不代表全部內容
- 第一章 C++引論
- 教材和參考資料
- 1.1程式設計語言
- 1.2程式編譯技術
- 第二章 型別、常量及變數
- 2.1 C++的單詞
- 2.2 預定義型別(內建資料型別)及值域和常量
- 2.2.1 常見預定義型別
- 2.2.2預定義型別的數值輸出格式化
- 2.3 變數及其型別解析
- 2.3.1 變數的宣告和定義(C++11標準3.1節)
- 2.3.2 變數的初始化(C++11標準8.5節)
- 2.3.3 constexpr(c++11)
- 2.3.4 複合型別(C++11標準3.9.2)
- 2.3.5 指標及其型別理解
- 2.4 引用
- 2.4.1 左值和右值
- 2.4.2 引用的本質
- 2.4.3 引用初始化
- 2.4.3.1 為什麼非const引用不能用右值或不同型別的物件初始化?
- 2.4.3.2 &定義的有址引用(左值引用)
- 2.4.3.3 &&定義的無址引用(右值引用)
- 2.5 列舉、陣列
- 2.5.1 列舉
- 2.5.2 元素、下標及陣列
- 2.6 運算子及表示式
第一章 C++引論
教材和參考資料
教材:C++程式設計實踐教程(新國標微課版)
出版:華中科技大學出版社
編著:馬光志
參考文獻 : C++ Primer(第五版)
深度探索C++物件模型
C++ 11標準
1.1程式設計語言
- 機器語言: 計算機自身可以識別的語言(CPU指令)
- 組合語言: 接近於機器語言的符號語言(更便於記憶,如MOV指令)
- 高階語言: 更接近自然語言的程式設計語言,如ADA、C、PASCAL、FORTRAN、BASIC(程序導向,程式基本單元是函式)
- 物件導向的語言:描述物件“特徵”及“行為”的程式設計語言,如C++、Java、C#、SMALLTALK等(程式基本單元是類)
1.2程式編譯技術
編譯過程: 預處理、詞法分析、語法分析、程式碼生成、模組連線。
- 預處理:透過#define宏替換和#include插入檔案內容生成純的不包含#define和#include等的C或C++程式。
- 詞法分析:產生一個程式的單詞序列(token)。一個token可以是保留字如if和for、識別符號如sin、運算子如+、常量如5和 "abcd"等。
- 語法分析:檢查程式語法結構,例如if後面是否出現else。
- 程式碼生成:生成低階語言程式碼如機器語言或組合語言。C和C++語言的識別符號編譯為低階語言識別符號時會換名,C和C++的換名策略不一樣。程式碼生成的是中間程式碼(如.OBJ檔案)
- 模組連線:將中間程式碼和標準庫、非標準庫連線起來,形成一個可執行的程式。靜態連線是編譯時由編譯程式完成的連線,動態連線是執行時由作業系統完成的連線。
不同廠家對C++標準的支援程度不一樣。一定要確認當前使用的編譯器是否支援C++11甚至11以上的標準。
在程式編譯過程中,函式呼叫的實現可以透過靜態連結和動態連結兩種方式來完成。
1. 靜態連結
靜態連結是在編譯時將庫的內容與使用者程式的目標檔案(如 .obj 檔案)一起打包,生成最終的可執行檔案(如 .exe)。在靜態連結中,庫檔案(如 f.lib)的內容被直接複製到可執行檔案中。
- 工作過程:
使用者程式編譯後生成的 .obj 檔案會和 f.lib 進行連結。
函式 f 的實現會被直接複製到使用者程式的最終可執行檔案中(如 .exe 檔案)。
當使用者程式啟動時,所有使用到的庫函式,包括 f,都會被載入到記憶體中。
- 記憶體佔用:
如果有多個程式都使用靜態連結,並且都呼叫了函式 f,那麼每個程式的記憶體中都會有一份 f 函式的副本。這意味著每個程式的記憶體中都會儲存一份獨立的 f 函式。
- 優點:
不需要在執行時載入庫,所有依賴的庫函式已經嵌入到可執行檔案中,因此不會遇到庫缺失的問題。
程式的啟動速度較快,因為所有的程式碼已經在編譯時整合。
- 缺點:
由於每個程式都包含了庫的副本,多個程式會導致記憶體的重複使用。
如果庫函式需要更新,所有使用靜態連結的程式都需要重新編譯。
- 例子:
在靜態連結的情況下,假設程式 A 和程式 B 都呼叫了函式 f,它們的 .exe 檔案中都會包含 f 的實現。因此,在記憶體中,程式 A 和程式 B 各自有一個 f 函式的副本。
2. 動態連結
動態連結是在執行時才將庫載入到記憶體中,併為程式提供所需的函式實現。庫檔案以動態連結庫的形式存在(如 .dll 檔案),而不是在編譯時嵌入到可執行檔案中。
- 工作過程:
編譯時,使用者程式的 .obj 檔案和 f.dll 檔案進行連結,生成可執行檔案。
在這個過程中,目標檔案中並不會包含 f 函式的實際程式碼,而是隻包含函式 f 的描述資訊。
當程式執行並且呼叫 f 函式時,系統會動態載入 f.dll,並將 f 函式的實現載入到記憶體中供程式使用。
- 記憶體佔用:
動態連結的最大好處之一是,多個程式可以共享同一個庫的副本。也就是說,如果程式 A 和程式 B 都使用 f.dll,那麼 f 函式的實現只會在記憶體中存在一個副本,所有程式共享這一份庫。
- 優點:
節省記憶體:多個程式可以共享動態連結庫的程式碼,不會重複載入函式 f 的實現。
易於更新:庫的實現可以獨立更新,無需重新編譯所有依賴它的程式。只需要替換動態連結庫的檔案即可。
- 缺點:
程式啟動時可能會稍慢,因為需要在執行時載入庫。
執行時依賴動態連結庫,若 .dll 檔案缺失或損壞,程式將無法正常執行。
- 例子:
假設程式 A 和程式 B 都呼叫 f 函式,並且都透過 f.dll 動態連結。在記憶體中,程式 A 和程式 B 都會共享同一個 f 函式的副本,而不會各自有獨立的副本。這大大減少了記憶體的重複使用。
第二章 型別、常量及變數
2.1 C++的單詞
單詞包括常量、變數名、函式名、引數名、型別名、運算子、關鍵字等。
關鍵字也被稱為保留字,不能用作變數名。
預定義型別如int等也被當作保留字
char16_t和char32_t是C++11引入的兩種新的字元型別,用於表示特定大小的Unicode字元
例如 char16_t x = u'馬';
wchar_t表示char16_t ,或char32_t
nullptr表示空指標
需要特別注意的是:char可以顯示地宣告為帶符號的和無符號的。因此C++11標準規定char,signed char和unsigned char是三種不同的型別。
但每個具體的編譯器實現中,char會表現為signed char和unsigned char中的一種。
unsigned char ua = ~0;
printf("%d ", ua);//輸出255
signed char ub = ~0;
printf("%d ", ub);//輸出-1
char uc = ~0;
printf("%d", uc);//輸出-1
2.2 預定義型別(內建資料型別)及值域和常量
2.2.1 常見預定義型別
型別的位元組數與硬體、作業系統、編譯有關。假定VS2019採用X86編譯模式。
void:位元組數不定,常表示函式無參或無返回值。
void
是一個可以指向任意型別的指標型別。它本質上是一個“無型別”*的指標,這意味著它可以指向任何型別的資料,而不關心具體的資料型別。
int n = 0721;//前置0代表8進位制
double pi = 3.14;
void* p = &n;
cout << *(int*)p << endl;//不能直接解引用哦
p = π
cout << *(double*)p << endl;
- bool:單位元組布林型別,取值false和true。
- char:單位元組有符號字元型別,取值-128~127。
- short:兩位元組有符號整數型別,取值-32768~32767。
- int:四位元組有符號整數型別,取值-231~231-1 。
- long:四位元組有符號整數型別,取值-231~231-1 。
- float:四位元組有符號單精度浮點數型別,取值-1038~1038。
- double:八位元組有符號雙精度浮點數型別,取值-10308~10308。
注意:預設一般整數常量當作為int型別,浮點常量當作double型別。 - char、short、int、long前可加unsigned表示無符號數。
- long int等價於long;long long佔用八位元組。
- 自動型別轉換路徑(數值表示範圍從小到大):
char→unsigned char→ short→unsigned short→ int→unsigned int→long→unsigned long→float→double→long double。
數值零自動轉換為布林值false,數值非零轉換為布林值true。 - 強制型別轉換的格式為:
(型別表示式) 數值表示式 - 字元常量:‘A’,‘a’,‘9’,‘\’’(單引號),‘\’(斜線),‘\n’(換新行),‘\t’(製表符),‘\b’(退格)
- 整型常量:9,04,0xA(int); 9U,04U,0xAU(unsigned int); 9L,04L,0xAL(long); 9UL, 04UL,0xAUL(unsigned long), 9LL,04LL,0xALL(long long);
這裡整型常量的型別相信大家看後面的字母也能看出來,例如L代表long,U代表unsigned
2.2.2預定義型別的數值輸出格式化
- double常量:0.9, 3., .3, 2E10, 2.E10, .2E10, -2.5E-10
- char: %c; short, int: %d; long:%ld; 其中%開始的輸出格式符稱為佔位符。
- 輸出無符號數用u代替d(十進位制),八進位制數用o代替d,十六進位制用x代替d
- 整數表示寬度如printf(“%5c”, ‘A’)列印字元佔5格(右對齊)。%-5d表示左對齊。
- float:%f; double:%lf。float, double:%e科學計數。%g自動選寬度小的e或f。
- 可對%f或%lf設定寬度和精度及對齊方式。“%-8.2f”表示左對齊、總寬度8(包括符號位和小數部分),其中精度為2位小數。
- 字串輸出:%s。可設定寬度和對齊:printf(“%5s”,”abc”)。
- 字串常量的型別:指向只讀字元的指標即const char *, 上述”abc“的型別。
- 注意strlen(“abc”)=3,但要4個位元組儲存,最後儲存字元‘\0’,表示串結束。
2.3 變數及其型別解析
2.3.1 變數的宣告和定義(C++11標準3.1節)
- 變數說明:描述變數的型別及名稱,但沒有初始化。可以說明多次。
- 變數定義:描述變數的型別及名稱,同時進行初始化。只能定義一次。
- 說明例子:extern int x; extern int x; //變數可以說明多次
- 定義例子:int x=3; extern int y=4; int z; //全域性變數z的初始值為0
