貪心演算法有時也很有用 - hashnode
貪心演算法是解決許多問題的有力武器不幸的是,它們並非總是可行的方法,因為它們可能導致錯誤的解決方案,它們何時起作用?什麼時候是最糟糕的選擇?他們什麼時候能得出可接受的解決方案?
貪心演算法嘗試透過在每個步驟中採取最佳選擇來找到最佳解決方案。您隨時可以走一條最大化利己的幸福道路。但這並不意味著您明天會更快樂。
同樣,也存在貪心演算法無法提供最佳解決方案的問題。實際上,它們可能會給出最糟糕的解決方案。但是在其他情況下,我們可以透過使用貪心策略來獲得足夠好的解決方案。
在本文中,即使無法保證找到最佳解決方案,我也會寫一些貪心演算法及其使用方法。
貪心演算法
貪心演算法始終選擇最佳的可用選項。通常,它們在計算上比其他演算法系列(如動態程式設計或蠻力)便宜。那是因為他們沒有過多地探索解決方案空間。而且,出於同樣的原因,他們沒有找到解決許多問題的最佳解決方案。
但是,貪心策略可以解決許多問題,而該策略正是最好的解決方法。
Dijkstra演算法是最流行的貪心演算法之一,該演算法以最小的代價找到圖中從一個頂點到另一個頂點的路徑。該演算法透過始終轉到最近的頂點來找到這樣的路徑。這就是為什麼我們說這是一個貪心的演算法。
這是演算法的虛擬碼。我用G圖和s源節點表示。
Dijkstra(G, s): distances <- list of length equal to the number of nodes of the graph, initially it has all its elements equal to infinite distances[s] = 0 queue = the set of vertices of G while queue is not empty: u <- vertex in queue with min distances[u] remove u from queue for each neighbor v of u: temp = distances[u] + value(u,v) if temp < distances[v]: distances[v] = temp return distances |
執行先前的演算法後,我們得到一個列表distances,該列表distances是從節點s到節點的最低開銷u。
僅當圖形的邊沒有負成本時,才能保證該演算法有效。邊緣中的負成本會使貪心的策略選擇一條非最佳路徑。
用來介紹貪心策略概念的另一個示例是Fractional Knapsack揹包。
在這個問題上,我們有一些專案。每個專案的權重Wi大於零,利潤Pi也大於零。我們有一個容量W可觀的揹包,我們希望以最大的利潤來填充它。當然,我們不能超過揹包的容量。
在揹包問題的分數形式中,我們可以取整個物件,也可以取一部分。當取0 <= X <= 1第i個物件的一小部分時,我們獲得的利潤等於X*Pi並且需要新增X*Wi到購物袋中。我們可以透過使用貪心策略來解決此問題。我不會在這裡討論解決方案。如果您不知道,建議您嘗試自己解決,然後線上尋找解決方案。
貪心的時候最糟糕
在上一節中,我們看到了使用貪心策略可以解決的兩個問題示例。這很棒,因為它們是非常快的演算法。
但是,正如我所說,Dijkstra的演算法不適用於帶有負邊的圖形。而且問題甚至更大。我總是可以用Dijkstra的解決方案達到我想要的效果來構建帶有負邊緣的圖形!考慮以下示例,該示例是從Stackoverflow提取的
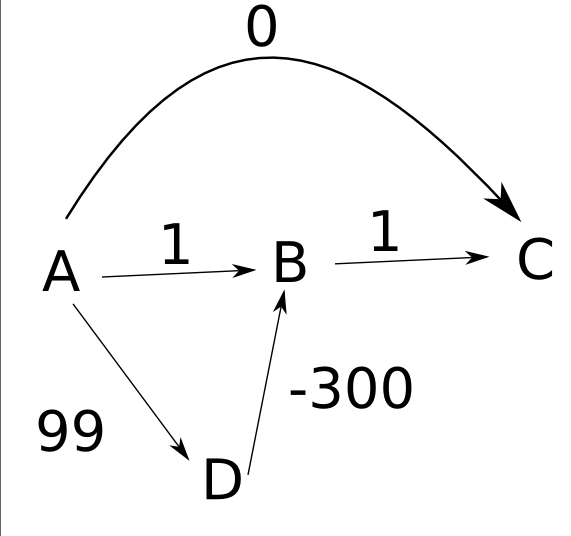
Dijkstra演算法未能找到之間的距離A和C。查詢d(A, C) = 0何時應為-200。並且,如果減小edge的值D -> B,我們將獲得一個距離實際最小距離甚至更遠的距離。
類似地,當我們無法在揹包問題(0-1揹包問題)中破壞物件時,使用貪心策略獲得的解決方案可能會像我們想要的那樣糟糕。我們總是可以為使貪婪演算法嚴重失敗的問題建立輸入。
另一個例子是旅行者問題(TSP)。給定一個城市列表以及每對城市之間的距離,最精確的路線是什麼?
