騰訊雲資料庫伍鑫:MPP資料庫HTAP技術探索
本文根據伍鑫在【第十三屆中國資料庫技術大會(DTCC2022)】線上演講內容整理而成。
講師介紹:

伍鑫,騰訊雲資料庫專家工程師,在資料庫核心、資料複製、大資料計算等領域有豐富經驗,曾發表多篇相關論文、專利。加入騰訊前曾在IBM DB2團隊工作多年,後加入Hashdata雲數倉公司。加入騰訊後,負責TDSQL PG係資料庫研發工作。
本文摘要:
騰訊雲TDSQL分散式關係型資料庫是一款面向海量線上實時資料的MPP資料庫系統。在面對實際業務HTAP混合負載時,不管是高併發的交易還是海量的實時資料分析,TDSQL都有足夠能力處理。
本次分享為大家介紹TDSQL提升HTAP混合負載處理能力時在儲存、計算、資源隔離等方面的探索最佳化歷程。
演講正文:
一、HTAP概述
早在上個世紀九十年代,大家就在討論儲存模型到底是用行存還是列存,因為針對交易系統每列資料是緊耦合,按行組織資料效果在OLTP場景更好。但OLAP效能分析在DSM列存格式上效果更好,因此從業務角度的特點來說就會分成兩個方向:
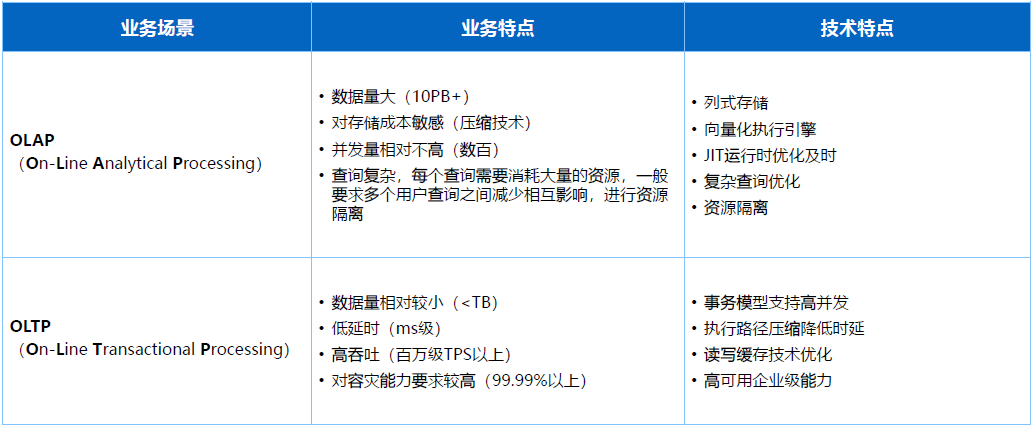
早期OLTP領域資料量相對較小,一般小於TB級別,要求低延遲,使用者交易請求需要在毫秒級甚至更快的情況下完成,達到一個高吞吐,交易請求可能會有非常高的併發請求數量,同時對資料高可用和容災能力要求非常高。
OLAP場景更多的是面向海量資料分析,最近幾十年資料整個規模的膨脹發展,資料量基本上會超過PB級別甚至達到EB級別,對儲存成本要求會比較高,因為海量的資料情況下,有些儲存場景成本會超過總體的50%甚至70%,隨之帶來針對資料壓縮技術要求會比較高。
OLAP場景大部分情況併發相對不高,但近幾年來併發要求也開始上升,所以在彈性計算和相關Serverless無狀態的構架下也有一些演進,整體來說相對OLAP場景併發度不高。
OLAP場景下複雜場景會比較多,儲存過程要求也比較高,複雜場景情況下資源就會消耗比較多,CPU網路和記憶體等層面,所以需要對使用者和資源做一些隔離,也是在不同業務特點下對產品形態的要求。
那麼在這樣的特點下就催生了不同產品的技術特點和技術路線:
OLTP場景更多要求是在事務模型支援高併發,執行路徑達到降低時延,讀寫快取技術最佳化以及企業級高可用要求比較高,包括容災場景針對性要求非常高。
