Python例項大全(基於Python3.7.4)
文章目錄
- 部落格說明:
- 基礎知識
- 001.Hello,World
- 002.CircularStatement
- 003.ConditionalStatement
- 004.range
- 005.lambda
- 006.random
- 007.time
- 008.re
- raw string 原生字串
- re.match(pattern, string, flags=0)
- 強化理解一:貪心模式與懶惰模式
- 強化理解二:例項補充
- 視野擴充:檢視官方的開發文件
- re.search(pattern, string, flags=0)
- re.sub(pattern, repl, string, count=0, flags=0)
- re.subn(pattern, repl, string, count=0, flags=0)
- re.compile(pattern[, flags])
- re.escape(string)
- findall(pattern, string, flags=0)
- 強化理解之優先順序問題
- re.finditer(pattern, string, flags=0)
- re.split(pattern, string[, maxsplit=0, flags=0])
- re模式
- 貪婪模式與惰性匹配
- group(s)
- 常見字元類
- 正則表達的常見應用(模型)
- 009.(not) in
- 010.is
- 011.stack
- 012.queue
- 013.列表生成式
- 014.package
- 015.搜尋演算法
- 016.最短路徑
- 017.矩陣
- 018.排序
- 019.查詢
- 020.eval
- 021.待定
- 模板程式碼
- 專案實戰
部落格說明:
只是一些python語言的基礎應用及其技巧,不斷更新、記錄,並製作對應目錄、索引。
目標是1000例,不斷更新補全,如有需要可提前說明相關知識點。
基礎知識
001.Hello,World
print "Hello,World!"
print "Hi,Python2!"
print ("Hello,World!")
print ("Hi,Python3!")
# python2.7可以輸出python3版本,但反過來不行
Python2.7能夠正常輸出py2、py3
{kind=link}
Python3.7無法正常輸出py2,版本不相容
{kind=link}
002.CircularStatement
for i in range(10):
print(i,"Hello,For Circular.")
簡單for迴圈之range示範
{kind=link}
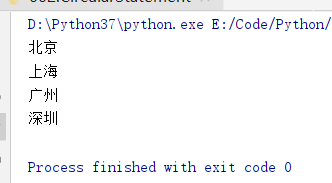
# 列表單、雙引號都可以使用
cities = ['北京','上海',"廣州","深圳"]
for eachCity in cities:
print (eachCity)
簡單for迴圈之輸出列表
{kind=link}
# 直接通過迭代器遍歷元素
py = "python"
for character in py:
print(character)
print()#預設會輸出空行
# 通過列表的索引遍歷元素
for i in range(len(py)):
print(i,py[i])
print("\nlen(py)=",len(py))
簡單for迴圈之字串
{kind=link}
# 簡單foreach迴圈,需要Python3
def foreach(function, iterator):
for item in iterator:
function(item)
return
def printItself(it):
print(it,end=" ")
return
# 在這裡,試著比較直接使用print與使用printItself的效果
my_tuple = (1, 2, 3, [4, 5], 6)
my_dictionary = {"Apple": "Red",
"Banana": "Yellow",
"Pear": "Green"
}
foreach(printItself, my_tuple)
# 1 2 3 [4, 5] 6 #註釋行為對應的輸出結果,下同
print()
foreach(print, my_tuple)
# 1
# 2
# 3
# [4, 5]
# 6
foreach(print, range(len(my_tuple)))
# 0
# 1
# 2
# 3
# 4
print()
foreach(print, my_dictionary)
foreach(print, my_dictionary.keys())
# 上二個語句等價,輸出相同
# Apple
# Banana
# Pear
foreach(print, my_dictionary.values())
# Red
# Yellow
# Green
print()
print(my_dictionary)
# {'Apple': 'Red', 'Banana': 'Yellow', 'Pear': 'Green'}
print(my_dictionary.keys())
# dict_keys(['Apple', 'Banana', 'Pear'])
print(my_dictionary.values())
# dict_values(['Red', 'Yellow', 'Green'])
print()
foreach(printItself, range(len(my_dictionary)))
# 0 1 2
print()
foreach(printItself,my_dictionary.keys())
# Apple Banana Pear
print()
foreach(printItself,my_dictionary.values())
# Red Yellow Green
print("\n")
foreach(print,my_dictionary)
print()
foreach(print,my_dictionary.keys())
# 上二個語句等價,輸出相同
# Apple
# Banana
# Pear
print()
foreach(print,my_dictionary.values())
# Red
# Yellow
# Green
print()
for item in my_dictionary.items():
print(item)
# ('Apple', 'Red')
# ('Banana', 'Yellow')
# ('Pear', 'Green')
for it in my_dictionary:
print(it,":",my_dictionary[it])
# Apple: Red
# Banana: Yellow
# Pear: Green
# 值得說明的是:dict[key]=value(講究與之對應),當key值為數值時還可以採用以下途徑
for i in range(len(my_dictionary)):
print(i)
# print(my_dictionary[i])#key值不是數值時,找不到對應項會報錯
# 0
# 1
# 2
自定義foreach迴圈之輸出元祖
{kind=link}
自定義foreach迴圈之輸出字典
{kind=link}
003.ConditionalStatement
