網易互娛資料成本最佳化治理實踐
1 專案背景
我們團隊為網易互娛大量遊戲產品提供了常規概況、經濟分析、留存分析、迴流分析、付費分析、伺服器分析、渠道分析、定製專題、社交分析、全球分析、問卷分析、全球裝置等多種遊戲分析專題服務,也支援自定義指標展示的BI看板分析。
目前為止,已累計服務互娛300+款產品,離線數倉SQL月執行次數便最高可達近400萬次。
2 專案挑戰
隨著業務發展,目前離線數倉執行作業數已達到每月三百萬+個,各個環節的問題也凸顯出來:
日誌管理混亂,多產品多程式規範不統一,日誌列印隨意,解析與維護困難;
產品持續運營,作業與資料累積,作業常需長期執行,資料生命週期不明確;
日誌重複儲存,原始日誌與經格式化解析後的原始表並存兩份,成本負擔大;
海外市場開拓,海外資料儲存成本遠高於國內,導致產品資料儲存成本飆升。

為此,對專案進行資料成本最佳化迫在眉睫。
3 專案實現
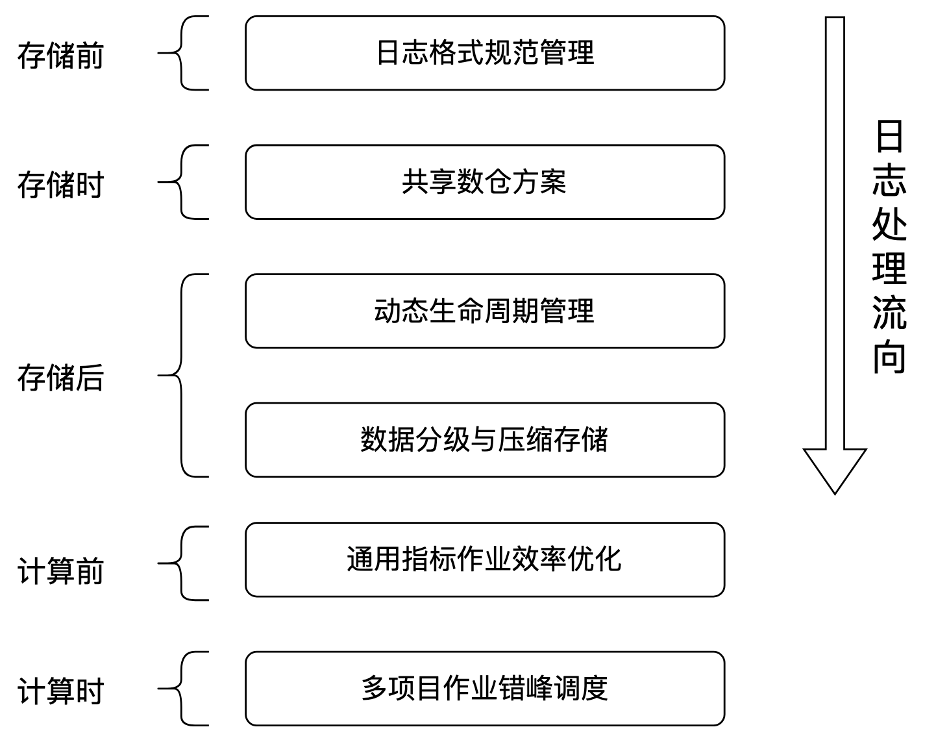
我們總體的最佳化方向分為儲存和計算兩大部分,基於日誌的處理流向分不同階段進行最佳化。
對於儲存部分,對互娛數倉總體儲存進行佔比分析,我們發現ODS層資料佔據了全專案的75%的儲存空間。因此,我們的首要目標便是最佳化ODS層的資料儲存,分為儲存前、儲存時、儲存後三個子目標進行最佳化。
對於計算部分,由於計算任務眾多,我們優先針對耗時較長、邏輯通用性較高的P1指標的計算任務進行最佳化,分為計算前、計算時兩個子目標進行最佳化。
(1)儲存前:日誌格式規範管理
程式日誌作為互娛ODS層資料的直接來源,合理的日誌格式規範可以直接從源頭上降低人力和儲存成本。這裡我們提出了日誌列印的三大原則:
標準:日誌列印遵守統一標準格式,保證下游可正常解析,異常日誌的儲存或特化解析會帶來儲存空間的浪費、人力維護跟進的投入開銷與下游解析作業的效能開銷;
按需:僅列印下游業務所需的日誌,非必要的日誌可不列印或不採集到下游鏈路中;在滿足業務分析的前提下,日誌列印可遵守最小原則,最大限度減少下游日誌傳輸量;
精簡:對於頻繁在多條日誌反覆列印的欄位,可僅在會話中的第一條日誌列印完整資訊,後續日誌透過會話ID進行關聯查詢;可透過維表查詢替換的欄位,在日誌列印時可進一步壓縮欄位的大小。
