B站基於K8S的雲原生混部技術實踐
一、背景
中大型網際網路公司的伺服器數量可達萬級別,在降本增效的大背景下,機器資源利用率的重要性日益凸顯。如何在確保服務SLO影響最小的情況下提高機器資源利用率,從而降低伺服器的採購成本,是一項非常值得研究的課題。
對於k8s雲平臺來說,造成機器平均資源利用率低的原因可以概括為以下幾點:
1)業務申請的資源配額超過實際使用量。即使用者在申請資源時可能會對服務的真實資源使用情況估計不足,一般傾向於申請過量的資源。這就導致機器配額被佔滿,無法繼續排程容器,而實際資源利用率卻很低。
2)服務的資源使用量存在波峰波谷。大部分服務的負載都會存在高低峰,當服務處於波谷的時候就會存在很大的資源浪費。
針對上述問題1),我們可以透過服務畫像給業務推薦一個合理的資源配置值,並結合彈性伸縮的手段來解決。
針對上述問題2),關鍵點在於如何將業務波谷時空閒出來的那部分資源利用起來,比如凌晨線上業務處於波谷的時候,往線上叢集排程適量的離線任務。
目前B站私有云平臺已經達到較大的機器規模,我們從上述兩個思路出發來給整體雲平臺降本:一方面提供了hpa和vpa的彈性伸縮能力,使得業務資源配額使用更為合理;另一方面,我們實施了較大規模的業務混部來解決算力的閒置問題。本文將主要分享B站雲平臺的混部實踐,而彈性伸縮方面的實踐我們會擇機在後續文章中介紹。
二、混部的概念
我們把業務劃分為線上業務和離線業務。線上業務一般是各類微服務,特點是延時敏感、有很高的可用性要求,如推薦、廣告、搜尋等服務;離線業務一般是批處理任務,特點是延時不敏感、允許出錯重跑,如大資料場景中的MapReduce任務、影片處理中的轉碼任務等。所謂混部技術,就是透過排程、資源隔離等手段,將不同型別、不同優先順序的在離線業務部署在相同的物理機器上,並且保證業務的SLO,最終達到提高資源利用率、降低成本的目的。需要注意的是,混部不是簡單地將容器部署到同一臺宿主機上,而是需要透過排程演算法將混部任務排程到具有空閒資源的機器,同時需要有隔離機制來保證高優任務不會受到混部任務的干擾。
三、B站混部的場景
1、在離線混部
B站是一個影片類網站,存在大量的點播影片轉碼任務,這類任務屬於計算密集型,具有執行時間短、允許失敗重試等特點。另外,在凌晨時段會觸發大量的轉碼定時任務,剛好和線上業務形成錯峰。我們透過在離線混部技術將轉碼任務排程到線上叢集,既提高了線上叢集的資源使用率,又補充了轉碼任務高峰期時的算力缺口,極大地降低了伺服器成本。這類混部場景的難點在於:
1)排程層
混部任務不能影響線上任務的整體配額容量,例如機器一共64核,如果混部任務直接申請32核的cpu request資源,那就會造成該機器只能排程32c的線上業務容器。
排程器需要動態感知到各個節點可混部資源量的變化,資源空閒越多的節點排程越多的混部任務。
2)節點層
