故障自愈出場後,運維就能歇歇了吧……
一、背景
最近晚上23:00甚至是凌晨總收到告警通知:磁碟可用量低於20%,這個時候不得不爬起來處理告警。當然這裡要提醒大家:對於小問題,運維也絕不要抱著僥倖的心理,因為只有痛過才知道。
磁碟類告警只是我們諸多告警中的冰山一角,雖然我們有值班人員甚至是運維團隊支撐,但是也不能因為這種小問題就分散注意力,這時我們就需要考慮如何透過自動化實現。
針對這種情況,我們通常會想到以下幾點:
在告警機器上設定定時任務
編寫指令碼壓縮日誌或清理磁碟空間
這種方案雖然可行,但是試想下:如果我們管理的是上千臺機器且目錄結構混亂,那麼我們面臨的將是上千個指令碼及定時任務,這個工作量是非常大的。
運維累都是有原因的,此時就可以輪到故障自愈出場了。
二、故障自愈
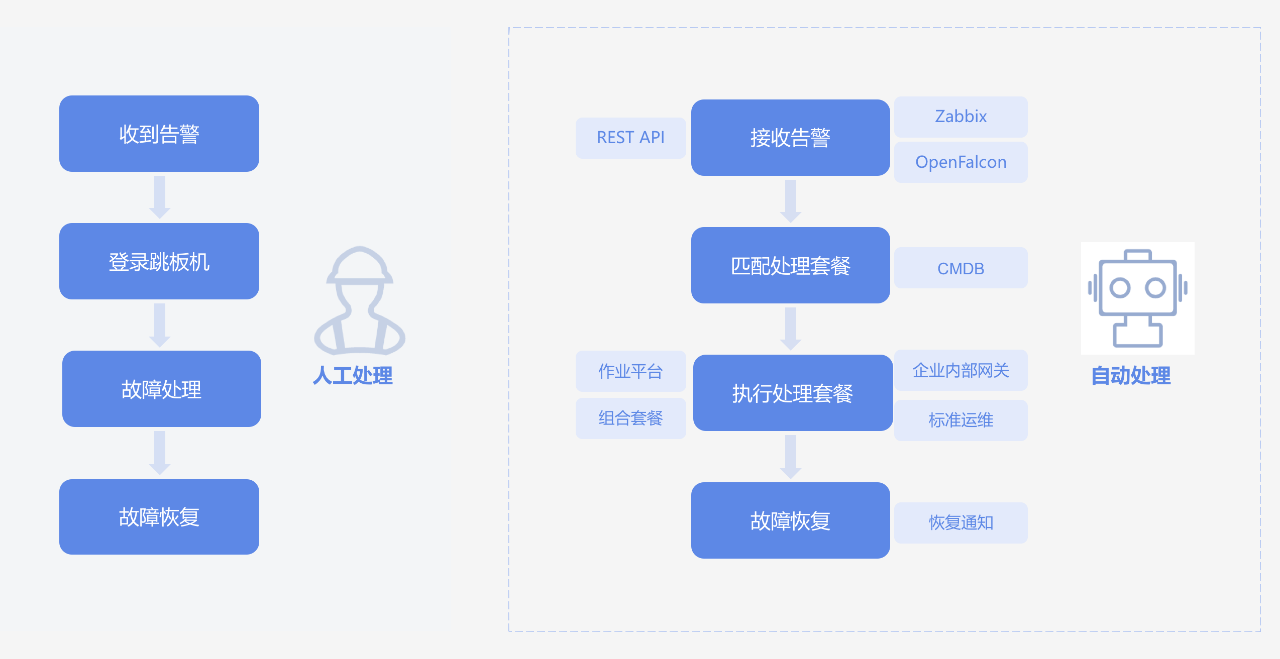
如圖所示,對於生產故障,運維標準的處理流程是收到告警、登入跳板機、故障處理、故障恢復,整個過程都是透過人工手動處理。而故障自愈則是接受監控平臺的告警定位,匹配預設的故障處理流程,進而透過自動化手段實現故障的自動恢復。
在認識故障自愈後,我們需要考慮的就是如何讓運維管理的生產環境更廣泛地接入故障自愈,而不是隻針對單一的機器或某一類故障。因此在正式接入故障自愈前,我們還有很多的工作要做。
三、前提
為滿足故障自愈透過自動化手段處理故障,我們必須提前制定一系列的流程規範:
1)目錄管理規範
標準的目錄結構,接入故障自愈後可以用一套自動化指令碼管理所有檔案資源。
2)應用標準規範
標準應用規範,接入故障自愈後可以用一套自動化指令碼管理所有應用。
3)監控告警規範
標準的監控告警規範,透過告警通知,無論是運維團隊或自愈平臺,都能透過告警通知更快速的定位問題。
4)標準的故障處理流程
標準的故障處理流程,不僅可以幫助我們更快速地解決問題,而且可以幫助我們建立起運維團隊的知識庫。
這些流程規範不僅是故障自愈,也是我們日常運維工作過程中需要持續關注的,這也意味著這些基礎性的工作是多麼的重要。
四、監控平臺
監控平臺作為整個故障自愈的源頭,必須滿足快速準確定位故障的要求,因此就需要在多個維度提供可靠的監控。
1)硬體監控維度
