百度熱點大事件搜尋的穩定性保障實踐
在網際網路行業裡,業務迭代很快,系統變更頻繁,尤其長青業務隨著時間會積累越來越多歷史包袱。阿拉丁作為百度搜尋垂直化的產品,業務歷經多年更迭,歷史包袱很多,在應對大事件比如高考、東京奧運會、北京冬奧會的大流量時業務叢集面臨很大挑戰。以高考來說,從2013年開始百度做高考,經過11年的堅持和沉澱,如今高考阿拉丁直接承接使用者搜尋高考相關內容的數十億pv的流量,積累多年的系統因其複雜度而面臨巨大的穩定性風險。為了應對高考等大事件的巨大流量,聯合多方快速建立了保障機制,本文結合實踐做了歸納和總結。
01 保障思路
大事件的流量很大且有很強時效性,在保障時尤其要注意系統瞬時扛壓能力。像每年高考的作文題,總是社會輿論熱點,每個省份的高考查分、分數線公佈的時間點都是瞬時熱度極高。而奧運會這類體育賽事的熱點事件難以預料,有時候是乒乓球半決賽焦灼,有時候是弱勢專案突然奪冠,關注事件的使用者不僅僅是平時活躍的幾百萬運動愛好群體,也有熱點爆發後大量新增關注的使用者,也就導致瞬時流量峰值難以預料,使用者對我們賽事資料的時效性要求也很高,最好的體驗是賽事資料實時更新,這些方方面面匯聚到一起,使得大事件保障比尋常保障工作難度大。常規思路包含3個方面:
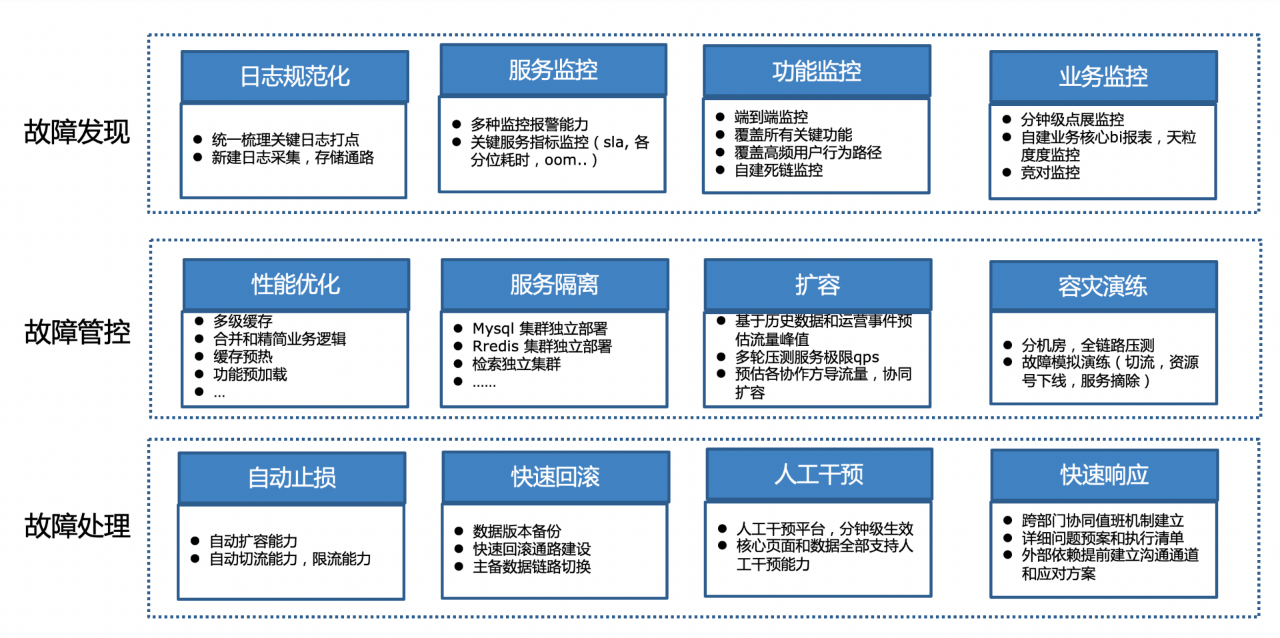
02 故障發現
常規做法首先是詳細梳理業務模型、依賴的上下游、依賴強弱程度、資料鏈路,同時做好隱患排查和修復、日誌的規範這些方面。在大事件保障時,需要針對不同的熱點事件單獨梳理其獨特的依賴鏈路:
(1)上下游負責人,提前通告熱點時間和影響範圍、做好緊急預案。
