日均上億慢查詢,如何基於AI+資料驅動索引推薦
目前,美團內部每天產生的慢查詢數量已經超過上億條。如何高效準確地為慢查詢推薦缺失的索引來改善其執行效能,是美團資料庫研發中心面臨的一項挑戰。為此,我們與華東師範大學開展了科研合作,在AI領域對索引推薦進行了探索和實踐,並將基於代價的方法和新提出的基於AI+資料驅動的方法共同應用於慢查詢的索引推薦,成功提升了推薦效果。
一、背景
隨著美團業務量的不斷增長,慢查詢的數量也日益增多。目前,日均慢查詢數量已經超過上億條,如果僅依靠DBA和開發人員手動地對這些慢查詢進行分析並建立合適的索引,顯然是不太現實的。為了解決這一難題,美團內部DAS(資料庫自治服務)平臺已經整合了基於代價的慢查詢最佳化建議來自動地為慢查詢推薦索引。然而,仍然存在一些問題:
基於代價的慢查詢最佳化建議是藉助於最佳化器的代價估計,來推薦出對於查詢代價改善最大的索引,但最佳化器的代價估計並不是完全準確[1],因此可能存在著漏選或者錯選推薦索引的問題。
基於代價的慢查詢最佳化建議需要計算查詢在不同索引下查詢代價的改善程度,因此需要進行大量的增刪索引操作,但真實增刪索引的代價是非常大的,需要藉助於假索引[2]技術,假索引技術並不建立真實的物理索引檔案,只是透過模擬索引存在時的查詢計劃來估算索引對於查詢的收益。目前,美團大部分業務都是執行在MySQL例項上的,不同於商業資料庫SQL Server和開源資料庫PostgreSQL,MySQL內部並沒有整合假索引技術,因此需要自己構建支援假索引的儲存引擎,其開發成本較高,這也是目前DAS平臺基於代價的慢查詢最佳化建議所採用的方案。
為了解決上述兩個問題,美團資料庫研發中心與華東師範大學資料科學與工程學院展開了《基於資料驅動的索引推薦》的科研合作,雙方透過在DAS平臺上整合基於AI+資料驅動的索引推薦,來與基於代價的方法並行地為慢查詢推薦索引,以提升推薦效果。
首先,基於代價的方法每天會為慢查詢推薦索引,並在取樣庫上評估推薦的索引是否真正地改善了查詢的執行時間,這為AI方法積累了大量可信的訓練資料,根據此資料訓練的AI模型,可以在一定程度上彌補基於代價的方法漏選或錯選索引的問題。
