降低彈性雲伺服器成本,聊聊宿主機管理
2020年,機器上線需要在八個服務間反覆橫跳,而且全程手動操作。伴隨滴滴業務規模上雲,彈性雲新增大量物理機,上線操作至少有百次,這時暴露了一個問題:如果按這個速度上線機器,需要大量人力投入到上機器中。因此,彈性雲急需一個平臺來管理宿主的上下線。
從無到有
DevOps,標準先行
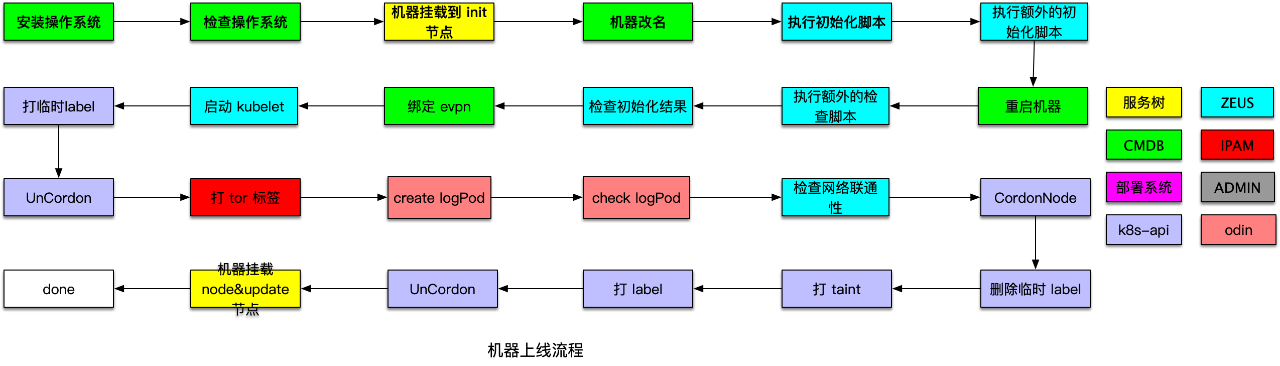
在 DevOps 實踐中,標準化是非常重要的一環。彈性雲的所有機器都是圍繞服務樹管理的。由於之前是由人工管理,彈性雲機器在服務樹上的掛載情況非常混亂。因此,為了機器管理更標準,彈性雲首先定義了服務樹節點標準和規範,將宿主機生命週期與服務樹節點進行關聯。具體而言:
機器上線:機器由 backup 節點掛載到 kube-node-init 節點初始化,然後掛載到線上 kube-node 節點進行報警關聯;
機器維修:線上機器掛載到 maintain 節點進行維修,維修完成掛載 kube-node-init 節點進行上線;
機器下線:容器漂移後,線上機器掛載到 pre-offline.backup 節點進行關機退換。
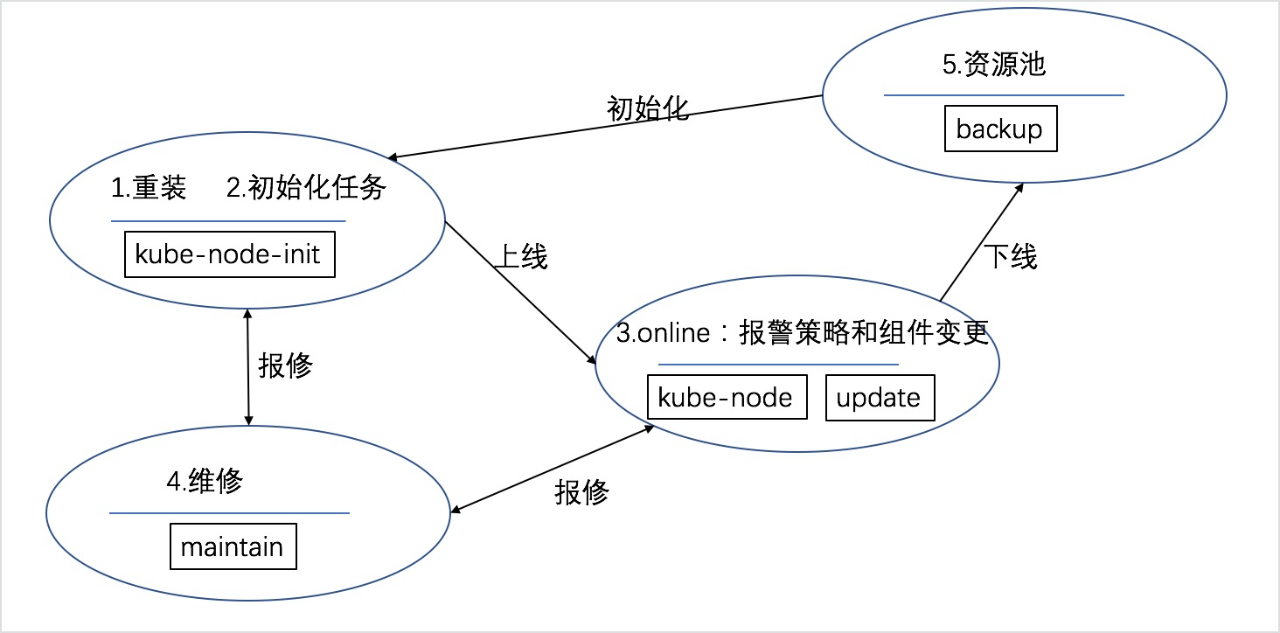
流程拆解,需求分析
標準定義好後,就是對平臺需求進行分析,我們首先將宿主機上線、下線和維修的流程進行拆解,如下圖所示:
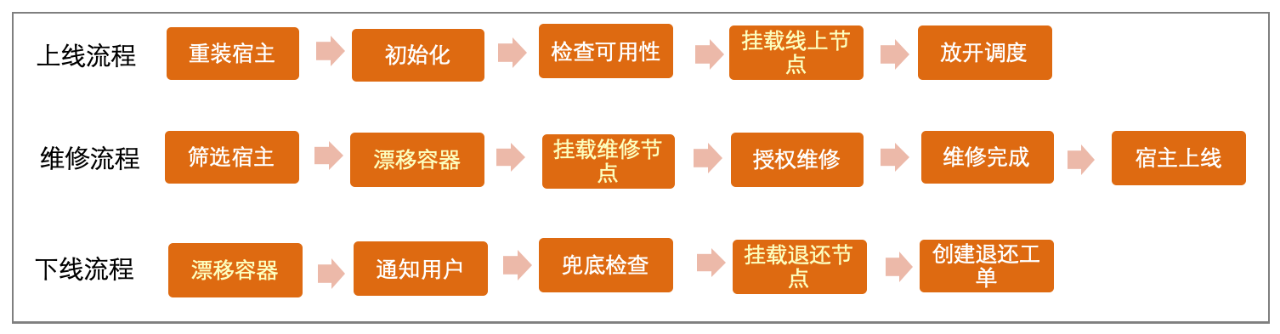
透過分析拆解後的流程,我們得出機器管理平臺至少需要具備以下功能:
整個流程耗時較長且為流式任務,所以任務需要非同步執行。
平臺依賴許多第三方服務,需要支援跳過、重試、暫停等功能,以靈活應對下游異常場景。
各流程之間有重複的步驟,步驟需要能被自由組合,以提升程式的靈活性。
按照 double-check 原則,任務需要以工單形式展現。
架構設計,程式碼開發
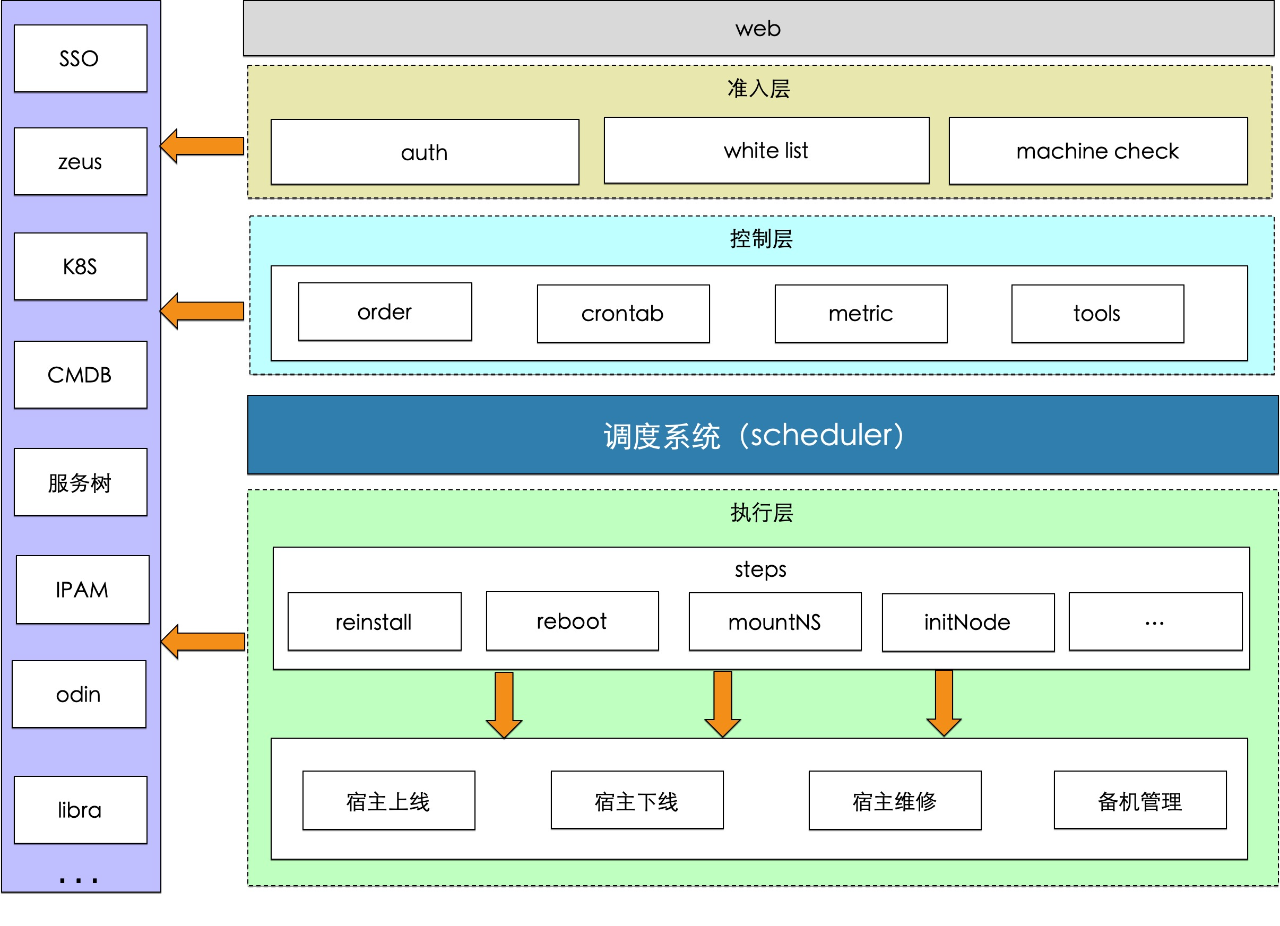
