網易嚴選離線數倉治理實踐
1 背景
任何一個系統,為了保證其良好地執行下去,一定是需要持續的維護和治理,數倉也不例外。本文主要分享下今年嚴選數倉團隊從規範、計存、質量、安全幾塊入手對現有資料資產進行的一些治理的思路和方案。
網易嚴選是個自營品牌電商,這意味著嚴選的業務會覆蓋C端的使用者營銷,商品到B端的供應鏈以及財務業務。業務和資料的整體複雜度會相對較高,各個不同業務域也呈現出不同的特點和問題。所以我們需要結合現有的資產特點去設計治理方法論和效果評估方法,然後圍繞著治理方法論去建設我們的治理工具。
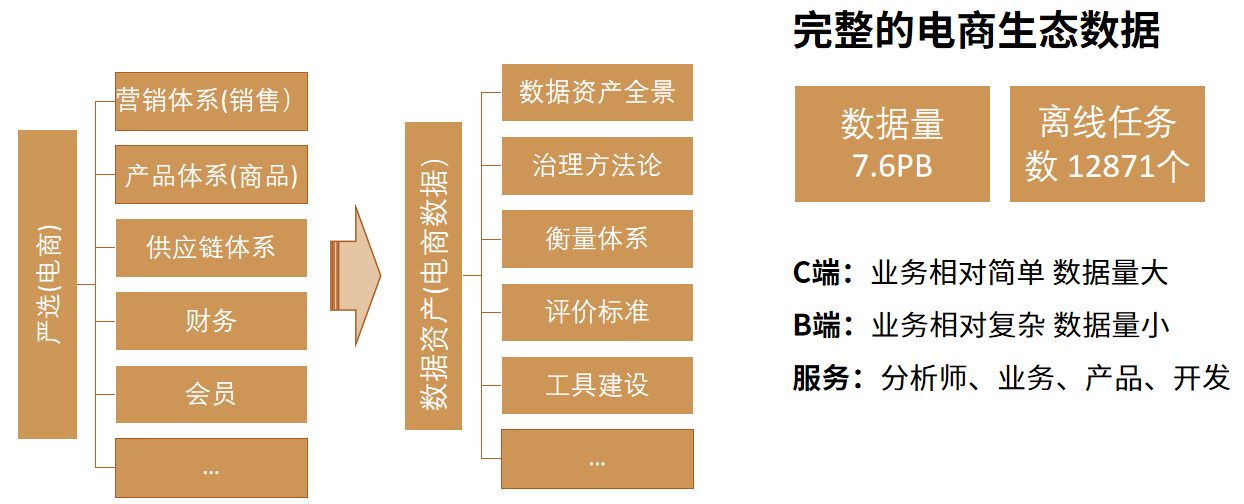
治理開始前,先盤一下我們可用的資源,設計下整體的方向。從人力上來說,專案整體設計與推動大概可投入1.5人力,治理實施可以拉上資產對應的資料開發配合,這個人力方案決定了我們肯定是不會去設計開發個整體的治理系統來做這個事情,而是應該把重點放在規範和治理方案設計上,依託現有基礎能力,以較低程度的開發資源投入來推動這個事情。
基礎能力上來說,已經沉澱的能力有:
資料地圖:由資料開發治理平臺的資料地圖及嚴選資料資產中心提供,大部分資料沉澱在產品,未入倉;
全鏈路血緣:由嚴選資料資產中心提供,資料沉澱在產品,未入倉;
資料探查能力:由資料開發治理平臺的測試中心提供;
影響評估能力:主要由嚴選資料資產中心提供,結合血緣和資料分級能力得出影響程度。
整體資產全景見下圖:

歷史我們也做過不少資料治理相關投入,但存在一些問題,比如缺乏體系化設計,導致多個專案/團隊交叉治理,重複治理等問題,同時,治理效果也缺乏持續的追蹤和效果衡量。這些是本次治理專案需要解決的問題。
2 思路
整體思路上我們分4步走。
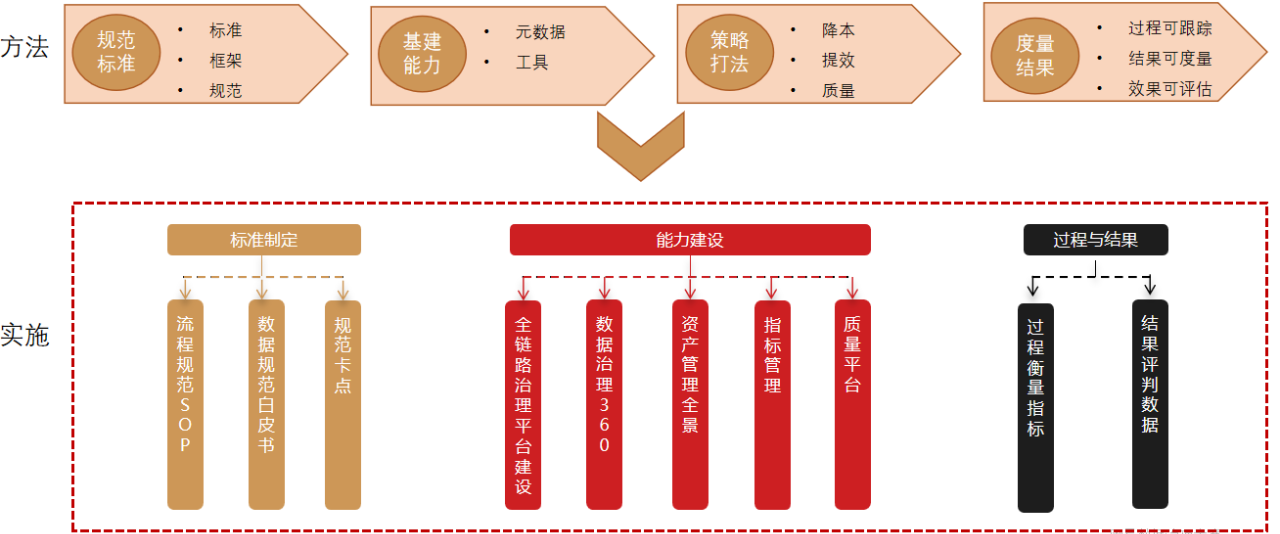
(1)規範制定
資料建模規範,即資料開發在設計模型階段需要遵循的規範,比如dwd不能加工指標等。
資料開發SOP,為了系統能幫我們自動做一些規範校驗和補全,我們可能制定一些流程上的規範,比如建表必須走模型設計中心,dw層全部先評審後開發等。
(2)能力建設
即我們資料治理過程中需要用到的系統能力補全,包含後設資料建設,資料平臺的迭代及治理工具的開發。
