高效構建vivo企業級網路流量分析系統
隨著網路規模的快速發展,網路狀況的良好與否已經直接關係到了企業的日常收益,故障中的每一秒都會導致大量的使用者流失與經濟虧損。因此,如何快速發現網路問題與定位異常流量已經成為大型企業內必須優先解決的問題,諸多網路流量分析技術也同時應運而生。
一、概述
隨著網路規模的快速發展,網路狀況的良好與否已經直接關係到了企業的日常收益,故障中的每一秒都會導致大量的使用者流失與經濟虧損。每一家企業都在不斷完善自己的網路監控手段,但在監控體系建設過程中,卻又不可避免的面臨以下難點:
網路流量資料龐大:由於網路流量的規模和複雜性都非常高,很難對大量的資料進行有效的監控和分析。
流量資料採集分析建設成本高昂:為獲取準確的流量資料,需要使用高效的資料採集技術和大容量的儲存裝置,以及大量的開發資源,這使得監控成本直線上升
監控手段單一、缺乏擴充套件性:傳統的監控手段一般只能監控固定的幾個資料點,難以針對不同的網路環境進行定製化和擴充套件。
難以快速定位和解決問題:由於網路流量資料量大、變化頻繁,往往需要花費大量的時間和精力才能找出問題根源。
因此,如何利用盡可能低的監控成本快速發現網路問題與定位異常流量已經成為大型企業內必須優先解決的問題,諸多網路流量分析技術也同時應運而生。
sFlow技術就是這樣一種高效、靈活的解決方案。它可以透過流量取樣技術抽取資料包中的部分資訊,從而實現對大量網路流量資料進行持續監控。同時,sFlow技術還具有靈活的配置和擴充套件性,可以根據實際需求進行定製,並支援多種網路裝置和協議。這些優勢使得sFlow技術在現代網路監控和管理中得到廣泛應用。
二、常見的網路流量採集技術
主流的網路流量採集主要分為全流量採集與取樣流量採集兩種。
2.1 全流量採集
全流量採集包括埠映象、分光裝置等方式。在流量龐大的網路中,使用埠映象方式不僅會導致全鏈路時延增加,而且會使吞吐量龐大情況下的網路裝置壓力激增。分光裝置雖然可以降低鏈路時延,但同樣存在採購價格高昂的門檻。除此之外,由於大型企業內IDC規模龐大,由此導致的全流量資料量也會激增,想要完整的靠自研做好全流量資料分析,不僅需要一定的儲存計算資源,也需要一定的軟體開發週期,不利於專案的快速搭建成型。