混部任務一旦排程到某個k8s節點後,在cpu、記憶體、磁碟、網路等各個資源層面都有可能對線上任務產生“競爭”,因此需要隨時感知線上任務的負載情況並做相應的隔離管控,儘量做到對線上任務零干擾。
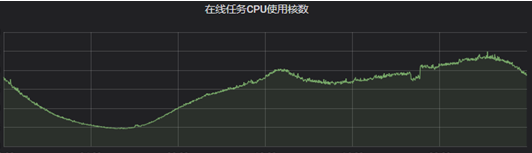
2、離線間混部
離線叢集整體的cpu使用率較高,但部分時段也存在一定的資源閒置,例如訓練平臺在訓練任務較少時整體利用率會偏低。由於都是離線任務,延時敏感性沒有線上那麼高,因此這類場景除了混部轉碼任務外,還可以混部一些更“重”的大資料任務。但是大資料任務通常用yarn排程,如何將k8s排程和yarn排程進行協調是我們需要解決的關鍵問題。實現了大資料混部後,我們就可以做到各個離線業務互相出讓資源。例如將hdfs datanode機器接入k8s用於混部轉碼任務;反過來,轉碼的機器上也可以執行hadoop/spark等大資料任務。
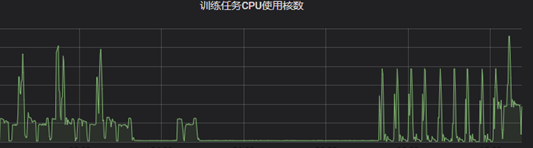
3、閒置機器混部
IDC通常會存在一定量的備機,用於各業務應急場景使用,但是日常是閒置的。這部分機器我們也會自動化接入k8s跑混部任務,當業務需要借調備機時再自動下線混部。
下面,我們結合在離線混部和離線間混部這兩個場景,具體介紹一下混部的關鍵技術點。
四、在離線混部
1、總體架構

任務提交模組
caster是我們的線上業務釋出平臺,crm則是離線批處理任務提交平臺。crm可以支援多叢集排程、混部資源餘量統計、混部資源quota管控等。
k8s排程模組
kube-scheduler為原生的線上任務排程器,而job-scheduler是我們自研的離線任務排程器,能支援轉碼任務的高併發排程。另外webhook負責對離線任務的資源配額進行動態轉換,轉換為自定義的k8s擴充套件資源。
colocation-agent
每個k8s節點上都會部署混部agent,負責混部算力動態計算和上報、資源隔離、監控資料上報等。
colocation config manager
在大規模k8s叢集中,各類節點的混部配置存在一定的差異性,同時也存在動態更新的需求。該模組負責對混部配置進行集中管控,支援策略下發、開關混部等功能。
混部的可觀測性
每個節點的agent負責採集節點中的一些混部指標,例如:可混部資源量、實際的混部資源用量等,最終上報給prometheus進行看板展示。可觀測性對於排查單機的混部問題非常有用,我們可以很方便地透過監控曲線來檢視某個時刻的混部資源使用情況。同時,我們也可以隨時檢視整體叢集的混部算力使用趨勢。
下面,我們從混部任務排程、線上QoS保障兩方面來介紹在離線混部的關鍵技術點。
2、混部任務排程
1)k8s原生排程器的基本原理和問題
k8s的每個節點都會上報節點資源總量(例如allocatable cpu)。對於一個待排程的pod,k8s排程器會檢視pod的資源請求配額(例如cpu reqeust)以及相關排程約束,然後經過預選和優選階段,最終挑選出一個合適的node用於部署該pod。如果混部任務直接使用這套原生的排程機制會存在幾個問題:
混部pod會佔用原生的資源配額(例如cpu request),這會導致線上任務釋出的時候沒有可用資源;
原生排程本質是靜態排程,沒有考慮機器實際負載,因此沒法有效地將混部任務排程到實際負載有空閒的機器上。
2)基於擴充套件資源的混部排程
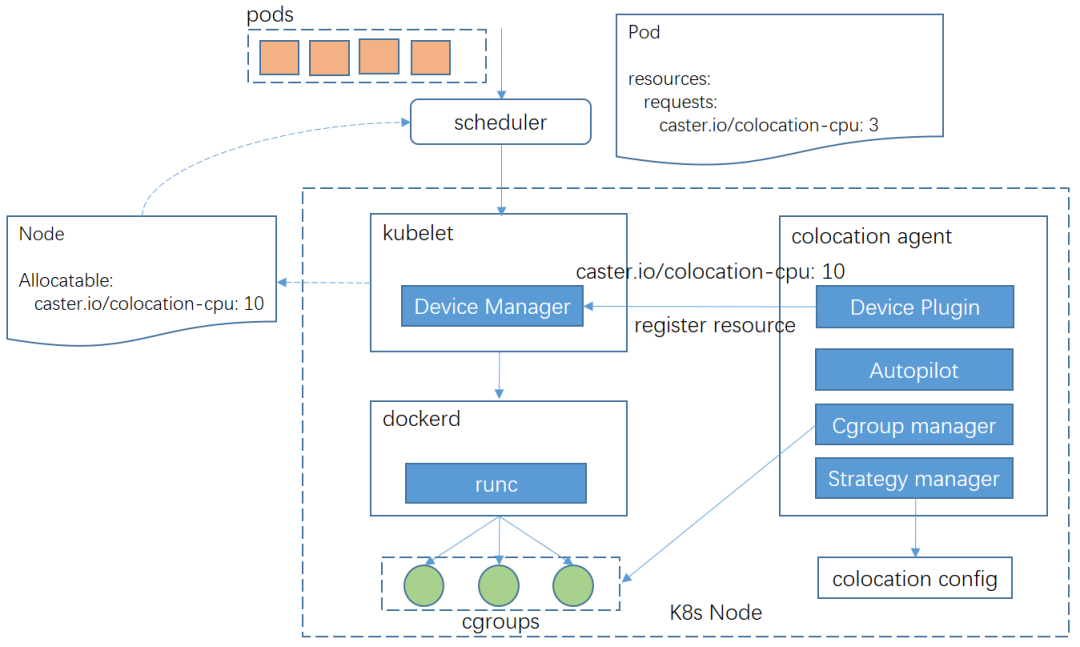
為了解決上述問題,我們基於k8s的擴充套件資源進行混部任務排程,整體分為3個步驟:
①colocation agent模組中,策略元件會實時載入當前接收到的混部配置,並呼叫autopilot元件進行混部算力的計算,然後透過device-plugin元件上報混部擴充套件資源,例如caster.io/colocation-cpu
②混部任務在申請資源配額時,仍然申請原生cpu資源,但是會增加pod標籤“caster.io/resource-type: colocation”。k8s webhook模組根據標籤識別到混部pod,然後將pod申請的資源修改為混部擴充套件資源。這種方式對業務層遮蔽了底層擴充套件資源,透過標註pod標籤即可指定是否使用混部資源。
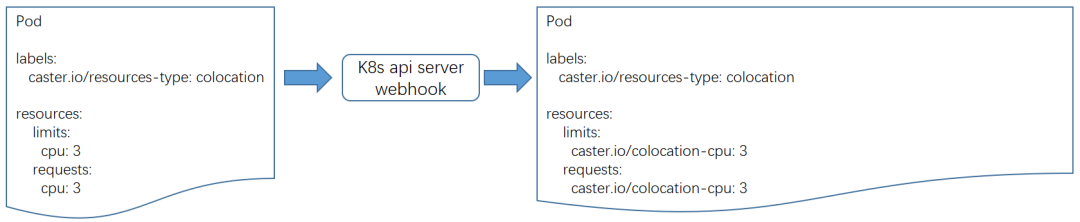
③混部排程器job-scheduler根據pod申請的擴充套件資源量以及各個節點上報的混部擴充套件資源量進行排程。我們利用轉碼pod存在同質化(資源規格和排程約束相同)的特點對排程器進行了最佳化,基本思路是:
將pod與排程相關的欄位進行hash值計算,並在排程佇列中按hash值排序pod
pod預選的結果同樣也滿足其他同質化pod的要求,因此將預選node進行快取
當前處理的pod若是同質化pod,則從快取中直接選取一個節點進行排程
3)混部資源量計算
k8s node是怎麼確定當前節點應該上報多少混部擴充套件資源量的呢?我們針對不同的應用場景設計了不同的混部策略演算法:
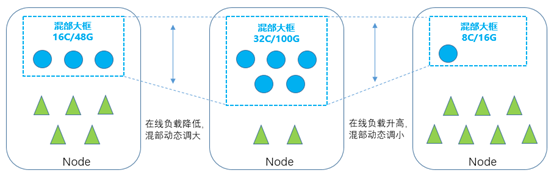
動態計算
針對各類物理資源,例如cpu、memory等,我們會分別設定機器的安全水位值n%。agent會實時探測線上程式的資源使用量online_usage,然後根據安全水位和線上負載動態計算出可混部資源量。線上使用量和可混部資源量是此消彼長的,隨著線上使用量上升,我們上報的可混部量就會下降,反之,當線上使用量下降,可混部量就會上升。
靜態計算
例如備機池閒置機器沒有線上業務,不需要動態資源計算,因此我們可以配置靜態上報策略,上報固定的可混部資源量即可。
分時計算
如果部分線上業務在某些時間段不希望部署混部任務,我們就需要用到分時策略,即在某些時間段關閉混部或者減少上報混部資源量。另外,我們還支援設定grace period,在分時混部結束前,會提前停止排程混部任務到該k8s node,並等待存量任務結束,做到優雅退出。
