python實現機率語言零和博弈
一篇 2021 年徐澤水老師《 The two-person and zero-sum matrix game with probabilistic linguistic information 》的一區論文的獨立重複實驗。
基本思想是將機率語言標準化,之後解模糊為三角模糊數的形式,最後帶入線性規劃進行納什均衡的求解。程式碼如下,關鍵步驟有註釋。
'''
想到一個好方法,如果對矩陣轉置,就可以很方便的獲得按列的切片,而不用大費周折了。
drop 函式刪除多行,使用的是 label 標籤而不是直接 [].
reset_values 函式中的 drop 引數代表的是是否丟棄原標籤。
而如何用新列替換舊列呢,不需要額外的 replace 函式,就是簡單的新增列 remp 儲存資料,然後 temp 賦值給指定的列,然後刪掉 temp 即可,
這就是之前三步交換元素的方法,放在這裡交換數列完全可行。
'''
from scipy import optimize as op
import numpy as np#scipy 包實現線性規劃
np.set_printoptions(suppress=True)
import pandas as pd
def getdef(n):# 匯入矩陣
df = pd.read_excel('D:\study\\test\data\\t14.xlsx',sheet_name=n)# 地址中包含 t 會被轉義,加雙斜槓即可
return df
def getmatrix(df,n):# 按照每個屬性對矩陣進行分組
df= df.loc[:, n:n + 3]
return df.T.reset_index(drop=True).T# 使用轉置消除列元素的索引成一個新的矩陣,不然切片形式會對後面的引用造成很大的困擾。
def getdivied(df,n):# 按照相通屬性的方案進行分組
df= df[n::3]
# print(df)
return df.reset_index(drop=True).T
def nornal_index(df):# 矩陣下標的標準化
df=df.reset_index(drop=True)
return df.T.reset_index(drop=True).T
def getnormal(df):# 補全機率
df[4]=df[1]+(1-df[1]-df[3])/2# 補全機率,可以直接作用在整個一列,因為如果加起來已經等於一,就不會在變大了。
df[5]=df[3]+(1-df[1]-df[3])/2
df[1]=df[4]
df[3]=df[5]
return df.drop(labels=[4,5],axis=1)
def gettrangle(df):# 解模糊方法
df1=pd.Series(1.25*(df[0]-1)*df[1])
df2=pd.Series(1.25*(df[0])*df[1])
df3=pd.Series(1.25*(df[0]+1)*df[1])
df4 = pd.Series(1.25 * (df[2] - 1) * df[3])
df5 = pd.Series(1.25 * (df[2]) * df[3])
df6 = pd.Series(1.25 * (df[2] + 1) * df[3])
d1=df1+df4
d2=df2+df5
d3=df3+df6
return pd.concat((d1,d2,d3),axis=1)
def getnashy(df):# 對 y 求解納什均衡
c=np.array([0,0,0,0,1,0,0])
A_ub=np.array(df)
