位元組序分為儲存器位元組序和網路位元組序(通常採用大端),這裡主要討論的是主儲存器位元組序。
主存是儲存器中的一種,為什麼只討論主存?因為編寫執行在現代主流作業系統上的程式,是沒有 I/O 許可權的。
主存位元組序
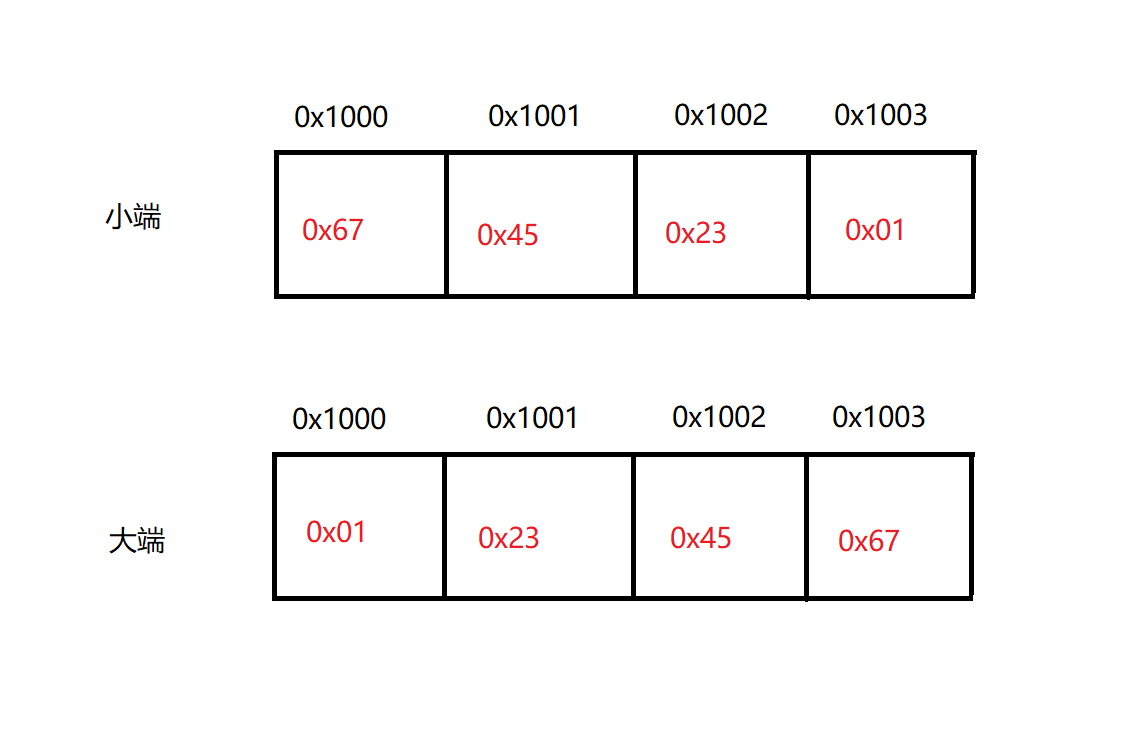
所謂位元組序就是位元組排列的順序,拿主存來說就是如果低位元組存放在低地址處,就是低端位元組序(小端),反之為高階位元組序(大端)。拿 0x1234567 來說:
判斷位元組序
- 透過指標
既然位元組序就是位元組的排列順序,那麼我們把至少 2 位元組的位元組序列存放到主存中,如果能獲取該資料的最低或最高地址的 1 位元組資料,不就知道位元組序了嗎?對應 C/C++ 來說就是指標。
#include <stdio.h>
int main(void)
{
unsigned int i = 1;
char *ch_ptr = (char*)&i; // 建立一個指向 i 的字元(位元組)指標
if (*ch_ptr)
{
printf("Little-Endian\n"); // 如果 *ch_ptr 為 1,表示最低位位元組為 1,為小端
}
else
{
printf("Big-Endian\n"); // 否則為大端
}
return 0;
}
為了保障可移植性,我這裡用的是 unsigned int i,以確保每個平臺都至少 2 個位元組。其它資料型別甚至是陣列都是可以的,沒有本質的區別,都是在主存中儲存相應數量的位元組序列。
- 使用聯合體(Union)
聯合體允許在相同的記憶體位置儲存不同的資料型別,並且可以透過不同的成員來檢視同一塊記憶體區域。利用該特性,我們可以在聯合體中定義兩個成員,其中一個成員確保為 1 位元組(當然,也可以定義成陣列,然後取陣列中的第一個元素),而另一個成員則確保每個平臺都至少為 2 位元組。
#include <stdio.h>
typedef union
{
unsigned int i;
char byte;
} ByteOrder;
int main(void)
{
ByteOrder order;
order.i = 1; // 將整數 1 儲存到聯合體中
if (order.byte)
{
printf("Little-Endian\n"); // 如果最低位位元組儲存的是 1,則為小端
}
else
{
printf("Big-Endian\n"); // 否則為大端
}
return 0;
}
如前所述,char byte 可以改為 char ch_arr[sizeof(unsigned int)] 形式的陣列,然後需要將 order.byte 改為 order.ch_arr[0]。
這兩種方法本質上是一樣的,都是透過判斷資料的低位位元組在記憶體中的位置來判斷位元組序。可以根據實際情況選擇其中一種方法來使用。
除了使用聯合體和指標外,還有一些其它方法可以檢測位元組序。
- 位移和掩碼
這種方法利用位操作(位移和掩碼)來檢測位元組序。它不依賴於聯合體,也不需要指標操作,而是直接透過數值操作來判斷:
#include <stdio.h>
int main(void)
{
unsigned int i = 1; // 只有最低位是 1 的整數
if ( (i >> 0) & 1 ) // 將 i 右移 0 位後與 1 進行與操作
{
printf("Little-Endian\n");
}
else
{
printf("Big-Endian\n");
}
return 0;
}
這種方法簡單明瞭,透過將整數 1(其二進位制形式在小端中為 01 00 00 00,在大端中為 00 00 00 01)的最低位(最右邊的位)與 1 進行與操作。如果結果為 1,那麼說明機器是小端位元組序。
這種方法的好處是程式碼簡單,且沒有使用額外的記憶體(如聯合體或指標)。它直接透過整型數值本身的操作來確定位元組序。
效能對比
-
聯合體:這種方法涉及訪問聯合體的不同成員。聯合體方法的優點是直觀易懂,但訪問聯合體成員可能導致微小的效能開銷,尤其是在編譯器最佳化不足的情況下。
-
指標:這種方法涉及將一個整數的地址轉換為字元指標,然後檢查具體的位元組。這種方法可能稍微快一點,因為它直接操作記憶體,沒有額外的抽象層。然而,這通常是微不足道的。
-
位移和掩碼:此方法使用位操作來檢查位元組序。位操作效率非常高,因為它是直接在暫存器級別上進行的,沒有記憶體訪問的開銷。
