玖章算術CEO葉正盛:程式設計師必須掌握的資料庫原理
本文根據葉正盛在【第十三屆中國資料庫技術大會(DTCC2022)】線上演講內容整理而成。

本期分享嘉賓

葉正盛
玖章算術科技公司CEO
【嘉賓介紹】原阿里雲資深技術與產品專家,資料庫產品管理與解決方案部總經理。20年軟體研發經驗,曾主導過多個工業控制軟體、ERP、大型電力計費系統研發,見證與實踐了阿里巴巴去IOE、異地多活、雲端計算多次技術變革。
演講內容:
合理的設計資料架構是程式設計師的核心競爭力,也是普通程式設計師走向技術專家的必修課。資料庫一直是計算機核心基礎軟體,經歷了40年的發展,從關係型資料庫,到資料倉儲、NoSQL、大資料以及雲原生資料庫,體系越來越複雜。
本次主題重點介紹應用軟體到底層資料庫全鏈路的核心原理,希望幫助廣大序員更好的理解並使用好資料庫。

資料庫簡介

資料庫管理系統(DBMS)是管理資料庫的大型軟體,可以建立、使用和維護資料庫,其提供了資料採集、儲存、查詢和分析的功能。
在沒有資料庫之前,如果我們要做庫存管理,以小超市、夫妻店為例,我們可以用手工記賬,但隨著資料越來越多,我們可以用Excel管理,如果是大型超市或大型庫存中心,Excel就不能應對了,需要使用資料庫來管理。那麼,資料庫和Excel有什麼區別呢?
第一,管理的資料量不同,Excel可以管理上萬條資料,而資料庫可以輕鬆管理數億條資料;
第二,多使用者,高效能,Excel一般是個人操作,資料庫系統需要處理網際網路平臺上可能是數億使用者同時請求;
第三,安全管理的不同,Excel只能設定密碼保護,資料庫支援使用者的複雜許可權控制;
第四,開發介面不同,Excel開發介面比較多,但基本是應用在內建單機開發,資料庫有面嚮應用軟體的開發介面,適合大型應用軟體或者網際網路平臺業務。
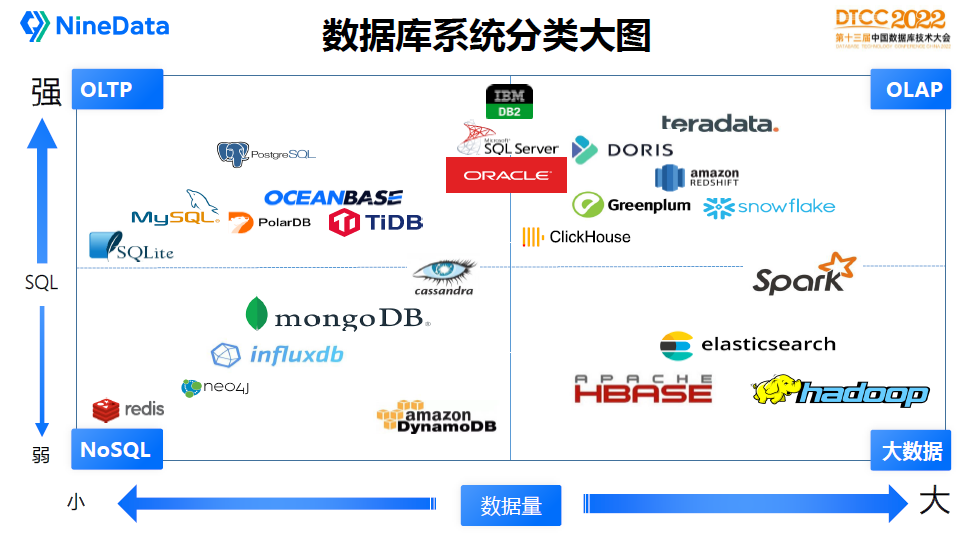
主流的資料庫有幾十種,這張圖描述了當前資料庫主流產品定位,透過管理資料量大小和SQL功能強弱把各個產品分為四大類:
OLTP:線上事務處理平臺,一般都是關係型資料庫來支撐,常見的資料庫有:SQLite、MySQL、PostgreSQL、PolarDB、TiDB、OceanBase
OLAP:線上分析業務,一般是資料倉儲,常見的產品有:Teradata、Clickhouse、Doris、Greenplum、Snowflake、AWS Redshift
NoSQL:新資料模型,網際網路行業用得非常多,代表產品有:Redis、Neo4j、InfluxDB、MongoDB、Cassandra、AWS DynamoDB
BigData:大資料業務,和資料倉儲比較類似,但是更擅長處理大規模資料分析業務,主流產品有:HBase、Hadoop、ElasticSearch、Spark
另外DB2、SQLServer、Oracle這幾款產品在OLTP和OLAP領域都比較強,有時稱為HTAP產品,也是目前資料庫的領導者。
