HDFS EC在B站的實踐
1.背景
隨著B站業務的高速發展,業務產生的資料每天以PB級的速度持續增長,之前主要應對方法是分析資料的使用頻率,把資料分為熱冷倆類資料,對冷資料進行高密儲存來降低儲存成本,以及對部分非核心的冷資料進行資料週期管理。隨著體量的增大,即使TTL機制的執行,冷資料的儲存量也越來越多,這部分資料長時間未有訪問,但仍然具有一定的價值,不能隨意清理,且佔總體資料量的30%以上,現有的高密儲存機制雖然能一定程度上降低儲存成本,但是為了進一步的降本增效,我們計劃用技術手段進一步節省儲存成本。
目前社群針對降低儲存容量的手段主要就是EC策略,我們為此推動了HDFS EC在B站儲存上進行實踐。
EC是什麼?Erasure Code(EC),即糾刪碼,是一種前向錯誤糾正技術(Forward Error Correction,FEC),是一種可透過計算降儲存的技術,相比多副本複製而言, 糾刪碼能夠以更小的資料冗餘度獲得更高資料可靠性,但編碼方式較複雜,需要大量計算。糾刪碼只能容忍資料丟失,無法容忍資料篡改,糾刪碼正是得名與此。Erasure Code可以將n份原始資料,增加m份資料,並能透過n+m份中的任意n份資料,還原為原始資料。即如果有任意小於等於m份的資料失效,仍然能透過剩下的資料還原出來。
就B站目前儲存的情況來看,Erasure Code能有效減少HDFS儲存空間,一個 256MB 的檔案按三副本方式儲存,需要在不同 DN 上存放 3 份完整的資料塊,消耗768M的空間,如果採用RS-6-3-1024k策略只需要384M,能降低50%的儲存,非常有利於實現降本增效的大目標。
2.HDFS EC整體方案
2.1 面臨的問題
HDFS在 3.0 版本中釋出了EC的重要特性,而我們當前是基於社群2.8.4版本,來構建B站的大資料生態,推動HDFS儲存支援EC儲存策略我們面臨一定的挑戰。主要有以下問題:
HDFS叢集版本較低,不相容EC。
目前B站基於社群2.8.4版本,而HDFS 3.0版本為了支援EC做了大量的修改,底層介面也發生了很大變化,而我們也在社群2.8.4版本的基礎上做了很多修改,如果將現有的叢集版本從2.8.4升級到3.x,不僅升級過程複雜,而且升級帶來的開發工作也非常巨大,我們需要在這個版本上進行取捨。
使用者使用的HDFS Client使用較雜亂,還有C++等版本的Client,難以相容而且還會給後續的開發。目前B站使用的HDFS Client主要有和叢集版本一致的2.8.4版本,presto使用的3.2版本,還有部分使用者使用的C++版本,相對較為複雜,統一使用版本從短期來看不太可能,為了儘快推動EC上線,緩解儲存壓力,我們需要支援部分非標的Client讀取EC資料。
2.2 設計選型