- 模組靜態變數:使用static在函式外部定義的變數,只在當前檔案(模組)可用。可透過單目::訪問。
- 區域性靜態變數:使用static在函式內部定義的變數。
static int x, y; //模組靜態變數x、y定義,預設初始值均為0
int main( ){
static int y; //區域性靜態變數y定義, 初始值y=0
return ::y+x+y;//分別訪問模組靜態變數y,模組靜態變數x,區域性靜態變數
}
為了允許把程式拆分成多個邏輯部分來編寫,C++支援分離式編譯(separation compilation),即將程式分成多個檔案,每個檔案獨立編譯。
為了支援分離式編譯,必須將宣告(Declaration)和定義(Definition)區分開來。宣告是使得名字(Identifier,如變數名)為其它程式所知。而定義則負責建立與名字(Identifier)相關聯的實體,如為一個變數分配記憶體單元。因此只有定義才會申請儲存空間。
One definition rule(ODR):只能定義一次,但可以多次宣告
如果想要宣告一個變數而非定義它,就在前面加關鍵字extern,而且不要顯示地初始化變數:
extern int i; //變數的宣告
int i;//變數的定義(雖沒有顯示初始化,但會有初始值並分配記憶體單元儲存,即使初始值隨機)
任何包含顯式初始化的宣告成為定義。如果對extern的變數顯式初始化,則extern的作用被抵消。
extern int i = 0; //變數的定義
宣告和定義的區別非常重要,如果要在多個檔案中使用同一個變數,就必須將宣告和定義分離,變數的定義必須且只能出現在一個檔案中,而其他用到該變數的檔案必須對其宣告,而不能定義。
例如,標頭檔案裡不要放定義,因為標頭檔案可能會被到處include,導致定義多次出現。
值得一提的是C++17引入了 inline 變數,這允許在多個翻譯單元中定義同一個全域性變數而不引發重複定義的連結錯誤。inline 變數使得變數像 inline 函式一樣,在多個檔案中共享同一個定義。而在之前的標準中,inline只能用於函式而不能用於變數
- 保留字inline用於定義函式外部變數或函式外部靜態變數、類內部的靜態資料成員。
- inline函式外部變數的作用域和inline函式外部靜態變數一樣,都是侷限於當前程式碼檔案的,相當於預設加了static。
- 用inline定義的變數可以使用任意表示式初始化
// header.h
inline int globalVar = 42;
關於其作用,可見C++17之 Inline變數
此外, C++20 引入了模組(Modules)機制,用於替代標頭檔案的傳統做法。模組減少了編譯依賴並提高了編譯速度。在模組中,變數宣告和定義的規則更為清晰,模組能夠很好地管理變數的可見性和作用範圍。
如有興趣,可見C++20 新特性: modules 及實現現狀
2.3.2 變數的初始化(C++11標準8.5節)
變數在建立時獲得一個值,我們說這個變數被初始化了(initialized)。最常見的形式為:型別 變數名=表示式;//表示式的求值結果為變數的初始值
用=來初始化的形式讓人誤以為初始化是賦值的一種。
其實完全不同:初始化的含義是建立變數時設定一個初始值;而賦值的含義是將變數的當前值擦除,而以一個新值來替代。
實際上,C++定義了多種初始化的形式:
int a = 0;
int b = { 0 };
int c(0);
int d{ 0 };
其中用{ }來初始化作為C++11的新標準一部分得到了全面應用(而以前只在一些場合使用,例如初始化結構變數)。這種初始化形式稱為列表初始化(list initialization)。
只讀變數:使用const或constexpr說明或定義的變數,定義時必須同時初始化。當前程式只能讀不能修改其值。constexpr變數必須用編譯時可計算表示式初始化。
易變變數:使用volatile說明或定義的變數,可以後初始化。當前程式沒有修改其值,但是變數的值變了。不排出其它程式修改。
const例項:extern const int x; const int x=3; //定義必須顯式初始化x
volatile例: extern volatile int y; volatile int y; //可不顯式初始化y,全域性y=0
若y=0,語句if(y==2)是有意義的,因為易變變數y可以變為任何值。
- volatile 的作用
編譯器通常會進行最佳化,將變數的值快取到暫存器中,以提高訪問速度。然而,某些情況下,變數的值可能會在程式執行過程中發生外部變化,例如透過硬體、訊號、作業系統或多執行緒訪問。因此,需要使用 volatile 關鍵字告知編譯器,每次訪問該變數時都要重新讀取記憶體中的值,而不要使用最佳化的快取值。
2.3.3 constexpr(c++11)
**constexpr **是 C++11 引入的關鍵字,主要用於在編譯期計算常量。constexpr 宣告的變數或函式保證可以在編譯時求值,並且在特定條件下也可以在執行時使用。它用於提高編譯期計算的能力,從而最佳化程式的效能。
- 任何被宣告為 constexpr 的變數或物件,必須在編譯時能求出其值。
- constexpr 變數比 const 更加嚴格,所有的初始化表示式必須是常量表示式。
字面值型別:對宣告constexpr用到的型別必須有限制,這樣的型別稱為字面值型別(literal type)。
