滴普科技馮森:FastData DLink實時湖倉引擎架構設計與落地實踐
本文根據馮森在【第十三屆中國資料庫技術大會(DTCC2022)】線上演講內容整理而成。
講師介紹

馮森,滴普科技FastData產品線DLink產品研發負責人,目前負責FastData DLink實時湖倉引擎產品研發工作。曾就職於網易MySQL資料庫核心研發團隊,有近10年資料庫核心研發經驗。
本文摘要:湖倉一體是目前比較火熱的方向,主要解決成本問題和減少ETL,同時可以提升資料端到端可見性。本次演講主要介紹DLink實時湖倉引擎的架構設計和核心功能實現介紹以及DLink在客戶側的落地實踐案例和未來規劃。
演講正文:
DLink架構介紹
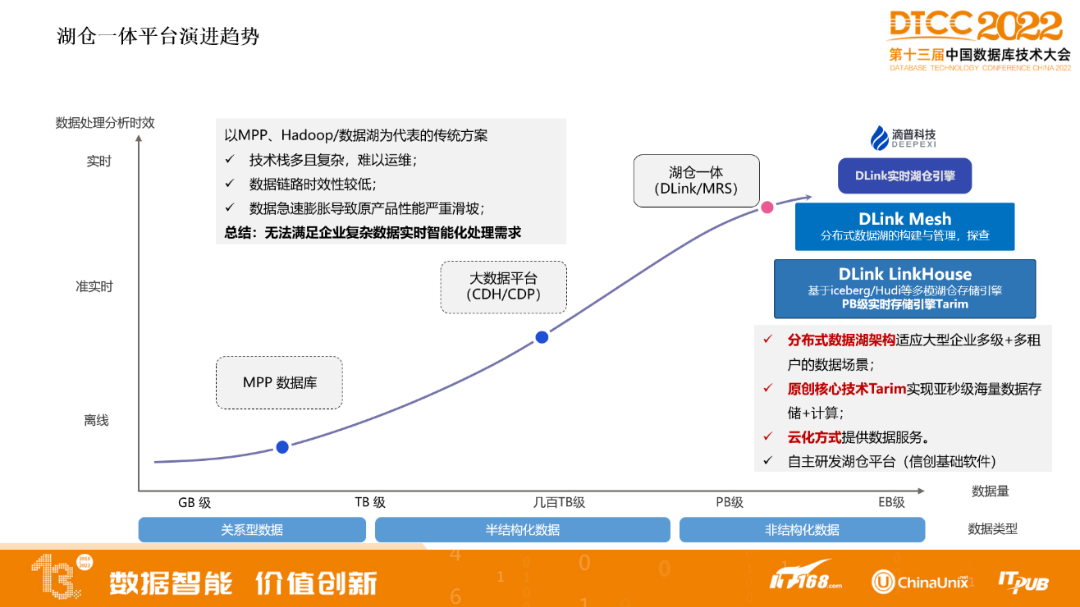
湖倉一體平臺演進趨勢
以MPP、Hadoop/資料湖為代表的傳統方案,存在技術棧多且複雜,難以運維;資料鏈路時效性低;資料急速膨脹導致原產品效能嚴重滑坡等難題,無法滿足企業複雜資料實時智慧化處理需求。
隨著資料量增加以及對時效性要求更高,來到新的架構湖倉一體,湖倉一體能帶來什麼樣的效果?可以從原來T+1增加到T+0,因為湖倉一體基本可以達到分鐘級別的時效性。
DLink還有企業級特性,像多級+多租戶的資料場景,內建了自研的引擎,可以實現亞秒級海量資料的儲存和計算,可以提供雲上服務方式。
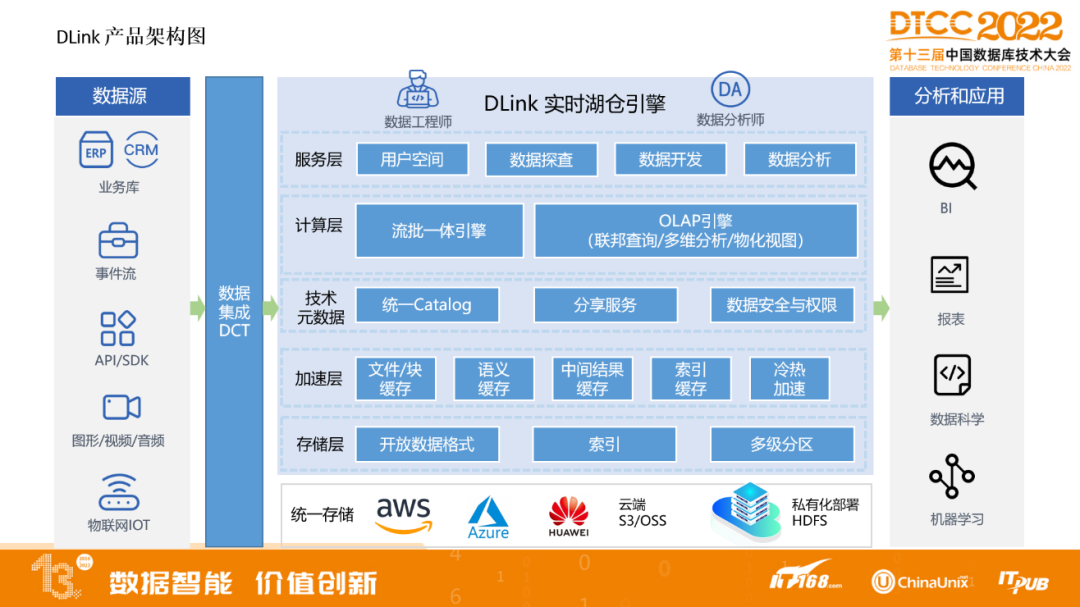
▲DLink產品架構圖
對接不同資料來源,如業務庫、Kafka、API、SDK,還有非結構化資料圖形、影片、音訊,包括IoT物聯網資料,都可以透過我們公司自研產品DCT資料整合工具來把這些抽取到實時湖倉引擎。
DLink支援私有化部署,儲存層支援開放資料表格式,加速層支援資料在記憶體和本地SSD快取,不只有檔案快取,還有中間結果,包括索引、冷熱資料、語義的快取,技術後設資料開發統一Catalog,可以對湖內資料提供統一檢視,對接上層不同引擎,基於技術後設資料可以對湖內資料做資料分享,包括控制一些資料的安全和訪問許可權。再上一層是計算層,基於Flink做的流批一體的引擎,不但藉助於Flink在流處理強大的效能,也同時開發了基於Flink做批處理的SDK,可以被排程引擎做批排程。OLAP引擎支援聯邦查詢,同時因為支援多湖多租戶,可以支援多個資料湖之間的聯邦查詢,包括多維分析、物化檢視功能。再上一層是服務層,支援不同使用者空間,主要可以對不同使用者、租戶做資源隔離,同時支援在產品上進行資料探查、資料開發、資料分析等。這套實時湖倉引擎可以對接不同應用,包括BI、報表、資料科學、機器學習等。

▲DLink實時湖倉架構圖