如上所述,推動HDFS EC策略在B站使用的主要矛盾是在於2.8.4版本的HDFS 叢集無法支援EC儲存策略,各種版本的HDFS Client無法支援讀寫EC儲存策略,解決該主要矛盾面臨的核心問題是如何使得HDFS儲存叢集和HDFS Client均能支援EC儲存策略,讀取EC資料。帶著上面的核心問題,我們調研了業界大廠的EC儲存策略解決方案,主要集中在叢集升級為3.x版本以上(京東,快手等),相對代價較大耗時較久,考慮到我們已經引入了RBF,支援多個叢集之間進行資料遷移和資料讀寫,因此我們結合社群的Hadoop 3.3 版本實現了B站自身的HDFS EC策略實現方案,如圖2-1所示。

圖2-1 HDFS EC轉換總體架構
Hadoop HDFS 3.3 原生支援EC資料讀寫,我們backport 之前在2.8.4版本上進行部分改動,部署了3.x版本的HDFS叢集;
HDFS Router 新增EC掛載點,支援新增資料寫入2.8.4叢集,歷史資料進行EC轉換,存放在3.3版本的HDFS叢集中;
2.8.4 版本的HDFS Client 合併 EC相關Patch ,支援對EC資料的讀寫操作;
開發EC Data Proxy 服務,相容老版本HDFS Client 以及C++ 等Client 讀取EC資料;
構建HDFS Block Checker機制,確保EC資料的可靠性;
構建智慧EC冷備策略,從元倉中篩選出可EC的資料,推動EC資料轉換。
2.3 總體流程
圖2-2展示我們在推動B站 HDFS EC 策略落地的總體流程,我們部署了3.3版本的EC叢集,在RBF側改造了掛載點支援EC資料轉換對使用者透明,改造了2.8.4版本的HDFS Client支援EC資料讀寫,落地了DataProxyServer服務用於野生客戶端,推動智慧EC轉換工具的實現,協調各個部門推進大量的冷資料轉換為EC儲存。

圖2-2 HDFS EC實踐總體流程
3.HDFS EC方案實現
下面章節會對HDFS EC方案的整體實現環節進行介紹, 包括Data Proxy,智慧資料路由服務,HDFS EC Block Checker,智慧EC資料轉換服務。
3.1 DN Proxy實現
在B站使用HDFS儲存服務的相關業務中,除了標準的Java 客戶端外,還有C++,Python的客戶端,由於低版本的HDFS Client 和 C++等客戶端並不相容讀取EC資料,而推動業務升級非管控的野生客戶端非常費時費力,還極有可能出現無法相容的場景(如修改C++的client支援EC資料,工作量巨大收益極小),但如果不相容這類客戶端的資料讀取便無法做到對上層業務透明,為了確保整個資料EC遷移的過程對上層業務透明,減少遷移的阻力,我們調研了業界的相關方案,自研實現了Data Proxy 服務,支援2.8.4版本HDFS pb協議的所有客戶端都能讀取EC資料。
以下簡單介紹一下Data Proxy服務,如圖3-1所示:
首先在2.8.4版本的HDFS Client 的基礎上,移植EC資料讀寫的相關Patch,支援讀取EC資料,同時配置HDFS Client對NameNode的訪問透過CallerContext透傳Client Version資訊,並約定某個版本之後的Client 支援讀取EC資料;