算術型別(字元、布林值、整型數、浮點數)、引用、指標都是字面值型別
自定義型別(類)都不是字面值型別,因此不能被定義成constexpr
其他的字面值型別包括字面值常量類、列舉
constexpr型別的指標的初始值必須是
- nullptr
- 0
- 指向具有固定地址的物件(全域性、區域性靜態)。
注意區域性變數在堆疊裡,地址不固定,因此不能被constexpr型別的指標指向
當用constexpr宣告或定義一個指標時,constexpr僅對指標有效 ,即指標是const的,
點選檢視程式碼
int i=0;
//constexpr指標
const int *p = nullptr; //p是一個指向整型常量的指標
constexpr int *q = nullptr; //q是一個指向整數的constexpr指標
constexpr int *q2 = 0;
constexpr int *q3 = &i; //constexpr指標初始值可以指向全域性變數i
int f2() {
static int ii = 0;
int jj = 0;
constexpr int *q4 = ⅈ//constexpr指標初始值可以指向區域性靜態變數
//constexpr int *q5 = &jj;//錯誤:constexpr指標初始值不可以指向區域性變數,區域性變數在堆疊,非固定地址
return ++i;
}
constexpr函式:是指能用於常量表示式的函式,規定:
-
函式返回型別和形參型別都必須是字面值型別
-
函式體有且只有一條return語句(c++11)
C++14之後,constexpr 函式可以包含複雜的控制流語句,如 if、for、while 等,這使得 constexpr 函式更加靈活和強大。 -
constexpr函式被隱式地指定為行內函數,因此函式定義可放標頭檔案
-
constexpr函式體內也可以包括其他非可執行語句,包括空語句,型別別名,using宣告
-
在編譯時,編譯器會將函式呼叫替換成其結果值,即這種函式在編譯時就求值
如果傳遞給 constexpr 函式的引數是常量表示式(可以在編譯時求值),那麼編譯器將會在編譯時對這個函式進行求值。
如果引數不是常量表示式,constexpr 函式將作為普通函式在執行時進行求值。 -
constexpr函式返回的不一定是常量表示式
點選檢視程式碼
//constexpr函式
constexpr int new_size() { return 42; }
constexpr int size = new_size() * 2; //函式new_size是constexpr函式,因此size是常量表示式
//允許constexpr返回的是非常量
constexpr int scale(int cnt) { return new_size() * cnt;}
//這時scale是否為constexpr取決於實參
//當實參是常量表示式時, scale返回的也是constexpr
constexpr int rtn1 = scale(sizeof(int)); //實參sizeof(int)是常量表示式,因此rtn1也是
int i = 2;
//constexpr int rtn2 = scale(i); //編譯錯:實參i不是是常量表示式,因此scale返回的不是常量表示式
2.3.4 複合型別(C++11標準3.9.2)
複合型別(Compound Type)是指基於其他型別定義的型別,例如指標、引用。和內建資料型別變數一樣,複合型別也是透過宣告語句(declaration)來宣告。一條宣告語句由基本資料型別和跟在後面的宣告符列表(declarator list)組成。每個宣告符命名一個變數並指定該變數為與基本資料型別有關的某種型別。
複合型別的宣告符基於基本資料型別得到更復雜的型別,如p,&p,分別代表指向基本資料型別變數的指標和指向基本資料型別變數的引用。,&是型別修飾符。
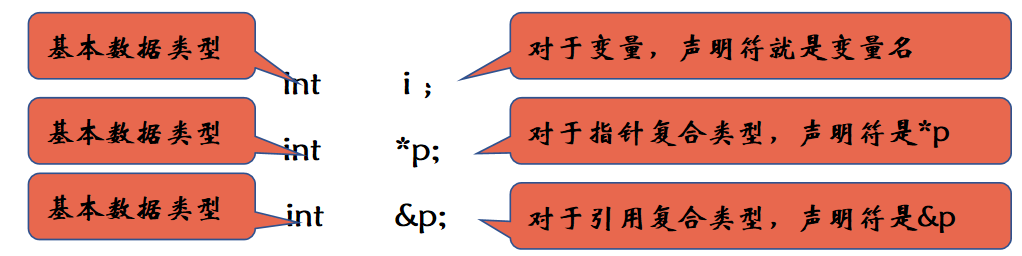
在同一條宣告語句中,基本資料型別只有一個,但宣告符可以有多個且形式可以不同,即一條宣告語句中可以宣告不同型別的變數:
int i, *p, &r; //i是int變數,p是int指標,r是int引用
正確理解了上面的定義,就不會對下面的宣告語句造成誤解:
int * p1,p2; //p1是int指標,p2不是int指標,而是int變數
為了避免類似的誤解,一個好的書寫習慣是把型別修飾符和變數名放連一起:
int *p1,p2, &r1;
2.3.5 指標及其型別理解
-
const預設與左邊結合,左邊沒有東西則與右邊結合
-
指標型別的變數使用*說明和定義,例如:int x=0; int *y=&x;。
-
指標變數y存放的是變數x的地址,&x表示獲取x的地址運算,表示y指向x。
-
指標變數y涉及兩個實體:變數y本身,y指向的變數x。
-
變數x、y的型別都可以使用const、volatile以及const volatile修飾。
const int x=3; //不可修改x的值
const int *y=&x; //可以修改y的值,但是y指向的const int實體不可修改
const int *const z=&x; //不可修改z的值,且z指向的const int實體也不可改 -
在一個型別表示式中,先解釋優先順序高的,若優先順序相同,則按結合性解釋。