3、線上QoS保障
資源隔離是混部架構的關鍵難點。我們希望在提高單機混部資源量的同時,儘可能地降低混部任務對線上業務的效能影響。主要從三個層次來保障線上業務的QoS:
任務排程
根據前文所述的混部任務排程機制,混部排程器可以實時感知各節點的可混部資源量,因此可以從全域性視角將混部任務排程到資源充足的節點上。
資源隔離
節點混部agent可以秒級檢測線上負載變化,根據安全水位值計算當前可混部資源量,然後透過cgroup及時進行資源限制。
任務驅逐
離線的混部任務一般都是可重試的,因此驅逐可以作為一種兜底手段。
下面我們詳細介紹一下資源隔離層的幾種策略。
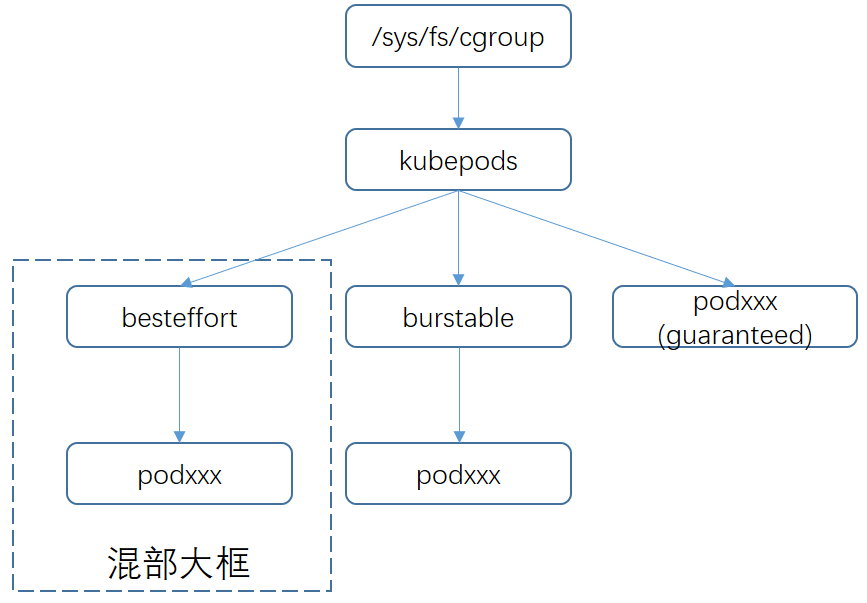
1)混部大框
在前面的介紹中我們提到webhook會對混部任務申請的資源型別進行修改,去除原生的資源型別request.cpu和request.memory,改成caster.io/colocation-cpu和caster.io/colocation-memory。由於沒有申請原生資源型別,那麼k8s會自動將這類pod歸類為best effort型別,並且最終透過runc將該類pod的cgroup設定到/sys/fs/cgroup/cpu/kubepods/besteffort目錄,我們稱為“混部大框”。
2)cpu動態隔離
在cgroup層面,我們給大框設定了最小的cpu share值,保證在資源爭搶時,混部任務獲得cpu時間片的權重最小。
colocation agent中的cgroup manager元件負責動態地調整“混部大框”的cpu quota,從而對混部任務進行整體的資源限制。當colocation agent檢測到線上負載降低時,就會調大“混部大框”的cpu quota,讓混部任務充分利用空閒的算力。當線上負載升高時,則是縮小“混部大框”的cpu quota,快速讓出資源給線上業務使用。
此外,我們透過cpuset cgroup對整體混部大框做了綁核處理,避免混部任務程式頻繁切換干擾線上業務程式。當混部算力改變時,agent會給大框動態選取相應的cpu核心進行繫結。另外,選取cpu核心的時候也考慮了cpu HT,即儘量將同一個物理核上的邏輯核同時繫結給混部任務使用。否則,如果線上任務和混部任務分別跑在一個物理核的兩個邏輯核上,線上任務還是有可能受到“noisy neighbor”干擾。
3)記憶體動態隔離
與cpu隔離方式類似,colocation agent會根據當前線上業務記憶體使用情況,動態擴縮混部大框的memory quota。另外,透過調節oom_score_adj,混部任務的oom_sore被設為最大值,保證oom時混部任務儘量優先被驅逐。
4)網路頻寬限制
