騰訊燈塔融合引擎的設計與實踐
01 背景介紹
騰訊燈塔是一款端到端的全鏈路資料產品套件,旨在幫助產品、研發、運營和資料科學團隊 30 分鐘內做出更可信及時的決策,促進使用者增長和留存。

2020 年後資料量仍然呈爆炸性增長的趨勢,且業務變化更加迅速、分析需求更加複雜,傳統的模式無法投入更多的時間來規劃資料模型。我們面臨一個海量、實時和自定義的三角難題。不同引擎都在致力於去解決這個問題。谷歌等部落格中曾提到,也是我們很認可的一個觀點是以卓越的效能可直接訪問明細資料(ODS/DWD)成為下一代計算引擎的必然趨勢。

下圖展示了燈塔融合分析引擎的整體技術架構:
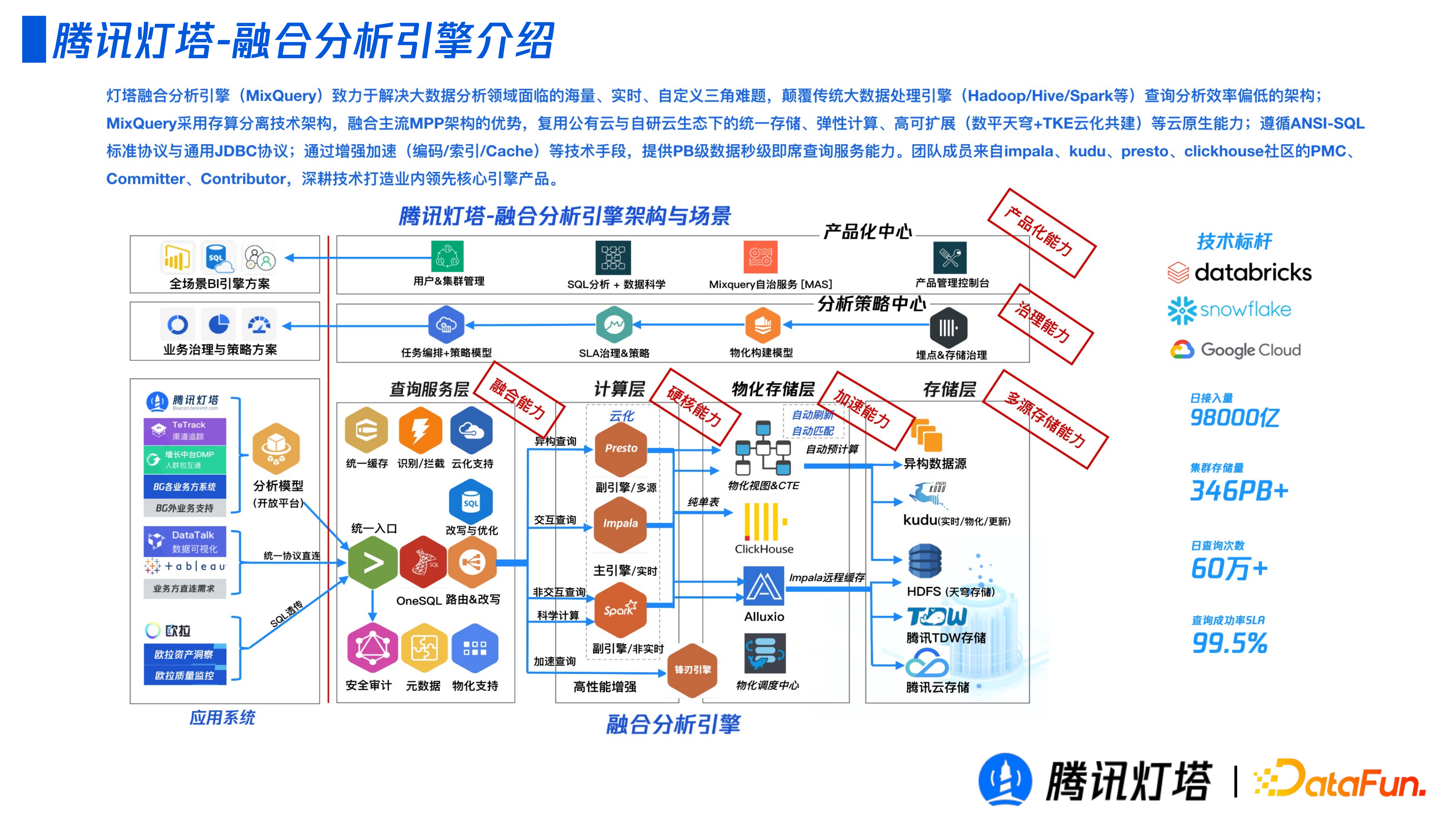
左側對接應用系統,包括燈塔自己提供的分析模型、視覺化方案和一些 API 請求;右側為融合分析引擎,包括查詢引擎層、計算層、物化儲存層、儲存層分析策略中心和產品化中心。
服務層,包括查詢、接收以及治理,比如任務級別的快取攔截等服務相關功能。
計算層,不同於其他公司的自研方案,我們是在開源能力之上做增強和整合,來滿足不同場景的需求。
物化儲存層,其中包含了我們構建現代物化檢視的解決方案,實現了基於 Alluxio 的塊級別快取池,以及針對 BI 場景基於 Clickhouse 的抽取加速方案。
儲存層,對接了多種儲存引擎,包括託管給燈塔的儲存層和非託管的儲存層,即業務方自己的資料。
分析策略中心,位於上述四層之上。主要負責業務方查詢的工作負載中的治理和理解執行的整體鏈路。從一個任務開始執行,到執行計劃的各個階段的計算的資源消耗、儲存的消耗、效率等表徵作統一儲存,並基於這些明細的資料抽出來一些衍生的指標,以推動任務最佳化,比如物化模型的構建和 SQL 自動最佳化,旨在端到端地解決這些問題。