OLAP場景跟隨業務特點會更深入地Focus在列式儲存、向量化執行引擎、JIT執行時最佳化、複雜查詢最佳化、資源隔離等場景會有比較多的要求。
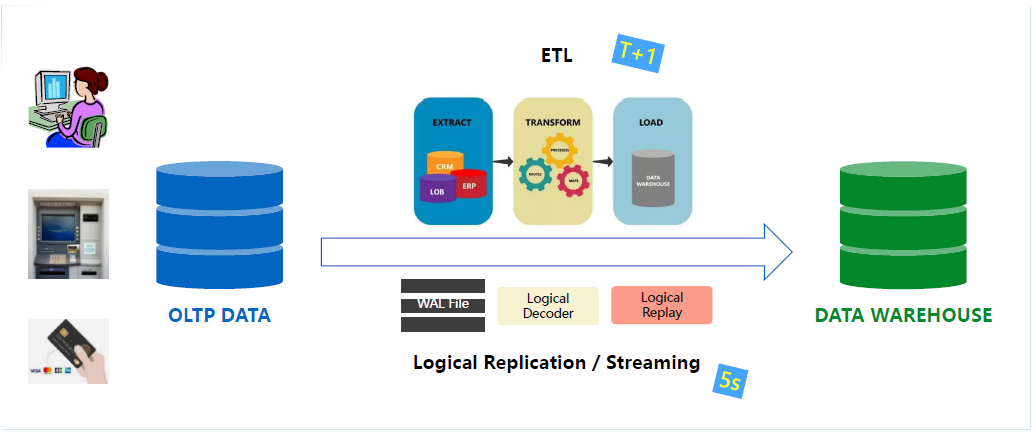
其實在比較早期的OLTP、OLAP產品形態比較獨立的情況下,大部分使用者其實也是有這樣的一個混合方案的需求。
產品獨立的情況下,早期需要向ETL工具去做一個定期的Extract Transform或者Load的操作,流程上就會比較煩瑣,使用者也需要在ETL工具進行選擇和消費,可能會買相應的產品。那麼在這樣的構架下,時效性相對比較低,一般需要在T1+的層面才能達到分析型的數倉,拿到準實時的資料。
過去的十年更多推進的是基於Logical Decoder和Logical Replay去做基於流式複製更高時效的複製層面設計,透過CDC從遠端TP場景抓取增量日誌、邏輯日誌,傳輸到端的數倉,再做一個日誌回放,這樣的話時效可以達到5秒內,目前國內的主流混合場景其實都可以透過流複製達到準實時或者基本近實時的效果。
這些是過去很長一段時間以來的融合方案,其實就會對產品、成本、構架有比較高的要求,如何降低成本,如何在產品選型做到更簡單,同一個資料庫同時實現OLTP和OLAP,業務開發和相關的成本也會下降得比較明顯。
在這樣新時代的需求下,我們前面也在強調產品是隨著使用者需求的形態轉變的,新時代的使用者需求可能會有這樣的一些場景:
1.日間交易和夜間批次業務複用。銀行業或者金融行業日間有很高的OLTP場景需求,夜裡交易量閒時可以利用這樣一個很大的OLTP資源場景去做分析,包括每晚業務的彙總或者銀行的月度結息都可以把OLTP資源進行復用,這是一個典型的OLTP和OLAP混合的場景。
2.實時分析型要求。剛才也有講到雖然最近用到邏輯複製和流複製的場景達到5秒內的資料延遲,但其實還不是一個完全實時的業務分析,面向現在更多要求實時性更嚴格,甚至是完全實時的分析場景就需要有一個挑戰,一體式的HTAP產品是否能夠完全實時的資料分析要求也是一個挑戰。
3.全量資料精度分析。因為大部分場景分析OLTP會有全量使用者的資料,OLAP場景可能會去複製或者加工後面的一些資料集,提供使用者資料價值的提煉,但實際上在現在這樣一個時代,我們需要對實時有一個要求,也是需要對全量實時資料進行分析。