在軟體開發中,程式分層是一種常見的軟體架構模式,它可以使軟體系統更模組化、可擴充套件和易於維護。需求明確後就可以進入開發流程,從平臺的產品形態來看,平臺將來的使用流程是:使用者建立工單,審批透過後使用者執行工單,程式感知到執行動作,執行任務,程式實時反饋任務進度,任務異常時通知使用者,使用者介入處理,任務執行完成後,工單結束。因此,平臺可以分成4層:
准入層:使用者訪問控制,機器准入控制。
控制層:工單控制,工單建立、執行、關閉等。
排程層:任務排程、分發。
執行層:組合步驟,執行任務,反饋狀態。
組內服務大多由 go 語言開發,所以此次開發也選擇了 go 語言。准入層、控制層可以使用常見的 web 框架,排程層和執行層需要一個非同步任務排程框架。
在 go 語言中,優秀的 web 框架很多,但是排程框架卻少得可憐。在對比了幾個框架後,最終選擇了 star 最多的非同步任務框架 machinery。但是在使用過程中發現,雖然 machinery 支援任務流、任務重試等功能,但是對任務暫停、跳過等功能缺乏支援,需要再封裝一些功能。在經歷了一段時間的嘗試後,我發現讀程式碼比寫程式碼要難上許多,再加上 go 原生對併發和非同步支援比較好,最終決定排程層還是自己實現一個。雖然最終的開發週期有所加長,但是程式的可維護性和可擴充套件性會更好些。就這樣,第一版宿主生命週期管理服務 (mmachine) 在 2 個月後上線了。
宿主下線,維修
在第一版宿主生命週期管理中只上線了機器上線的功能,基本上實現了機器上線由人工到無人值守的轉變,但是機器的下線,維修還是由人工支援。
由於歷史原因,彈性雲部分服務間透過容器 IP 進行通訊,所以部分容器無法變 IP 漂移,在機器下線時很難把機器上的容器漂空。人工下線時會把可漂容器漂移走,不可漂容器在聯絡業務側進行服務遷移,從經驗來看,人工 push 業務服務遷移都要花費很長時間,如果透過程式來 push,那效果比人工也不會好太多。