產品化中心,除了燈塔產品套件整體作為產品對外輸出以外,融合分析引擎也可以單獨作為產品對外輸出。
02 挑戰與融合分析引擎的解法
回到前文提到的挑戰,即以卓越的效能直接訪問明細資料,我們會從融合、核心最佳化和加速三個方面發力。
1. 融合
同類產品的思路多為一體化,而本文的思路是取長補短,博採眾長,融合開源社群的能力實現 1+1>2 的效果。
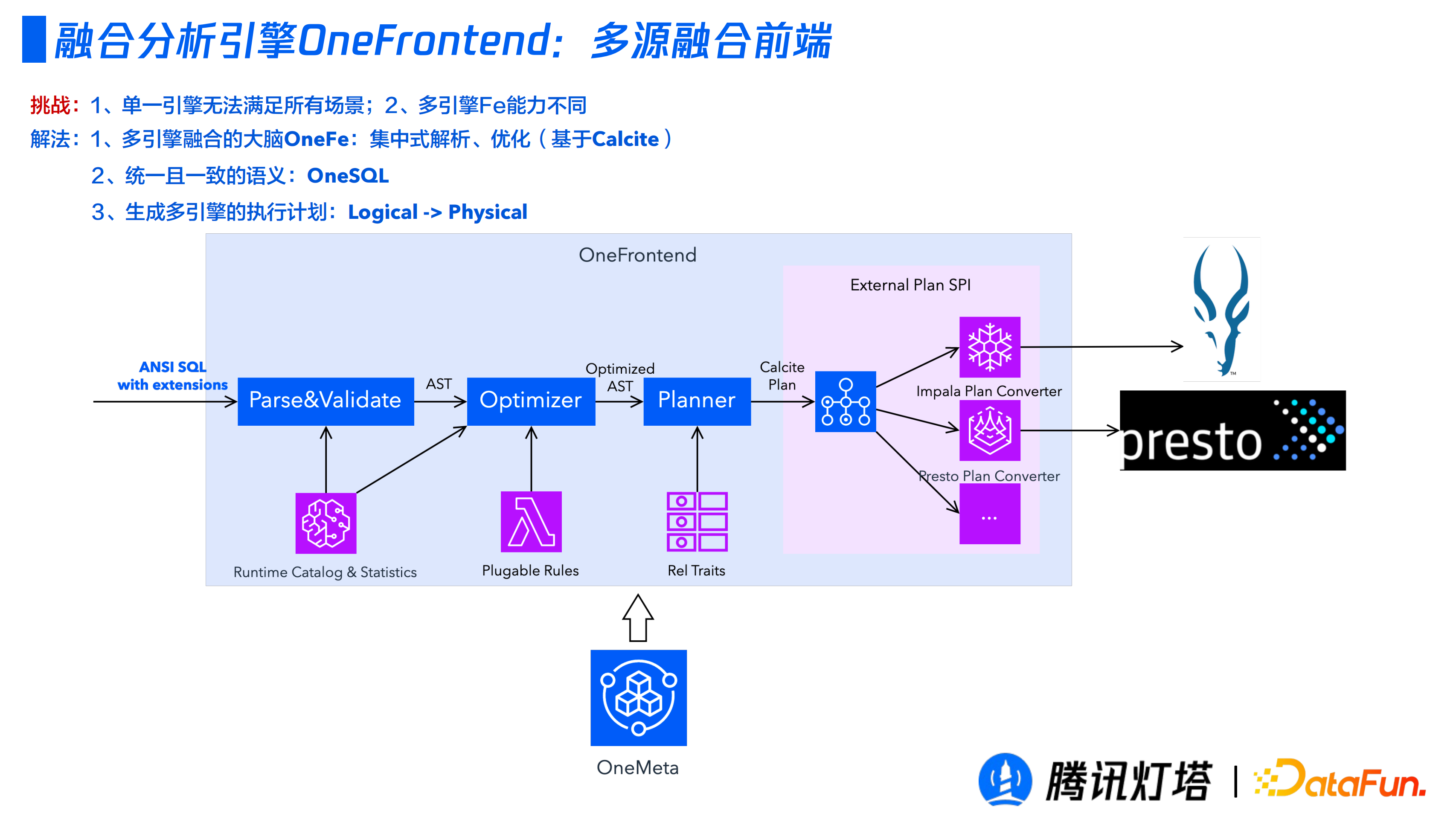
① 多源融合前端
前端聚焦於提供集中化的 SQL 解析、最佳化和執行計劃生成。它更多的承擔的是對各個底層的理解以做出更優邏輯執行計劃的角色。
前端是基於 Calcite 的兩段式。第一段為常規操作,一個 SQL 要經過 Parse、Validate、Optimizer、Planner,透過自建的統一後設資料管理中心來提供了執行時的Catalog和統計資訊以輔助生成更優的執行計劃;第二段為不同引擎的融合,提供統一的對外介面且進行一些定製化的增強。
② 融合後端
前端主要解決的是 SQL 解析和執行計劃的生成最佳化,融合後端真正解決計算層面融合。
RDBMS面臨算力、記憶體不足,無法提高計算並行度;Clickhouse 資料來源面臨複雜查詢效率低等問題。
針對上述問題分別有以下解決方案:
通用 MPP 引擎(Presto\Impala)加上高效能 connector。
增強版 JDBC Connection,基於Mysql表模型對 Split Providers 進行自適應的最佳化,將單個 Table Scan 轉換為多個 Table Scan 以提升計算效率。
