網易嚴選跨域多目標演算法演進
導讀:嚴選是網易旗下受新中產喜愛的電商品牌,覆蓋居家生活、服飾鞋包、美食酒水、個護清潔、母嬰親子、運動戶外、數碼家電等品類。嚴選站內業務包括核心入口頁、活動頁、商詳頁,還有其他小流量的場景。目前這些場景都已經實現了個性化推薦演算法的覆蓋,嚴選電商推薦場景中演算法建模面臨多目標平衡、多場景資料如何共用等問題的挑戰,針對這些挑戰,本次主要分享跨域多目標在嚴選推薦演算法中的實踐。

01 背景介紹

推薦系統的總體流程可以分成四塊,主要是召回、粗排、精排、重排。其中精排會承載很多業務模組的業務指標,在不同業務模組,關注的業務指標有所不同。對於某一些業務指標,存在轉化資料比較稀疏,以及冷啟動的問題。另外,我們在與業務方的交流中發現,他們關注的一些業務指標與演算法目標不直接相關,需要我們去做一些長期價值的探索。
嚴選精排演算法演進過程,開始是基於深度學習的 CTR 單目標建模,然後在此基礎上增加了基於使用者行為序列進行建模,接著衍生到多目標建模,最後是跨域多目標建模。
02 多目標建模及最佳化
1. 樣本與特徵
近年來,多目標建模是業界排序建模的主流方式,而業務資料和特徵工程決定了模型的上限。

在多目標建模中,我們選取使用者的點選與轉化行為為正樣本,根據 Skip-Above 原則,選取曝光未點選的樣本作為負樣本。此外,在樣本構造中還會注意以下幾個最佳化點:
頭部的熱門商品可能存在過曝光,需要對這種 Top 流量的商品做降取樣。
短時間之內會存在同一商品的多次曝光,需要在時間視窗對樣本進行聚合,保留點選樣本、剔除曝光未點選樣本。
虛假曝光,第一種是使用者在刷 Feed 流瀏覽時,快速滑躍或無意識的快速瀏覽時的曝光;第二種是由於頁面佈局的影響,導致卡片頭部一定比例在頁面載入時預設曝光。這兩種曝光實際上並沒有對使用者產生心智影響,因此,需要定製規則去噪。
假正樣本,主要包含使用者的誤點以及點進去之後快速回退的操作,使用者並沒有對商品產生興趣,這類正樣本也需要特殊處理。
特徵工程方面,我們將其分為四類:數值特徵、類別特徵、序列特徵和 Embedding。各類特徵處理方式如下:
數值特徵的處理,對連續特徵進行歸一化,或者採用 RankGauss[1](Rank 預處理保留資料排序資訊,並轉化為高斯分佈);然後進行分桶,再計算 Embedding 。
類別特徵,透過雜湊對映,對於頻率出現過低的一些類別做過濾,同時保留一個預設和異常處理的坑位,再計算 Embedding。
序列特徵,把使用者行為互動序列中的每個元素進行embedding,再做attention 或者 Pooling 操作。
Embedding 特徵,主要是商品側的表徵特徵,基於一個預訓練模型得到的Embedding 作為模型中對應的商品側表徵的初始化權重;為處理值域過大的情況,可以做 Normalize 操作。
2. 模型結構迭代
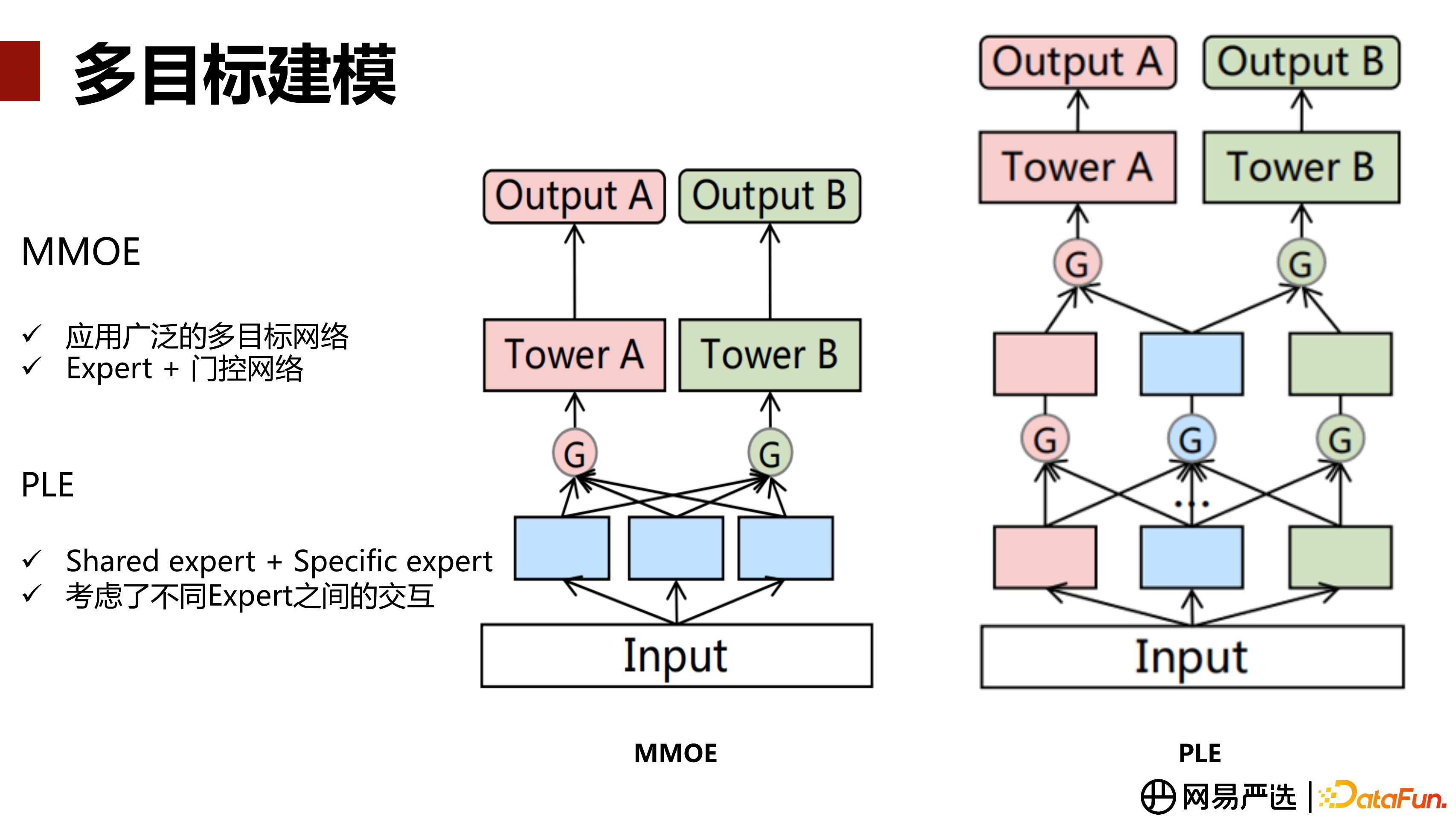