我們支援這些資料來源匯入到湖內,支援從端到端,也就是從原端資料來源一直到資料可以查到,支援分鐘級延遲。資料入湖之後可以透過Flink做CDC的功能,在湖內構建實時數倉,之後可以透過分析引擎做實時數倉查詢分析。
DLink產品關鍵特性
雲原生架構:雲中立,對接不同雲平臺,支援彈性擴縮容。
支援流批一體:計算上透過Flink做流和批的計算。
多模資料儲存和管理:結構化、半結構化和非結構化資料儲存和管理。
存算分離:計算和儲存資源可以單獨進行擴縮容。
安全和隱私:可以對資料檔案進行加密,像Parquet/ORC等檔案進行加密處理。查詢,查詢時進行掩碼。
統一後設資料管理:透過它來對接湖內不同引擎,也可以對接湖外不同的引擎,比如可以對接湖外的Hive、Spark等引擎,也可以對接湖外後設資料,不同版本可以透過註冊形式連到我們後設資料上。
支援統一資料介面:包括基於分析引擎做分析,在專案空間級別進行資料開發,包括機器學習等。
支援租戶管理:支援不同租戶進行管理,包括空間概覽,目前在湖內有哪些資料,有哪些任務,有哪些異常監控狀態,都可以看到。
資料探查:支援SQL編輯器,可以直接在開發介面上進行查詢、分析。
湖倉管理:因為資料入湖之後可能會產生一些小檔案,我們提供統一後臺服務來自動對這些小檔案進行合併。
實時計算:提供了DLink SQL作業和任務管理能力,包括任務運維監控功能。
資料分析:我們做了一些最佳化,像物化檢視、計算下推,提供更多統計資訊,來提升它的查詢效能。
機器學習:因為底層支援非結構化資料儲存,對外可以對接不同的AI平臺來提供機器學習的能力。同時支援Python對湖內資料的訪問,也支援機器學習的場景。
作業管理:支援多種不同型別作業管理。
DLink核心功能
DLink是基於最核心的三大開源元件做的,比開源社群做了一些優勢功能,也提供給了開源社群。
優於開源Iceberg
BloomFilter索引:在等值查詢和範圍查詢場景下效能大幅提升。
Z-Odrer資料排序:在多維資料分析場景下效能大幅提升。
Hive存量資料快速遷移:支援生成Iceberg後設資料的方式對Hive歷史資料快速遷移,避免資料搬遷。
Iceberg CDC功能:Iceberg透過流讀變更資料構建實時數倉的重要能力。
小檔案自動合併:透過內建合併策略,可以自動進行後臺小檔案合併,快照清理等。
隱藏分割槽/計算列:支援Flink在Iceberg上建立帶有計算列/隱藏分割槽的表。
支援Iceberg維表:支援透過Iceberg儲存維表功能。
優於開源Trino
Catalog熱載入:支援動態載入Catalog能力。
支援Local cache:對IO密集型query進行效能最佳化。
支援多租戶:基於ranger支援多租戶能力。