2.2 取樣流量採集
在流量分析系統欠缺的情況下,使用取樣分析的優勢就體現出來了,相對於全流量,他部署成本低,資料分析代價小,很適合對異常流量的快速定位以及網路內的趨勢佔比分析。以下主要對比介紹sFlow與Netflow兩種取樣方式的優缺點。

sFlow在流量監控上範圍更廣,在滿足硬體要求的IDC內部環境,使用sFlow進行取樣流量監測,可以有效降低網路裝置負載,並且提供實時流量監控手段,以應對突發網路異常場景。
三、基於sFlow的系統設計
3.1 基礎設計
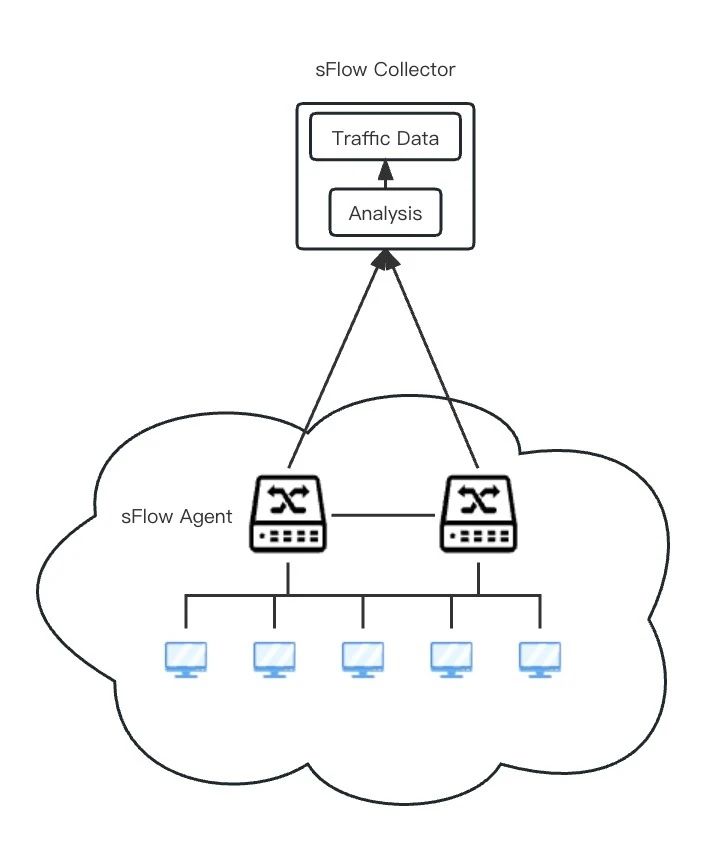
在滿足硬體條件的情況下,基於sFlow的基礎系統設計很簡單,使用sFlow agent + sFlow collector + sFlow analyser即可實現整個流程的資料閉環。
sFlow agent:透過enabled相關網路裝置上的sFlow能力,設定取樣比等引數並制定收集端相應地址,即可對埠收發流量進行採集。agent側更重要的反而是如何確定採集的網路裝置範圍,相對於無目的的全量網路裝置部署,針對邊界核心網路裝置進行部署更有意義,因為所有的對外流量最終都必須經過邊界網路裝置。在能更好監控外部流量異常的情況下,也能減輕資料儲存負擔。
sFlow collector:收集並解析agent側採集傳輸的 sFlow datagrams。
sFlow analyser:對格式化的資料進行視覺化分析展示,以供網路管理員進行有效觀測分析。
3.2 開源+自研:架構進階
在確定了基本架構之後,如何進行元件選用與定製化功能擴充,開源解決方案elastiflow為我們提供了很好的示例,筆者基於開源進行了擴充套件,以滿足更多定製化功能。