那麼一臺機器,要達到什麼狀態,就認為這個機器可以下線且不會對線上業務造成影響呢?於是我們定義了一個新的標準-1、2、10原則。在機器下線時,對於未漂移容器的叢集進行反查:
當機器存在副本數小於5且非 running 容器數大於1的叢集,機器不可被下線;
當機器存在副本數大於5小於20且非 running 容器數大於2的叢集,機器不可被下線;
當機器存在副本數大於20個且非 running 容器數大於總副本數10%的叢集,機器不可被下線。
機器下線時,首先對機器上的容器進行漂移,在正式下線前對機器進行兜底檢查,在不打破1、2、10原則的前提下,彈性雲會對機器進行關機操作。
得益於排程器設計的靈活性,將機器下線和機器上線的步驟整合後就成為了機器維修的流程(下線-報修-上線),而且機器維修需操作的機器比較明確所以自動化程度也相對較高,幾乎不需要人工介入處理,具體策略如下:
報修:週一至週五每個機房報修 1 臺機器。
上線:每週一、三、五掃描維修完成機器,上線機器。
效率提升
在第一階段彈性雲完成了宿主生命週期管理服務(mmachine)從0到1的建設,機器上線耗時也從天級別縮短到小時級別,但是在服務使用過程中我們發現服務還有很多可最佳化點。
上線流程最佳化
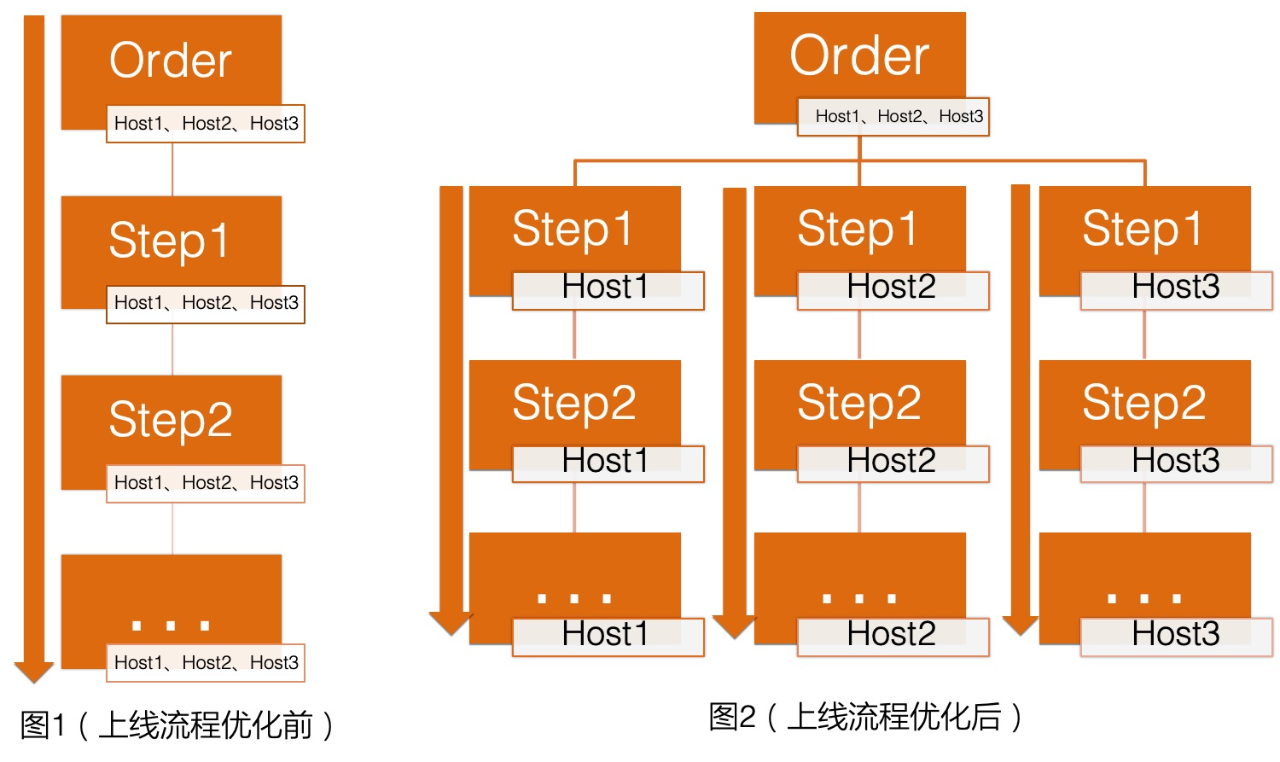
在第一版的機器上線流程中,所有機器都在一個工單中。然而,一臺機器上線失敗將會影響整個工單的進度。例如,如果在上線 100 臺機器時,有1臺機器重灌失敗,那麼其他 99 臺機器必須等失敗機器修復完成才能繼續上線。這嚴重影響了機器上線的效率。實際上,機器上線並沒有相互依賴性,因此可以將上線流程由序列改為並行,以大大縮短單臺機器的上線時間。因此,我們重新設計了上線工單,以減少機器相互影響所帶來的時間消耗。
然而,如果將上線流程改為並行,那麼下游服務也需要支援並行。但在重構過程中,我們發現有兩個關鍵點無法並行處理:
機器上線需要進行重灌,而重灌操作必須在所有機器都完成後才能結單。
