Kafka 依賴 Zookeeper 來維護叢集成員的資訊:
- Kafka 使用 Zookeeper 的臨時節點來選舉 controller
- Zookeeper 在 broker 加入叢集或退出叢集時通知 controller
- controller 負責在 broker 加入或離開叢集時進行分割槽 leader 選舉

broker 管理
每個 broker 都有一個唯一識別符號 ID,這個識別符號可以在配置檔案裡指定,也可以自動生成。
在 broker 啟動的時候,它通過在 Zookeeper 的 /brokers/ids 路徑上建立臨時節點,把自己的 ID 註冊 Zookeeper。
Kafka 元件會訂閱 Zookeeper 的 /brokers/ids 路徑,當有 broker 加入叢集或退出叢集時,這些元件就可以獲得通知。
在 broker 停機、出現網路分割槽或長時間垃圾回收停頓時,會導致其 Zookeeper 會話失效,導致其在啟動時建立的臨時節點會自動被移除。
監聽 broker 列表的 Kafka 元件會被告知該 broker 已移除,然後處理 broker 崩潰的後續事宜。
在完全關閉一個 broker 之後,如果使用相同的 ID 啟動另一個全新的 broker,它會立即加入叢集,並擁有與舊 broker 相同的分割槽和主題。
controller 選舉
controller 其實就是一個 broker,它除了具有一般 broker 的功能之外,還負責分割槽 leader 的選舉。
為了在整個叢集中指定一個唯一的 controller,broker 叢集需要進行選舉,該過程依賴以下兩個 Zookeeper 節點:
// 臨時節點 controller(儲存最新的 controller 節點資訊,保證唯一性)
object ControllerZNode {
def path = "/controller"
def encode(brokerId: Int, timestamp: Long): Array[Byte] = {
Json.encodeAsBytes(Map("version" -> 1, "brokerid" -> brokerId, "timestamp" -> timestamp.toString).asJava)
}
def decode(bytes: Array[Byte]): Option[Int] = Json.parseBytes(bytes).map { js =>
js.asJsonObject("brokerid").to[Int]
}
}
// 永久節點 controller_epoch(儲存最新 controller 對應的任期號,用於避免腦裂)
object ControllerEpochZNode {
def path = "/controller_epoch"
def encode(epoch: Int): Array[Byte] = epoch.toString.getBytes(UTF_8)
def decode(bytes: Array[Byte]): Int = new String(bytes, UTF_8).toInt
}
broker 啟動後會發起一輪選舉,選舉通過 Zookeeper 提供的建立節點功能來實現:
/controller,建立成功的 broker 將成為 controller。新選出的 controller 會同時遞增
/controller_epoch 中的任期號,其他 broker 可以根據任期號忽略已過期 controller 的訊息。搶佔失敗的 broker 會收到一個 NODEEXISTS 響應,轉而在節點上建立
Watcher實時監控/controller節點。當 controller 被關閉或者斷開連線,Zookeeper 上的臨時節點就會消失,叢集裡的其他 broker 會接收到通知併發起一輪新的選舉。
broker 中的 KafkaController 物件負責發起選舉:
private def elect(): Unit = {
// 檢查叢集中是否存在可用 controller (activeControllerId == -1)
try {
// 當前 broker 通過 KafkaZkClient 發起選舉,並選舉自己為新的 controller
val (epoch, epochZkVersion) = zkClient.registerControllerAndIncrementControllerEpoch(config.brokerId)
// 如果 broker 當選,則更新對應的 controller 相關資訊
controllerContext.epoch = epoch
controllerContext.epochZkVersion = epochZkVersion
activeControllerId = config.brokerId
info(s"${config.brokerId} successfully elected as the controller. Epoch incremented to ${controllerContext.epoch} and epoch zk version is now ${controllerContext.epochZkVersion}")
onControllerFailover() // 選舉成功後觸發維護操作
} catch {
case e: ControllerMovedException =>
maybeResign()
if (activeControllerId != -1) // 其他 broker 被選為 controller
debug(s"Broker $activeControllerId was elected as controller instead of broker ${config.brokerId}", e)
else // 本輪選舉沒有產生 controller
warn("A controller has been elected but just resigned, this will result in another round of election", e)
case t: Throwable =>
error(s"Error while electing or becoming controller on broker ${config.brokerId}. Trigger controller movement immediately", t)
triggerControllerMove()
}
}
KafkaZkClient 中更新 Zookeeper 的邏輯如下:
def registerControllerAndIncrementControllerEpoch(controllerId: Int): (Int, Int) = {
val timestamp = time.milliseconds()
// 從 /controller_epoch 獲取當前 controller 對應的 epoch 與 zkVersion
// 若 /controller_epoch 不存在則嘗試建立
val (curEpoch, curEpochZkVersion) = getControllerEpoch
.map(e => (e._1, e._2.getVersion))
