深度學習在攜程搜尋詞義解析中的應用
一、背景介紹
搜尋是電商最重要的門面之一,大部分使用者透過搜尋來找到他們想要的商品,因此搜尋是使用者表達意圖最直接的方式,也是轉化率較高的流量來源之一。絕大部分的電商搜尋是透過搜尋框輸入搜尋詞(Query)來完成,因此,搜尋詞的詞義解析和意圖理解成為了搜尋中的重要一環。
主流的搜尋詞義解析和Query理解需要經過糾錯、同義詞替換、分詞、詞性標註、實體識別、意圖識別、詞重要度權重、丟詞等步驟。以旅遊場景下的搜尋舉例,如圖1所示,當使用者在搜尋框輸入“雲南香各里拉”作為Query的時候,首先搜尋引擎需要對該搜尋詞進行糾錯,這是為了便於後續步驟正確解析出使用者想要搜尋的內容;如果有必要,還會進行同義詞替換。然後,對搜尋詞進行分詞和詞性標註,識別出“雲南”是省,“香格里拉”是城市或者酒店品牌,緊接著會做實體識別,召回“雲南”和“香格里拉”在後臺資料庫裡對應的實體id。
這個時候,出現了一個分歧,“香格里拉”既可能是城市,又可能是酒店品牌。在使用者進行搜尋的時候,是否能夠預測出正確的類別和實體,對於搜尋結果的精準展示和提升使用者體驗有重要的意義。因此,我們必須識別出使用者真正想要搜的是什麼類別,並找到對應的實體,否則可能在搜尋列表頁前排會給出使用者不想要的結果。從人的先驗知識來看,使用者搜尋“雲南香格里拉”,很大可能性是想要搜城市。意圖識別步驟,就是為了實現這個功能,識別出使用者真正的搜尋意圖是代表城市的“香格里拉”。
後續就可以進入搜尋的召回步驟,召回主要負責的是把和搜尋詞意圖相關的商品或內容找出來。前面的步驟獲取了“雲南”和“香格里拉”的id,就可以很方便的召回和“雲南”和“香格里拉”都相關的商品或內容。但是,有些時候,召回的結果為空或者過於稀少,這個時候給使用者的體驗不好,因此,在召回的結果為空或者過於稀少的情況下,往往還需要丟詞和二次召回的操作。此外,有些詞屬於可省略詞,或者對搜尋產生干擾的詞,也可以透過丟詞來處理。
所謂丟詞,就是把搜尋詞中相對不重要或者聯絡不緊密的詞丟掉,再次召回。那麼該如何衡量每個詞的重要程度或者緊密程度?這裡就需要引入了Term Weighting的模組,把每個詞視為term,透過演算法或規則計算每個term的weight,每個term的weight直接決定了term重要度和緊密度的順序。例如,假設“雲南”的term weight是0.2,“香格里拉”的term weight是0.8,那麼如果需要丟詞,就應該先丟“雲南”,保留“香格里拉”。

圖1 搜尋詞義解析和Query理解步驟
傳統的搜尋意圖識別會採用詞表匹配,類目機率統計,加上人為設定規則。傳統的Term Weighting同樣會採用詞表匹配和統計方法,比如根據全量商品的標題和內容統計出詞的TF-IDF、前後詞互資訊、左右鄰熵等資料,直接存成詞典和分值,提供給線上使用,再根據一些規則輔助判斷,比如行業專有名詞直接給出較高的term weight,助詞直接給出較低的term weight。