上線依賴部署系統來初始化指令碼,而部署系統不支援單模組的併發操作。
因此,我們與系統部門合作,將每臺機器的重灌狀態暴露出來,並將初始化指令碼由部署系統改為使用 Zeus 執行,解決了下游無法並行處理的問題,並將上線流程升級為每臺宿主對應一個任務流,各個任務流之間相互獨立,經過最佳化後,彈性雲的宿主上線耗時由之前的小時級縮短到分鐘級。
備機管理
雖然機器上線的流程得到了極大的縮短,但在真實機器交付的過程中,機器上線只是整個交付過程中的一步。從發現資源不足到機器上到線上的完整流程包括以下幾個步驟:"資源不足->申請機器->交付機器->重灌機器->上線->排程容器"。當線上流量突增時,透過這個流程補充機器無異於遠水救近火。然而,從彈性雲的視角來看,交付流程可以簡化為"資源不足->加入資源->排程容器",只要能提前完成"加入資源"這一步,就能實現分鐘級的資源交付。
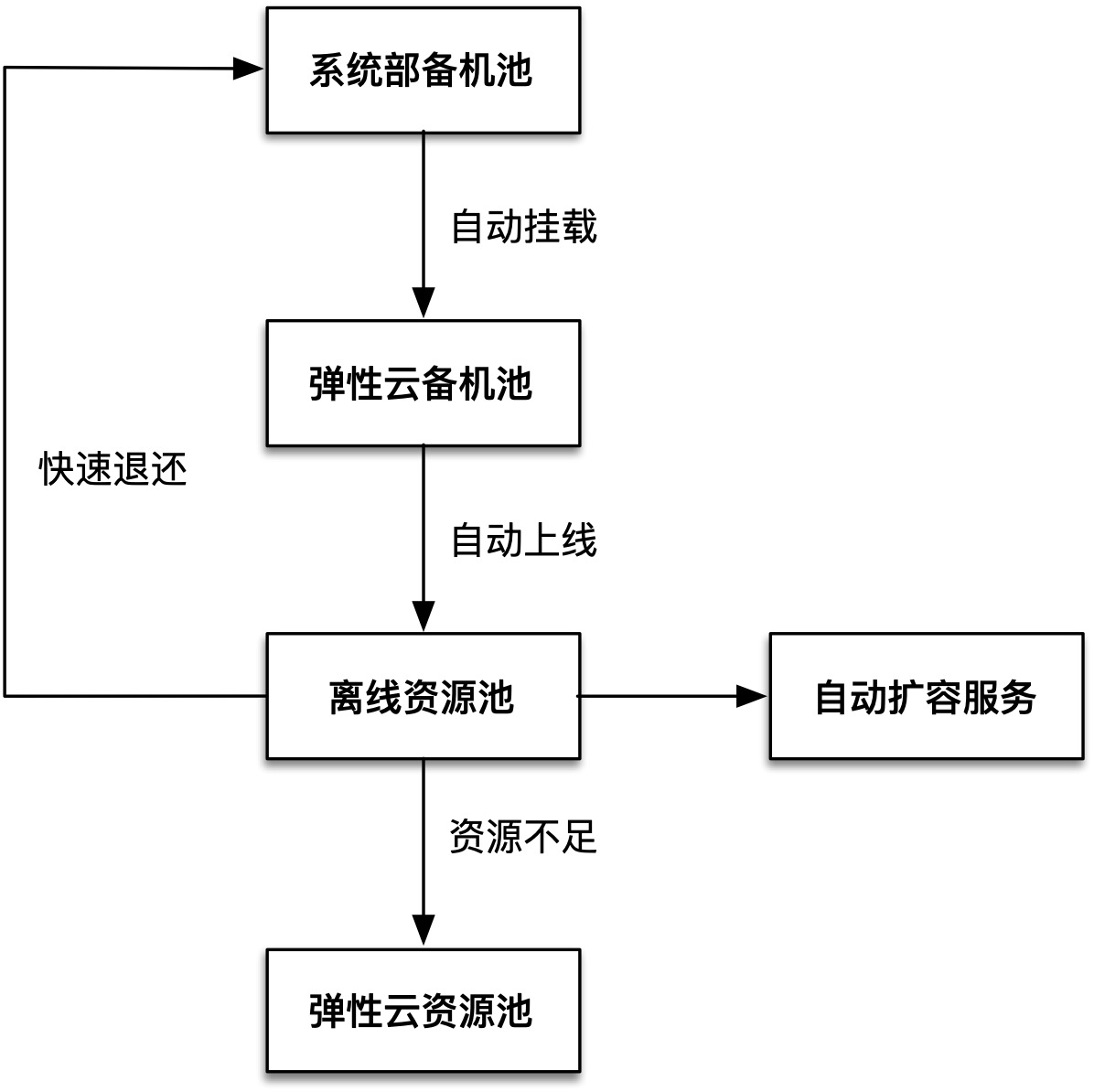
透過分析,我們發現系統部門有部分用於日常資源交付的備機。同時,彈性雲的離線叢集計算資源相對緊缺。離線叢集在彈性雲中屬於隔離叢集,而隔離叢集和公共叢集的本質是透過 Kubernetes 的 taint 特性來控制的。如果備機一直執行在離線隔離叢集中,當線上資源不足時,只需移除備機上的 taint,即可將其加入公共叢集,從而實現分鐘級的資源交付。此外,離線容器對穩定性要求不高,因此當備機需要用於非彈性雲業務線交付時也可以快速退回。因此,彈性雲與系統部門合作開發了備機管理模組,具體功能如下:
自動上線:當備機交付到彈性雲備機池後,它們會被自動上線到離線資源池。離線服務檢測到有空閒容量自動擴容服務。
快速補充:當線上資源不足時,備機管理模組透過修改 taint 將機器轉移到彈性雲的公共資源池中。
快速退還:當系統部門需要備機時,可以快速縮容離線服務並將機器退回。
透過這種方式,彈性雲的容量得到了保障,公司的備機池得到了充分利用,備機的利用率也得到了提升。