(3)治理實施
從治理目標上來說,我們圍繞降本、提效、質量3個點去規劃治理方案;
從實施方案上來說,主要落實在規範、計算儲存、資料質量、資料安全4個方面。
(4)結果衡量
治理結果目標制定;
治理過程指標衡量。
3 實施
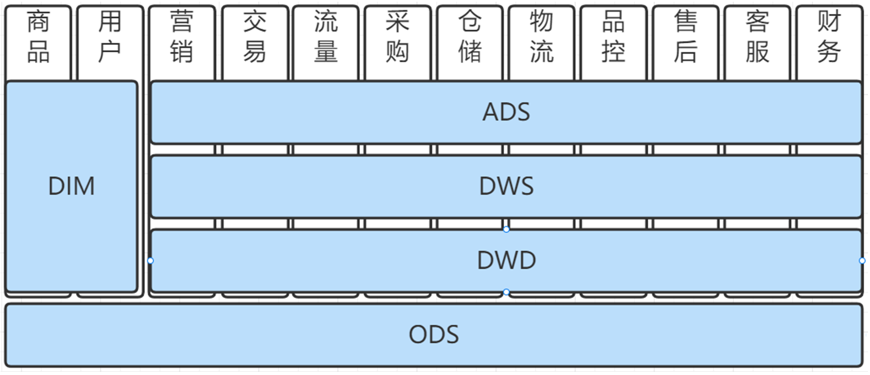
3.1 規範治理
嚴選數倉建模規範主要基於Kimball維度建模理論,結合嚴選業務實際情況制定,大致架構如下圖:
有了規範定義,那我們首先需要的就是看下當前數倉的規範程度,這裡我們基於後設資料ETL加工得到我們的監測指標,並基於有數BI進行的視覺化呈現。

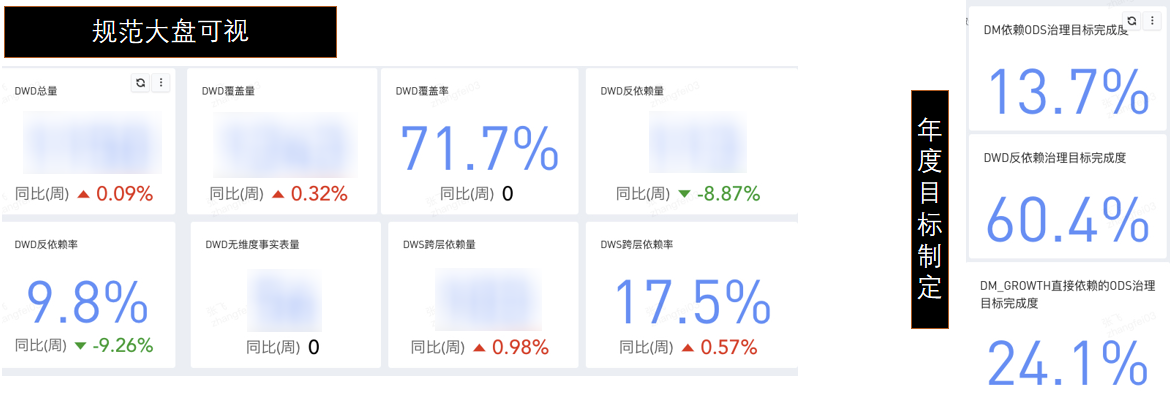
然後基於當前數倉規範的達成情況,我們制定了今年主要要解決的問題及規範治理的目標,並同樣對治理目標做了視覺化。主要問題及解決方式如下:
(1)跨層依賴——巡檢及待辦分發
DWS依賴ODS
DM依賴ODS
(2)反向依賴——巡檢及待辦分發
DWD依賴DM
DWD依賴DWS
DWS依賴DM
(3)單一事實建模——運動式治理
一張DWD只依賴一張ODS
3.2 指標治理
嚴選的指標管理基於自研的指標管理系統,該系統會對指標的口徑進行管理,並強制繫結到資料閘道器,實現從資料閘道器輸出的資料,都附帶明確的口徑定義。但該系統存在一個問題,那就是定義和研發分離。指標口徑基於該系統定義,但是指標的開發和該系統並沒關聯,那麼在開發過程中,口徑定義和實際開發的口徑可能就會出現偏差,並且在dws和ads的加工上,建模設計完全由資料開發把關,也就可能出現模型設計質量參差不齊的情況。
對於以上問題,我們的解法是新設計一套指標管理系統,將指標定義和開發工作耦合起來,實現定義即研發的效果。目前該系統已經在部分場景實現了落地,系統詳細設計這裡就不展開了,感興趣的同學可以線下交流。
3.3 計算儲存治理
計算儲存資源的消耗直接關係資料的生產成本以及資料產出的穩定性和及時性,所以這塊也是比較重要的。
(1)計算治理
計算資源可最佳化的點主要在於因程式碼或引數的不合理導致的低效任務上,主要思路是識別出這部分任務,然後透過by任務的最佳化去提高資源利用率。治理方法如下:
觸發條件:
資料開發治理平臺openAPI獲取yarn資源消耗明細
記憶體空閒時間分佈聚類取前20%閾值
RAM實際申請大於1TB
利用率小於10%
防治:
全域性:整體消耗資源(RMB/RAM/CPU/TIME)分佈監控
個人:觸發條件發飛書push任務治理通知
過程記錄(已治理/待治理)效果統計
最佳化方法:謂詞下推/小檔案合併/join最佳化/data skew最佳化/提高任務並行度/Spark AQE 引數調整
首先我們起個資料開發治理平臺的任務,按照觸發條件去巡檢,篩選出待治理列表。然後發現這部分任務有著明顯的長尾分佈特性,極少數任務佔用了大部分資源。所以我們針對top100的任務由專人挨個進行的by case的最佳化,剩餘的任務則透過待辦分發的形式推送給任務的負責人進行最佳化跟進。同時,我們做了全域性的和個人的計算資源監控大盤,透過訊息通知的形式,每天進行監控和公示。

(2)儲存治理
歷史對於冷表冷任務這塊我們沒有系統關注和清理過,所以隨著業務的不斷髮展積累的大量的冷表冷任務。對於這塊兒的治理主要藉助資料開發治理平臺的資料資產中心的儲存最佳化功能。但因為資料資產中心對於特殊儲存比如kudu、iceberg,以及倉外血緣沒有做邏輯判斷。所以拿到資料資產中心的推薦下線資料後,我們結合嚴選維護的全鏈路血緣做了交叉校驗,得到最終的待下線任務集。任務集的判斷條件如下:
觸發條件:
強推薦:30天開啟次數+近30天引用次數+近30天訪問次數+近30天寫入次數 = 0
弱推薦 :近30天開啟次數+近30天引用次數+近30天訪問次數 = 0
不存在於排程任務
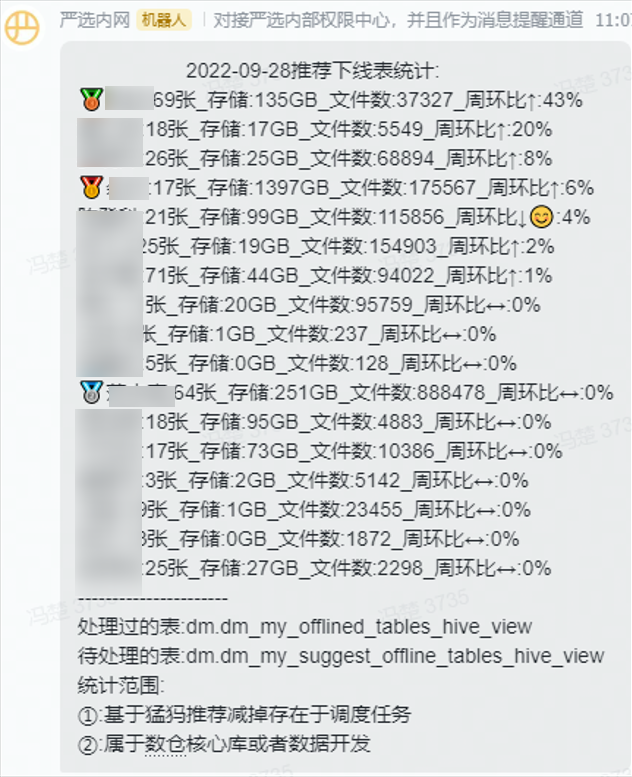
得到任務集後,先大致分析了下待下線表的分佈,發現有幾個佔比較大且風險較低的庫,比如kylin cube build的臨時資料,庫存中心的流水日誌等,我們判斷風險較小,且數量較大,就讓資料開發治理平臺的同學幫忙批次下線掉。對於是dw,dm等db的表,因為誰也沒辦法保證血緣100%的準確性,且攤分到每個人頭上後量不算大,所以就採取待辦分發的形式push表負責人去進行治理。然後我們再透過open API去監控叢集整體,和每個資料開發的冷表治理情況,針對需要改進的點再單獨push。