但是,傳統的搜尋意圖識別和Term Weighting演算法無法達到很高的準確率和召回率,特別是無法處理一些較為罕見的搜尋詞,因此需要一些新的技術來提升這兩個模組的準確率和召回率,以及提升對罕見搜尋詞的適應能力。此外,因為訪問頻率較高,搜尋詞義解析需要非常快的響應速度,在旅遊搜尋場景下,響應速度往往需要達到接近個位數的毫秒級,這對於演算法來說是一個很大的挑戰。
二、問題分析
為了提高準確率和召回率,我們採用深度學習來改進搜尋意圖識別和Term Weighting演算法。深度學習透過樣本的學習,可以有效解決各種情況下的意圖識別和Term Weighting。此外,針對自然語言處理的大規模預訓練語言模型的引入,可以進一步強化深度學習模型的能力,減少樣本的標註量,使得原本標註成本較高的深度學習在搜尋上應用成為可能。
但是深度學習面臨的問題是,由於模型的複雜度較高,神經網路層數較深,響應速度沒法滿足搜尋的高要求。因此我們採用模型蒸餾和模型壓縮來減少模型的複雜度,在略微降低準確率和召回率的情況下減少深度學習模型的耗時,以此保證較快的響應速度和較高的效能。
三、意圖識別
類目識別是意圖識別的主要組成部分。意圖識別中的類目識別是搜尋詞query經過分詞後,對分詞結果打上所屬類目並給出對應機率值的方法。解析使用者的搜尋詞的意圖有利於分析使用者的直接搜尋需求,從而輔助提升使用者體驗。例如使用者在旅遊頁面搜尋 “雲南香格里拉”,獲取到使用者輸入的“香格里拉”對應的類目是“城市”,而不是“酒店品牌”,引導後續檢索策略偏向城市意圖。
在旅遊場景下,使用者輸入的類目存在歧義的搜尋詞佔總量約11%,其中包含大量無分詞的搜尋詞。“無分詞”是指經過分詞處理後無更細化的切分片段,“類目存在歧義”是指搜尋詞本身存在多種可能的類目。例如使用者輸入“香格里拉”,無更細化的切分片段,且對應類目資料中存在“城市”、“酒店品牌”等多個類目。
如果搜尋詞本身是多個詞的組合,則可以透過搜尋詞自身上下文明確類目,優先會以搜尋詞本身作為識別目標。如果單從搜尋詞本身不能明確所屬類目,我們會優先追加該使用者不相同的最近歷史搜尋詞,以及最近商品類目點選記錄,若無上述資訊則追加定位站,作為補充語料。原始搜尋詞經過處理獲得待識別的Query R。
最近幾年,預訓練語言模型在很多自然語言處理任務中大放光彩。在類目識別中,我們利用預訓練模型的訓練網路引數,獲取含上下文語義的字特徵Outputbert;使用字詞轉換模組,字特徵結合位置編碼:
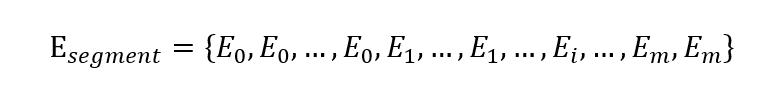
獲取到分詞對應的字元片段,如:
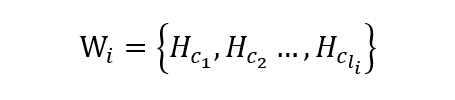