雲上管理
隨著雲原生在公司的開展,彈性雲機器管理也迎來了新的挑戰。在 IDC 內,物理機的單次上線數量通常不超過幾百臺,而云上的彈性伸縮每天需要擴縮數千臺虛擬機器。IDC 內物理機的上線頻率、數量與雲上存在顯著差異,而且雲上資源用於承載核心鏈路的流量,因此擴容效率也需要更快。隨著雲上機器數量的增加,問題也逐漸暴露出來:
全流程服務有 8 個下游服務,而不同的下游服務具有不同的限速策略。
機器初始化時間過長,單次初始化耗時超過 5 分鐘。
單次上線超過千臺機器時,工單可能會卡死。
為了解決限速的問題,根據不同限速策略全流程做了最大限度地相容。例如:當掛載的機器超過 200 臺時,全流程會將機器按每組 200 臺進行分組掛載,並確保容器的檢查頻率不超過 10 毫秒/臺。
對於耗時問題,利用雲上的映象功能,將需要部署的服務提前打入映象中。這樣在上線虛擬機器時,無需對機器進行初始化,大大縮短了機器上線的時間。然而,這種情況下的機器上線流程與之前完全不同。得益於排程器最初的設計便利性,我們為雲上虛擬機器上線單獨增加了一套任務流,並將上線流程從 23 步精簡到 10 步,大幅縮短了機器上線的時間。

對工單卡死的問題,透過排查發現瓶頸主要出現在 etcd 和 MySQL 上。在排程器設計之初,為了確保步驟執行的連貫性,排程器會持續獲取未關閉的 MySQL 任務並嘗試在 etcd 上獲取鎖。已獲取到鎖的程式執行任務,未獲取到鎖的任務會不斷嘗試獲取。在高併發情況下,這種模式可能導致鎖丟失。因此,針對任務,我們在資料庫中新增了 isRunning 欄位,用於判斷任務是否已在執行。對正在執行的任務,排程器不再獲取任務列表,也不再嘗試搶鎖。此外,我們對資料庫關鍵欄位新增了索引以減少任務查詢耗費的時間。雖然這樣做會損失部分任務執行的連貫性,但卻換來了穩定性的極大提升。透過一系列最佳化措施,雲上虛機的上線效率也提升到了1.5分鐘/千臺,滿足了日常彈性伸縮的需求。
成本最佳化