不是說管理的資料量越大和SQL功能越強就越好,每一種資料庫它是在特定的場景能夠展開它的優勢,這裡只是把它劃分在不同的區域。
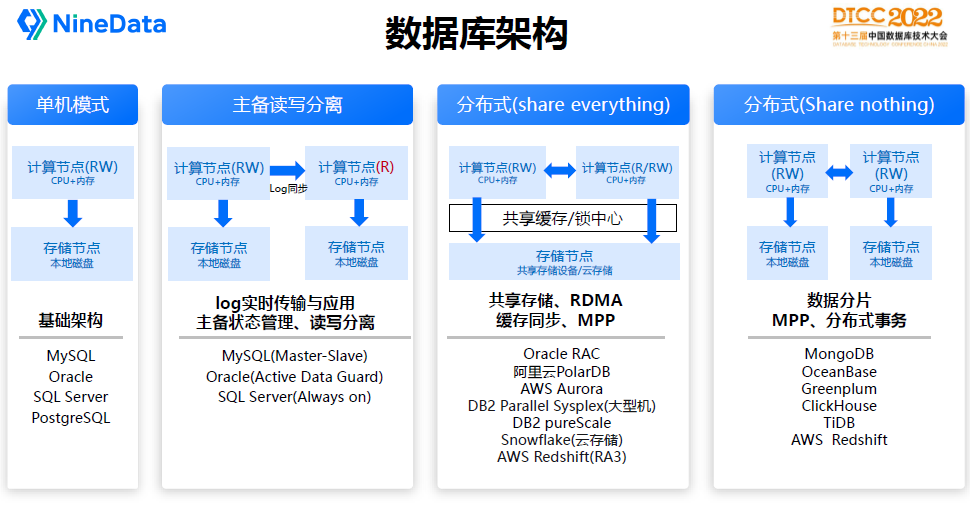
根據資料庫計算節點和儲存節點部署整體架構分為幾大種類:
單機:計算節點和儲存節點一般在同一臺機器上,通常儲存節點是本地硬碟,如單機版的MySQL、Oracle。單機模式沒有高可用保障,常用於臨時開發測試或者個人學習場景,生產環境不建議使用。
主備讀寫分離:在單機模式上增加了備用節點,備用節點既可以作為高可用保障,也可以承擔只讀業務請求,主備之間透過資料庫的log實時傳輸實現。比較常見的有MySQL的Master-Slave,Oracle的Active Dataguard,SQL Server的Always on,主備模式也是當前生產環境最常見的部署架構。
隨著資料量或者負載的增加,主備模式已經無法滿足業務需求,因此誕生了分散式的軟體架構,資料倉儲和大資料產品通常都是分散式架構,主要由兩種模式:
分散式(Share everything):Share everything架構通常儲存節點採用分散式的共享儲存,比如專業的EMC儲存裝置或者是雲端儲存OSS/S3。因為資料共享問題解決了,計算節點就能擴充套件多個,從而承擔更多業務負載。典型代表有Oracle RAC、阿里雲PolarDB、Snowflake、AWS Redshift(RA3)。IBM DB2也是典型的分散式架構,它同時還採用了集中式共享快取的模式。
分散式(Share nothing):在沒有共享儲存的情況下,通常會採用Share Nothing的架構設計。這類架構是儲存資料分片儲存在不同的節點,因此計算和儲存節點都是獨立執行,透過MPP計算引擎實現叢集資源的排程運算。
資料庫內部結構
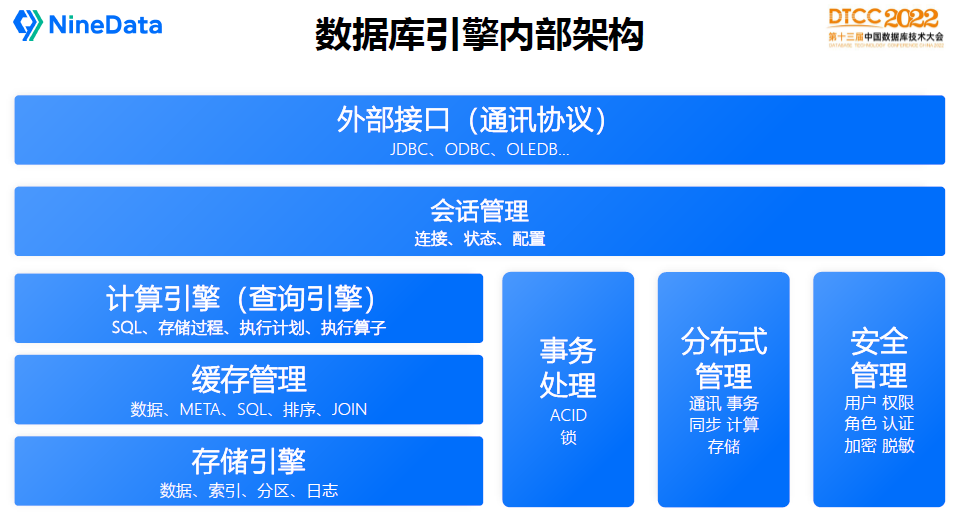
資料庫引擎主要包括以下元件:
儲存引擎:負責資料的儲存管理,包括資料、索引、日誌等資料的管理;
快取管理:負責資料庫的快取管理,包括資料快取、SQL快取、會話快取、運算快取等等;
計算引擎:也稱為查詢引擎,負責業務請求的邏輯運算,包括SQL解析、執行計劃生成、執行運算元下發到儲存引擎等等;
事務處理:負責資料庫的事務管理,ACID、鎖等特性的實現;
分散式管理:分散式資料庫的核心元件,用於協調資料庫各個節點通訊、事務狀態一致性協調、分散式計算等等;
安全管理:資料庫的安全訪問基礎,包括基本的使用者、角色認證,加密解密,以及高階的資料脫敏特性;
會話管理:資料庫連線和連線池狀態、配置等管理;
外部介面:負責對外提供標準的資料庫訪問介面,支援應用軟體透過JDBC、ODBC、Socket等方式訪問資料庫。
每種資料庫都有自己的實現方案和技術架構,但通常都會包括以上元件功能。