針對 Clickhouse 資料來源會將分散式表運算改為基於本地表運算。
對 Projection、Aggregation、Predicate 操作進行下推。

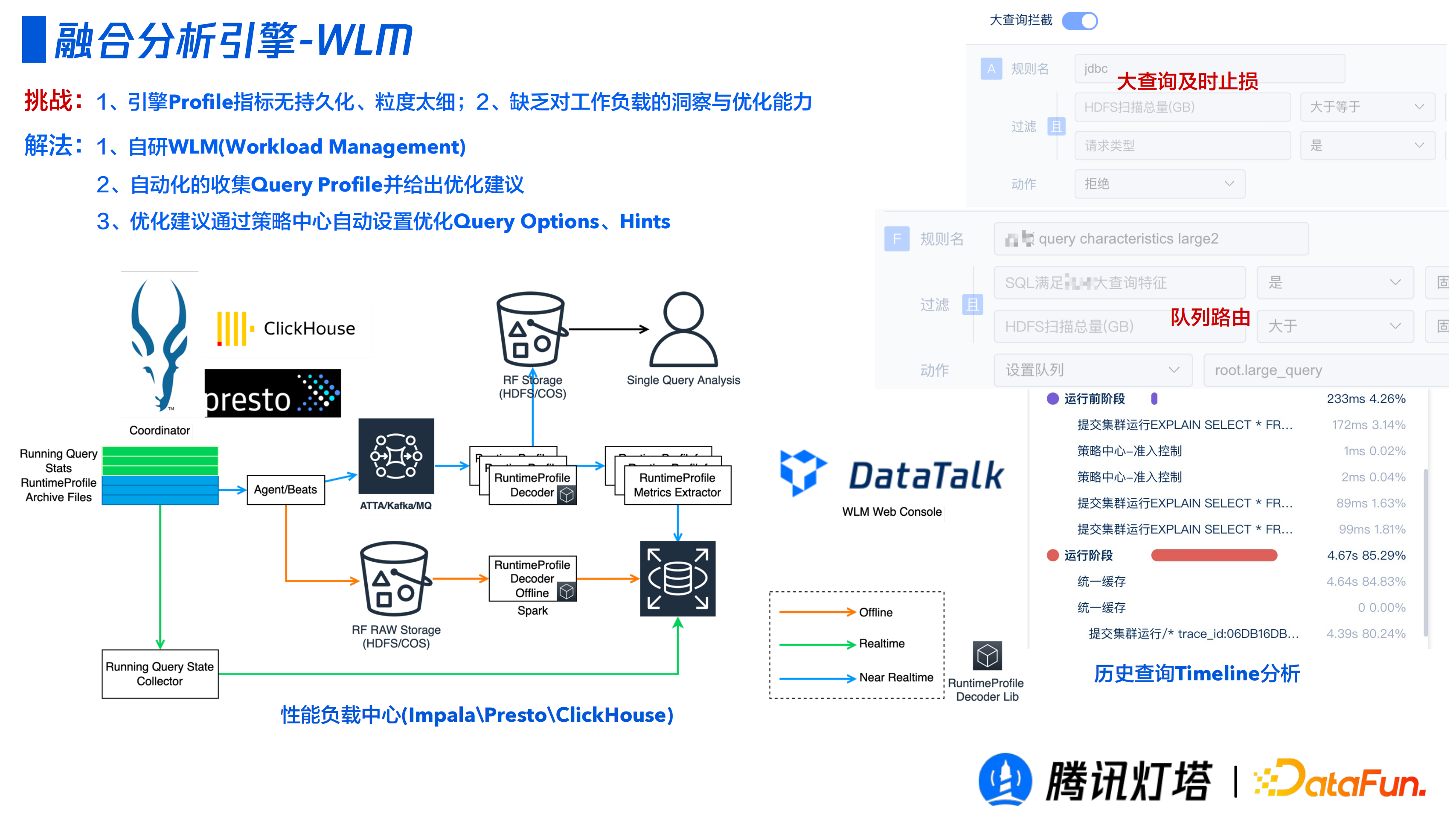
③ WLM(Workload Management)
前端和後端解決的是多個引擎如何融合和配合的問題,除此之外是端到端的分析策略中心的實現。裸用開源引擎存在以下問題:
引擎 Profile 指標無持久化,單點分析粒度太細,無法對租戶整體進行洞察;
對運維人員要求高,需要足夠的工作負載的洞察與最佳化的能力。
本設計的解決方案是透過自研的WLM(Workload Management),自動化收集不同引擎的 Query Profile 並結合歷史查詢給出基於專家經驗給出最佳化建議,在策略中心基於最佳化建議自動設定 Query Options、Hints 等最佳化配置。
透過一系列的規則探查到這個 SQL 會存在大量的 Shuffle,會導致佔用了大量的記憶體和網路資源。該裝置會注入一些 Query Options 和 Hints,比如把它的 broadcast 換成 shuffle join,對於一些 CPU 最佳化器完成不了的事情基於我們的策略做一個自動最佳化,等 SQL 再進來就會有比較好的規劃。
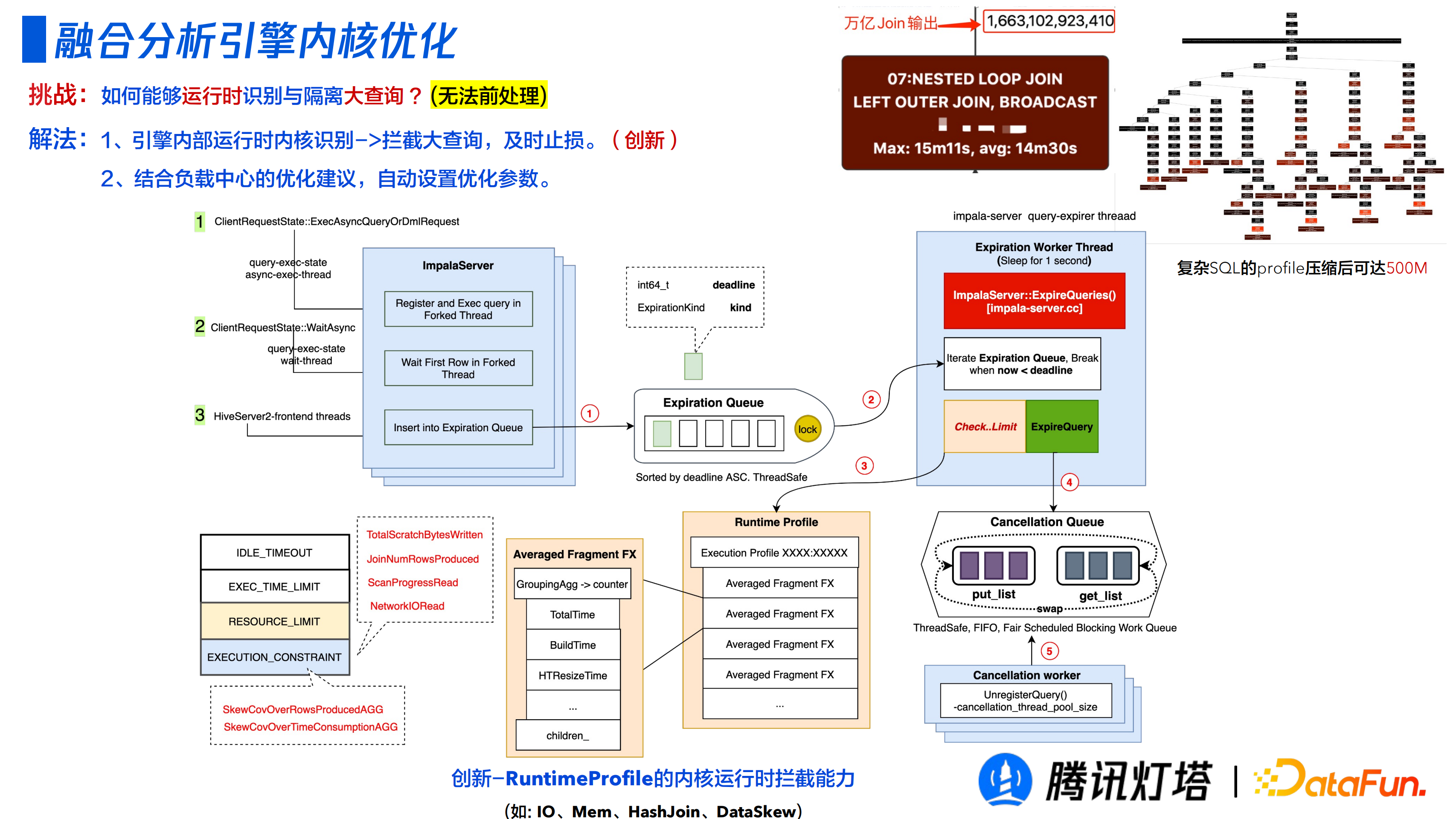
2. 核心最佳化
在商業場景下經常會遇到很消耗資源量的大查詢,如何能夠在執行時識別和隔離大查詢成為一個挑戰。
查詢在執行前是無法斷定其查詢對資源的影響的,比如兩表 JION 後笛卡爾積的導致其輸出有上萬億記錄數的規模。於是本引擎在收集監控執行時的指標引數,結合負載中心的最佳化建議,自動設定最佳化引數,以使得查詢更高效的執行;對於無法最佳化且識別對資源使用有嚴重影響的查詢,會進行攔截,及時止損。