目前業界主流的多目標建模的網路結構是 MMOE[2] 和 PLE[3] 兩種,我們也分別迭代了這兩種結構。MMOE 是基於專家網路和門控做多工學習的框架,它的特點是每個任務有單獨的門控網路,同時在底部共享幾個專家網路,透過不同的門控網路去控制專家網路對於不同任務的權重貢獻。PLE 是在 MMOE 的基礎上更加細粒度化,在專家網路共享的同時,還給每個任務單獨提供獨有的專家網路。這個獨有的網路會去強化每一個任務的權重學習,能夠有效地避免在 MMOE 中可能由於某些任務的訓練占主導地位,帶偏小任務的問題;也可以讓不同任務的專家,透過整合方式,進行權重互動。
3. 位置偏差與 Debias
上面介紹了資料特徵處理和使用基礎的多目標網路結構進行建模,在此基礎上,會根據實際業務場景的問題進行最佳化。
第一個問題是位置偏差,位置偏差是指推薦 Feed 流場景下使用者傾向點選/互動曝光位置靠前的物品,這個資訊蘊含在正樣本里,可能會導致建模存在偏差。如下圖左上角是對某個業務模組做的位置偏差分析,橫軸是時間,縱軸是曝光點選率。可以看到隨著坑位的逐漸往下,曝光點選率逐漸下降。基於帶位置偏差的資料進行模型訓練,會形成一個迴圈反饋,模型去學習這種趨勢,然後做預測推薦,會導致位置偏差在不斷地放大,從而導致整體的推薦流量生態出現問題,比如部分商品過曝光。
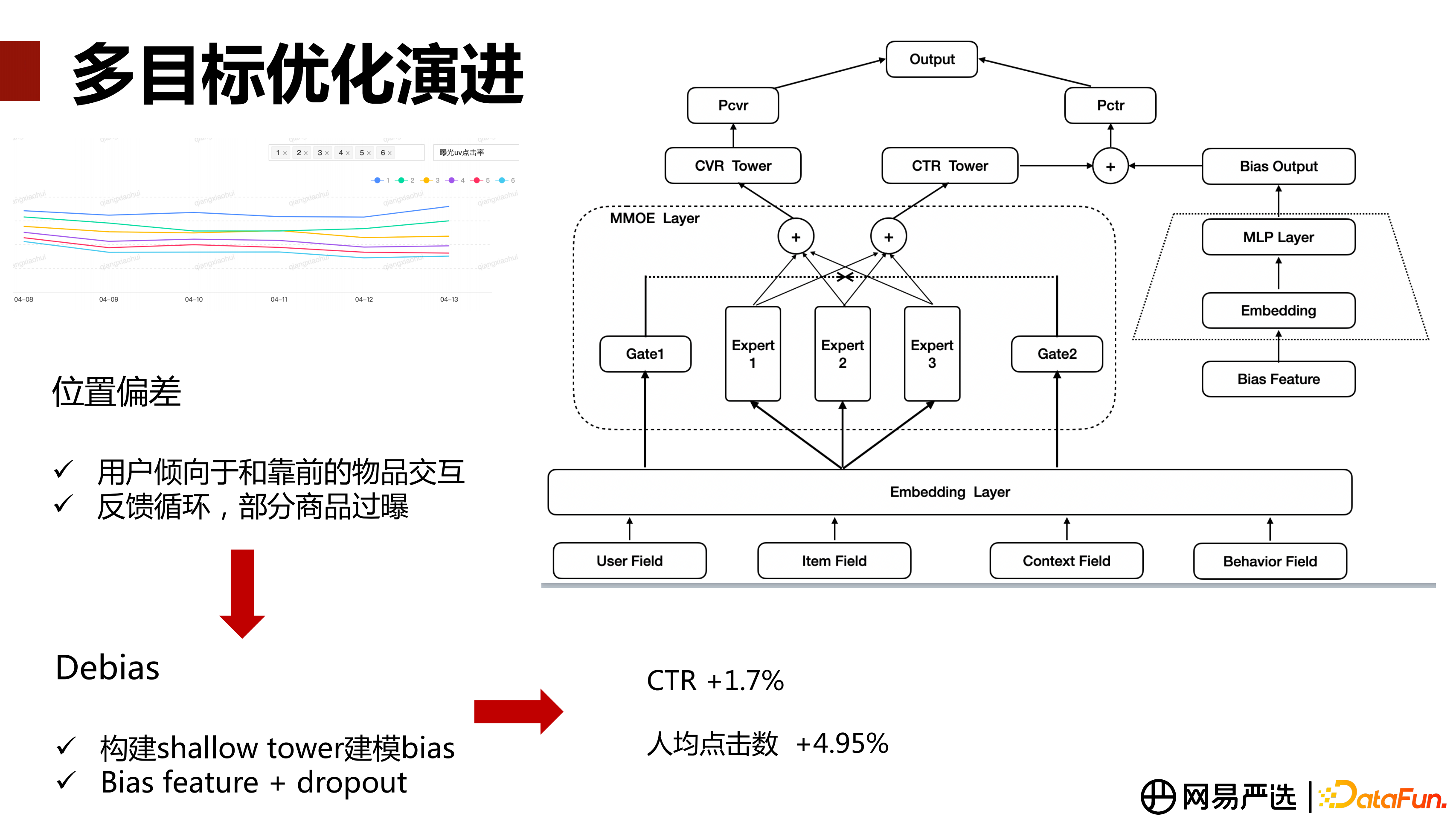
存在的位置偏差需要做 Debias 的操作。我們做 Debias 的方式是在 MMOE 多工的基礎上,加一個消偏模組。整體結構如上圖右邊部分,輸入是常見的幾類特徵(使用者側、商品側、情境上下文,行為互動序列特徵)。經過特徵預處理後,輸入到 Embedding 層,然後會進入 MMOE 主網路。同時會構建一個 Debais 輔助網路,輸入主要是 Bias 相關的特徵(比如商品曝光的坑位、裝置的型號、使用者的身份等可能影響到展示位置的特徵),經過淺層網路後得到bias 的學習表徵。然後把這個結果與多工主網路學出來的 CTR 結果直接相加,再經過一層啟用函式得到最終 CTR 預測結果,CVR 網路無任何操作。Debais 輔助網路的淺層部分,會加上 Dropout,主要是為了防止模型學習結果過於依賴淺層網路的特徵,保證模型的魯棒性。
多工模型 Debias 最佳化上線 AB 後,人均點選數+4.95%、曝光點選率+1.70%。需要說明的是,Debias 最佳化需要根據具體業務特點做判斷,我們的場景 AB 剛上線前幾天,會對某些業務指標產生非正向收益,因為 Debias 會對熱門做打壓,對長尾的商品進行扶持,這可能會影響銷售額。Debias 最佳化,本質上是從整體業務生態或者長期收益的角度考慮問題,在短期內能承載一部分收益下降的前提下,可以推全放量,它會帶動整體推薦流量生態向良性、健康的方向發展。
4. 多目標 Loss 最佳化
