平穩時間序列的意義
根據數理統計學常識,要分析的隨機變數獲得的樣本資訊越多,分析的結果就會越可靠,但由於時間序列分析的特殊資料結構,對隨機序列{...,X1,X2...,Xt,...}而言,它在任意時刻 t 的序列值 Xt 都是一個隨機變數,而且由於時間的不可重複性,該變數在任意一個時刻都只能獲得唯一的樣本觀察值,通常是沒有辦法分析的。在平穩序列場合裡,序列的均值等於常數,意味著原本含有可列多個隨機變數的均值序列變成了一個常數序列,原本每個隨機變數的均值只能依靠唯一的一個樣本觀察值去估計,現在每一個樣本觀察值都變成了常數均值的樣本觀察值,這極大的減少了隨機變數的個數,並增加了待估引數的樣本容量。
平穩性校驗
- 一種是根據時序圖和自相關圖顯示的特徵做出判斷的圖檢驗方法(自相關圖是一個平面二維座標懸垂線圖,一個座標軸便是延遲時期數,另一個座標軸表示自相關係數,通常以懸垂線表示自相關係數的大小。自相關圖進行平穩性判斷的標準:隨著延遲期數 k 的增加,平穩序列的自相關係數會很快的衰減向零;反之,非平穩序列的自相關係數衰減向零的速度通常比較慢)
import numpy as np
import pandas as pd
from datetime import datetime
import matplotlib.pylab as plt
from statsmodels.graphics.tsaplots import plot_acf, plot_pacf
#讀取原始時間序列資料
df=pd.read_csv('wq.csv',encoding='utf-8', index_col='datatime') #從csv檔案中讀取時間序列資料,index_col列定義為索引物件
df.index=pd.to_datetime(df.index)
ts=df['dataColumn'] #指定時間序列中對應的資料列
ts.head()
ts.head().index
#輸出原始序列
f = plt.figure(facecolor='white')
ts.plot(color='blue', label='Original')
plt.title('TimeSeries Original Data')
plt.show()
#輸出ACF(自相關圖)、PACF(偏自相關圖)
f = plt.figure(facecolor='white')
ax1 = f.add_subplot(211)
plot_acf(ts, lags=31, ax=ax1)
ax2 = f.add_subplot(212)
plot_pacf(ts, lags=31, ax=ax2)
plt.show()
- 另一種是構造檢驗統計量進行假設檢驗的方法(目前最常用的平穩性統計校驗方法是單位根檢驗,DF檢驗和ADF檢驗)
from statsmodels.tsa.stattools import adfuller
#adf校驗
ts=ts[~ts.isin(['null'])] #去除時間序列中值為空的行
ts=ts.dropna() #去除掉所有NaN值
dftest = adfuller(ts) #ADF校驗
# 對上述函式求得的值進行語義描述
dfoutput = pd.Series(dftest[0:4], index=['Test Statistic','p-value','#Lags Used','Number of Observations Used'])
for key,value in dftest[4].items():
dfoutput['Critical Value (%s)'%key] = value
print(dfoutput) #輸出df校驗結果
白噪聲檢驗
通過平穩性校驗,序列可以分為平穩序列和非平穩序列
- 對於非平穩序列,通常要進行進一步的校驗、變換或處理後,才能確定合適的擬合模型;
- 對於平穩序列,只有那些序列值之間具有密切的相關關係,歷史資料對未來發展有一定影響的序列,才值得建模。(如果序列彼此之間沒有任何相關性,那就意味著該序列是一個沒有記憶的序列,過去的序列對未來的發展沒有任何影響,是一種沒有任何分析價值的而序列,稱之為純隨機序列,白噪聲序列就是一種純隨機序列)
使用Q統計量和LB統計量來校驗白噪聲序列
- Q統計量:Q統計量近似服從自由度為m的卡方分佈,當Q統計量大於卡方分位點或者統計量的P值小於α時,則可以以1-α的置信水平拒絕原假設,認為該序列為非白噪聲序列,否則,不能拒絕原假設,認為該序列為純隨機序列。在大樣本場合,檢驗效果很好,但在小樣本場合不太精確
- LB統計量:是對Q統計量的修正,同樣近似服從自由度為m的卡方分佈,在各種檢驗場合,普遍採用的Q統計量通常指的都是LB統計量