B_ub=np.array([0,0,0,0,0,0,0,0,0])
A_eq=np.array([[1,1,1,1,0,0,0]])
B_eq=np.array([1])
x1=(0,1)
x2=(0,1)
x3=(0,1)
x4=(0,1)
x5=(None,None)
x6=(0,None)
x7=(0,None)
res=op.linprog(c,A_ub,B_ub,A_eq,B_eq,bounds=(x1,x2,x3,x4,x5,x6,x7))
return res.x
def getnashx(df):# 對 x 求解納什均衡
c = np.array([0, 0, 0, 1, 0, 0])
A_ub = np.array(df)
B_ub = np.array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
A_eq = np.array([[1, 1, 1, 0, 0, 0]])
B_eq = np.array([1])
x1 = (0, 1)
x2 = (0, 1)
x3 = (0, 1)
x5 = (None, None)
x6 = (0, None)
x7 = (0, None)
res = op.linprog(-c, A_ub, B_ub, A_eq, B_eq, bounds=(x1, x2, x3, x5, x6, x7))
return res.x
if __name__ == '__main__':
df = getdef(0)
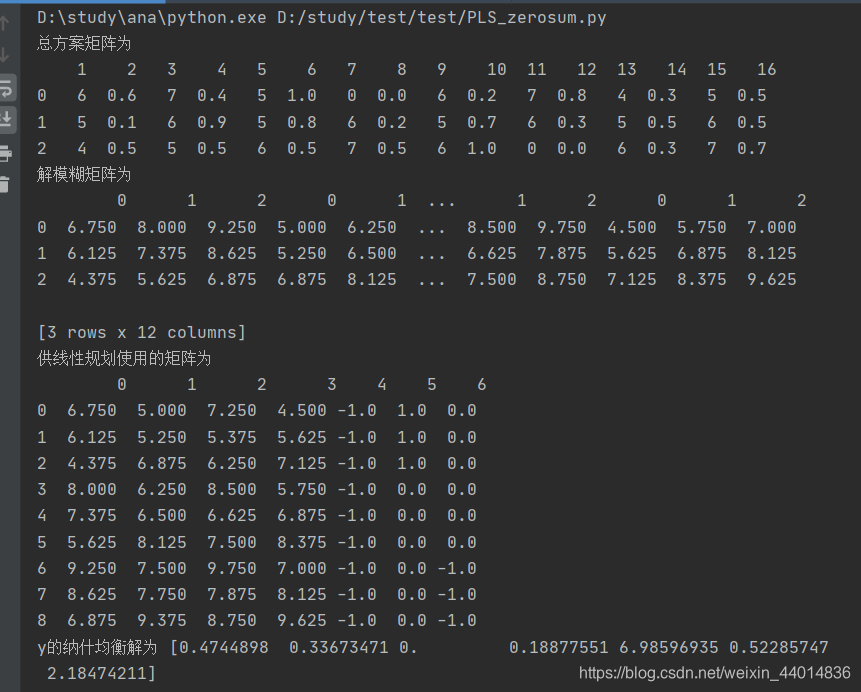
print(' 總方案矩陣為 \n',df)
df4=getmatrix(df,13)
df3=getmatrix(df,9)
df2=getmatrix(df,5)
df1=getmatrix(df,1)
df5=getnormal(df4)# 對需要更新資料的分組呼叫更新函式
dfsum=pd.concat((gettrangle(df1),gettrangle(df2),gettrangle(df3),gettrangle(df5)),axis=1)# 再將分組的拼接起來。
print(' 解模糊矩陣為 \n',dfsum)
dfliner_valuesy=nornal_index(getdivied(dfsum.T,0).append(getdivied(dfsum.T,1)).append(getdivied(dfsum.T,2)))
# y 因為線性規劃等式右邊的不能從姐模糊矩陣獲得 ,外匯跟單gendan5.com 因此單獨列出來再做拼接
df_valuesy=pd.DataFrame([[-1,1,0],[-1,1,0],[-1,1,0],[-1,0,0],[-1,0,0],[-1,0,0],[-1,0,-1],[-1,0,-1],[-1,0,-1]])
dfy=nornal_index(pd.concat((dfliner_valuesy,df_valuesy),axis=1))# 每次對拼接好的新矩陣使用索引重置方法。
print(' 供線性規劃使用的矩陣為 \n',dfy)
print('y 的納什均衡解為 ',getnashy(dfy))
tempx=nornal_index((getdivied(dfsum.T,0).T).append(getdivied(dfsum.T,1).T).append(getdivied(dfsum.T,2).T))
dfliner_valuesx=tempx.applymap(lambda x:-x)# 匿名函式將矩陣每一個元素變號,因為大於零的約束需要化為小於零的形式。