① Impala
Impala 面臨的一個挑戰是如何充分利用計算引擎的索引加速。
引擎 IO 排程核心最佳化,比如區域性性的同檔案多 DataRange 排序;透過調整權重以實現大查詢 IO 懲罰,因為有些場景更多想保小查詢,將大查詢放到慢車道。
儲存特性價值發揮-索引(Pageindex、Zorder、Hillbert)。要高效查詢原始資料,就需要利用好原始資料中的索引,比如 Parquet 中的資料頁 Page Index,可以結合原始儲存資料中的索引資訊,在執行時進行資料過濾。如果要達到很高的效率,往往不是演算法本身,而是底層的資料分佈。比如一個謂詞的列都是隨機分佈,那麼一個值分佈在每個資料頁,就無法進行跳過,我們會透過負載中心檢視歷史查詢去最佳化 Zorder 或者 Hillbert 索引。

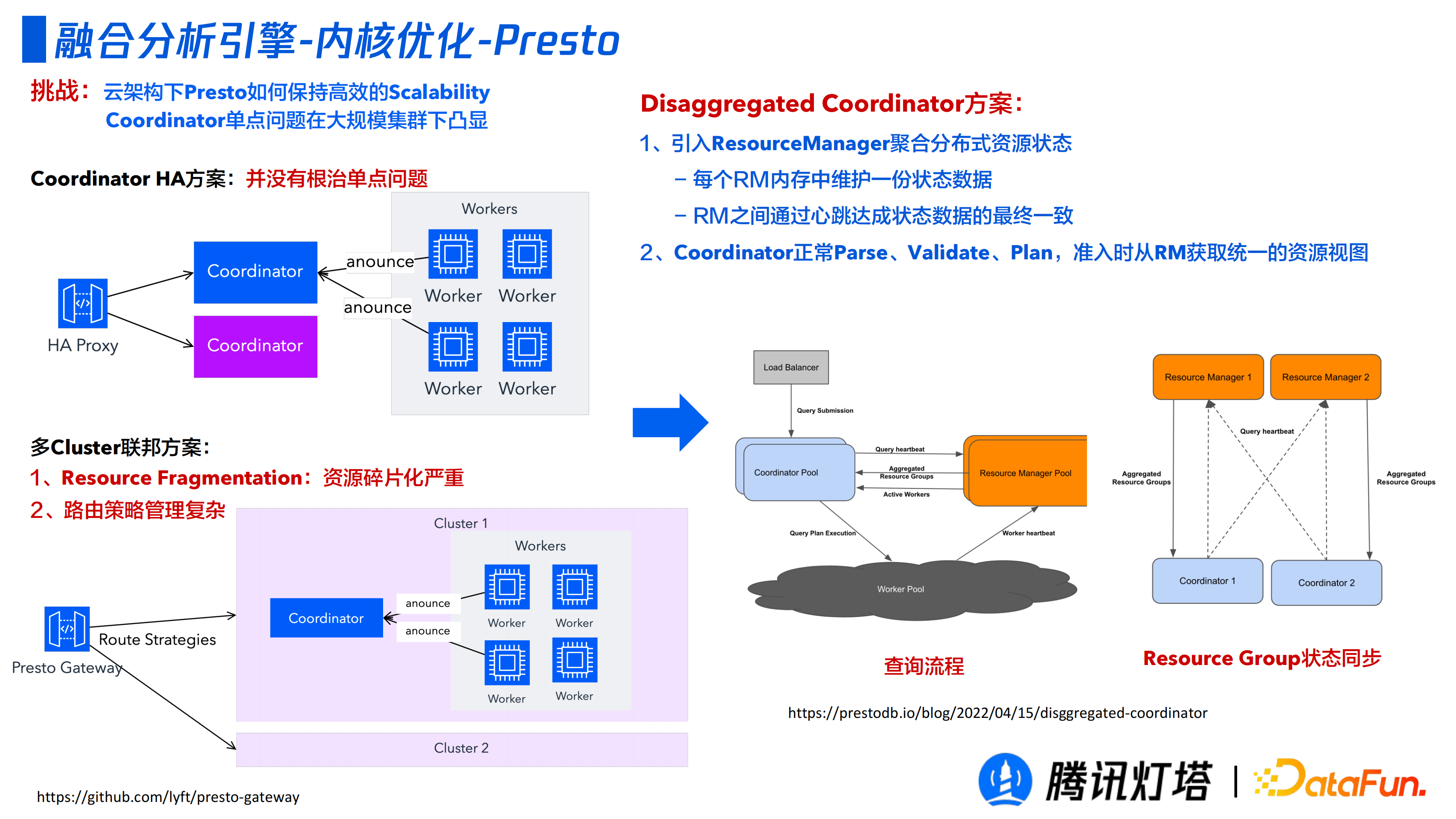
② Presto
雲架構 Presto 在大規模叢集下如何保持高效的 Scalabaility Coordinator 單點問題是一個公認的挑戰,這部分最佳化並非我們獨創,而是業界的一個 feature。
第一種方案是 Coordinator HA 方案,但其並沒有從根源解決問題,一旦 Active 節點失活,過不久 stand by 節點也會掛掉。
第二種方案是多 Cluster 聯邦方案,部署多個叢集,透過 Presto Gateway 路由不同的叢集。但是路由策略管理是一個很大的難點,如果路由策略不當會帶來嚴重的資源碎片化。