.getOrElse(maybeCreateControllerEpochZNode())
// 建立 /controller 並原子性更新 /controller_epoch
val newControllerEpoch = curEpoch + 1
val expectedControllerEpochZkVersion = curEpochZkVersion
debug(s"Try to create ${ControllerZNode.path} and increment controller epoch to $newControllerEpoch with expected controller epoch zkVersion $expectedControllerEpochZkVersion")
// 處理 /controller 節點已存在的情況,直接返回最新節點資訊
def checkControllerAndEpoch(): (Int, Int) = {
val curControllerId = getControllerId.getOrElse(throw new ControllerMovedException(
s"The ephemeral node at ${ControllerZNode.path} went away while checking whether the controller election succeeds. " +
s"Aborting controller startup procedure"))
if (controllerId == curControllerId) {
val (epoch, stat) = getControllerEpoch.getOrElse(
throw new IllegalStateException(s"${ControllerEpochZNode.path} existed before but goes away while trying to read it"))
// 如果最新的 epoch 與 newControllerEpoch 相等,則可以推斷 zkVersion 與當前 broker 已知的 zkVersion 一致
if (epoch == newControllerEpoch)
return (newControllerEpoch, stat.getVersion)
}
throw new ControllerMovedException("Controller moved to another broker. Aborting controller startup procedure")
}
// 封裝 zookeeper 請求
def tryCreateControllerZNodeAndIncrementEpoch(): (Int, Int) = {
val response = retryRequestUntilConnected(
MultiRequest(Seq(
// 傳送 CreateRequest 建立 /controller 臨時節點
CreateOp(ControllerZNode.path, ControllerZNode.encode(controllerId, timestamp), defaultAcls(ControllerZNode.path), CreateMode.EPHEMERAL),
// 傳送 SetDataRequest 更新 /controller_epoch 節點資訊
SetDataOp(ControllerEpochZNode.path, ControllerEpochZNode.encode(newControllerEpoch), expectedControllerEpochZkVersion)))
)
response.resultCode match {
case Code.NODEEXISTS | Code.BADVERSION => checkControllerAndEpoch()
case Code.OK =>
val setDataResult = response.zkOpResults(1).rawOpResult.asInstanceOf[SetDataResult]
(newControllerEpoch, setDataResult.getStat.getVersion)
case code => throw KeeperException.create(code)
}
}
// 向 zookeepr 發起請求
tryCreateControllerZNodeAndIncrementEpoch()
}
分割槽管理
一個 Kafka 分割槽本質上就是一個備份日誌,通過利用多份相同的冗餘副本replica保持系統高可用性。
Kafka 把分割槽的所有副本均勻地分配到所有 broker上,並從這些副本中挑選一個作為 leader 副本對外提供服務。
而其他副本被稱為 follower 副本,不對外提供服務,只能被動地向 leader 副本請求資料,保持與 leader 副本的同步。

當 controller 發現一個 broker 加入叢集時,它會使用 broker.id 來檢查新加入的 broker 是否包含現有分割槽的副本。
如果有,controller 就把變更通知傳送所有 broker,新 broker 中的分割槽作為 follower 副本開始從 leader 那裡複製訊息。
ISR
Kafka 為每個主題維護了一組同步副本集合in-sync replicas(其中包含 leader 副本)。
只有被 ISR 中的所有副本都接收到的那部分生產者寫入的訊息才對消費者可見,這意味著 ISR 中的所有副本都會與 leader 保持同步狀態。
為了避免出現新 leader 資料不完整導致分割槽資料丟失的情況,只有 ISR 中 follower 副本才有資格被選舉為 leader。
若 follower 副本無法在 replica.lag.time.max.ms 毫秒內向 leader 請求資料,那麼該 follower 就會被視為不同步,leader 會將其剔除出 ISR。
leader 會在 ISR 集合發生變更時,會在/isr_change_notification下建立一個永久節點並寫入變更資訊。
當監控/isr_change_notification的 controller 接收到通知後,會更新其他 broker 的後設資料,最後刪除已處理過的節點。
當出現瞬時峰值流量,只要 follower 不是持續性落後,就不會反覆地在 ISR 中移進、移出,避免頻繁訪問 Zookeeper 影響效能。
首選副本
建立主題時,Kafka 會為每個分割槽選定一個初始分割槽 leaderpreferred leader,其對應的副本被稱為首選副本preferred replica。
controller 在建立主題時會保證 leader 在 broker 之間均衡分佈,因此當 leader 按照初始的首選副本分佈時,broker 間的負載均衡狀態最佳。
然而 broker 失效是難以避免的,重啟後的首選副本只能作為 follower 副本加入 ISR 中,不能再對外提供服務。
隨著叢集的不斷執行,leader 不均衡現象會愈發明顯:叢集中的一小部分 broker 上承載了大量的分割槽 leader 副本。
可以設定 auto.leader.rebalance.enable = true 解決這一問題:
leader.imbalance.per.broker.percentage 時會自動執行一次 leader 均衡操作。
分割槽重分配
當一個新的 broker 剛加入叢集時,不會自動地分擔己有 topic 的負載,它只會對後續新增的 topic 生效。
如果要讓新增 broker 為己有的 topic 服務,使用者必須手動地調整現有的 topic 的分割槽分佈,將一部分分割槽搬移到新增 broker 上。這就是所謂的分割槽重分配reassignment操作。
除了處理 broker 擴容導致的不均衡之外,再均衡還能用於處理 broker 儲存負載不均衡的情況,在單個或多個 broker 之間的日誌目錄之間重新分配分割槽。 用於解決多個代理之間的儲存負載不平衡。
首領選舉
觸發分割槽 leader 選舉的幾種場景:
- Offline:建立新分割槽或分割槽失去現有 leader
- Reassign:使用者執行重分配操作
- PreferredReplica:將 leader 遷移回首選副本
- ControlledShutdown:分割槽的現有 leader 即將下線
當上述幾種情況發生時,controller 會遍歷所有相關的主題分割槽並從為其指定新的 leader。
然後向所有包含相關主題分割槽的 broker 傳送更新請求,其中包含了最新的 leader 與 follower 副本分配資訊。
更新完畢後,新 leader 會開始處理來自生產者和消費者的請求,而follower 開始從新 leader 那裡複製訊息。
分割槽狀態資訊在對應的節點資訊:
// 節點 /brokers/topics/{topic-name}/partitions/{partition-no}/state 儲存分割槽最新狀態資訊的
object TopicPartitionStateZNode {
def path(partition: TopicPartition) = s"${TopicPartitionZNode.path(partition)}/state"
def encode(leaderIsrAndControllerEpoch: LeaderIsrAndControllerEpoch): Array[Byte] = {
val leaderAndIsr = leaderIsrAndControllerEpoch.leaderAndIsr
val controllerEpoch = leaderIsrAndControllerEpoch.controllerEpoch
Json.encodeAsBytes(Map("version" -> 1, "leader" -> leaderAndIsr.leader, "leader_epoch" -> leaderAndIsr.leaderEpoch,
"controller_epoch" -> controllerEpoch, "isr" -> leaderAndIsr.isr.asJava).asJava)
}
def decode(bytes: Array[Byte], stat: Stat): Option[LeaderIsrAndControllerEpoch] = {
Json.parseBytes(bytes).map { js =>
val leaderIsrAndEpochInfo = js.asJsonObject
val leader = leaderIsrAndEpochInfo("leader").to[Int]
val epoch = leaderIsrAndEpochInfo("leader_epoch").to[Int]
val isr = leaderIsrAndEpochInfo("isr").to[List[Int]]
val controllerEpoch = leaderIsrAndEpochInfo("controller_epoch").to[Int]
val zkPathVersion = stat.getVersion
LeaderIsrAndControllerEpoch(LeaderAndIsr(leader, epoch, isr, zkPathVersion), controllerEpoch)
}
}
}
PartitionStateMachine 管理分割槽選舉的程式碼:
private def doElectLeaderForPartitions(partitions: Seq[TopicPartition], partitionLeaderElectionStrategy: PartitionLeaderElectionStrategy
): (Map[TopicPartition, Either[Exception, LeaderAndIsr]], Seq[TopicPartition]) = {
// 請求 Zookeeper 獲取 partition 當前狀態
val getDataResponses = try {
zkClient.getTopicPartitionStatesRaw(partitions)
} catch {
case e: Exception =>
return (partitions.iterator.map(_ -> Left(e)).toMap, Seq.empty)
}
val failedElections = mutable.Map.empty[TopicPartition, Either[Exception, LeaderAndIsr]]
val validLeaderAndIsrs = mutable.Buffer.empty[(TopicPartition, LeaderAndIsr)]
getDataResponses.foreach { getDataResponse =>
val partition = getDataResponse.ctx.get.asInstanceOf[TopicPartition]
val currState = partitionState(partition)
if (getDataResponse.resultCode == Code.OK) {
// 剔除狀態已失效或不存在的 partition
TopicPartitionStateZNode.decode(getDataResponse.data, getDataResponse.stat) match {
case Some(leaderIsrAndControllerEpoch) =>
if (leaderIsrAndControllerEpoch.controllerEpoch > controllerContext.epoch) {
val failMsg = s"Aborted leader election for partition $partition since the LeaderAndIsr path was " +
s"already written by another controller. This probably means that the current controller $controllerId went through " +
s"a soft failure and another controller was elected with epoch ${leaderIsrAndControllerEpoch.controllerEpoch}."
