網易公開課iOS資訊流卡頓最佳化實踐
背景
在公開課APP中,資訊流是使用者獲取和瀏覽課程相關內容的核心介面之一。然而,我們發現在效能較差的裝置上,使用者在瀏覽資訊流時有時會遇到卡頓現象,即頁面滾動不流暢,載入速度緩慢的現象,此時螢幕的幀率通常在35~45FPS之間,遠低於理想的60FPS。卡頓對使用者的使用體驗有較大的影響,因此我們決定對資訊流的卡頓進行最佳化。
理論基礎
影像渲染原理
通常計算機螢幕顯示是CPU與GPU協同合作完成一次渲染,如下圖所示:
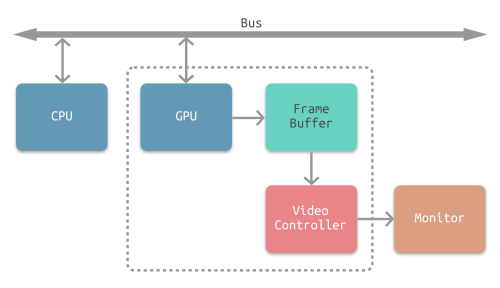
渲染流程如圖所示:
CPU將要顯示的圖形透過frame計算、圖片解碼等處理後將需要繪製的紋理圖形資料透過匯流排BUS提交至GPU,
GPU經過對影像的紋理混合、頂點變換與計算、畫素點的填充計算等處理後轉化為一幀幀的資料並提交至幀緩衝區,
iOS採用雙緩衝機制,GPU會預先渲染一幀放入一個緩衝區中,用於影片控制器的讀取。當下一幀渲染完畢後,GPU會直接把影片控制器的指標指向第二個緩衝器,如下圖所示:
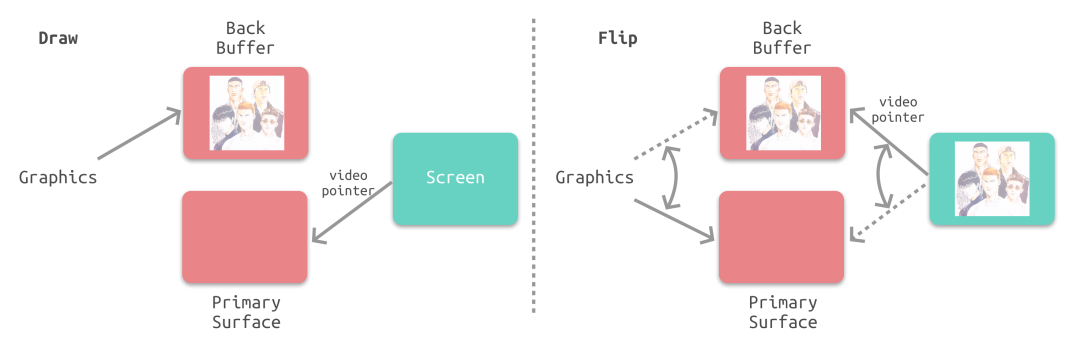
4. 影片控制器會透過垂直同步訊號VSync逐幀讀取幀緩衝區的資料並提交至螢幕控制器最終顯示在螢幕上。
卡頓的產生
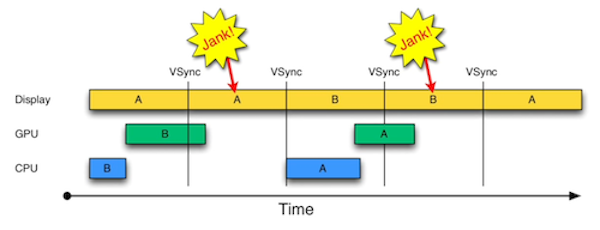
在顯示系統的VSync訊號到來後,系統圖形服務會通知App,App主執行緒開始在CPU中計算顯示內容,比如檢視的建立、佈局計算、圖片解碼、文字繪製等。隨後CPU會將計算好的內容提交到GPU,由GPU進行變換、合成、渲染。隨後GPU會把渲染結果提交到幀緩衝區去,等待下一次VSync訊號到來時顯示到螢幕上。由於垂直同步的機制,如果在一個VSync時間內,CPU或者GPU沒有完成內容提交,則那一幀就會被丟棄,等待下一次機會再顯示,而這時螢幕會保留之前的內容不變。這就是介面卡頓的原因。
卡頓最佳化方案的選擇
從上文卡頓產生的原因我們可以發現,如果想要減少卡頓就需要減輕CPU以及GPU的壓力。我們參考了現有對於卡頓最佳化的方案,比較主流的有:Graver和Texture (AsyncDisplayKit)。
Graver
Graver是美團18年底開源的iOS非同步渲染框架,由於某些爭議的原因Graver取消了開源,不過可以透過fork過的倉庫可以找到 ()) 。
Graver的基本思路就是從“拼控制元件”到“畫控制元件”,Graver的每個繪製元素透過WMMutableAttributedItem來表達內容資訊、渲染資訊,CGRect 表達繪製元素的大小和位置。渲染整個過程除畫板檢視外,完全沒有使用 UIKit 控制元件,最終產出的結果是一張點陣圖(Bitmap)。如果能透過一棵樹形結構組織所有的繪製元素即繪製結點樹,即可按照遞迴遍歷的方式“畫控制元件”來轉義“拼控制元件”構建檢視。Graver把每個cell都以一張點陣圖的形式進行展現。
優點:
效能:Graver有效提升空閒CPU的資源利用率,降低峰值CPU的佔用率