# -*- coding: UTF-8 -*-
# python 陣列用法
# array.array(typecode,[initializer])
# --typecode:元素型別程式碼;
# initializer:初始化器,若陣列為空,則省略初始化器
import array
num = array.array('H',[1]*21)
# print("len(num)=",len(num))
# print(num)
len = len(num)
for i in range(len):
if 0==i or i==1:
num[i] = 0
continue
j = i
while i*j<len:
if(num[j*i]):
num[j*i] = 0
j+=1
# for i in range(len):
# print(i,num[i])
# print(num)
# 以上實現的是一個簡單的質數篩法,PrimeNumber
for i in range(len):
if i<2:
print(i,"既不是質數,也不是偶數。")
elif num[i] and i%2:
print(i,"是質數,且是奇質數")
elif num[i] and 0==i%2:
print(i, "是質數,且是偶質數")
elif not(num[i]) and not(i%2):
print(i, "非質數,且是偶數")
else: # not(num[i]) and (i%2)
print(i, "非質數,且是奇數")
條件語句,以及質數篩法
{kind=link}
while i*j<len:
statement
該語句完全可以換成另外一種寫法(殊途同歸)
while True:
statement
if i*j>=len:
break
# 官方文件
https://docs.python.org/2/library/array.html
Python陣列型別的說明符
{kind=link}
004.range
# range(10)
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
# range(5,10)
# [5, 6, 7, 8, 9]
# range(0,10,3)
# [0, 3, 6, 9]
# range(1,10,3)
# [1, 4, 7]
# range(1,10,10)
# [1,]
# range(1,10,-2)
# [1,]
# range(2,-10,-1)
# [2,1,0,-1,-2,-3,-4,-5,-6,-7,-8,-9]
# range(-2,-10,-1)
# [-2,-3,-4,-5,-6,-7,-8,-9]
# range(2,10,-1)、range(-2,10,-1)、range(2,-10,1)
# 以上三個容器都為空
# 語法 range(start, stop[, step])
# range(a,b,c)
# a不寫時預設為0,從a開始;生成到b(故通常b>=a);c為步距
# range 預設生成正數方向,若a>b即b<a時將會往左生成負數,步距c也應要改為負數
# 即 不要求start和stop有什麼直接的大小關係
# 測試
for i in range(10):
print(i,end=" ")
print()
range(start, stop[, step])
{kind=link}
print(sum(range(1,101)))
面試問題:一行程式碼求和[0,100],並輸出結果
![面試問題:一行程式碼求和[0,100],並輸出結果](https://img-blog.csdnimg.cn/20191104221324724.PNG#pic_center){kind=link}
005.lambda
lambda
map
filter
reduce
sum
006.random
007.time
008.re
# -*- coding:utf-8 -*-
# re 正規表示式
import re
# raw string 原生字串
s1 = "abc\nop"
s2 = r"abc\nop"
print("s1=",s1)
print("s2=",s2)# 逗號隔開的輸出會預設輸出一個空格以分開
print(s2,s2) # 再次驗證該空格
raw string 原生字串
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
import re
# patter 正規表示式
# string 待匹配的母字串
# flags 標誌位:是否區分大小寫、是否多行匹配
text = 'This is a student,named MY from SJTU University.'
# re.match(pattern, string, flags=0)
# 定死了必須從開頭的首元素位置(索引為0)開始匹配
res = re.match('This',text)# 預設flag為0,完全匹配模式(嚴格大小寫、字元配對)
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('this',text)
# None
print(res)
res = re.match('this',text,re.I)# 置 flags 為 re.I後忽略大小寫;爬蟲資料清洗通常使用多行匹配且不區分大小寫的匹配模式
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('is',text) # None,re.match()非開頭即是匹配得到也不能夠配對
print(res)
res = re.match('(.*)is',text)
# "."匹配任意字元(預設為貪婪模式、儘可能多地匹配) + "*"匹配前一個字元0次或多次 = 若存在,則往前取任意多字元直到起始位置(全部取)
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*) is',text)# ' is'往前全部取、包括正規表示式子串本身(貪婪、會盡可能多匹配),上一個是'is'往前全部取,兩者執行結果一樣
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*) is ',text)# ' is '往前全部取(包括正規表示式子串本身、貪婪模式會盡可能多匹配)
# <re.Match object; span=(0, 8), match='This is '>
print(res)
res = re.match('(.*?)is',text)# ‘?'匹配前一個元素0次或1次,預設懶惰模式、儘可能少匹配、故不含包括正規表示式子串,此例子中即不含'is'
# <re.Match object; span=(0, 4), match='This'>
print(res)
res = re.match('(.*?) is',text)
# <re.Match object; span=(0, 5), match='This '># 注意區分這句與上一句,一個空格引起差異
print(res)
res = re.match('(.*?)is ',text)
# <re.Match object; span=(0, 7), match='This is'>
print(res)
res = re.match('(.*?) is ',text) # 由上述三句可知'?'懶惰模式無法捨棄空格