此類監控故障自愈一般無法接入,僅作為輔助手段幫我們及時發現問題。
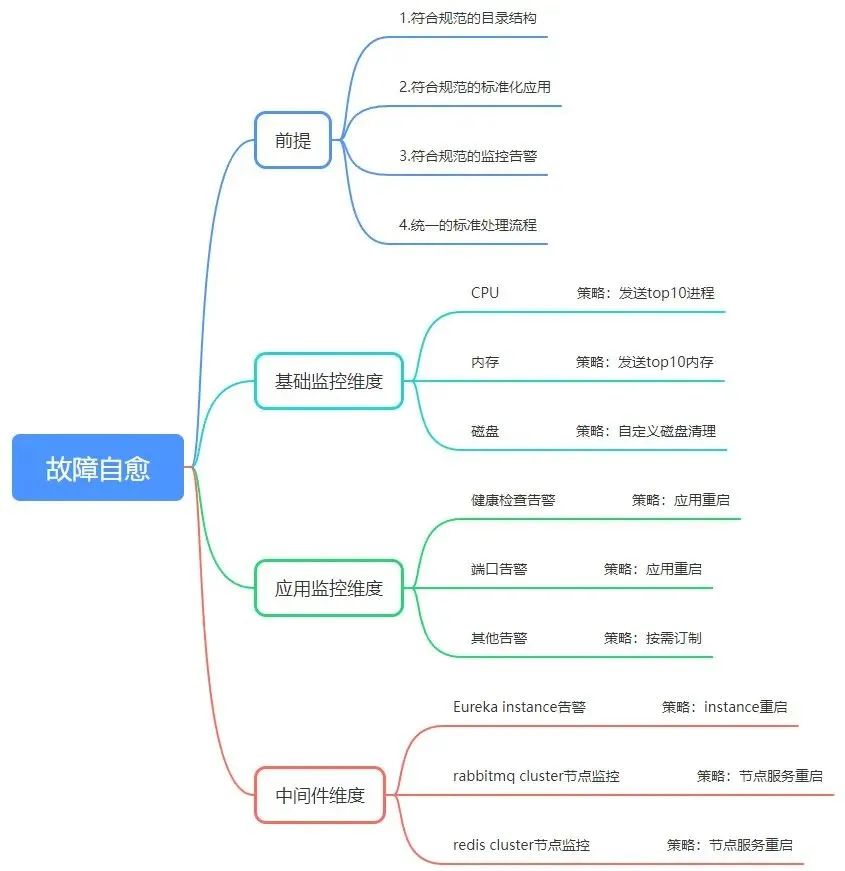
2)基礎監控維度
基礎監控主要是對CPU、記憶體、磁碟等資源使用情況進行監控,接入故障自愈後可傳送佔用資源的前10程式及自定義的磁碟清理策略。
3)應用監控維度
應用監控主要是對應用狀態進行監控,如健康檢查、埠、其他自定義告警,接入故障自愈後可對應用進行重啟。
4)中介軟體維度
中介軟體維度主要是對叢集的健康狀態進行監控,如eureka instance、rabbitmq叢集各節點服務、redis叢集各節點服務等,接入故障自愈後可對各節點的服務進行處理。
當然根據監控平臺的維度和粒度,我們可以將更多的故障場景接入故障自愈,這個隨著我們運維經驗的增多會不斷豐富。
五、故障自愈平臺
1、多告警源
故障自愈的源頭是監控平臺,因此我們希望故障自愈平臺不能是隻針對某一特定的監控平臺,因此它一定是多源的,這也符合當今監控工具的發展趨勢。新的業務、系統和場景會催生新的監控需求,企業未來監控一定是多種監控產品並存,構建功能可持續成長的監控平臺才能適應滿足運維監控需求。
當今主流的監控工具如下:
Zabbix
Nagios
Open Falcon
Prometheus
等等
當然除了滿足與監控工具對接,還要兼具REST API等方式接入。
2、統一資料來源
試想一個場景,透過監控平臺傳送的告警通知,我們可以快速定位到業務、應用、IP,那麼故障自愈平臺如何接入這些資源呢?因此我們就需要一個統一的資料來源,為監控平臺、故障自愈平臺等上層應用提供可靠的權威資料來源,此時CMDB就可以擔任如此重要的角色。
在 ITIL 體系裡,CMDB 是構建其它流程的基石,為應用提供了各種運維場景的配置資料服務。它是企業 IT 管理體系的核心,透過提供配置管理服務,以資料和模型相結合對映應用間的關係,保證資料的準確和一致性;並以整合的思路推進,最終面向應用消費,發揮配置服務的價值。
CMDB的建設是一個非常痛苦的過程,雖然我們是站在巨人的肩膀上直接使用其能力進行納管資源,但其實也是走了很多彎路的:
運維團隊內部的認可
按部門、角色對基礎設施的職責劃分
CMDB的管理規範