在大多數實際應用中,位元組序的檢查通常只在程式啟動或初始化階段進行一次,因此這裡的效能差異幾乎可以忽略不計。即便如此,從純粹理論和微最佳化的角度來看,位移和掩碼方法可能是最快的,因為它避免了任何記憶體訪問,直接在處理器中完成所有操作。
然而,選擇哪種方法應該基於程式碼的可讀性、可維護性以及平臺相容性,而不僅僅是微小的效能差異。在大多數情況下,清晰和正確的程式碼要比微小的效能提升更加重要。
其它方法
除了前面提到的 3 種常見方法,還可以使用一些更具體或高階的技術來檢測或處理位元組序問題,尤其是在涉及到跨平臺相容性或網路通訊時。
標準庫函式
在某些程式設計環境中,標準庫提供了函式來處理位元組序問題。例如,在 C 語言中,網路程式設計常用的庫如 <arpa/inet.h> 提供了 htonl() 和 ntohl() 函式,用於將主機位元組序轉換為網路位元組序,或反之。這些函式自動考慮了底層平臺的位元組序:
#include <stdio.h>
#include <arpa/inet.h>
int main(void)
{
unsigned int x = 0x12345678;
unsigned int y = htonl(x); // 主機到網路位元組序
if (y == x)
{
printf("Big-Endian\n");
}
else
{
printf("Little-Endian\n");
}
return 0;
}
該方法不僅能判斷位元組序,還能在需要的時候轉換位元組序,非常適合網路通訊中的資料交換。
編譯器特定的預定義宏
一些編譯器提供預定義的宏來指示目標平臺的位元組序。例如,GCC 和一些其他編譯器可能定義了特定的宏,可以在編譯時判斷位元組序。這種方法在編譯時就確定了位元組序,無需執行時檢測。
- GCC 和 Clang 編譯器
GCC 和 Clang 通常不直接提供檢測位元組序的宏,但你可以根據平臺或者架構特定的預定義宏來推斷位元組序。例如,你可以檢查是否定義了特定於某個架構的宏:
#include <stdio.h>
int main(void)
{
#if defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
printf("Little-endian\n");
#elif defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
printf("Big-endian\n");
#else
printf("Unknown byte order\n");
#endif
return 0;
}
這裡使用了 GCC 和 Clang 編譯器提供的 __BYTE_ORDER__ 宏以及相關的 __ORDER_LITTLE_ENDIAN__ 和 __ORDER_BIG_ENDIAN__ 宏來確定位元組序。
- MSVC 編譯器
MSVC 編譯器沒有直接提供檢測位元組序的宏,因為 Windows 平臺通常是小端位元組序。如果你在使用 Visual Studio 且需要編寫可移植的程式碼,可能需要自行定義這些宏或者使用其他方法來確定位元組序。
- 跨平臺編譯
如果專案涉及不同的編譯器和平臺,就需要組合多種方法來使用,確保在這些宏未定義的情況下中也能夠處理。
#include <stdio.h>
int main(void)
{
#if defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_LITTLE_ENDIAN__
printf("Little-endian\n");
#elif defined(__BYTE_ORDER__) && __BYTE_ORDER__ == __ORDER_BIG_ENDIAN__
printf("Big-endian\n");
#elif defined(_BIG_ENDIAN)
printf("Big-endian\n");
#elif defined(_LITTLE_ENDIAN)
printf("Little-endian\n");
#else
printf("Byte order unknown or assuming default (e.g., little-endian)\n");
#endif
return 0;
}
常見 CPU 的位元組序
- 大端位元組序:IBM、Sun、PowerPC。
- 小端位元組序:x86、DEC 。
ARM 體系的 CPU 則大小端位元組序通吃,具體用哪類位元組序由硬體選擇。