當然,基於人工遵守原則來保證日誌規範總會有遺漏的地方,因此互娛資料治理平臺的日誌上報模組便應運而生。就以日誌精簡列印為例,使用者可在日誌上報模組上報和配置日誌的對映關係,首先程式按約定列印日誌時僅列印日誌列名的縮寫,其次業務同學按約定的對映欄位登記表或欄位的英文全名以及業務描述,理論上可以減少10%-20%的日誌儲存空間。

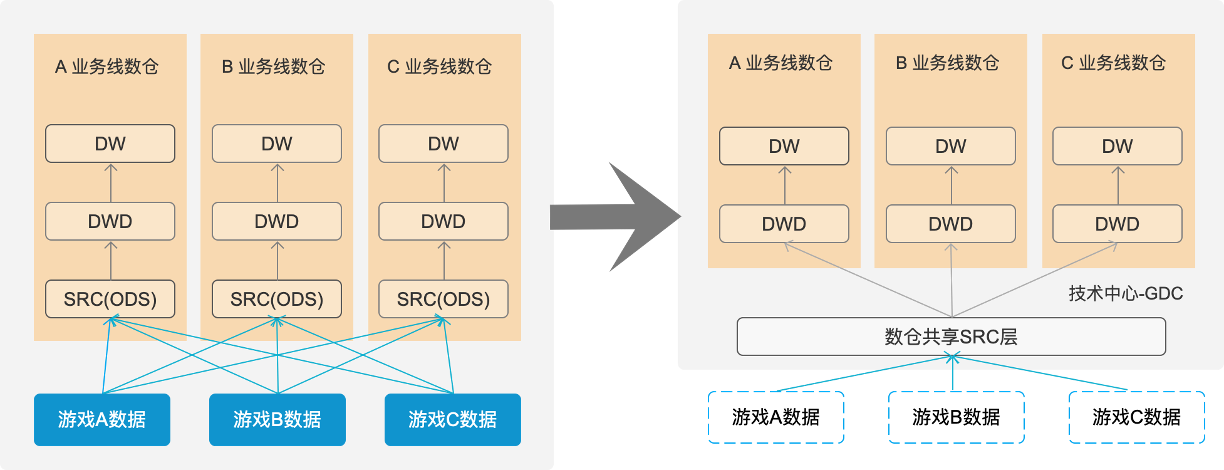
(2)儲存時:共享數倉方案
互娛舊版原始日誌儲存架構中多個部門都有各自ETL後的ODS層,形成了多份原始日誌重複儲存的局面。為此,UX+SDC+GDC等多個部門聯合推進了共享數倉的方案,實現一個多部門共享實時ODS層:讀取實時流資料,實時ETL後按日誌名入庫為不同表,分鐘級時效,業務部門直接基於共享ODS層進行上層指標計算,實現一份ODS層的最優儲存。該方案的推進,也帶來了諸多好處:
解決原先原始日誌不可「查詢」的問題:提供給使用者最基礎的ODS表查詢,而原始日誌本身將不再儲存;
解決原先檔案儲存無法細粒度管理問題:調整為表儲存模組, 給產品提供專案日誌資料管理入口;
最佳化上層業務線按單日誌重跑執行效率:底層日誌按表分別儲存,上層資料重跑無需掃描全部日誌。
(3)儲存後:動態生命週期管理
早期我們對於ODS層資料儲存最佳化的手段便是由業務同學人工配置ODS表生命週期,但該方式存在諸多問題:
錯誤衝突:人工配置可能會誤消亡正在讀取的表分割槽資料,業務A配置的規則不一定符合業務B的要求;
維護麻煩:生命週期額外配置,與業務同學計算指標作業隔離,業務邏輯更新時需兼顧兩處;
歷史遺留:人工配置容易可能會造成歷史遺留問題,出於穩定考慮,業務無法有絕對把握縮短生命週期。
因此,針對上述痛點,互娛資料團隊提出了一個自動化方案:基於SQL審計記錄,動態消亡長期未讀分割槽資料,再次讀取時自動重切資料。

2022年6~9月份,某海外大型專案,回收過期資料2229.5T,截止2022年09月27日,專案現存資料僅386.3T,減少了85%的儲存空間。
(4)儲存後:資料分級與壓縮儲存
當資料必須儲存時,我們可以透過分級儲存與壓縮儲存來進一步降低儲存成本。