儲存引擎最基礎的是HEAP結構,這也是表資料檔案通常的儲存格式。
常見的資料庫,像Oracle,SQL Server,MySQL(ISAM),PostgreSQL表的基礎結構都是堆表引擎。可以理解為一條記錄過來,就把它按先後順序堆進去。資料庫由多個檔案構成,一個檔案由多個Extent/Segment構成,每個Extent包含多個Block/Page,OLTP通常在4K~32K大小,Block裡面就是具體的行資料資訊。
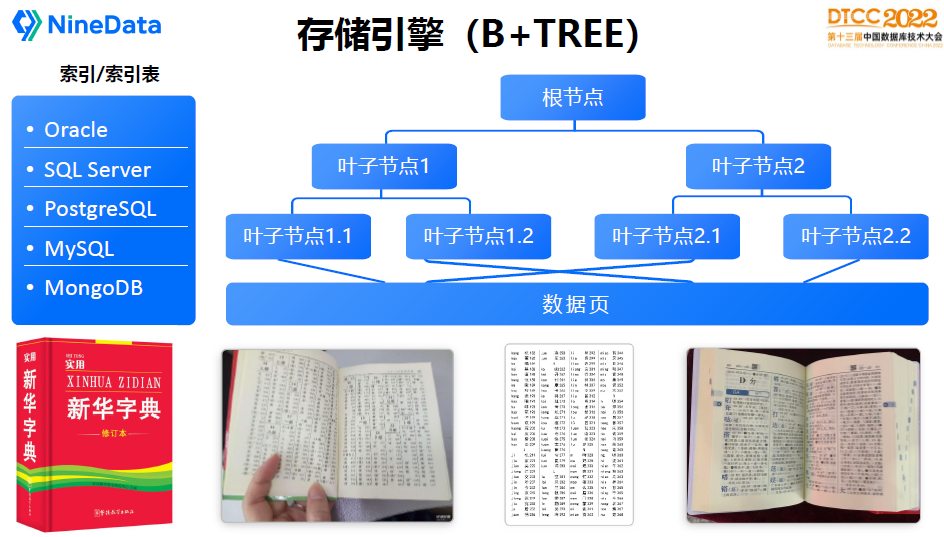
B-TREE是資料庫索引最常用的資料結構,MySQL(InnoDB)的表資料也直接採用了B-TREE的儲存結構。
B-TREE的核心特點是對資料排序,可以從根節點到葉子節點再定位到資料,葉子節點可以有多層,就像一棵樹的樹枝一樣。
我最喜歡的例子還是用新華字典來形容,大家小時候經常查字典,其實就是B樹的原理,要查一個字,首先要找索引,如果知道它的拼音,根據拼音索引裡面的位置去找到頁碼,再找到資料,查詢效率還是非常高的。
字典可能有很多種目錄索引,常見的有拼音、部首、筆劃,這樣就可以按不同的方式快速找到要需要的字。資料庫B-TREE原理跟查字典基本上是一樣的,很多文章介紹不等於、大於、小於等條件能不能使用上索引,其實想想這個邏輯,用字典目錄能不能查,就能大概判斷出來能不能做,原理是完全一樣的,沒有什麼特別之處。

HEAP和BTREE通常是OLTP資料庫使用,而OLAP通常資料量非常大,COLUMN-STORE(列存)是更常見的儲存結構,因為按列儲存資料可以做到更好的編碼壓縮,並且當SQL只是需要請求大寬表的部分欄位時,COLUMN-STORE就非常有優勢。
開源的ORC和PARQUET是列式儲存的典型模型,都比較常見。Greenplum、ClickHouse等資料倉儲都支援列式儲存。
在我們生活中也有這樣的例子,比如說大超市的貨架,通常都是按品類擺放的,電器、水果、零食都是放在不同的位置,這就是一種列式分類管理的機率,查詢效率也比較高,也可以擺放更多的貨物。

再談談LSM-TREE,上面是阿里內部X-DB的技術架構圖,很好的描述LSM-TREE模型。業務往裡面寫資料時,先寫日誌,同時放在記憶體裡面,記憶體積累到一定的資料,就排好序往底下磁碟刷盤,按同樣的邏輯一層一層刷盤,這是典型的分層儲存的概念。
它在寫方面非常強,尤其是順序寫,像日誌這種資料比較適合。它的缺點是讀效能比B樹差,尤其是按範圍讀取資料。大量的傳統OLTP商業資料庫依然用B樹去做,因為實踐下來綜合讀寫會更高效。LSM-Tree在日誌儲存場景比較合適,如Hbase,另外我們也會看到一些分散式資料庫儲存用LSM結構,如TiDB、OceanBase,這個還有待驗證。LSM-Tree在面向傳統硬碟上有順序寫入優勢,對SSD寫磨損也更友好,但在SSD硬碟上的整體效能提升收益沒有傳統硬碟突出,因為SSD的隨機IO效能也不錯。
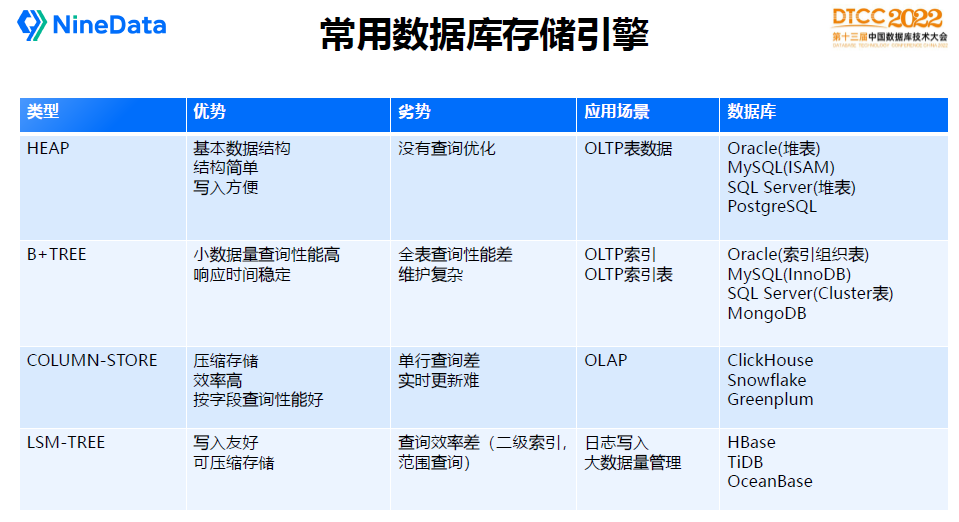
用一個表格彙總各種儲存引擎的優劣勢和應用場景。

