定義和一些記號
定義
自動機由 \(5\) 個模組組成:
- \(\Sigma\) :字符集
- \(state\) : 狀態集合
- \(init\) : 初始狀態(只有一個)
- \(end\) : 終止狀態集合
- \(Trans(s,c)\) : 轉移函式,狀態 \(s\) 在接受字元 \(c\) 之後,返回下一個狀態
一個字串 \(S\) 的字尾自動機(\(SAM\),Suffix Automaton)是其最小的確定有限狀態自動機(\(DFA\) ,Deterministic Finite Automaton),僅接受\(S\) 的所有字尾,即只在輸入字尾後,自動機會達到終止狀態。
記號
\(null\) : 不存在狀態,若 \(s\) 無法接受字元 \(c\),則 \(Trans(s,c)=null\)。同時定義 \(Trans(null,*)=null\)
\(ST(str)\) : \(Trans(init,str)\),即從初始狀態開始輸入 \(str\) 之後得到的狀態。
\(str[l,r]\) : 字串 \(str\) 中下標 \(\in[l,r]\) 的子串
\(Fac\) : 子串集合
\(Right(s)\) : 狀態 \(s\) 在字串中出現的所有位置的集合,即 \(Right(s)=\{r\;|ST(str[l,r])=s\}\)
\(Reg(A)\) : 自動機 \(A\) 能夠識別的字串的集合
\(Reg(s)\) : 從狀態 \(s\) 開始能夠識別的字串的集合,即 \(Reg(s)=\{str\;|Trans(s,str)\in end\}\)
前置性質
如果用樸素的想法去實現 \(SAM\) 的功能,其實只需將字串 \(str\) 的所有字尾拿出來建一棵 \(Trie\) 即可,不過這樣的狀態數是 \(O(n^2)\) 級別的,我們需要將自動機的狀態數簡化。觀察兩個串 \(a\) 和 \(b\),如果 \(Reg(a)=Reg(b)\),可以發現兩者在自動機上被處理的方式完全相同,從而我們將這些串合併起來,儲存在同一個狀態 \(s\) 中。
在進一步討論之前,我們先分析一些性質。
- 達到狀態 \(s\) 的字串其長度構成一段區間,我們設其為 \([Min(s),Max(s)]\)
這些字串達到狀態 \(s\),說明它們在原串中的出現次數等於 \(|Right(s)|\),而這些串之間為字尾關係,一個串在原串中的出現次數隨著其長度增加而減小,且其母串的出現位置為自己的子集,所以出現次數為 \(|Right(s)|\) 這一值的串長構成一段區間。
- 對於兩個狀態 \(a\) 和 \(b\),要麼 \(Right(a)\bigcap Right(b)=\phi\),要麼 \(Right(a)\subset Right(b)\) 或者 \(Right(a)\supset Right(b)\) 。
考慮 \(Right(a)\bigcap Right(b)\neq \phi\) 的情況,設 \(r\in Right(a)\bigcap Right(b)\),對於這個位置,兩者的 \(len\) 區間不能有交,否則就存在一個字串同時能夠到達兩個狀態了,由於 \(SAM\) 是 \(DFA\),這種情況不被允許。那麼我們設 \(Max(a) < Min(b)\),則 \(a\) 中所包含的字串均為 \(b\) 中字串的字尾,\(b\) 中字串是由 \(a\) 中延伸出來的,從而有 \(Right(a)\supset Right(b)\) 。
有了性質 \(2\),我們可以用樹的方式將狀態之間聯絡起來,引入父親的概念:
\(par(s)\) : 最小的滿足 \(Right(s)\) 為其 \(Right\) 子集的狀態
我們將建出的這棵樹稱為 \(Parent\;\;Tree\),再分析 \(Parent\;\;Tree\) 的性質:
- 每一個非葉子節點都有至少 \(2\) 個兒子。
由於父親兒子之間的 \(Right\) 是真子集關係,而每一個位置都要被一個狀態認領,性質成立。
- \(Parent\;\;Tree\) 至多有 \(n\) 個葉子節點,總共至多有 \(2n-1\) 個節點。
葉子節點就是字串匹配到最後的情況,僅剩下一個可能位置,顯然至多有 \(n\) 種這樣的情況,比如 \(str=aaaaa\) 的時候,葉子節點就只有 \(1\) 個。由於至少是二叉樹,顯然至多有 \(2n+1\) 個節點。