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
} else {
validLeaderAndIsrs += partition -> leaderIsrAndControllerEpoch.leaderAndIsr
}
case None =>
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, Left(exception))
}
} else if (getDataResponse.resultCode == Code.NONODE) {
val exception = new StateChangeFailedException(s"LeaderAndIsr information doesn't exist for partition $partition in $currState state")
failedElections.put(partition, Left(exception))
} else {
failedElections.put(partition, Left(getDataResponse.resultException.get))
}
}
// 如果全部 partition 均失效,則跳過此次選舉
if (validLeaderAndIsrs.isEmpty) {
return (failedElections.toMap, Seq.empty)
}
// 根據指定的選舉策略選擇 partition leader
val (partitionsWithoutLeaders, partitionsWithLeaders) = partitionLeaderElectionStrategy match {
// Elect leaders for new or offline partitions.
case OfflinePartitionLeaderElectionStrategy(allowUnclean) =>
val partitionsWithUncleanLeaderElectionState = collectUncleanLeaderElectionState(validLeaderAndIsrs, allowUnclean)
leaderForOffline(controllerContext, partitionsWithUncleanLeaderElectionState).partition(_.leaderAndIsr.isEmpty)
// Elect leaders for partitions that are undergoing reassignment.
case ReassignPartitionLeaderElectionStrategy =>
leaderForReassign(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
// Elect preferred leaders.
case PreferredReplicaPartitionLeaderElectionStrategy =>
leaderForPreferredReplica(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
// Elect leaders for partitions whose current leaders are shutting down.
case ControlledShutdownPartitionLeaderElectionStrategy =>
leaderForControlledShutdown(controllerContext, validLeaderAndIsrs).partition(_.leaderAndIsr.isEmpty)
}
partitionsWithoutLeaders.foreach { electionResult =>
val partition = electionResult.topicPartition