第三種方案是 Disaggregated Coordinator 方案,引入了 ResouceManager 聚合分散式資源狀態,每個 RM 記憶體中維護一份狀態資料,RM 之間透過心跳達成狀態資料的最終一致。Coordinator 可以正常的 Parse、Validate、Plan,准入時 RM 統一獲取資源檢視,判斷是執行還是等待等狀態。
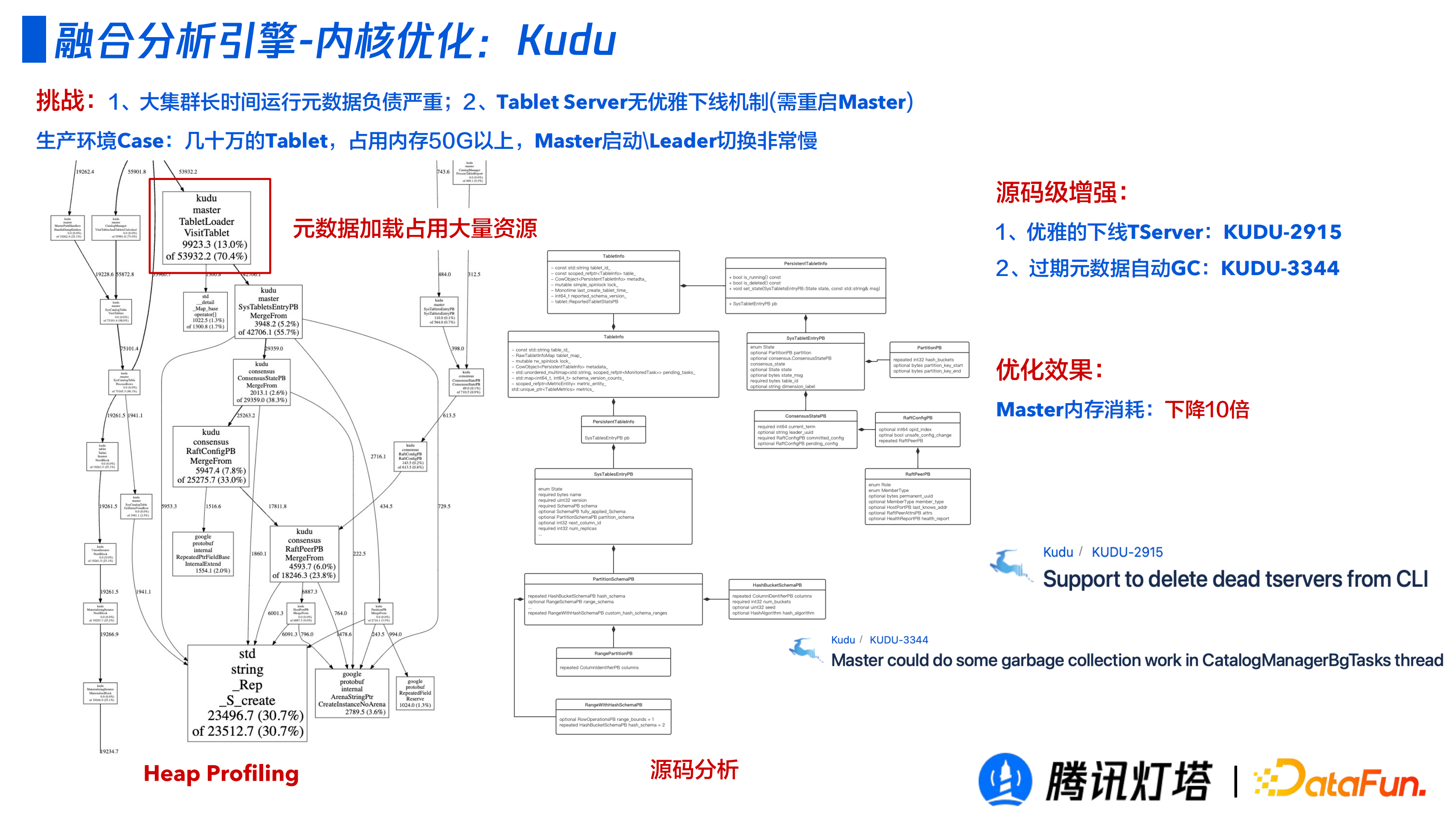
③ Kudu
這是一個不常見的問題,在一個執行很久的大叢集,有一臺機器要裁撤,由於大叢集長時間執行元資訊負債嚴重,導致 Tablet Server 無法優雅下線(需要重啟 master),耗時可能高達幾小時。
在一次實際生產 Case 中,幾十萬 Tablet,佔用記憶體 50G 以上,Master 啟動和Leader 切換都非慢。經排查,叢集一直在載入後設資料,並發現以前刪除的表和資料叢集還在維護。透過原始碼級別的增強,Master 記憶體消耗降低 10 倍。
3. 加速
考慮到叢集的算力和引擎本身的瓶頸上限,除了融合和核心最佳化,我們還需要做各種各樣的加速手段。
除了引擎最佳化,Databrick 商業版的 OLAP 引擎新增了快取層和索引層;Snowflake 支援了物化檢視的能力;Google 的 BigQuery 提供了多級快取,以進一步的加速。快取、計算最佳化、索引與資料分佈、物化、雲化是業界的主攻方向,本次分享主要介紹三種手段。

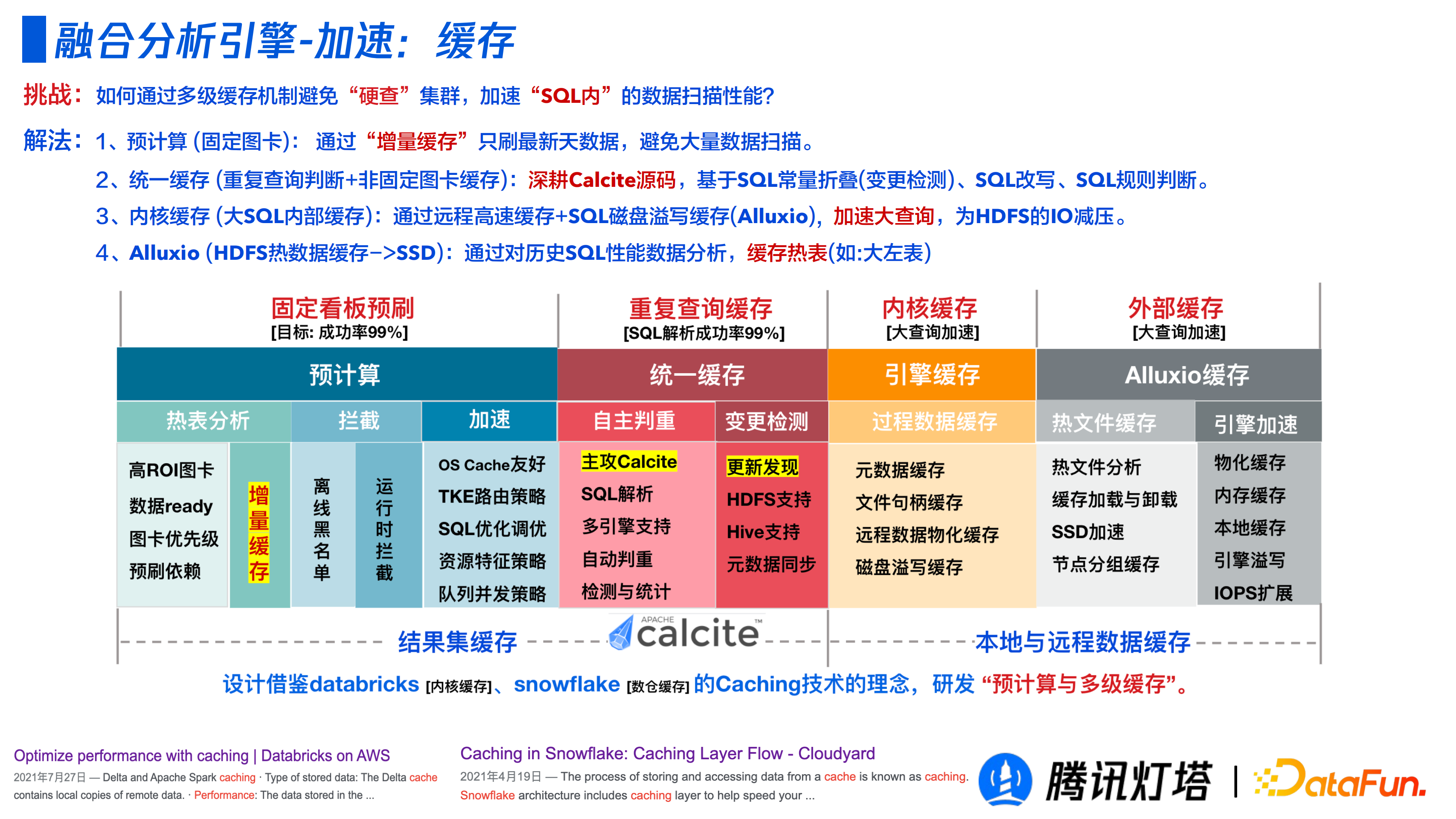
① 快取
實際場景中經常會遇到重複的查詢,我們需要解決如何透過多級快取機制避免“硬查”叢集,加速“SQL 內”的資料掃描效能。該引擎的快取設計借鑑了 Databrick 的核心快取、Snowflake 的數倉快取的快取設計理念,研發了預計算與多級快取的技術。