其次,基於AI的方法將針對慢查詢的索引推薦看作是二分類問題,透過分類模型直接判別在某一列或某些列上建立索引是否能夠改善查詢的執行效能,並不藉助於查詢最佳化器和假索引技術,這使得AI方法更加通用,且開發成本更低。
二、索引推薦介紹
索引推薦可以劃分為兩個級別:Workload級別和Query級別:
在Workload級別,索引推薦是在限制的索引儲存空間或索引個數下,推薦出一組最優的索引集合來使得整個Workload的代價最低。
Query級別的索引推薦可以被視為Workload級別索引推薦的簡化版本,在Query級別,索引推薦是為單個慢查詢推薦缺失的索引,以改善其效能。
1、基於代價的索引推薦
基於代價的索引推薦[3]大多聚焦於Workload級別的索引推薦,出現在查詢中每一列或者列的組合都可以看作是一個能夠改善Workload代價的候選索引,所有的候選索引構成了一個巨大的搜尋空間(候選索引集合)。
基於代價的索引推薦的目標,是在候選索引集合中搜尋出一組最優索引集合,以最大程度地改善Workload代價。如果候選索引的個數N,限制的最大推薦索引個數是M,那麼最優索引集合的搜尋空間是:
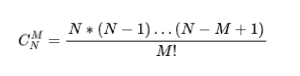
這是一個屬於NP-hard範疇的搜尋問題[4]。目前,基於代價的索引推薦方法大多會採用“貪心策略”來簡化搜尋過程,但這可能會導致最後推薦出的索引是次優解[5]。
2、基於AI+資料驅動的索引推薦
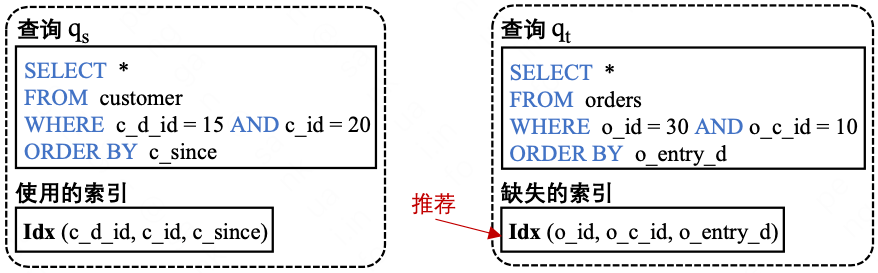
基於AI+資料驅動的索引推薦聚焦於Query級別的索引推薦,出發點是在某個資料庫中因為缺失索引導致的慢查詢,在其它資料庫中可能有相似的索引建立案例:這些查詢語句相似,因此在相似位置上的列建立索引也可能帶來類似的收益。例如下圖中,查詢 q8 和 qt 和在語句結構和列型別上非常相似。因此,我們可以透過學習查詢 q8 的索引建立模式來為查詢 qt 推薦缺失的索引。
對於不同列數的索引推薦,我們會分別訓練基於XGBoost的二分類模型。例如,我們目前最高支援三列的索引推薦,因此會分別訓練一個單列索引推薦模型、一個兩列索引推薦模型和一個三列索引推薦模型。對於給定的一個單列候選索引和它對應的慢查詢,我們使用單列索引推薦模型來判斷該單列候選索引是否能夠改善該慢查詢的效能。