sFlow agent:使用上報統一vip的形式進行埠流量取樣(官方規定的取樣比需是2^n),可以利用vip的LB能力進行負載均衡,使得sFlow報文均衡打到收集端固定埠。針對不同的網路線路設定不同的取樣比,在降低資料儲存的同時也可以保證重要線路更高的精準性。

sFlow collector:使用ELK套件進行資料收集與視覺化分析是比較成熟的技術方案之一。因此,收集端我們使用logstash進行原生資料包文收集與解析。elastiflow的作者使用了logstash內原生的udp-sFlow報文解析元件進行資料解析,但筆者在實際測試中發現,雖然該方案能得到結構化更好的資料格式,但在資料解析的效能表現上很差,在資料量龐大的情況下會造成大量資料丟包現象,導致資料準確性下降。而sFlowtool由於底層是基於C語言來編寫的,在效能表現上很優異,單物理機(32c64g)即可達到10w+tps,雖然對sFlow報文解析後的資料結構化要弱一點,但可以在後續分析模組對資料進行清洗與結構化構建。sFlowtool分析的資料示例如下所示。經由logstash的資料傳送到kafka訊息佇列中。
sFlow analyser:透過從kafka實時消費資料,將資料進行清洗結構化,並藉助三方meta data,對解析後的資料進行軟體定義,以便於後續儲存與分析。
database+display:使用Elasticsearch+Kibana進行儲存與視覺化展示,同時也可以利用mertic beat對logstash的採集效能進行監控。Kibana作為Bi類的資料視覺化方案,提供了大部分可供免費使用的圖表及Dashboard,可以很好的進行視覺化分析。
3.3 分析端軟體定義
擁有原生資料的情況下,我們已經能基於一些ip五元組等進行基本會話流量分析。但是流量資料所能體現的價值遠不止這些,利用企業內其他的cmdb等平臺,可以為我們的流量資料提供更大價值。
網路裝置維度:透過資料內的交換機地址,出入向埠,可以根據採集配置的交換機埠index,判斷該條流量出入向。也可基於網路裝置ip,賦予其通道,線路,以及裝置名等等其他屬性。