如:int *y[10][20];在y的左邊是*,右邊是[10],據表2.7知[ ]的優先順序更高。
解釋: (1) y是一個10元素陣列;(2)每個陣列元素均為20元素陣列
(3) 20個元素中的每個元素均為指標int * -
但括號()可提高運算子的優先順序,如:
int (*z)[10][20];
(…)、[10]、[20]的運算子優先順序相同,按照結合性,應依次從左向右解釋。
因此z是一個指標,指向一個int型的二維陣列,注意z與y的解釋的不同。
指標移動:y[m][n]+1移動到int 指標指向的下一整數,z+1移動到下一1020整數陣列。
指標使用注意事項
-
只讀單元的指標(地址)不能賦給指向可寫單元的指標變數。
例如:
const int x=3; const int *y=&x; //x是隻讀單元,y是x的地址
int z=y; //錯:y是指向只讀單元的指標
z=&x; //錯:&x是是隻讀單元的地址
證明:
(1)假設int z=&x正確(應用反正法證明)
(2)由於int z表示z指向的單元可寫,故z=5是正確的
(3)而z修改的實際是變數x的值,const int x規定x是不可寫的。矛盾。
可寫單元的指標(地址)能賦給指向只讀單元的指標變數: y=z;
前例的const換成volatile或者const volatile,結論一樣。
int可以賦值給const int *,const int 不能賦值給int -
除了二種例外情況,指標型別型別都要與指向(繫結)的物件嚴格匹配:二種例外是:
- 指向常量的指標(如const int *)可以指向同型別非常量
- 父類指標指向子類物件
2.4 引用
引用(reference)為變數起了一個別名,引用型別變數的宣告符用&來修飾變數名:
int i = 10;//i為一個整型變數
int &r = i; //定義一個引用變數r,引用了變數i,r是i的別名
//定義引用變數時必須馬上初始化,即馬上指明被引用的變數。
int &r2; //編譯錯誤,引用必須初始化,即指定被引用變數
C++11增加了一種新的引用:右值引用(rvalue reference),課本上叫無址引用,用&&定義. 當採用術語引用時,我們約定都是指左值引用(lvalue reference),課本上叫有址引用,用&定義。關於右值引用,會在後續介紹
2.4.1 左值和右值
C++表示式的求值結果要不是左值(lvaue),要不是右值(rvalue)。在C語言裡,左值可以出現在賦值語句的左側(當然也可以在右側),右值只能出現在賦值語句的右側。
但是在C++中,情況就不是這樣。C++中的左值與右值的區別在於是否可以定址:可以定址的物件(變數)是左值,不可以定址的物件(變數)是右值。這裡的可以定址就是指是否可以用&運算子取物件(變數)的地址。
int i = 1; //i可以取地址,是左值;1不可以取地址,是右值
//3 = 4; //錯誤:3是右值,不能出現在賦值語句左邊
const int j = 10; //j是左值, j可以取地址
const int *p = &j;
// j = 20; //錯誤:const左值(常量左值)不能出現在賦值語句左邊
非常量左值可以出現在賦值運算子的左邊,其餘的只能出現在右邊。右值出現的地方都可以用左值替代。
區分左值和右值的另一個原則就是:左值持久、右值短暫。左值具有持久的狀態(取決於物件的生命週期),而右值要麼是字面量,要麼是在表示式求值過程中建立的臨時物件。
//i++等價於用i作為實參呼叫下列函式
//第一個引數為引用x,引用實參,因此x = x + 1就是將實參+1;第二個int引數只是告訴編譯器是後置++
int operator++(int &x, int) {
int tmp= i; //先取i的值賦給temp
x = x + 1;
return tmp;
}
//因此i++ = 1不成立,因為1是要賦值給函式的返回值,而函式返回後,tmp生命週期已經結束,不能賦值給tmp
//i++等價於operator++(i, int),實參i傳遞給形參x等價於int &x = i;
2.4.2 引用的本質
引用的本質還是指標,考查以下C++程式碼及其對應的彙編程式碼
int i = 10;
int &ri = i;
ri = 20;
//從彙編程式碼可以看到,引用變數ri裡存放的就是i的地址
int i = 10;
mov dword ptr [i],0Ah //將文字常量10送入變數i
int &ri = i;
lea eax,[i] //將變數i的地址送入暫存器eax
mov dword ptr [ri],eax //將暫存器的內容(也就是變數i的地址)送入變數ri
ri = 20;
mov eax,dword ptr [ri] //將變數ri的值送入暫存器eax
mov dword ptr [eax],14h //將數值20送入以eax的內容為地址的單元中
引用變數在功能上等於一個常量指標
但是,為了消除指標操作的風險(例如指標可以++,- -),引用變數ri的地址不能由程式設計師獲取,更不允許改變ri的內容。
由於引用本質上是常量指標,因此凡是指標能使用的地方,都可以用引用來替代,而且使用引用比指標更安全。例如Java、C#裡面就取消了指標,全部用引用替代。
- 引用與指標的區別是:
- 引用在邏輯上是“幽靈”,是不分配實體記憶體的,因此無法取得引用的地址,也不能定義引用的引用,也不能定義引用型別的陣列。引用定義時必須初始化,一旦繫結到一個變數,繫結關係再也不變(常量指標一樣)。