預計算(固定圖卡):透過“增量快取”只刷最新天資料,避免大量資料掃描
統一快取(重複查詢判+非固定圖卡快取):深耕 Calcite 原始碼,基於 SQL 常量摺疊(變更檢測)、SQL改寫、SQL規則判斷。
核心快取(大 SQL 記憶體快取):透過遠端告訴快取+SQL磁碟溢寫快取(Alluxio),加速大查詢,減輕 HDFS IO 壓力。
Alluxio(HDFS 熱資料快取->SSD):透過對歷史 SQL 效能資料分析,快取熱表(如大左表)。
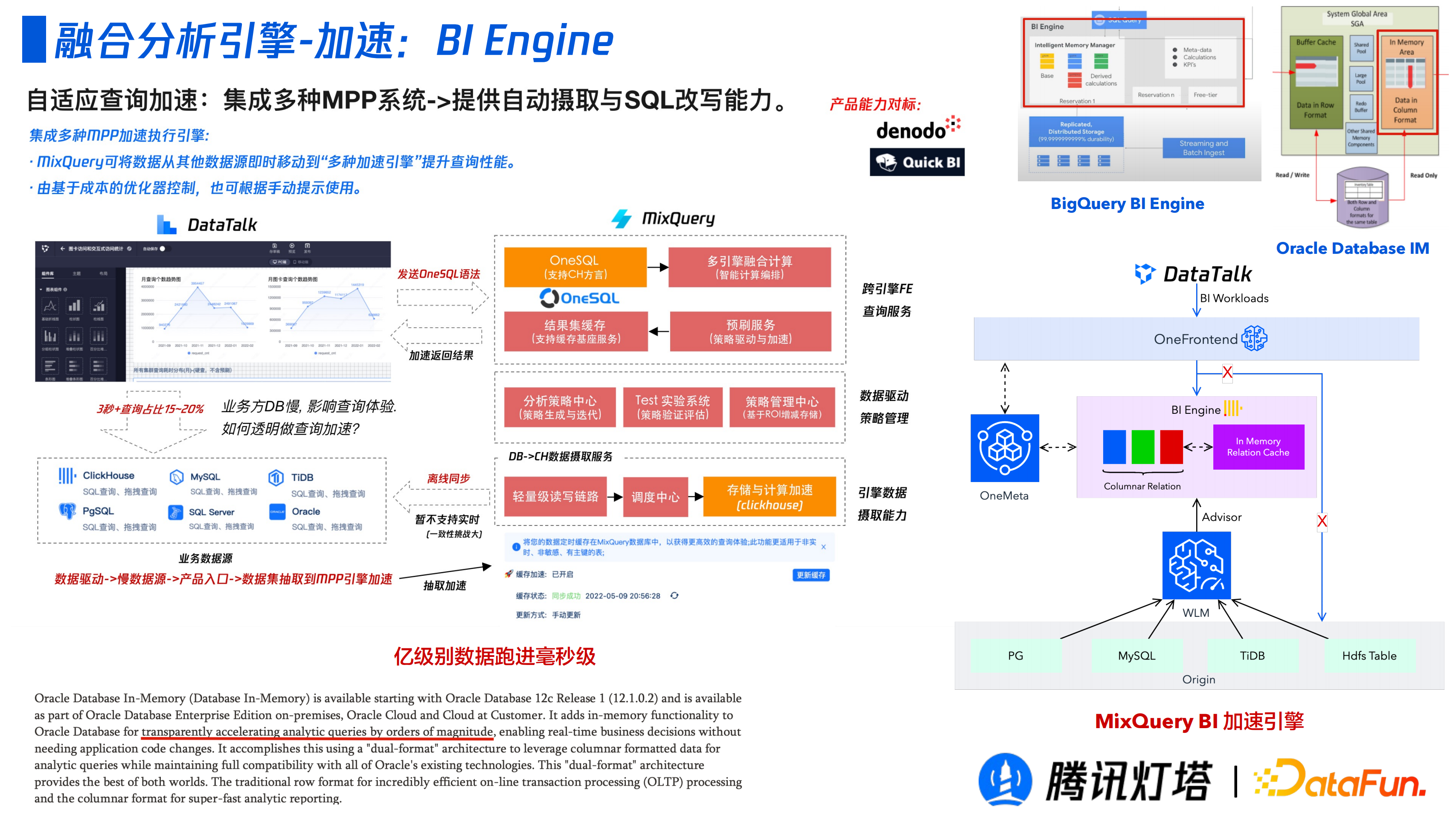
② BI Engine
由於 BI 場景不用其他的查詢分析場景,BI 場景下的看板對出數的時延要求很高,所以需要 BI 場景進行了特殊的最佳化。借鑑以 BigQuery 為例,它是有一塊單獨的記憶體池,它會根據歷史查詢判斷出熱資料並以列式的快取下來。該引擎除了使用到上述的預設策略,還會新增一個 Clickhouse 的快取層,基於歷史記錄判斷那些資料是可加速並透明的將可加速的表移動到 Clickhouse 中作為快取資料。這一整套策略可以讓億級資料執行至毫秒級。
③ 現代的物化檢視
如何更高效利用好物化檢視面臨著三個問題:如何達到用最少成本達到最高效能;如何低成本維護好物化檢視;查詢時,在不改變查詢語句的前提下如何將查詢路由到不同的物化檢視? 現代物化檢視就是在致力於解決上述三個問題。