ip維度:ip五元組提供了探索資料更高的可能,我們可以根據歸屬ip,判斷他的專案,部門等歸屬資訊,也可反向關聯域名。這在對異常流量進行分析判斷時能夠快速定位到所屬業務方,很大程度提高了運維效率。
3.4 壓縮儲存與視覺化自研
由於Elasticsearch本身的資料壓縮效果不夠理想,使得我們在進行長時間儲存資料時體量龐大臃腫。相應的,olap型資料庫Druid很好地解決了這個問題,資料取樣後經過分析端嚴格的結構化處理,可以在Druid內實現很好的資料壓縮。除此之外,Druid內嵌的資料預聚合能力也能更好的幫助我們對歷史資料進行降精處理,減少儲存壓力。切換儲存引擎後,也就意味著沒辦法再使用Kibana進行通用展示,使用自研的web服務框架也能夠應對靈活的需求場景,實現更多定製化的分析。
3.5 基於Celery設計的輕量流處理模型
雖然流量資料經過了取樣降精,但整體的資料量依然很龐大。高效快速的進行流處理,降低整體系統時延至30s內,能夠更快的幫助網路管理人員發現問題,除卻利用傳統的流處理工具外,我們也可以使用Celery來構建一個輕量高效易擴充套件的分散式流處理叢集。
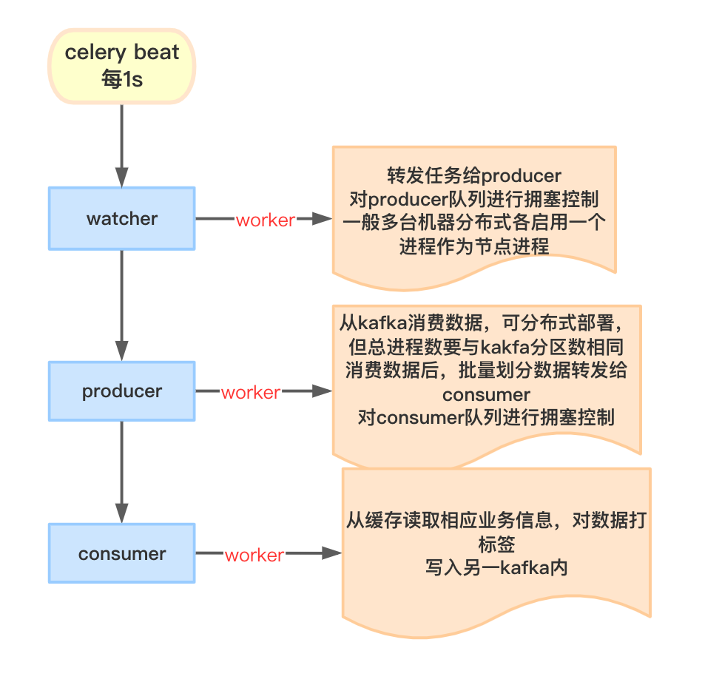
Celery是一個簡單、靈活且可靠的,處理大量訊息的分散式系統,專注於實時處理的非同步任務佇列,同時也支援任務排程。我們基於celery實時非同步處理的特性,設計 celerybeat → watcher → producer → consumer 的消費鏈路來進行流處理。
celery beat:作為定時任務的觸發器,每1s向watcher佇列裡派發一個新任務。
watcher worker:在佇列中拿到任務後,轉發給producer,並根據設定的佇列最大值,對producer佇列進行擁塞控制。
producer worker:在佇列中拿到任務後,從kafka中獲取採集的流量資料,按照batch size批次傳送給consumer佇列,並根據設定的佇列最大值,對consumer佇列進行擁塞控制。