代表第i個分詞對應的長度為li的字特徵。基於字元片段Wi,字詞轉換模組聚合出每個詞的特徵Hwi。聚合手段可以是最大值池化max-pooling、最小值池化min-pooling、均值池化mean-pooling等方式,實驗得到最大池化效果優秀。模組輸出為搜尋詞R的詞特徵OutputR;透過並行分類器對搜尋詞的詞特徵OutputR中各個片段給出類目資料庫中涵蓋的匹配類目,並給出對應類目的匹配機率。
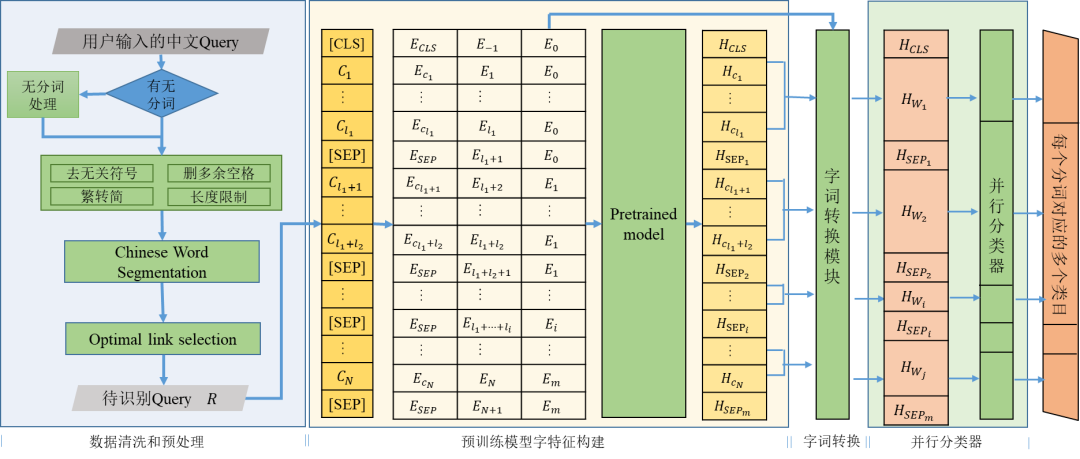
圖2 類目識別整體結構示意圖
類目識別模型是基於BERT-base 12層模型,由於模型過大,不滿足線上執行的響應速度要求,我們對模型進行了知識蒸餾(Knowledge Distillation),將網路從大網路轉化成一個小網路,保留接近於大網路的效能的同時滿足線上執行的延遲要求。
原先訓練好的類目識別模型作為teacher網路,將teacher網路的輸出結果 作為student網路的目標,訓練student網路,使得student網路的結果p接近q ,因此,我們可以將損失函式寫成:
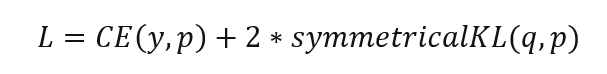
這裡CE是交叉熵(Cross Entropy),symmetricalKL是對稱KL散度(Kullback–Leibler divergence),y是真實標籤的one-hot編碼,q是teacher網路的輸出結果,p是student網路的輸出結果。
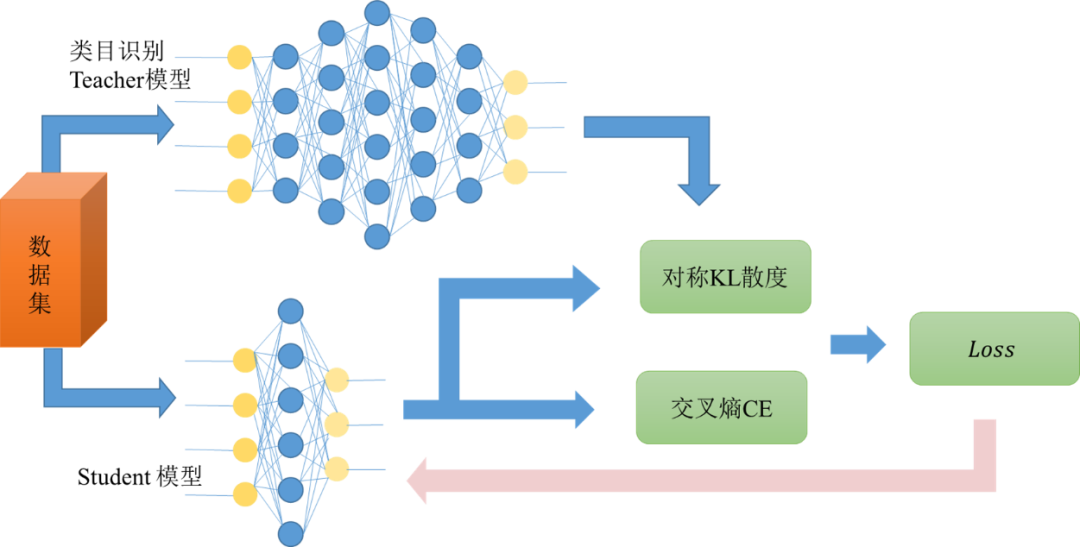
圖3 知識蒸餾示意圖
經過知識蒸餾,類目識別最終仍然可以達到較高的準確率和召回率,同時可以做到整體響應時間的95線為5ms左右。
經過類目識別之後,還需要經過實體連結等步驟,完成最終的意圖識別過程。具體內容可以參見《攜程實體連結技術的探索及實踐》一文,本文不再闡述。
四、Term Weighting
對於使用者輸入的搜尋詞,不同的term對於使用者的核心語義訴求有著不同的重要性。在搜尋的二次召回排序中需要重點關注重要性高的term,同時在丟詞的時候可以忽略重要性低的term。透過計算使用者輸入搜尋詞的各個term weight,來二次召回出最接近使用者意圖的產品,提升使用者體驗。
首先,我們需要尋找線上使用者真實的反饋資料作為標註資料。使用者在搜尋框的輸入和聯想詞點選情況一定程度上反映了使用者對於搜尋短語中詞語的重視程度,因此我們選用聯想詞輸入和點選資料,加以人工篩選和二次標註,作為Term Weighting模型的標註資料。
在資料預處理方面,我們所能獲得的標註資料為短語及其對應的關鍵詞,這裡為了使權重的分配不過於極端,給定非關鍵詞一定量小的權重,並將剩餘權重分配給關鍵詞的每個字上,如果某一短語在資料中出現了複數次,且對應的關鍵詞不同,則會根據關鍵詞的頻率對這些關鍵詞的權重進行分配,並進一步分配每個字的權重。