透過SQL審計資訊發現,按時間從近到遠,資料的讀取頻率也從高到低遞減,因此我們提出了分級儲存的模式:按資料生產日期從近到遠,權衡讀寫效能,選擇儲存介質。
第一級:儲存在常規Hadoop叢集,保證讀寫效能;
第二級:儲存在冷備Hadoop叢集,可讀寫,但效能稍差;
第三級:儲存在冷備S3叢集,只讀不可寫,效能最差。
同時,在儲存時,我們可以基於資料的讀寫特性,比如是否要支援追加寫等約束,為資料選擇合適的壓縮格式,這裡我們也分為兩級進行實現:
第一級:格式壓縮,基於不同表,壓縮為orc/textfile+snappy格式,壓縮率在30~48%左右;
第二級:使用糾刪碼技術,從3副本減少到1.5副本,壓縮率在50%左右。
(5)計算前:計算效率最佳化
由於互娛數倉作業任務數眾多,因此我們選擇優先針對耗時較長、邏輯通用性較高的計算任務進行最佳化。具體思路是從資料倉儲建模角度重新梳理資料鏈路,減少跨層引用,複用資料中間層降低重複計算和IO等。經過測驗,專案裡滿足條件的作業所需計算資源會降低70%-90%,整體常規運營指標任務所需計算資源能降低30%-50%。

(6)計算時:任務錯峰排程
在早期,由於缺乏有效規範,過往的計算任務分配排程時間相對隨意。從專案排程圖可以觀測到,很多專案下的任務執行時間集中在了忙時階段,造成計算成本相對較高。而不同的時段的記憶體、CPU等計算資源成本是不一致,一般可以分為忙時(凌晨2點-8點)和閒時兩個階段,忙時和閒時計算費用單價比為4:1。
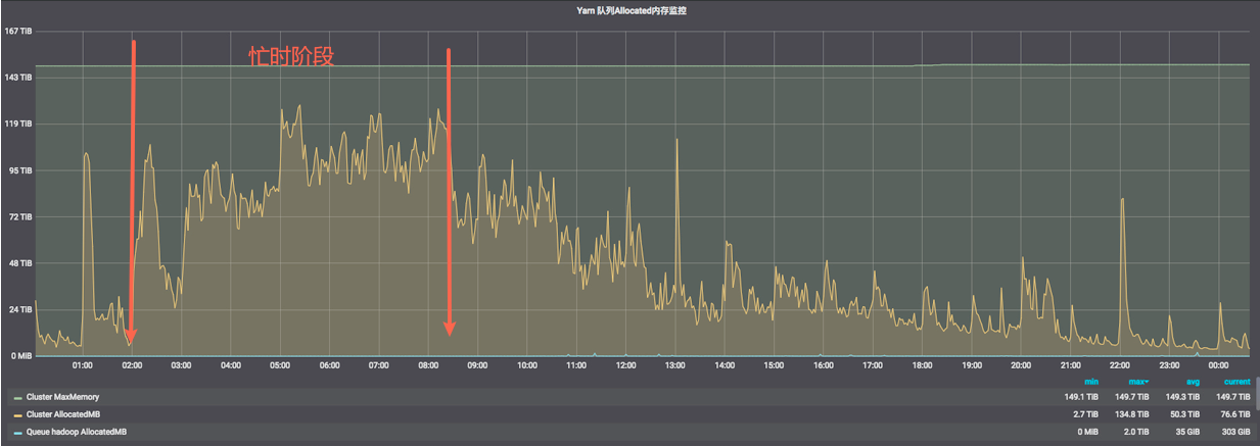
因此我們透過對專案任務優先順序和預期產出時間進行梳理,使用遷移非關鍵分析指標至閒時等手段,重新合理分配了任務的排程執行時間,從而降低了總體專案的計算成本。
4 專案成果
(1)2021年的計算儲存最佳化效果
2021年9月份對公司部分遊戲業務進行儲存和計算最佳化之後,如右圖所示,在保障不影響業務運轉的前提下,成本方面環比8月各業務都有了較為明顯的下降。儲存部分最高最佳化65%,計算部分最高最佳化71%,總計預估年節約成本約合960萬元。

(2)2022年的計算儲存最佳化效果
2022年6月份起對公司海外專案為主進行儲存和計算最佳化後,最佳化佔最終最佳化總體各為45%、55%,總計預估年節約成本約合1500萬+元。