非同步化:Graver從文字計算、樣式排版渲染、圖片解碼,再到繪製,實現了全程非同步化,並且是執行緒安全的
效能消耗的“邊際成本”低:Graver渲染整個過程除畫板檢視外完全沒有使用 UIKit 控制元件,最終產出的結果是一張點陣圖(Bitmap),檢視層級、數量大幅降低
渲染速度快:Graver併發進行多個畫板檢視的渲染、顯示工作。得益於圖文混排技術的應用,達到了記憶體佔用低,渲染速度快的效果。
缺點:
靈活性:Graver透過將所有子檢視/圖層壓扁的形式來減少圖層的層級,比較適用於靜態內容渲染的場景,但失去了檢視/圖層樹,也相應就失去了樹形結構的靈活性。
複雜性:由於檢視最終透過渲染點陣圖來呈現,這就需要建立基於點陣圖的事件處理系統;動效等無法依託Graver進行圖文渲染,需要考慮跨渲染引擎融合。
維護性:由於Graver已不再開源,後期維護成本較高。
Texture (AsyncDisplayKit)
Texture (AsyncDisplayKit)是2012年由Facebook開始著手開發,並於2014年出品的高效能顯示類庫,主要作者是Scott Goodson。
Texture的基本思路就是非同步:我們知道對於一般UIView和CALayer來說,因為不是執行緒安全的,任何相關操作都需要在主執行緒進行。Texture引入了Node的概念來解決UIView/CALayer只能在主執行緒上操作的限制。Texture需要建立UIView時替換成對應的Node來獲取效能提升。
優點:
效能:由於ASDisplayNode的顯示是非同步的,因此可以在主執行緒以外進行,並且有快取,效能有很大提升。
維護性:由於ASDK是開源的,除錯難度大大降低。
缺點:
學習曲線陡峭:Texture由於大量原本熟悉的操作變成非同步,對於一個團隊來說學習曲線也較為陡峭。
現有業務改造工作量大:Texture對於現有程式碼改動較大,侵入性較高。Texture使用的是Flex佈局,如果想對已有的view改造成用Flexbox進行佈局,需要重新使用ASDisplayNode來實現相應的view。
方案的選擇
經過上述對Graver和Texture(AsyncDisplayKit)兩種主流方案的研究,結合我們公開課現有的業務無法接入這兩種方案。原因如下:
由於Graver已不再維護,以及依然有較多的限制性的問題,導致接入後的風險及不可控性過高
由於公開課資訊流是基於現有業務進行最佳化改造,接入Texture會使開發成本成倍增長。
基於上述原因,我們決定借鑑這兩種方案的非同步渲染思想對公開課資訊流做最佳化。
最佳化實踐
預排版
檢視佈局計算是應用最為常見的消耗CPU資源的地方,其最終實現都會透過UIView.frame/bounds/center等屬性的調整上,並且文字寬高計算也會佔用很大一部分資源,並且不可避免。我們針對公開課資訊流的業務場景,同時結合MVVM架構模式,衍生出公開課資訊流的架構模式。我們在原有的MVVM架構模式插入了Layout層用於儲存資訊流中的佈局資訊,如下圖所示:
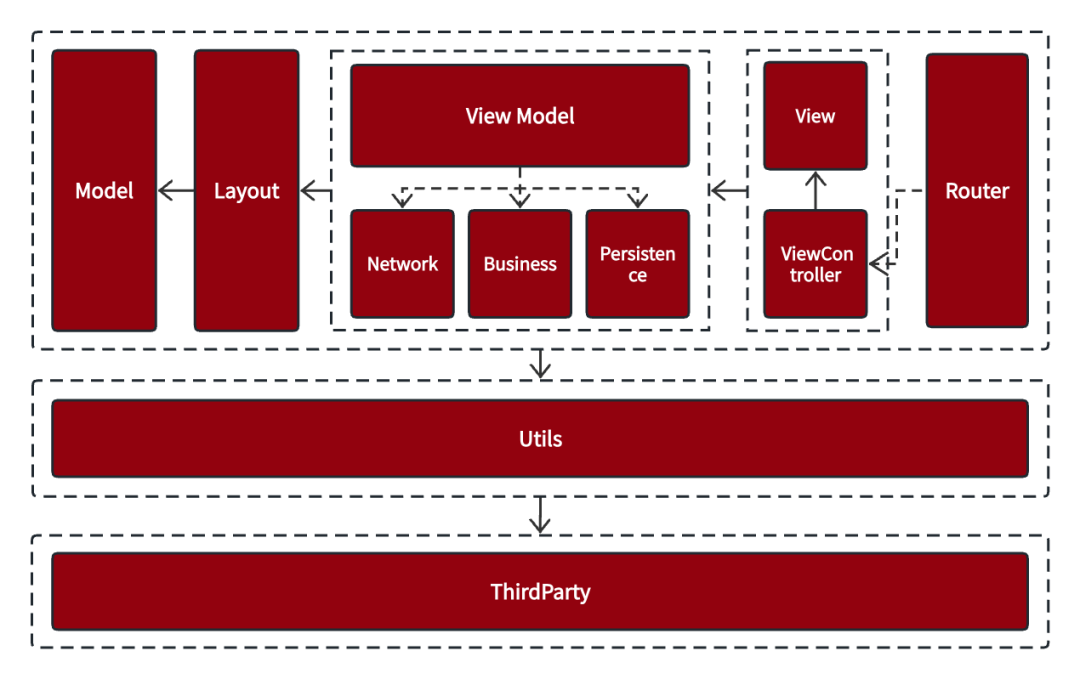
ThirtyParty:主要包含第三方pod庫以及我們自己下沉的脫離了業務的本地開發庫
Utils: 主要是一些工具類;
Router:公開課路由跳轉;
ViewController&View:用於資訊的展示;
ViewModel:用於網路請求,業務資料處理、持久化以及資訊流中佈局元素的計算等;
Layout:用於展示的佈局資訊,比如cell的寬高、渲染資訊、模型資料等;
Model:業務資料模型;
資訊流涉及多個執行緒互動,整體流程如下:
主執行緒構建請求引數,建立請求任務並放入網路執行緒佇列中,發起網路請求。
網路執行緒向後端服務發起請求,獲得對應的資訊流模型資料。
網路請求獲得資訊流資料模型後,將其交由並行佇列進行預排版,其中包含佈局、渲染資訊的排版模型。解析結束後,通知主執行緒排版完成。
主執行緒獲取排版模型後,隨即觸發資訊流的過載。相對不同的排版資訊交由生成對應的Cell,並進行資料的顯示。
非同步渲染
文字的非同步渲染
螢幕上能看到的所有文字內容控制元件,包括UIWebView,在底層都是透過CoreText排版、繪製為Bitmap顯示。常見的文字控制元件,如UILabel、UITextView等,其排版和繪製都是在主執行緒進行,當顯示大量文字時,CPU的壓力會非常大。 因此我們決定對資訊流中的文字進行最佳化。為了避免重複造輪子,我們採用YYLabel的非同步渲染機制,對於資訊流中的文字進行非同步繪製。非同步渲染機制核心程式碼如下:

圖片的非同步渲染
圖片檔案被載入就必須要進行解碼,解碼過程是一個相當複雜的任務,需要消耗CPU非常長的時間。當使用UIImage或CGImageSource的那幾個方法建立圖片時,圖片資料並不會立即解碼。只有圖片設定到UIImageView或者CALayer.contents中去,並且CALayer被提交到GPU前,CGImage中的資料才會得到解碼,且需要在主執行緒執行。因此我們對圖片解碼過程做了非同步處理。
對於網路圖片或者本地圖片的非同步渲染核心程式碼如下:

檢視層級最佳化
所有的Bitmap,包括圖片、文字、柵格化的內容,最終都要從記憶體提交到視訊記憶體,繫結為GPU紋理。不論是提交到視訊記憶體的過程,還是GPU調製和渲染紋理的過程,都要消耗不少GPU資源。在多檢視且多層次重疊顯示時,GPU會首先將其混合在一起。如果檢視結構很複雜,混合的過程也會消耗很多的GPU資源。 為了減輕GPU的消耗,我們對Cell中的檢視層級做了最佳化,最佳化策略如下:
減少冗餘檢視控制元件:刪除Cell中不必要的檢視控制元件。
檢視合併:將檢視中小的icon和文字使用NSAttributedString合併成一個檢視控制元件來達到減少檢視層級的目的。
預排版機制:利用預排版的機制提前將TextLayout計算並快取在記憶體中,以便在顯示時可以直接使用以及避免了重複繪製的問題。
使用輕量級檢視:使用相對於UIView更輕量級的CALayer來替代原有的UIView進行顯示。例如我們將Cell的原UIImageView實現的漸變蒙層替換成CALayer來進行程式碼實現。