# <re.Match object; span=(0, 8), match='This is '>
print(res)
re.match(pattern, string, flags=0)
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
import re
str = 'This is the last one'
res = re.match('(.*) is (.*?).*',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*?)(.*)',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*).*',str,re.M | re.I)
print(res)
res = re.match('(.*) is (.*)',str,re.M | re.I)
print(res)
# 以上四個執行結果同為 <re.Match object; span=(0, 20), match='This is the last one'>
res = re.match('(.*) is (.*?)',str,re.M | re.I)
print(res)
# <re.Match object; span=(0, 8), match='This is '>
# 由上可知,'.*'貪心匹配、元素有則取之
# 由上可知,'.*?'懶惰匹配、滿足正則子串即可(注意:空格也要匹配)
# 資料清洗通常使用多行匹配 re.M 且不區分大小寫 re.I 的匹配模式
強化理解一:貪心模式與懶惰模式
{kind=link}
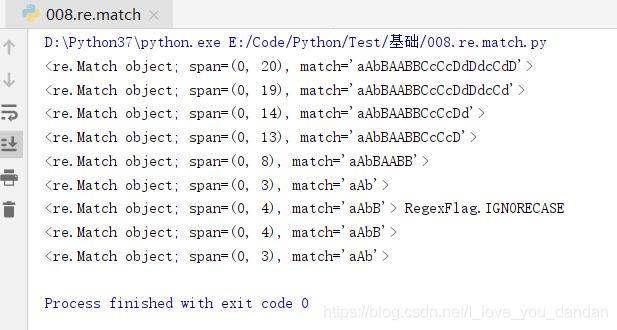
text = "aAbBAABBCcCcDdDdcCdD"
print( re.match("a.*d",text,re.I))
# <re.Match object; span=(0, 20), match='aAbBAABBCcCcDdDdcCdD'>
print( re.match("a.*d",text))
# <re.Match object; span=(0, 19), match='aAbBAABBCcCcDdDdcCd'>
print( re.match("a.*?d",text))
# <re.Match object; span=(0, 14), match='aAbBAABBCcCcDd'>
print( re.match("a.*?d",text,re.I))
# <re.Match object; span=(0, 13), match='aAbBAABBCcCcD'>
print( re.match("a.*b",text,re.I))
print( re.match("a.*?b",text,re.I))
print( re.match("a.*?B",text),re.I)
print( re.match("a.*?B",text))
print( re.match("a.*?b",text))
# 上邊四句的輸出結果依次對應如下:
# <re.Match object; span=(0, 8), match='aAbBAABB'>
# <re.Match object; span=(0, 3), match='aAb'>
# <re.Match object; span=(0, 4), match='aAbB'> RegexFlag.IGNORECASE
# <re.Match object; span=(0, 4), match='aAbB'>
# <re.Match object; span=(0, 3), match='aAb'>
強化理解二:例項補充
{kind=link}
貪心儘可能多、從原母字串原長逐漸剔減,
惰性則正則字串剛好滿足條件即可
由此兩個強化理解的例項可知,re.match的正規表示式為字串,需要使用單或雙引號格式,但有無小括號並不影響re.match的匹配。
剩下的諸如特殊表示式序列、字符集、以花括號指定匹配次數、順/逆序肯/否定環視等知識點,多多敲碼、多看官方文件。
視野擴充:檢視官方的開發文件
# -*- coding:utf-8 -*-
import re
text = 'This is a text written by MY ,' \
'from SheHui University on 2019/11/06 at 00:39.'
res = re.search(r'(\d)',text,re.I)
# <re.Match object; span=(69, 70), match='2'>
# \d 同 [0-9] 匹配任意(單個)十進位制數
print(res)
res = re.search(r'(\D)',text,re.I|re.M)
# <re.Match object; span=(0, 1), match='T'>
# \D 同 [^0-9] 匹配任意(單個)非數字字元
# 注意:符號^在方括號內
print(res)
res = re.search(r'(\d).*',text,re.I|re.M)
# <re.Match object; span=(69, 89), match='2019/11/06 at 00:39.'>
print(res)
# res = re.search(r'.*(\d)',text,re.I)
# res = re.search(r'.*(\D).*',text,re.I)
# res = re.search(r'.*(\D)',text,re.I)
res = re.search(r'(\D).*',text,re.I|re.M)
# 上邊被註釋掉的3句,執行結果與此句相同
# <re.Match object; span=(0, 88), match='This is a text written by a student named MY from>
print(res)
res = re.search(r'(\w)',text,re.I|re.M)
# <re.Match object; span=(0, 1), match='T'>
# \w 同 [a-zA-Z0-9]
print(res)
res = re.search(r'(\W)',text,re.I|re.M)
# <re.Match object; span=(4, 5), match=' '>
# \W 同 [^a-zA-Z0-9]
print(res)
res = re.search(r'(\W).*',text,re.I|re.M)
# <re.Match object; span=(4, 76), match=' is a text written by MY ,from SheHui University >
print(res)
res = re.search(r'(\w)(.*)',text,re.I|re.M)
# <re.Match object; span=(0, 76), match='This is a text written by MY ,from SheHui Univers>
print(res)
re.search(pattern, string, flags=0)
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
