容器叢集監控系統架構如何對症下藥?
一、概述
在雲原生的體系下,面對高彈性、拆分微服務以及應用動態生命週期等特點,傳統監控體系如 cacti 、nagios 、Zabbix 等已經逐漸喪失了優勢,難以適用和支撐,對應的新一代雲原生監控體系應運而生,Prometheus 為核心的監控系統已成為雲原生監控領域的事實標準。
之前公司有文章介紹過,Qunar 內部的一站式監控平臺,後端儲存是基於 Graphite+Whisper 做的二次開發,前端控制面是基於 Grafana 做的二次開發。而 Grafana 是支援多資料來源的,其中就包含 Prometheus 資料來源。所以在容器化落地期間最初計劃採用的監控方案也是 Prometheus ,其本身是個 All in One 的系統,擁有強大的 PromQL ,集採集、處理、儲存、查詢、rule檢測於一身,非常易於部署和運維。但每個系統都不是完全能夠契合使用需求的,Prometheus 也一樣不是完美的。
該文章將以 Qunar 容器監控實踐過程和經驗為基礎,講述我們監控體系構建、遇到的挑戰和相應對策,以及對 VictoriaMetrics 的簡單介紹與 Qunar 在過渡至 VictoriaMetrics 後的效果。
二、使用Prometheus的相關問題
Prometheus 是個 All in One 的系統,集採集、處理、儲存、查詢、rule 檢測於一身,這樣做易於部署和運維,但也意味著喪失了拆分元件所具備的獨立性和可擴充套件性。實踐測試摘錄的幾個問題如下:
資料採集量大存在瓶頸,目前 Qunar 單叢集容器指標量級每分鐘將近 1 億;
不支援水平擴容;
只支援 All in One 單機部署,不支援叢集拆分部署;
其本身不適用於作為長期資料儲存;
佔用資源高;
查詢效率低,Prometheus 載入資料是從磁碟到記憶體的,不合理查詢或大範圍查詢都會加劇記憶體佔用問題,範圍較大的資料查詢尤其明顯,甚至觸發 OOM 。
如上例舉的幾項問題點,其實對於大多數公司來講都不是問題,因為沒有那麼大的資料量和需求。但是對於我們或一些資料規模較大的公司來講,每一項都在對我們的使用環境說 No... 我們也對這些問題嘗試了以下解決方案:
使用分片,對 Prometheus 進行按服務維度分片進行分別採集儲存。預設告警策略條件是針對所有 Targets 的,分片後因每例項處理的 Targets 不同,資料不統一,告警規則也需要隨著拆分修改。
使用 HA ,也就是跑兩個 Prometheus 採集同樣的資料,外層透過負載均衡器進行代理對其實行高可用
使用Promscale作為其遠端儲存,保留長期資料注:Promscale是 TimescaleDB 近兩年釋出的一個基於 TimescaleDB 之上的 Prometheus 長期儲存。
但做了這些處理後,其實還是留存問題,也有侷限性和較大隱患:
例如 2 個例項,1、2 同時執行採集相同資料,他們之間是各自採集各自的沒有資料同步機制,如果某臺當機一段時間恢復後,資料就是缺失的,那麼負載均衡器輪訓到當機的這臺資料就會有問題,這意味著使用類似 Nginx 負載均衡是不能夠滿足使用的。
各叢集 2w+ Targets,拆分 Prometheus 後可以提升效能,但依然有限,對資源佔用問題並未改善。
遠端儲存 Promscale 資源佔用極大,40k samples/s,一天 30 億,就用掉了將近16 cores/40G 記憶體/150GB 磁碟。而我們單叢集1.50 Mil samples/s,一天就產生 1300 億左右,而且需求資料雙副本,這樣的資源需求下如果上了線,僅磁碟單叢集 1 天就要耗費 12TB 左右,這樣的代價我們是表示有些抗拒的……