由於 \(Parent\;\;Tree\) 是由所有狀態構成的,性質 \(4\) 說明了 \(SAM\) 的狀態數至多有 \(2n-1\) 種。
我們再來證明 \(SAM\) 狀態之間的轉移數量是 \(O(n)\) 的。
- \(SAM\) 的狀態轉移數量 \(\leq 3n-4\)
我們取出 \(SAM\) 狀態轉移關係構成的圖的最長路徑生成樹。
對於樹邊,根據前面的結論其數量 \(\leq 2n-2\)
對於非樹邊,考慮一條非樹邊 \(a\rightarrow b\),我們先從 \(init\) 沿著樹邊走到 \(a\),然後經過 \(a\rightarrow b\) 走到 \(b\),令這條非樹邊對應所有 \(b\) 最終可以到達的字尾,顯然至少有一個。對於每一個字尾,如果它匹配的過程中經過了非樹邊,則讓其對應經過的第一條非樹邊,從而每個字尾最多對應一條非樹邊。所以非樹邊的數量 \(\leq\) 字尾的數量,由於這裡是最長路徑生成樹,\(str\) 本身不經過非樹邊,所以非樹邊數量 \(\leq n-1\)
但是兩種情況無法同時取等,可以說明總共的轉移數量 \(\leq 3n-4\)
在愉快地構建 \(SAM\) 之前,再觀察一些性質,記 \(t=Trans(s,c), \;fa=par(s)\) 。
- \(Right(t)=\{r+1\;|r\in Right(s),s[r+1]=c\}\),\(SAM\) 是一個 \(DAG\) 。
前者根據定義顯然,由於 \(r\) 一直在增加,不會出現環的情況,所以 \(SAM\) 是一個 \(DAG\) 。
- \(Max(t)>Max(s)\)
\(Max(s)\) 對應的那個字串多增加了 \(c\) 字元,顯然要變大了。
- \(Trans(s,c)\neq null \Rightarrow Trans(fa,c)\neq null\)
\(Right(fa)\supset Right(s)\),顯然
- \(Max(fa)=Min(s)-1\)
根據合法的 \(len\) 的連續性可證。
- \(Right(Trans(s,c))\subseteq Right(Trans(fa,c))\)
\(Parent\;\;Tree\) 的包含關係所保證。
- \(ST(str)\neq null\iff str\in Fac\)
這些性質不會在構造中全部用到,但是在實際應用 \(SAM\) 的時候很重要。
構建 \(SAM\)
假設當前已經有了 \(T\) 的 \(SAM\),考慮構建 \(T+x\) 的 \(SAM\),設 \(L=|T|\)。
-
找到狀態 \(u\) 滿足 \(Right(u)=\{L\}\),\(u\) 是 \(Parent\;\;Tree\) 的一個葉子節點。
-
構造狀態 \(u'\),\(Right(u')=\{L+1\}\),\(Max(u')=L+1\) 。
-
現在考慮從 \(u\) 到 \(init\) 的這一段鏈,將節點依次記為 \(v_1,v_2,...,v_k\)(\(v_k=init\)),找到 \(Trans(v,x)=null\) 的所有狀態,它們應為 \(\{v\}\) 的一段字首,令 \(Trans(v,x)=u'\) 。
-
找到第一個 \(Trans(v,x)\neq null\) 的狀態 \(v_p\) :
若 \(v_p\) 不存在,則令 \(par(u')=init\) (因為鏈上除了 \(init\) 沒有節點的 \(Right\) 能包含 \(u'\))
若 \(v_p\) 存在,設 \(q=Trans(p,x)\),有 \(Max(q)\geq Max(v_p)+1\),分兩種情況:
(圖中的橫線為 \([r_i-Max(s)+1, r_i]\))
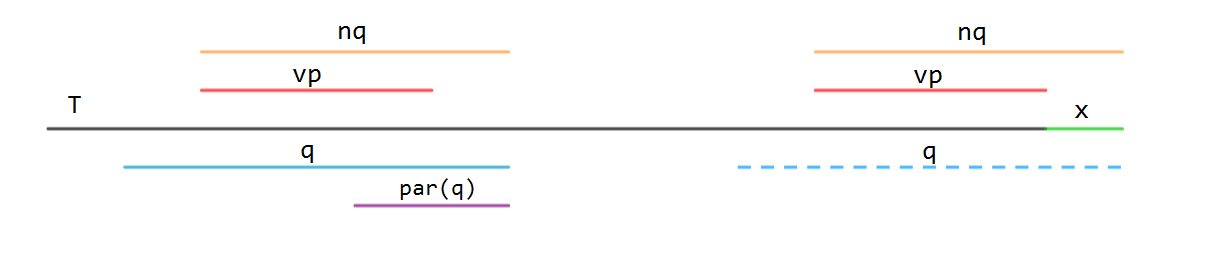
-
\(Max(q)=Max(v_p)+1\)
此時 \(v_p\) 中的所有字串都可以直接擴充到 \(L+1\),因為紅線和藍線左端對齊了,那麼紅線區域中的字串可以,藍色的也可以。令 \(par(u')=q\) 即可。
-
\(Max(q)>Max(v_p)+1\)