OLTP和OLAP業務混合負載。在同一套系統下,能夠降低整個使用者的選型成本以及資源利用率的提升,都是有這樣的一個效果。在新時代下,這四個場景是對產品整個形態的演進有一定的挑戰。
在這樣的需求下,我們怎樣構建我們的產品,其實我們也是持續透過多年的探索和演進去做規整,今天主要做這樣一個分享。
Gartner對HTAP的整個趨勢判斷也是比較早地提出這樣的概念,現在的IT構架師需要在HTAP層面思考更多,是否是透過HTAP構架下為公司和業務部署提供低成本和更實時高效分析的狀態,我們在這種趨勢判斷下進行多年的探索。
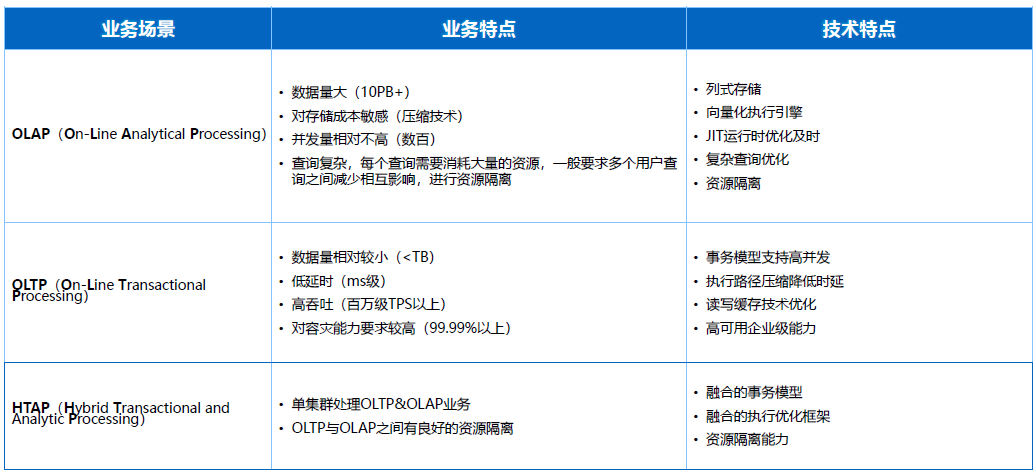
剛才講到OLTP和OLAP分別的特徵,混合場景下我們更關注融合場景下的事務模型,是否可以同時支援TP和AP的事務請求,混合場景下的執行和最佳化是否在同一套構架下可以完成TP和AP計算或者查詢最佳化的分析,混合場景下是否可以為使用者在OLTP和OLAP資源進行隔離,保證互相不受干擾。OLTP場景的實時性要求更高,需要保證更好的網路和快取的機制,保證基本的TP場景的低時延和高吞吐,AP場景其實也要分配足夠的CPU和記憶體自來帶來高效的記憶體計算。
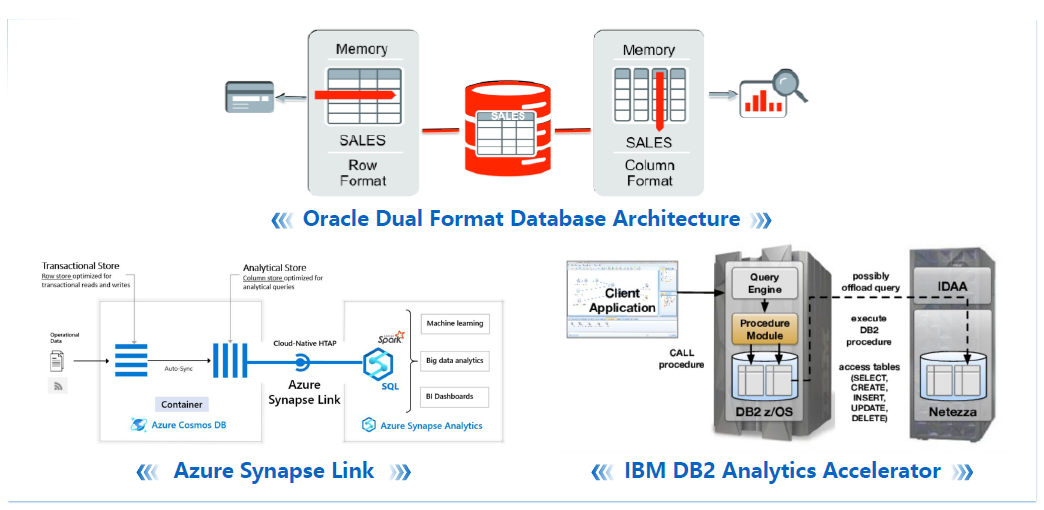
很多場景和產品在過去也有進行很多HTAP嘗試,Oracle是大家瞭解比較多的,大家經常對Oracle做混合場景,OLTP和OLAP效能都是相對比較好。
這裡有些混合方案,比如行存和列存的構建格式,透過實時雙模儲存格式達到HTAP的整體要求,Azure Synapse和IBM DB2 Analytics Accelerator也是融合不同的TP和AP產品,無論是外部還是內部達到實時的資料複製,為使用者提供一個基本透明的HTAP體驗,這些都是傳統廠商做的探索。
我們也會提出更進一步的挑戰,是否真的可以在同一套系統裡面完全融合實現儲存、計算以及最佳化,包括使用者介面的融合。
二、TDSQL-PG探索
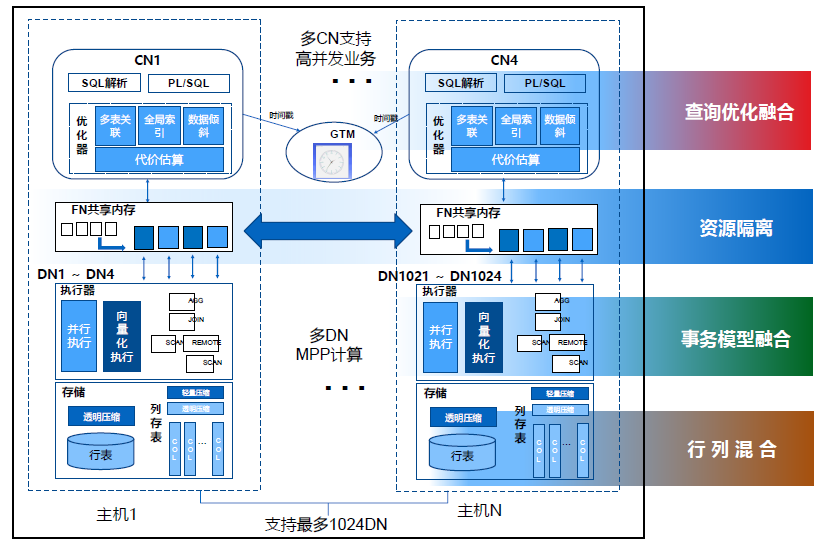
TDSQL做了很多探索,MPP引擎其實是TDSQL整體構架圖,這裡有幾個模組:入口模組是Coordinator Node,我們支援多CN協調節點,可以為使用者提供高併發的業務請求,同時支援TP和AP場景下的高併發需求。
DN就是儲存和計算節點,這裡是MPP Sharing構架,最多可以支援超千臺DN節點,達到MPP平行計算效果。中間層面是做了一個資料轉發的最佳化,解決MPP在高併發、海量併發複雜查詢場景下的連線問題。