支援物化檢視:支援物化檢視動態重新整理。
資料加密:支援透過masking的方式對資料進行加密。
資料許可權:支援庫、表和欄位級資料許可權。
支援CBO最佳化:支援基於Iceberg統計資訊進行最佳化執行計劃。
優於開源Flink
UI介面:DLink在UI介面整合了作業提交、管理運維、資料檢視Metrics等能力。
Flink引擎支援多版本:支援Flink1.12-1.14版本。如果客戶正在使用1.15~1.16的話,我們也可以快速進行支援。
流批一體:Flink支援SDK的方式提供被批排程能力。
整庫入湖:支援整庫資料入湖,提升入湖效率。
運算元調優:支援Flink運算元自動調優、運算元拆分、運算元併發。
資料連線:支援豐富的connector。
支援yarn/K8S:Flink支援on yarn和on K8S資源排程。
DLink在開源社群的貢獻
Iceberg社群:PR總數:31個;Contributor總人數:9位;
Hudi社群:PR總數:13個;Contributor總人數:3位;
Trino社群:PR總數:4個;Contributor總人數:2位。
DLink核心功能包括帶來新的效果
Z-Order是一種特殊的將多維資料對映到一維的方法,對於一個二維的查詢條件來說,無論對A還是對B進行範圍查詢,都能至少過濾掉50%的資料量。在多維分析場景效能會有大幅提升。
DLink BloomFilter索引
是基於檔案block級別的索引進行過濾,在10億規模點查產品下進行測試,如果開啟BloomFilterF的話,大概有8倍左右效能的提升。
DLink支援Iceberg CDC流讀Insert/Update/Delete
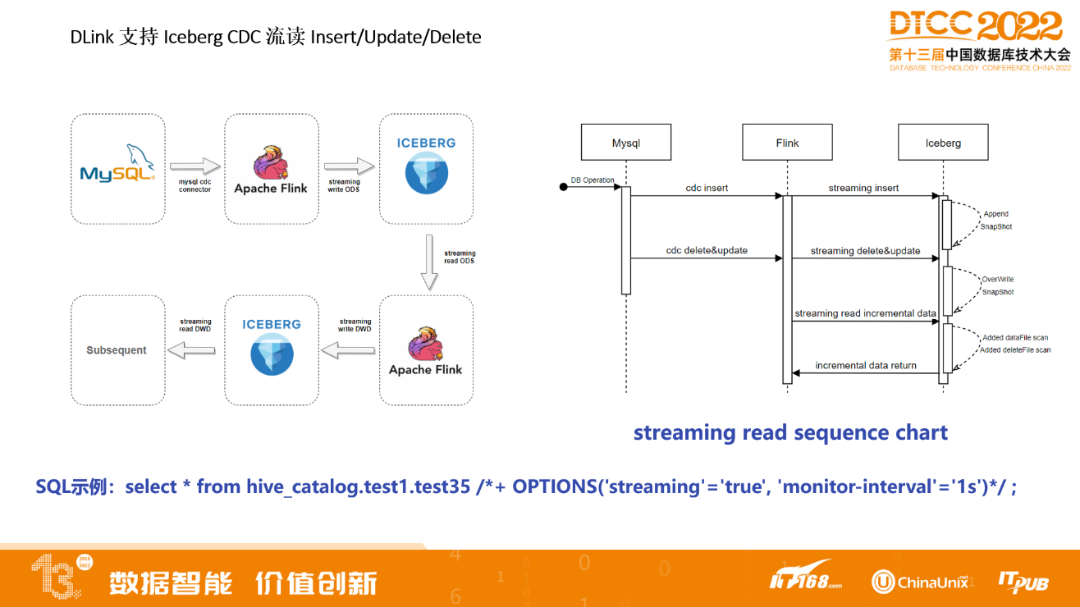
這是一個Flink任務,流讀間隔可以設定1秒或幾分鐘都可以。如果ODS層上資料變更的話,透過流讀在每層數倉進行實時變化,每層1秒,透過4秒,在ADS層就可以查到,效能比較快。如果沒有這樣的方式,每層數倉還要重新跑一遍批。
DLink自動化合並Iceberg小檔案
做了獨立的後臺服務,可以自動對檔案進行合併。Iceberg社群本身也提供了對應的合併介面,透過寫程式方式對應介面進行合併小檔案。把這塊做得更加智慧,讓Iceberg包括DLink可以達到開箱即用目的,就像資料庫一樣,不需要手動或定時觸發合併,客戶無感知,根據他的規則,如快照數量、小檔案數量,來進行自動觸發檔案合併。同時也做了資源隔離和多種任務排程策略。客戶對每張表想馬上觸發,在介面上可以配置,觸發之後,這個策略就會跑到佇列前面,下一個任務馬上可以執行。
DLink Hive歷史資料快速入Iceberg