# patter 正規表示式
# 用於替換的字串
# string 要被替換的母字串
# count 替換次數,預設為0表示無窮多次
# flags 標誌位:是否區分大小寫、是否多行匹配
# re.sub(pattern, repl, string, count=0, flags=0)
import re
# 單純替換
text = '1+1=2'
res = re.sub(r'=',r'>',text,0,re.I)
print(text)
print(res)
print('------------0------------')
# 去除註釋(無用資訊、這在爬蟲中往往用於資料清理)
text = '1+1=2 # 這是客觀真理 \n' \
' 1+1>2 # 這是團結的力量 \n' \
' 1+1<2 # 這是內鬥結果 \n'
res = re.sub(r'#.*$',r'',text,0,re.M)
print(text)
print('------------1----------')
print(res)
print('------------2----------')
res = re.sub(r'#.*$',r'',text,0,re.M)
print(res)
print('------------3----------')
res = re.sub(r'#.*$',r'',text,0,re.M|re.S)
print(res)
print('----------4------------')
res = re.sub(r'#.*$',r'',text,1,re.M)
print(res)
print('----------5------------')
res = re.sub(r'#.*$',r'',text,2,re.M) # 多行模式,去掉註釋(替換)次數為 2
print(res)
print('----------6------------')
res = re.sub(r'#.*$',r'',text,3,re.M)
print(res)
print('----------7------------')
res = re.sub(r'#.*$',r'',text,2)# 不出標誌說明是多行模式的話,$ 僅僅匹配末尾
print(res)
print('----------8------------')
res = re.sub(r'#.*$',r'',text,2,re.X)
print(res)
# 詳細模式的多行將忽略空白字元和註釋,故替換失敗
# re.find()查詢預設對多行模式生效
print('----------9------------')
res = re.findall('#',text)
print(res)
re.sub(pattern, repl, string, count=0, flags=0)
{kind=link}
{kind=link}
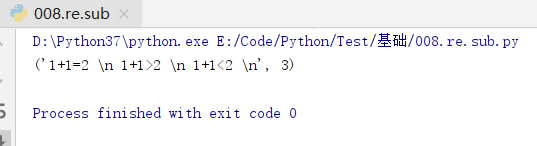
# -*- coding:utf-8 -*-
# re.subn(pattern, repl, string, count=0, flags=0)
import re
text = '1+1=2 # 這是客觀真理 \n' \
' 1+1>2 # 這是團結的力量 \n' \
' 1+1<2 # 這是內鬥結果 \n'
res = re.subn(r'#.*$',r'',text,0,re.M)
print(res)
# subn 與 sub 這兩個函式用法完全一樣,只是前者返回元組,後者返回字串
re.subn(pattern, repl, string, count=0, flags=0)
{kind=link}
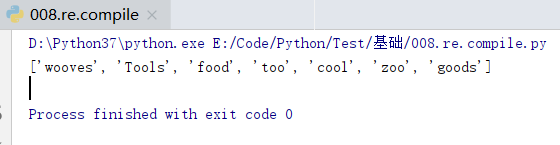
# -*- coding:utf-8 -*-
# re 正規表示式
# patter 正規表示式(定義字串如何構成)
# flags 標誌位:是否區分大小寫、是否多行匹配
# re.compile(pattern[, flags])
import re
words = 'wooves Tools food too cool hello zoo \n goods'
ret = re.compile(r'\w*oo\w*') # 編譯生成查詢含有oo字母元素的單詞的正則表達模式物件 obj物件可以直接呼叫re的方法
print(re.findall(ret,words)) # re.findall() 預設多行查詢
print((ret.findall(words))) # 這是第二種有效的等價寫法
# 正則模式的物件obj可以直接呼叫re的任何方法
re.compile(pattern[, flags])
{kind=link}
# -*- coding:utf-8 -*-
import re
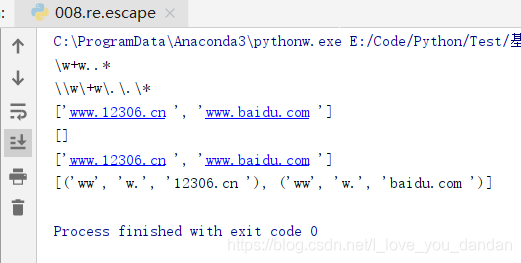
# re.escape(string)
# string 為需要轉義的字串(常作為正則表達字串)
str = 'www.12306.cn \n' \
'www.baidu.com '
pat = '\w+w..*'
ret = re.escape(pat)
print( pat)
print( ret)
# findall(pattern, string, flags=0)
print( re.findall(pat,str))
print( re.findall(ret,str))
print( re.findall(r'\w+w..*',str))
print( re.findall(r'(\w+)(w.)(.*)',str))
# 輸出依次為
# \w+w..*
# \\w\+w\.\.\*
# ['www.12306.cn ', 'www.baidu.com ']
# []
# ['www.12306.cn ', 'www.baidu.com ']
# [('ww', 'w.', '12306.cn '), ('ww', 'w.', 'baidu.com ')]
# escape “逃離”->“偏離原有意圖”
# 不再是 raw string 原生字串、可以可以表示轉義
# 而是 硬生生的字元本身、別無組合之後的其他意思
re.escape(string)
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
# findall(string[, pos[, endpos]])
import re
res = re.findall(r"\d", "圖書館2019年11月的閱讀次數為 99萬") # 返回的是不可修改的元組
print(res) # ['2', '0', '1', '9', '1', '1', '9', '9']
res = re.findall(r"(\d+)", "圖書館2019年11月的閱讀次數為 99萬,點贊數:3200")
print(res) # ['2019', '11', '99', '3200']
res = re.findall(r"(\D+)", "圖書館2019年11月的閱讀次數為 99萬,點贊數:3200")
print(res) # ['2019', '11', '99', '3200']
for i in res:
print(i)
print('--------分割線---------')
# words = ['wooves','Tools','food','too','cool','hello','zoo']
words = 'wooves Tools food too cool hello zoo \n goods'