(2)依賴的功能點,明確熱點事件裡使用者關注的哪些功能點用了哪個業務方或架構提供的哪個能力,在熱點發生前就密切關注流量走勢。
(3)預估不同熱點事件的峰值QPS,根據依賴程度和功能點評估上下游的峰值QPS,提前做好擴容和準備降級方案,預留緊急擴容的資源。
(4)排查不同熱點事件對應的核心功能點的程式碼是否足夠健壯,梳理上下游瓶頸點,做好風險預案、降級預案。
(5)為快速定位熱點事件的業務、資料鏈路故障點,規劃日誌打點,方便構建針對性的業務監控和報警。
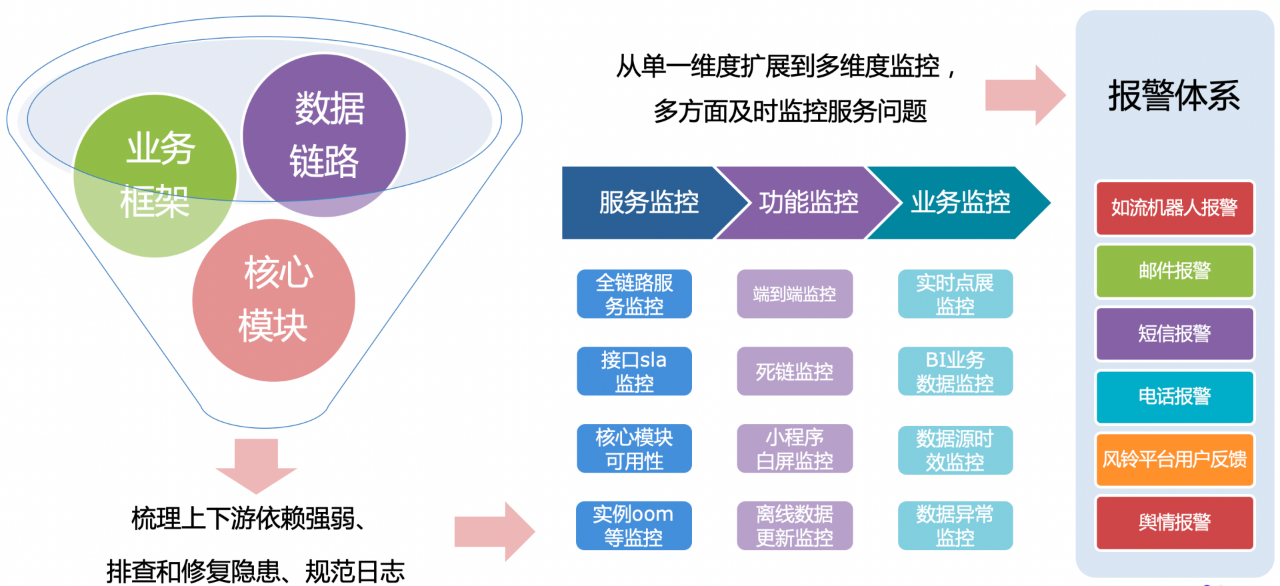
常規保障的第二方面是構建多維度多視角地監控體系,如上圖所示的功能、業務等監控。大事件不僅要做到及時發現故障,更需要快速感知使用者體驗問題,同時能實時關注與官方資料的差異。所以,我們圍繞熱點事件及其核心功能包含的資料時效來設定監控的內容、頻率。從資料來源頭開始設定儘可能短的更新時間,在資料處理過程的各個環節做好異常的實時報警和應對預案,實時監控多地域多機房在端到端效果上的差異,實現了整個資料鏈路的時效感應和保障。
03 故障管控
在做到及時發現故障的同時,還需要做到能有效控制故障影響範圍,也就是故障管控。常規的管控措施包括故障隔離、效能最佳化、問題預案、故障演練。大事件時期,各方面都圍繞熱點事件展開。
(1)故障隔離
在大事件過程中,圍繞熱點事件相關核心模組做故障隔離,包含業務的隔離、還有依賴的各服務的隔離、儲存層的隔離。除了常規的儲存和業務隔離,還針對性地補強了核心模組。
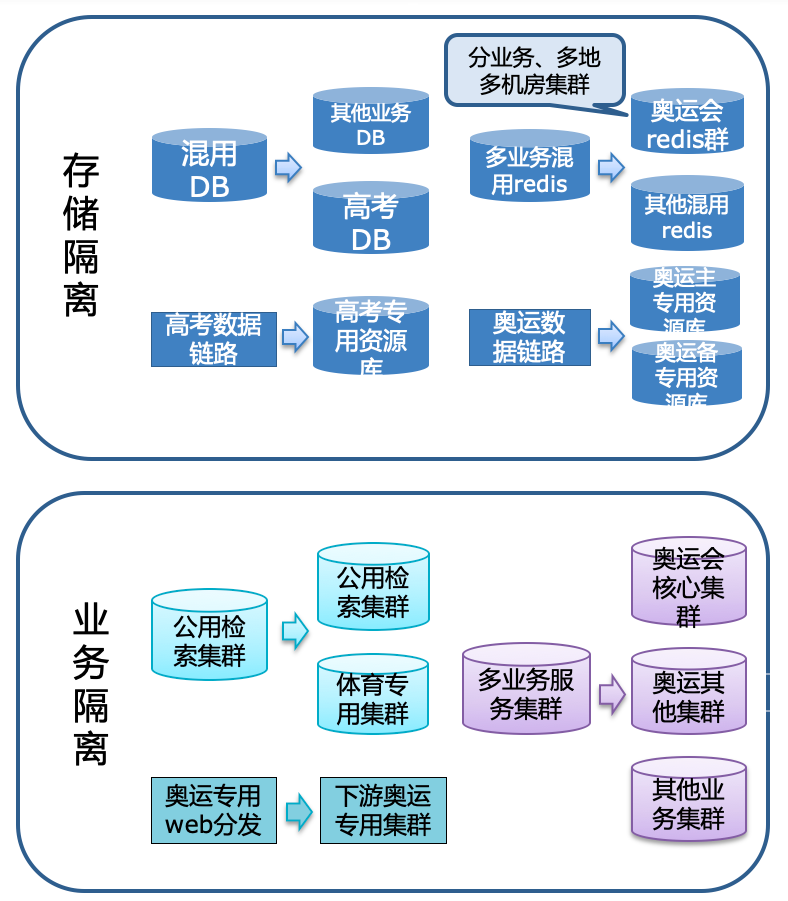