資料庫快取分為幾大板塊,第一是資料快取,一般來說是全域性性的,所有的會話都在統一的資料快取裡讀取和寫入資料。框的大小代表著佔用記憶體的大小,比如資料塊,這是佔用最多的,其次是索引塊,另外是日誌,比如REDO LOG。
也有一些開發者會問,這個快取為什麼資料庫單獨去管理?用作業系統不行嗎?如果說不深度理解這個問題,確實作業系統快取也做得很好,有些資料庫確實沒有快取,但是我們看到非常強大的資料庫都有自己的快取管理模組,比如Oracle、SQLServer等等。
資料庫自己做快取管理可以做得非常精細,比如說有全表掃描和按索引掃描,如果不做精細化的快取,有可能一個大表的查詢就把以前有效的快取都給清出去了,對於資料庫來講是不能接受的,所以需要自己做管理,因為可以判斷這個快取的重要性。Oracle,MySQL(InnoDB)這方面都做了很多細的工作,這是作業系統不一定能解決好的問題。
當然也會存在一定問題,資料庫有快取,作業系統還有快取,會不會導致快取重複使用,效率不高?因此有些資料庫就把作業系統的快取給旁路了,作業系統會提供DirectIO這樣的介面。
圖中右上角是SQL與物件的快取,有兩個比較重要的,一個是SQL的文字和執行計劃,第二是後設資料,比如說表結構定義資訊。SQL文字和執行計劃快取比較大,尤其像Oracle這些成熟的商業資料庫,因為需要支援非常複雜的SQL最優執行計劃制定,所以快取管理就更加重要。反而開源的資料庫執行計劃快取會做得非常弱,比如MySQL,可以說是幾乎沒有。如果有執行計劃快取,像Oracle這種資料庫,效率是完全不一樣的,每次執行,效率有可能會有10倍以上的提升。
然後是會話快取,這塊比較好理解。還有是運算快取,在數倉裡非常重要,OLTP系統,一般資料快取很重要,OLAP運算快取會更重要,主要原因是OLAP系統的Hash與排序運算量比較大。

資料庫事務處理的核心是ACID:
Atomicity:原子性,表示資料庫一個事務操作要麼成功,要麼失敗,不能出現部分成功或者部分失敗的情況。通常採用WAL(Write Ahead Log)來實現,同時利用了硬體的原子寫介面。
Consistency:一致性,表示資料庫要能保證定義的約束有效性,包括定義的主鍵、唯一約束、外來鍵、NOT NULL等約束,在每個事務提交後都要確保約束有效。在事務過程中沒有強制約束,因此不同資料庫對約束的實現會有些區別,比如插入唯一約束重複的資料是立即失敗,還是等事務commit再檢查唯一約束?
Isolation:隔離性,這個是事務最複雜的地方,國際標準定義了4種事務隔離級別。對於OLTP系統,大部分都採用了Read Committed的隔離級別,唯獨MySQL(InnoDB)預設採用了Repeatable Read的隔離級別,這個也是由於歷史原因,MySQL的主備同步使用了Statement模式導致的。現在MySQL基本都是採用ROW格式的Binlog格式,所以建議改為Read Committed隔離級別更好,也能減少Repeatable Read帶來的各種鎖和死鎖問題。我在第一次使用MySQL就踩了一個坑,當時使用Create table as select備份一張線上表,然後表就被鎖定了,導致業務故障,這個也是非常坑的地方。阿里巴巴集團內部和阿里雲RDS也預設把事務隔離級別改為了Read Committed,系統也更加穩定。
Durability:永續性,意思是事務提交後,資料庫一定要確保生效,即使作業系統重啟或者是伺服器掉電。資料庫通常也是使用WAL加硬體的永續性來實現,這裡需要保證commit後刷盤立即寫入,不能臨時快取在記憶體中,否則伺服器掉電就丟失資料。
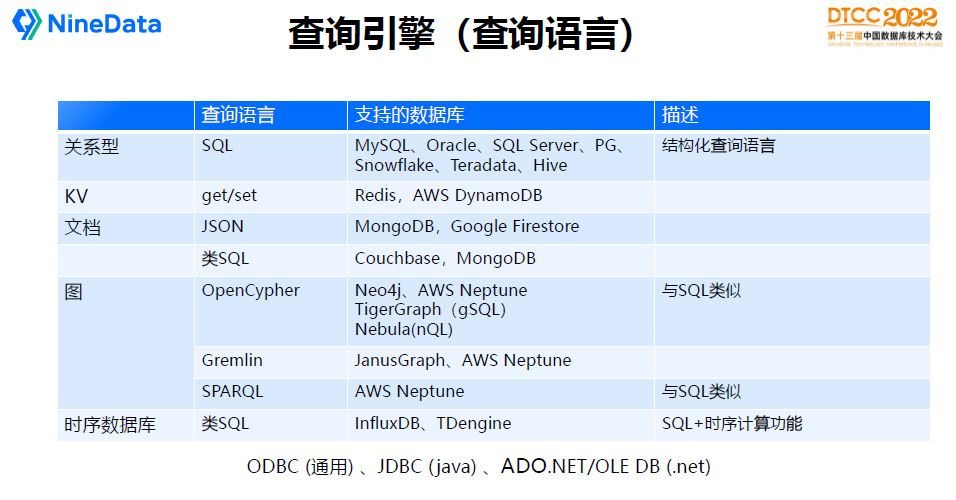
查詢引擎是資料庫最複雜的模組,核心是處理業務請求邏輯,如SQL怎麼解析、執行,可以稱為資料庫的大腦。
每種資料庫使用的查詢語言不太一樣。關係型資料庫通常使用SQL語言,KV資料庫一般使用get/set語義,文件資料庫一般是用JSON模型表達,圖資料庫比較複雜,有OpenCypher、Gremiln、SPARQL等。時序資料庫,也大部分是類SQL的模型,它在SQL的基礎上增加了一些時序計算視窗類的表達模型。
資料庫設計與SQL最佳化