其次,EC叢集的NameNode 對訪問EC資料的Client驗證版本資訊,對低於設定版本的Client和未設定版本的Client(如C++版本的HDFS Client)返回Data Proxy埠,讓其訪問Data Proxy Server,對高於設定版本的HDFS Client (已經知道EC資料讀取的Client)返回 DataNode Xceiver 埠,正常訪問EC資料;
我們在3.3 版本HDFS DataNode服務基礎上,仿照DataXceiver實現了ErasureCodingDataXceiver新增單獨埠用於轉化EC資料,當使用Replication-Based Data Transfer Protocol 協議支援低版本Client 請求時,Data Proxy服務根據請求資訊讀取多個DN的EC資料,聚合後按照Replication-Based Data Transfer Protocol 協議返回Client對應的資料流。
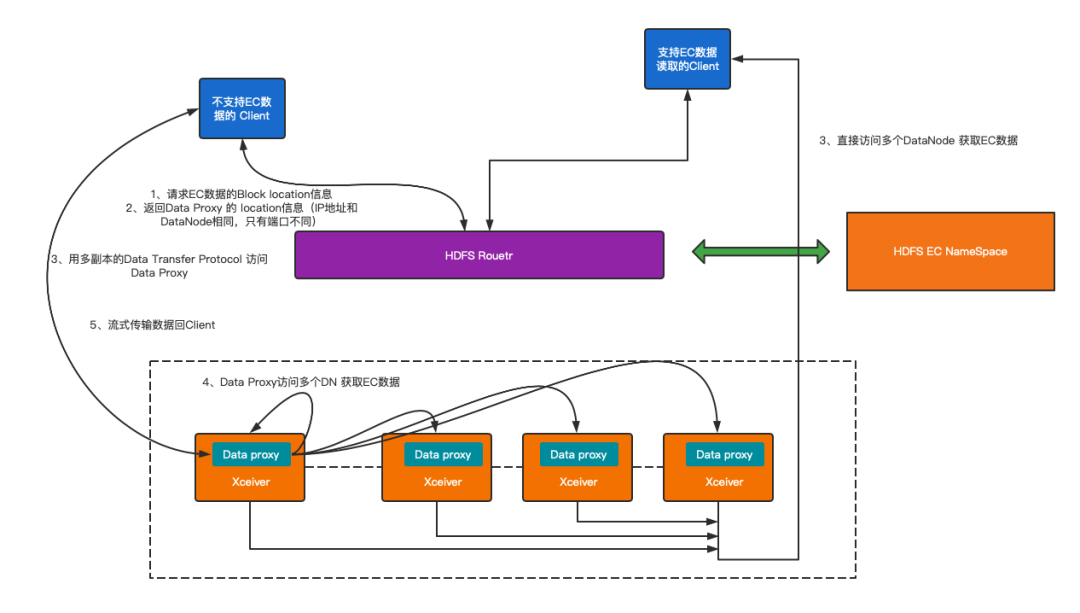
圖3-1 Data Proxy 總體架構
3.2 智慧資料路由體系
在之前的工作中,我們已經推動HDFS Client接入HDFS DFSRouter服務來訪問後端多達20組的NameSpace,當前使用者資料訪問99.9% 透過RBF透傳到後端的HDFS,因此我們在RBF側配置智慧資料路由體系,支援使用者透明訪問EC資料,同時方便我們進行EC資料轉換,如圖3-2所示。
在社群版本的HDFS Router 基礎上,定製化開發EC掛載點型別支援EC資料遷移,該掛載點支援一個掛載點配置多個NameSpace,新寫入資料會按規則路由到最靠前的HOT的NameSpace中,但歷史資料和EC資料仍然可見,透過這種方式,我們能確保資料讀取的一致性;
建設了EC遷移工具,能在業務低峰時期自動化的非同步遷移多副本的冷資料到支援EC的NameSpace中,將冷資料轉換成EC儲存,節省儲存空間;
基於HDFS元倉,不斷分析出需要轉換的EC資料,用於指導哪些資料需要遷移。

圖3-2 智慧資料路由服務
3.3 Block Checker
HDFS EC儲存策略,採用編碼的方式對資料進行拆分,在B站的實踐中,主要採用了RS6-3的編碼方式,將一個Block拆分成9個副本進行儲存,其中包括6個資料塊和3個校驗塊,損失3個副本內都能透過設定的演算法重構丟失的副本,但同行的經驗和HDFS EC的發展過程中都曾經出現過因某些原因導致資料損壞的場景出現,一旦發生資料塊的資料錯誤,而無法及時發現,導致下游資料錯亂,將會造成更大的影響,為了確保資料的準確性和完整性,我們自研的HDFS BlockChecker 元件(圖3-3),確保EC資料的每個Block在重建後資料的準確性。
由HDFS EC資料的寫入原理上來看,每個寫入的Block存在真實資料和meta資訊,meta資訊記錄了Block真實資料的校驗資訊,每512位元組生成1個位元組的校驗資訊,HDFS 本身的checksum機制就是讀取block的meta資訊進行校驗;