- 指標是分配實體記憶體的,可以取指標的地址,可以定義指標的指標(多級指標),指標在定義時無需初始化(但很危險)。對於非常量指標,可以被重新賦值(指向不同的物件,改變繫結關係),可以++, --(有越界風險)
- 定義了引用後,對引用進行的所有操作實際上都是作用在與之繫結的物件之上。被引用的實體必須是分配記憶體的實體(能按位元組定址)
- 暫存器變數可被引用,因其可被編譯為分配記憶體的自動變數。
- 位段成員不能被引用,計算機沒有按位編址,而是按位元組編址。注意有址引用被編譯為指標,存放被引用實體記憶體地址。
- 引用變數不能被引用。對於int x; int &y=x; int &z=y; 並非表示z引用y, int &z=y表示z引用了y所引用的變數i。
例如
點選檢視程式碼
struct A {
int j : 4; //j為位段成員
int k;
} a;
void f() {
int i = 10;
int &ri = i; //引用定義必須初始化,繫結被引用的變數
ri = 20; //實際是對i賦值20
int *p = &ri; //實際是取i的地址,p指向i,注意這不是取引用ri的地址
//int &*p = &ri; //錯誤:不能宣告指向引用的指標
//int & &rri = ri; //錯誤:不能定義引用的引用
//int &s[4]; //錯誤:陣列元素不能為引用型別,否則陣列空間邏輯為0
register int i = 0, &j = i; //正確:i、j都編譯為(基於棧的)自動變數
int t[6], (&u)[6] = t; //正確:有址引用u可引用分配記憶體的陣列t
int &v = t[0]; //正確:有址引用變數v可引用分配記憶體的陣列元素
//int &w = a.j; //錯誤:位段不能被有址引用,按位元組編址才算有記憶體
int &x = a.k; //正確:a.k不是位段有記憶體
}
2.4.3 引用初始化
引用初始化時,除了二種例外情況,引用型別都要與繫結的物件嚴格匹配:即必須是用求值結果型別相同的左值表示式來初始化。二種例外是:
- const引用
- 父類引用繫結到子類物件
點選檢視程式碼
int j = 0;
const int c = 100;
double d = 3.14;
int &rj1 = j; //用求值結果型別相同的左值表示式來初始化
//int &rj2 = j + 10; //錯誤:j + 10是右值表示式
//int &rj3 = c; //錯誤:c是左值,但型別是const int,型別不一致
//int &rj4 = j++; //錯誤:j++是右值表示式
//int &rd = d; //錯誤:d是double型別左值,型別不一致
而const引用則是萬金油,可以用型別相同(如型別不同,看編譯器)的左值表示式和右值表示式來初始化。
int j = 0;
const int c = 100;
double d = 3.14;
const int &cr1 = j; //常量引用可以繫結非const左值
const int &cr2 = c; //常量引用可以繫結const左值
const int &cr3 = j + 10; //常量引用可以繫結右值
const int &cr4 = d; //型別不一致,報**警告**錯誤 (VS2017)
int &&rr = 1; //rr為右值引用
const int &cr5 = rr; //常量引用可以繫結同型別右值引用
2.4.3.1 為什麼非const引用不能用右值或不同型別的物件初始化?
對不可定址的右值或不同型別物件,編譯器為了實現引用,必須生成一個臨時(如常量)或不同型別的值,物件,引用實際上指向該臨時物件,但使用者不能透過引用訪問。如當我們寫
double dval = 3.14;
int &ri = dval;
編譯器將其轉換成
int temp = dval; //注意將dval轉換成int型別
int &ri = temp;
如果我們給ri賦給新值,改變的是temp而不是dval。對使用者來說,感覺賦值沒有生效(這不是好事)。
const引用不會暴露這個問題,因為它本來就是隻讀的。
乾脆禁止用右值或不同型別的變數來初始化非const引用比“允許這樣做,但實際上不會生效”的方案好得多。
2.4.3.2 &定義的有址引用(左值引用)
const和volatile有關指標的用法可推廣至&定義的(左值)引用變數
例如:“只讀單元的指標(地址)不能賦給指向可寫單元值的指標變數”推廣至引用為“只讀單元的引用不能初始化引用可寫單元的引用變數”。如前所述,反之是成立的。
int &可以賦值給const int &,const int &不能賦值給int &
-
const int &u=3; //u是隻讀單元的引用 -
int &v=u; //錯:u不能初始化引用可寫單元的引用變數v -
int x=3; int &y=x;//對:可進行y=4,則x=4。 -
const int &z=y; //對:不可進行z=4。但若y=5,則x=5, z=5。 -
volatile int &m=y;//對,m引用x。
2.4.3.3 &&定義的無址引用(右值引用)
右值引用:就是必須繫結到右值的引用。
右值引用的重要性質:只能繫結到即將銷燬的物件,包括字面量,表示式求值過程中建立的臨時物件。