print("1 ",re.findall(r'Oo',words))
print('2 ',re.findall(r'Oo',words,re.I))
print('3 ',re.findall(r'(\w+)(Oo)(\w*)',words,re.I))
# 方式3 正規表示式全部被括號分割包圍時,結果為元組內部巢狀了列表
# 方式4 將按照元祖形式輸出符合匹配條件的“單詞”(即含有元素“oo”、不區分大小寫)
print('4 ',re.findall(r'\w+Oo\w*',words,re.I))
print('5 ',re.findall(r'\w+(Oo\w*)',words,re.I))
# 當正規表示式只是部分還有括號時,僅輸出 括號部分對應的元祖(字串)
print('6 ',re.findall(r'(\wOo)w*',words,re.I))
print('7 ',re.findall(r'(\wOo).*',words,re.I))
print('8 ',re.findall(r'(\wOo)(.*)',words,re.I))
print('9 ',re.findall(r'\wOo.*',words,re.I))
print('10 ',re.findall(r'\w+oo\w.*',words))
print('11 ',re.findall(r'\w+oo\w.*',words,re.S))
# re.S 模式下 '.'可以匹配任意字元,包括預設不允許的回車‘\n’換行符
findall(pattern, string, flags=0)
{kind=link}
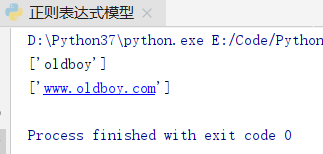
ret=re.findall('www.(baidu|oldboy).com','www.oldboy.com')
print(ret) # ['oldboy']
ret=re.findall('www.(?:baidu|oldboy).com','www.oldboy.com')
print(ret) # ['www.oldboy.com']
# findall會優先把匹配結果組裡內容返回,這也正是上邊只輸出部分括號對應的正則匹配結果的原因
# 如果想要完整的正則匹配結果,使用 ‘?:’取消優先順序許可權即可
強化理解之優先順序問題
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
# patter 正規表示式(定義字串如何構成)
# string 待查詢的母字串
# flags 標誌位:是否區分大小寫、是否多行匹配
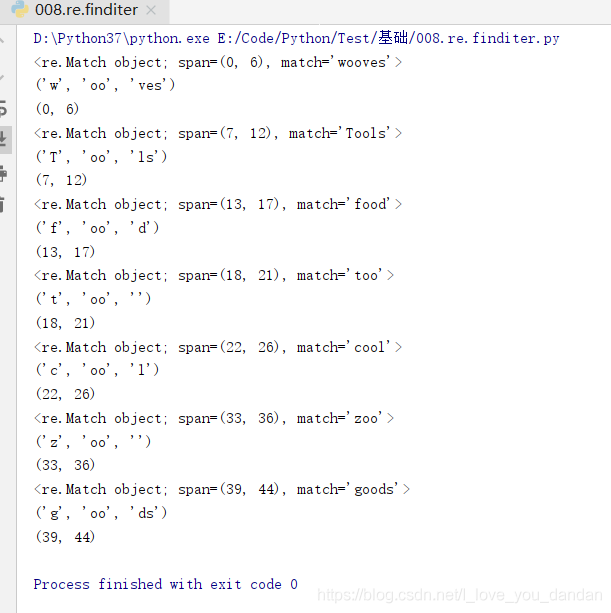
# re.finditer(pattern, string, flags=0)
import re
words = 'wooves Tools food too cool hello zoo \n goods'
ret = re.compile(r'(\w*)(oo)(\w*)') # 編譯生成查詢含有oo字母元素的單詞的正則表達模式物件
res = re.finditer(ret,words)
for i in res:
print(i)
print(i.groups())# 所有分組;正則表達模式有了括號才有分組,否則為空
print(i.span())# 生產的區間始終是“左閉右開”格式
# 需要注意的是,re.finditer()與re.find()一樣,只輸出有括號的部分
# 但區別是 前者生成列表,後者生成元組
re.finditer(pattern, string, flags=0)
{kind=link}
# -*- coding:utf-8 -*-
# re 正規表示式
# patter 正規表示式(用於替換的字串)
# string 作為分隔素材的母字串
# maxsplit 用於指定最大分割次數,不指定則預設為0表示無窮大、將全部分割
# flags 標誌位:是否區分大小寫、是否多行匹配
# re.split(pattern, string[, maxsplit=0, flags=0])
# 返回列表
import re
words = 'wooves Tools food too cool hello zoo \n goods'
res = re.split(r'\W',words)
print(res)
res = re.split(r'\s',words)
print(res)
res = re.split(r'\s+',words) # 這才是正確去除所有空白符 [\t\n\r\f\v] 因為 *與+ 表示貪心模式(?要看情況)
print(res)
res[1]='123' # 成功修改,故返回的是列表而不是元組
print(res)
text = '?a_b!2@'
res = re.split(r'\w+',text) # 由該句可知:\w除了匹配字母和數字,還匹配下劃線(識別符號命名規則……)
print(res)
print(re.split('a','1A1a2A3',re.I)) # ['1A1', '2A3']
print(re.split('a','1A1a2A3',0,re.I))# ['1', '1', '2', '3']
# 請注意使用格式這個大坑,否則將會導致re.I無法忽略字母的大小寫
re.split(pattern, string[, maxsplit=0, flags=0])
{kind=link}
\w 匹配字母數字及下劃線,即:\w = [a-zA-Z0-9] + '_'
\W 匹配f非字母數字下劃線,即: \W = [^a-zA-Z0-9] + '_'
\s 匹配任意空白字元,即: \s = [\t\n\r\f\v]
\S 匹配任意非空字元,即: \S = [^\t\n\r\f\v]
\d 匹配任意十進位制數數字,即: \d = [0-9]
\D 匹配任意非數字字元,即: \D = [^0-9]
\A 只在字串首部開始匹配
\b 匹配位於開始或結尾的空字串
\B 匹配不位於開始或結尾的空字串
\Z 匹配字串結束,如果存在換行,只匹配換行前的結束字串
\z 匹配字串結束
\G 匹配最後匹配完成的位置
\n 匹配一個換行符
\t 匹配一個製表符
^ 匹配字串的開頭
$ 匹配字串的末尾
. 匹配任意字元,除了換行符,re.DOTALL標記被指定時,則可以匹配包括換行符的任意字元
[....] 用來表示一組字元,單獨列出:[amk]匹配a,m或k
[^...] 不在[]中的字元:[^abc]匹配除了a,b,c之外的字元
* 匹配0個或多個的表示式
+ 匹配1個或者多個的表示式
? 匹配0個或1個由前面的正規表示式定義的片段,非貪婪方式
{n} 精確匹配n前面的表示
{m,m} 匹配n到m次由前面的正規表示式定義片段,貪婪模式
a|b 匹配a或者b
() 匹配括號內的表示式,也表示一個組
re模式
前面的*,+,?等都是貪婪匹配,也就是儘可能匹配:
“從整個字串逐減1個末尾元素直至滿足條件……”
後面加?號使其變成惰性匹配:
“從字串的第一個元素開始,逐增1個首部元素直至滿足條件……”
貪婪模式與惰性匹配
res = re.search(r"\d+", "圖書館2019年11月的閱讀次數為 99萬").group() # 只匹配第一組數字
print(res) # 2019