核心價值:Hive資料可以在不遷移資料檔案的情況下,直接構建Iceberg後設資料,轉換為Iceberg表,並在此基礎上做了效能最佳化,降低了遷移成本。
測試結果:經過多次對比測試,說明資料輕量級遷移任務的執行還是很快速、穩定的。
DLink整庫資料入湖
支援Oracle、MySQL、TiDB等。同時支援整庫多張表和部分表,也支援歷史資料和增量資料一體化入湖,這個任務建好之後,可以對存量和增量資料一起入湖。
支援在入湖過程中如果原庫資料DDL發生變更,增加列或新增表,都可以自動識別、自動同步。
支援並行化入湖。
支援時間戳回溯。
DLink統一後設資料服務

可以相容不同HMS多例項,內建把不同的HMS版本做了大量相容工作。可以透過統一後設資料來控制上面引擎DDL許可權操作,比如哪些使用者不能建表/刪表等。支援基於統一後設資料做租戶和不同Catalog級別的隔離,支援相容不同引擎,對湖內引擎,像Flink、Trino等,都可以對接,Hive/Spark 的話,都可以對接到統一後設資料上,透過外部引擎也可以訪問到湖內資料。好處是客戶基於CDH/CDP做業務處理的話,基於Hive、Spark業務,這些就不需要改了,直接可以非常順滑遷到DLink上。
DLink資料許可權控制
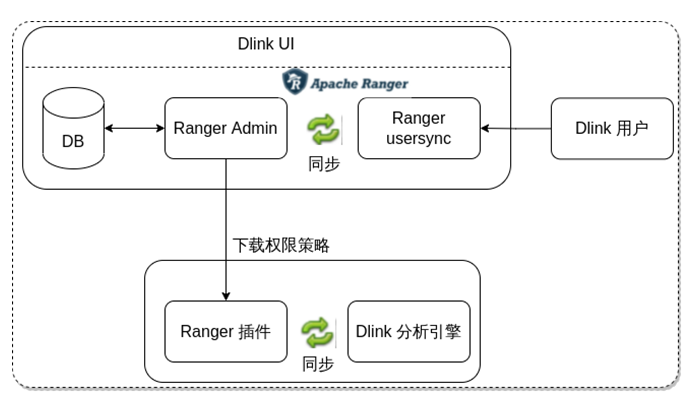
目前做到分析引擎查詢時,可以設定許可權,比如庫表列,設定好策略之後,存到Ranger,透過策略下載,直接可以控制對應後設資料的查詢能力,能控制到查詢哪些資料。也可以跟目前大資料體系做許可權打通,如果客戶原來也是基於Ranger來做的話,可以透過DLink進行統一管理。
DLink Trino支援批處理和容錯機制
容錯執行是Trino中的一種機制,它使叢集能夠透過在發生故障時重試查詢或其元件任務來減輕查詢故障。支援Query和Task級別重試,同時基於Tardigrade 實現了強大的批處理能力。
DLink支援物化檢視
物化檢視的全量重新整理很慢,其次當我們對物化檢視關聯的表進行dml操作的時候,資料會進行變化,但是物化檢視無感知,導致物化檢視查詢的結果可能不是最新資料。定時重新整理的好處在於我們重新整理之後,把表的資料同步到了物化檢視,使查詢的資料不是舊的資料。
DLink支援資料快取

Alluxio Local data cache,輕量級僅本地節點訪問的快取,將資料快取在計算Node的本地SSD中,不考慮叢集節點間資料共享,依賴於soft affinity schedule,增加快取命中率,儘量本地node處理本地的資料。
DLink Trino Catalog熱載入