同樣的,對於給定的一個兩列(三列)候選索引和它對應的慢查詢,我們使用兩列(三列)索引推薦模型來判斷這個兩列(三列)候選索引是否能夠改善該慢查詢的效能。如果一條慢查詢中包含的候選索引個數為N,那麼則需要N次模型預測來完成對這條慢查詢的索引推薦。
三、整體架構
基於AI+資料驅動的索引推薦的整體架構如下圖所示,主要分為兩個部分:模型訓練和模型部署。
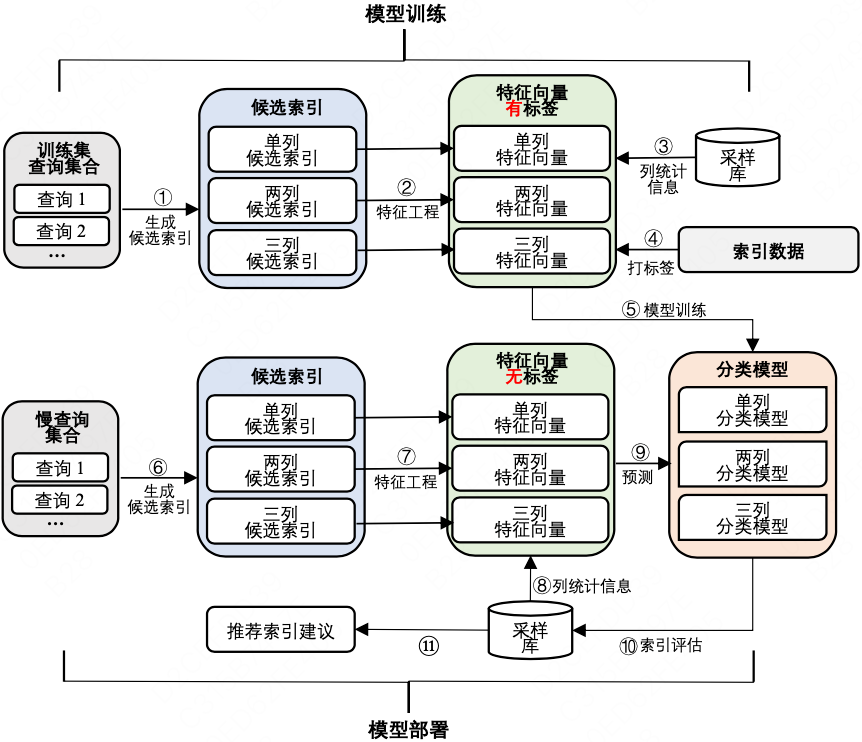
1、模型訓練
如上文所述,我們收集DAS平臺基於代價的慢查詢最佳化建議每天的索引推薦資料(包括慢查詢和被驗證有效的推薦索引)作為訓練資料。我們生成每條查詢的單列、兩列和三列候選索引,並透過特徵工程來為每個候選索引構建特徵向量,使用索引資料來為特徵向量打標籤。之後,單列、兩列和三列特徵向量將分別用於訓練單列、兩列和三列索引推薦模型。
2、模型部署
針對需要推薦索引的慢查詢,我們同樣生成候選索引並構建特徵向量。接下來,我們使用分類模型來預測特徵向量的標籤,即預測出候選索引中的有效索引。隨後,我們在取樣庫上建立模型預測出的有效索引,並透過實際執行查詢來觀察建立索引前後查詢效能是否得到改善。只有當查詢效能真正得到改善時,我們才會將索引推薦給使用者。
四、建模過程
1、生成候選索引
我們提取查詢中出現在聚合函式、WHERE、JOIN、ORDER BY、GROUP BY這些關鍵詞中的列作為單列候選索引,並對這些單列候選索引進行排列組合來生成兩列和三列候選索引。同時,我們會獲取查詢所涉及的表中已經存在的索引,並將其從候選索引集合中刪除。這一步驟遵循索引的最左字首原則:如果存在索引 Idx(col1,col2),那麼候選索引 (col1) 和 (col1,col2) 都將從候選索引集合中刪除。
2、特徵工程
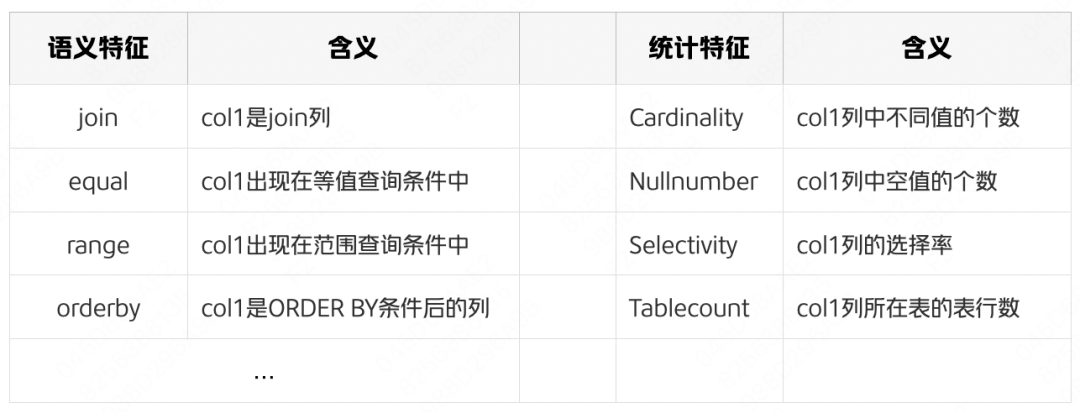
一個候選索引的特徵向量包括語句特徵和統計特徵兩部分。語句特徵描述了候選索引列在查詢中的出現位置(採用one-hot的編碼方式),統計特徵描述了候選索引列的統計資訊,如所在表的錶行數、Cardinality值、選擇率等,這些是判斷是否需要在候選索引列上建立索引的重要指標。
下表以單列候選索引(col1) 為例,展示了它的部分重要特徵及其含義:
兩列候選索引 (col1,col2) 的特徵是透過對單列候選索引 (col1) 和 (col2) 的特徵進行拼接而成的,此外,我們還會計算 (col1) 和 (col2) 共同的Cardinality值作為兩列候選索引 (col1,col2) 的額外統計特徵,以更加全面地描述其統計資訊。同樣地,我們也會採用使用這種方式來構建三列候選索引 (col1,col2,col3) 的特徵。在生成完一條查詢的特徵向量之後,我們使用這條查詢使用到的索引來為生成的特徵向量打標籤。
3、建模舉例
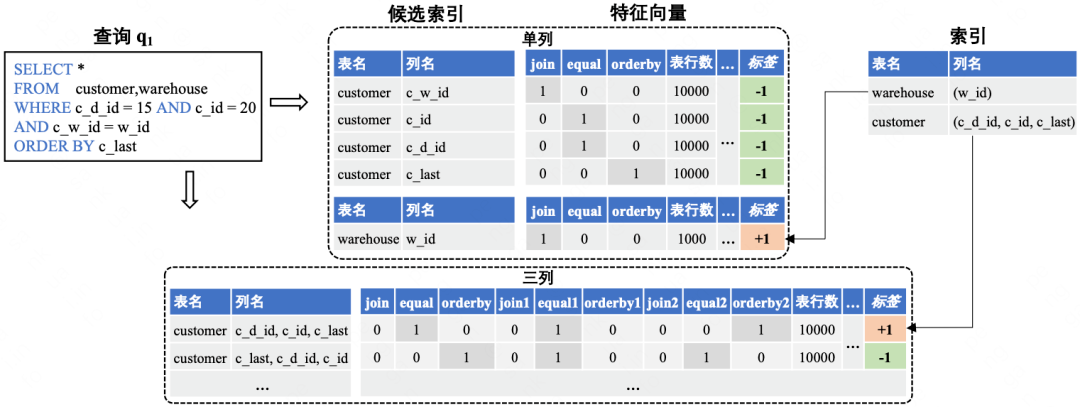
下圖以查詢 q1 為例,展示我們為訓練集中的一條查詢生成特徵向量並打標籤的過程。查詢 q1 涉及兩張表customer表和warehouse表,其中customer表的c_w_id、c_id、c_d_id、c_last四列參與到查詢中,因此對應生成四條單列特徵向量;warehouse表的w_id列參與到查詢中,因此只生成了一條單列特徵向量。查詢 q1 使用的單列索引為Idx(w_id),所以單列候選索引 (w_id) 對應的特徵向量被標記為正樣本,其餘特徵向量則被標記為負樣本。
接下來,我們對單列候選索引進行排列組合來生成多列候選索引及其特徵向量。由於查詢 q1 使用到的多列索引只有一個三列索引 Idx(c_d_id, c_id, c_last),因此我們跳過生成兩列候選索引,只生成三列候選索引。這是因為我們是基於查詢使用到的索引來為特徵向量打標籤的,如果查詢沒有使用到兩列索引,那麼生成的所有兩列特徵向量均為負樣本,這可能會導致訓練集正負樣本不均衡的問題。
最後,基於查詢使用到的三列索引,我們將三列候選索引 (c_d_id, c_id, c_last) 對應的特徵向量標記為正樣本。以上就是我們為查詢 q1 生成特徵向量並打標籤的整個過程,查詢 q1 為單列索引推薦模型的訓練集貢獻了五條樣本(一條正樣本,四條負樣本),為三列索引推薦模型的訓練集貢獻了六條樣本(一條正樣本,五條負樣本)。
4、模型預測和索引評估