剛才講的多CN需要在事務層面有一個協調節點,我們叫做Global Transaction Manager,透過這樣的一個構架,可以在幾個層面幫助客戶實現資料融合和HTAP構架下的最低成本和最高效的部署模式。
後面會具體講如何在同一個事務層面達到完全實時一致的資料儲存請求和服務,行列混合是如何做到同一套事務模型如何做到行存和列存,資源隔離如何做到TP和AP資源隔離和查詢最佳化,如何同時做到,就是剛才講的HTAP架構。
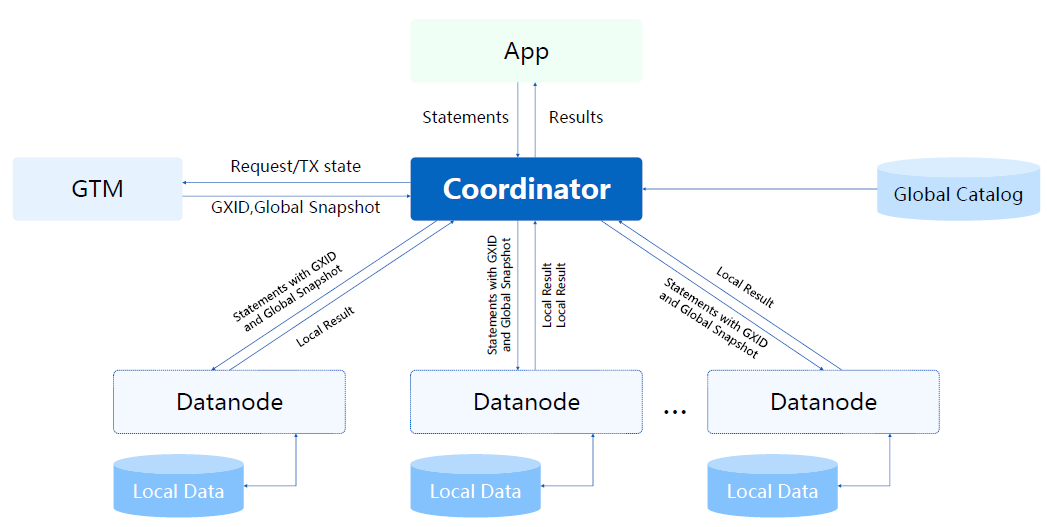
剛才講到我們是多CN節點,其實是需要GTM全域性事務管理模組剝離出來,因為需要對CN和DN提供統一的事務請求。最開始我們是透過全域性事務快照機制在GTM維護活躍事務連結串列,相當於統一處理CN節點請求的快照,但在這種情況下包括GTM節點的單點瓶頸和快照網路傳輸消耗是比較大的。
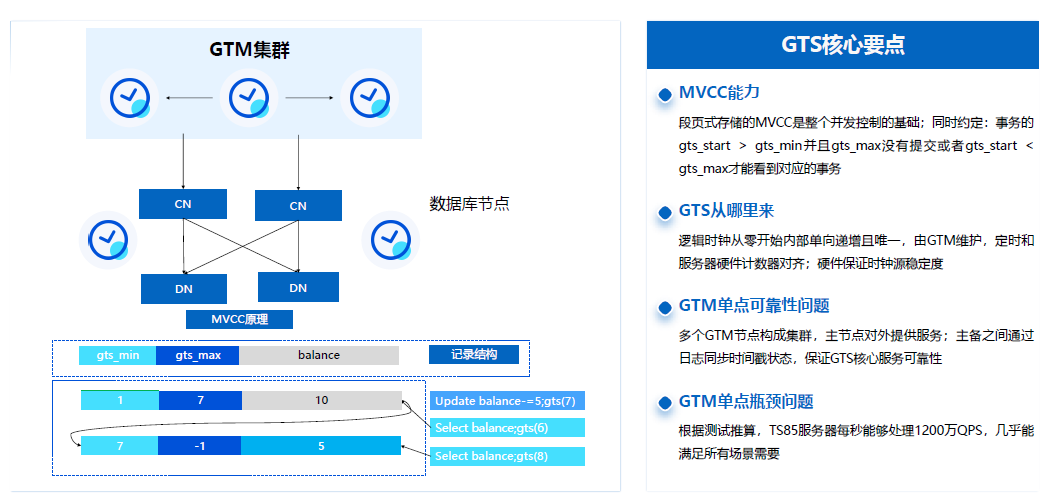
我們2016年就開始做一些探索,結合Spanner和Percolator相關思想做了一些創新和專利發表,然後基於中止提交協議把GTM節點的單點瓶頸解除,相當於把單點事務協調的狀態推到CN或者DN節點去做分散式的協調。
這裡主要是透過基於一個單調遞增的邏輯時間戳,以及基於時間戳的可能性判斷的邏輯調整,GTS也是在GTM節點能做了很多並行生成最佳化,保證單臺TS85伺服器達到1200萬QPS的請求服務標準,然後在這樣的GTM底座下支援叢集多節點的行列混合的事務模型基礎。
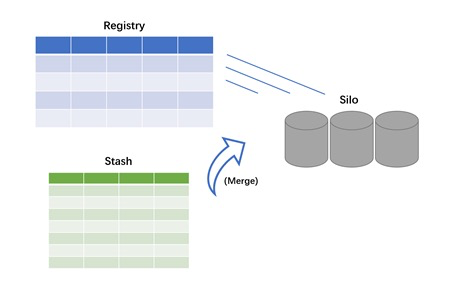
講完事務模型,我們再簡單介紹一下行列混合儲存情況下的事務模型是如何體現的。可能大家對PG行存表相對熟悉一些,簡單介紹一下列存表。為了達到事務層面和行存表一致,其實列存表分為後設資料和使用者資料儲存模組。

後設資料是複用行存表的一些機制,相當於每個列都是按照緊湊排列,每個列存塊相當於一個Silo,就是資料筒倉的概念,後設資料會有一個行表明資料狀態。DML的操作都會根據後設資料表去做一個相應的體現,我們還有一張輔助表把TP場景下短事務的DML操作快取在一張行存表,透過後設資料的行存表和Stash行存表為列存表做後設資料管理和偏TP場景的最佳化。