val failMsg = s"Failed to elect leader for partition $partition under strategy $partitionLeaderElectionStrategy"
failedElections.put(partition, Left(new StateChangeFailedException(failMsg)))
}
// 將選舉結果同步到 TopicPartitionStateZNode 對應的 Zookeeper 節點
val recipientsPerPartition = partitionsWithLeaders.map(result => result.topicPartition -> result.liveReplicas).toMap
val adjustedLeaderAndIsrs = partitionsWithLeaders.map(result => result.topicPartition -> result.leaderAndIsr.get).toMap
val UpdateLeaderAndIsrResult(finishedUpdates, updatesToRetry) = zkClient.updateLeaderAndIsr(adjustedLeaderAndIsrs, controllerContext.epoch, controllerContext.epochZkVersion)
finishedUpdates.forKeyValue { (partition, result) =>
result.foreach { leaderAndIsr =>
val replicaAssignment = controllerContext.partitionFullReplicaAssignment(partition)
val leaderIsrAndControllerEpoch = LeaderIsrAndControllerEpoch(leaderAndIsr, controllerContext.epoch)
controllerContext.putPartitionLeadershipInfo(partition, leaderIsrAndControllerEpoch)
controllerBrokerRequestBatch.addLeaderAndIsrRequestForBrokers(recipientsPerPartition(partition), partition,
leaderIsrAndControllerEpoch, replicaAssignment, isNew = false)
}
}
(finishedUpdates ++ failedElections, updatesToRetry)
}
日誌複製
複製流程
日誌複製中的一些重要偏移概念:
- 起始位移
base offset:副本所含第一條訊息的 offset - 高水位值
high watermark:副本最新一條己提交訊息的 offset - 日誌末端位移
log end offset:副本中下一條待寫入訊息的 offset

每個副本會同時維護 HW 與 LEO 值:
- leader 保證只有 HW 及其之前的訊息,才對消費者是可見的。
- follower 當機後重啟時會對其日誌截斷,只保留 HW 及其之前的日誌訊息(新版本有改動)。
Kafka 中的複製流程大致如下:
- leader 會將接收到的訊息寫入日誌檔案,同時更新 \(\tiny \textsf{leader LEO}\)
- follower 傳送 fetch 請求指定 offset 的訊息
- 接收到請求後 leader 會根據 offset 更新下面兩個值
- \(\tiny \textsf{follower LEO} = \texttt{offset}\)
- \(\tiny \textsf{HW} = \min(\textsf{leader LEO}, \min(\textsf{follower LEO of ISR}))\)
- leader 返回訊息的同時會附帶上最新的 HW
- follower 接收到響應後會將訊息寫入日誌檔案,並同時更新 HW