此外,在 CTR 跟 CVR 目的基礎上根據業務方的需求增加更多的目標,包括加購、評論商品、檢視促銷資訊、分享、收藏等。有些目標如收藏、分享的轉化資料相對會比較稀疏,這些任務與 CTR、CVR 樣本比較豐富的任務一起訓練時,由於樣本過於稀疏,會導致訓練不夠充分,被帶偏。
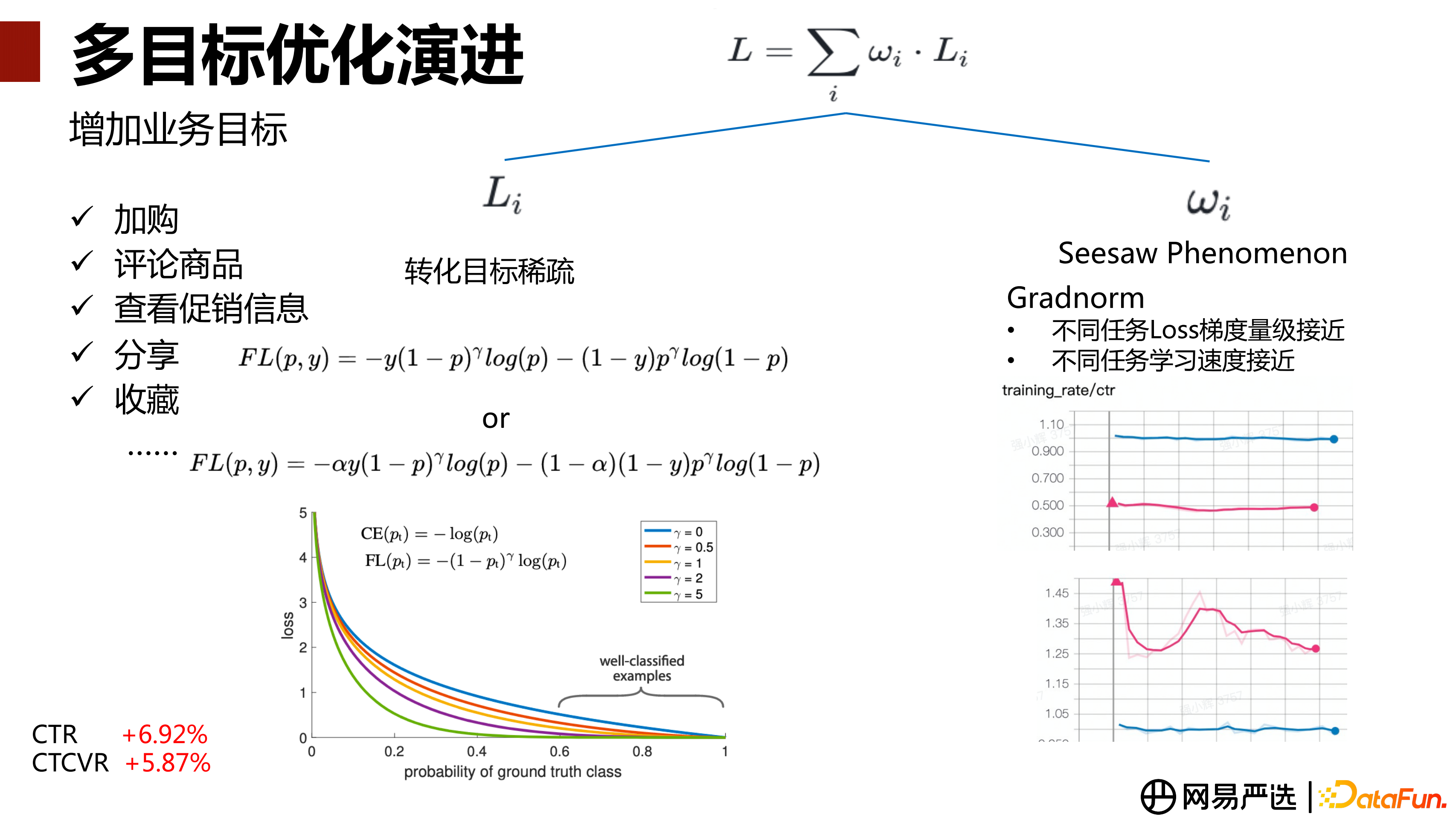
針對轉化目標比較稀疏,訓練不充分的問題。我們會考慮在損失函式上引入 Focal Loss[4] 替換交叉熵函式。如上圖中的 FL(p, y),Focal Loss 在交叉熵基礎上,增加了 P 和 Gamma 兩個引數,P 就是模型預測樣本是否為正樣本的機率。看損失函式第一項,對於正樣本,P 的預測接近 1 時,1-p 的 Gamma 次方會更加接近於 0,那麼很容易區分的那部分正樣本,損失會下降非常明顯;P 的預測接近 0 時,損失無太大變化。對負樣本的處理與正樣本同理。Focal Loss 目的是讓 Loss 去關注/聚焦比較難以區分樣本資訊,Gamma 引數是去調節聚集程度。還可以再引入一個類別權重引數A lpha,去解決正負樣本不平衡的問題。比如 Alpha 定義為正負樣本比,增強正樣本的損失影響。
另外,多個子任務一起訓練時可能存在某個子任務被帶偏的情況,即蹺蹺板(Seesaw Phenomenon)效應。我們嘗試使用 Gradnorm[5] 梯度歸一化來控制 WI 的權重。梯度歸一的目標是讓不同的任務的 Loss 梯度量級更加接近,同時還可以讓不同任務的學習速率也更加接近。透過這兩個點最佳化 WI 權重,讓各個任務的學些更加平衡。上圖右下角兩張圖是 CTR、CVR 訓練速度的展示。紅線是它原有的訓練速度,藍線是經過 Gradnorm 調整之後的,可以看到調整之後,訓練的速度接近 1 左右,不會出現速度訓練過快或過慢的情況。
多目標損失最佳化,引入 Focal Loss 和 GradNorm 控制損失權重後,整體上線 AB 實驗,CTR +6.92%,CTCVR+5.87%,都有顯著提升。
5. 跨域多目標建模
在我們的業務中,會涉及到很多場景,比如新客、新品頁面,使用者的行為資料會比較稀疏,還有新上線的業務模組,剛上線資料非常少,處於冷啟狀態。那麼在這些場景下,如何能夠讓模型學習得更好呢?那就需要考慮多場景的跨域建模。引入多場景的好處在於,首先讓模型先意識到場景之間的差異性,建模擬合對映由 P(y|x) -> P(y|x, d),輸入增加了場景資訊(Domain)。另外小樣本的場景,能夠透過對樣本更加豐富/比較成熟模組的場景共性的刻畫和遷移學習,讓模型對小場景也能夠取得更好的效果。

跨域多目標演算法的整體網路結構,如上圖。