比如奧運會的核心模組預估qps達到數十萬qps,這個流量超出NBA最熱門賽事峰值、對部分服務來說超出2019年百度APP紅包活動的流量,服務叢集乃至相關架構都很難直接承接這麼大的流量,而且核心服務的下游還有流量被放大的特性。為此,我們做了全鏈路多級快取,在核心服務裡利用redis來直接承接流量。考慮到redis在單叢集模式下承擔的流量達不到預估峰值,所以依據業務特點、流量分佈、現有redis叢集效能上限,為奧運搭建了多地多redis叢集來一起承接奧運總體流量。
(2)效能最佳化
當前服務叢集能否支撐大事件峰值流量,依賴的上下游又能否支撐峰值流量?我們要確保這些方面不存在問題,就需要將前面梳理的內容運用起來,透過預估大事件不同熱點事件的峰值流量,評估各服務狀態怎麼支撐預估的流量,對服務鏈路的瓶頸做效能最佳化。
首先基於歷史資料、運營活動安排、梳理熱點事件等評估搜尋鏈路的各模組流量峰值。比如我們預估東京奧運會流量時,發現2016年奧運的資料太久遠、參考性不高,做預估時就參考了2021年NBA等熱點賽事的流量,同時針對奧運業務框架和產品特點分別對各種搜尋場景、前端頁面做了細緻的流量預估。
確定預估的峰值之後,就開始評估服務鏈路上各模組是否需要擴容、需要擴多少,然後在大事件之前做好擴容。擴容的範圍不只是當前服務鏈路,還有各業務協同方的服務叢集。
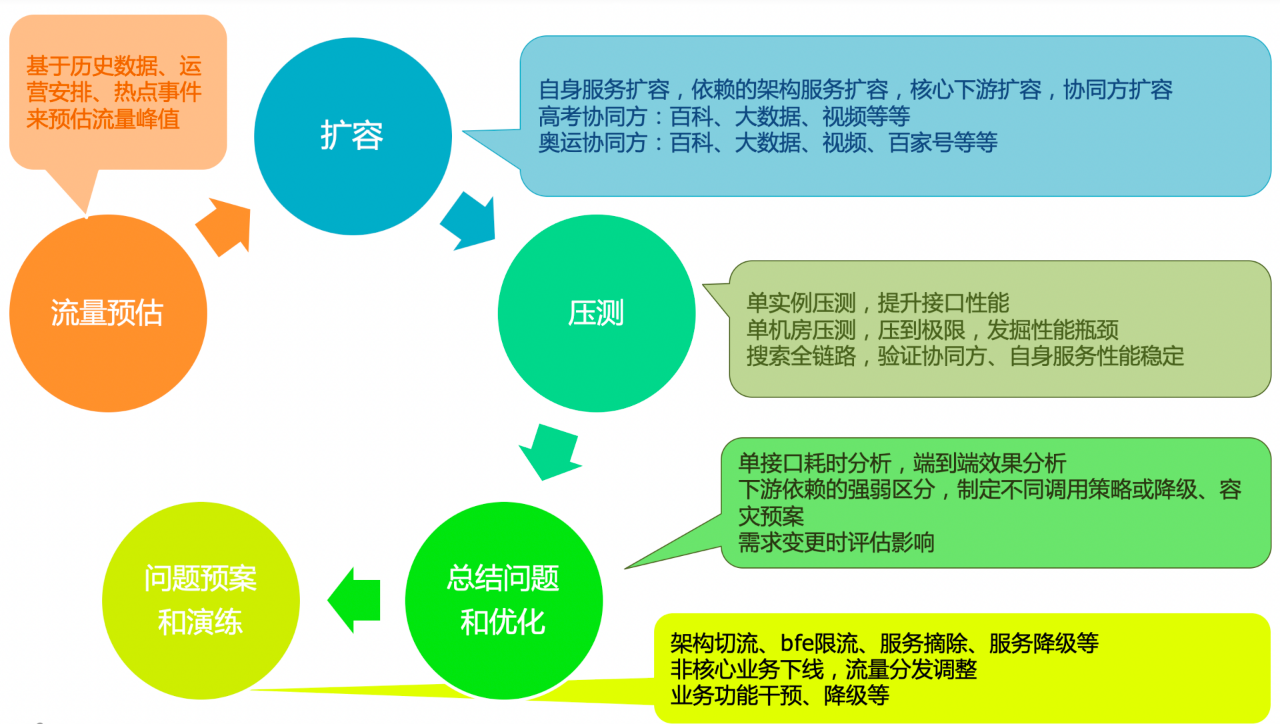