模型部分主要嘗試BERT作為特徵提取的方法,並進一步對每個term的權重進行擬合。對於給定的輸入,將其轉化為BERT所能接收的形式,將透過BERT後的張量再透過全連線層進行壓縮,得到一維的向量後進行Softmax處理,並用該向量對結果的權重向量進行擬合,具體模型框架如下圖所示:
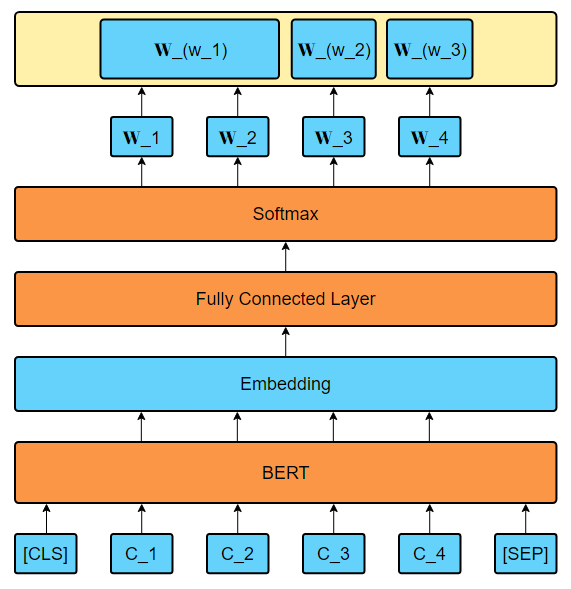
圖4 Term Weighting模型框架
由於中文BERT基於字元,因此需要將每個term中的所有字的權重進行求和,從而最終得到term的權重。
在整個模型框架中,除去一些訓練的超引數,能調整的部分主要包含兩個部分:一是透過BERT產生Embedding時,可以選擇BERT最後一層,或者綜合BERT的第一層和最後一層的方式產生Embedding;二是在損失函式的選擇上,除去使用MSE損失衡量預測權重與實際權重之間差距之外,也嘗試使用非重要詞的預測權重的和作為損失進行計算,但這種損失更適合只有單個關鍵詞的情況使用。
模型最終是以小數的形式輸出每個term weight,例如[“上海”、“的”、“迪士尼”]的term weight結果為[0.3433,0.1218,0.5349]。
該模型是為搜尋服務的,有嚴格的響應速度要求。由於BERT模型整體比較大,在推理部分很難達到響應速度要求,因此類似於類目識別模型,我們對訓練好的BERT模型進行進一步的蒸餾處理,以達到符合線上的要求。在此專案中,透過少數幾層transformer去擬合BERT-base 12層transformer的效果,最後以損失可以接受的一部分效能的情況下,使得模型整體的推理速度快了10倍左右。最終,Term Weighting線上服務整體的95線可以達到2ms左右。
五、未來與展望
採用深度學習後,旅遊搜尋對於較為罕見的長尾搜尋詞,詞義解析能力有了較大的提升。在目前的線上真實搜尋場景,深度學習方法一般選擇與傳統的搜尋詞義解析方法相結合,這樣既可以保證頭部常見搜尋詞的效能穩定,又可以加強泛化能力。
未來,搜尋詞義解析致力於給使用者帶來更好的搜尋體驗,隨著硬體技術和AI技術的更新換代,高效能運算和智慧計算越來越成熟,搜尋詞義解析的意圖識別和Term Weighting未來會往更高效能的目標發展。此外,更大規模的預訓練模型和旅遊領域的預訓練模型有助於進一步提升模型的準確率和召回率,更多使用者資訊和知識的引入有助於提升意圖識別的效果,線上使用者的反饋和模型迭代有助於提升Term Weighting的效果。這些都是我們後續會嘗試的方向。
除了意圖識別和Term Weighting之外,搜尋的其他功能,比如詞性標註、糾錯等,在滿足響應速度要求的前提下未來也可以採用深度學習技術,來實現更強大的功能和更優秀的效果。