離屏渲染最佳化
GPU螢幕渲染存在兩種方式:當前螢幕渲染(On-Screen Rendering)和離屏渲染(Off-Screen Rendering),其中當前螢幕渲染就是正常的GPU渲染流程,GPU將渲染完成的幀放到幀緩衝區,然後顯示到螢幕;而離屏渲染會額外建立一個離屏渲染緩衝區(如儲存後續複用的資料),後續仍會提交至幀緩衝區進而顯示到螢幕。離屏渲染需要建立新的緩衝區,渲染過程中會涉及從當前螢幕切換到離屏環境多次上下文環境切換,等到離屏渲染完成後還需要將渲染結果切換到當前螢幕環境,因此付出的代價較高。
CALayer的border、圓角、陰影、遮罩(mask),CASharpLayer的向量圖形顯示,通常會觸發離屏渲染(offscreen rendering),而離屏渲染通常發生在GPU中。當一個列表檢視中存在大量圓角的CALayer切換滑動時,會消耗大量的GPU資源,進而引發介面卡頓。
為了避免產生離屏渲染,我們對Cell中的檢視做了以下最佳化:
cornerRadius最佳化:我們使用CAShapeLayer+UIBezierPath繪製圓角來實現圓角的繪製。
shadow最佳化:我們棄用了原有普遍使用的shadow設定的方法,轉而使用shadowPath去設定陰影
圖片的最佳化:我們棄用了原UIImageView對圓角的處理,轉而將網路圖片預處理成帶有圓角的圖片,然後進行顯示。
下圖為最佳化前後,離屏渲染對比效果。從圖中我們可以看到,經過上述最佳化,我們完全避免了資訊流的離屏渲染。
總結
最佳化效果
經過上述的最佳化,我們在降低資訊流卡頓率上收穫到了一定的效果。透過對比效能較差的iPhone7和iPad Air及以下機型上的資訊流顯示幀率,我們進行了最佳化前後的對比。在最佳化前,資訊流的顯示幀率在35~45FPS之間,而經過最佳化後,資訊流的顯示幀率得到顯著提升,達到了55~60FPS,如下圖所示:
經驗總結
以上都是結合我們公開課資訊流業務卡頓制定的方案,因此,我們也從實踐中總結出一些如何避免卡頓的的方案,如下所示:
預排版:在顯示之前可以透過將資訊流中的資料提前在並行佇列中進行計算佈局,最後提交主執行緒進行顯示。
非同步渲染:可以將文字和圖片在將內容提交給layer.contents之前交給並行佇列處理,最後交由主執行緒進行顯示。
檢視層級縮減:可以透過減少、合併檢視來達到縮減檢視層級的目的。
使用輕量級的檢視:儘量使用CALayer替代UIView。
避免離屏渲染:透過對cornerRadius、shadow、圓角的最佳化來避免產生離屏渲染。
以上是我們公開課對卡頓最佳化的一些經驗總結,希望能為iOS開發者在卡頓最佳化的實踐中帶來一些啟發。iOS的卡頓最佳化是一個複雜且艱鉅的任務,它涉及到程式碼的重構、邏輯的重寫、底層元件的改動,在最佳化的同時,還必須要保障業務邏輯的正常和穩定。
後續規劃
持續效能最佳化:當前的效能最佳化工作還有一些方面沒有涉及到,例如儘量減少物件的建立和釋放、按需載入以及光柵化等。在後續的工作中,我們將繼續對這些方面進行最佳化,以進一步提升效能。