SQL是資料庫最常用的語言,也是資料庫的核心資源開銷,因此SQL最佳化是程式設計師的必備技能。
SQL最佳化通常分3個階段,我們常稱為SQL最佳化三板斧,這三板斧下去,90%的問題都可以解決。
第一是先找到問題SQL,有兩種情況,如果是現在系統有問題,我們可以去看活躍的連線在幹什麼,把正在執行的SQL取出來。每種資料庫通常都提供了查詢當前活躍會話的介面,比如MySQL使用show processlist,Oracle可以查詢v$session檢視資訊。如果說問題已經過去了,沒有現場,可以透過Slow Log,或者TOP SQL,找到問題,這個需要資料庫開啟歷史SQL記錄功能。
第二是分析問題SQL,最主要先看SQL的執行計劃,再去看整個資料庫的IO訪問量是不是符合預期,緩衝命中率怎麼樣,如果不是99%以上,可能都有問題,有些程式設計師看到記憶體都用完了,其實也不是什麼問題,比如有10G的記憶體,如果你的資料量超過10GB,那記憶體很快都會用滿,關鍵要看快取命中率。另外是網路IO,多叢集的話,需要關注網路傳輸的延遲和頻寬容量。如果有鎖,要分析SQL鎖的模型。CPU重點要看一下排序、函式計算等操作。
最後是解決問題,就是最佳化SQL,可以修改SQL提升效能,如果沒有索引就要增加索引,如果快取命中率有問題就要調整記憶體配置。資料整理也是比較常見的,有些資料庫歷史資料非常多,影響了效率,要考慮怎麼把歷史資料歸檔,提升資料訪問效率。
再有是提升硬體效能,最後是分散式改造,分散式改造比較困難,如果前面幾個步驟能解決最好,實在不行再去考慮比較複雜的分散式改造。
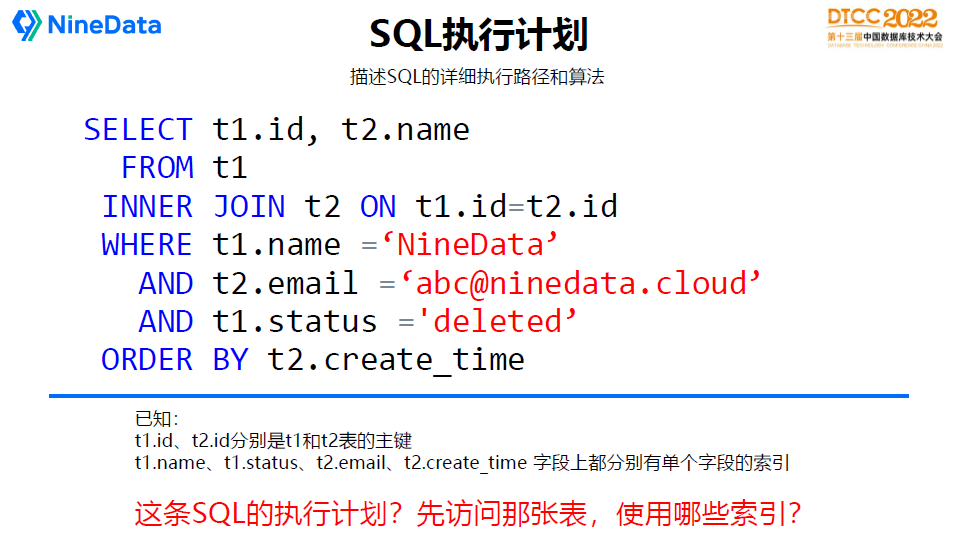
接下來重點講一下執行計劃。有些初級程式設計師往往忽視這個問題,SQL執行計劃是描述SQL詳細執行路徑和演算法。
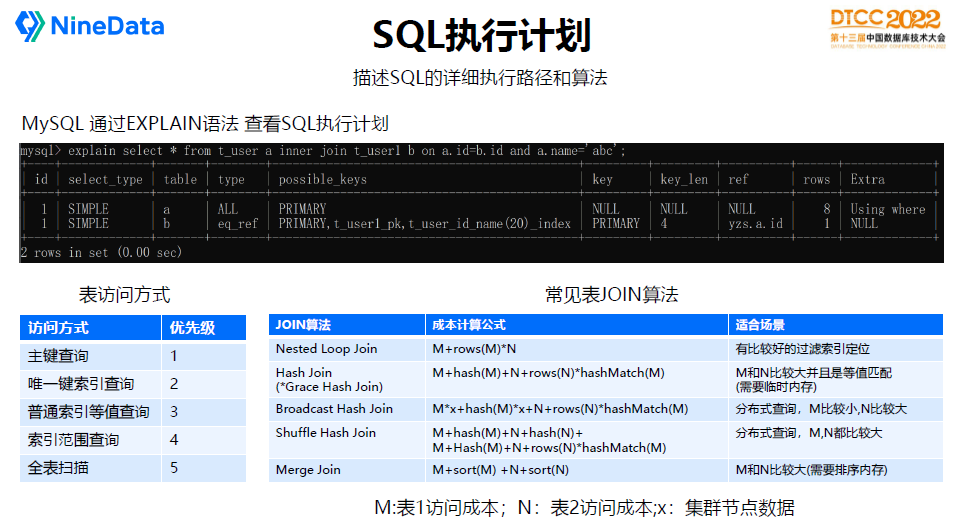
資料庫通常支援使用EXPLAIN語法來檢視SQL的執行計劃,會展示出SQL具體的執行路徑和演算法,包括訪問表的順序,每張表使用索引訪問還是全表掃描,每次執行預計返回的行數等等,資訊會比較詳細。
SQL訪問單表主要有幾種方式,包括:
主鍵:示例SQL:select * from t where id=?
唯一索引:select * from t where uk=?
普通索引:select * from t where name=?
索引範圍掃描:select * from t where create_time>?
全表掃描:select * from t
對於多表連線,通常有以下幾種JOIN演算法:
Nested loop join:適合兩張表有非常好的索引訪問路徑,如:select * from t1 inner join t2 where t1.id=t2.id and t1.id=?
Hash Join:適合兩張表都沒有好的索引,需要全表掃描,並且是等值關聯查詢,如:select * from t1 inner join t2 where t1.id=t2.id
Hash Join需要把一張表載入到記憶體後,另外一張表再透過Hash匹配到對應的記錄,所以會需要臨時記憶體,當臨時記憶體不夠時會產生臨時磁碟轉儲的開銷。為了解決Hash Join在分散式場景的問題,也誕生了Shuffle Hash Join和Broadcast Hash Join演算法。
Merge Join:適合兩張表都沒有好的索引,需要全表掃描,支援非等值關聯查詢,關聯欄位最好是有排序,因為Merge Join演算法是需要把兩邊資料排序再Merge 。