為了驗證擴容後能支撐預估流量,我們根據預估qps做了分階段的多輪壓測,模擬真實流量來進一步排查服務中的風險點,發掘效能瓶頸點。發現瓶頸點後,做核心業務演算法或業務邏輯最佳化、清除冗餘程式碼、業務邏輯瘦身、資料拆分、分級快取等,結合搜尋架構的最佳化一起提升效能。
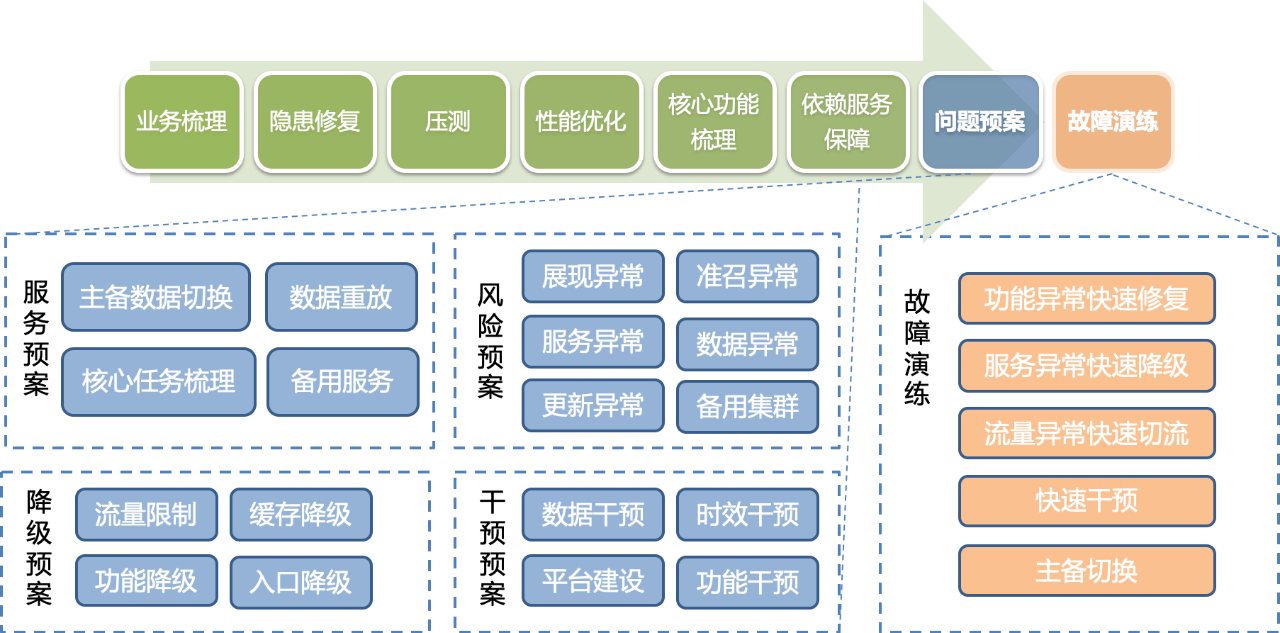
(3)問題預案
透過前面的工作,彙總出不同熱點事件相關服務全鏈路的問題預案,應對系統的各個風險。問題預案包含服務、風險、降級、干預這4個方面,從資料到功能、服務都有針對性的應對措施。
(4)故障演練
梳理完問題預案後,圍繞熱點事件的核心功能做故障注入、故障修復演練,驗證預案有效性和生效速度。
04 故障處理
在做到及時發現故障、有效故障管控後,在大事件過程中還要做到故障處理有效得當。首先要成立大事件快速響應值班群,與服務鏈路各方負責人、協同方負責人提前溝通熱點事件前後的故障響應預案。然後與運維部門合作做好服務叢集運維、故障例項自動下線,在熱點流量突增時隨時根據各方面監控情況做切流、限流甚至是部分功能降級。大事件期間會收到各方面包括使用者的反饋,遇到反饋功能出問題等在前面已經做好了人工干預預案的方面,就可透過干預快速解決。一些人工干預覆蓋不了的問題、一些緊要產品迭代仍然需要開發後上線,這時候快速拉齊協同團隊配合上線。
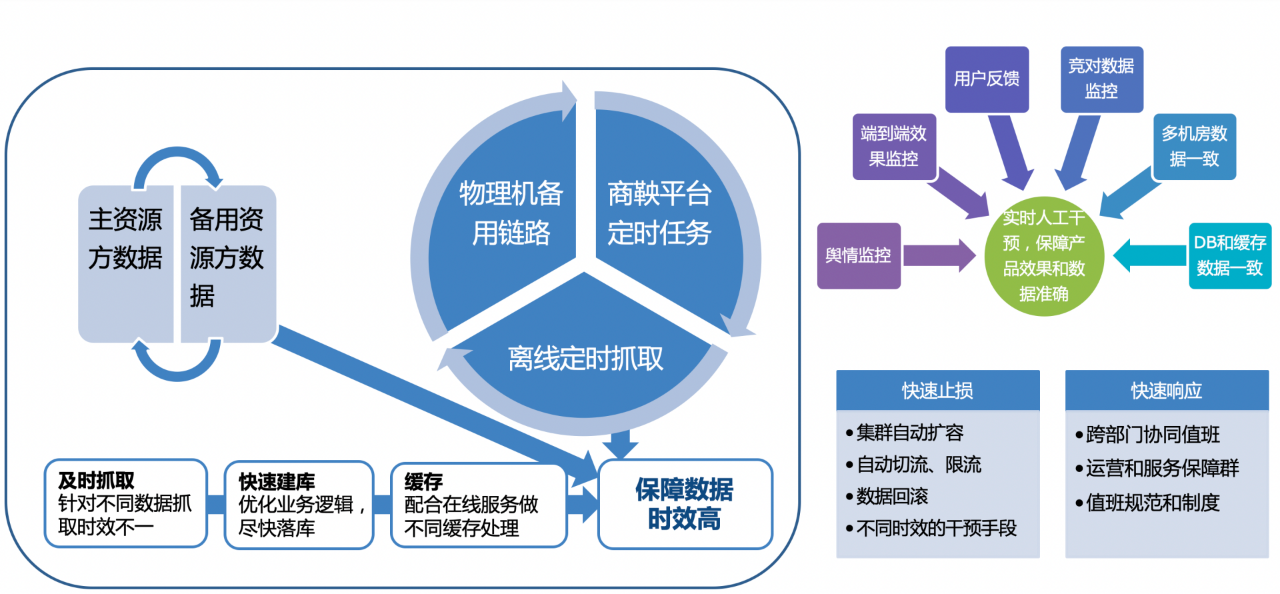
除了上面提到的常規故障處理,我們還要考慮大事件的核心功能特性而制定對應方案。在高考、奧運會、冬奧這些大事件中,資料時效性是使用者最關注的方面,也是產品競爭力的核心體現。除了前面提到的監控和預案,我們準備了主備兩條資料資源方、快速切換並混合使用各自時效性最高的內容,同時搭建3種離線處理平臺、故障時快速切換。我們建立了實時人工干預平臺,根據產品效果監控、使用者反饋、服務監控等各方面指標判斷是否人工干預,最大程度保障產品效果和資料準確。