行列存在很多系統裡面其實是相對割裂的存在,使用者需要在建表的時候瞭解資料模型,然後針對使用者資料模型去建行存表和列存表,選擇偏OLTP場景還是偏OLAP場景。我們這裡需要去做一個透明的最佳化,就是儘量讓使用者體驗更好,不用去選擇我是要用行存表還是列存表。
我們的做法是列存表格式下,使用者可以選擇一個開關建對應的行列混合的表,行存表部分其實就是內嵌一張輔助的行存表,儲存相關的一些OLTP場景的資料,我們會自動地為使用者進行區分,比如使用者業務場景進來,就是小資料量的插入更新,可能會有一個閾值進行設定,會走入行存表Stash表裡面,如果是批次匯入和批次更新,這些資料會直接組織成列存格式,然後以最優的面向查詢請求的方式去做資料編排。
如何做到行存表和列存表同步,而且資料完全一致,我們其實是會有一個背景程式,自動為使用者把行存表裡的資料Stash Merge列存格式,這個動作是透明的,自動為使用者做的。需要強調的一點是,我們的資料是隻有一份,不會產生冗餘的資料儲存帶來的成本開銷,所以我們會透過這樣的一個設計,更加面向企業級使用者。因為是完全實時的、沒有資料冗餘儲存的設計,透明的方案就是這樣設計,帶來這樣一個構架的好處就是面向未來可能更高要求的實時要求和儲存成本要求,我們做到最優。
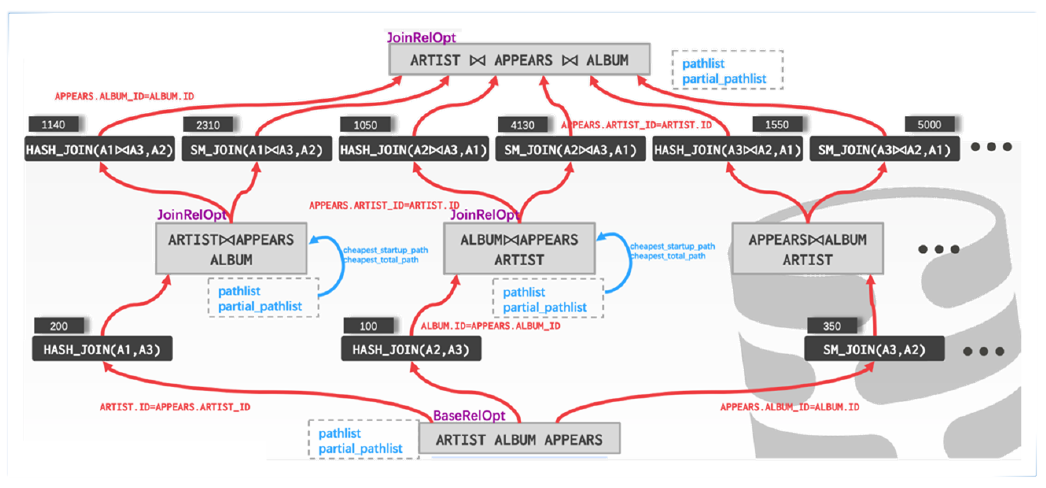
剛才講的是儲存和事務層面,產品最佳化也是做了統一的基於CBO和RBO的最佳化器,典型的動態規劃演算法。多表關聯,每個Level開始規劃單表的執行路徑,可能的Table Scan還是Index Scan,嘗試所有可能的多表關聯、兩表關聯,生成相對應的路徑,然後判斷這一層的Cost,形成狀態轉一函式,完善多層的動態規劃,尋找最優執行計劃的方法。
這個相對比較簡單,要是有並行場景的話就會有更復雜的執行路徑,不同Level去做執行路徑對比的時候其實還需要對並行場景甚至去做一些延遲物化場景做更復雜的轉移判斷,所以整個演算法是相對比較複雜的,我們也是沉澱了比較久,分散式場景、並行場景都有進行很多細緻最佳化。這裡對行存表和列存表都有不同的Cost估算,索引層面列存在多值反覆查詢,沒有快取的情況下其實效果會比較差,所以我們也是針對Bitmap Index Scan去做很多效能最佳化,包括Cost Model的調整保證我們在同一套最佳化器裡面可以支援行存表查詢和列存表查詢,或者混合行列存的查詢。