我們使用了cni-adaptor元件,使得k8s node可以支援多種網路模式,對於轉碼混部任務,通常不需要被外部訪問,因此透過annotation可以指定bridge網路模式,分配host-local的ip,避免佔用全域性網段中的ip資源。同時也利用了linux tc進行混部pod的網路頻寬限制。
5)驅逐機制
混部agent層支援記憶體、磁碟、cpu load等維度的驅逐機制。當任意資源負載達到設定的驅逐水位時,agent會立即驅逐機器上的混部任務。為了防止任務在同一臺機器上被頻繁驅逐,需要在驅逐後設定一定的冷卻時間,冷卻期內禁止排程混部任務。
五、離線間混部
針對訓練、轉碼等離線叢集跑大資料混部任務的場景,我們基於在離線混部框架做了功能增強,其關鍵點在於yarn nodemanager on k8s。具體的排程步驟為:
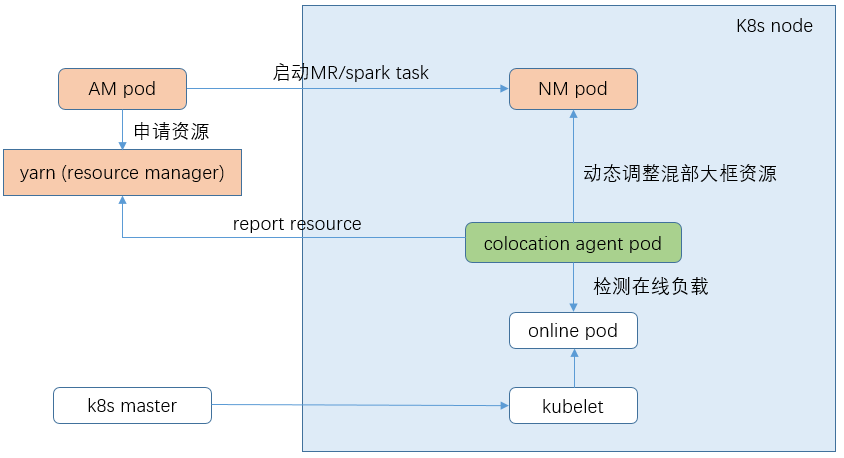
1)yarn node manager以daemonset的形式部署在相應的混部節點上
2)節點上的混部agent會動態檢測線上容器負載變化,並根據設定的混部策略計算可混部值。這個值一方面會透過介面上報給yarn rm,另外一方面會設定到混部大框的cgroup中進行動態的資源限制
3)使用者把大資料任務提交到混部叢集時,rm會找到叢集中有充足資源的混部節點,並最終在nm中拉起task
為了降低大資料任務對非混部業務的影響,大資料團隊也做了相關技術改造,例如支援remote shuffle、基於應用畫像識別小規格任務進行排程等。
六、混部管理平臺
我們開發了介面化的混部管理平臺來支撐日常的運維需求。主要功能包括:
策略管理
支援批次檢視和設定節點的混部策略,例如安全水位、硬限值等。同時也支援設定節點組,只要節點打上對應的組標籤,管控層可以秒級感知並立即下發相應混部策略。
開關混部
如果臨時需要對特定機器關閉混部,可以在平臺進行一鍵關閉,此時會立即驅逐機器上的混部任務並且停止上報混部資源。
監控檢視
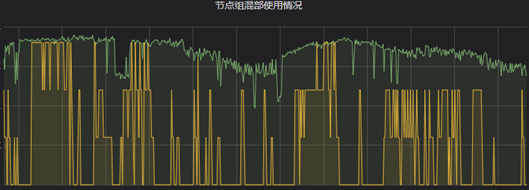
單機粒度監控主要滿足日常排障需求,可以精確檢視某一時刻機器上的混部上報量、混部任務數、混部實際資源消耗等。節點組粒度的監控則可以評估這批機器整體貢獻的混部量以及對應的使用情況。

七、混部效果
目前B站雲平臺大部分機器都參與了混部,混部機器的平均cpu使用率可以達到35%,峰值使用率則可以達到55%左右。這些混部算力支撐了B站大規模的影片轉碼任務,以及ai機審、大資料MR等任務,節省了數千臺機器的採購成本。
八、總結
本文介紹了B站基於k8s雲平臺進行的混部實踐,主要分為在離線混部、離線間混部等業務場景。我們採用了一套對k8s無侵入的混部框架,並且透過排程、資源隔離等手段來確保非混部業務的SLO,另外也開發了相關的監控、策略管理平臺等來提高整體混部系統的可運維性。後續我們會在核心層隔離與可觀測、統一排程等方面最佳化混部技術框架,持續助力雲平臺降本。