返回非引用型別的函式、算術運算、布林運算、位運算、後置++,後置--都生成右值,右值引用和const左值引用可以繫結到這些運算的結果上。
c++ 11中的右值引用使用的修飾符是&&,如:
int &&aa = 1; //實質上就是將不具名(匿名)變數取了個別名
aa = 2; //可以。匿名變數1的生命週期本來應該在語句結束後馬上結束,但是由於被右值引用變數引用,其生命期將與右值引用型別變數aa的生命期一樣。這裡aa的型別是右值引用型別(int &&),但是如果從左值和右值的角度區分它,它實際上是個左值
- &&定義右值引用變數,必須引用右值。如int &&x=2;
- 注意,以上x是右值引用(引用了右值),但它本身是左值,即可進行賦值:x=3;
- 但:const int &&y=2;//不可賦值: y=3;
- 同理:“右值引用共享被引用物件的“快取”,本身不分配記憶體。”
int && *p; //錯:p不能指向沒有記憶體的無址引用
int && &q; //錯:int &&沒有記憶體,不能被q引用
int & &&r; //錯:int &沒有記憶體,不能被r引用。
int && &&s; //錯:int &&沒有記憶體,不能被s引用
int &&t[4]; //錯:陣列的元素不能為int &&:陣列記憶體空間為0。
const int a[3]={1,2,3}; int(&& t)[3]=a; //錯:a是有址的, 有名的均是有址的。&&不能引用有址的
int(&& u)[3]= {1,2,3}; //正確,{1,2,3}是無址右值
右值引用的主要作用:
-
移動語義:允許臨時物件的資源(如記憶體、檔案控制代碼等)被“移動”到另一個物件中,而不是進行複製。這可以避免不必要的資源複製,提高程式效率。
-
完美轉發:在模板程式設計中,能夠將函式的引數以左值或右值的形式完美轉發給另一個函式。
int b = 1;
//int && c = b; //編譯錯誤! 右值引用不能引用左值
A getTemp() { return A( ); }
A o = getTemp(); // o是左值 getTemp()的返回值是右值(臨時變數),被複製給o,會引起物件的複製
// getTemp()返回的右值本來在表示式語句結束後,其生命也就該終結了,而透過右值引用,該右值又重獲新生,其生命期將與右值引用型別變數refO的生命期一樣,只要refO還活著,該右值臨時變數將會一直存活下去。
A && refO = getTemp(); //getTemp()的返回值是右值(臨時變數),可以用右值引用,但不會引起物件的複製
//注意:這裡refO的型別是右值引用型別(A &&),但是如果從左值和右值的角度區分它,它實際上是個左值(其生命週期取決於refO)。因為可以對它取地址,而且它還有名字,是一個已經命名的左值。因此
A *p = &refO;
//不能將一個右值引用繫結到一個右值引用型別的變數上
//A &&refOther = refO; //編譯錯誤,refO是左值
- 若函式不返回(左值)引用型別,則該函式呼叫的返回值是無址(右值)的
int &&x=printf(“abcdefg”); //對:printf( )返回無址右值
int &&a=2; //對:引用無址右值
int &&b=a; //錯:a是有名有址的,a是左值
int&& f( ) { return 2; }
int &&c=f( ); //對:f返回的是無址引用,是無址的
- 位段成員是無址的。
struct A { int a; /*普通成員:有址*/ int b : 3; /*位段成員:無址*/ }p = { 1,2 };
int &&q=p.a; //錯:不能引用有址的變數,p.a是左值
int &&r=p.b; //對:引用無址左值
2.5 列舉、陣列
2.5.1 列舉
- 列舉一般被編譯為整型,而列舉元素有相應的整型常量值;
- 第一個列舉元素的值預設為0,後一個元素的值預設在前一個基礎上加1
enum WEEKDAY {Sun, Mon, Tue, Wed, Thu, Fri, Sat}; //Sun=0, mon=1
WEEKDAY w1=Sun, w2(Mon); //可用限定名WEEKDAY::Sun, - 也可以為列舉元素指定值,哪怕是重複的整數值。
enum E{e=1, s, w= –1, n, p}; //正確, s=2, p= 1和e相等 - 如果使用“enum class”(C++11 引入)或者“enum struct”定義列舉型別,則其元素必須使用型別名限定元素名
enum struct RND{e=2, f=0, g, h}; //正確:e=2,f=0,g=1,h= 2
RND m= RND::h; //必須用限定名RND::h
int n=sizeof(RND::h); //n=4, 列舉元素實現為整數
2.5.2 元素、下標及陣列
-
陣列元素按行儲存, 對於“int a[2][3]={{1,2,3},{4,5,6}};”,先存第1行再存第2行
a: 1, 2, 3, 4, 5, 6 //第1個元素為a[0][0], 第2個為a[0][1],第4個為a[1][0]``` -
若上述a為全域性變數,則a在資料段分配記憶體,1,2…6等初始值存放於該記憶體。
-
若上述a為靜態變數,則a的記憶體分配及初始化值存放情況同上。
-
若上述a函式內定義的區域性非靜態變數,則a的記憶體在棧段分配
-
C++陣列並不存放每維的長度資訊,因此也沒有辦法自動實現下標越界判斷。每維下標的起始值預設為0。