主要做法是透過產品層面提供restAPI方式,新增註冊Catalog介面。每個節點都可以載入到Catalog,達到叢集Catalog熱載入,包括刪除、更新操作。
DLink支援Flink Job運算元併發拆分和調優
主要作用是方便排查瓶頸運算元,比如三個運算元算一個節點,其中有一個運算元OP1有瓶頸的話,如果沒有拆分功能,需要對整個節點資源都要調優,對OP2/3來講不需要調整,會有資源浪費的情況。拆分之後,就可以單獨對OP1調整併發,保證整個任務可以順利進行,也節省了資源,提升作業效能。
DLink支援在湖內構建維表和快取加速
DLink支援多租戶和多湖企業級架構,主要適合的客戶,如大型央國企,大型跨國公司,集團租戶不同子公司。
原來方式是每個子公司和集團公司自己都有一個湖,這個湖實際上是物理隔離的,不同的機房,如果主湖跟子湖資料想同步的話,目前透過資料複製的方式效能和成本會有很大的問題,我們支援多湖、多租戶,透過DLink構建對外部資料來源透過資料註冊方式註冊進來,對湖內管理,同時在湖上也可以支援多個物理湖之間跨湖的聯邦查詢,資料不需要兩個湖之間同步,可以透過Trino聯邦查詢,對兩個湖進行統一查詢管理。
同時也可以對原有業務庫,像MySQL、Oracle業務庫,沒有入湖的話,註冊完之後,也可以支援外部資料來源和每個湖之間資料的聯邦查詢。同時在聯邦時,可以透過對租戶許可權的控制,如集團的湖不想讓子湖全部訪問到它的資料,透過對角色、使用者進行許可權控制,支援平臺級許可權,支援庫表列許可權,只能訪問對應資料,做到資料安全。
DLink落地實踐
例1,某儲存客戶資料能力建設現狀
某某儲存現有大資料平臺以CDH(6.3.2)技術棧為主,基於本地IDC物理架構構建。沿用業界經典的Lambda架構,以離線採集+離線數倉為主核心技術架構。
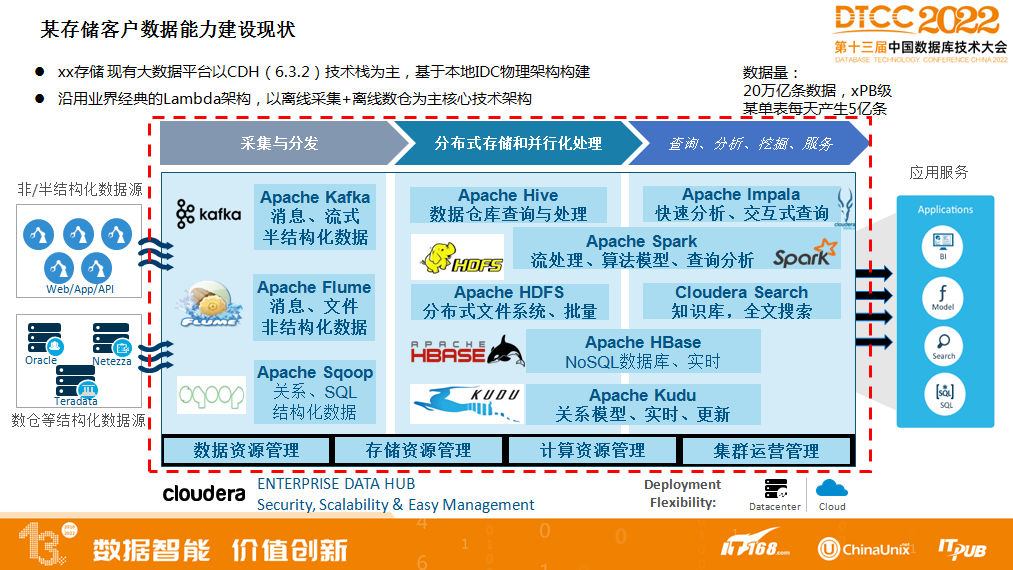
隨著業務資料不斷增多,還想對資料業務去從,儲存和計算成本透過跑批壓力也比較大,成本比較高,所以引入了我們DLink。
客戶關注點:
穩定性、可用性。希望能做到大資料元件到資料本身的全鏈路監控。
靈活性、相容性。各技術元件支援靈活的組合,需要與現有的CDH相容。隨著業務的發展,資料的增加,支援橫向擴充套件。
資料準確可靠。Hive歷史資料快速遷移入湖,歷史資料和新增資料去重,流式任務出現異常後,需要有相應的補數方案。
解決方案:
DataOps理念。提供可靠的資料採集到上線運維的流程監控,實現資料的持續穩定交付。
湖倉一體架構。支援DLink on YARN/K8S的部署方式,相容現有CDH,各元件之間解耦;雲原生架構,支援計算和儲存資源彈性擴容。