資料庫如何生成SQL執行計劃,如何選擇最優的執行路徑,通常是內部有個最佳化器的元件來完成。最佳化器型別有RBO和CBO兩種。
RBO:Rule Base Optimizer,意思是基於規則的最佳化器邏輯,早期資料庫都是採用RBO,實現比較簡單,但很依靠程式設計師對資料庫的邏輯理解,在SQL非常複雜的情況下很容易走到糟糕的執行計劃。
CBO:Cost Base Optimizer,意思是基於成本的邏輯,最佳化器會計算各種不同的路徑成本,最後選擇一條最優的路徑來執行。
舉個例子,我們通常的交通方案有飛機、火車、汽車、輪船、步行,每種方案的速度都不同。如果我們要從杭州去北京,那麼該選擇那種交通方式?
對於RBO來說,它總是會選擇飛機,不管是否發生交通管制,以及去機場的交通是否順暢。
對於CBO來說,它會評估從出發點到杭州機場/火車站,北京火車站/機場到目的地的交通時間,綜合評估一個最短時間的交通方案。
CBO是目前資料庫主流的最佳化器模型,實現難度也更大,需要收集很多統計資訊,如每張表的儲存空間大小和記錄數,欄位的區分度等等,在資料經常變化時需要保證統計資訊的準確性。
RBO和CBO通常都是在生成執行計劃後就不能再修改,即使執行過程中發現嚴重偏差也不會改變,因此後來有些資料庫在CBO的基礎上實現了更智慧的Adaptive的邏輯,意思是在執行過程中,如果發現有更優路徑,那最佳化器可以調整執行計劃。就好像本來選擇坐飛機從杭州去北京,但是到了機場,發現航班大量延誤,起飛時間完全不確定,這個時候可以調整計劃,選擇做火車出發。
開源資料庫的最佳化器相對比較弱,商業資料庫更領先。國內在這塊技術相比國際落後很多。

接下來講一下資料庫的設計,基礎知識是要掌握正規化,在教科書裡面非常多,這裡不多講 。反正規化我覺得是比較有意思,尤其是表設計裡面,有非常多的反正規化的案例。比如說標記組合是比較常見的,如果有多個標記狀態位,可能會用bit的資料型別去儲存,這其實就已經違反了第一正規化,因為第一正規化要求欄位的內容要原子性,不能拆分。實際上資料庫核心裡面,它用了很多bit型別這種反正規化來設計後設資料,從而提升儲存和查詢效率。
另外一個是日常習慣欄位,拿身份證號碼來舉例,也是違反了第一正規化,因為身份證號碼已經包括所在的地區、出生年月、登記順序以及校驗碼這4個資訊。但是我們實際的表結構設計,還是會把身份證號碼當做一個欄位,不會說把身份證號碼拆成4個欄位,否則閱讀習慣會不太方便。
還有計算列,典型的違反了第三正規化,如商品的金額=單價*數量,訂單總金額,我們一般都會冗餘去儲存。
數倉裡面就更多的反正規化的案例,歷史資料快照,會把相關的資訊都儲存下來,也是違反正規化,但我們基本都這麼幹。
拆表也是一種常見設計,比如說一張表裡面有常用和不常用的欄位,如有個欄位是大欄位,我們就會把它拆成另外一張表。
這些其實都是比較常見的反正規化設計的場景。所以部分場景下我們不用去特別糾結一定要遵循正規化,如果說你覺得合理,業務邏輯實現可控,適當的冗餘資料其實也沒什麼問題。

關於主鍵選擇,比較推薦兩種,一種是自增欄位,比較適合內部系統的表,如果說是對外的網際網路應用需要注意,有被猜測攻擊的隱患。我們公司比較喜歡用雪花模型,根據時間序列加上順序號產生主鍵,效能比較好,比較安全,實現相對複雜,需要應用程式產生。