05 總結與思考
透過上面的舉措,高考、東京奧運會、北京冬奧會期間,搜尋阿拉丁相關服務的穩定性保持在99.99%+,資料更新速度與官方資料幾乎同步,不僅僅保障了大事件的穩定性,還確保了我們的產品有很好的使用者體驗。
搜尋阿拉丁涉及很多服務,面對大事件時需要考慮和準備的方面也很多,本文從故障發現、故障管控、故障處理三方面闡述瞭如何做穩定性保障。大事件各有特點,核心業務服務鏈路也有不同程度的技術負債和改造難點,如果平時業務迭代時就注重穩定性建設,能減少應對大事件的峰值流量而改造的難度。
來自 “ 百度Geek說 ”, 原文作者:百度Geek說;原文連結:https://server.it168.com/a2023/1123/6830/000006830646.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 數十萬QPS,百度熱點大事件搜尋的穩定性保障實踐事件
- 有數BI大規模報告穩定性保障實踐
- 概念解讀穩定性保障
- 研發效能與穩定性保障
- 穩定性保障,如何慢慢放量灰度
- Kubernetes 穩定性保障手冊:洞察+預案
- Kubernetes 穩定性保障手冊 -- 極簡版
- 如何利用 “叢集流控” 保障微服務的穩定性?微服務
- 四個步驟,教你落地穩定性保障工作
- Kubernetes 穩定性保障手冊 -- 日誌專題