consumer worker:在佇列中拿到任務後,根據本地快取/共享快取內的業務資訊,對採集資料進行資料清洗,打業務標籤等操作,並寫入另一kakfa或直接寫入database。
每一個角色以及節點可以透過Celery broker進行通訊,實現分散式叢集部署,針對consumer單元化操作,可以使用eventlet以協程方式啟動,以保證叢集高併發消費。
四、應用場景
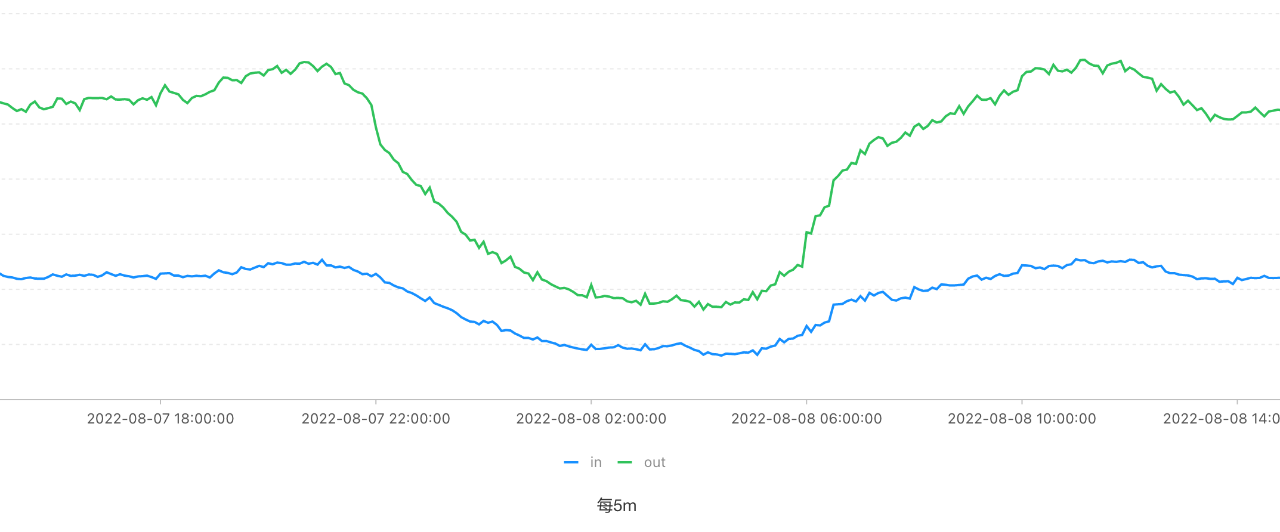
4.1 機房維度流量分析
透過基於網路cmdb的ip匹配,對流量資料進行機房維度的彙總,可以得到機房整體的對外出入向流量分析,在IDC同外部互動時,整體流量的趨勢變化,是判斷頻寬佔用程度的直接標準。
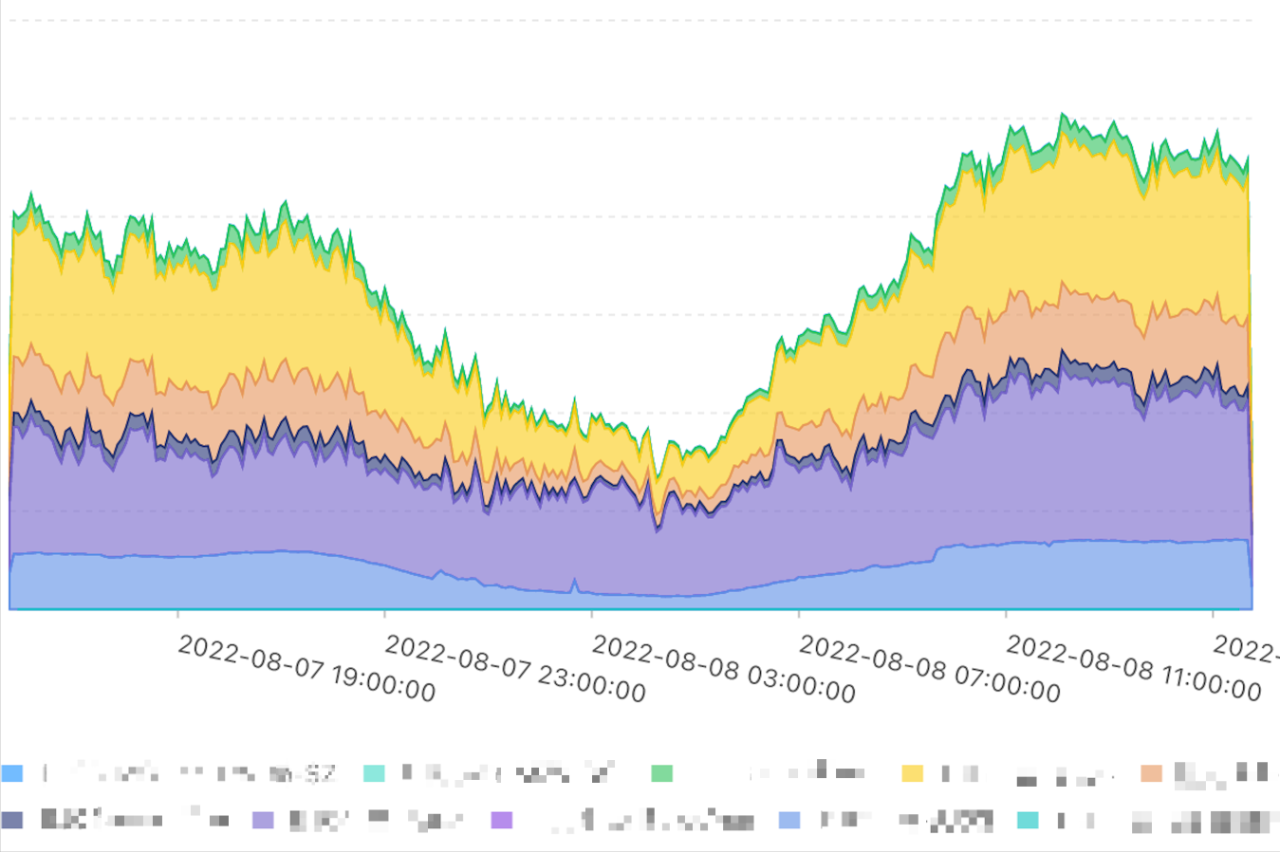
4.2 網路線路資訊關聯
透過對網路裝置基於ip+ifindex的邏輯資訊對映,可以對核心通道線路做到聚合展示,在針對一些公網線路異常,專用線路頻寬打滿等異常問題時,透過觀察線路分析可以直接準確定位故障發生的第一時間點。
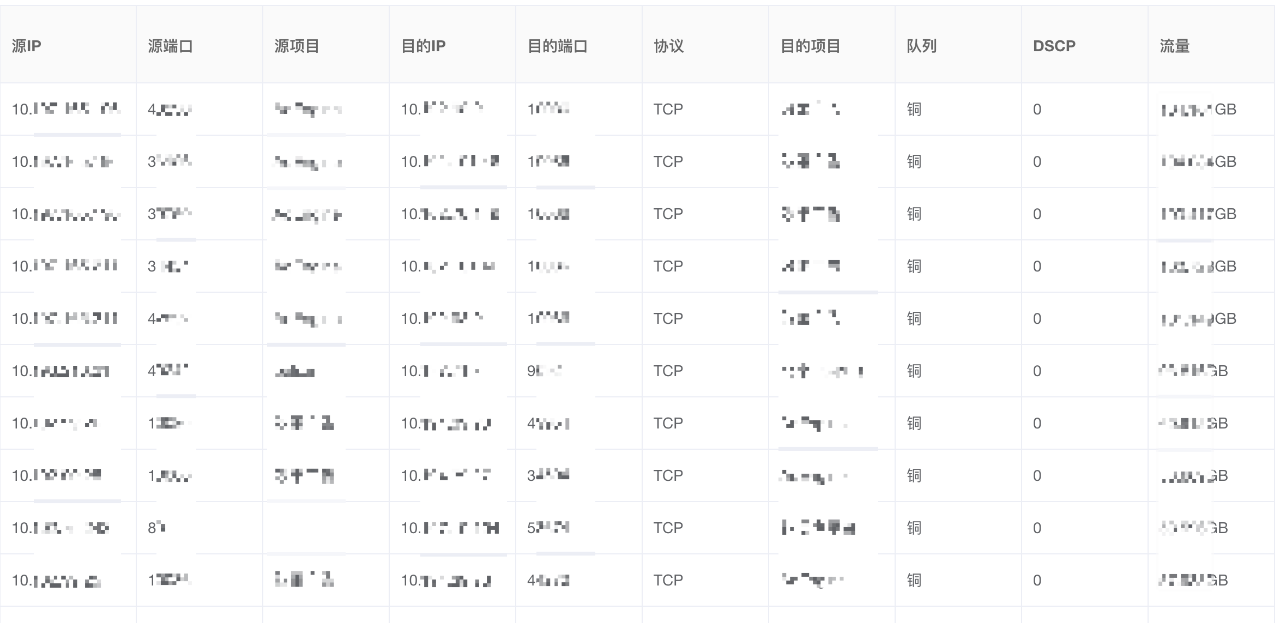
4.3 ip會話資訊挖掘
雖然sflow只擷取了報文的頭部資訊而不包含資料包部分,但ip五元組本身也提供了極大的網路流量分析價值。
利用會話資訊,我們可以準確有效的定位異常流量的ip歸屬,透過ip+服務埠的,我們甚至可以定位具體產生流量異常的服務與程式,從而做出下一步決策。除此之外,ip也能同企業內CMDB產生聯動,定位到ip所屬資源的所在資源組,從而得到不同部門/行政組產生的流量佔比分析,這同時也有利於在產生異常流量時第一時間感知到相關業務,並進行通知管控。
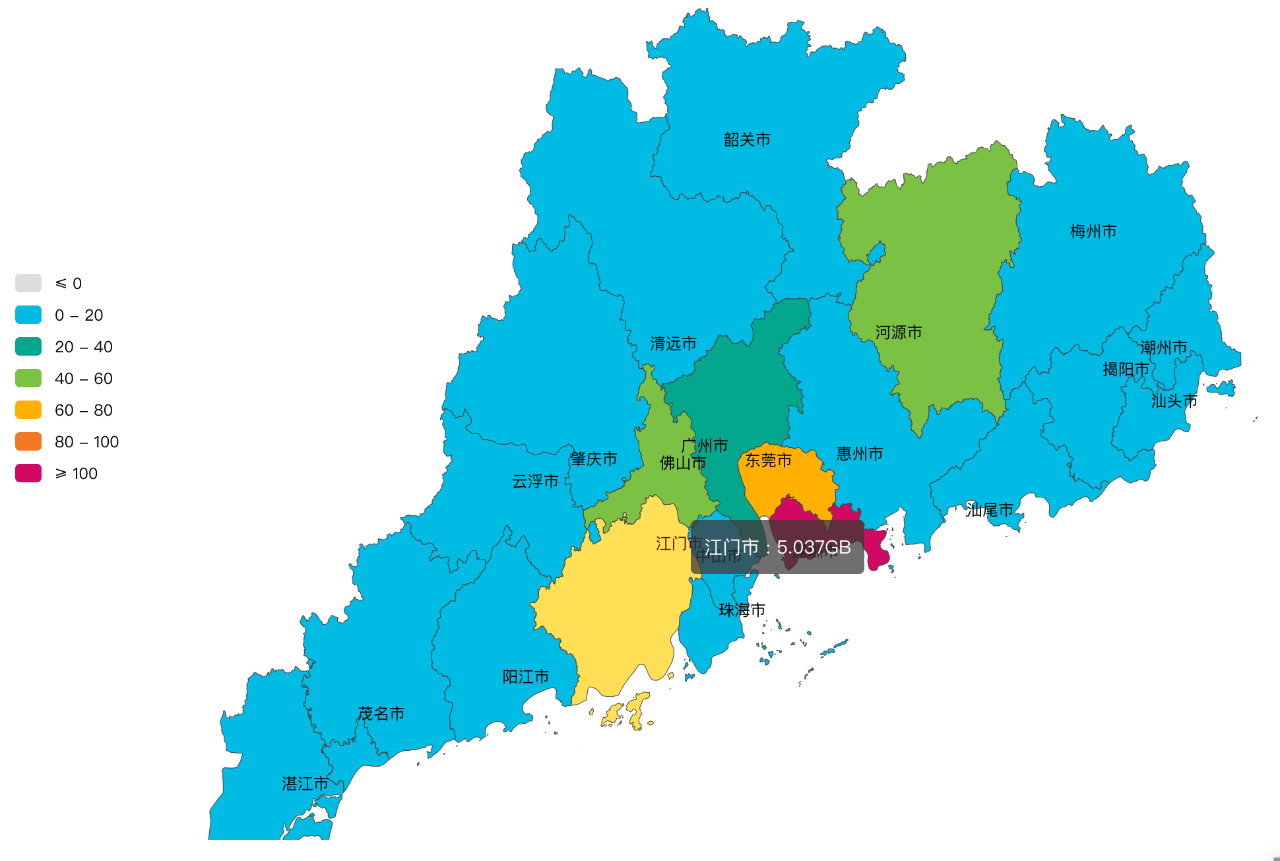
4.4 ip歸屬地分析
除了結合內部資訊,透過運營商提供的歸屬地資訊,我們可以檢視ip訪問的來源,進行相關歸屬地分析與Dashboard製作。
五、總結