在為一條慢查詢推薦索引時,我們依次生成慢查詢中所有的單列、雙列和三列候選索引,並透過上述的特徵工程來構造特徵向量。然後,我們將特徵向量輸入給對應的分類模型進行預測,並從三個分類模型的預測結果中分別挑選出一個預測機率最高的候選索引(即一個單列索引、一個兩列索引和一個三列索引)作為模型推薦的索引。
雖然推薦的索引越多,慢查詢的效能就越有可能得到改善,但是模型推薦的部分索引可能是無效的,這些無效索引帶來的儲存空間開銷和更新索引的開銷是不可忽視的。因此,直接將模型推薦的索引全部推薦給使用者是不合理的。為此,在將索引推薦給使用者之前,我們會首先將三個分類模型推薦的索引建立在取樣庫上進行驗證,取樣庫是線上資料庫的一個mini版本,它抽取了線上資料庫的部分資料。在取樣庫上,我們會觀察在建立推薦的索引之後,查詢的執行時間是否得到改善。如果得到改善,我們就把查詢使用到的一個或多個模型推薦的索引作為索引建議推薦給使用者。
五、專案執行情況
正如前文所述,美團DAS平臺目前採用代價方法和AI模型並行為慢查詢推薦索引。具體來說,AI模型可以在某些場景下,彌補代價方法漏選或錯選推薦索引的問題。就在剛過去的3月份,在代價方法推薦索引的基礎上,AI模型有額外12.16%的推薦索引被使用者所採納。
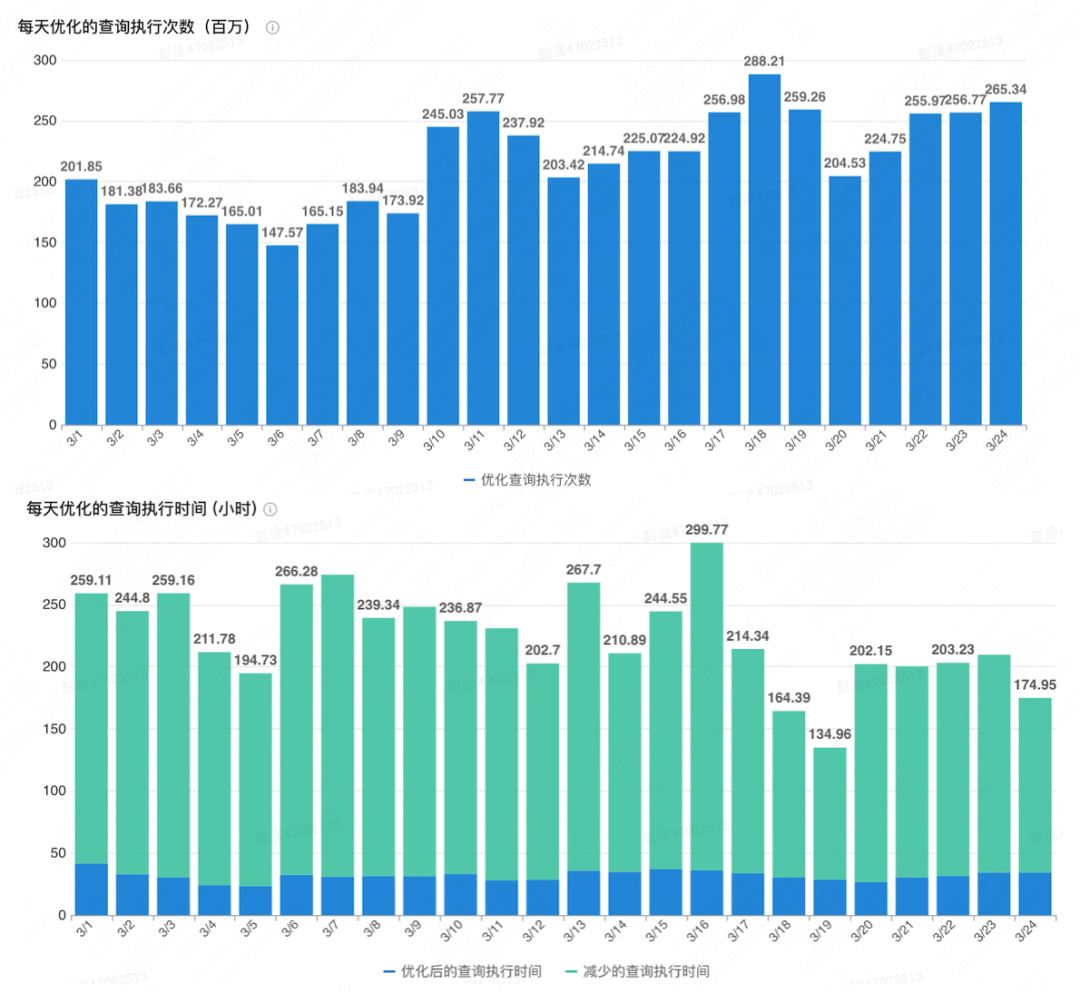
這些額外補充的索引對於查詢的改善情況如上圖所示:上半部分展示了最佳化的查詢執行次數,下半部分展示了查詢在使用推薦的索引之後的執行時間以及減少的執行時間,這些索引總計約最佳化了52億次的查詢執行,減少了4632小時的執行時間。
六、未來規劃
目前,大模型技術(如GPT-4)已經得到了越來越多的認可,幾乎可以勝任各種領域的任務。我們計劃嘗試透過Fine-Tune開源的大型語言模型(如Google開源的T5模型)來解決索引推薦的問題:輸入一條慢查詢,讓模型來生成針對慢查詢的索引建議。
在推薦索引無法改善慢查詢的情況下,後續我們可以提供一些文字建議來幫助使用者最佳化SQL,比如減少返回不必要的列,使用JOIN代替子查詢等。
參考資料
[1] Leis V, Gubichev A, Mirchev A, et al. 2015. How good are query optimizers, really? Proc. VLDB Endow. 9, 3 (2015), 204-215.