底層輸入特徵(包括使用者側、商品側、上下文情境、行為序列特徵),經過特徵預處理進入 Embedding 層,然後進 MMOE 層進行多工的資訊抽取。網路右邊部分是一個輔助網路,把域/不同場景/Domain Field 相關的特徵輸入,然後經過一個 Domain Tower 得到對應場景的抽象特徵。然後將場景的抽象特徵與多工的輸出表徵共同輸入到 STAR 網路層(參考阿里 STAR 文章[6]),STAR 的拓撲結構裡包含兩種塔:共享 Share塔、表徵不同場景的 Domain塔。Share塔主要去學習場景的一些共性資訊,Domain 塔去學習各個不同場景對應的獨特資訊,之後對兩邊塔的權重進 Element相乘後得到的結果,作為每個場景的權重,最終得到每個場景下不同任務的輸出。
這個最佳化上線後,在主場景和小樣本場景上取得的效果有些差異,小樣本場景下的提升更加明顯,曝光轉化率和曝光點選率有 10.8% 和 3.5% 的相對提升。主場景下,本身資料比較豐富,效果提升沒有那麼顯著,曝光轉化率和曝光點選率分別有 2.2% 和 0.81% 的提升。
03 長期價值探索
此外,我們還做了一些提升長期價值的探索工作,分別是多業務混排和使用者留存最佳化。我們有很多業務模組,除了向使用者透出商品卡片,還需要拓出場景化的如榜單、清單卡片、活動卡片等,這些資訊在同一個模組展示,如何做到個性化的頁面佈局,需要做混排策略,我們基於湯普森取樣演算法[7],根據線上使用者的實時行為互動,做 Reward 反饋,這個反饋對每個使用者去擬合 Beta 分佈,在 Beta 分佈上算使用者對三種卡片的點選機率。如果使用者剛點選過很多場景化卡片,可能後續會推更多場景化卡片。但場景化或者活動性卡片,對於我們的業務價值可能不如商品卡片那麼高, 如何判斷混排這個動作到底有沒有價值,需要去做比較長時間週期(1個月以上)的 AB 實驗 ,觀察單個模組和全站資料表現,如果全站 UV 價值和全站加購率提升,那混排就是有價值的。
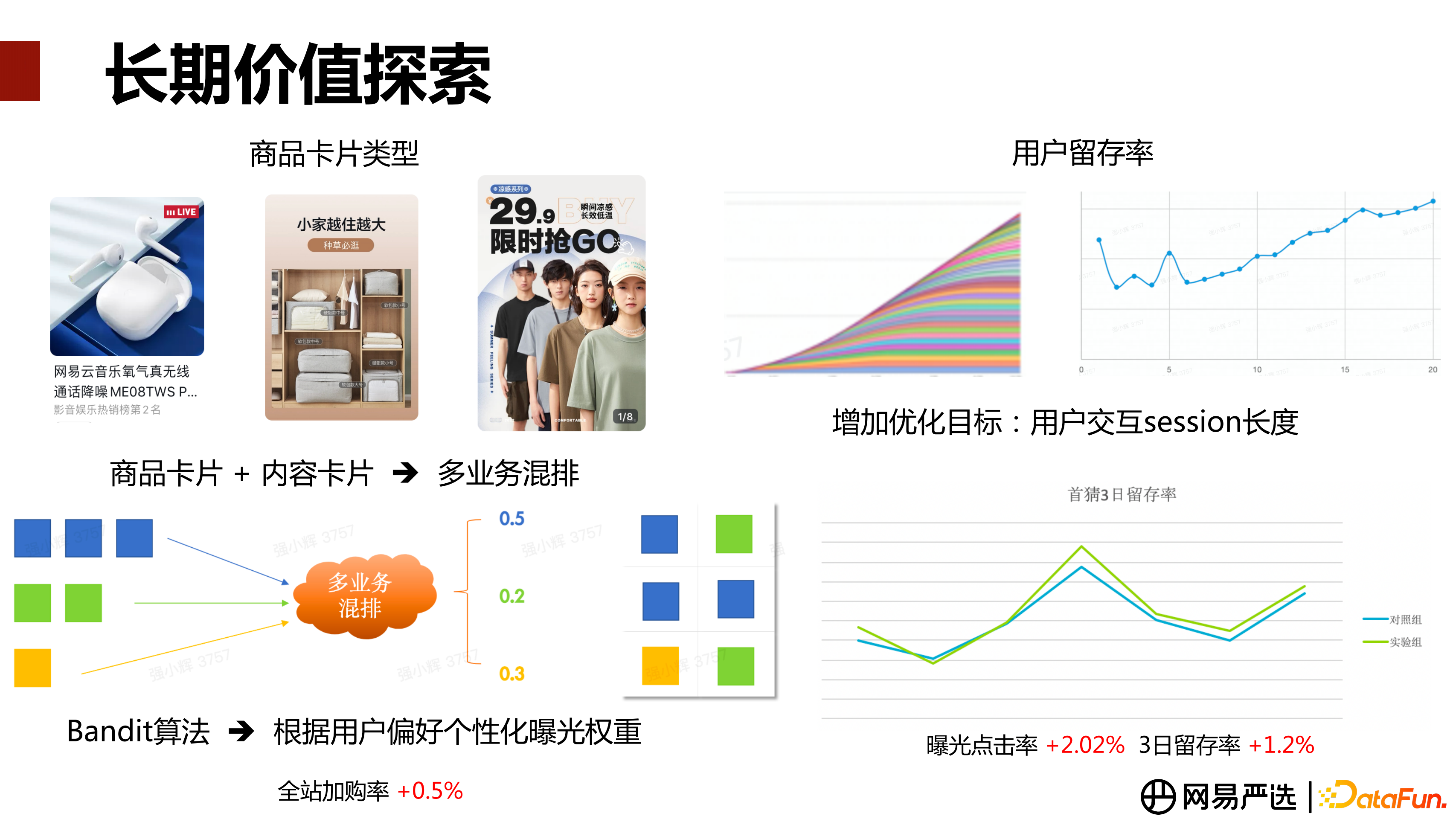
使用者留存最佳化,是指關注使用者在一些模組當中有停留且有後續的行為,而不是僅關注短期產生的價值,比如我們希望在簽到或者其他模組,能夠透過留存來增加後期的使用者價值收益,那就需要考慮如何透過主動干預來來提留存。如上圖,透過資料分析可以看到使用者互動 Session 長度與 3 日留存率會顯著正相關(Session 長度 6-20),所以,可考慮最佳化使用者互動 Session 長度。具體做法是在多目標建模中增加戶互動的 Session 長度目標。這塊我們建模最佳化之後得到的 AB 結論是,在首猜場景下,曝光點選率跟 3 日留存率會有一定的提升。這裡也是需要我們做價值上的判斷和取捨,看是否能夠接受短期損失,比如說某個模組在 1 到 3 天之內部分使用者未回訪,但是 3 日內還沒有返回,到第三天或者第四天才進行回訪和留存,之後才產生價值。這個過程可能會產生一些業務價值的波動,但時間週期拉長,會看到整體的收益比短期能覆蓋的範圍更大。
04 多場景建模實踐
1. 什麼是多場景建模?