HDFS DataNode在接收Block副本寫入完成後,會進行finalizeBlock操作,此時,我們獲取副本meta資訊的 Crc 校驗值,儲存到kv儲存服務中;
當HDFS進行資料重構時,DataNode 收到來自 Namenode 的重建命令,從滿足重構要求的最少DN節點讀取資料,根據獲取的資料透過演算法解碼出目標DN的資料,將資料以packet為單位傳輸至目標DN,在這個過程中,我們透過ComposedCrc 計算每個packet的checksum資訊,最後當資料塊傳輸完成後,我們可以獲得這個重構副本的meta資訊的crc校驗值,我們將這個校驗值和kv儲存中的校驗值進行對比,確保資料的準確性。

圖3-3 HDFS Block Checker 元件
3.4 智慧EC冷備策略
在上線EC策略過程中,我們在完成了基礎的EC實現方案上線後,如何推動使用者配置EC策略就成了我們日常運營的一部分工作。當前我們的 HDFS叢集上儲存著分割槽表、無分割槽表和非表結構的資料,我們初期只針對有分割槽表進行EC儲存策略轉換,按照分割槽級別的力度進行轉換。實踐過程中我們發現,推動使用者按表級別配置EC策略相對困難,且非常耗費人力且成效不足,為此我們在支援使用者配置表級別的EC轉換策略的基礎上,實現了智慧EC的篩選策略,配合HDFS元倉,篩選出我們定義為冷資料的資料進行EC轉換。
我們定義的冷資料主要由以下幾點特性:
分割槽路徑下所有檔案距今未修改的天數 < 冷備期限 ;
最近x天表分割槽的 cmd= ‘OPEN’ 操作次數 < EC冷存閾值;
最近x天表分割槽被查詢引擎讀取的次數 < EC冷存閾值;
在制定出需要進行EC的規則後,我們實現瞭如下圖所示的EC轉換流程。
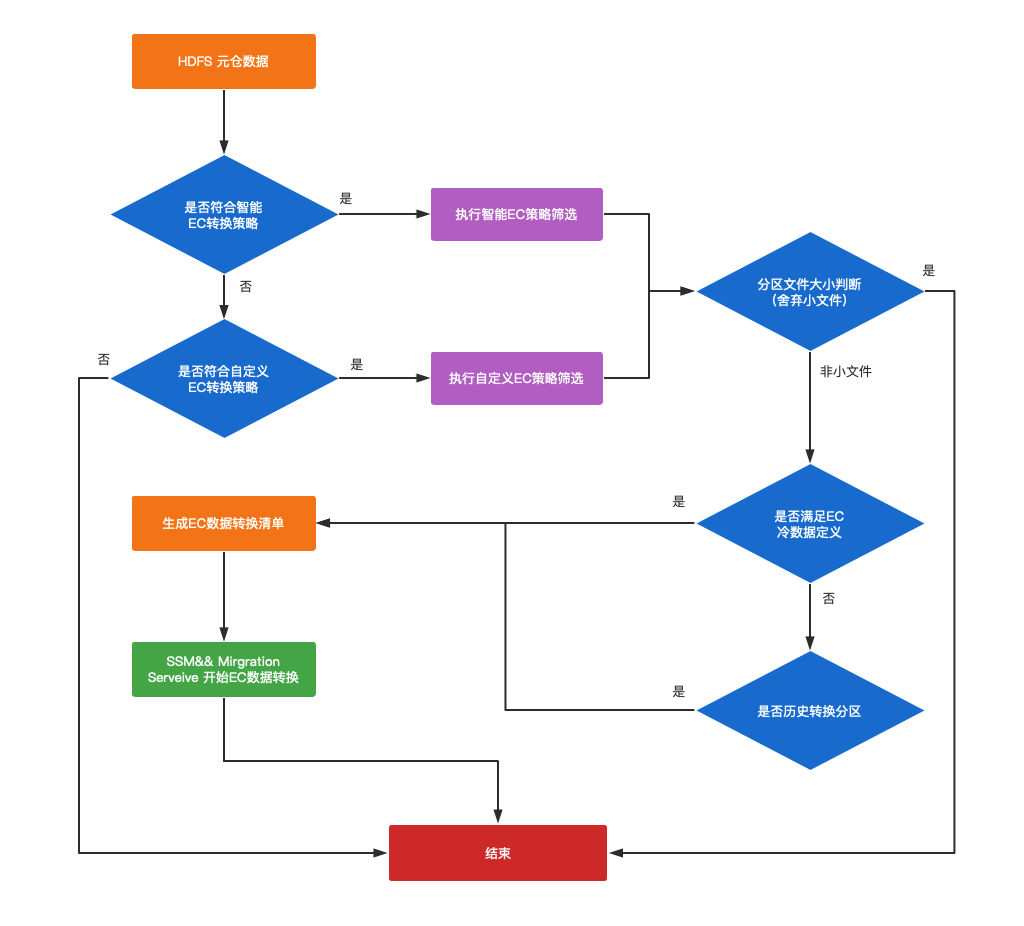
圖3-4 分割槽冷備流程圖
HDFS 元倉記錄了表分割槽的冷備標識,讀寫次數、資料年齡、冷備期限等資訊;
根據使用者選擇 自定義冷備(使用者指定) OR “智慧冷備”(由管理員負責按策略冷備),依據不同的冷備引數(EC冷備期限,EC冷存閾值)篩選出需要進行冷存的表;
判斷分割槽下平均檔案大小,過濾檔案Size小於3M的檔案的分割槽;
由於其他資料治理服務會影響已經轉成EC的資料(如zstd轉表任務、z-order重組織任務會重寫EC資料為多副本資料;資料遷移服務,回刷任務等會破壞資料年齡的判定條件等),我們會根據歷史資料是否滿足EC冷存條件將這類分割槽重新進行EC轉換;
對於滿足冷分割槽的定義的分割槽最終會由EC轉換服務進行EC轉換。
4.總結與展望
經過上述EC相關策略和工具的不斷落地,我們的EC功能已經在生產環境下執行了不短的時間,已經將大量的資料進行EC轉換,迄今為止,儲存了上百PB的資料(如圖4-1所示),為公司節省了上千臺伺服器成本。從當前的結果來看該方案能有效降低HDFS儲存成本,但較之前的多副本儲存相比,EC儲存也有一定的不足之處,如寫效能損失,小檔案不適合進行EC轉換,EC叢集DataNode節點上塊數量的暴增等,但相信隨著技術的發展,EC技術也會不斷進步。
