Arctic助力傳媒實現低成本的大資料準實時計算
網易傳媒大資料實際業務中,存在著大量的準實時計算需求場景,業務方對於資料的實效性要求一般是分鐘級;這種場景下,用傳統的離線數倉方案不能滿足使用者在實效性方面的要求,而使用全鏈路的實時計算方案又會帶來較高的資源佔用。
基於對開源資料湖方案的調研,我們注意到了網易數帆開源的基於 Apache Iceberg 構建的 Arctic 資料湖解決方案。Arctic 能相對較好地支援與服務於流批混用的場景,其開放的疊加式架構,可以幫助我們非常平滑地過渡與實現 Hive 到資料湖的升級改造,且由於傳媒離線數倉已接入有數,透過 Arctic 來改造現有業務的成本較低,於是我們準備透過引入 Arctic ,嘗試解決 push 業務場景下的痛點。
1 專案背景
以傳媒 push 實時數倉為例,新聞推送在地域、時間、頻次等因素上有較高的不確定性,非常容易出現偶發的流量洪峰,尤其是在出現突發性社會熱點新聞的時候。如果採用全鏈路的實時計算方案來處理,則需要預留出較多的資源 buffer 來應對。
由於推送時機的不確定性,push 業務的資料指標一般不是增量型的,而是以當天截止到當前的各種累計型指標為主,計算視窗通常為十五分鐘到半小時不等,統計維度區分傳送型別、內容分類、傳送票數、傳送廠商、首啟方式、使用者活躍度、AB 實驗等,具有流量波動大和資料口徑繁多等特點。

此前採用的全鏈路 Flink 實時計算方案中,主要遇到以下問題:
(1)資源佔用成本高
為應對流量洪峰,需要為實時任務分配預留出較高的資源,且多個聚合任務需要消費同一個上游資料,存在讀放大問題。push 相關的實時計算流程佔到了實時任務總量的 18+%,而資源使用量佔到了實時資源總使用量的近 25%。
(2)大狀態帶來的任務穩定性下降
push 業務場景下進行視窗計算時,大流量會帶來大狀態的問題,而大狀態的維護在造成資源開支的同時比較容易影響任務的穩定性。
(3)任務異常時難以及時的進行資料修復
實時任務出現異常時,以實時方式來回溯資料時效慢且流程複雜;而以離線流程來修正,則會帶來雙倍的人力和儲存成本。
2 專案思路和方案
2.1 專案思路
我們透過對資料湖的調研,期望利用資料實時入湖的特點,同時使用 Spark 等離線資源完成計算,用較低的成本滿足業務上對準實時計算場景的需求。我們以 push 業務場景作為試點進行方案的探索落地,再逐漸將方案推廣至更多類似業務場景。
基於對開源資料湖方案的調研,我們注意到了網易數帆開源的基於 Apache Iceberg 構建的 Arctic 資料湖解決方案。Arctic 能相對較好地支援與服務於流批混用的場景,其開放的疊加式架構,可以幫助我們非常平滑地過渡與實現 Hive 到資料湖的升級改造,且由於傳媒離線數倉已接入有數,透過 Arctic 來改造現有業務的成本較低,於是我們準備透過引入 Arctic ,嘗試解決 push 業務場景下的痛點。