防治:
全域性:整體情況及佔比變化效果群訊息
個人:單獨push需要治理的表
資料開發治理平臺的資料資產儲存模組操作
API獲取處理結果統計
3.4 資料安全治理
這個事情大的背景是目前數倉關於資料加密脫敏,資料許可權管理等工作基本靠共識,比如大家都知道使用者手機號是敏感資料,有人要這份資料時也會多走個流程審批一下。但是到底哪些表裡面有存使用者手機號,這些手機號有沒有被妥善地加密或脫敏,表授權時有沒有去判斷裡面是否有敏感資料,這些我們都是不知道的。所以我們考慮基於實體識別的方法,把資料資產的敏感程度給分級打標出來。

分級打標的依據是集團下發的《網易資料分類分級管理制度》,根據這個檔案,我們手工把數倉的各項涉敏資料項給盤點出來,整理成結構化的資料。再用一個Spark Job的形式去批次對所有數倉表進行取樣和欄位打標。大致實現如下:↓
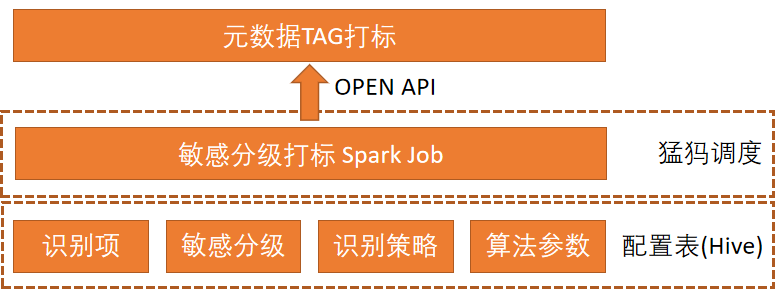
目前這個系統做了基本的實現,後續需要繼續擴充套件識別項覆蓋率和準確率,具體技術細節我們就不在這裡討論了,後面單開一篇文章分享。
得到分級結果後,我們就可以拿這份資料去重新盤點和治理我們的資料加密和許可權管理情況了。
3.5 資料質量治理
質量這塊兒我們分事前、事中、事後三塊去實施。
(1)事前
事前我們主要是規範資料需求流程,明確各個參與方職責,進行風險評估和保障定義:
業務:需求提出
BI/PM:1、需求拆解 2、確定口徑
資料開發:需求評審
資料系分評審、鏈路評估
驗證方案、回滾方案
鏈路風險巡檢/治理
SLA 定義、保障方式定義
QA:測試評審
測試測分及評審
自測標準、驗收標準
測試報告、驗收反饋
事故報告、事故覆盤
(2)事中
事中我們遵循資料開發->研發自測->QA自測->資料釋出->產品釋出->使用者驗收的流程,保證研發過程的質量合格。
(3)事後
事後指的是需求交付後的運維保障及應急恢復,這裡的策略包括:基線值班、DQC、變更感知、大促時的壓測和發生故障後的覆盤。