這個時候 \(q\) 中的串不止 \(vp\) 中的,有一些更長的可能匹配不了 \(x\),如右邊藍色虛線部分,如果強行轉過去,\(Max(q)\) 就反而變小了,這可能會導致一系列問題。為了解決這種情況,我們新建一個結點 \(nq\),將 \(q\) 裡 \(len\leq Max(v_p)+1\) 的字串給 \(nq\),\(L+1\) 那一塊轉移也交給 \(nq\) 處理。
由於 \(L+1\) 以外的位置還沒法轉移,所以 \(nq\) 的轉移情況是和 \(q\) 完全一樣的,\(Trans(nq,*)=Trans(q,*)\)。而 \(par(nq)\) 即為先前 \(SAM\) 中的 \(par(q)\),由圖,可以知道有這樣的變化:
\[par(q)\leftarrow nq,\; par(u')\leftarrow nq \]然後我們找到所有滿足 \(Trans(v,x)=q\) 的結點(是 \(v_p\) 到 \(v_e\) 的一段區間),現在 \(q\) 已經滿足不了 \(L+1\) 的轉移需求了,但是 \(nq\) 可以,所以將 \(Trans(v,x)\) 改為 \(nq\) 。
然後就沒了。初始是 \(SAM\) 是單獨一個結點 \(init\),每次增量構造即可。
時間複雜度
- 對於原先 \(Trans(v,x)=null\),後來改為 \(u'\) 的結點,這個操作增加了一個轉移,先前證轉移數是 \(O(n)\) 的,從而該操作是 \(O(n)\) 的。
- 增加新結點 \(nq\) 的操作是和總結點數掛鉤的,總節點數 \(O(n)\),從而此操作 \(O(n)\) 。
- 對於將 \(Trans(v,x)\) 改為 \(nq\) 這個操作,時間複雜度證明:
記 \(lst\) 為上一次的 \(u\),每一次構造後它變為 \(u'\),觀察 \(Min(par(lst))\) 的變化情況:
\[Min(u)=Min(v_1)>Min(v_2)>...>Min(v_e)\geq Min(q)-1\geq Min(nq)-1 \]倒數第二個大於等於是因為 \(q\) 向右擴充了一個 \(x\),所以會增加,最後一個大於等於即繼承關係。可以發現在鏈上往上走的過程中,\(Min\) 一直減小,到了 \(q\) 處才可能會加 \(1\),而下一次往上跳的時候經過 \(nq\) 就直接到 \(v_{e-1}\) 處了,\(Min\) 會減少至少 \(1\),而 \(Min\) 最大為 \(|S|\),從而總時間複雜度為 \(O(n)\) 的。
綜上,\(SAM\) 的構造時間複雜度為 \(O(n)\) 。
程式碼實現
話說著很多,但是程式碼還挺短的,這裡的 \(len\) 即 \(Max(s)\),\(link\) 即 \(par(s)\) 。
struct Suffix_Automaton{
struct state{
int len, link;
int next[26];
} t[N<<1];
int cnt, lst;
void init(){
t[1].len = 0, t[1].link = 0;
mem(t[1].next, 0);
cnt = 1, lst = 1;
}
void extend(int c){
int cur = ++cnt;
t[cur].len = t[lst].len+1;
mem(t[cur].next, 0);
int u = lst;
while(u && !t[u].next[c])
t[u].next[c] = cur, u = t[u].link;
if(u == 0) t[cur].link = 1;
else{
int q = t[u].next[c];
if(t[q].len == t[u].len+1) t[cur].link = q;
else{
int nq = ++cnt;
memcpy(t[nq].next, t[q].next, sizeof(t[nq].next));
t[nq].link = t[q].link;
t[q].link = t[cur].link = nq;
while(u && t[u].next[c] == q)
t[u].next[c] = nq, u = t[u].link;
}
}
lst = cur;
}
} SAM;
應用
\(SAM\) 其特殊之處在於它維護的是字尾資訊,但是讀取串卻是從前往後讀的,所以它能夠解決眾多子串型別的問題,其中最典型的一個,即 \(ST(T)\neq null \iff T\in Fac\) 。