-
陣列名a代表陣列的首地址,其代表的型別為int [2][3]或int(*)[3]。
-
一維陣列可看作單重指標,反之也成立。例如:
int b[3]; //*(b+1)等價於訪問b[1]
int p=&b[0]; //(p+2)等價訪問p[2],也即訪問b[2] -
字串常量可看做以’\0’結束儲存的字元陣列。例如“abc”的儲存為
| ‘a’ | ‘b’ | ‘c’ | ‘\0’ | //字串長度即strlen(“abc”)=3,但需要4個位元組儲存。
char c[6]=“abc”;//sizeof(c)=6,strlen(c)=3, “abc”可看作字元陣列
char d[ ]=“abc”;//sizeof(d)=4,編譯自動計算陣列的大小, strlen(d)=3
const char*p=“abc”;//sieof(p)=4, p[0]=‘a’,“abc”看作const char指標,注意必須加const -
故可以寫:
cout << “abc”[1];//輸出b
2.6 運算子及表示式
C++運算子、優先順序、結合性見表。優先順序高的先計算,相同時按結合性規定的計算順序計算。可分如下幾類:
- 位運算:按位與&、按位或|、按位異或^、左移、右移。左移1位相當於乘於2,右移1位相當於除於2。
- 算數運算:加+、減-、乘*、除/、模%。
- 關係運算:大於、大等於、等於、小於、小等於
- 邏輯運算:邏輯與&&、邏輯或||
| 優先順序 | 運算子 | 描述 | 結合性 | 運算型別 |
|---|---|---|---|---|
| 1 | :: |
作用域解析運算子 | 無 | 其他 |
| 2 | ++ -- |
字尾自增、自減 | 從左到右 | 算數運算 |
| 2 | () |
函式呼叫 | 從左到右 | 其他 |
| 2 | [] |
下標 | 從左到右 | 其他 |
| 2 | . -> |
成員訪問 | 從左到右 | 其他 |
| 2 | typeid |
型別資訊 | 從左到右 | 其他 |
| 2 | const_cast dynamic_cast reinterpret_cast static_cast |
型別轉換 | 從右到左 | 其他 |
| 3 | ++ -- |
字首自增、自減 | 從右到左 | 算數運算 |
| 3 | + - |
正負號 | 從右到左 | 算數運算 |
| 3 | ! ~ |
邏輯非、按位取反 | 從右到左 | 邏輯運算、位運算 |
| 3 | * & |
指標解引用、取地址 | 從右到左 | 指標運算 |
| 3 | sizeof |
取大小 | 從右到左 | 其他 |
| 3 | new new[] |
動態記憶體分配 | 從右到左 | 其他 |
| 3 | delete delete[] |
動態記憶體釋放 | 從右到左 | 其他 |
| 3 | typeid |
型別資訊 | 從右到左 | 其他 |
| 3 | decltype |
推導型別 | 無 | 其他 |
| 4 | .* ->* |
成員指標運算子 | 從左到右 | 指標運算 |
| 5 | * / % |
乘法、除法、取餘 | 從左到右 | 算數運算 |
| 6 | + - |
加法、減法 | 從左到右 | 算數運算 |
| 7 | << >> |
位移 | 從左到右 | 位運算 |
| 8 | < <= > >= |
比較運算子 | 從左到右 | 關係運算 |
| 9 | == != |
等於、不等於 | 從左到右 | 關係運算 |
| 10 | & |
按位與 | 從左到右 | 位運算 |
| 11 | ^ |
按位異或 | 從左到右 | 位運算 |
| 12 | ` | ` | 按位或 | 從左到右 |
| 13 | && |
邏輯與 | 從左到右 | 邏輯運算 |
| 14 | ` | ` | 邏輯或 | |
| 15 | ?: |
條件運算子 | 從右到左 | 三元運算子 |
| 16 | = |
賦值 | 從右到左 | 賦值運算 |
| 16 | += -= *= /= %= <<= >>= &= ^= ` |
=` | 複合賦值 | 從右到左 |
| 16 | throw |
異常丟擲 | 從右到左 | 其他 |
| 17 | , |
逗號運算子 | 從左到右 | 其他 |
-
由於C++邏輯值可以自動轉換為整數0或1,因此,數學表示式的關係運算在轉換為C++表示式容易混淆整數值和邏輯值。假如x=3,則數學表示式 “1<x<2”的結果為假,但若C++計算則1<x<2⇔1<3<2⇔1<2⇔真,
-
數學表示式實際上是兩個關係運算的邏輯與,相當於C++的“1<x&&x<2”。
-
賦值表示式也是C++一種表示式。對於int x(2); x=x+3; 賦值語句中的表示式:
x+3是加法運算表示式,其計算結果為傳統右值5。
x=5是賦值運算表示式,其計算結果為傳統左值x(x的值為5) 。
由於計算結果為傳統左值x,故還可對x賦值7,相當於運算:(x=x+3)=7;結果為左值x -
選擇運算使用”?:”構成, 例如:y=(x>0)?1:0; 翻譯成等價的C++語句如下。
if(x>0) y=1;
else y=0; -
前置運算“++c”、後置運算“c ++”為自增運算;相當於c=c+1,前置運算“—c”、後置運算“c –”為自減運算,相當於c=c-1。前置運算先運算後取值,結果為傳統左值;後置運算先取值後運算,結果為傳統右值。