leader epoch
在前面我們提到 follower 在重啟後會對日誌進行截斷,這可能導致訊息會丟失:

假設某個分割槽分佈在 A 和 B 兩個 broker 上,且最開始時 B 是分割槽 leader
- 某個時刻,follower A 從 leader B 同步訊息 m2,但此時並未收到 HW 更新
- 就在此時,follower A 發生了重啟,此時它會截斷 m2 所在的日誌,然後才向 leader B 重新請求資料
- 不巧,此時 leader B 也發生了當機,此時 follower A 會被選為新的 leader A,這意味著訊息 m2 已經永久丟失了
為了解決這一問題,Kafka 為每一屆 leader 分配了一個唯一的 epoch,由其追加到日誌的訊息都會包含這個 epoch。
然後每個副本都在本地維護一個 epoch 快照檔案,並在其中儲存 (epoch, offset):
- epoch 表示 leader 的版本號,當 leader 變更一次 epoch 就會加 1
- offset 則對應 epoch 版本的 leader 寫入第一條訊息的對於的位移
回到之前的場景,增加了 leader epoch 之後的行為如下:
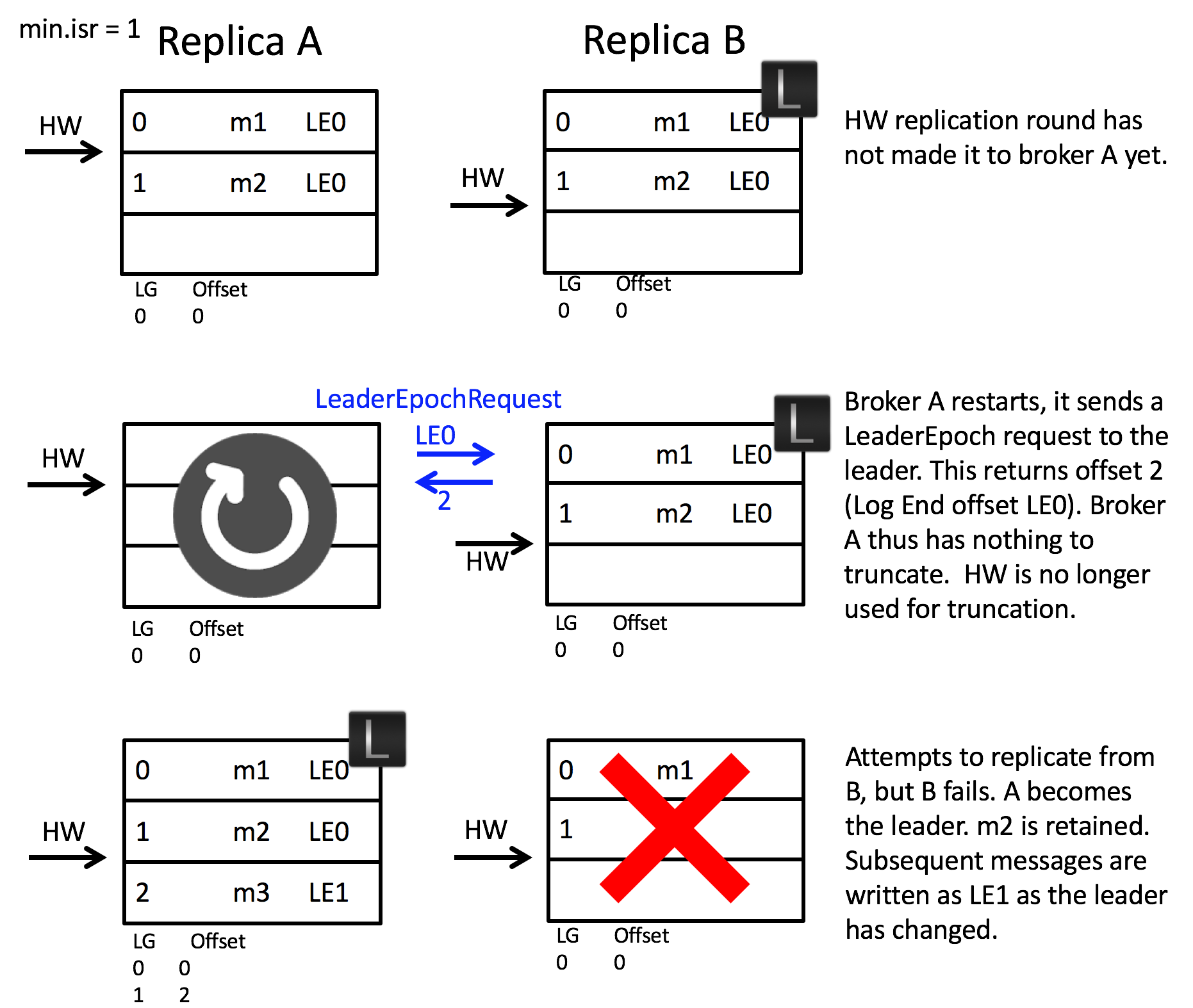
- follower A 發生重啟後,會向 leader B 傳送
LeaderEpochRequest請求最新的 leader epoch - leader B 會在響應中返回自己的 LEO
- follower A 接收到響應後發現無需對日誌進行截斷,從而避免了訊息 m2 丟失
更多的細節可以參考這篇文章。
檔案格式
建立主題時,Kafka 會為主題的每個分割槽在檔案系統中建立了一個對應的子目錄,命名格式為主題名-分割槽號,每個日誌子目錄的檔案構成如下:
[lhop@localhost log]$ tree my-topic-*
my-topic-0
├── 00000000000050209130.index
├── 00000000000050209130.log
├── 00000000000050209130.snapshot
├── 00000000000050209130.timeindex
└── leader-epoch-checkpoint
my-topic-1
├── 00000000000048329826.index
├── 00000000000048329826.log
├── 00000000000048329826.timeindex
└── leader-epoch-checkpoint
其中的 leader-epoch-checkpoint檔案用於儲存 leader epoch 快照,用於協助崩潰的副本執行恢復操作,在此就不詳細展開。我們重點關注剩餘的兩類檔案。
資料檔案
日誌段檔案(.log)的檔案儲存著真實的 Kafka 記錄。
Kafka 使用該檔案第一條記錄對應的 offset 來命名此檔案。
每個日誌段檔案是有上限大小的,由 broker 端引數log.segment.bytes控制。

除了鍵、值和偏移量外,訊息裡還包含了訊息大小、校驗和、訊息格式版本號、壓縮演算法和時間戳。時間戳可以是生產者傳送訊息的時間,也可以是訊息到達 broker 的時間,這個是可配置的。
如果生產者傳送的是壓縮過的訊息,那麼同一個批次的訊息會被壓縮在一起。broker 會原封不動的將訊息存入磁碟,然後再把它傳送給消費者。消費者在解壓這個訊息之後,會看到整個批次的訊息,它們都有自己的時間戳和偏移量。
這意味著 broker 可以使用zero-copy技術給消費者傳送訊息,同時避免了對生產者已經壓縮過的訊息進行解壓和再壓縮。
索引檔案
位移索引檔案(.index)與時間戳索引(.timeindex)是兩個特殊的索引檔案:
- 前者可以幫助快速定位記錄所在的物理檔案位置
- 後者則是根據給定的時間戳查詢對應的位移資訊
它們都屬於稀疏索引檔案,每寫入若干條記錄後才增加一個索引項。寫入間隔可以 broker 端引數 log.index.interval.bytes 設定。
索引檔案嚴格按照時間戳順序儲存,因此 Kafka 可以利用二分查詢演算法提高查詢速度。