三、接觸 VictoriaMetrics
在為調整後面臨到的這些難點,進行進一步調研,結合 Qunar 自身經驗和需求參考各類相關文件以及各大廠商的架構分享時,我們注意到了 VictoriaMetrics ,並在其官網列出的諸多使用者案例中,發現知乎使用 VictoriaMetrics 的資料分享與我們的資料規模量級幾乎一致,而且效能與資源表現都相當優異,非常符合我們期望需求,便開始了 VictoriaMetrics 的嚐鮮旅程,也歸結出適合我們生產場景的雲原生監控體系架構,並在後續工作中透過使用測試完全滿足我們需求,進行了全面替換使用。
在此,先對 VictoriaMetrics 進行介紹,也推薦給大家對 VictoriaMetrics 進行了解和使用,後面也會貼出我們的使用架構和效果展示。
1、VictoriaMetrics 介紹
VictoriaMetrics (後續簡稱 VM )是一種快速、經濟高效且可擴充套件的監控解決方案和時間序列資料庫,它可以僅作為 Prometheus 的遠端寫入做長期儲存,也可以用於完全替換 Prometheus 使用。
Prometheus 的 Config、API、PromQL,Exporter、Service discovery 等 VM 基本都能夠相容支援,如果作為替換方案,替換成本會非常低。
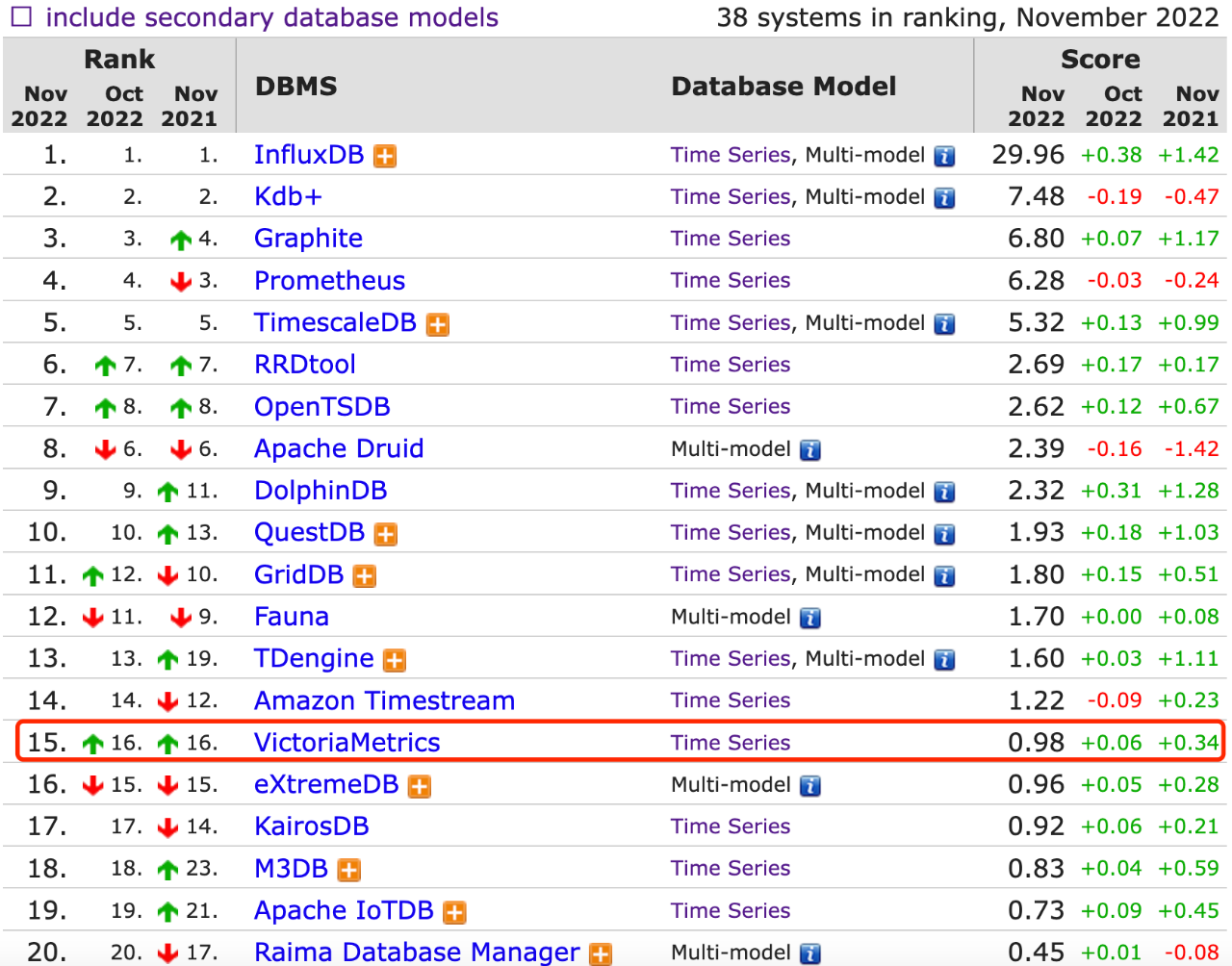
在 DB-Engines - TSDB 的排行中,VM 當前排名為 Top 15,並呈上升趨勢,可見下圖:
2、VictoriaMetrics特點
可以作為 Prometheus 的長期資料儲存庫:
相容 PromQL 並提供改進增強的 MetricsQL ;
可以直接使用 Grafana 的 Prometheus DataSource 進行配置,因為相容 Prometheus API ;
高效能 - 查詢效率優於 Prometheus ;
低記憶體 - 相較 Prometheus 低 5 倍,相較 Promscale 低 28 倍;
高壓縮 - 磁碟空間相較 Prometheus 低 7 倍,相較 Promscale 低 92 倍,詳情可參見 Promscale VS VictoriaMetrics ;
叢集版可水平擴充套件、可資料多副本、支援多租戶。
3、VictoriaMetrics 架構
VM 有兩類部署方式,都非常簡單,如果對 Prometheus 有一定基礎,整個替換過程會非常順滑,這裡就不對安裝進行細述了。
VM - Single server - All in One 單點方式,提供 Docker image ,單點 VM 可以支撐 100 萬 Data Points/s。
VM - Cluster - 叢集版,拆分為了 vmselect、vminsert、vmstorage 3個服務,提供 Operate ,支援水平擴充套件;低於百萬指標/s建議用單點方式,更易於安裝使用和維護。
Qunar 單叢集 Total Data points 17萬億,採用的是 VMCluster 方案。
另外對於指標採集和告警,需要單獨以下元件:
可選,可按自身需求選擇是否使用如下元件替代現有方案。
如果只是將 VM 作為 Prometheus 的遠端儲存來使用的話,這兩個元件可忽略,僅部署 VM - Single 或 VM - Cluster ,並在 Prometheus 配置 remoteWrite 指向 VM 地址即可。