下面結合嚴選某業務場景,細粒度介紹多場景建模的具體實踐和應用。業務定義上,根據業務場景我們將業務分為核心場景和通用推薦場景。核心場景包括核心入口頁猜你喜歡、購物車、個人頁等,它的特點是流量大,位置顯著,資料豐富,會承擔一些核心的業務指標。其他的中小流量場景,統稱為通用推薦場景,特點是流量少、資料稀疏,但模組數量很龐大、場景非常豐富。接下來主要針對通用推薦場景介紹多場景建模的思路。

關於多場景的定性,不同的使用者群體(新客、老客)、不同客戶端(iOS 、安卓)、App 中的不同模組,因為他們的商品展示形式或對使用者心智影響等有一些顯著差異,只要在資料上有明顯的差異,都可視為多場景的一個子場景。
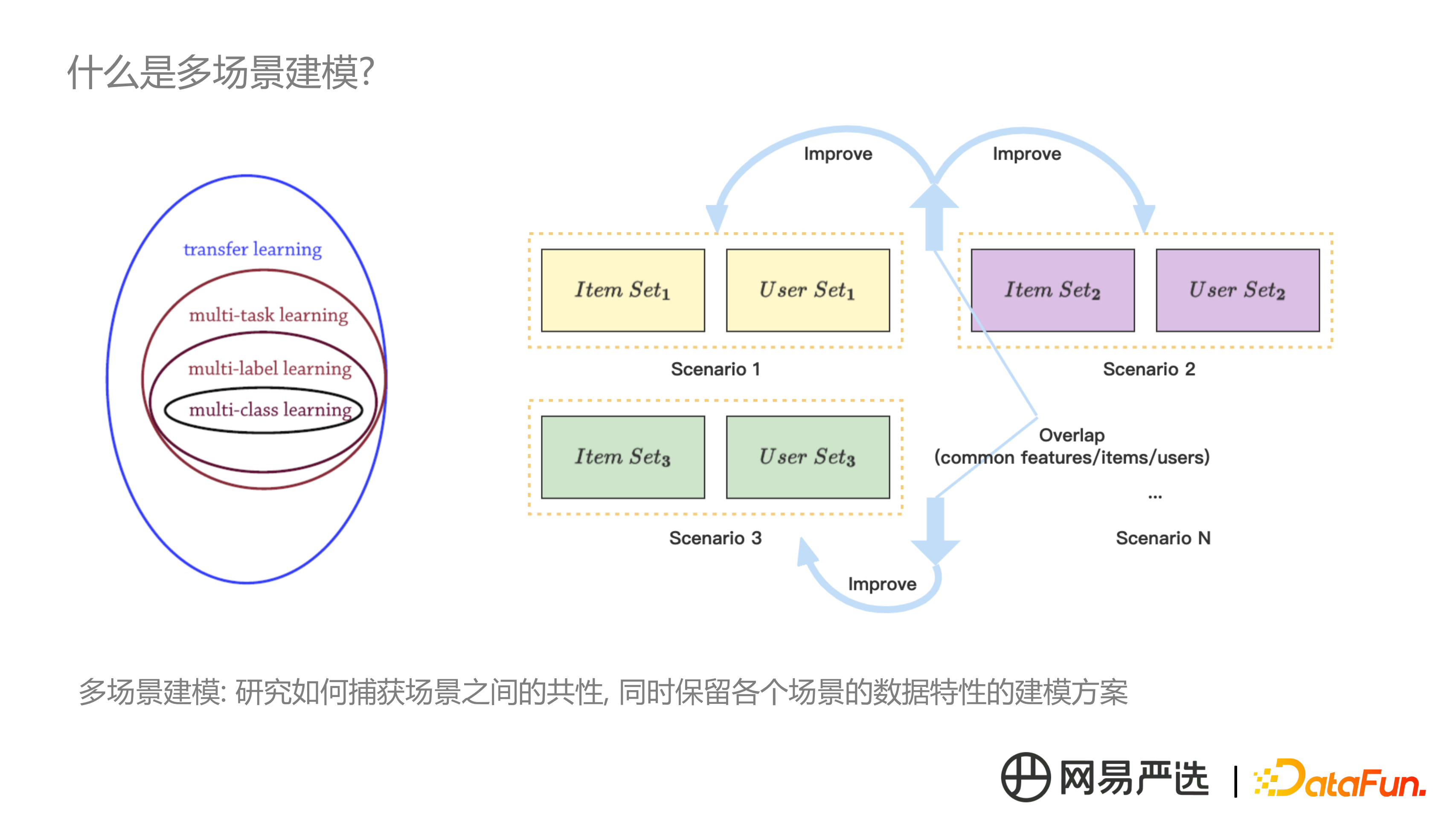
關於多場景建模,沒有確切的定義,與學術上遷移學習和跨域推薦比較接近。在實際建模方案落地中,主要考慮如何捕獲場景間的共性,同時保留各個場景的資料本身的特點。機器學習有個基礎假設,訓練資料要服從獨立同分布,實際上各場景的訓練資料的分佈存在顯著差異。
2. 為什麼多場景建模?
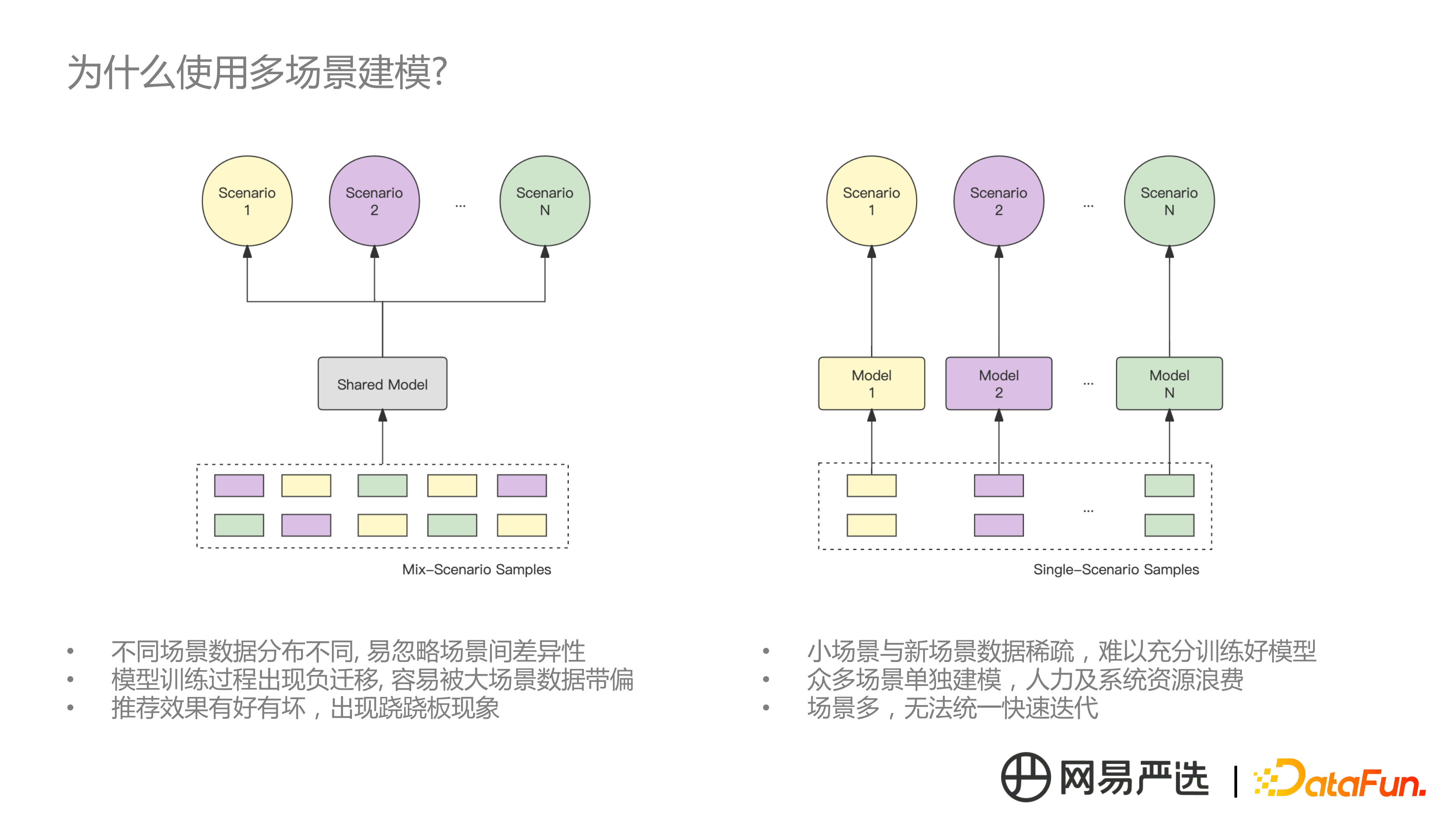
如上左圖,是我們之前採取的方案,在通用推薦場景下,多個場景採用同樣的推薦演算法。最早期採用同一套 CF 演算法,後來切換成向量演算法,在後來淺層深度模型。這會存在問題,把所有場景的資料混合在一起去訓練模型,完全沒有考慮到各個場景之間存在的資料差異性,模型訓練方向會被大流量場景的資料帶偏,導致推薦效果是一個的中庸的效果,即各個場景下都不是最優的。
另外一種極端做法,如上右圖是針對每個場景,都建立一個模型,這樣做的問題是小場景或新接入場景的資料比較稀,少量的樣本很難訓練出比較好的模型。同時維護成本非常高,迭代不方便。
3. 如何進行多場景建模?