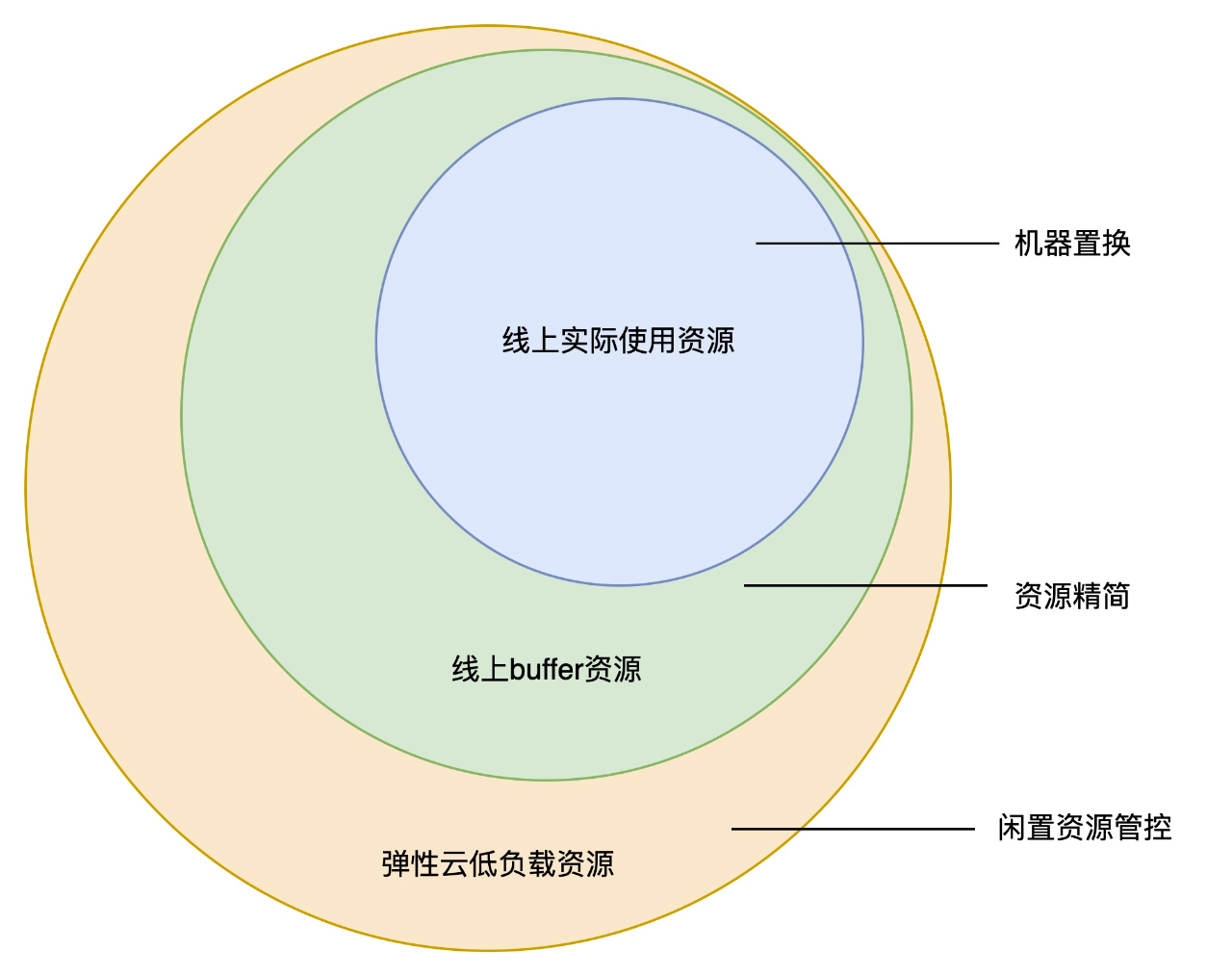
彈性雲成本主要集中在三部分,即伺服器費用、定價服務費用和人力費用。其中,伺服器費用每個月佔了總成本的大部分。為了降低成本,彈性雲可以採取容器治理和宿主縮容等措施來減少伺服器定價支出,並降低對彈性雲平臺伺服器的投入。彈性雲機器資源可分為三類:線上實際使用資源、線上 buffer 資源和低負載(閒置)資源。透過對這些資源進行最佳化,有效降低了彈性雲機器方面的成本。
機器下線加速
經過之前的最佳化,彈性雲機器的上線耗時已基本符合預期。由於機器下線和各業務的穩定性相關,下線耗時仍處於一個較高的水位。隨著各類成本最佳化專案的開展,彈性雲在2023年預計退還大量機器,但根據以往的經驗來看,完全退還這些機器可能需要約2年時間,這個速度顯然無法滿足需求。機器下線耗時較長的原因主要有兩個:
機器下線時需要按機器序列漂移容器,每臺宿主機器漂移容器約需10分鐘,每天最多可漂移50臺機器。
彈性雲存在一些容器無法漂移,並且還存在許多無主容器。在機器下線時,這些無主容器沒有人處理,由於不清楚其影響範圍,這些機器也不能輕易關機。
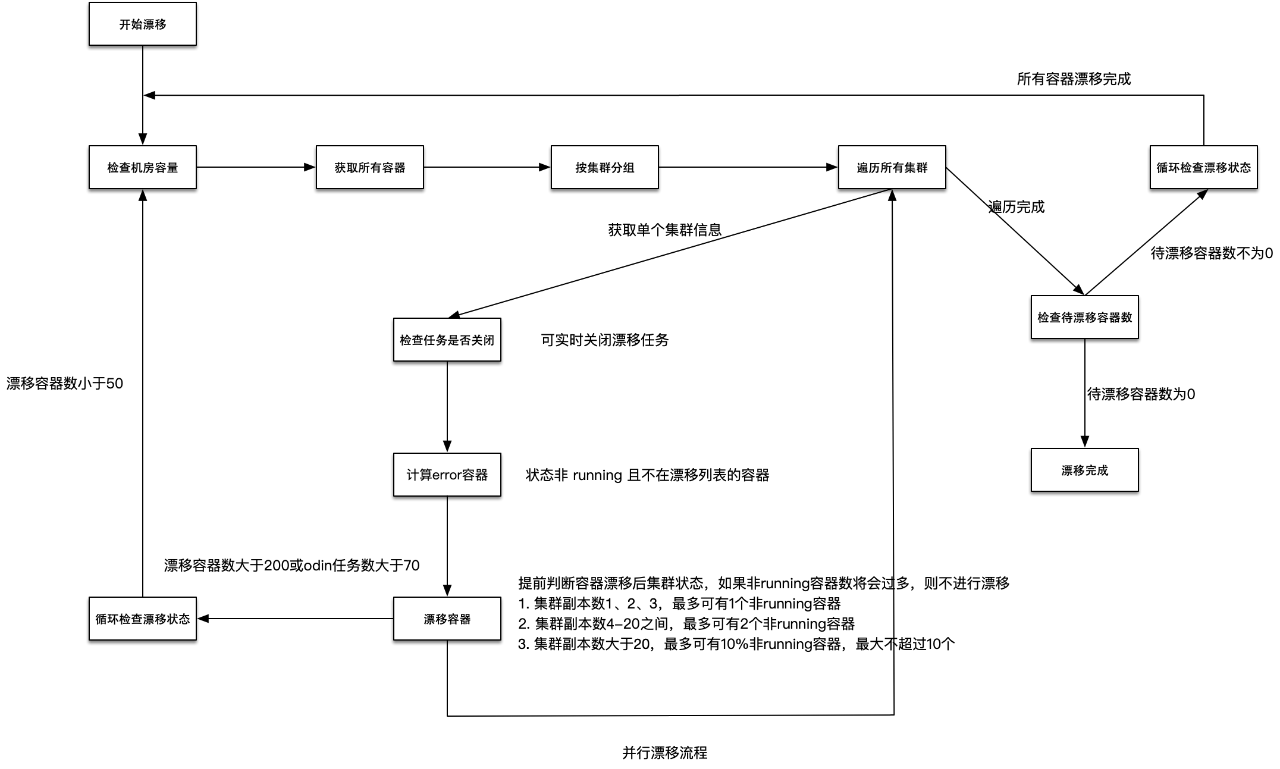
為了提升容器漂移速度,我們對下線流程進行了最佳化。將漂移方式由“按機器序列漂移”改造為“按叢集並行漂移”,在不打破1、2、10原則的前提下儘可能地漂移容器。在確保穩定性的前提下,容器漂移速度由每天50臺提升到了每小時100臺。針對無主容器,我們與 SRE 及各業務線同學合作進行清理,並對長期無人處理的容器制定了下線標準,即:
每天向負責人傳送通知,連續三次通知後,對不符合兜底策略的叢集負責人進行拉群通知。
在拉群通知後觀察一天,對仍未處理的叢集,關閉對應宿主機並觀察三天。
如果在三天內使用者反饋異常,我們將在一小時內對容器進行恢復操作。如果三天後仍然無人反饋,將進行機器退還操作。