CMDB如何按組織架構對環境、部門、業務、應用等情況劃分
如何更合適的納管物理機、虛擬機器、網路裝置、資料庫、中介軟體等資源
CMDB如何為架構提供資料支撐
以上這些問題也只是在使用推廣階段我們所遇到的,因此在很多情況下CMDB都從萬眾期待走向了置之不理,但“撥開雲霧見天日,守得雲開見月明”,隨著我們不遺餘力的嘗試與調整,CMDB 最終還是扛下了所有,發揮了它真正的價值。
3、故障處理
有了統一的資料來源,剩下的操作就是如何進行故障處理了,此時就需求故障自愈平臺能夠遠端執行指令碼。在日常運維工作中,我們一般透過以下幾種方式:
Ansible、SaltStack等自動化運維工具
中控機透過ssh遠端執行命令
以上是我們通常使用的手段,但是還有更高階或更優雅的方式供我們參考:
整合CMDB的統一作業平臺
Jenkins流水線引數化構建
當然了,“不管黑貓白貓,能捉老鼠的就是好貓”,只要是適合當下運維能力的任何方式都可以。不要一味地追求高大上,給我們帶來其他額外的工作負擔。
4、結果通知
無論最終的故障處理是否成功,我們都需要知道結果來決定是否要人工干預,因此我們希望處理結果能夠對接多種渠道通知,如:
郵件通知
微信通知
釘釘通知
簡訊通知
電話通知
等等
六、總結
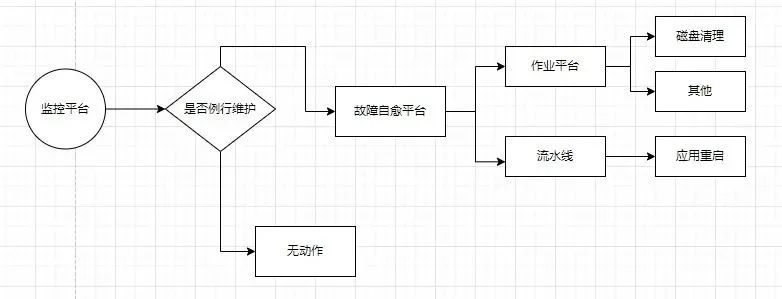
從上圖我們可以看到,故障自愈雖然可以幫助我們解決很多問題,但其也只是問題處理過程中的一個環節,例如例行維護期間我們需要做到不觸發故障自愈,否則還可能引起一些不必要的問題。因此,故障自愈還需和其他元件做好密切的對接,這就透過運維管理人員進行排程了。
最後需要明確的是,故障自愈只是運維過程中的一種手段而已,如何將其更廣泛的應用還需運維本身去腳踏實地地去實踐摸索。
來自 “ 木訥大叔愛運維 ”, 原文作者:三頁;原文連結:http://server.it168.com/a2022/1108/6773/000006773238.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 運維累了:該故障自愈出場了運維
- 透過運維編排實現自動化智慧運維與故障自愈運維