我們從特徵工程入手,先構造一些場景的特徵,在輸入層直接拼接到現有模型中,但實際效果並不理想。因為最底層加入的這些場景資訊特徵,經過多層抽象網路很難傳遞到末端,被模型學習到。透過分析各場景商品的 CTR 分佈,有較明顯的差異,因此場景資訊有很強的先驗知識。如上右圖可以透過一個偏置網路,類似位置消偏,認為不同場景資料分佈的差異性是由該場景偏差導致的,偏置網路的輸出層加回主網路。這個簡單的做法,只在在一些場景上有一定效果,大部分沒效果。原因是僅僅依賴偏置網路進行糾偏,對不同場景的特徵分佈差異,沒有進行很好的捕獲。
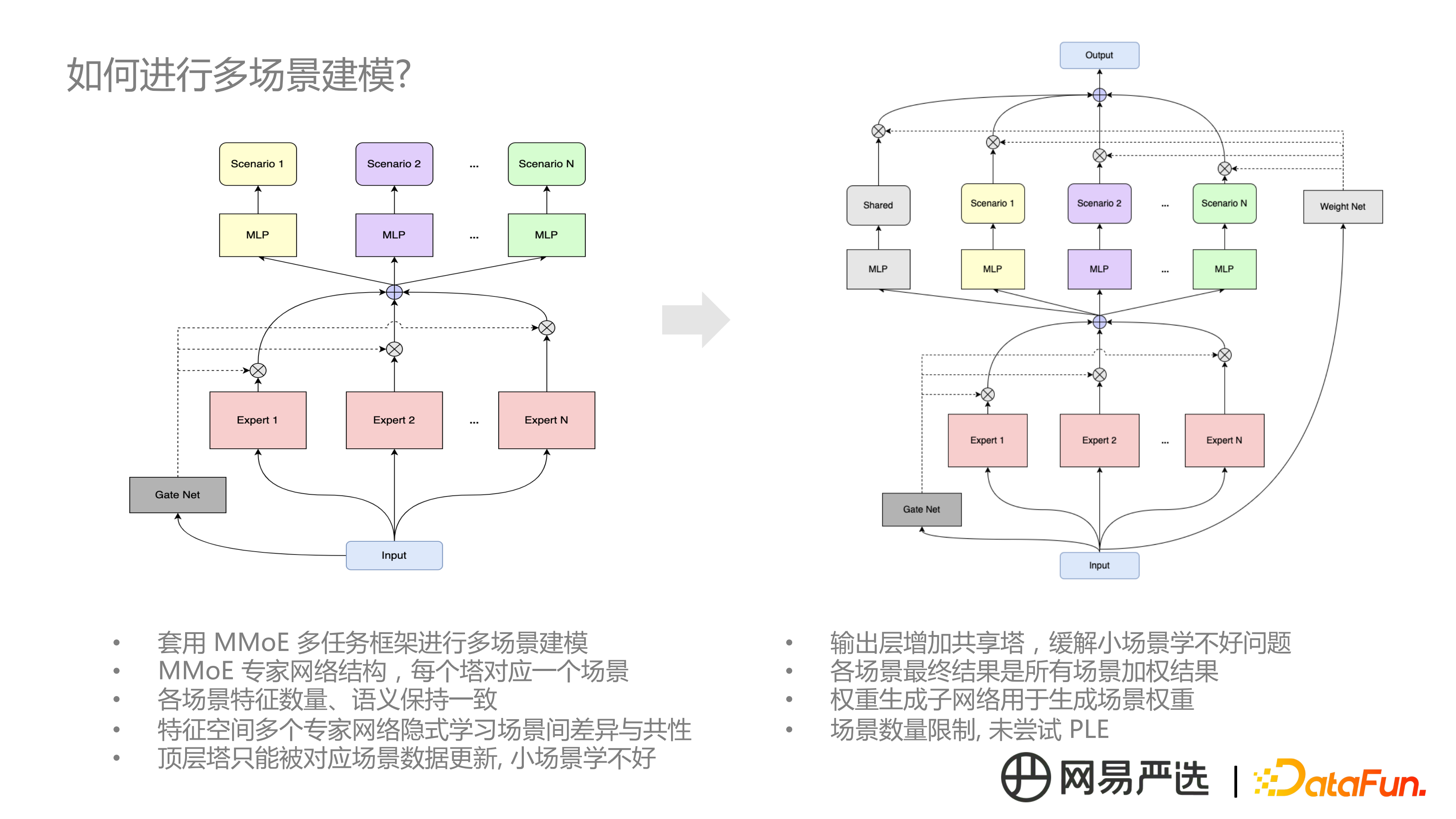
在此基礎上,套用 MMOE 多工框架進行多場景建模。頂層的每個塔對應一個場景,各個場景的特徵數量和語義是保持一致的,如果某個場景有獨特的特徵,其他場景下特徵用預設值代替,MMOE 裡用多個專家網路來隱式地學習場景間的差異和共性。但也有個問題,模型訓練中,每個場景資料只單獨更新對應塔權重,這樣會導致某些小場景學不好,效果不大。另一方面場景特徵資訊,也沒有得到顯示的表達。基於這兩方面考慮,在 MMOE 基礎上增加了一個模組,首先在頂層增加 1 個共享塔,我們認為即使某個場景做預測時,其他場景也會對這個場景的預測起到貢獻,此外接到頂層有個權重生成自網路,類似門控矩陣形式,最終該場景的預測是由所有場景的加權結果,這能夠緩解小場景學不好的問題。由於場景數量較多導致 PLE 模型過於複雜,並可能帶來的延時問題,未嘗試。
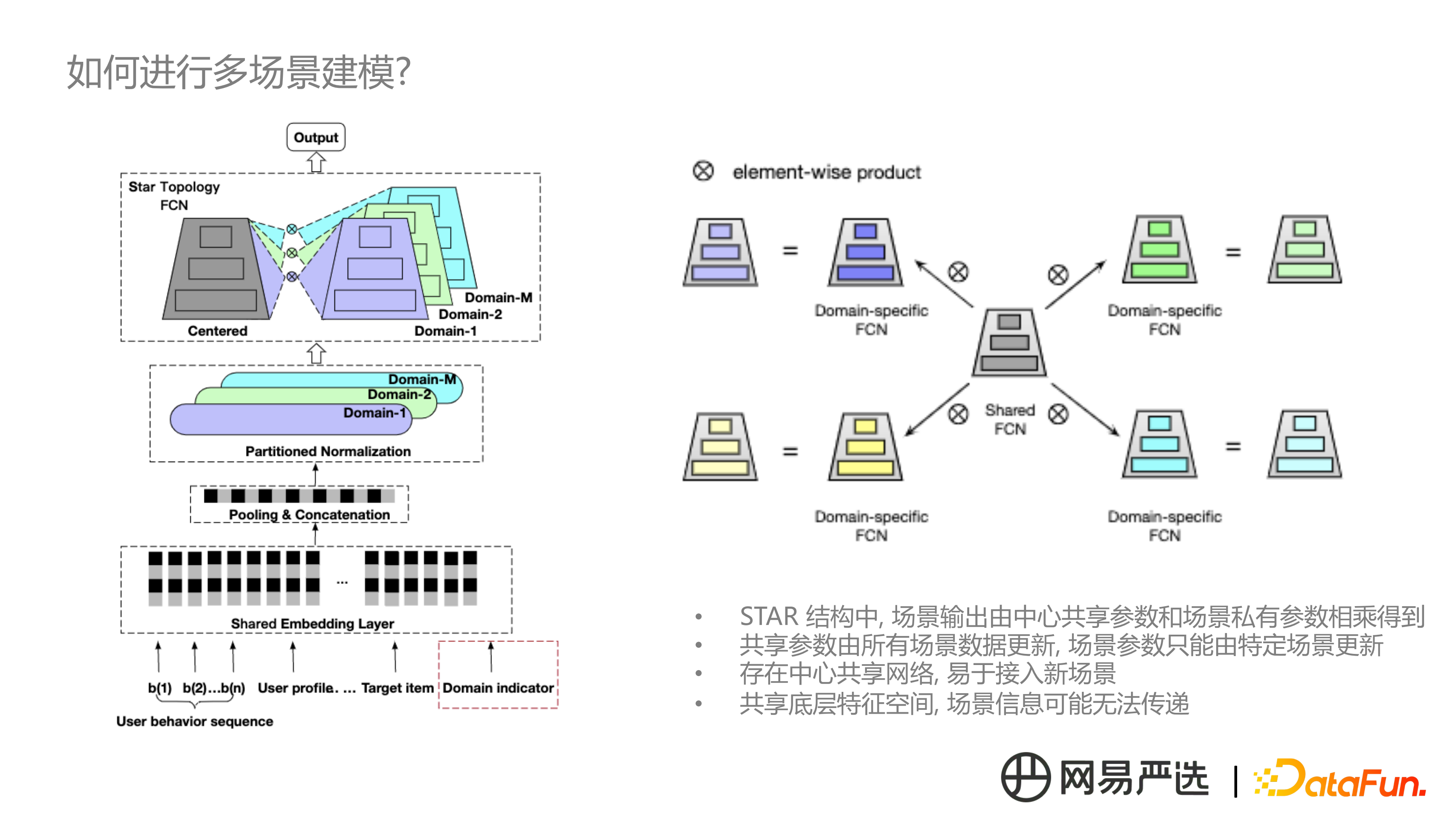