面向資料質量提升的技術架構。提供Hive歷史資料生成DLink Iceberg後設資料的方式快速遷移資料入湖;提供歷史資料快速批式去重,新增資料流式去重;提供流式任務異常情況補資料的方案。
客戶原本大資料底座是CDH6.3.2,透過Hive進行大資料量的資料去重操作,效率極低,資源佔用非常高,資源庫壓力大。
客戶最大的一張表存量資料3000億條,日增7億條左右。
採用DLink資料湖方案,該表歷史全量資料去重時間壓縮至4小時左右,入湖速度在11w條每秒,日增量資料批次merge到全量表耗時在1.0小時左右。
該方案收益:
大大降低了Oracle源庫壓力。
大大降低了資源消耗,只有原來的1/4。
大大提高了時效,資料從入庫到Iceberg表中可查時延在2分鐘以內。
例2,某能源自建雲新系統架構:統一技術棧、實時湖倉、容器化
這個客戶也是我們目前正在交付的客戶,核心訴求是統一技術棧,也使用CDH,透過Hive構建的數倉,效能也是T+1,資料用test格式,還沒有壓縮,整個用起來比較浪費儲存。資料來源有Oracle、MySQL、SQL server、postgreSQL、mongoDB等。底層儲存可以對接他們JFS,JFS可以遮蔽掉底層不同的儲存方式,提供統一儲存介面來進行訪問,這塊我們也做了對接。
在數倉建模之後,到ODS層,可以達到分鐘級別,如果客戶對這種資料的新鮮度要求更高的話,比如到秒級以下做業務的分析,我們業提供DLink對湖內資料進行出湖,遷移出去做資料處理。
例3,某零售行業客戶案例

基於CDH做的,是6.3版本。最核心的訴求是想對圖片、音影片、結構化資料和非結構化資料做統一儲存,更好地對業務進行賦能,可以對圖片進行搜尋、檢索、對接AI平臺能力,我們給它提供流批一體能力,可以T+1到T+0時效性提升。存算分離,雲原生架構計算儲存可以彈性擴縮容,讓計算資源和儲存資源不再成為瓶頸。Data+AI,支援非結構化資料分析,更好挖掘非結構化資料價值。
DLink未來規劃
支援亞秒級實時數倉能力,這是我們的目標,如果支援之後,在DLink上可以支援多模儲存引擎。
支援企業級多租戶多級資料湖,也是我們未來想繼續完善和深耕的特性。
支援IMT二級索引,主要也是對重複資料合併效能帶來的問題做最佳化。
支援自適應實時物化檢視,查詢時可以自動改寫物化檢視,改進以後,客戶無感知隨著業務慢慢往前演進,會越來越快。
支援資料加密和查詢脫敏,主要是向金融客戶、大型央國企資料加密和脫敏有嚴格的要求,我們也在支援這方面。
支援Hudi表格式,相當於做一個橫向的擴充套件,因為目前DLink是構建在Iceberg表格之上的,我們也正在做Hudi表格式,進度到明年Q1DLink產品就可以上線支援Hudi表格式。
支援機器學習,我們在多個客戶場景下現在已經在落地和交付DLink+AI平臺服務於客戶機器學習的場景,接下來會重點做這塊支援和能力。