接下來介紹幾個常見的資料模型:
首先是平臺型網際網路資料模型,像淘寶、微信公眾號、美團、BOSS直聘、滴滴等等,他們的資料模型都比較類似,主要包括以下物件。
會員資訊:買家(淘寶、美團)、乘客(滴滴)、讀者(公眾號)、求職人(BOSS直聘)。
服務提供者資訊:賣家(淘寶、美團)、博主(公眾號)、司機(滴滴)、主播(抖音)、公司(BOSS直聘)
服務內容資訊:商品、文章、微博、用車、影片、職位
庫存資訊:電商的概念
網際網路平臺根據以上幾張表資訊,透過搜尋、推薦等各種匹配演算法,最後產生訂單資訊,接著是付款資訊、物流/配送資訊,最後是服務反饋資訊。
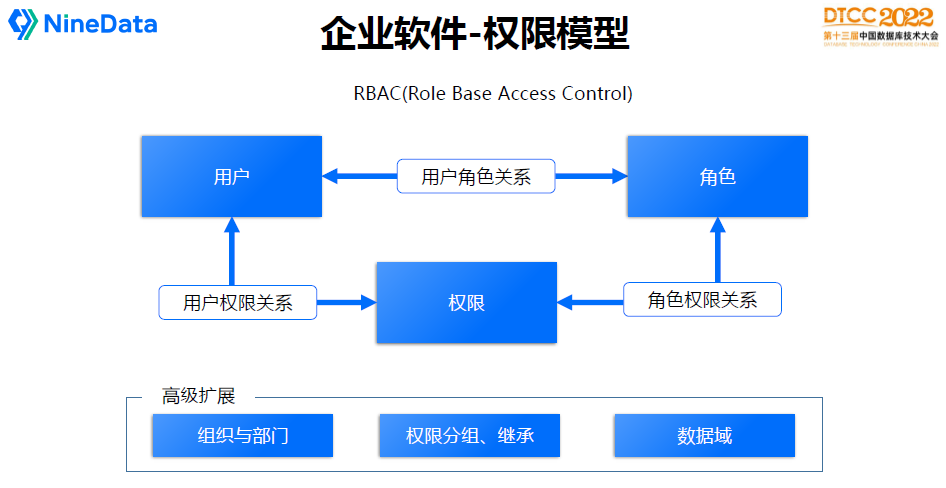
剛才是網際網路的模型,企業軟體不太一樣,企業軟體講究兩個東西,一個是安全,一個是流程規範。
安全核心是許可權模型設計,比較標準的是RBAC(Role Base Access Control),我們可以參考這套模型演進。核心是理解使用者、許可權、角色三個重要的物件。按照RBAC設計問題不會太大,有可能會有擴充套件的東西。比如面向公司的使用者,會有組織和部門的關係。許可權會擴充套件出許可權分組,角色會有繼承等。另外一個是資料域許可權,同樣的許可權與角色,但是能訪問的是不同範圍的資料,就會有資料域等高階定義。
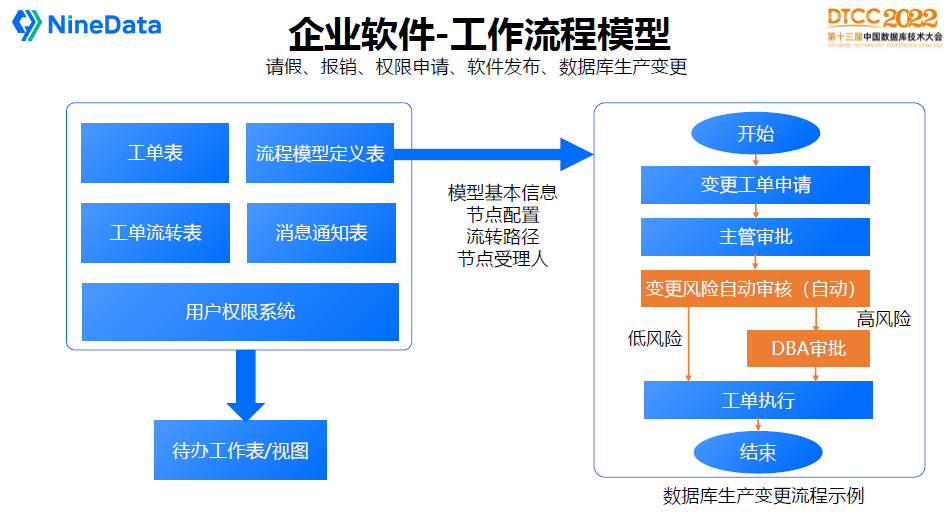
我們再看企業軟體裡比較常見的流程規範,最常見的是工作流引擎。
首先有工單表,不管是請假、許可權申請還是生產變更,都有一個工單來儲存你做什麼事情。
然後是流程模型定義表,例如資料庫產生變更的流程,現在做生產釋出,變更表結構,要提交變更申請,主管要審批,如果高風險還需要DBA的審批,這就是一個業務流程模型。
流程模型會包括基本定義資訊,有哪幾個節點,流轉路徑,根據什麼條件流轉,哪些人受理等等。
針對每個工單的流程處理,都有工單流轉表,訊息通知表,再加上使用者許可權系統,這樣就可以形成工作流的待辦工作表,基本上就是這麼一個套路,大家理解這個概念,在企業級軟體裡就可以如魚得水了,不會那麼糾結。
資料傳輸和安全管理
前面是資料庫架構和 SQL最佳化板塊,最後一個板塊我要講一下資料傳輸和安全管理,這個也是我們開發者其實經常會遇到的問題。

資料傳輸是一個統稱,包括資料遷移、資料同步、資料分發等,也稱為資料複製。
比較常見的幾個場景:資料庫上雲、更換資料庫、資料同步到備庫、異地資料多活、資料ETL等等。
通常包括結構遷移、全量資料複製、增量資料複製幾個核心模組,為了保障資料複製的正確性,還需要資料對比模組。這裡面最難的增量資料複製模組,市場上很多產品會採用按日期增量抽取簡化處理,只能做到定時複製,要做到實時資料複製需要使用CDC技術,要精通資料庫的內部原理,適配各種主流資料庫產品和版本,技術難度和工程難度都是非常有挑戰。
我在這個領域做了10年,從早期的去IOE、異地多活到釋出阿里雲DTS,裡面有非常多的問題,尤其是在生產環境下,源端經常會有各種DDL變更的情況很容易鏈路中斷或者資料錯亂。目前市場上推薦的三款代表產品:
阿里雲DTS:功能完備,與阿里雲整合度很好
NineData(重點推薦):玖章算術公司研發的SaaS產品(),支援阿里雲、華為雲、騰訊雲、AWS等多個雲平臺,技術指標上更領先,易用性也更好,免安裝使用
Canal:阿里開源的產品,影響力很大,不算是完整的產品,一般需要二次開發。