資料預處理
對數變換主要是為了減小變化較大的時序資料的振動幅度,使其線性規律更加明顯
#對數變換
ts_log = np.log(ts)
#對數變換後的序列輸出
f = plt.figure(facecolor='white')
ts_log.plot(color='blue', label='log Data')
plt.title('TimeSeries log Data')
plt.show()
平滑法:根據平滑技術的不同,平滑法分為移動平均法和指數平均法,移動平均即利用一定時間間隔內的平均值作為某一期的估計值,而指數平均則是用變權的方法來計算均值,認為離著預測點越近的點,作用越大。
# 對size個資料進行移動平均 rol_mean = timeSeries.rolling(window=size).mean() # 對size個資料進行加權移動平均 rol_weighted_mean = pd.ewma(timeSeries, span=size) rol_mean.dropna(inplace=True) rol_weighted_mean.dropna(inplace=True)
差分運算,(預測方法中並沒有解決高於2階的差分)經過差分運算後的序列,呈現典型的隨機波動特徵。差分方法的優點是對確定性資訊的提取比較充分,缺點是很難對模型進行直觀解釋(當序列具有非常顯著的確定性趨勢或者季節效應時,為了通過確定性因素分解方法提取序列中各種確定性效應的解釋,構造了殘差自迴歸模型)
- 序列蘊涵顯著的線性趨勢,1階差分就可以實現趨勢平穩
- 序列蘊涵曲線趨勢,通常低階(2階或者3階)差分就可以提取出曲線趨勢的影響
- 蘊涵固定個週期的序列,進行步長為固定週期長度的差分運算,可以較好的提取週期資訊
#差分計算 ts_diff1=ts.diff(1) ts_diff2=ts.diff(2) #輸出時間序列 f = plt.figure(facecolor='white') ts.plot(color='green', label='原始資料') ts_diff1.plot(color='blue', label='1階差分') ts_diff2.plot(color='red', label='2階差分') plt.show()
拆分:使用確定性因素分解方法。所有的序列波動都可以歸納為受長期趨勢、迴圈趨勢、季節性變化、隨機波動4大類因素的綜合影響,也就是說任何一個時間序列都可以用這4個因素的某個函式進行擬合,最常用的函式是加法函式和乘法函式
from statsmodels.tsa.seasonal import seasonal_decompose decomposition = seasonal_decompose(ts, model="additive",period=6) trend = decomposition.trend #趨勢序列 seasonal = decomposition.seasonal #季節序列 residual = decomposition.resid #隨機序列
- 簡單中心移動平均能有效消除季節效應,有效提取低階趨勢,能實現擬合方差最小
- 簡單移動平均比值能有效提取季節效應
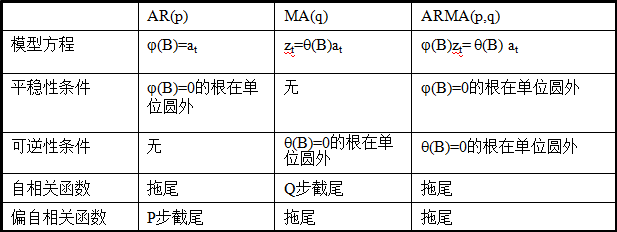
模型選擇
常見模型包括AR(自迴歸模型)、MA(移動平均模型)、ARMA(自迴歸移動平均模型)。通過對平穩時間序列的自相關係數(ACF)和偏自相關係數(PACF)的計算,繪製自相關圖和偏自相關圖,通過拖尾、截尾性質,確定合適的模型以及各自階數。
引數估計
- 矩估計
- 極大似然估計(必須已知總體的分佈函式,在時間序列分析中,序列總體的分佈通常是未知的,為便於分析和計算,通常假設序列服從多元正態分佈)
- 最小二乘估計(在實際中,最常用的是條件最小二乘估計方法)
模型檢驗
模型檢驗包括模型的顯著性校驗和引數的顯著性校驗
- 模型的檢驗即為殘差序列中的白噪聲檢驗,如果殘差序列是白噪聲序列,則擬合殘差項中將不蘊涵任何相關資訊,即模型提取的資訊足夠充分,模型的顯著性高;反之,說明模型擬合不夠有效,需要選擇其他模型,重新擬合
- 引數的顯著性校驗就是要檢驗每一個未知引數是否顯著非零。檢驗的目的是使模型最精簡
模型優化
綜合考慮模型的擬合精度和未知引數個數的綜合最優配置。若一個擬合模型通過了校驗,說明在一定的置信水平下,該模型能有效擬合觀察值序列的波動,但這種有效模型不一定是唯一的。在所有通過校驗的模型中使用AIC或者SBC函式達到最小的函式為相對最優模型。
參考資料:中國人民大學出版社《應用時間序列分析》第四版 王燕編著