後續我們已經做到向量化的處理層面,也是在同一套最佳化其判斷哪些運算元可以走向量化,哪些運算元是走偏行級別的,這些都是有場景的,不是所有場景都是向量化更好,這些都是我們很多複雜場景下同一套最佳化其做的最佳化。

之前講的是通用的查詢最佳化,這裡對OLTP場景也有一些針對性的最佳化。圖中就是分散式場景下的兩種層面:PLAN Shipping就是Query在CN節點進行統一場景分片規劃,針對子的場景計劃推到對應的計算節點進行執行計劃,這樣的好處就是對複雜SQL會有一個統一的CN節點去做評估、蒐集和判斷,多分片情況下,不同分片計劃同時可以啟動多個程式進行平行計算,不需要有些等待。
這裡有一個問題就是PLAN在複雜場景下本身的資料量傳輸相對比較大,描述場景計劃需要佔用的網路頻寬比較大,整個過程中也做了一些針對性的最佳化,就是有些SQL可以直接下推到單個DN,可以避免這樣的場景,提高事物高吞吐的場景的要求。要是把Query提前判斷,SQL能夠直接下到DN節點,中間的網路傳輸也是會有比較大的減輕。
如果是一個簡單的單點查詢就是Select ID From Table,傳輸的資料量遠比下推一個場景計劃小很多。透過這種方式,可以大大減輕高併發情況下的網路頻寬的壓力,很好地在同一套系統又支援複雜場景的PLAN Shipping也支援OLTP場景的SQL Shipping,這些是兩個層面維度去做最佳化和執行層面的融合。
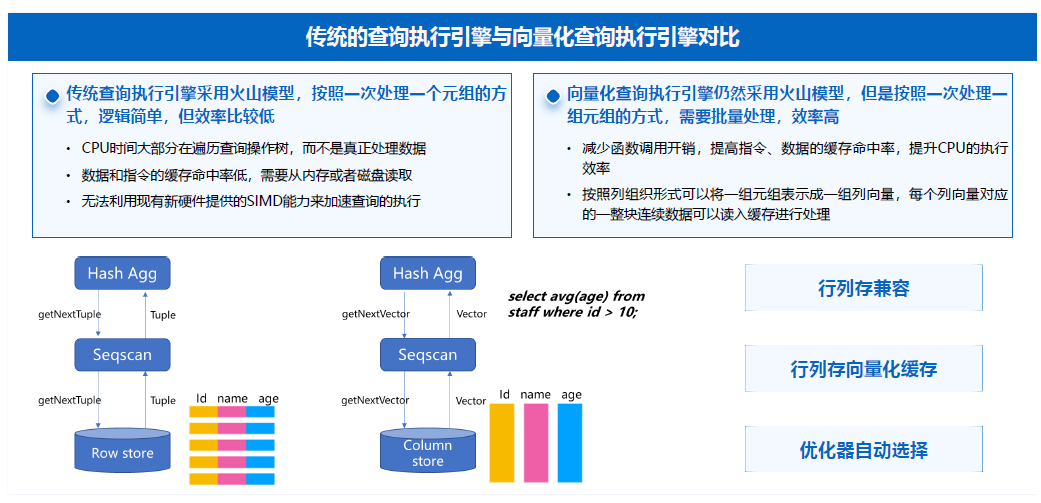
向量化計算就是OLAP場景下如何進行深入最佳化,這個Topic比較大,我們不深入展開,簡單來講就是在OLAP場景下,已經對執行引擎進行深入改造,Scan、網路傳輸和全鏈路的複雜程度更高的語句都可以完全走向量化引擎,最佳化器層面也是自動去做規劃,甚至一個Query裡面有一部分查詢走向更優,資料量減少的情況下要求更快的資料,後面的運算元不走向量化,這些都會有自動的判斷。
向量化引擎也會對行存表和列存表去做向量化執行:行存表會有一個運算元做資料型別的轉換,轉換成記憶體格式計算,列存表本身是原生,就是向量化掃描的,記憶體執行效率會因為有向量化執行去做進一步的效能最佳化。
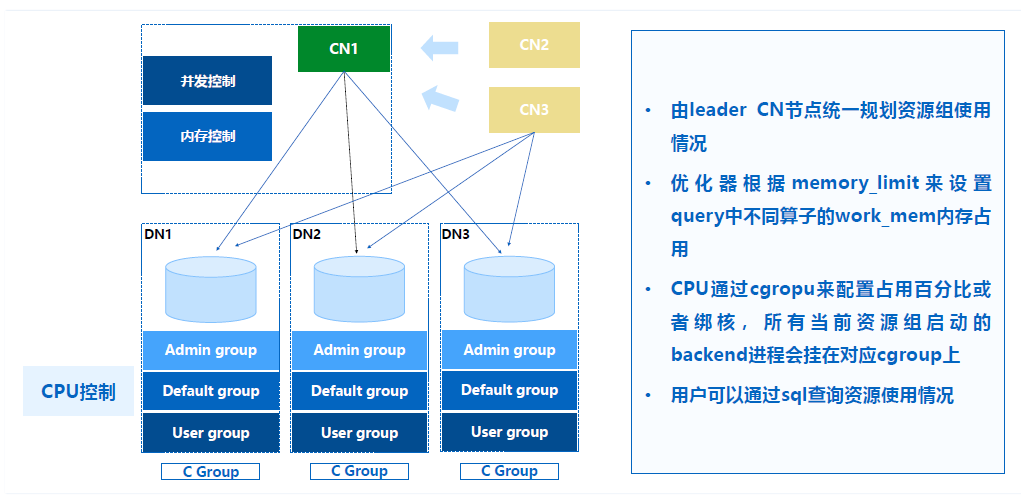