基線值班會有資料基線該怎麼掛的問題,任務A到底要保障到7點產出還是9點產出,值班的資源是有限的,都保障就意味著保障力度都降低,同理DQC的配置也是。這裡我們的做法是,先從資料的使用場景出發,看看線上服務和有數報表的重要性分級是什麼樣的。再根據血緣往上追蹤,對整個上游鏈路的資料任務挨個打標,高優覆蓋低優,以此來確認任務的保障等級。
獲得任務分級後,我們把P0,P1的任務掛載到了7:30/9:30兩條基線,P2任務掛載到了10:00基線,由資料值班來保障他們的按時產出,並對破線及任務失敗進行記錄和覆盤,便於確認後續最佳化方向。同時,P0、P1的任務也強制要求大家配上了基本的資料稽核。
然後是變更感知這塊兒,包含資料來源變更感知和ETL變更感知。數倉不生產資料,我們在只是資料的搬運工,所以感知資料來源的變更和“搬運程式”的變更對資料質量的保障特別重要。

這裡我們的做法是,收集資料來源的變更工單日誌以及數倉表和任務的修改記錄,透過一個週期排程的spark sql任務去識別出風險變更以及影響範圍,並推送訊息給到對應的資料開發評估。
3.6 橫向巡檢機制
前面關於各個治理專案都有提到需要推送待辦任務給資料開發處理,所以我們需要一個通用的訊息通知機制。再結合到我們大多數巡檢場景都可以基於後設資料+SQL的形式識別,於是我們採用UDF的方法,對接訊息中心的介面,實現了訊息通知的SQL化。

4 效果
治理效果這塊兒,我們基於有數BI搭建了視覺化看板,對整體的目標達成率和每個人的目標達成率進行了監控和跟進。
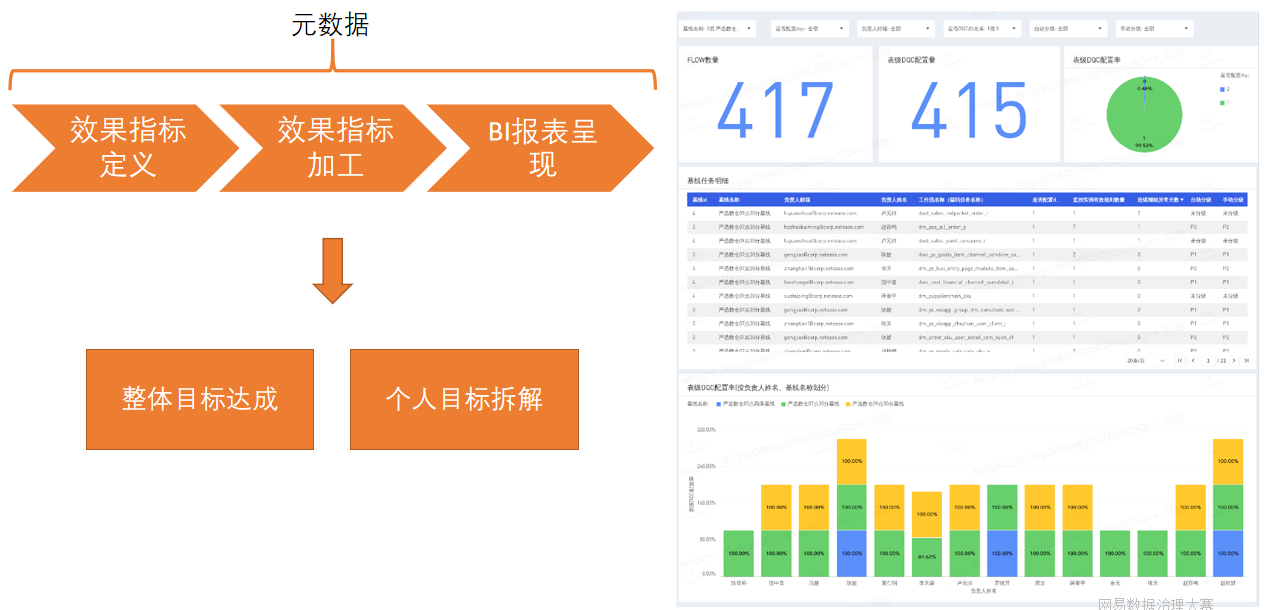
具體關鍵成果如下:
(1)規範
DWS跨層依賴率 21.2%->17.5%
DWD反依賴率18.1%->11.5%
(2)計存
冷表下線10W+張,累計下降儲存2.8PB,淨下降1.9PB(8.49-6.59)
資源費用 12k/day->2k/day
記憶體memory seconds 下降33%
高耗資源任務執行時間 下降90%
高耗資源任務成本消耗 下降69%
(3)質量
基線破線率23.76%->0%
DQC配置率10%->100%
來自 “ 網易有數 ”, 原文作者:馮楚 張嘉志;原文連結:http://server.it168.com/a2022/1207/6779/000006779058.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 資料治理實踐 | 網易某業務線的計算資源治理