來自 “ ITPUB部落格 ” ,連結:http://blog.itpub.net/28285180/viewspace-2929026/,如需轉載,請註明出處,否則將追究法律責任。
相關文章
- 滴普科技馮森 FastData DLink 實時湖倉引擎架構設計與落地實踐AST架構
- 直播預約丨《實時湖倉實踐五講》第二講:實時湖倉功能架構設計與落地實戰架構
- 滴普科技劉波 FastData DataFacts建設資料智慧平臺的實踐AST
- 直播預約丨《實時湖倉實踐五講》第四講:實時湖倉架構與技術選型架構
- 直播預約丨《實時湖倉實踐五講》第三講:實時湖倉在袋鼠雲的落地實踐之路
- 美團實時數倉架構演進與建設實踐架構
- 農業銀行湖倉一體實時數倉建設探索實踐
- 從離線到實時資料生產,網易湖倉一體設計與實踐
- B站基於Iceberg的湖倉一體架構實踐架構
- 【架構與設計】常見微服務分層架構的區別和落地實踐架構微服務
- 直播預約丨《實時湖倉實踐五講》第五講:實時湖倉領域的最/佳實踐解析
- 低程式碼實時數倉構建系統的設計與實踐
- 網易考拉規則引擎平臺架構設計與實踐架構
- 數倉實踐:匯流排矩陣架構設計矩陣架構
- 亞馬遜雲科技潘超:雲原生無伺服器數倉最佳實踐與實時數倉架構亞馬遜伺服器架構
- 實時數倉在滴滴的實踐和落地
- 面向微服務架構設計理念與實踐微服務架構
- 領域驅動設計DDD和CQRS架構模式落地實踐架構模式
- 實時數倉:Kappa架構APP架構
- 攜程實時計算平臺架構與實踐丨DataPipeline架構API
- 作業幫多雲架構設計與實踐架構
- Serverless 架構落地實踐及案例解析Server架構
- Vue 專案架構設計與工程化實踐Vue架構
- vivo 服務端監控架構設計與實踐服務端架構
- vivo 全球商城:商品系統架構設計與實踐架構
- 都強調實時性,偶數科技實時湖倉一體有啥不同?
- 位元組跳動資料湖在實時數倉中的實踐
- 新興資料倉儲設計與實踐手冊:從分層架構到實際應用(二)架構
- 新興資料倉儲設計與實踐手冊:從分層架構到實際應用(三)架構
- JUST京東城市時空資料引擎2.0架構實踐架構
- 短視訊 SDK 架構設計實踐架構
- vivo全球商城:庫存系統架構設計與實踐架構
- 通用資料湖倉一體架構正當時架構
- 基於 Paimon 的袋鼠雲實時湖倉入湖實戰剖析AI
- B 站構建實時資料湖的探索和實踐
- DevOps落地實踐點滴和踩坑記錄-(1)dev
- 深度解讀KubeEdge架構設計與邊緣AI實踐探索架構AI
- vivo 全球商城:優惠券系統架構設計與實踐架構