- 關閉百度搜尋時的百度熱榜廣告(非常實用)
- Apache Flink 在小米的穩定性最佳化和實踐Apache
- 海量資料搜尋---demo展示百度、谷歌搜尋引擎的實現谷歌
- OpenSergo & CloudWeGo 共同保障微服務執行時流量穩定性GoCloud微服務
- Kubernetes 穩定性保障手冊 -- 可觀測性專題
- 從0到1:億級訊息推送的穩定性保障攻略
- 百度搜尋萬億規模特徵計算系統實踐特徵
- 端智慧在大眾點評搜尋重排序的應用實踐排序
- 使用Google百度等搜尋引擎的常用搜尋技巧Go
- 貨拉拉技術穩定性體系1.0建設實踐
- 這是阿里技術專家對 SRE 和穩定性保障的理解阿里
- Filecoin激勵機制:通過Slashing保障網路穩定性
- Kafka 的穩定性Kafka
- 穩定性
- 從前端程式設計師的視角看小程式的穩定性保障前端程式設計師
- 軟體穩定性測試的測試點
- 大眾點評搜尋相關性技術探索與實踐
- 多利熊基於分散式架構實踐穩定性建設分散式架構
- 前端監控穩定性資料分析實踐 | 得物技術前端
- 前端監控穩定性資料分析實踐|得物技術前端
- 文生圖大型實踐:揭秘百度搜尋AIGC繪畫工具的背後故事!AIGC
- 百度搜尋深度學習模型業務及最佳化實踐深度學習模型
- 雙11在即,分享一些穩定性保障技術乾貨
- 億級搜尋系統的基石,如何保障實時資料質量?
- 點選搜尋框清空搜尋提示文字
- 搜尋引擎分散式系統思考實踐分散式
- 內容社群行業搜尋最佳實踐行業
- 企業如何優化百度熱議?品牌搜尋百度熱議有負面如何壓制?優化