隨著EC叢集資料量的不斷增長,在接下來的時間裡,我們也將推動使用 native 方法加速 EC 資料的編解碼效率,同時提升EC功能的穩定性,向社群回饋我們的改造,與社群一起努力建設更加穩定,更加效率的HDFS儲存系統。
來自 “ 嗶哩嗶哩技術 ”, 原文作者:陳世雲;原文連結:http://server.it168.com/a2023/0315/6794/000006794020.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- HLS直播協議在B站的實踐協議
- Flink 在 B 站的多元化探索與實踐
- Apache Hudi 在 B 站構建實時資料湖的實踐Apache
- HDFS3.2升級在滴滴的實踐S3
- DWDM技術在B站基礎工程的落地實踐之路
- B站故障演練平臺實踐
- 節省數億IT成本,B站FinOps實踐
- B站雲原生混部技術實踐
- B 站構建實時資料湖的探索和實踐
- B站資深運維工程師:DCDN在遊戲應用加速中的實踐運維工程師遊戲
- B站公網架構實踐及演進架構
- 在B站學Java!Java
- B站基於Iceberg的湖倉一體架構實踐架構
- B站基於Flink的海量使用者行為實時ETL實踐
- B站的資料質量管理——理論大綱與實踐
- 節省數億IT成本,B站FinOps最佳化實踐
- B站大資料系統診斷實踐-SQLSCAN篇大資料SQL
- Presto + Alluxio:B站資料庫系統效能提升實踐RESTUX資料庫
- Flutter 在哈囉出行 B 端創新業務的實踐Flutter
- B站運維數倉建設和資料治理實踐運維
- B站基於K8S的雲原生混部技術實踐K8S
- B站基於ClickHouse的海量使用者行為分析應用實踐
- vivo 萬臺規模 HDFS 叢集升級 HDFS 3.x 實踐
- Elasticsearch在Hdfs上build的實現及優化ElasticsearchUI優化
- Vodafone A/B測試實踐
- 青春不老 - B站的微服務與持續交付實踐|IDCF DevOps案例研究微服務dev
- B站萬億級資料庫選型與架構設計實踐資料庫架構
- HDFS系列之DataNode磁碟管理解析及實踐!
- 林意群:eBay HDFS架構的演進優化實踐架構優化
- B站繼續在深水區掙扎
- 刷B站的年輕人,到底在刷什麼?
- 利用PHP擴充套件Taint找出網站的潛在安全漏洞實踐PHP套件AI網站
- axios在vue中的實踐iOSVue
- Jenkins 在 Kubernetes 上的實踐Jenkins
- Elasticsearch在Laravel中的實踐ElasticsearchLaravel
- 大資料專案實踐(一)——之HDFS叢集配置大資料
- 開源實踐 | 攜程在OceanBase的探索與實踐
- 開源實踐 | 攜程在 OceanBase 的探索與實踐