要實現對網路全面、實時的監控分析必須依靠先進有效的網路監控協議和技術來滿足業務日益增長的需求。基於sFlow的流量分析雖然在輕量化構建上有著很大的優勢,在面對異常流量時也能夠基於流量趨勢與分佈佔比做出快速反應。但sFlow本身的取樣卻不包含報文內資料包的資訊,針對一些sql注入、資料安全等等網路安全攻防問題,沒辦法提供準確定位與解決方案。因此,全流量分析也應是流量分析系統未來必不可少的一環,兩者相結合才能夠提供更全面、更精細化的流量監控,為資料中心的網路安全保駕護航。
六、未來展望
雖然sFlow技術在網路效能監控和管理領域中得到了廣泛應用,但在未來更大規模的網路流量場景衝擊下,還需要具備更多的能力:
1.支援更多協議和應用:sFlow監控的思想不僅適用於網路流量,還可以監控應用流量、虛擬化環境、雲平臺等。未來,sFlow技術應該支援更多的協議和應用,以更好地適應新型網路環境。
2.自適應流量採集技術:sFlow技術的流量採集技術是固定週期的,但是隨著網路流量的變化,固定週期的採集可能無法準確反映網路實時狀態。未來,sFlow監控技術應該支援自適應流量採集技術,能夠根據實際網路流量變化自動調整採集週期。
3.便捷的管理功能:sFlow目前的配置更多依賴於網路管理人員在交換機上進行配置,無法實現一鍵下發,自動發現,快速調整取樣比等等功能,未來更需要一個能夠便捷下發命令,熱載入配置變更的sFlow管理平臺。
來自 “ vivo網際網路技術 ”, 原文作者:Ming Yujia;原文連結:https://server.it168.com/a2024/0228/6840/000006840816.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 如何構建高效協同的企業級重保體系?答案在這裡!
- 企業級日誌分析系統——ELK
- 北京智和信通企業級網路流量監控方案
- 構建企業級 Agent 系統:核心元件設計與最佳化元件
- 企業指標設計方法:構建高效指標體系指標