我們可以總是去最近的城市來貪心地解決問題。我們選擇任何一個城市作為第一個城市並應用該策略。
正如前面的示例中所發生的那樣,我們總是可以透過貪心策略找到最糟糕的解決方案的方式來構建城市。
在本節中,我們看到了貪心的策略可能導致我們陷入災難。但是存在一些問題,其中這種方法可以很好地逼近最佳解決方案。
貪心的時候還不錯
我們已經看到,貪心策略對於某些問題來說是我們想要的那樣糟糕。這意味著我們不能用它來獲得最優解,甚至不能很好地近似它。
但是,在某些示例中,貪心演算法為我們提供了很好的近似值!在這些情況下,貪心方法非常有用,因為它往往更便宜且更易於實現。
圖的頂點覆蓋是最小的一組頂點,以使圖的每個邊緣在該集中具有至少一個端點。
這是一個非常困難的問題。實際上,沒有任何有效且精確的解決方案。但是,好訊息是我們可以使用貪心演算法進行近似。
我們<u, v>從圖中選擇任何邊,然後將u和新增v到集合中。然後,我們刪除所有具有u或v作為端點之一的邊,並在其餘圖具有邊的同時重複上一過程。
這可能是先前演算法的虛擬碼。
vertexCover(G):
VertexCover <- {} // empty set
E' <- edges of G
while E' is not empty:
VertexCover <- VertexCover U {u,v} where <u,v> is in E'
E' = E' - {<u, v> U edges incident to u, v}
return VertexCover
|
如您所見,這是一個簡單且相對較快的演算法。但是最好的部分是解決方案將始終小於或等於最佳解決方案的兩倍!無論輸入圖的構建方式如何,我們都永遠不會獲得大於較小頂點覆蓋範圍兩倍的集合。
我不會包括在這個帖子這句話的示範,但你可以注意到,每邊證明這一點<u, v>,我們新增到頂點覆蓋,無論是u或者v是最佳的解決方案(即在較小的頂點覆蓋) 。
許多電腦科學家正在努力尋找更多這些近似值。還有更多示例,但我將在這裡停止。這是電腦科學和應用數學領域一個有趣而活躍的研究領域。透過這些近似值,我們可以透過實施非常簡單的演算法來為非常棘手的問題提供非常好的解決方案。
相關文章
- 貪心演算法演算法
- 貪心演算法(貪婪演算法,greedy algorithm)演算法Go
- 貪心演算法Dijkstra演算法
- 學一下貪心演算法-學一下貪心演算法演算法
- Moving Tables(貪心演算法)演算法
- 9-貪心演算法演算法
- 常用演算法之貪心演算法演算法
- 演算法基礎–貪心策略演算法
- 貪心演算法——換酒問題演算法
- 「演算法」貪心與隨機化演算法隨機
- 貪心
- 【LeetCode】貪心演算法–分發糖果(135)LeetCode演算法
- dfs與貪心演算法——洛谷5194演算法
- 貪心演算法篇——區間問題演算法
- 加油站問題(貪心演算法)演算法
- 演算法---貪心演算法和動態規劃演算法動態規劃
- 資料結構與演算法——貪心演算法資料結構演算法
- 反悔貪心
- Supermarket(貪心)
- 《演算法筆記》9. 培養貪心思維、貪心演算法深度實踐演算法筆記
- 貪心演算法之無重疊區間演算法
- leedcode-分發餅乾(貪心演算法)演算法
- Day28 貪心演算法part2演算法
- Day27 貪心演算法part1演算法
- Day31 貪心演算法part5演算法
- LeetCode解題記錄(貪心演算法)(二)LeetCode演算法
- LeetCode解題記錄(貪心演算法)(一)LeetCode演算法
- 貪心例題
- 貪心+搜尋
- leetcode:跳躍遊戲II(java貪心演算法)LeetCode遊戲Java演算法
- KuonjiCat的演算法學習筆記:反悔貪心演算法筆記
- 貪心演算法-找不重疊的區間段演算法
- 活動選擇問題理解貪心演算法演算法
- 汽車加油問題 SDUT OJ 貪心演算法演算法
- 貪心演算法——Huffman 壓縮編碼的實現演算法
- 貪心演算法與動態規劃的區別演算法動態規劃
- 使用貪心演算法解決集合覆蓋問題演算法
- HDU 5821 Ball(貪心)