VMagent
VMalert
vmcluster 架構圖
vm-single 特別簡單不做贅述,這裡說下 vm-cluster,vmcluster 由以下 3 個服務組成:
vmstorage 負責提供資料儲存服務;
vminsert 是資料儲存 vmstorage 的代理,使用一致性hash演算法將資料寫入分片;
vmselect 負責資料查詢,根據輸入的查詢條件從vmstorage 中查詢資料。vmselece、vminsert為無狀態服務,vmstorage是有狀態的,每個服務都可以獨立擴充套件。
vmstorage 使用的是 shared nothing 架構,節點之間各自獨立互無感知、不需要通訊和共享資料,由此也提升了叢集的可用性,降低運維、擴容難度。
如下為官網提供的 vmcluster 的架構圖:

vmagent
vmagent 是一個輕量的指標收集器,可以收集不同來源處的指標,並將指標儲存在vm或者其他支援 remote_write 協議的 Prometheus 相容的儲存系統。
建議透過VM Operate進行管理,它可以識別原Prometheus建立的 ServiceMonitor、PodMonitor 等資源物件,不需要做任何改動直接使用。
vmagent具備如下特點(摘要):
可以直接替代 prometheus 從各種 exporter 進行指標抓取;
相較 prometheus 更少的資源佔用;
當抓目標數量較大時,可以分佈到多個 vmagent 例項中並設定多份抓取提供採集高可用性;
支援不可靠遠端儲存,資料恢復方面相比 Prometheus 的 Wal ,VM 透過可配置 -remoteWrite.tmpDataPath 引數在遠端儲存不可用時將資料寫入到磁碟,在遠端儲存恢復後,再將寫入磁碟的指標傳送到遠端儲存,在大規模指標採集場景下,該方式更友好;
支援基於 prometheus relabeling 的模式新增、移除、修改 labels,可以在資料傳送到遠端儲存之前進行資料的過濾;
支援從 Kafka 讀寫資料。
vmalert
前面說到 vmagent 可用於替代 Prometheus 進行資料採集,那麼 vmalert 即為用於替代 Prometheus 規則運算,之前我們都是在 prometheus 中配置報警規則評估後傳送到 alertmanager,在 VM 中即可使用 vmalert 來處理報警。
vmalert 會針對 -datasource.url 地址執行配置的報警或記錄規則,然後可以將報警傳送給 -notifier.url 配置的 Alertmanager 地址,記錄規則結果會透過遠端寫入的協議進行儲存,所以需要配置 -remoteWrite.url 。
建議透過VM Operate進行管理,它可以識別原Prometheus建立的 PrometheusRule、Probe 資源物件,不需要做任何改動直接使用。
vmalert具備如下特點:
與 VictoriaMetrics TSDB 整合
VictoriaMetrics MetricsQL 支援和表示式驗證
Prometheus 告警規則格式支援
自 Alertmanager v0.16.0 開始與 Alertmanager 整合
在重啟時可以保持報警狀態
支援記錄和報警規則重放
輕量級,且沒有額外的依賴
Qunar 的 VictoriaMetrics 架構