- 透過視覺化運維配置,實現故障秒級自愈視覺化運維
- 透過自動化運維實現無人值守的故障自愈運維
- 醫院運維 告警閃現後的故障排查運維
- 阿里如何做到百萬量級硬體故障自愈?阿里
- Oracle RAC日常運維-DATA磁碟組故障Oracle運維
- 掌握運維必備技能--問題故障定位運維
- Spring Boot 2.7.0釋出,2.5停止維護,節奏太快了吧Spring Boot
- 做運維前 vs 做運維後,太形象了!運維
- MongoDB日常運維-05副本集故障切換MongoDB運維
- Oracle RAC日常運維-NetworkManager導致叢集故障Oracle運維
- 資料中心運維:減少折騰就是降低故障運維
- 反思一次Exchange伺服器運維故障薦伺服器運維
- 線上故障的排查清單,運維拿走不謝!運維
- 阿里雲釋出ECS運維體系,提供原生運維能力阿里運維
- 如何運用結構化思維進行故障處理
- rabbitmq 原理、叢集、基本運維操作、常見故障處理MQ運維
- 什麼是自愈路由?自愈路由自愈網路有什麼好處路由
- 運維不是修電腦!月薪30K的高階運維告訴你,學會這些就能逆襲運維
- 故障自愈是不是應該儘可能讓資料庫自己來做資料庫
- 前端、後端、運維的基本思考前端後端運維
- 阿里:千億交易背後的0故障釋出阿里
- 夜鶯監控 V7 第二個 beta 版本釋出,內建整合故障自愈能力,簡化部署
- 京東科技全鏈路故障診斷智慧運維實踐運維
- 銳捷釋出智慧運維平臺,讓IT運維“樂享其成”運維
- 學習Linux運維後的薪水如何?Linux運維
- 運維場景下的兩個自我運維
- 運維中的“後見之明”現象運維
- 供水泵站組態監控與故障運維一體化系統運維
- 快準穩:值得所有運維學習的SRE故障處理經驗運維
- 從“悲劇”的幾個運維場景談談運維開發的痛點運維
- IT運維之自動化運維運維
- 運維必讀:避免故障、拒絕背鍋的六大原則!運維
- 入門運維必知必會的系統故障排查和修復技巧運維
- 裝置故障監控報警運維工單系統有什麼功能運維
- ECCV 2024 | 像ChatGPT一樣,聊聊天就能實現三維場景編輯ChatGPT
- 學習Linux運維後應該如何找工作?Linux運維