剛才講的就是在儲存和計算層面,其實在資源整合層面我們也做了產品化的能力。我們透過資源組來做資源隔離,就是使用者可以配置系統叢集上的資源是如何分成不同的池子,相當於可以把使用者的業務請求放到不同的資源組裡面去做隔離,我們是做到CPU、記憶體、併發度和佇列等待的能力。
這裡是透過CPU進行強隔離,記憶體是透過增強查詢最佳化器動態規劃,Query在每個運算元到底需要多少記憶體,PLAN限定好對應運算元的記憶體使用量,去做一個靈活的規劃,保證不會超過資源組的資源限制,如果超過的話使用者可以配置不同User裡面的優先順序去做任務排程的等待和任務插入的操作。透過這種層面,我們可以對TP、AP甚至AP場景下不同的使用者組或者任務組去做隔離。
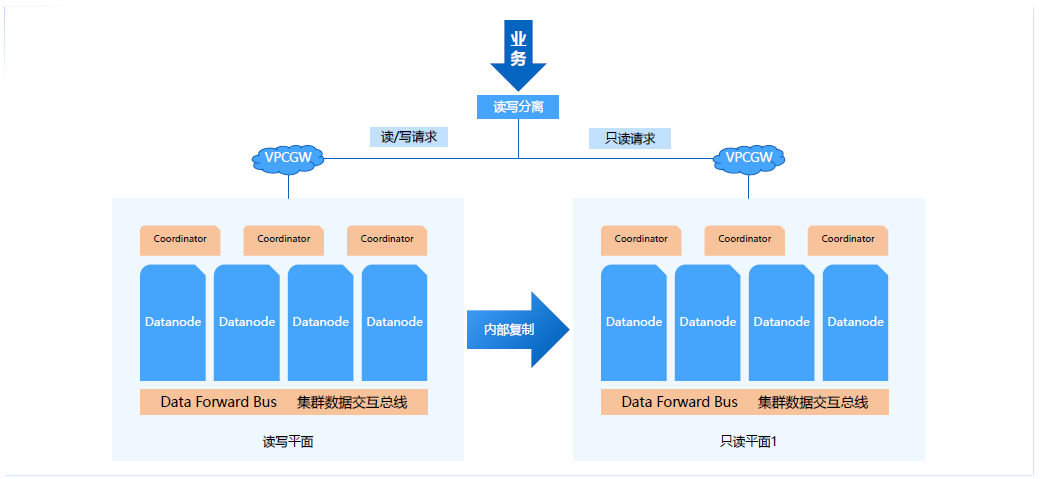
剛才講的是同一套例項中的邏輯隔離的方式,其實這裡我們也可以透過主備平面達到物理隔離,就是可以在主叢集的備節點形成備平面,透過備平面支援只讀請求。
這裡備平面和主平面是內部的物理複製,透過物理複製效率就會比較高,使用者可以配置完全實時還是隻是傳輸日誌,或者只要主平面提交就可以,這些都可以做到靈活配置,使用者也可以配置一個強實時同步。
透過這樣的讀寫請求,達到資源平面隔離的方式,透過更多的資源或者更多的物理資源去做物理隔離,邏輯和物理層面可以做到多租戶、多業務的隔離。
三、後續探索
剛才講的這些都是TDSQL本身已經實現的HTAP相關的能力,我們後面還會持續為大家在同一套系統同時達到TP和AP儲存、計算以及最佳化層面完全一致的融合,不是兩套系統做流式複製的融合方案。
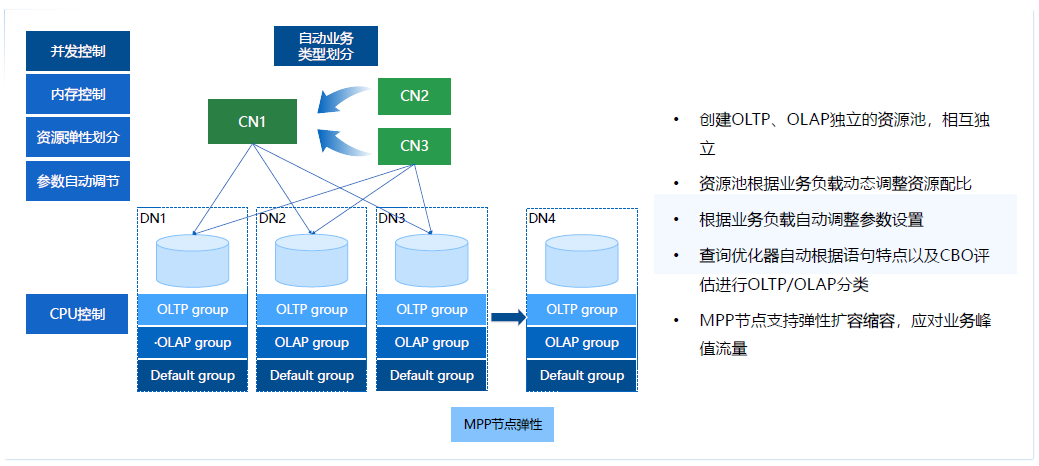
我們認為需要持續最佳化的是幾個方向:併發控制、記憶體控制、資源彈性劃分以及引數自動調解。白天營業的狀態下TP場景可能更多,夜裡AP場景可能更多,如何去做一個動態的調整,引數可以根據業務模型去做自動規劃,自動和智慧的業務劃分其實都是我們未來持續探索的一個方向,持續為大家提供一個完全透明、單系統的HTAP方案。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/28285180/viewspace-2929970/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 騰訊雲TDSQL-C雲原生資料庫技術SQL資料庫
- MPP 資料庫資料庫