- 網易有道成人教育數倉建設實踐
- 從離線到實時資料生產,網易湖倉一體設計與實踐
- 使用pypiserver快速搭建內網離線pypi倉庫實踐Server內網
- 網易雲音樂資料全鏈路基線治理實踐
- 網易雲音樂基於Flink實時數倉實踐
- 網易某業務線的計算資源資料治理實踐
- 離線數倉測試
- 雲音樂實時數倉建設以及任務治理實踐
- 易點天下基於 StarRocks 構建實時離線一體的數倉方案
- B站運維數倉建設和資料治理實踐運維
- 網易互娛資料成本最佳化治理實踐
- 網易嚴選的wkwebview測試之路WebView
- GitHub Daily - Taro 實戰網易嚴選三端專案GithubAI
- 資料治理 VS 公司治理、IT治理、數倉治理
- 網易嚴選基於“服務畫像”的長效穩定效能力建設實踐
- 網易數帆資料治理演進
- WEEX-EROS | 移植自網易嚴選 app demoROSAPP
- 大宗商品貿易集團資料治理實踐,夯實數字基座 | 數字化標杆
- 美圖離線ETL實踐
- 實時數倉混沌演練實踐
- 乾貨分享|袋鼠雲數棧離線開發平臺在小檔案治理上的探索實踐之路
- 應用實踐——新東方實時數倉實踐
- 離線數倉建設之資料匯出
- 華為雲服務治理 — 隔離倉的作用
- Doris和Flink在實時數倉實踐
- 網易嚴選跨域多目標演算法演進跨域演算法
- 網易數帆實時資料湖 Arctic 的探索和實踐
- 招商銀行 KubeVela 離線部署實踐
- 實時數倉在滴滴的實踐和落地
- 微信ClickHouse實時數倉的最佳實踐
- Docker 離線安裝 & 離線私有倉庫搭建總結Docker
- 網易數帆雲原生日誌平臺架構實踐架構
- 快手實時數倉保障體系研發實踐
- 基於 Flink 的實時數倉生產實踐
- vivo 在離線混部探索與實踐
- 農業銀行湖倉一體實時數倉建設探索實踐
- 網易嚴選商城小程式全棧開發,域名備案中近期上線(mpvue+koa2+mysql)全棧VueMySql