線上卡頓監控:目前我們只能在測試裝置上進行除錯和最佳化,無法實時監測線上真實使用者的卡頓情況。因此,我們計劃對接入線上版本的卡頓檢測進行研究和調研,以便及時發現和解決線上卡頓問題。
來自 “ 網易傳媒技術團隊 ”, 原文作者:趙英如;原文連結:https://server.it168.com/a2024/0116/6837/000006837191.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 網易互娛資料成本最佳化治理實踐
- iOS實戰公開課視訊 Swift語法答疑第七期iOSSwift
- 吳恩達機器學習網易公開課視訊和講義吳恩達機器學習
- 初識React:仿網易公開課(react+antd)React
- 社交場景下iOS訊息流互動層實踐iOS
- 教你爬取騰訊課堂、網易雲課堂、mooc等所有課程資訊
- 移動APP卡頓問題解決實踐APP
- 爬蟲實踐之獲取網易雲評論資料資訊爬蟲
- iOS App卡頓監控(Freezing/Lag)iOSAPP
- 大眾點評資訊流基於文字生成的創意最佳化實踐
- ios微信小程式 BLE藍芽通訊開發介面UI卡頓問題iOS微信小程式藍芽UI
- thinkphp開發 網易雲課堂-線上IT學習|視訊教程|慕課網PHP
- IM開發乾貨分享:萬字長文,詳解IM“訊息“列表卡頓優化實踐優化
- 【今晚8點】2020年網易面試真題解析公開課面試
- iOS獲取SIM卡資訊iOS
- iOS免費公開課答疑第四期視訊錄播iOS
- 資料標準在網易的實踐
- 網易戲精ARCore短視訊新玩法實踐
- 洪增林:網易遊戲統一資料流平臺架構與實踐遊戲架構
- iOS開發——專案實戰總結&UITableView效能優化與卡頓問題iOSUIView優化
- 史丹佛iOS Swift開發公開課總結(一)iOSSwift
- Stanford iOS10 公開課知識點(3)iOS
- Stanford iOS10 公開課知識點(6)iOS
- Stanford iOS10 公開課知識點(1)iOS
- ios使用openlayer地圖縮放時卡頓iOS地圖
- 不到 0.3s 完成渲染!360 資訊流正文“閃開”優化實踐優化
- oracle資料庫卡頓Oracle資料庫
- iOS開發實踐-OOM治理iOSOOM
- Flutter、iOS混合開發實踐FlutteriOS
- iOS 獲取裝置uuid,公網ip,手機ip等資訊iOSUI
- 滴水公開課
- RunLoop實戰:實時卡頓監控OOP
- 網易數帆實時資料湖 Arctic 的探索和實踐
- 【騰訊課堂】視訊點播上雲實踐
- 網易雲課堂影片課件課程下載工具,如何在電腦端下載網易雲課堂影片課程課件資料到本地?
- android檢測卡頓問題,recycleview卡頓AndroidView
- 網站開啟卡如何進行最佳化網站
- 網易 Android 遊戲保護實踐Android遊戲