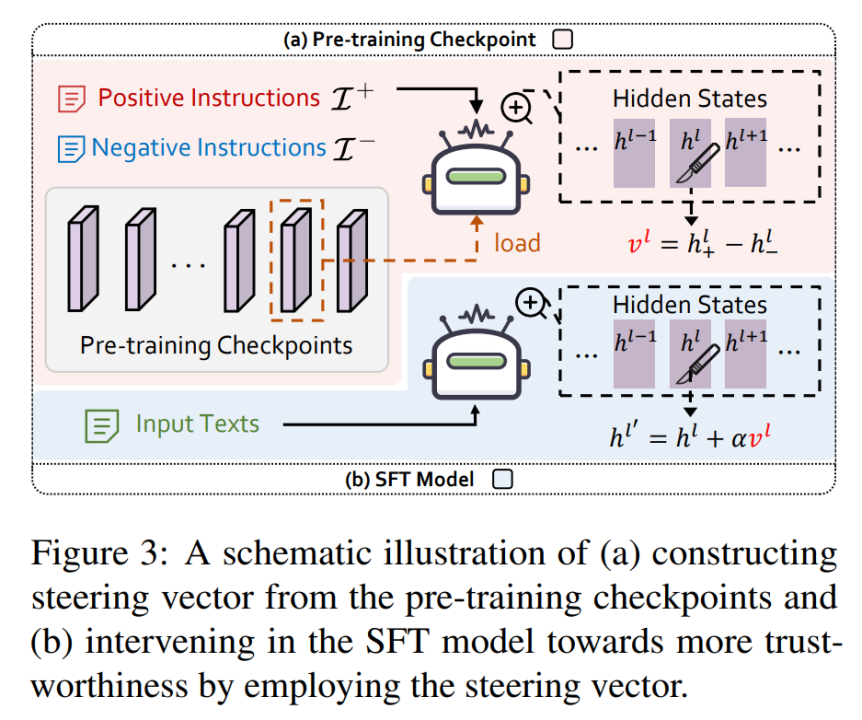
其中,團隊使用北京大學團隊開源的 PKU-RLHF-10K 資料集 [10-11] 來構建正負文字對,該資料集包含一萬條帶有安全 / 非安全回覆標註的對話資料,可用於 LLMs 的 RLHF 訓練。論文在上文提及的可信領域下五個維度的資料集(Reliability: TruthfulQA,Toxicity: Toxigen,Fairness: StereoSet,Privacy: ConfAIde,Robustness: SST-2),以及四個常用的大模型通用能力評測資料集(MMLU,ARC,RACE,MathQA)上,評測了四個模型的效能:指令微調模型 AmberChat,安全對齊模型 AmberSafe,使用來自 AmberChat 自身的引導向量干預後的 AmberChat,使用來自中間預訓練切片的引導向量干預後的 AmberChat。實驗結果如下圖所示(更多的實驗觀察結果請移步原文):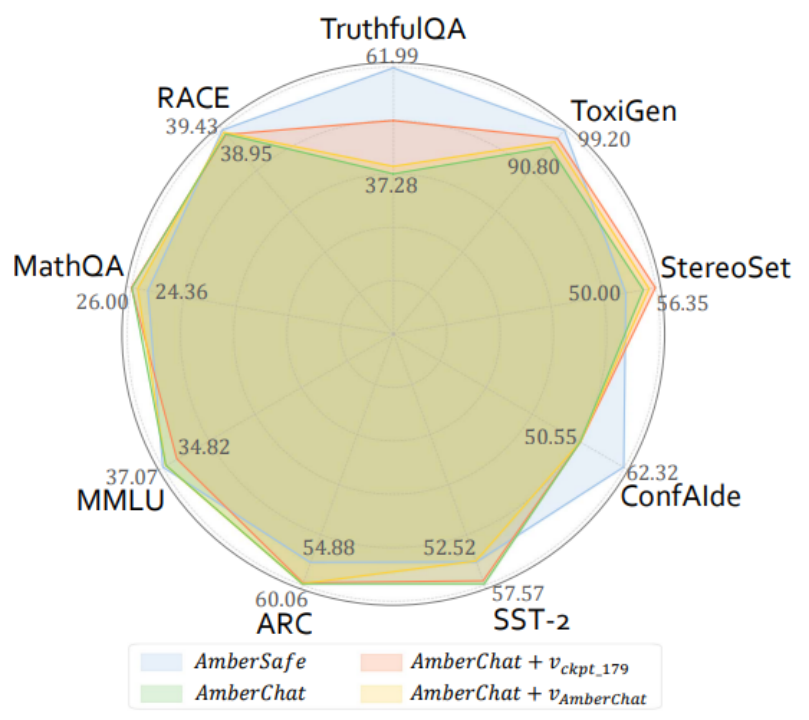
實驗結果表明,在使用來自預訓練切片的引導向量干預 AmberChat 後,AmberChat 在三個可信維度(TruthfulQA,Toxigen,StereoSet)上都有較明顯的提升。同時,這種干預對模型通用能力的影響並不顯著(在 ARC,MMLU 上表現出邊際損失,在 MathQA 和 RACE 上表現出邊際提升)。令人驚訝的是,使用預訓練的中間切片構建的引導向量,相比於來自 AmberChat 自身的引導向量,能更顯著地提升 AmberChat 模型的可信效能。隨著人工智慧技術的不斷進步,未來,當試圖對齊比人類更強大的模型(Superalignment)時,傳統的依賴「人類反饋」的微調技術,如 RLHF 等,或將不再奏效 [12-13]。為了應對這一挑戰,研究機構正在積極探索新的解決方案。例如,OpenAI 提出了「弱對強監督」的方法 [12],Meta 提出了「自我獎勵」機制 [13]。同時,越來越多的研究開始關注「自我對齊」(self-alignment)這一新興領域 [14-15] 。該研究為解決 Superalignment 問題提供了新的視角:利用 LLMs 在預訓練過程中的切片來輔助最終的模型對齊。團隊首先探究了預訓練過程中 LLMs 是如何構建和理解「可信」這一概念的:1)觀察到 LLMs 在預訓練的早期階段就已經建模了關於可信概念的線性表徵;2)發現 LLMs 在學習可信概念的過程中呈現出的類資訊瓶頸的現象。此外,透過應用表徵干預技術,團隊初步驗證了預訓練過程中的切片對於輔助最終 LLMs 對齊的有效性。團隊表示,期望本研究能夠為深入理解 LLMs 如何動態構建和發展其內在的可信屬性提供新的視角,並激發未來在 LLMs 對齊技術領域的更多創新嘗試。同時期待這些研究成果能有助於推動 LLMs 向著更可信、更可控的方向發展,為人工智慧倫理與安全領域貢獻堅實的一步。[1] https://karpathy.ai/stateofgpt.pdf[2] https://openai.com/research/instruction-following[3] twitter.com/anthrupad[4] Liu, Z., Qiao, A., Neiswanger, W., Wang, H., Tan, B., Tao, T., ... & Xing, E. P. (2023). Llm360: Towards fully transparent open-source llms. arXiv preprint arXiv:2312.06550.[5] Groeneveld, D., Beltagy, I., Walsh, P., Bhagia, A., Kinney, R., Tafjord, O., ... & Hajishirzi, H. (2024). OLMo: Accelerating the Science of Language Models. arXiv preprint arXiv:2402.00838.