資料安全管理,太重要了,我把這個單獨列出來講。
先說軟硬體的故障,比如伺服器,磁碟肯定會壞,過保機器壞的可能性更高了,所以一定要做好災備工作。再有是機房也有可能發生災難,業界每個月都會有機房出問題,像火災,地震,或者是斷電、光纜斷了等,都是機房故障。另外是軟體Bug,一般是指資料庫本身的軟體Bug,成熟的資料庫Oracle、MySQL每次釋出都會說修復了幾十個Bug,普通資料庫的bug可能更多。
如果用雲平臺會好一些,比人工管理更安全,雲很注重伺服器的故障檢測,及時升級資料庫最新的安全補丁,大型雲廠商都有專業的團隊去做這個事情。
第二大類是人為故障,比如駭客入侵會造成資料洩露或者勒索,駭客通常會利用軟體裡面SQL隱碼攻擊,只要有注入的風險,駭客是全網掃描的,一旦掃到就進來了。
還有是密碼洩露,如果是弱密碼就肯定能被駭客發現,只是等駭客啥時間要搞你。另外是如果有系統漏洞,駭客一般來說提前就知道了,會去看能不能攻破你。今天還有一點非常重要,就是內部資料洩露,還有刪庫跑路。在今天員工和公司對立的情況下,還是時常發生的,尤其是和主管關係不好,遲早都會發生刪庫跑路的事情,管資料庫的員工還是要比較慎重。
最後是資料誤操作,比如說做軟體的升級釋出,不小心寫錯了,我做DBA的時候就碰到過非常多,每個月都會碰到程式設計師將提交的SQL給搞錯了,需要恢復資料,這些都是人為的問題。資料備份是一定要做的,如果沒有備份一定是不踏實的,總會發生問題。
如果是非常重要的資料,要考慮異地容災。如果是敏感的資料,要考慮資料加密,包括資料傳輸的加密。
另外一點,流程規範非常重要,尤其是對生產系統的資料操作,最好有系統來支撐,靠人監督是沒有用的。一定要透過平臺來管控,不要把資料庫賬號密碼放出去,包括只讀許可權的賬號密碼,這些都是系統隱患,說不準哪天你家公司的敏感資料就在網上被駭客販賣…

最後,希望讓每個人用好資料和雲,這個也是我們玖章算術公司的使命。NineData是我們研發的產品,希望可以幫助你解決相關的問題,歡迎訪問,它提供了企業級的SQL開發流程管理,資料複製、資料備份、資料對比等功能。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/28285180/viewspace-2932497/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 程式設計師必須掌握的資料結構 2程式設計師資料結構
- 程式設計師必須掌握的資料結構 1程式設計師資料結構
- Java程式設計師必須掌握的Spring依賴管理原理Java程式設計師Spring
- Java程式設計師必須掌握的5個註解!Java程式設計師
- 前端工程師必須掌握的設計模式前端工程師設計模式
- 面試阿里P6,Java程式設計師必須掌握的技術面試阿里Java程式設計師
- 程式設計師必須掌握的核心演算法有哪些?程式設計師演算法
- 程式設計師生存指南:你必須要掌握的兩點!程式設計師
- 強烈推薦:程式設計師必須懂的資料庫知識程式設計師資料庫
- 【Linux常用命令①】程式設計師必須掌握的Linux命令Linux程式設計師
- Java程式設計師必須掌握的7個Java效能指標!Java程式設計師指標
- 為什麼說 Java 程式設計師必須掌握 Spring Boot ?Java程式設計師Spring Boot
- 列舉幾個Java程式設計師通用的、必須掌握的框架Java程式設計師框架
- shell程式設計必須要掌握的命令-xargs程式設計
- 你還敢說不會做資料分析?做程式設計師必須掌握的資料分析思維!程式設計師
- iOS 程式設計師必須收藏的資源大全iOS程式設計師
- 牛逼程式設計師必須要掌握金字塔思維程式設計師
- JAVA程式設計師“黃金5年”必須要掌握的知識技能Java程式設計師
- 從事Python資料分析師,必須掌握的Python工具!Python
- 為什麼說 Java 程式設計師到了必須掌握 Spring Boot 的時候?Java程式設計師Spring Boot
- 24個必須掌握的資料庫面試問題~資料庫面試
- 關於資料庫索引,必須掌握的知識點資料庫索引
- 前端er必須掌握的資料視覺化技術前端視覺化
- 好程式設計師分享SpringBoot須掌握的註解程式設計師Spring Boot
- 程式設計師必須要了解的web安全程式設計師Web
- Java程式設計師必須要掌握這10種工具,缺一不可!Java程式設計師
- 微服務架構技術棧:程式設計師必須掌握的微服務架構框架詳細解析微服務架構程式設計師框架
- java程式設計師進階架構師你必須掌握的架構知識體系Java程式設計師架構
- 程式設計師計算私活薪資的正確方式程式設計師
- 程式設計師必須走向專業化程式設計師
- Java程式設計師微服務架構你必須要掌握的十個要點Java程式設計師微服務架構
- 5大資料經典模型詳解——資料分析師必須掌握大資料模型
- @程式設計師,安全問題必須重視!程式設計師
- 2020年前必須掌握的資料庫面試問題~資料庫面試
- PHP程式設計師必須知道的兩種日誌PHP程式設計師
- 程式設計師必須掌握的Java 框架,小白學會之後15k不是問題程式設計師Java框架
- 每個程式設計師必須掌握的常用英語詞彙分享給你(建議收藏)程式設計師
- Java開發需要掌握哪些技術?Java程式設計師必備技能Java程式設計師