Arctic 是由網易數帆開源的流式湖倉系統,在 Iceberg 和 Hive 之上新增了更多實時場景的能力。透過 Arctic,使用者可以在 Flink、Spark、Trino、Impala 等引擎上實現更加最佳化的 CDC、流式更新、OLAP 等功能。

實現 push 業務場景下的資料湖改造,只需要使用 Arctic 提供的 Flink Connector,便可快速地實現 push 明細資料的實時入湖。
此時需要我們關注的重點是,資料產出需要滿足分鐘級業務需求。資料產出延遲由兩部分組成:
資料就緒延遲,取決於 Flink 實時任務的 Commit 間隔,一般為分鐘級別;
資料計算耗時,取決於計算引擎和業務邏輯:資料產出延遲 = 資料就緒延遲 + 資料計算耗時
2.2 解決方案
2.2.1 資料實時入湖
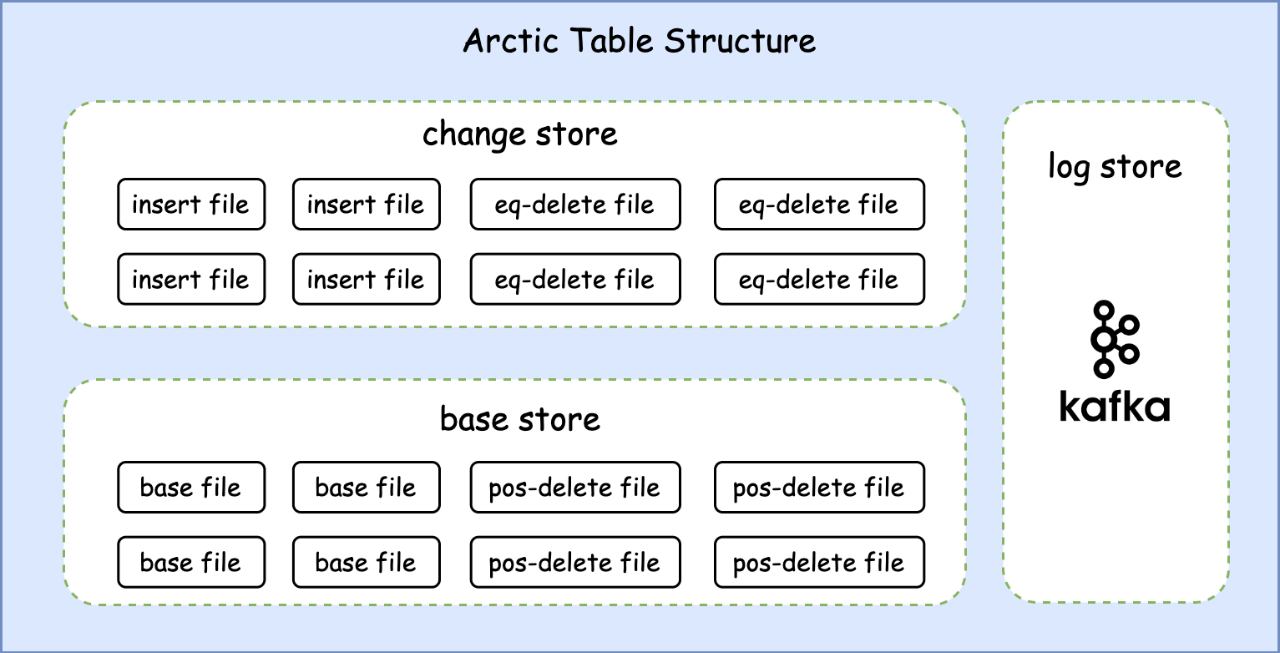
Arctic 能夠相容已有的儲存介質(如 HDFS)和表結構(如 Hive、Iceberg),並在之上提供透明的流批一體表服務。儲存結構上主要為 Basestore 和 Changestore 兩部分:
(1)Basestore 中儲存了表的存量資料。它通常由 Spark/Flink 等引擎完成第一次寫入,再之後則透過自動的結構最佳化過程將 Changestore 中的資料轉化之後寫入。
(2)Changestore 中儲存了表上最近的變更資料。Changestore 中儲存了表上最近的變更資料。它通常由 Apache Flink 任務實時寫入,並用於下游 Flink 任務進行準實時的流式消費。同時也可以對它直接進行批次計算或聯合 Basestore 裡的資料一起透過 Merge-On-Read(以下簡稱為MOR) 的查詢方式提供分鐘級延遲的批次查詢能力。
Arctic 表支援實時資料的流式寫入,資料寫入過程中為了保證資料的實效性,寫入側需要頻繁的進行資料提交,但因此會產生大量的小檔案,積壓的小檔案一方面會影響資料的查詢效能,另一方面也會對檔案系統帶來壓力。這方面,Arctic 支援基於主鍵的行級更新,提供了 Optimizer 來進行資料 Update 和自動的結構最佳化,以幫助使用者解決資料湖常見的小檔案、讀放大、寫放大等問題。
以傳媒 push 數倉場景為例,push 傳送、送達、點選、展示等明細資料需要透過 Flink 作業實時寫入到 Arctic 中。由於上游已經做了 ETL 清洗,此階段只需要透過 FlinkSQL 即可方便地將上游資料寫入 Changestore。Changestore 內包含了儲存插入資料的 insert 檔案和儲存刪除資料的 equality delete 檔案,更新資料會被拆分為更新前項和更新後項分別儲存在 delete 檔案與 insert 檔案中。