CF123D String
給定一個串 \(S\),記 \(f(t)\) 為串 \(t\) 在 \(S\) 的出現次數,求 \(\sum_{t\subseteq S}\frac{f(t)(f(t)-1)}{2}\) ,\(|S|\leq 10^5\) 。
我們只需要維護每個子串的出現次數即可,即該串對應的狀態 \(s\) 的 \(|Right(s)|\),注意到 \(Right(s)\) 即為其子樹中所有節點 \(Right\) 的並集,那麼只需在建 \(SAM\) 的時候,在第一個 \(Right\) 中包含 \(L+1\) 的節點,即新添的 \(u'\) 上記錄一下即可。具體來說,維護狀態的一個屬性 \(siz=|Right(s)|\),每次在 \(u'\) 的地方 \(siz\) 設為 \(1\),表示 \(L+1\) 的出現,然後自底向上貢獻到父親的 \(siz\) 中。一個節點中的字串數量即為 \(Max(s)-Min(s)+1=Max(s)-Max(par(s))\),將它們的值加入答案中即可。
時間複雜度 \(O(n)\)
Code
#include<iostream>
#include<cstring>
#define mem(a,b) memset(a, b, sizeof(a))
#define rep(i,a,b) for(int i = (a); i <= (b); i++)
#define per(i,b,a) for(int i = (b); i >= (a); i--)
#define N 101000
#define ll long long
#define t(x) SAM.t[x]
using namespace std;
struct Suffix_Automaton{
struct state{
int len, link, siz;
int next[26];
} t[N<<1];
int cnt, lst;
void init(){ cnt = lst = 1; }
void extend(int c){
int cur = ++cnt;
t[cur].len = t[lst].len+1, t[cur].siz = 1;
int u = lst;
while(u && !t[u].next[c])
t[u].next[c] = cur, u = t[u].link;
if(u == 0) t[cur].link = 1;
else{
int q = t[u].next[c];
if(t[q].len == t[u].len+1) t[cur].link = q;
else{
int nq = ++cnt;
t[nq].len = t[u].len+1;
memcpy(t[nq].next, t[q].next, sizeof(t[nq].next));
t[nq].link = t[q].link;
t[q].link = t[cur].link = nq;
while(u && t[u].next[c] == q)
t[u].next[c] = nq, u = t[u].link;
}
}
lst = cur;
}
} SAM;
int head[2*N], to[2*N], nxt[2*N];
int cnt;
string s;
ll ans;
void init(){ mem(head, -1), cnt = -1; }
void add_e(int a, int b){
nxt[++cnt] = head[a], head[a] = cnt, to[cnt] = b;
}
void dfs(int x){
for(int i = head[x]; ~i; i = nxt[i])
dfs(to[i]), t(x).siz += t(to[i]).siz;
ans += (ll)(t(x).len-t(t(x).link).len) * t(x).siz * (t(x).siz+1) / 2;
}
int main(){
ios::sync_with_stdio(false);
cin>>s;
SAM.init();
for(char c : s) SAM.extend(c-'a');
init();
rep(i,2,SAM.cnt) add_e(t(i).link, i);