res = re.search(r"\d+", "圖書館2019年11月的閱讀次數為 99萬")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# () 由此可知group存在的條件是正則匹配使用了小括號
res = re.search(r"(\d+)", "圖書館2019年11月的閱讀次數為 99萬")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('2019',)
res = re.search(r"(\d)(\d+)", "圖書館2019年11月的閱讀次數為 99萬")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('2', '019')
res = re.search(r"(\d+)(\d)", "圖書館2019年11月的閱讀次數為 99萬")
# print(res) # <re.Match object; span=(3, 7), match='2019'>
print(res.groups())# ('201', '9')
res = re.search(r"(\d)(\d+)(\d)(\D)", "圖書館2019年11月的閱讀次數為 99萬")
# print(res) # <re.Match object; span=(3, 8), match='2019年'>
print(res.groups())# ('2', '01', '9', '年')
res = re.search(r"(\d+)(.*)", "圖書館2019年11月的閱讀次數為 99萬,點贊數:3200")
print(res) # <re.Match object; span=(3, 30), match='2019年11月的閱讀次數為 99萬,點贊數:3200'>
print(res.groups()) # ('2019', '年11月的閱讀次數為 99萬,點贊數:3200')
print(res.group(0))
print(res.group(1))
print(res.group(2))# 超出索引將會輸出空列表,不報異常
group(s)
{kind=link}
# -*- coding:utf-8 -*-
import re
a = "123abc456"
res = re.search("([0-9]*)([a-z]*)([0-9]*)",a) #123abc456,返回整體
print(res.groups())
for i in range(1+len(res.groups())):
print(res.group(i))
# 由此可見,group(i)引數i並非像索引那般範圍被限定在了[0,len)左閉右開區間
# 而是[0,len]雙閉合,即能夠取到引數len
# 另外,值得注意的是 group 與 groups不是拼寫錯誤,而是規定……
# 注意融會貫通,當只需要各個列表元素時,使用以下的寫法
print("----------------我是分割線----------------")
for i in res.groups():
print(i)
{kind=link}
特別補充說明:
一般情況下,group()和groups()方法 僅與re.match()或re.search() 共同使用,不涉及其他 re的操作。
雖然re.findall()與re.finditer()在它們的正規表示式存在圓括號時,也可以使用,但由於返回的是列表資料型別,直接呼叫會更加方便、高效。
(任意長)片語:
ret = re.compile(r'\w+',re.I)
匹配到任意一個字母或單詞(不區分大小寫)、中文(單個漢字或連續的多個漢字)、或連續的阿拉伯數字,也可為此三者直接相連的組合體
及一反三:
r'\w+abc\w*'表示含有字母abc(必須完全匹配abc)的單詞/字串
(任意長)數字:
ret = re.compile(r'\d+')
匹配到任意數字(串)
(任意長)空白字元:
r'\s+'或r'\s*' 可用於資料清洗
舉一反三:
re.split(r'\s+',text,0,re.S|re.X)文字按照空白字元全部分割
re.sub(r'\s+',r'',text,0,re.S|re.X))文字所有空白字元一律刪除
(多行)註釋去除
re.sub(r'#.*$',r'',text,0,re.M)
(多行)資料刪除
re.sub(r'.*?<p>',r'',text),re.S|re.X)
<p>標籤之前全部刪除 可等效改為r'.*<p>'或r'.+<p>'或r'.+?<p>'
舉一反三:
r'<p>.*'或r'<p>.+' 表示匹配<p>標籤之後全部資料
說明:<p>標籤本身也在資料範圍之內(貪婪模式)
常見字元類
正則表達的常見應用(模型)
詳情請看專案實戰部分:04 資料清洗
009.(not) in
010.is
011.stack
012.queue
013.列表生成式
def fizzBuzz(n):
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
print(fizzBuzz(30))
面試問題:FizzBuzz數列
{kind=link}
014.package
015.搜尋演算法
find
BFS(廣度優先)
DFS(深度優先)
016.最短路徑
017.矩陣
支援多維陣列 #### NumPy
018.排序
019.查詢
020.eval
def fizzBuzz(n):
return ['Fizz' * (not i % 3) + 'Buzz' * (not i % 5) or str(i) for i in range(1, n+1)]
n = input('input n:')
res = fizzBuzz(eval(n)) # str(n)將報錯
print(res)
eval()與str()
{kind=link}
021.待定
模板程式碼
001.ProgrammingParadigm
# -*- coding: UTF-8 -*-
# 正規化程式設計(函數語言程式設計)
def main():
my_dict = {'子': '鼠', '醜': '牛', '寅': '虎', '卯': '兔',
'辰': '龍', '巳': '蛇', '午': '馬', '未': '羊',
'申': '猴', '酉': '雞', '戌': '狗', '亥': '豬'}
prinfDictKeys(my_dict)
printDictValues(my_dict)
printDict(my_dict)
def prinfDictKeys(dict):
for key in dict.keys():
print(key, end=" ")
print()
def printDictValues(dict):
for value in dict.values():
print(value, end=" ")
print()
def printDict(dict):
for key in dict:
print(key,":",dict[key],end='\t\t')
if __name__ == '__main__':
main()
正規化程式設計(函數語言程式設計)
{kind=link}
# 上邊構造的字典my_dict有另外一種等價寫法
my_dict = dict(子='鼠', 醜='牛', 寅='虎', 卯='兔', 辰='龍', 巳='蛇', 午='馬', 未='羊', 申='猴', 酉='雞', 戌='狗', 亥='豬')