具體的,對於有主鍵場景,insert/update_after 訊息會寫入 Changestore 的 insert 檔案,delete/update_before 會寫入 Arctic 的 delete 檔案。當進行 Optimize 的時候,會先把 delete 檔案讀到記憶體中形成一個 delete map, map 的 key 是記錄的主鍵,value 是 record_lsn。然後 再讀取 Basestore 和 Changestore 中的 insert 檔案, 對主鍵相同的 row 進行 record_lsn 的對比,如果 insert 記錄中 record_lsn 比 deletemap 中相同主鍵的 record_lsn 小,則認為這條記錄已經被刪除了,不會再追加到 base 裡;否則把資料寫入到新檔案裡,最終實現了行級的更新。
2.2.2 湖水位感知
傳統的離線計算在排程方面需要有一個觸發機制,一般由作業排程系統按照任務之間的依賴關係來處理,當上遊任務全部成功後自動調起下游的任務。但在實時入湖的場景下,下游任務缺乏一個感知資料是否就緒的途徑。以 push 場景為例,需要產出的指標主要為按照指定的時間粒度來計算一次當天累計的各種統計值,此時下游如果沒法感知當前湖表水位的話,要麼需要留出一個較冗餘的緩衝時間來保證資料就緒,要麼則有漏資料的可能,畢竟 push 場景的流量變化是非常起伏不定的。
傳媒大資料團隊和 Arctic 團隊借鑑了 Flink Watermark 的處理機制和 Iceberg 社群討論的方案,將 Watermark 資訊寫入到 Iceberg 表的 metadata 檔案裡,然後由 Arctic 透過訊息佇列或者 API 暴露出來,從而做到下游任務的主動感知,儘可能地降低了啟動延遲。具體方案如下:
(1)Arctic 表水位感知
當前只考慮 Flink 寫入的場景,業務在 Flink 的 source 定義事件時間和 Watermark。ArcticSinkConnector 包含兩個運算元,一個是負責寫檔案的多併發的 ArcticWriter, 一個是負責提交檔案的的單併發的 ArcticFileCommitter。當執行 checkpoint 時,ArcticFileCommitter 運算元會進行 Watermark 對齊之後取最小的 Watermark。會新建一個類似於 Iceberg 事務的 AMS Transaction,在這個事務裡除了 AppendFiles 到 Iceberg,同時把 TransactionID,以及 Watermark 透過 AMS 的 thrift 介面上報給 AMS。

(2)Hive 表水位感知
Hive表裡可見的資料是經過 Optimize 過後的資料,Optimize 由 AMS 來排程,Flink 任務異常執行檔案的讀寫合併,並且把 Metric 上報給 AMS, 由 AMS 來把這一次 Optimize 執行的結果 Commit,AMS 天然知道這一次 Optimize 推進到了哪次 Transaction, 並且 AMS 本身也儲存了 Transaction 對應的 Watermark,也就知道 Hive 表水位推進到了哪裡。