dfs(1);
cout<<ans<<endl;
return 0;
}
CF235C Cyclical Quest
給定一個主串 \(S\) 和 \(n\) 個串 \(x\),求每個串 \(x\) 的迴圈同構串在 \(S\) 中的出現次數。
\(|S|\leq 10^6,\;n\leq 10^5,\;\sum|x|\leq 10^6\)
先通過和上面相同的方式將每個狀態對應的字串數量求出來,要求迴圈同構串的出現次數,考慮將 \(x_i\) 重複兩遍作為一個串,在 \(SAM\) 上找所有匹配長度 \(\geq |x_i|\) 的位置數量。
在匹配的過程中,如果當前 \(trans(st,c)\neq null\),則直接走,匹配長度 \(L++\) ,否則一直跳 \(par(st)\) 直到存在轉移,如果最終不存在,則 \(st\) 回到 \(init\),\(L=0\),否則 \(L=Max(st)+1\) (這肯定是變小了),\(st=Trans(st,c)\) 。由於 \(|x_i|\) 可能還有迴圈節,我們直接匹配的時候還要注意去重,若 \(L\geq |x_i|\),則一直跳 \(par(st)\) 直到 \(Max(par(st))<L\),此時的 \(st\) 即為該迴圈節真正匹配上的狀態,\(ans\leftarrow siz_{st}\),在這個節點上記錄此次匹配,防止一個狀態被重複匹配。
時間複雜度 \(O(n+\sum|x|)\)
Code
Automaton 中的內容和上一份程式碼完全一樣,就不貼了。
#include<iostream>
#include<cstring>
#define mem(a,b) memset(a, b, sizeof(a))
#define rep(i,a,b) for(int i = (a); i <= (b); i++)
#define per(i,b,a) for(int i = (b); i >= (a); i--)
#define N 1001000
#define t(x) SAM.t[x]
using namespace std;
struct Suffix_Automaton{ ... } SAM;
int head[N<<1], to[N<<1], nxt[N<<1];
int cnt;
string s, x;
void init(){ mem(head, -1), cnt = -1; }
void add_e(int a, int b){
nxt[++cnt] = head[a], head[a] = cnt, to[cnt] = b;
}
void dfs(int x){
for(int i = head[x]; ~i; i = nxt[i])
dfs(to[i]), t(x).siz += t(to[i]).siz;
}
int main(){
ios::sync_with_stdio(false);
cin>>s;
SAM.init();
for(char c : s) SAM.extend(c-'a');
init();
rep(i,2,SAM.cnt) add_e(t(i).link, i);
dfs(1);
int T; cin>>T;
rep(o,1,T){
cin>>x;
int m = x.size();
x += x;
int st = 1, l = 0, ans = 0;
rep(i,0,2*m-2){
int c = x[i]-'a';
if(t(st).next[c]) l++, st = t(st).next[c];
else{
while(st && t(st).next[c] == 0) st = t(st).link;
if(st == 0) st = 1, l = 0;
else l = t(st).len+1, st = t(st).next[c];
}
if(i >= m-1 && l >= m){
while(t(t(st).link).len >= m) st = t(st).link;
if(t(st).vis < o) ans += t(st).siz, t(st).vis = o;
l = m;
}
}
cout<<ans<<endl;
}
return 0;
}
UOJ#395. 【NOI2018】你的名字
待更。