來自 “ 攜程技術 ”, 原文作者:大資料AI研發團隊;原文連結:http://server.it168.com/a2022/1111/6774/000006774280.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 深度學習在視覺搜尋和匹配中的應用深度學習視覺
- Searching with Deep Learning 深度學習的搜尋應用深度學習
- 深度學習在美團搜尋廣告排序的應用實踐深度學習排序
- 深度學習在搜尋業務中的探索與實踐深度學習
- 深度學習在OC中的應用深度學習
- AI在汽車中的應用:實用深度學習AI深度學習
- 【AI in 美團】深度學習在OCR中的應用AI深度學習
- 雲搜尋服務在APP搜尋場景的應用APP
- 【深度學習】深度解讀:深度學習在IoT大資料和流分析中的應用深度學習大資料
- 微信高階研究員解析深度學習在NLP中的發展和應用深度學習
- 深度學習在股票市場的應用深度學習
- 【Elasticsearch學習】文件搜尋全過程Elasticsearch
- 語義解析在“UI 2 CODE”中的應用UI
- 語義解析在「UI 2 CODE」中的應用UI
- 自動網路搜尋(NAS)在語義分割上的應用(二)
- 深度學習模型在序列標註任務中的應用深度學習模型
- 如何理解雅克比矩陣在深度學習中的應用?矩陣深度學習
- 深度學習助力引力波訊號搜尋深度學習
- 卷積操作的概念及其在深度學習中的應用卷積深度學習
- BM42:語義搜尋與關鍵詞搜尋結合
- 深度學習的未來:神經架構搜尋深度學習架構
- 大資料HBase在阿里搜尋中的應用實踐大資料阿里
- 【Leetcode 346/700】79. 單詞搜尋 【中等】【回溯深度搜尋JavaScript版】LeetCodeJavaScript
- 深度學習在醫療領域的應用深度學習
- 深度學習在乳腺癌上的應用!深度學習
- 深度學習在推薦系統中的應用綜述(最全)深度學習
- 深度學習技術在網路入侵檢測中的應用深度學習
- 深度學習在攝影技術中的應用與發展深度學習
- 【長篇乾貨】深度學習在文字分類中的應用深度學習文字分類
- ScaleFlux CSD 2000 在攜程的應用實踐UX
- 單詞搜尋
- RecSys提前看 | 深度學習在推薦系統中的最新應用深度學習
- 深度強化學習在時序資料壓縮中的應用強化學習
- 深度學習及深度強化學習應用深度學習強化學習
- Elasticsearch:使用同義詞 synonyms 來提高搜尋效率Elasticsearch
- 【AI in 美團】深度學習在文字領域的應用AI深度學習
- 深度學習在計算機視覺各項任務中的應用深度學習計算機視覺
- 搜尋引擎es-分詞與搜尋分詞