來自 “ dbaplus社群 ”, 原文作者:許龍;原文連結:http://server.it168.com/a2022/1229/6783/000006783279.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- B站雲原生混部技術實踐
- 雲原生 SIG:關於 Koordinator 混部原理及最佳實踐 | 第 43 期
- 助力Koordinator雲原生單機混部,龍蜥混部技術提升CPU利用率達60%|龍蜥技術
- DWDM技術在B站基礎工程的落地實踐之路
- 雲原生技術領域的探索與實踐
- 【雲原生下離線上混部實踐系列】深入淺出 Google BorgGo
- 基於雲原生技術的融合通訊是如何實現的?
- 混部之殤-論雲原生資源隔離技術之CPU隔離(一)
- 雲原生技術實踐營 · 深圳站——Serverless + AI 專場開啟報名!ServerAI
- 雲上影片業務基於邊緣容器的技術實踐
- 基於雲原生的大資料實時分析方案實踐大資料
- B站基於Iceberg的湖倉一體架構實踐架構
- 中國銀行雲原生技術探索與實踐
- 技術集錦 | 大資料雲原生技術實戰及最佳實踐系列大資料
- 雲原生技術在離線交付場景中的實踐
- 雲上視訊業務基於邊緣容器的技術實踐
- 藏書館App基於Rainbond實現雲原生DevOps的實踐APPAIdev
- CCE雲原生混部場景下的測試案例
- B站基於Flink的海量使用者行為實時ETL實踐
- 技術沙龍 | 雲時代下的架構演進—企業雲及雲原生技術落地實踐架構
- 基於雲原生閘道器的可觀測性最佳實踐
- 雲原生技術
- 基於雲原生技術打造全球融合通訊閘道器
- B站基於ClickHouse的海量使用者行為分析應用實踐
- 銀行基於雲原生架構的 DevOps 建設實踐經驗架構dev
- 活動回顧|雲原生技術實踐營Serverless + AI 專場 (深圳站) 回顧&PPT下載ServerAI
- 基於kubernetes自研容器管理平臺的技術實踐
- 青雲雲原生沙龍線上集結,找到屬於你的雲原生實踐之路!
- 百度基於雲原生的推薦系統設計與實踐
- .NET雲原生應用實踐(四):基於Keycloak的認證與授權
- vivo 在離線混部探索與實踐
- 阿里開源雲原生混部系統Koordinator正式開源阿里
- 阿里巴巴雲原生混部系統 Koordinator 正式開源阿里
- 2022 年第一場雲原生技術實踐營開啟報名
- HDFS EC在B站的實踐
- 申通的雲原生實踐之路:如何實現應用基於容器的微服務改造?微服務
- 基於 Coolbpf 的應用可觀測實踐 | 龍蜥技術
- 基於 Gitlab + Harbor + K8s + Kuboard 的 CI 實踐GitlabK8S