如何達到用最少成本達到最高效能? 一般方案是做一些領域專家模型。但是對於這樣一個平臺化的產品是無法做到這一點的, 因為業務方才是最瞭解業務的。所以該產品可以依賴端到端的負載中心去歷史查詢記錄來找到最大的公共子查詢來自動的實現物化檢視。同時,還會做一些其他的最佳化,比如新增相應的索引或者 Zorder\hillbert 排序。
如何低成本維護好物化檢視? 增量重新整理物化檢視,並透過負載中心來分析歷史查詢物化檢視是否起到加速的效果,刪除加速效果較差的物化檢視。
查詢時,在不改變查詢語句的前提下如何將查詢路由到不同的物化檢視? 透過基於 Calcite 的自動改寫功能,使用者不需要修改原有的 SQL 語句,SQL 會透明地路由到不同的物化檢視。

03 實踐總結
燈塔融合分析引擎,在 SQL、計算和儲存三個技術領域,做了很多的技術創新和沉澱。下圖列出了重要的最佳化點。

04 未來演進方向
我們未來將繼續致力於從融合、核心最佳化和加速三個方向,解決“以卓越效能直接訪問資料”的問題。
來自 “ DataFunTalk ”, 原文作者:馮國敬;原文連結:http://server.it168.com/a2023/0208/6788/000006788639.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- “全真互聯”時代:騰訊發力數實融合四大引擎
- RedisSyncer同步引擎的設計與實現Redis
- DevOps與傳統的融合落地實踐dev
- 網易考拉規則引擎平臺架構設計與實踐架構
- 騰訊雲操作實踐
- 騰訊安全李濱:騰訊雲資料安全與隱私保護探索與實踐
- 騰訊 iOA 技術實踐
- 微前端的設計理念與實踐初探前端
- Scrum與OKR融合實踐經驗分享ScrumOKR
- 與騰訊雲“直接對話”,用友生態如何為數實融合加力?