- CNCC技術論壇|分散式資料庫HTAP的探索與實踐分散式資料庫
- HTAP資料庫技術的現在和未來資料庫
- 騰訊雲 雲資料庫遷移資料庫
- 國產開源資料庫:騰訊雲TBase在分散式HTAP領域的探索與實踐資料庫分散式
- 攻克資料庫核心技術壁壘,騰訊雲推出新一代企業級雲資料庫CynosDB資料庫
- 騰訊雲資料庫生態經資料庫
- 被低估的騰訊雲資料庫資料庫
- 騰訊雲資料庫的向上之路資料庫
- 騰訊基於全時態資料庫技術的資料閃回資料庫
- 什麼是騰訊雲資料庫 CynosDB?雲資料庫 TencentDB for CynosDB 的特性資料庫
- 為資料賦能:騰訊TDSQL分散式金融級資料庫前沿技術SQL分散式資料庫
- 【招聘資訊】騰訊雲資料庫高階專家資料庫
- 騰訊分散式資料庫TDSQL榮獲技術卓越獎分散式資料庫SQL
- 騰訊雲原生資料庫TDSQL-C架構探索和實踐資料庫SQL架構
- 天雲資料Hubble資料庫透過信通院首批HTAP資料庫產品評測資料庫
- 入選國際資料庫頂級會議ICDE,騰訊雲資料庫技術創新獲權威認可資料庫
- 天雲大資料獲1億增資,釋出HTAP資料庫Hubble大資料資料庫
- 最佳實踐:騰訊HTAP資料庫TBase助力某省核心IT架構升級資料庫架構
- 騰訊雲王義成 騰訊雲資料庫賦能企業釋放資料生產力資料庫
- 騰訊雲資料庫2021年成績單!資料庫
- 如何理解騰訊雲資料庫戰略升級?資料庫
- 向量資料庫技術全景資料庫
- 4篇論文入選資料庫頂會,騰訊雲突破資料庫效能瓶頸資料庫
- 站在騰訊雲資料庫的2022年看中國資料庫的現狀和未來資料庫
- MySQL之父造訪騰訊雲 為騰訊雲資料庫開源點贊MySql資料庫
- 在PGConf.Asia-中文技術論壇,聆聽騰訊雲專家對資料庫技術的深度理解GC資料庫
- 騰訊雲劉迪 新一代雲原生資料庫關鍵技術解析與最佳實踐資料庫
- 從技術角度看騰訊雲“資料丟失”事件!事件
- 騰訊資料治理技術實踐
- 突破、進化,騰訊雲資料庫2018全年盤點資料庫
- 日吞吐萬億,騰訊雲時序資料庫CTSDB解密資料庫解密
- 對話蔣傑、丁奇,騰訊雲資料庫之路資料庫
- 資料庫圈周盤點:騰訊Q2財報首次披露資料庫收入增幅;《雲原生資料庫白皮書》釋出資料庫
- 資料庫HTAP能力強弱怎麼看資料庫
- HTAP資料庫及應用場景分析資料庫
- 【資料庫系統】資料庫系統概論====第十三章 資料庫技術發展資料庫