002.Object-Oriented Programming
OOP物件導向程式設計
Python中,類即物件;對比JavaScript;以及原始印象中的C++的類與物件
003.待定
專案實戰
001.Python繪圖
Python應用範圍廣泛,正是因為它的第三方庫非常的豐富。今天來介紹一些和繪圖有關的第三方庫。
第一種是繪圖工具
hmap-影象直方圖的庫。
imgSeek-使用視覺相似性搜尋影象集合的專案。
Nude.py-色情圖片識別的庫。
pagan-基於輸入字串和雜湊的復古識別(Avatar)生成。
pillow-Pillow由PIL而來,是一個影象處理庫。
pyBarcode-在Python中建立條形碼而不需要PIL。
pygram-像Instagram的影象過濾器。
python-qrcode-一個純Python QR碼生成器。
Quads-基於四叉樹的計算機藝術。
scikit-image-用於(科學)影象處理的Python庫。
thumbor-一個小型影象服務,具有剪裁,尺寸重設和翻轉功能。
wand-MagickWand的Python繫結,ImageMagick的C API。
turtle-海龜渲染器,使用Turtle庫畫圖也叫海龜作圖(留言貢獻)
第二種就是資料視覺化的繪相簿
Altair-使用Altair,您可以花費更多時間瞭解您的資料及其含義。Altair的API簡單,友好和一致,建立在強大的Vega-Lite JSON規範之上。這種優雅的簡潔性以最少的程式碼產生了美麗而有效的視覺化。
Bokeh-Python的互動式網路繪圖。
ggplot-與ggplot2相同的API。
Matplotlib-一個Python 2D繪相簿,用以繪製一些高質量的數學二維圖形。
Pygal-一個Python SVG圖表建立者。
PyGraphviz-Graphviz的Python介面。
PyQtGraph-互動式和實時2D/3D/影象繪圖和科學/工程小部件。
Seaborn-使用Matplotlib的統計資料視覺化。
VisPy-基於OpenGL的高效能科學視覺化。
002.檔案操作
# -*- coding:utf-8 -*-
import csv
csvfile = open('csv_test','w',newline='')
writer = csv.writer(csvfile)
writer.writerow(['name','age','sex','phone'])
data = [('bbc','18','M','7458025'),
('cnn','17','F','9969966'),
('CCTV','12','M','1100901')]
writer.writerow(data)
csvfile.close()
CSV檔案
注意事項:py檔名不能起成“csv”
否則將會導致如下錯誤:
“AttributeError: module 'csv' has no attribute 'writer'”
## 003.涉及網路(上傳、下載)
004.資料清洗 (字串操作)
知識點詳情請往回檢視基礎知識部分:008 re 正規表示式
正規表示式
str = "1234567"
print( str[0:5:] )# 左閉右開區間,元素下標 從min到max-1(右邊是指中間位置)
print( str[2:10:] )# 右邊超出可當作len值
print( str[::])# 原串
print( str[6::])# 左邊若是超過len-1則為空串,右邊不寫預設 len
print(str[2]," ",str[-2])# 單個點索引不可超出範圍[0,len)或[0,len-1]
print( str[-2::])# 左邊為負數-則表示從倒數第i個數開始往右
print( str[:-2:])# 左邊不寫預設為0,右邊為負數-擷取至i-1(即:依舊是左閉右開)
print( str[2:-2:])# 345
print( str[-4:-2:])# 45
print( str[::-1])# 反序字串,相鄰索引值差為1
print( str[::-2])# 反序字串,按照相鄰索引值差為2擷取部分
print( str[::-4])# 反序字串# 反序字串,按照相鄰索引值差為4擷取部分
print( str[3::-1])# 4321 逆序,索引i在左、正數,取str[i]左側、含str[i]
print( str[:3:-1])# 765 逆序,索引i在右、正數,取str[i]右側、不含str[i]
print( str[:-3:-1])# 76 逆序,索引i在右、負數,取str[len-i]右側、不含str[len-i]
print( str[-3::-1])# 54321 逆序,索引i在右、負數,取str[len-i]左側、含str[len-i]
print( str[-2:-4:-1])# 65
print( str[-2:2:-1])# 654
三個引數“左起點a:右起點b:順序及步距標誌c”。
a、b可正可負,正則從左往右數、負則自右往左數、區間始終是左閉右開區間。
c通常省略預設正序步距為1或者置c為-1表示逆序步距為1,也可修改步距大小(可正可負)。
字串擷取
{kind=link}
str = "abcABCaBcD"
print( str.replace('c','E'))# abEABCaBED 大小寫敏感
print( str) # abcABCaBcD 由此可知,替換生成了新物件、原字串不受影響
print( str.replace('Bc','E'))# abEABCaBED 替換並不要求元素的位數相同
print( str.replace('Bc',' '))# abEABCaB D 替換成空格
print( str.replace('Bc',''))# abEABCaBED 替換成空串時預設為刪除該(片段)元素
print( str.replace('Bc',' '))# abEABCaB D 替換成空格
字串替換
{kind=link}
# 字串查詢
str = "AbCdABCDabcdABCD"
print( str.find('A'))# 預設從索引0開始往右查詢
print( str.find('A',2))# 從索引2即第三個數開始往右查詢
print( str.find('c',2,10))# 在索引範圍 [2,10)開始查詢,左閉右開區間
print( str.find('c',2,11))# 在索引範圍 [2,10)開始查詢
# 找到,返回對應索引(單個數值);找不到,返回 -1
# index與find等效果,不過找不到時會報異常而不是返回-1
字串查詢
{kind=link}
# 字串分割
str = "ABCDABCDABCD"
print( str.split('A'))# 返回元組(元組的元素不可更改)
print( str.split('A',2))# 分割成 i+1份(i為數字引數)在最左邊分割,左側將會產生空串
print( str.split('B',2))# 分割成 i+1份(i為數字引數),分割時去除分隔符
print( str.split('D',2))# 在最右邊元素產生分割無效,有且僅有此種情況保留分隔符
# 字串的分割和替換是資料清洗的基本
字串分割
{kind=link}
str = '123123'
all = []
for i in range(0,len(str),1): # 開始的索引位置 i
for j in range(1,len(str)+1,1):# 子串長度 j ,而且還是字串擷取的有區間點(左閉右開)