[2]
[3] Kossmann J, Halfpap S, Jankrift M, et al. 2020. Magic mirror in my hand, which is the best in the land? an experimental evaluation of index selection algorithms. Proc. VLDB Endow. 13,12 (2020), 2382-2395.
[4] Piatetsky-Shapiro G. 1983. The optimal selection of secondary indices is NP-complete. SIGMOD Record. 13,2 (1983), 72-75.
[5] Zhou X, Liu L, Li W, et al. 2022. Autoindex: An incremental index management system for dynamic workloads. In ICDE. 2196-2208.
來自 “ 美團技術團隊 ”, 原文作者:彭淦;原文連結:http://server.it168.com/a2023/0509/6802/000006802982.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 基於AI+資料驅動的慢查詢索引推薦AI索引
- MongoDB慢查詢與索引MongoDB索引
- 上億級別資料庫查詢資料庫
- 資料庫查詢慢的原因資料庫
- MySQL索引原理及慢查詢最佳化MySql索引
- 筆記 mongo查詢慢日誌,建立索引筆記Go索引
- indexedDB 通過索引查詢資料Index索引
- AppBoxFuture: 二級索引及索引掃描查詢資料APP索引
- 測試驅動開發(TDD)—— 資料庫查詢篇資料庫
- 慢查詢
- 為什麼我使用了索引,查詢還是慢?索引
- TableStore多元索引,大資料查詢的利器索引大資料
- 資料庫基礎查詢--單表查詢資料庫
- ClickHouse內幕(3)基於索引的查詢最佳化索引
- ES 20 - 查詢Elasticsearch中的資料 (基於DSL查詢, 包括查詢校驗match + bool + term)Elasticsearch
- MySQL慢查詢MySql
- MySQL 慢查詢MySql
- mysql 表資料量大量查詢慢如何優化MySql優化
- 關於MySQL 通用查詢日誌和慢查詢日誌分析MySql
- MySQL資料庫基礎——多表查詢:子查詢MySql資料庫
- PostgreSQL、KingBase 資料庫 ORDER BY LIMIT 查詢緩慢案例SQL資料庫MIT
- 【ElasticSearch】給ElasticSearch資料庫配置慢查詢日誌Elasticsearch資料庫
- Elasticsearch如何做到億級資料查詢毫秒級返回?Elasticsearch
- 資料庫MySQL一般查詢日誌或者慢查詢日誌歷史資料的清理資料庫MySql
- 《MySQL慢查詢優化》之SQL語句及索引優化MySql優化索引
- openGauss-索引推薦索引
- 推薦一款基於業務行為驅動開發(BDD)測試框架:Cucumber!框架
- 在MongoDB資料庫中查詢資料(上)MongoDB資料庫
- ElasticSearch分片互動過程(建立索引、刪除索引、查詢索引)Elasticsearch索引
- mongodb慢查詢分析MongoDB
- 基於滴滴雲 MySQL 驗證索引最佳化簡單查詢MySql索引
- 如何查詢上標
- 基於物件特徵的推薦物件特徵
- 很高興!終於踩到了慢查詢的坑
- 為什麼所有的查詢條件都命中索引還是那麼慢?記一次慢查詢優化過程索引優化
- 資料上雲,我推薦華為雲資料庫!資料庫
- PHP 5.3以上版本推薦使用mysqlnd驅動PHPMySql
- 二分查詢 | 二分查詢的一種推薦寫法