在實踐中參考的另一個解決方案是阿里的 STAR 星型結構模型,底層是特徵共享層,往上 BatchNorm 的時候,區分場景分別進行,頂層不同的場景分別對應一個塔,同時有一個共享的中心塔。最終每個場景的輸出結果是由場景塔和中心塔相乘得到的,引數更新方式是共享的引數是由所有場景的樣本資料同時更新,場景引數只能由特定場景的樣本去更新。但這個方案也存在場景特徵資訊無法顯示錶達的問題,因為底層的特徵空間是共享的。為了解決這個問題,它的做法是把場景特徵過一個偏置網路,把場景資訊的資訊直接傳遞到輸出層,類似方案一。
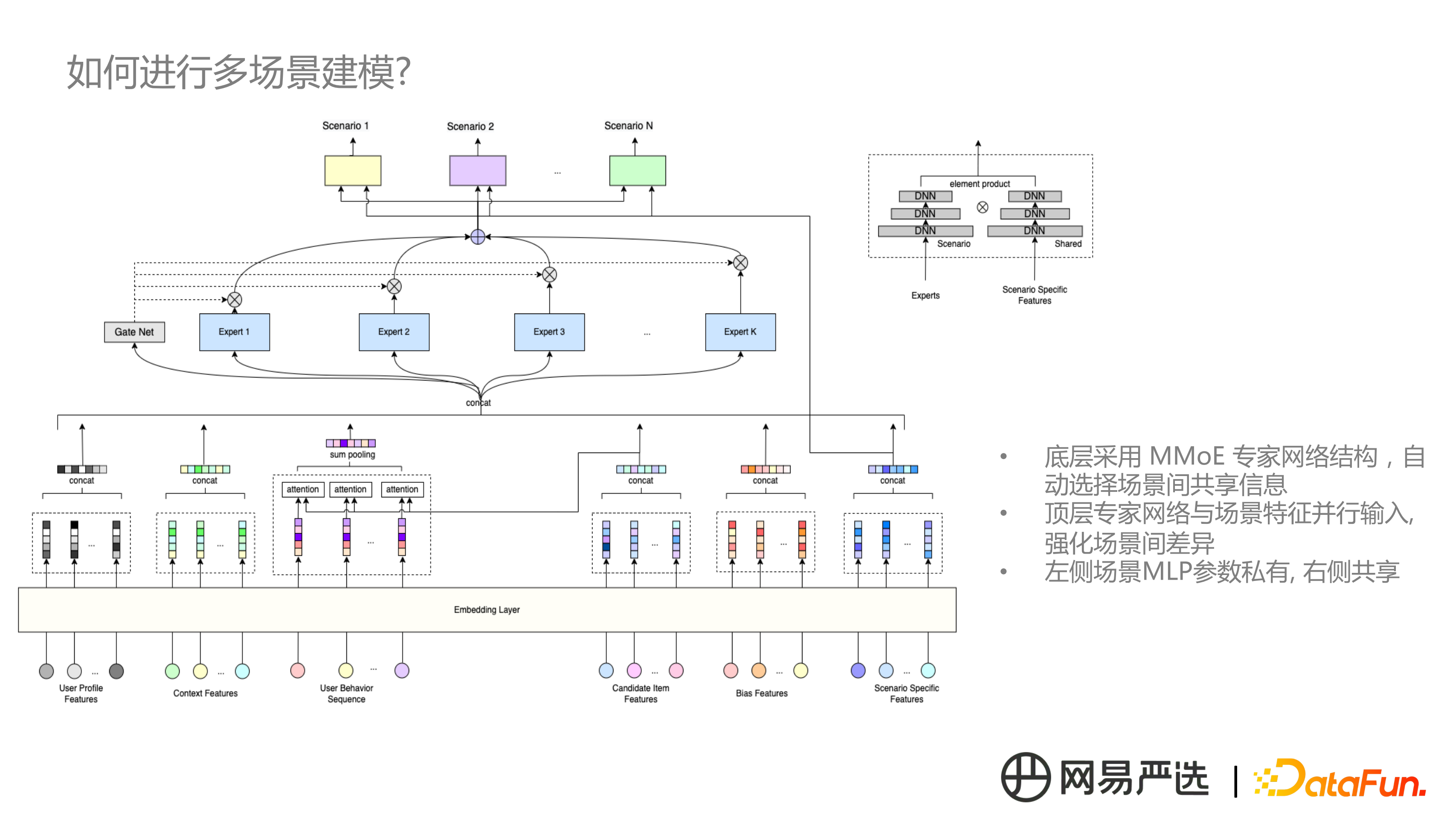
最後的方案還是以 MMOE 為基礎,底層特徵共享,MMOE 專家網路結構自動選擇場景間共享資訊,同時針對每個場景考慮特徵來源,上圖中右上角為各場景的輸出結構,由 MMOE 專家網路和底層的場景特徵資訊直接傳遞,並行輸入。左側場景 MLP 引數私有,右側 MLP 引數共享。
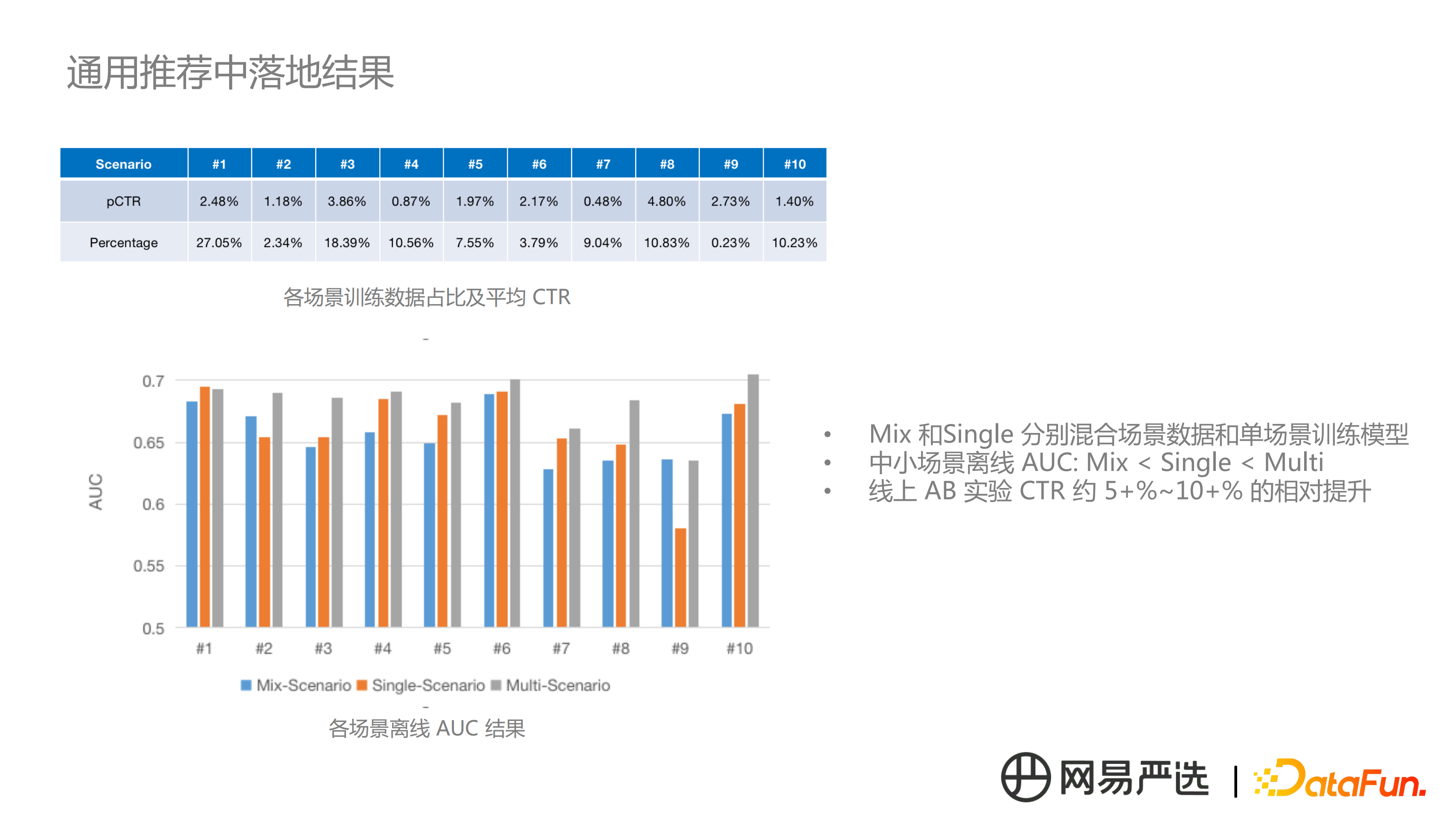
接下來看下在通用推薦場景中的落地情況,上圖中列舉了 10 個場景,其中 Mix 和 Single 分別表示用混合場景和單場景資料去訓練模型,Multi 代表多場景建模。從 AUC 結果可以看到,如果場景資料量比較充足的情況下(#1),單場景資料訓練的 AUC 高於混合場景資料訓練,同時和多場景建模是 AUC 基本持平。對於小場景(#9),資料稀疏,單場景資料訓練效果不好。線上效果是在某些場景 pCTR 有 5%-10% 的提升。
來自 “ 網易有數 ”, 原文作者:強小輝&陳自強;原文連結:http://server.it168.com/a2022/1117/6775/000006775668.shtml,如有侵權,請聯絡管理員刪除。
相關文章
- 分類TAB商品流多目標排序模型的演進排序模型
- 網易嚴選的wkwebview測試之路WebView
- 網易數帆資料治理演進
- WEEX-EROS | 移植自網易嚴選 app demoROSAPP
- 網易嚴選離線數倉治理實踐
- 多種跨域方案跨域
- 跨平臺技術演進