2.2.3 資料湖查詢
Arctic 提供了 Spark/Flink/Trino/Impala 等計算引擎的 Connector 支援。透過使用Arctic資料來源,各計算引擎都可以實時讀取到已經 Commit 的檔案,Commit 的間隔按照業務的需求一般為分鐘級別。下面以 push 業務為例介紹幾種場景下的查詢方案和相應成本:
(1)Arctic + Trino/Impala 滿足秒級 OLAP 查詢
OLAP 場景下,使用者一般更關注計算上的耗時,對資料就緒的敏感度相對不高。針對中小規模資料量的 Arctic 表或較簡單的查詢,透過 Trino/Impala 進行 OLAP 查詢是一個相對高效的方案,基本上可以做到秒級 MOR 查詢耗時。成本上,需要搭建 Trino/Impala 叢集,如果團隊中已有在使用的話,則可以根據負載情況考慮複用。

Arctic 在開源釋出會上釋出了自己的 benchmark 資料,在資料庫 CDC 持續流式攝取的場景下,對比各個資料湖 Format 的 OLAP benchmark 效能, 整體上帶 Optimize 的 Arctic 的效能優於 Hudi,這主要得益於 Arctic 內部有一套高效的檔案索引 Arctic Tree,在 MOR 場景下可以做到更細粒度、精確地 merge。詳細的對比報告可以參考:。
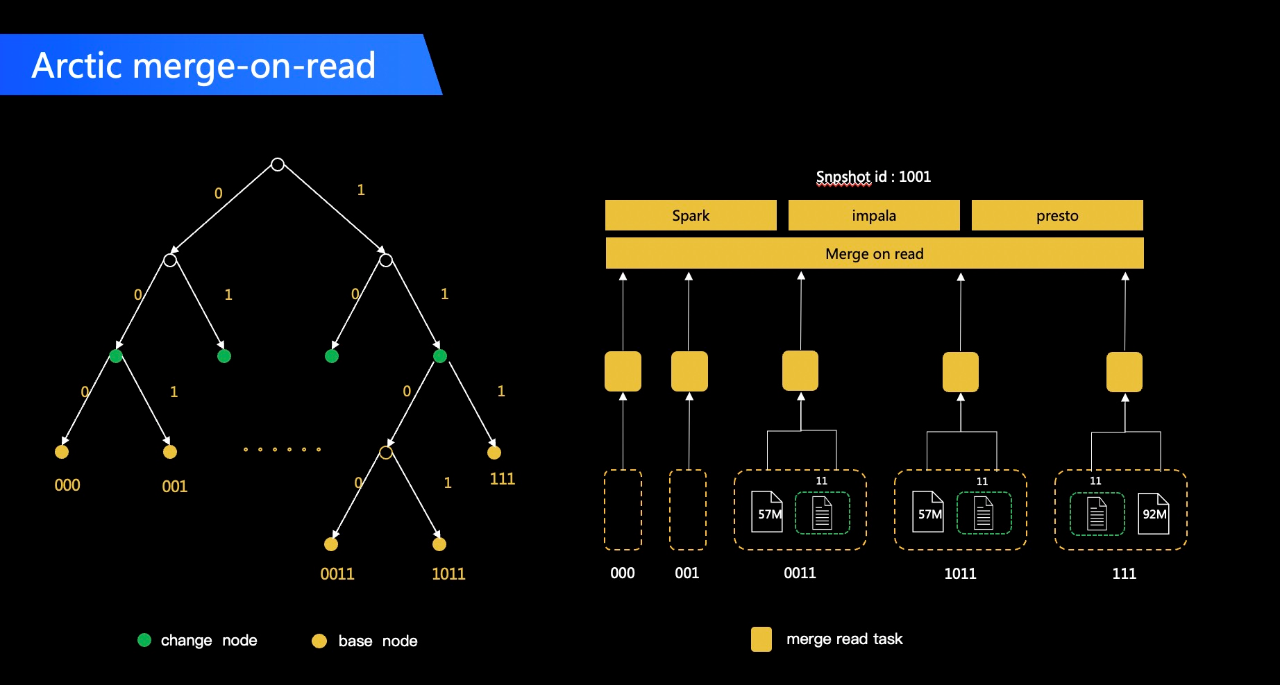
(2)Arctic + Spark 滿足分鐘級預聚合查詢
針對提供下游資料包表展示的場景,一般需要走預計算的流程將結果持久化下來,對資料就緒和計算耗時的敏感度都較高,而且查詢邏輯相對複雜,Trino/Impala 叢集規模相對較小,執行容易失敗,導致穩定性欠佳。這個場景下我們使用了叢集部署規模最大的 Spark 引擎來處理,在不引入新的資源成本的情況下,做到了離線計算資源的複用。
資料就緒方面,透過 Arctic 表水位感知方案,可以做到較低的分鐘級就緒延遲。
計算方面,Arctic 對 Spark Connector 提供了一些讀取最佳化,使用者可以透過配置 Arctic 表的 read.split.planning-parallelism 和 read.split.planning-parallelism-factor 這兩個引數值,來調整 Arctic Combine Task 的數量,進而控制計算任務的併發度。由於 Spark 離線計算的資源相對靈活和充足,我們可以透過上述調整併發度的方式來保證在 2~3 分鐘內完成業務的計算需求。

(3)Hive + Spark 滿足傳統離線數倉生產鏈路的排程