print(dfliner_valuesx)
df_valuesx=pd.DataFrame([[1,-1,0],[1,-1,0],[1,-1,0],[1,-1,0],[1,0,0],[1,0,0],[1,0,0],[1,0,0],[1,0,1],[1,0,1],[1,0,1],[1,0,1]])
dfx=nornal_index(pd.concat((dfliner_valuesx,df_valuesx),axis=1))# 每次對拼接好的新矩陣使用索引重置方法。
print(' 供線性規劃使用的矩陣為 \n',dfx)
print('x 的納什均衡解為 ',getnashx(dfx))```
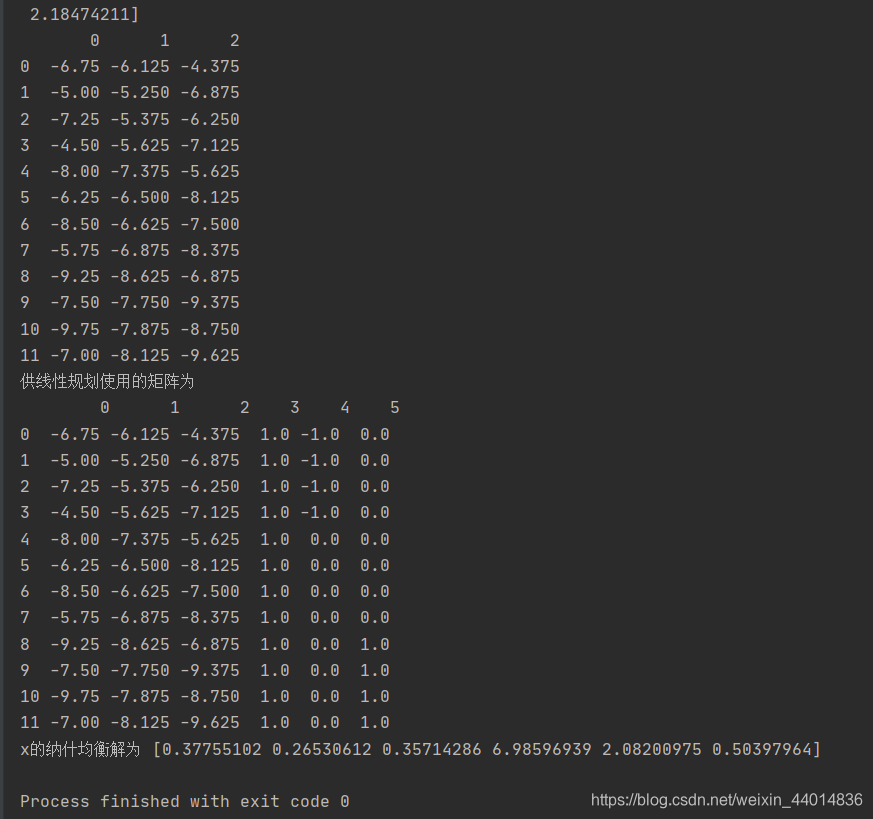



最後的三角模糊數還原機率語言術語沒有實現,這個地方沒看太懂算出來不對,回頭再補充。
github 倉庫在
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/69946337/viewspace-2779138/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- Python語言認識和實用工具(1)Python
- 使用Python語言通過PyQt5和socket實現UDP伺服器PythonQTUDP伺服器
- 三種語言實現快速排序(C++/Python/Java)排序C++PythonJava
- 三種語言實現差分(C++/Python/Java)C++PythonJava
- Go語言實現RPCGoRPC
- 如何使用Python語言實現計數排序演算法?Python排序演算法
- 三種語言實現歸併排序(C++/Python/Java)排序C++PythonJava
- python和r語言的區別PythonR語言
- 掃雷--C語言實現C語言
- go語言實現掃雷Go
- c語言實現階乘C語言
- 人工智慧全球合作不會是“零和博弈”人工智慧
- python中如何實現資訊增益和資訊增益率Python
- 支援向量機(SVM)和python實現(二)Python
- 回溯和遞迴實現迷宮問題(C語言)遞迴C語言
- 詞!自然語言處理之詞全解和Python實戰!自然語言處理Python
- Python 和 C 語言學哪個更好?Python
- [譯]用javascript實現一門程式語言-語言構想JavaScript
- C語言__LINE__實現原理C語言
- go語言實現ssh打隧道Go
- Go語言interface底層實現Go
- so easy 前端實現多語言前端
- C語言實現檔案加密C語言加密
- c語言實現this指標效果C語言指標
- 高精度加法(C語言實現)C語言
- .NET CORE 多語言實現方案
- go語言依賴注入實現Go依賴注入
- C語言實現TCP通訊C語言TCP
- Go語言實現TCP通訊GoTCP
- GO語言 實現埠掃描Go
- C語言 形參和實參C語言
- 《自然》證實:計算機語言更類似人類語言計算機
- 用JavaScript實現一門程式語言 2 (λanguage語言簡介)JavaScript
- Bash 和 Python 程式語言優缺點分析Python
- Python和C語言區別是什麼?PythonC語言
- Python和C語言有什麼區別?PythonC語言
- 對數機率迴歸(邏輯迴歸)原理與Python實現邏輯迴歸Python
- 機器學習實戰----k值近鄰演算法(Python語言)機器學習演算法Python