來自 “ 網易有數 ”, 原文作者:林澤程 賴餘康;原文連結:http://server.it168.com/a2022/1201/6778/000006778288.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 資料治理實踐 | 網易某業務線的計算資源治理
- 網易雲音樂資料全鏈路基線治理實踐
- 網易某業務線的計算資源資料治理實踐
- 高途資料平臺遷移與成本治理實踐
- 網易互娛基於 Flink 的支付環境全關聯分析實踐
- 網易嚴選離線數倉治理實踐
- 網易數帆資料治理演進
- 資料標準在網易的實踐
- 研發團隊資源成本最佳化實踐
- 美團配送資料治理實踐
- 資料治理之後設資料管理實踐
- 網易互娛 遊戲研發 暑期實習面試面經遊戲面試
- 資料庫治理的探索與實踐資料庫
- 騰訊資料治理技術實踐
- 中通快遞資料治理實踐
- 網易公開課iOS資訊流卡頓最佳化實踐iOS
- 資料治理:管理資料資產的最佳實踐框架框架
- 釐清企業資料治理難題,《網易資料治理白皮書》重磅釋出!
- Iceberg 資料治理及查詢加速實踐
- 輕量&聚焦:精益資料治理實踐——以客戶資料治理為例
- 8個雲成本最佳化的最佳實踐
- 最佳化 20% 資源成本,新東方的 Serverless 實踐之路Server
- 雲訊息佇列 ApsaraMQ 成本治理實踐(文末附好禮)佇列MQ
- ag介面對接網站Mysql資料庫資源資料互動實踐網站MySql資料庫
- 大宗商品貿易集團資料治理實踐,夯實數字基座 | 數字化標杆
- 網易數帆實時資料湖 Arctic 的探索和實踐
- 資料治理:資料標準管理的內容和實踐!
- 資料治理:資料標準管理的內容和實踐
- 小米大資料儲存服務的資料治理實踐大資料
- 網易雲音樂資料互動—async&await實現版AI
- 解讀資料治理(Data Governance)最佳實踐DPGoNaN
- 愛奇藝的雲上資料治理實踐
- 滿成見:獵聘網資料治理實踐全流程經驗分享
- vivo 短影片體驗與成本最佳化實踐
- 主機廠資料資產血緣分析治理實踐
- 資料治理實踐:後設資料管理架構的演變架構
- 爬蟲實踐之獲取網易雲評論資料資訊爬蟲
- 2萬字揭秘阿里資料治理建設實踐阿里