透過新的漂移流程和下線標準,可以有效提升彈性雲機器的下線宿主,同時也能確保各最佳化專案的穩定推進。
低負載資源治理
彈性雲2022年低負載時間大於10天的機器存在不少,最佳化低負載機器的數量能降低部分彈性雲成本,低負載資源在彈性雲可分為以下兩類:
預期內低負載:新機房交付還未投入使用、控制面機器利用率較低等
預期外低負載:機器交付忘記上線、測試後忘記退還等原因導致機器處於閒置狀態,部分機器過保、維修後無法上線且未進行置換、退換等。
全流程為此開發了閒置資源管控模組,自動對閒置機器操作人進行通知。指定使用者可對預期內低負載機器進行豁免,而長期未豁免的機器將自動退還。這樣可以最終消化存量的預期外低負載機器並減少新增情況。
總結
在彈性雲的發展過程中,宿主機的生命週期管理是一個重要的問題。最初,機器的上線操作是手動進行的,導致上線速度緩慢。
為了解決這個問題,彈性雲開發了宿主生命週期管理平臺(mmachine)。透過不斷最佳化和改進,mmachine 縮短了機器上線的耗時,提高了效率,並透過定製下線標準、併發漂移等方式,縮短了機器下線週期,在保障穩定性的前提前下,加速退還彈性伸縮、機器置換等專案節省下來的資源。透過自動報修、低負載治理等模組,mmachine 將資源充分利用起來,提升了彈性雲平臺的整體資源利用率,降低了彈性雲伺服器的成本。
來自 “ 滴滴技術 ”, 原文作者:薛繼鵬;原文連結:https://server.it168.com/a2023/1101/6827/000006827362.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 聊聊宿主機管理
- 雲伺服器能降低成本嗎?伺服器
- 【雲成本】降低雲成本三大技巧你知道嗎?
- 雲訊息佇列 Kafka 版全面升級:經濟、彈性、穩定,成本比自建最多降低 82%佇列Kafka
- 彈性雲伺服器(Elastic Cloud Server,ECS)伺服器ASTCloudServer
- 雲上跑容器,如何降低儲存成本