[6] Belinkov, Y. (2022). Probing classifiers: Promises, shortcomings, and advances. Computational Linguistics, 48 (1), 207-219.[7] Shwartz-Ziv, R., & Tishby, N. (2017). Opening the black box of deep neural networks via information. arXiv preprint arXiv:1703.00810.[8] Li, K., Patel, O., Viégas, F., Pfister, H., & Wattenberg, M. (2024). Inference-time intervention: Eliciting truthful answers from a language model. Advances in Neural Information Processing Systems, 36.[9] Turner, A., Thiergart, L., Udell, D., Leech, G., Mini, U., & MacDiarmid, M. (2023). Activation addition: Steering language models without optimization. arXiv preprint arXiv:2308.10248.[10] Ji, J., Liu, M., Dai, J., Pan, X., Zhang, C., Bian, C., ... & Yang, Y. (2024). Beavertails: Towards improved safety alignment of llm via a human-preference dataset. Advances in Neural Information Processing Systems, 36.[11] https://huggingface.co/datasets/PKU-Alignment/PKU-SafeRLHF-10K[12] Burns, C., Izmailov, P., Kirchner, J. H., Baker, B., Gao, L., Aschenbrenner, L., ... & Wu, J. (2023). Weak-to-strong generalization: Eliciting strong capabilities with weak supervision. arXiv preprint arXiv:2312.09390.[13] Yuan, W., Pang, R. Y., Cho, K., Sukhbaatar, S., Xu, J., & Weston, J. (2024). Self-rewarding language models. arXiv preprint arXiv:2401.10020.[14] Sun, Z., Shen, Y., Zhou, Q., Zhang, H., Chen, Z., Cox, D., ... & Gan, C. (2024). Principle-driven self-alignment of language models from scratch with minimal human supervision. Advances in Neural Information Processing Systems, 36.[15] Li, X., Yu, P., Zhou, C., Schick, T., Levy, O., Zettlemoyer, L., ... & Lewis, M. (2023, October). Self-Alignment with Instruction Backtranslation. In The Twelfth International Conference on Learning Representations.