- react 設計模式與最佳實踐React設計模式
- RocketMQ Flink Catalog 設計與實踐MQ
- 滴普科技馮森 FastData DLink 實時湖倉引擎架構設計與落地實踐AST架構
- 滴普科技馮森:FastData DLink實時湖倉引擎架構設計與落地實踐AST架構
- 綜合設計——多源異構資料採集與融合應用綜合實踐
- 輕量級工作流引擎的設計與實現
- 最佳實踐 | 用騰訊雲AI人臉融合實現畢業照推廣活動小程式AI
- JavaScript設計模式與實踐--代理模式JavaScript設計模式
- Django RESTful API設計與實踐指南DjangoRESTAPI
- 端遊HUD設計實踐與策略
- 短視訊 SDK 架構設計實踐架構
- Socket網路程式設計基礎與實踐:建立高效的網路通訊程式設計
- 騰訊雲CDB的AI技術實踐:CDBTuneAI
- 有贊全鏈路壓測引擎的設計與實現
- 利他,我們人生的燈塔
- 日誌與追蹤的完美融合:OpenTelemetry MDC 實踐指南
- 如何設計資訊保安領域的實時安全基線引擎
- vivo 敏感詞匹配系統的設計與實踐
- 設計出色API的最佳實踐與原則 - JamesAPI
- 58同城敏捷BI系統的設計與實踐敏捷
- 億級使用者中心的設計與實踐
- 騰訊魔方張樊鈞:玩家自敘事遊戲體驗設計的價值和實踐遊戲
- 騰訊資料治理技術實踐
- 資料採集與融合實踐作業三
- 聲網下一代視訊引擎架構探索與實踐架構
- JavaScript設計模式與實踐–工廠模式JavaScript設計模式
- JavaScript設計模式與實踐--工廠模式JavaScript設計模式
- 服務API版本控制設計與實踐API