- ECS彈性雲伺服器常用埠、安全組伺服器
- GPU伺服器定製化降低成本GPU伺服器
- 阿里雲Elasticsearch Severless 如何做到成本降低50%阿里Elasticsearch
- 準確估算頻寬用量 降低伺服器租用成本伺服器
- 聊聊所謂的彈性工作制
- 彈性雲伺服器是什麼,大家怎樣租用雲伺服器才可靠?伺服器
- 雲伺服器的“彈性”體現在哪些方面?伺服器
- 華為雲彈性雲伺服器ECS搭建FTP服務實踐伺服器FTP
- AI降成本利器!阿里雲彈性加速計算例項來了,最高節省50%推理成本AI阿里
- 降低雲成本的 N 種方法:終極節省指南
- 電話機器人能降低成本嗎?機器人
- 如何將離線計算業務的成本降低65%——彈性容器服務EKS「競價例項」上線
- 採購管理系統方案:提高採購效率,降低採購成本
- 企業遷移到雲平臺是如何降低成本的?
- 阿里雲專有宿主機(商業化)釋出阿里
- 雲端計算如何避免隱性成本
- web伺服器管理系統 彈性 web 託管例項上部署 DedeCMSWeb伺服器
- 聊聊新手如何挑選雲伺服器?伺服器
- 上海共享辦公,降低企業成本
- 阿里雲專有宿主機日本站(公測)釋出阿里
- 連線多種型別的伺服器降低維護和運營成本型別伺服器
- docker宿主機iptables配置Docker
- 如何用手機遠端管理雲伺服器伺服器
- 阿里雲彈性裸金屬伺服器特性優勢及是否值得購買?阿里伺服器
- 阿里雲專有宿主機國際站(公測)釋出阿里
- 如何通過大資料連鎖經營管理,降低成本?_每日萊大資料
- CRM平臺如何有效降低成本
- 電子元器件供應鏈管理系統:降低管理成本,提升供應鏈系統效率
- 騰訊雲釋出國內首款Serverless資料庫,成本將降低70%Server資料庫
- vps管理 批次管理雲伺服器伺服器
- 阿里雲專有宿主機,構建公共雲上的專有資源池阿里
- 阿里雲端計算型彈性裸金屬伺服器ebmc4雲伺服器配置效能及優惠價格阿里伺服器