Arctic 支援將 Hive 表作為 Basestore,Full Optimize 時會將檔案寫入到 Hive 資料目錄下,以達到更新 Hive 原生讀取內容的目的,透過儲存架構上的流批一體來降低成本。因此傳統的離線數倉生產鏈路,可以直接使用對應的 Hive 表來作為離線數倉鏈路的一部分,時效性上相較於 Arctic 表雖缺少了 MOR,但透過 Hive 表水位感知方案,可以做到業務能接受的就緒延遲,從而滿足傳統離線數倉生產鏈路的排程。

3 專案影響力與產出價值
3.1 專案影響力
透過 Arctic + X 方案在傳媒的探索和落地,為傳媒準實時計算場景提供了一個新的解決思路。該思路不但減輕了全鏈路 Flink 實時計算方案所帶來的實時資源壓力和開發運維負擔,而且還能較好地複用現有的 HDFS 和 Spark 等儲存計算資源,做到了降本增效。
此外 Arctic 在音樂、有道等多個 BU 也有落地,比如在音樂公技,用於 ES 冷資料的儲存,降低了使用者 ES 的儲存成本;而有道精品課研發團隊也在積極探索和使用 Arctic 作為其部分業務場景下的解決方案。
目前 Arctic 已經在 github 上開源,受到了開源社群與外部使用者的持續關注,在 Arctic 的建設與發展中,也收到了不少外部使用者提交的高質量 PR 。
3.2 專案產出價值
透過上述方案我們將 push ETL 明細資料透過 Flink 實時入湖到 Arctic,然後在排程平臺上配置分鐘級的排程任務,按照不同交叉維度進行計算後將累計型指標後寫入關聯式資料庫,最後透過有數直連進行資料展示,做到了業務方要求的分鐘級時效資料產出。改造後的方案,同原來的全鏈路 Flink 實時計算方案相比:
(1)充分複用離線空閒算力,降低了實時計算資源開支
方案利用了空閒狀態下的離線計算資源,且基本不會帶來新的資源開支。離線計算業務場景註定了資源使用的高峰在凌晨,而新聞 push 推送及熱點新聞產生的場景大多為非凌晨時段,在滿足準實時計算時效的前提下,透過複用提升了離線計算叢集的綜合利用率。另外,該方案能幫我們釋放大約 2.4T 左右的實時計算記憶體資源。
(2)降低任務維護成本,提升任務穩定性
Arctic + Spark 水位感知觸發排程的方案可減少 17+ 實時任務的維護成本,減少了 Flink 實時計算任務大狀態所帶來的穩定性問題。透過 Spark 離線排程任務可充分利用離線資源池調整計算並行度,有效提升了應對突發熱點新聞流量洪峰時的健壯性。
(3)提升資料異常時的修復能力,降低資料修復時間開支
透過流批一體的 Arctic 資料湖儲存架構,當資料出現異常需要修正時,可靈活地對異常資料進行修復,降低修正成本;而如果透過實時計算鏈路回溯資料或透過額外的離線流程來修正,則需要重新進行狀態累計或複雜的 ETL 流程。
4 專案未來規劃和展望
當前還有一些場景 Arctic 不能做到較好的支援,傳媒大資料團隊將和 Arctic 團隊繼續對以下場景下的解決方案進行探索和落地:
(1)當前入湖前的 push 明細資料是透過上游多條資料流 join 生成的,也同樣會存在大狀態的問題。而 Arctic 當前只能支援行級的更新能力,如果能落地有主鍵表的部分列更新能力,則可以幫助業務在入湖的時候,以較低的成本直接實現多流 join。