- AlertManager解析:構建高效告警系統
- 創業公司如何快速構建高效的監控系統?創業
- 億級流量系統架構演進之路架構
- 網際網路企業:如何建設資料安全體系?
- 智慧水務系統:構建高效節水的城市水網
- 億級流量系統架構之如何設計承載百億流量的高效能架構【石杉的架構筆記】架構筆記
- 阿里雲企業級雲網路解決方案,助力企業構建安全可靠的雲網路阿里
- 讀零信任網路:在不可信網路中構建安全系統14流量信任
- 讀零信任網路:在不可信網路中構建安全系統12原始碼和構建系統原始碼
- Flink X Hologres 構建企業級 Streaming Warehouse
- 雲企業網CEN-TR打造企業級私有網路
- ESB編排平臺,靈活構建企業系統流程
- 數商云為中大型企業構建高效、科學的採購管理系統平臺
- 雲端計算學習路線教程大綱課堂筆記:構建企業級WIKI及工單系統筆記
- 企事業單位OA辦公系統建設效益分析
- 10 分鐘構建企業級雲原生框架框架
- 01 . 中小企業到億級流量架構演進過程架構
- 容器網路流量轉發分析
- 工業網際網路平臺架構方案,構建工業網際網路企業數字化、網路化、智慧化服務體系架構
- 大型企業網路系統整合方案如何設計?
- 2022年APP將成企業構建私域流量池首選APP
- DevOps升級&AIOps落地,網際網路企業和傳統企業的做法有何異同?devAI
- 雲棲釋出|企業級網際網路架構全新升級 ,助力數字創新架構
- 用低程式碼開發工具高效構建企業門戶
- 鴻蒙 Next 企業級應用安全認證體系構建實戰鴻蒙
- OA系統之網路硬碟,高效管理大容量網路硬碟硬碟
- 深圳雲端計算培訓學習:構建企業級WIKI及工單系統 --【千鋒】
- 墨子企業官網系統
- 企業網際網路應用高效能解決之道
- 構建未來:2024年中國企業級IT市場的前瞻性分析
- iNeuOS工業網際網路作業系統,高效採集資料配置與應用作業系統
- 企業網路安全的“人防”工事該如何建?
- 企業級React專案的個人構建總結React