# print("i=", i, " ", "j=", j)
if i>=j:
continue
all.append( str[i:j:])
print( all)
print( set( all)) # 可以直接輸出,也可以賦成新的列表
print( all) # 並不對列表的原始資料造成影響
字串生成所有非空子串
{kind=link}
# -*- coding:utf-8 -*-#
Html_content = """<html><head><title> Python</title></head>
<p class="title"><b>Beautiful Soup的學習</b></p>
<p class="study">學習網址:http://blog.csdn.net/huangzhang_123
<a href="www.xxx.com" class="abc" id="try1">web開發</a>,
<a href=" www.ccc.com " class="bcd" id="try2">網路爬蟲</a> and
<a href=" www.aaa.com " class="efg" id="try3">人工智慧</a>;
</p>
<p class="other">...</p>"""
from bs4 import BeautifulSoup # 引入beautifulsoup
soup = BeautifulSoup(Html_content,'html5lib') #
print(1,soup.head) # 頭部原樣
print(soup.head.getText()) # 頭部資料(即內容)
print(2,soup.title) # 標題原樣
print(soup.title.getText()) # 標題資料
print(3,soup.body.b) # 可直接指定標籤類別
print(soup.body.b.getText()) # 標籤資料
print(4,soup.a) # 獲取指定標籤的第一個
print(soup.a.getText()) # 標籤內容
print(soup.a['class']) # 標籤屬性值,若有多個時,同樣是返回列表
print(5,soup.find_all('a')) # findall返回的是列表list
for i in soup.find_all('a'): # list的沒一個元素是一個標籤原樣
print(i) # 標籤原樣
print(i.getText()) # 標籤內容
print(7,soup.select('#try3')) # id
print(soup.select('.efg')) # class
print(soup.select('a[class="efg"]')) # 屬性
# CSS選擇器,可以通過以下3種方式進行查詢
# soup.select('#try3') # id
# soup.select('.efg') # class
# soup.select('a[class="efg"]') # 屬性
# <a href="www.aaa.com" class="efg" id="try3"> 人工智慧</a>
005.Beautiful Soup
例項執行結果(內嵌HTML字串)
{kind=link}
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title> Python</title>
</head>
<body>
<p id="python">
<a href="/index.html"> Python </a>BeautifulSoup的使用
</p>
<p class=”myclass”>
<a href="http://www.baidu.com/">這是</a> 一個指向百度的頁面的URL。
</p>
</body>
</html>
MySoup.Html與mySoupDemoPy檔案處於同一目錄下
# -*- coding:utf-8 -*-
from bs4 import BeautifulSoup
Open_file = open('MySoup.html','r',encoding='utf-8')
Html_Content = Open_file.read()
Open_file.close()
soup = BeautifulSoup(Html_Content,'html5lib')
print(soup.title.getText())
find_first_p = soup.find('p',id='python')
print(find_first_p.getText())
find_all_p = soup.find_all('p')
for i, k in enumerate(find_all_p):
print(i+1,k.getText())
強化理解(處理絕對路徑或同目錄下的Html檔案)
006.requests爬取網頁
007.爬蟲框架爬取網頁
Scrapy
008.selenuim+無界瀏覽器
008.待定
相關文章
- Python基礎——切片例項Python
- C#開發例項大全C#
- css例項整理-練習大全CSS
- 遞迴函式例項大全遞迴函式
- MyBatis基於Maven入門例項MyBatisMaven
- 基於laravel的事件監聽例項Laravel事件
- Python入門基礎知識例項,Python
- 例項總結Oracle知識點大全Oracle
- 基礎python5個例項運用Python
- python socket例項Python
- python例項1Python
- python爬蟲例項專案大全-GitHub 上有哪些優秀的 Python 爬蟲專案?Python爬蟲Github
- 基於NCF的多模組協同例項
- Python例項集錦Python
- python鬧鐘例項Python
- python100例項Python
- python 類和例項Python
- 基於QT錄製PCM音訊例項詳細QT音訊
- Hibernate基於Maven入門例項,與MyBatis比對MavenMyBatis
- 基於SEH的靜態反除錯(例項分析)除錯
- restful風格請求,基於token鑑權例項REST
- python爬蟲之Beautiful Soup基礎知識+例項Python爬蟲
- 基於滴滴雲 DC2 搭建 VPP 應用例項
- 基於svelteKit開發仿微信app介面聊天例項APP
- 關於《完全手冊Excel VBA典型例項大全——透過368個例子掌握》隨書樣例的下載Excel
- python開發例項-python開發案例Python
- Python例項之用Python求完全平方數Python
- Python學習:類和例項Python
- Python專案實戰例項Python
- Python 動態新增例項屬性,例項方法,類屬性,類方法Python
- 基於4G Cat.1的內網穿透例項分享內網穿透
- uni-ttLive:基於uniapp+uViewUI短視訊+聊天直播例項APPViewUI
- 基於大量圖片與例項深度解析Netty中的核心元件Netty元件
- 遷移學習系列---基於例項方法的遷移學習遷移學習
- 零基礎學習 Python 之細說類屬性 & 例項Python
- Python 描述符(Descriptor) 附例項Python
- python例項方法中self的作用Python
- python類例項化如何實現Python