按照官網建議資料量低於 100w/s 採用 VM 單機版, 資料量高於 100w/s 採用 VM 叢集版,根據 Qunar 的指標資料量級,以及對可擴充套件性的需求等,選擇使用了 VM 叢集版。

採集方面使用 vmagent 並按照服務維度劃分採集目標分為多組,且每組雙副本部署以保障高可用。各叢集互不相關和影響,透過新增env、Cluster labels進行環境和叢集標識。
資料儲存使用 VMcluster,每個叢集部署一套,並透過 label 和 tolerations 與 podAntiAffinity 控制 VMcluster 的節點獨立、vmstorage 同節點互斥。同一叢集的 vmagent 均將資料 remoteWrite 到同叢集 VM 中,並將 VM 配置為多副本儲存,保障儲存高可用。
部署 Promxy 新增所有叢集,查詢入口均透過 Promxy 進行查詢。
Watcher 中的 Prometheus 資料來源配置為 Promxy 地址,將 Promxy 作為資料來源
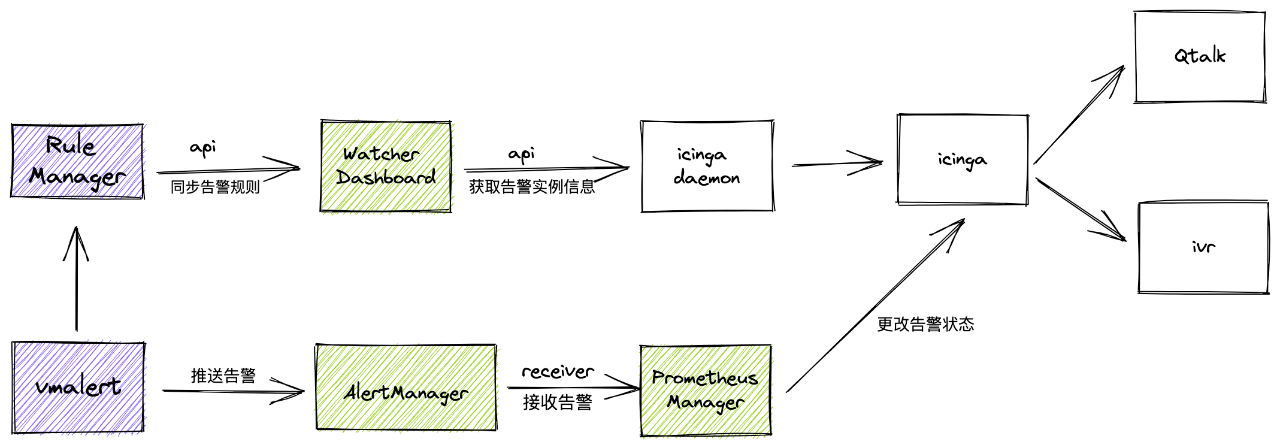
告警方面使用了 vmalert,並在 Qunar 告警中心架構上,Watcher 團隊自研新增了 Rule Manager、Prometheus Manager 兩個模組。
Rule Manager 表示的是 rule 同步模組,將規則同步至我們 Watcher Dashboard ,用於使用者檢視和自定義修改,便於一站式管理。同時也繼續沿用原有告警例項資訊同步 icinga daemon 邏輯。
Prometheus Manager 模組主要是實現了 reciever 介面,接收 alertmanager 的 hook ,然後更改 icinga 的報警狀態。
最後對於 vmalert 本身狀態,則是採用撥測監控實現。於此以最小改動代價融入至 Qunar 現有告警中心。
建議使用 vm-operate 進行部署和管理,它實現瞭如下幾項 CRD:
VMCluster:定義 VM 叢集
VMAgent:定義 vmagent 例項
VMServiceScrape:定義從 Service 支援的 Pod 中抓取指標配置
VMPodScrape:定義從 Pod 中抓取指標配置
VMRule:定義報警和記錄規則
VMProbe:使用 blackbox exporter 為目標定義探測配置
同時預設也可以識別 prometheus-perate 實現的 Servicemonitor 、 PodMonitor 、PrometheusRule 、Probe 這些 CRD ,開箱即用平滑接替 Prometheus 。
完全替換後的表現
Qunar 容器化已將全環境叢集的原 Prometheus 方案全部使用 VM 解決方案進行替換,所有的應用都是使用 VM-Operate 完成部署和管理的。
替換後其中某叢集的資料表現如下:

後續準備做的幾個最佳化
VM 開源版本不支援 downsampling ,僅企業版中有。對於時間範圍較大的查詢,時序結果會特別多處理較慢,後續計劃嘗試使用 vmalert 透過 recordRule 來進行稀釋,達到 downsampling 的效果;
其實很多應用如 Etcd、Node-exporter 暴露出來的指標裡有些是我們並不關注的,後續也計劃進行指標治理,排除無用指標來降低監控資源開銷。
總結
本文介紹了 Victoriametrics 的優勢以及 Prometheus 不足之處,在 Qunar 替換掉的原因以及替換後的效果展示。也分享了 Qunar 對 VM 的使用方式和架構。