- GitHub Daily - Taro 實戰網易嚴選三端專案GithubAI
- 【目標區域捕獲-2】目標區域捕獲簡介
- IIS配置多域名跨域跨域
- 跨端小程式框架 --Taro演進跨端框架
- 高德網路定位演算法的演進演算法
- 多目標跟蹤全解析,全網最全
- 多目標遺傳演算法NSGA-Ⅱ與其Python實現多目標投資組合優化問題演算法Python優化
- Java使用位域進行多標記(狀態)管理Java
- 多目標優化演算法(一)NSGA-Ⅱ(NSGA2)優化演算法
- 跨域庫herryPostMessage.js的一些優化,多iframe跨域跨域JS優化
- 多種跨域方式實現原理跨域
- goldengate同源一目標+多表和同源多目標+多表Go
- 2021直播電商下半場,“網易嚴選們”為何成主播良港?
- 跨域問題(普通跨域和springsecurity跨域)跨域SpringGse
- BSN官方培訓精選:FISCO BCOS共識演算法演進之路演算法
- 嚴選好物,嚴選小程式
- 前端技術演進(七):前端跨棧技術前端
- 跨平臺技術演進及Flutter未來Flutter
- 目標跟蹤演算法概述演算法
- vue中proxyTable反向代理進行跨域Vue跨域
- 【多目標優化演算法】非支配的精英策略遺傳演算法:NSGA-II優化演算法
- Flutter:移動端跨平臺技術演進之路Flutter
- 移動開發的跨平臺技術演進移動開發
- 【Flutter 專題】97 仿網易新聞標籤選擇器Flutter
- 目標檢測演算法學習演算法
- 目標跟蹤演算法分類演算法
- opencv的目標跟蹤演算法OpenCV演算法
- 跨域跨域
- 網路 Server 模型的演進Server模型
- DL目標檢測技術演進(通俗易懂,看一遍能記一輩子!)
- 深度學習|基於MobileNet的多目標跟蹤深度學習演算法深度學習演算法