(2)進一步完善 Arctic 表和 Hive 表的水位定義和感知方案,提升時效,並推廣到更多的業務場景中。當前的方案只支援單 Spark/Flink 任務寫入的場景,對於多個任務併發寫表的場景,還需要再完善。
來自 “ 網易有數 ”, 原文作者:魯成祥 馬一帆;原文連結:http://server.it168.com/a2022/1108/6773/000006773324.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 網易數帆實時資料湖 Arctic 的探索和實踐
- 大資料開發實戰:實時資料平臺和流計算大資料
- 大資料“重磅炸彈”:實時計算框架 Flink大資料框架
- 伍翀 :大資料實時計算Flink SQL解密大資料SQL解密
- 一文讀懂大資料實時計算大資料
- 實時計算無線資料分析
- 跳過大資料精準實時推薦大資料
- 實時計算助力1688打造「實時挑貨」系統
- 如何實現上億級資料的精準計數?
- 實現報表資料預先計算
- 百城匯杭州站大資料實時計算實戰專場圓滿落幕大資料
- 阿里雲實時大資料解決方案,助力企業實時分析與決策阿里大資料
- 大文字平行計算實現方式
- 大資料之亞秒級實時計算技術學哪些內容?大資料
- 快速部署DBus體驗實時資料流計算
- 基於 Flink 流計算實現的股票交易實時資產應用
- 資料重整:用Java實現精準Excel資料排序的實用策略JavaExcel排序
- 實時計算如何幫助淘寶實現線上「實時選品」?
- 實現MySQL資料庫的實時備份MySql資料庫
- 七牛大資料平臺的實時資料分析實戰大資料
- ACCESS 在資料表中實現簡單計算
- NVIDIA推出液冷GPU 助力實現可持續高效計算GPU
- Flink 在有贊實時計算的實踐
- Hadoop大資料實戰系列文章之Mapreduce 計算框架Hadoop大資料框架
- (github原始碼) 如何利用.NETCore向Azure EventHubs準實時批量傳送資料?Github原始碼NetCore
- 報表實施案例:某市利用大資料助力精準扶貧專案開展大資料
- PLC實時資料採集如何實現?
- 信用算力實現金融級資料服務的實踐
- 分散式時序資料庫QTSDB的設計與實現分散式資料庫QT
- 實時計算神器:binlog
- 實時計算小括
- 大資料3.2 -- 實時筆記大資料筆記
- 全球疫情實時監控——約翰斯·霍普金斯大學資料大屏實現方案
- 雲端計算暴露資料處理缺乏和安全實踐標準缺陷
- 【最佳實踐】微信小程式客服訊息實時通知如何快速低成本實現?微信小程式
- 超3萬億資料實時分析,JCHDB助力海量資料處理
- 亞信安慧AntDB 資料庫:超融合資料庫引領實時計算新時代資料庫
- 大資料計算生態之資料計算(二)大資料