使用 VM 替代 Prometheus 是個很好的選擇,其它有類似需求的場景或組織也可以嘗試 VM 。如果要用最直接的話來形容 VM ,可以稱其為 Prometheus 企業版,Prometheus Plus 。
最後,任何系統、架構都並非一勞永逸,都要隨著場景、需求變化而變化;也並沒有哪種系統、架構可以完全契合所有場景需求,都需要根據自身場景實際情況,本著實用至上的原則進行設計規劃。
來自 “ Qunar技術沙龍 ”, 原文作者:王坤;原文連結:http://server.it168.com/a2023/0324/6795/000006795791.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- vivo 容器叢集監控系統架構與實踐架構
- 打造雲原生大型分散式監控系統(四): Kvass+Thanos 監控超大規模容器叢集分散式
- 微服務架構之「 監控系統 」微服務架構
- Docker 容器監控系統初探Docker
- 對症下藥丨數商雲採購管理系統解決方案
- java商城系統架構之第三篇——叢集架構搭建Java架構
- 老闆:把系統從單體架構升級到叢集架構!架構
- 如何用Prometheus監控十萬container的Kubernetes叢集PrometheusAI
- Python對系統資料進行採集監控——psutilPython
- 胡永:聯想集團IT監控體系架構變革之路!架構
- Redis安裝+叢集+效能監控Redis
- 如何優雅地使用雲原生 Prometheus 監控叢集Prometheus
- vivo服務端監控系統架構及演進之路服務端架構
- 系統架構面臨的三大挑戰,看 Kubernetes 監控如何解決?架構
- Linux系統效能監控採集項Linux
- Apache Kafka – 叢集架構ApacheKafka架構
- 對症下藥,快速下載github單個資料夾Github
- 微服務架構下的監控系統設計(一)——指標資料的採集展示 UCloud雲端計算微服務架構指標Cloud
- prometheus監控k8s叢集PrometheusK8S
- 軟體系統的架構演進以及叢集和分散式架構分散式
- 「服務端」node服務的監控預警系統架構服務端架構
- 容器雲多叢集環境下如何實踐 DevOpsdev
- 架構設計 | 分散式體系下,服務分層監控策略架構分散式
- SAP ERP系統:企業數智化發展的“對症之藥”
- 大規模 IoT 邊緣容器叢集管理的幾種架構-0-邊緣容器及架構簡介架構
- 創業公司如何快速構建高效的監控系統?創業
- 用 Weave Scope 監控叢集 - 每天5分鐘玩轉 Docker 容器技術(175)Docker
- 阿里巴巴 Sigma 排程和叢集管理系統架構詳解阿里架構
- 一文讀懂clickhouse叢集監控
- zanePerfor監控系統在高流量專案下的架構配置建議實踐說明架構
- SEO不同行業,對症下藥才能有好的排名!行業
- 一種對雲主機進行效能監控的監控系統及其監控方法
- 基於 K8s 容器叢集的容災架構與方案K8S架構
- 應對複雜架構下的監控挑戰?統一運維可觀測能力是關鍵!架構運維
- ARM架構安裝Kubernetes叢集架構
- AI醫療發展現狀市場掃描 應該如何對症“下藥”?AI
- JAVA架構-使用redis叢集輕鬆應對大併發Java架構Redis
- Centos mini系統下的Hadoop叢集搭建CentOSHadoop